このゲスト投稿は、Planet Labs のビジネス開発スペシャリストである Lydia Lihui Zhang とソフトウェア エンジニア/データ サイエンティストの Mansi Shah の共同執筆です。 の この投稿のきっかけとなった分析 原作はジェニファー・ライバー・カイルによって書かれました。
Amazon SageMaker の地理空間機能 と組み合わせること 惑星の衛星データは作物の細分化に使用でき、この分析には農業と持続可能性の分野に数多くの応用例と潜在的な利点があります。 2023 年後半、プラネット パートナーシップを発表 AWS と連携して地理空間データを利用できるようにする アマゾンセージメーカー.
クロップのセグメンテーションは、衛星画像を同様のクロップ特性を持つピクセルの領域、つまりセグメントに分割するプロセスです。 この投稿では、セグメンテーション機械学習 (ML) モデルを使用して、画像内のトリミング領域と非トリミング領域を識別する方法を説明します。
作物地域の特定は、農業に関する洞察を得るための中核となるステップであり、豊富な地理空間データと ML を組み合わせることで、意思決定と行動を促進する洞察を得ることができます。 例えば:
- データに基づいて農業に関する意思決定を行う – 作物の空間的理解をより良くすることで、農家やその他の農業関係者は、季節を通じて水から肥料、その他の化学物質に至るまで、資源の使用を最適化できます。 これにより、廃棄物を削減し、可能な限り持続可能な農業慣行を改善し、環境への影響を最小限に抑えながら生産性を向上させるための基盤が確立されます。
- 気候関連のストレスと傾向の特定 – 気候変動が地球の気温と降雨パターンに影響を与え続けているため、作物のセグメント化を使用して、気候適応戦略のための気候関連ストレスに対して脆弱な地域を特定できます。 たとえば、衛星画像アーカイブを使用して、作物栽培地域の経時的な変化を追跡できます。 これらは、農地のサイズと分布の物理的な変化である可能性があります。 また、作物の健全性をより深く分析するために、衛星データのさまざまなスペクトルインデックスから得られる土壌水分、土壌温度、バイオマスの変化も考えられます。
- 被害の評価と軽減 – 最後に、作物のセグメンテーションを使用すると、自然災害が発生した場合に作物の被害地域を迅速かつ正確に特定でき、救援活動の優先順位付けに役立ちます。 たとえば、洪水の後、高頻度の衛星画像を使用して作物が水没または破壊された地域を特定できるため、救援団体は被害を受けた農家をより迅速に支援できるようになります。
この分析では、K 最近傍 (KNN) モデルを使用して作物のセグメンテーションを実行し、これらの結果を農業地域のグラウンド トゥルース画像と比較します。 私たちの結果は、KNN モデルによる分類が、2017 年のグラウンド トゥルース分類データよりも 2015 年の現在の作物畑の状態をより正確に表していることを明らかにしました。これらの結果は、Planet の高ケイデンス地理空間画像の力の証拠です。 農地は頻繁に、時には季節に複数回変化します。この土地の観察と分析に高周波衛星画像を利用できることは、農地と急速に変化する環境を理解する上で計り知れない価値をもたらします。
Planet と AWS の地理空間 ML におけるパートナーシップ
SageMaker の地理空間機能 データ サイエンティストと ML エンジニアが地理空間データを使用してモデルを構築、トレーニング、デプロイできるようにします。 SageMaker 地理空間機能を使用すると、大規模な地理空間データセットを効率的に変換または強化し、事前トレーニングされた ML モデルを使用してモデル構築を加速し、3D 高速グラフィックスと組み込みの視覚化ツールを使用してインタラクティブなマップ上でモデル予測と地理空間データを探索できます。 SageMaker の地理空間機能を使用すると、衛星画像やその他の地理空間データの大規模なデータセットを処理して、この投稿で説明する作物のセグメンテーションなど、さまざまなアプリケーション向けの正確な ML モデルを作成できます。
プラネットラボPBC は、大規模な衛星群を使用して地球表面の画像を毎日取得している、地球画像の大手企業です。 したがって、Planet のデータは地理空間 ML にとって貴重なリソースです。 その高解像度の衛星画像を使用すると、地球上のどこにいても、さまざまな作物の特性とその健康状態を長期にわたって識別できます。
Planet と SageMaker のパートナーシップにより、顧客は AWS の強力な ML ツールを使用して、Planet の高周波衛星データに簡単にアクセスして分析できるようになります。 データ サイエンティストは、環境を切り替えることなく、独自のデータを持ち込んだり、Planet のデータを簡単に見つけてサブスクライブしたりできます。
地理空間画像を使用した Amazon SageMaker Studio ノートブックでのクロップセグメンテーション
この地理空間 ML ワークフローの例では、Planet のデータをグラウンド トゥルース データ ソースとともに SageMaker に取り込む方法と、KNN 分類子を使用してクロップ セグメンテーション モデルをトレーニング、推論、デプロイする方法を説明します。 最後に、結果の精度を評価し、これをグラウンド トゥルース分類と比較します。
使用される KNN 分類器は、 地理空間を備えた Amazon SageMaker Studio ノートブック 画像を提供し、地理空間データを操作するための柔軟で拡張可能なノートブック カーネルを提供します。
Amazon SageMakerスタジオ 地理空間画像を含むノートブックには、GDAL、Fiona、GeoPandas、Shapely、Rasterio などの一般的に使用される地理空間ライブラリがプリインストールされており、Python ノートブック環境内で地理空間データを直接視覚化して処理できます。 OpenCV や scikit-learn などの一般的な ML ライブラリも、KNN 分類を使用したクロップ セグメンテーションの実行に使用され、これらも地理空間カーネルにインストールされます。
データの選択
私たちがズームインする農地は、カリフォルニア州のいつも晴れているサクラメント郡にあります。
なぜサクラメントなのか? このタイプの問題に対するエリアと時間の選択は、主にグラウンド トゥルース データが利用できるかどうかによって決まりますが、作物の種類や境界データなどのデータを入手するのは簡単ではありません。 の 2015 年サクラメント郡土地利用 DWR 調査データセット は、その年のサクラメント郡をカバーする公開されているデータセットであり、手動で調整された境界を提供します。
私たちが使用する主な衛星画像は、惑星の 4 バンドです。 PSScene 製品これには、青、緑、赤、および近赤外のバンドが含まれており、センサーの放射輝度に放射測定的に補正されます。 センサーでの反射率を補正するための係数はシーンのメタデータで提供され、異なる時間に撮影された画像間の一貫性がさらに向上します。
この画像を生成した Planet's Dove 衛星は、14 年 2017 月 XNUMX 日に打ち上げられました (ニュースリリース)そのため、2015 年にはサクラメント郡の画像を撮影していませんでした。しかし、サービス開始以来、この地域の画像を毎日撮影しています。 この例では、グラウンド トゥルース データと衛星画像の間にある不完全な 2 年のギャップに落ち着きます。 ただし、Landsat 8 の低解像度画像は、2015 年から 2017 年までの橋渡しとして使用できた可能性があります。
Planet データにアクセスする
ユーザーが正確で実用的なデータをより迅速に取得できるようにするために、Planet は Python 用の Planet ソフトウェア開発キット (SDK) も開発しました。 これは、衛星画像やその他の地理空間データを扱うデータ サイエンティストや開発者にとって強力なツールです。 この SDK を使用すると、Planet の高解像度衛星画像の膨大なコレクションや、OpenStreetMap などの他のソースからのデータを検索してアクセスできます。 この SDK は、Planet の API への Python クライアントとコード不要のコマンド ライン インターフェイス (CLI) ソリューションを提供し、衛星画像や地理空間データを Python ワークフローに簡単に組み込むことができます。 この例では、Python クライアントを使用して、分析に必要な画像を特定してダウンロードします。
簡単なコマンドを使用して、地理空間画像を含む Planet Python クライアントを SageMaker Studio ノートブックにインストールできます。
クライアントを使用して、関連する衛星画像をクエリし、対象地域、時間範囲、およびその他の検索基準に基づいて利用可能な結果のリストを取得できます。 次の例では、いくつあるかを尋ねることから始めます。 プラネットスコープのシーン (Planet の毎日の画像) は、1 年 1 月 2017 日から 10 月 XNUMX 日までの特定の時間範囲を考慮して、サクラメントの地上データを通じて以前に定義したのと同じ対象地域 (AOI) をカバーしています。 および XNUMX% という特定の望ましい最大雲カバレッジ範囲:
返された結果には、対象領域と重複する一致するシーンの数が表示されます。 これには、各シーンのメタデータ、イメージ ID、およびプレビュー イメージの参照も含まれます。
特定のシーンを選択した後、シーン ID、アイテム タイプ、製品バンドルを指定します (リファレンスドキュメント)、次のコードを使用して画像とそのメタデータをダウンロードできます。
このコードは、対応する衛星画像を AmazonElasticファイルシステム SageMaker Studio の (Amazon EFS) ボリューム。
モデルトレーニング
Planet Python クライアントを使用してデータをダウンロードした後、セグメンテーション モデルをトレーニングできます。 この例では、KNN 分類と画像セグメンテーション技術の組み合わせを使用して、トリミング領域を特定し、地理参照された geojson フィーチャを作成します。
Planet データは、SageMaker の組み込み地理空間ライブラリとツールを使用してロードおよび前処理され、KNN 分類器のトレーニング用に準備されます。 トレーニング用のグラウンド トゥルース データは、2015 年のサクラメント郡土地利用 DWR 調査データセットであり、モデルのテストには 2017 年の Planet データが使用されます。
グラウンド トゥルース フィーチャを等高線に変換する
KNN 分類器をトレーニングするには、各ピクセルのクラスを次のいずれかにします。 crop or non-crop 特定する必要があります。 クラスは、ピクセルがグラウンド トゥルース データのクロップ フィーチャに関連付けられているかどうかによって決定されます。 この決定を行うために、まずグラウンド トゥルース データが OpenCV 等高線に変換され、次にそれが分離に使用されます。 crop から non-crop ピクセル。 ピクセル値とその分類は、KNN 分類器のトレーニングに使用されます。
グラウンド トゥルース フィーチャを等高線に変換するには、まずフィーチャを画像の座標参照系に投影する必要があります。 次に、特徴は画像空間に変換され、最後に輪郭に変換されます。 輪郭の精度を確保するために、次の例に示すように、輪郭は入力画像に重ねて視覚化されます。
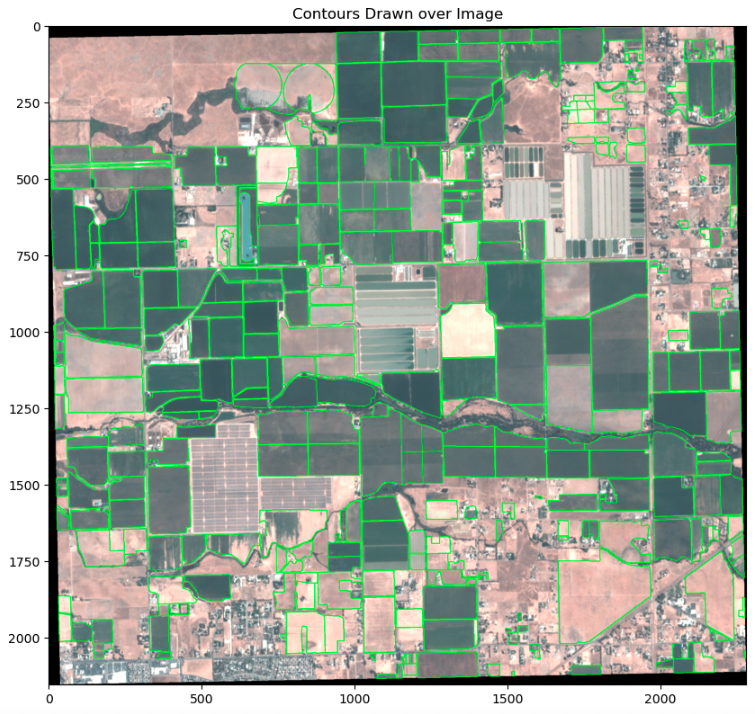
KNN 分類器をトレーニングするには、トリミング フィーチャの輪郭をマスクとして使用して、トリミング ピクセルと非トリミング ピクセルを分離します。

KNN 分類器の入力は 2 つのデータセットで構成されます。X、分類対象の特徴を提供する 1 次元配列。 y はクラスを提供する XNUMX 次元配列 (例)。 ここでは、単一の分類されたバンドが非クロップ データセットとクロップ データセットから作成されます。バンドの値はピクセル クラスを示します。 次に、バンドとその下にある画像のピクセル バンド値が、分類子フィット関数の X 入力と y 入力に変換されます。

クロップピクセルとクロップ以外のピクセルで分類器をトレーニングします。
KNN 分類は次のように実行されます。 scikit-learn KNeighborsClassifier。 近傍数は、推定器のパフォーマンスに大きく影響するパラメーターであり、KNN 相互検証の相互検証を使用して調整されます。 次に、準備されたデータセットと調整された数の近傍パラメーターを使用して分類器がトレーニングされます。 次のコードを参照してください。
入力データに対する分類器のパフォーマンスを評価するために、ピクセル バンド値を使用してピクセル クラスが予測されます。 分類器のパフォーマンスは主に、トレーニング データの精度と、入力データ (ピクセル バンド値) に基づくピクセル クラスの明確な分離に基づいています。 近傍数や距離重み関数などの分類器のパラメーターを調整して、後者の不正確さを補正できます。 次のコードを参照してください。
モデルの予測を評価する
トレーニングされた KNN 分類器は、テスト データ内の作物領域を予測するために利用されます。 このテスト データは、トレーニング中にモデルに公開されなかった領域で構成されます。 言い換えれば、モデルには分析前にその領域に関する知識がないため、このデータを使用してモデルのパフォーマンスを客観的に評価できます。 まず、比較的ノイズの多い領域から始めて、いくつかの領域を視覚的に検査します。

目視検査により、予測されたクラスがグラウンド トゥルース クラスとほぼ一致していることがわかります。 逸脱している領域がいくつかありますので、さらに検査します。

さらなる調査により、この領域のノイズの一部は、機密画像に存在する詳細が欠けているグラウンド トゥルース データによるものであることがわかりました (左上および左下と比較して右上)。 特に興味深い発見は、分類器が川沿いの木を次のように識別したことです。 non-crop、一方、グラウンドトゥルースデータはそれらを誤って次のように識別します。 crop。 これら XNUMX つのセグメンテーション間のこの違いは、作物の上でその地域を木々が覆っているためである可能性があります。
これに続いて、2015 つの方法間で異なるように分類された別の領域を検査します。 これらの強調表示された領域は、2017 年のグラウンド トゥルース データ (右上) では以前は非農作地としてマークされていましたが、XNUMX 年に変更され、Planetscope シーン (左上と左下) を通じて明らかに農耕地として表示されました。 これらはまた、分類子 (右下) によって主に農地として分類されました。

繰り返しますが、KNN 分類器はグラウンド トゥルース クラスよりも詳細な結果を提示し、農地で起こっている変化もうまく捕捉していることがわかります。 この例は、毎日更新される衛星データの価値についても語っています。なぜなら、世界は年次報告書よりもはるかに速く変化することが多く、このように ML と組み合わせた方法は、変化が起こったときにそれを把握するのに役立ちます。 特に進化する農業分野において、衛星データを介してそのような変化を監視および発見できることは、農家が作業を最適化するための有益な洞察を提供し、バリューチェーン内の農業関係者が季節のより良い脈動を把握するために役立つ洞察を提供します。
モデル評価
予測されたクラスの画像とグランド トゥルース クラスの視覚的な比較は主観的なものになる可能性があり、分類結果の精度を評価するために一般化することはできません。 定量的評価を取得するには、scikit-learn のツールを使用して分類メトリックを取得します。 classification_report 関数:
ピクセル分類はトリミング領域のセグメンテーション マスクを作成するために使用され、精度と再現率の両方が重要な指標となり、F1 スコアは精度を予測するための優れた全体的な尺度になります。 この結果から、トレーニング データセットとテスト データセット内の作物領域と非作物領域の両方のメトリクスが得られます。 ただし、話を簡単にするために、テスト データセットのトリミング領域のコンテキストでこれらのメトリクスを詳しく見てみましょう。
精度は、モデルの肯定的な予測がどの程度正確であるかを示す尺度です。 この場合、作物領域の精度 0.94 は、モデルが実際に作物領域であるエリアを正しく識別することに非常に成功しており、偽陽性 (作物領域として誤って識別される実際の非作物領域) が最小限に抑えられていることを示しています。 一方、再現率は肯定的な予測の完全性を測定します。 言い換えれば、リコールは正しく識別された実際の陽性者の割合を測定します。 この場合、クロップ領域のリコール値 0.73 は、すべての真のクロップ領域ピクセルの 73% が正しく識別され、偽陰性の数が最小限に抑えられることを意味します。
理想的には、精度と再現率の両方が高い値が好ましいですが、これはケーススタディの用途に大きく依存します。 たとえば、農業用作物地域を特定しようとしている農家向けにこれらの結果を検討する場合、偽陰性 (非作物地域として特定された地域) の数を最小限に抑えるために、精度よりも高い再現率を優先したいと思うでしょう。土地を最大限に活用するために。 F1 スコアは、適合率と再現率の両方を組み合わせた全体的な精度の指標として機能し、1 つの指標間のバランスを測定します。 作物地域の F0.82 スコア (1) など、高い F1 スコアは、精度と再現率の両方のバランスが取れており、全体的な分類精度が高いことを示しています。 F0.77 スコアはトレーニング データセットとテスト データセットの間で低下しますが、分類器がトレーニング データセットでトレーニングされているため、これは予想どおりです。 全体の加重平均 FXNUMX スコア XNUMX は有望であり、機密データに対してセグメンテーション スキームを試すには十分です。
分類子からセグメンテーション マスクを作成する
テスト データセット上の KNN 分類器からの予測を使用してセグメンテーション マスクを作成するには、画像ノイズによって引き起こされる小さなセグメントを回避するために予測出力をクリーンアップすることが含まれます。 スペックル ノイズを除去するには、OpenCV を使用します。 メディアンぼかしフィルター。 このフィルターは、形態学的オープン操作よりも作物間の道路の輪郭をよりよく保存します。

ノイズ除去された出力にバイナリ セグメンテーションを適用するには、まず OpenCV を使用して、分類されたラスター データをベクター フィーチャに変換する必要があります。 輪郭を見つける 機能。

最後に、実際のセグメント化されたトリミング領域は、セグメント化されたトリミングの輪郭を使用して計算できます。

KNN 分類器から生成されたセグメント化された作物領域により、テスト データセット内の作物領域を正確に識別できます。 これらのセグメント化された領域は、圃場境界の識別、作物の監視、収量の推定、資源の割り当てなど、さまざまな目的に使用できます。 達成された 1 という F0.77 スコアは良好であり、KNN 分類器がリモート センシング画像における作物のセグメンテーションに効果的なツールであるという証拠を提供します。 これらの結果は、作物セグメンテーション技術をさらに改善および改良するために使用でき、作物分析の精度と効率の向上につながる可能性があります。
まとめ
この投稿では、次の組み合わせを使用する方法を説明しました。 プラネットの 高頻度、高解像度の衛星画像と SageMaker の地理空間機能 作物のセグメンテーション分析を実行し、農業の効率、環境の持続可能性、食料安全保障を改善できる貴重な洞察を導き出します。 作物地域を正確に特定することで、作物の成長と生産性に関するさらなる分析、土地利用の変化の監視、潜在的な食料安全保障リスクの検出が可能になります。
さらに、Planet データと SageMaker を組み合わせることで、作物のセグメンテーションを超えた幅広いユースケースが提供されます。 この洞察により、農業だけでも作物管理、資源配分、政策計画についてデータに基づいた意思決定が可能になります。 さまざまなデータと ML モデルを使用すると、組み合わせたサービスは他の業界や、デジタル変革、持続可能性変革、セキュリティに向けたユースケースにも拡張できる可能性があります。
SageMaker 地理空間機能の使用を開始するには、以下を参照してください。 Amazon SageMaker 地理空間機能を使ってみる.
Planet の画像仕様と開発者参考資料の詳細については、次のサイトをご覧ください。 プラネット デベロッパー センター。 Planet の Python SDK に関するドキュメントについては、次を参照してください。 Python 用の Planet SDK。 既存のデータ製品や今後の製品リリースなど、Planet の詳細については、次の Web サイトをご覧ください。 https://www.planet.com/.
Planet Labs PBC の将来予想に関する記述
ここに含まれる過去の情報を除き、このブログ投稿に記載されている事項は、Planet Labs を含む (ただしこれに限定されない) 1995 年の私募証券訴訟改革法の「セーフハーバー」規定の意味における将来の見通しに関する記述です。市場機会を捉え、現在または将来の製品強化、新製品、または戦略的パートナーシップや顧客協力から潜在的な利益を実現する PBC の能力。 将来の見通しに関する記述は、Planet Labs PBC の経営陣の信念、経営陣が行った仮定、および現在入手可能な情報に基づいています。 このような記述は将来の出来事や結果に関する予想に基づいており、事実の記述ではないため、実際の結果は予測と大きく異なる場合があります。 実際の結果が現在の予想と大きく異なる可能性がある要因には、Planet Labs PBC の定期報告書、委任勧誘状、および当時提出されたその他の開示資料に含まれる、Planet Labs PBC およびその事業に関するリスク要因およびその他の開示が含まれますが、これらに限定されません。証券取引委員会 (SEC) に合わせてオンラインで入手できます。 www.sec.gov、Planet Labs PBC の Web サイト www.planet.com でご覧いただけます。 すべての将来予想に関する記述は、そのような記述が行われた日の時点でのみ、Planet Labs PBC の信念と仮定を反映しています。 Planet Labs PBC は、将来の出来事や状況を反映するために将来の見通しに関する記述を更新する義務を負いません。
著者について
 リディア・リフイ・チャン Planet Labs PBC のビジネス開発スペシャリストであり、さまざまなセクターと無数のユースケースにわたって、地球の改善のために宇宙を結び付けることに貢献しています。 以前は、農業に焦点を当てたソリューションを提供する McKinsey ACRE でデータ サイエンティストを務めていました。 彼女は MIT 技術政策プログラムで宇宙政策に焦点を当て、理学修士号を取得しています。 地理空間データと、それがビジネスと持続可能性に与える広範な影響は、彼女のキャリアの焦点です。
リディア・リフイ・チャン Planet Labs PBC のビジネス開発スペシャリストであり、さまざまなセクターと無数のユースケースにわたって、地球の改善のために宇宙を結び付けることに貢献しています。 以前は、農業に焦点を当てたソリューションを提供する McKinsey ACRE でデータ サイエンティストを務めていました。 彼女は MIT 技術政策プログラムで宇宙政策に焦点を当て、理学修士号を取得しています。 地理空間データと、それがビジネスと持続可能性に与える広範な影響は、彼女のキャリアの焦点です。
 マンシ・シャー ソフトウェア エンジニア、データ サイエンティスト、ミュージシャンであり、芸術的な厳密さと技術的な好奇心が衝突する空間を探求する仕事をしています。 彼女はデータ (芸術と同様!) が生命を模倣していると信じており、数字やメモの背後にある奥深い人間の物語に興味を持っています。
マンシ・シャー ソフトウェア エンジニア、データ サイエンティスト、ミュージシャンであり、芸術的な厳密さと技術的な好奇心が衝突する空間を探求する仕事をしています。 彼女はデータ (芸術と同様!) が生命を模倣していると信じており、数字やメモの背後にある奥深い人間の物語に興味を持っています。
 周雄 AWS の上級応用科学者です。 彼は、Amazon SageMaker 地理空間機能の科学チームを率いています。 彼の現在の研究分野には、コンピュータ ビジョンと効率的なモデル トレーニングが含まれます。 余暇には、ランニング、バスケットボールをしたり、家族と時間を過ごしたりすることを楽しんでいます。
周雄 AWS の上級応用科学者です。 彼は、Amazon SageMaker 地理空間機能の科学チームを率いています。 彼の現在の研究分野には、コンピュータ ビジョンと効率的なモデル トレーニングが含まれます。 余暇には、ランニング、バスケットボールをしたり、家族と時間を過ごしたりすることを楽しんでいます。
 ヤノシュ・ヴォシッツ AWS のシニア ソリューション アーキテクトであり、地理空間 AI/ML を専門としています。 15 年以上の経験を持つ彼は、地理空間データを活用した革新的なソリューションのために AI と ML を活用する世界中の顧客をサポートしています。 彼の専門知識は機械学習、データ エンジニアリング、スケーラブルな分散システムに及び、ソフトウェア エンジニアリングの強力な背景と自動運転などの複雑な領域における業界の専門知識によって強化されています。
ヤノシュ・ヴォシッツ AWS のシニア ソリューション アーキテクトであり、地理空間 AI/ML を専門としています。 15 年以上の経験を持つ彼は、地理空間データを活用した革新的なソリューションのために AI と ML を活用する世界中の顧客をサポートしています。 彼の専門知識は機械学習、データ エンジニアリング、スケーラブルな分散システムに及び、ソフトウェア エンジニアリングの強力な背景と自動運転などの複雑な領域における業界の専門知識によって強化されています。
 シタル・ダカール は、サンフランシスコ ベイエリアに拠点を置く SageMaker 地理空間 ML チームのシニア プログラム マネージャーです。 彼はリモート センシングと地理情報システム (GIS) の経験があります。 彼は、顧客の問題点を理解し、それらを解決するための地理空間製品を構築することに情熱を注いでいます。 余暇には、ハイキング、旅行、テニスを楽しんでいます。
シタル・ダカール は、サンフランシスコ ベイエリアに拠点を置く SageMaker 地理空間 ML チームのシニア プログラム マネージャーです。 彼はリモート センシングと地理情報システム (GIS) の経験があります。 彼は、顧客の問題点を理解し、それらを解決するための地理空間製品を構築することに情熱を注いでいます。 余暇には、ハイキング、旅行、テニスを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/build-a-crop-segmentation-machine-learning-model-with-planet-data-and-amazon-sagemaker-geospatial-capabilities/

