Amazon SageMakerスタジオ は、データ サイエンティストが機械学習 (ML) モデルを対話的に構築、トレーニング、デプロイできるフルマネージド ソリューションを提供します。 ML タスクに取り組む過程で、データ サイエンティストは通常、関連するデータ ソースを見つけて接続することからワークフローを開始します。次に、SQL を使用して、さまざまなソースからのデータを探索、分析、視覚化、統合してから、ML トレーニングと推論で使用します。以前は、データ サイエンティストは、ワークフローで SQL をサポートするために複数のツールをやりくりすることが多く、それが生産性の妨げになっていました。
SageMaker Studio の JupyterLab ノートブックに SQL のサポートが組み込まれたことを発表できることを嬉しく思います。データ サイエンティストは次のことができるようになりました。
- 以下のような一般的なデータ サービスに接続します。 アマゾンアテナ, Amazonレッドシフト, アマゾンデータゾーン、ノートブック内で直接 Snowflake
- データベース、スキーマ、テーブル、ビューを参照および検索し、ノートブック インターフェイス内でデータをプレビューします。
- SQL と Python コードを同じノートブックに混在させて、ML プロジェクトで使用するデータの効率的な探索と変換を実現します。
- SQL コマンド補完、コードの書式設定支援、構文の強調表示などの開発者の生産性機能を使用して、コード開発を加速し、全体的な開発者の生産性を向上させます。
さらに、管理者はこれらのデータ サービスへの接続を安全に管理できるため、データ サイエンティストは資格情報を手動で管理することなく、承認されたデータにアクセスできます。
この投稿では、SageMaker Studio でこの機能をセットアップする手順を説明し、この機能のさまざまな機能について説明します。次に、高度なラージ言語モデル (LLM) によって提供される Text-to-SQL 機能を使用してノートブック内の SQL エクスペリエンスを強化し、自然言語テキストを入力として使用して複雑な SQL クエリを作成する方法を示します。最後に、より多くのユーザーがノートブックの自然言語入力から SQL クエリを生成できるようにするために、これらの Text-to-SQL モデルを次を使用して展開する方法を示します。 アマゾンセージメーカー エンドポイント
ソリューションの概要
SageMaker Studio JupyterLab ノートブックの SQL 統合により、Snowflake、Athena、Amazon Redshift、Amazon DataZone などの一般的なデータ ソースに接続できるようになりました。この新機能により、さまざまな機能を実行できるようになります。
たとえば、データベース、テーブル、スキーマなどのデータ ソースを JupyterLab エコシステムから直接視覚的に探索できます。ノートブック環境が SageMaker Distribution 1.6 以降で実行されている場合は、JupyterLab インターフェイスの左側で新しいウィジェットを探してください。この追加により、開発環境内のデータへのアクセスと管理が強化されます。
現在、推奨される SageMaker ディストリビューション (1.5 以下) を使用していない場合、またはカスタム環境を使用していない場合、詳細については付録を参照してください。
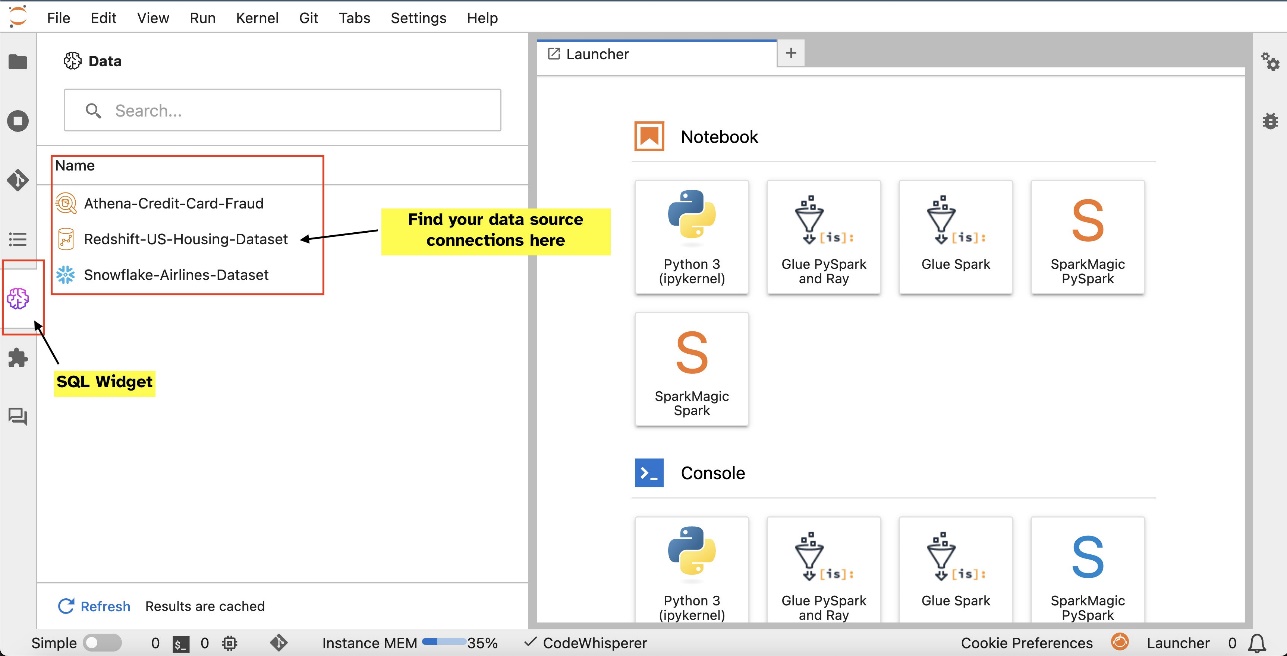
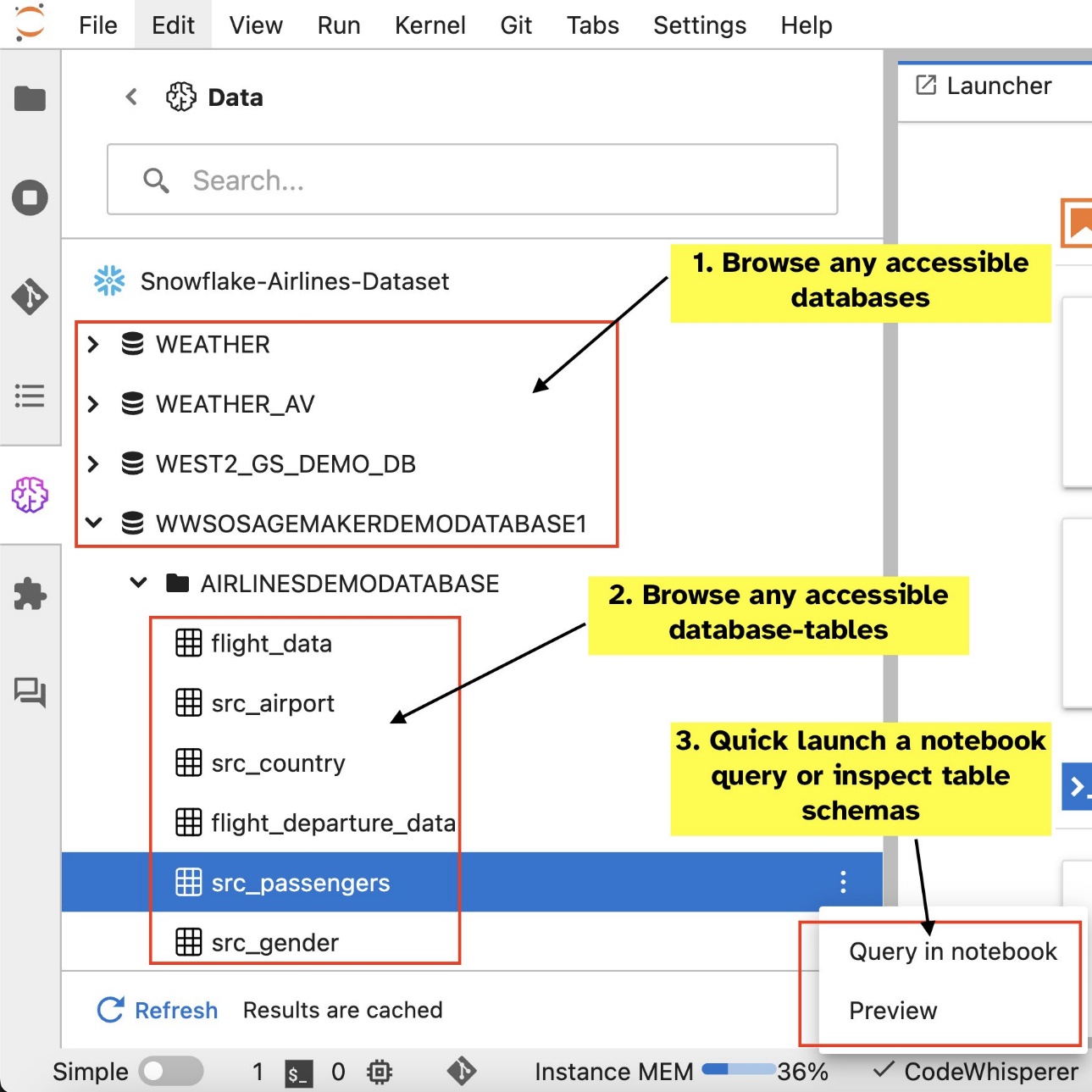
接続を設定した後 (次のセクションで説明します)、データ接続の一覧表示、データベースとテーブルの参照、スキーマの検査を行うことができます。
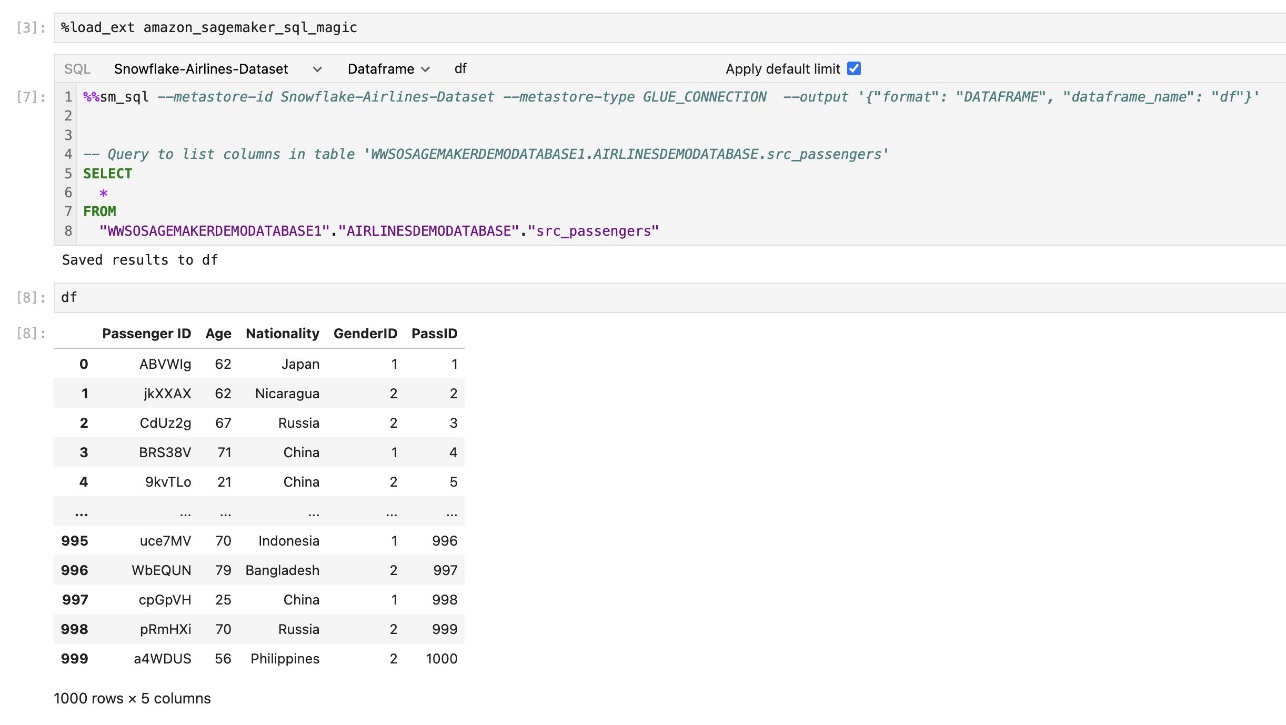
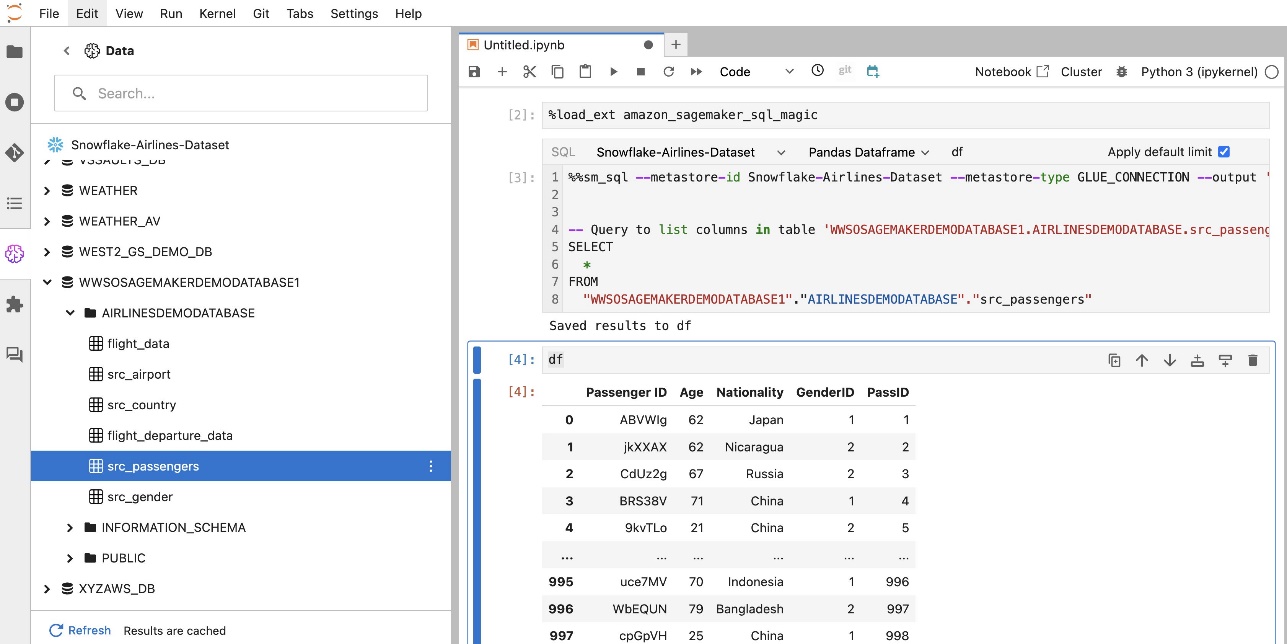
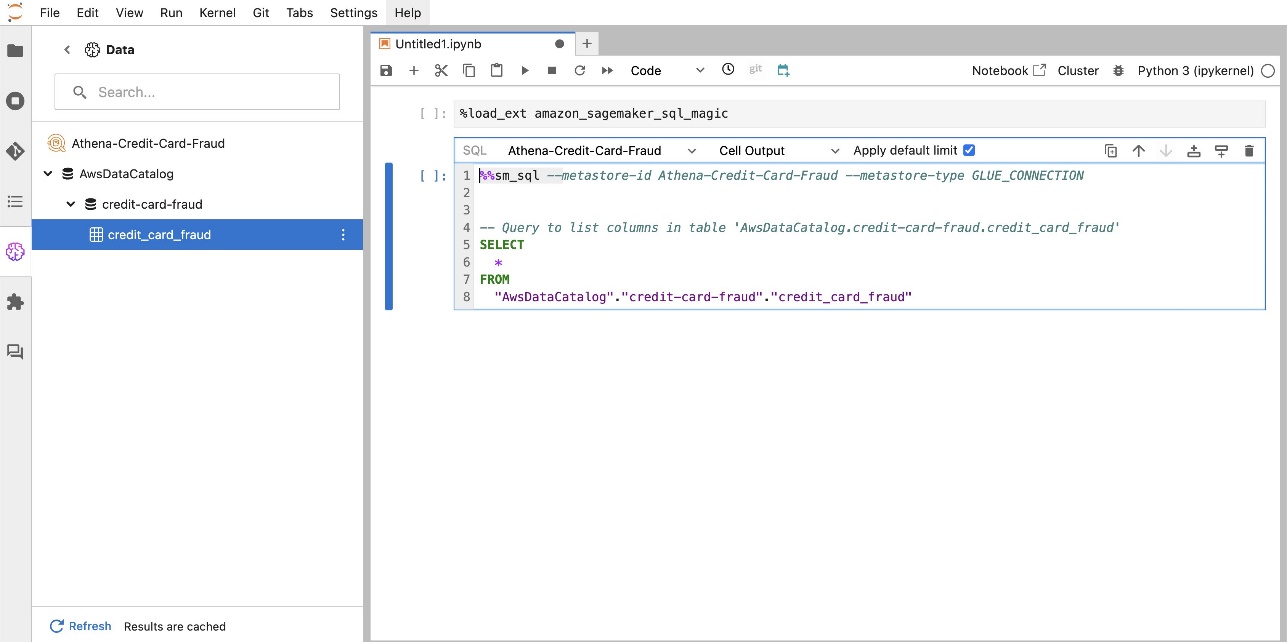
SageMaker Studio JupyterLab 組み込み SQL 拡張機能を使用すると、ノートブックから SQL クエリを直接実行することもできます。 Jupyter ノートブックは、 %%sm_sql マジック コマンド。SQL コードを含むセルの先頭に配置する必要があります。このコマンドは、次の命令が Python コードではなく SQL コマンドであることを JupyterLab に通知します。クエリの出力はノートブック内に直接表示できるため、データ分析における SQL と Python のワークフローのシームレスな統合が容易になります。
次のスクリーンショットに示すように、クエリの出力は HTML テーブルとして視覚的に表示できます。

に書き込むこともできます。 パンダのデータフレーム.
前提条件
SageMaker Studio ノートブック SQL エクスペリエンスを使用するには、次の前提条件を満たしていることを確認してください。
- SageMaker スタジオ V2 – 最新バージョンを実行していることを確認してください。 SageMaker Studio のドメインとユーザー プロファイル。現在 SageMaker Studio Classic を使用している場合は、以下を参照してください。 Amazon SageMaker Studio Classic からの移行.
- IAMの役割 – SageMaker には AWS IDおよびアクセス管理 権限を効率的に管理するために、SageMaker Studio ドメインまたはユーザー プロファイルに割り当てられる (IAM) ロール。データ参照および SQL 実行機能を導入するには、実行ロールの更新が必要になる場合があります。次のポリシー例では、ユーザーが付与、リスト、および実行できるようにします。 AWSグルー、アテナ、 Amazon シンプル ストレージ サービス (Amazon S3)、 AWSシークレットマネージャー、および Amazon Redshift リソース:
- ジュピターラボ スペース – 更新された SageMaker Studio と JupyterLab Space にアクセスする必要があります。 SageMaker ディストリビューション v1.6 以降のイメージ バージョン。 JupyterLab Spaces または SageMaker Distribution の古いバージョン (v1.5 以下) のカスタム イメージを使用している場合は、環境でこの機能を有効にするために必要なパッケージとモジュールをインストールする手順について付録を参照してください。 SageMaker Studio JupyterLab Spaces の詳細については、以下を参照してください。 Amazon SageMaker Studio での生産性の向上: JupyterLab Spaces と生成 AI ツールの紹介.
- データソースのアクセス認証情報 – この SageMaker Studio ノートブック機能では、Snowflake や Amazon Redshift などのデータ ソースにユーザー名とパスワードでアクセスする必要があります。これらのデータ ソースへのユーザー名とパスワード ベースのアクセス権をまだ持っていない場合は、作成します。 Snowflake への OAuth ベースのアクセスは、この記事の執筆時点ではサポートされている機能ではありません。
- SQL マジックをロードする – Jupyter Notebook セルから SQL クエリを実行する前に、SQL マジック拡張機能をロードすることが重要です。コマンドを使用する
%load_ext amazon_sagemaker_sql_magicこの機能を有効にするには、さらに、%sm_sql?コマンドを使用して、SQL セルからのクエリでサポートされているオプションの包括的なリストを表示します。これらのオプションには、デフォルトのクエリ制限の 1,000 の設定、完全な抽出の実行、クエリ パラメータの挿入などが含まれます。この設定により、ノートブック環境内で直接、柔軟かつ効率的な SQL データ操作が可能になります。
データベース接続の作成
SageMaker Studio の組み込み SQL 参照および実行機能は、AWS Glue 接続によって強化されます。 AWS Glue 接続は、ログイン認証情報、URI 文字列、特定のデータ ストアの Virtual Private Cloud (VPC) 情報などの重要なデータを保存する AWS Glue データ カタログ オブジェクトです。これらの接続は、AWS Glue クローラー、ジョブ、開発エンドポイントによってさまざまなタイプのデータストアにアクセスするために使用されます。これらの接続をソース データとターゲット データの両方に使用でき、複数のクローラや抽出、変換、ロード (ETL) ジョブ間で同じ接続を再利用することもできます。
SageMaker Studio の左側のペインで SQL データソースを探索するには、まず AWS Glue 接続オブジェクトを作成する必要があります。これらの接続により、さまざまなデータ ソースへのアクセスが容易になり、そのスケマティック データ要素を探索できるようになります。
次のセクションでは、SQL 固有の AWS Glue コネクタを作成するプロセスについて説明します。これにより、さまざまなデータ ストアにわたるデータセットにアクセス、表示、探索できるようになります。 AWS Glue 接続の詳細については、以下を参照してください。 データへの接続.
AWS Glue 接続を作成する
データソースを SageMaker Studio に取り込む唯一の方法は、AWS Glue 接続を使用することです。特定の接続タイプを使用して AWS Glue 接続を作成する必要があります。この記事の執筆時点では、これらの接続を作成するためにサポートされている唯一のメカニズムは、 AWSコマンドラインインターフェイス (AWS CLI)。
接続定義JSONファイル
AWS Glue でさまざまなデータソースに接続する場合は、まず接続プロパティを定義する JSON ファイルを作成する必要があります。 接続定義ファイル。このファイルは AWS Glue 接続を確立するために重要であり、データ ソースにアクセスするために必要なすべての設定を詳細に記述します。セキュリティのベスト プラクティスとして、Secrets Manager を使用してパスワードなどの機密情報を安全に保存することをお勧めします。一方、他の接続プロパティは、AWS Glue 接続を通じて直接管理できます。このアプローチにより、接続構成にアクセスして管理できるようにしながら、機密の資格情報が確実に保護されます。
以下は接続定義 JSON の例です。
データソースに AWS Glue 接続を設定する場合、機能とセキュリティの両方を提供するために従うべき重要なガイドラインがいくつかあります。
- プロパティの文字列化 - 以内
PythonPropertiesキー、すべてのプロパティが次のとおりであることを確認してください 文字列化されたキーと値のペア。必要に応じてバックスラッシュ () 文字を使用して二重引用符を適切にエスケープすることが重要です。これは、正しい形式を維持し、JSON 内の構文エラーを回避するのに役立ちます。 - 機密情報の取り扱い – すべての接続プロパティを含めることは可能ですが、
PythonProperties、パスワードなどの機密情報をこれらのプロパティに直接含めないことをお勧めします。代わりに、機密情報の処理には Secrets Manager を使用してください。このアプローチでは、主要な構成ファイルから離れた、管理され暗号化された環境に機密データを保存することで、機密データを保護します。
AWS CLI を使用して AWS Glue 接続を作成する
接続定義 JSON ファイルに必要なフィールドをすべて含めると、AWS CLI と次のコマンドを使用してデータ ソースの AWS Glue 接続を確立できるようになります。
このコマンドは、JSON ファイルに詳細に記載されている仕様に基づいて、新しい AWS Glue 接続を開始します。コマンド コンポーネントの簡単な内訳は次のとおりです。
- -地域 – これは、AWS Glue 接続が作成される AWS リージョンを指定します。遅延を最小限に抑え、データ常駐要件に準拠するには、データ ソースおよびその他のサービスが配置されているリージョンを選択することが重要です。
- –cli-input-json file:///path/to/file/connection/定義/file.json – このパラメータは、JSON 形式の接続定義が含まれるローカル ファイルから入力設定を読み取るように AWS CLI に指示します。
Studio JupyterLab ターミナルから前述の AWS CLI コマンドを使用して AWS Glue 接続を作成できるはずです。で File メニュー、選択 新作 & ターミナル.

Status create-connection コマンドが正常に実行されると、SQL ブラウザー ペインにデータ ソースがリストされるはずです。データ ソースがリストに表示されない場合は、 Refresh キャッシュを更新します。

Snowflake 接続を作成する
このセクションでは、Snowflake データ ソースと SageMaker Studio の統合に焦点を当てます。 Snowflake アカウント、データベース、ウェアハウスの作成は、この投稿の範囲外です。 Snowflake を使い始めるには、以下を参照してください。 スノーフレーク ユーザーガイド。この投稿では、Snowflake 定義 JSON ファイルの作成と、AWS Glue を使用した Snowflake データ ソース接続の確立に重点を置きます。
Secrets Manager シークレットを作成する
Snowflake アカウントに接続するには、ユーザー ID とパスワード、または秘密キーを使用します。ユーザー ID とパスワードを使用して接続するには、資格情報を Secrets Manager に安全に保存する必要があります。前述したように、この情報を PythonProperties に埋め込むことは可能ですが、機密情報をプレーン テキスト形式で保存することはお勧めできません。潜在的なセキュリティ リスクを回避するために、機密データは常に安全に扱われるようにしてください。
Secrets Manager に情報を保存するには、次の手順を実行します。
- Secrets Managerコンソールで、 新しい秘密を保存する.
- シークレットタイプ、選択する 他のタイプの秘密.
- キーと値のペアとして、 平文 次のように入力します。
- シークレットの名前を入力します。
sm-sql-snowflake-secret. - 他の設定はデフォルトのままにするか、必要に応じてカスタマイズします。
- シークレットを作成します。
Snowflake の AWS Glue 接続を作成する
前に説明したように、AWS Glue 接続は、SageMaker Studio から接続にアクセスするために不可欠です。のリストを見つけることができます Snowflake でサポートされているすべての接続プロパティ。以下は、Snowflake の接続定義 JSON のサンプルです。ディスクに保存する前に、プレースホルダーの値を適切な値に置き換えます。
Snowflake データ ソースの AWS Glue 接続オブジェクトを作成するには、次のコマンドを使用します。
このコマンドは、SQL ブラウザー ペインに参照可能な新しい Snowflake データ ソース接続を作成し、JupyterLab ノートブック セルからそれに対して SQL クエリを実行できます。
AmazonRedshift接続を作成します
Amazon Redshift は、標準 SQL を使用してすべてのデータを分析するコストを簡素化し、コストを削減する、フルマネージドのペタバイト規模のデータ ウェアハウス サービスです。 Amazon Redshift 接続を作成する手順は、Snowflake 接続の手順とほぼ同じです。
Secrets Manager シークレットを作成する
Snowflake のセットアップと同様に、ユーザー ID とパスワードを使用して Amazon Redshift に接続するには、シークレット情報を Secrets Manager に安全に保存する必要があります。次の手順を実行します。
- Secrets Managerコンソールで、 新しい秘密を保存する.
- シークレットタイプ、選択する Amazon Redshift クラスターの認証情報.
- データソースとして Amazon Redshift にアクセスするためのログインに使用する認証情報を入力します。
- シークレットに関連付けられた Redshift クラスターを選択します。
- シークレットの名前を入力します。
sm-sql-redshift-secret. - 他の設定はデフォルトのままにするか、必要に応じてカスタマイズします。
- シークレットを作成します。
これらの手順に従うことで、AWS の堅牢なセキュリティ機能を使用して機密データを効果的に管理し、接続認証情報が安全に処理されるようになります。
Amazon Redshift 用の AWS Glue 接続を作成する
JSON 定義を使用して Amazon Redshift との接続を設定するには、必要なフィールドに入力し、次の JSON 設定をディスクに保存します。
Redshift データソースの AWS Glue 接続オブジェクトを作成するには、次の AWS CLI コマンドを使用します。
このコマンドは、Redshift データソースにリンクされた AWS Glue に接続を作成します。コマンドが正常に実行されると、SageMaker Studio JupyterLab ノートブック内で Redshift データ ソースが表示され、SQL クエリを実行してデータ分析を実行できるようになります。

Athena 接続を作成する
Athena は、AWS のフルマネージド SQL クエリ サービスで、標準 SQL を使用して Amazon S3 に保存されたデータの分析を可能にします。 JupyterLab ノートブックの SQL ブラウザーで Athena 接続をデータ ソースとして設定するには、Athena サンプル接続定義 JSON を作成する必要があります。次の JSON 構造は、データ カタログ、S3 ステージング ディレクトリ、およびリージョンを指定して、Athena に接続するために必要な詳細を構成します。
Athena データソースの AWS Glue 接続オブジェクトを作成するには、次の AWS CLI コマンドを使用します。
コマンドが成功すると、SageMaker Studio JupyterLab ノートブック内の SQL ブラウザから Athena データ カタログとテーブルに直接アクセスできるようになります。
複数のソースからデータをクエリする
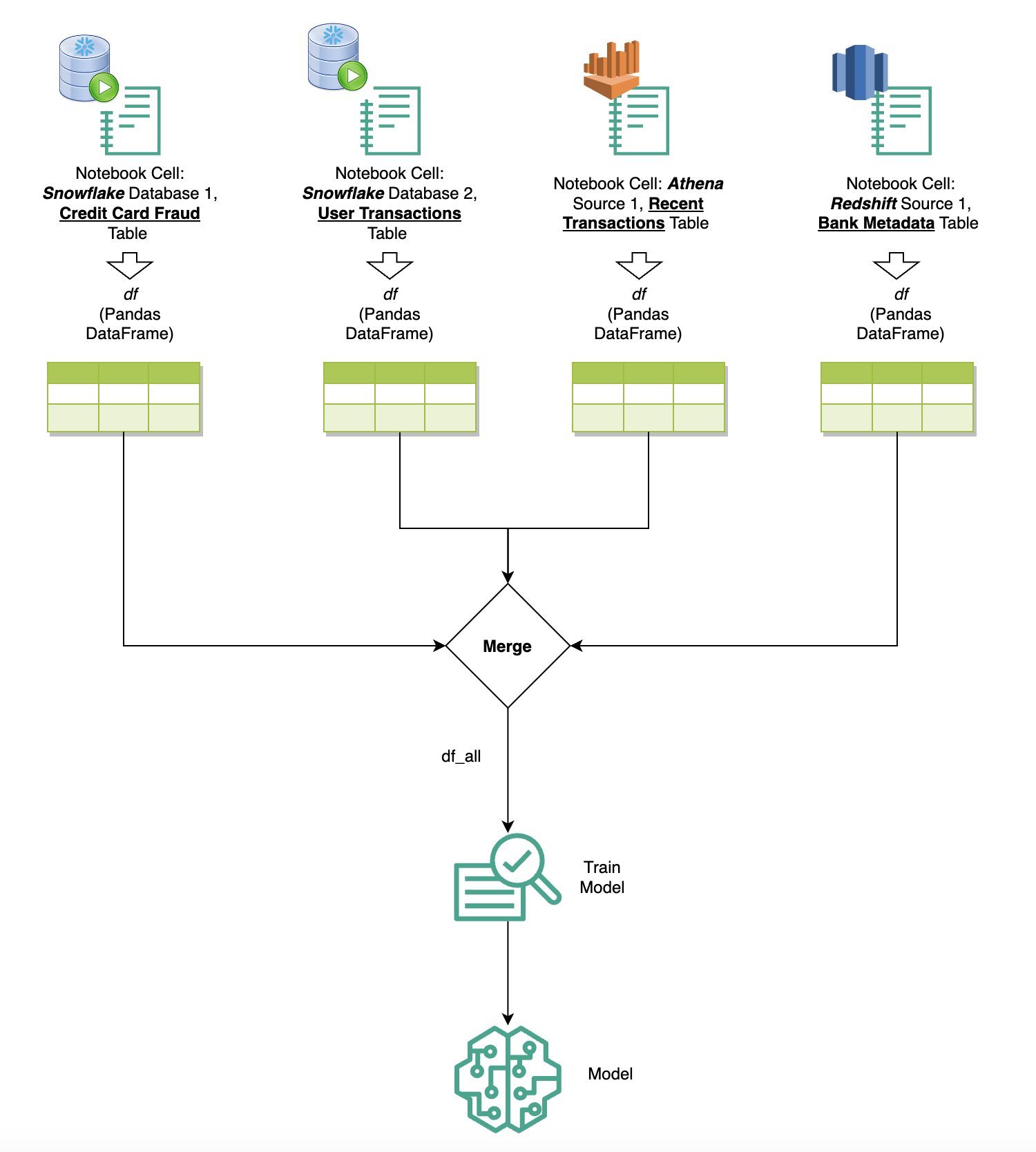
組み込みの SQL ブラウザとノートブック SQL 機能を通じて複数のデータ ソースを SageMaker Studio に統合している場合、クエリをすばやく実行し、ノートブック内の後続のセルでデータ ソース バックエンドを簡単に切り替えることができます。この機能により、分析ワークフロー中に異なるデータベースまたはデータ ソース間をシームレスに移行できます。
データ ソース バックエンドの多様なコレクションに対してクエリを実行し、その結果を Python スペースに直接取り込んで、さらに分析や視覚化を行うことができます。これを促進するのは、 %%sm_sql SageMaker Studio ノートブックで使用できるマジック コマンド。 SQL クエリの結果を pandas DataFrame に出力するには、次の 2 つのオプションがあります。
- ノートブックのセルのツールバーから、出力タイプを選択します データフレーム DataFrame 変数に名前を付けます
- 次のパラメータを
%%sm_sqlコマンド:
次の図は、このワークフローを示しており、後続のノートブック セル内のさまざまなソースに対してクエリを簡単に実行する方法と、トレーニング ジョブを使用して SageMaker モデルをトレーニングする方法、またはローカル コンピューティングを使用してノートブック内で直接 SageMaker モデルをトレーニングする方法を示しています。さらに、この図は、SageMaker Studio の組み込み SQL 統合により、JupyterLab ノートブック セルの使い慣れた環境内で直接、抽出および構築のプロセスがどのように簡素化されるかを示しています。
Text to SQL: 自然言語を使用してクエリ作成を強化する
SQL は、データベース、テーブル、構文、メタデータの理解が必要な複雑な言語です。現在、生成人工知能 (AI) により、SQL の深い経験を必要とせずに複雑な SQL クエリを作成できるようになりました。 LLM の進歩は、自然言語処理 (NLP) ベースの SQL 生成に大きな影響を与え、自然言語記述から正確な SQL クエリを作成できるようになりました。これは Text-to-SQL と呼ばれる技術です。ただし、人間の言語と SQL の間には本質的な違いがあることを認識することが重要です。人間の言語は時々曖昧または不正確になることがありますが、SQL は構造化されており、明示的であり、明確です。このギャップを埋めて自然言語を SQL クエリに正確に変換することは、大きな課題となる可能性があります。適切なプロンプトが提供されると、LLM は人間の言語の背後にある意図を理解し、それに応じて正確な SQL クエリを生成することで、このギャップを埋めるのに役立ちます。
SageMaker Studio のノートブック内 SQL クエリ機能のリリースにより、SageMaker Studio では、Jupyter ノートブック IDE を離れることなく、データベースとスキーマを検査し、SQL クエリを作成、実行、デバッグすることが簡単になりました。このセクションでは、高度な LLM の Text-to-SQL 機能により、Jupyter ノートブック内で自然言語を使用した SQL クエリの生成がどのように容易になるかについて説明します。最先端の Text-to-SQL モデルを採用しています defog/sqlcoder-7b-2 Jupyter Notebook 用に特別に設計された生成 AI アシスタントである Jupyter AI と連携して、自然言語から複雑な SQL クエリを作成します。この高度なモデルを使用すると、自然言語を使用して複雑な SQL クエリを簡単かつ効率的に作成できるため、ノートブック内での SQL エクスペリエンスが向上します。
Hugging Face Hub を使用したノートブックのプロトタイピング
プロトタイピングを開始するには、次のものが必要です。
- GitHubコード – このセクションで示されているコードは、次の場所から入手できます。 GitHubレポ そして、を参照することにより、 サンプルノート.
- ジュピターラボ スペース – GPU ベースのインスタンスによってサポートされる SageMaker Studio JupyterLab Space へのアクセスが不可欠です。のために
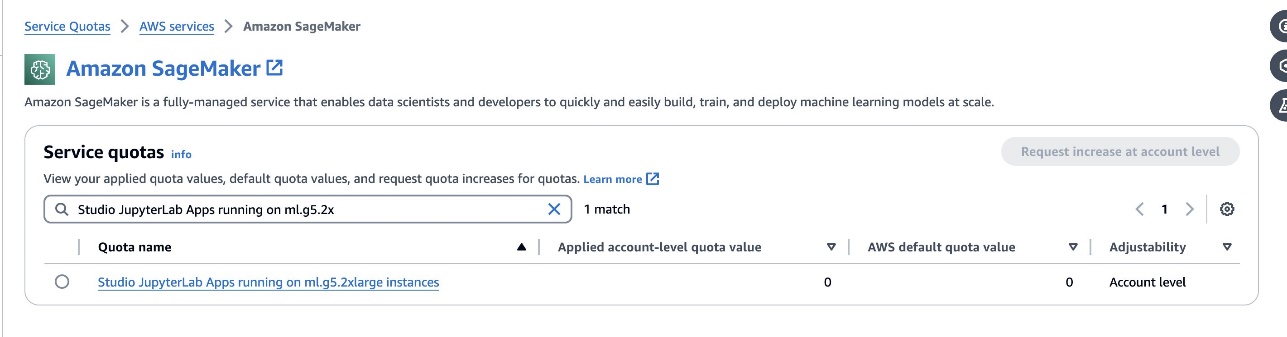
defog/sqlcoder-7b-2モデル (7B パラメーター モデル) では、ml.g5.2xlarge インスタンスを使用することをお勧めします。次のような代替案defog/sqlcoder-70b-alphまたはdefog/sqlcoder-34b-alpha自然言語から SQL への変換にも実行可能ですが、プロトタイピングにはより大きなインスタンス タイプが必要になる場合があります。 Service Quotas コンソールに移動し、SageMaker を検索して、GPU ベースのインスタンスを起動するためのクォータがあることを確認します。Studio JupyterLab Apps running on <instance type>.
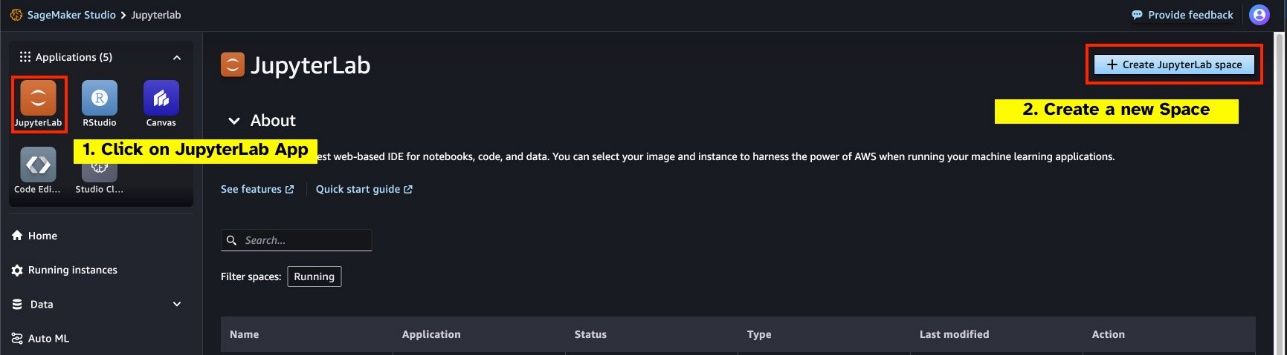
SageMaker Studio から新しい GPU 支援の JupyterLab Space を起動します。少なくとも 75 GB の新しい JupyterLab スペースを作成することをお勧めします。 Amazon Elastic Blockストア (Amazon EBS) 7B パラメーター モデルのストレージ。

- フェイスハブを抱き締める – SageMaker Studio ドメインが、 フェイスハブを抱き締める、あなたは
AutoModelForCausalLMからのクラス ハグフェイス/トランスフォーマー モデルを自動的にダウンロードし、ローカル GPU に固定します。モデルの重みはローカル マシンのキャッシュに保存されます。次のコードを参照してください。
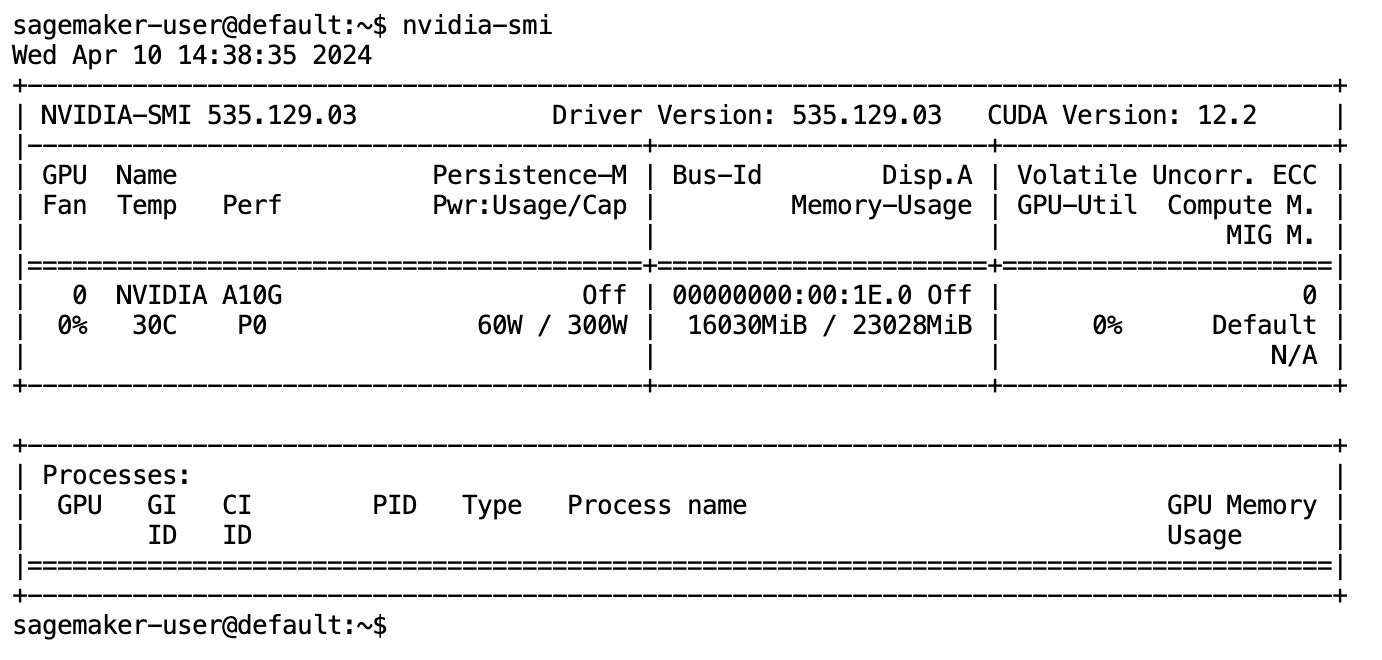
モデルが完全にダウンロードされてメモリに読み込まれた後、ローカル マシンの GPU 使用率の増加が観察されるはずです。これは、モデルが計算タスクに GPU リソースをアクティブに使用していることを示します。これを自分の JupyterLab スペースで実行して確認できます。 nvidia-smi (1 回限りの表示の場合) または nvidia-smi —loop=1 (毎秒繰り返す) JupyterLab ターミナルから。
Text-to-SQL モデルは、使用されている言語が会話的または曖昧な場合でも、ユーザーのリクエストの意図とコンテキストを理解するのに優れています。このプロセスには、自然言語入力をテーブル名、列名、条件などの正しいデータベース スキーマ要素に変換することが含まれます。ただし、既製の Text-to-SQL モデルは本質的にデータ ウェアハウスの構造や特定のデータベース スキーマを認識せず、列名のみに基づいてテーブルの内容を正確に解釈することもできません。これらのモデルを効果的に使用して、自然言語から実用的で効率的な SQL クエリを生成するには、SQL テキスト生成モデルを特定のウェアハウス データベース スキーマに適合させる必要があります。この適応は、次のものを使用することで促進されます。 LLM プロンプト。以下は、defog/sqlcoder-7b-2 Text-to-SQL モデルの推奨プロンプト テンプレートであり、XNUMX つの部分に分かれています。
- 仕事 – このセクションでは、モデルによって実行される高レベルのタスクを指定する必要があります。最終的な SQL クエリの生成に影響を与える可能性のある構文上の微妙な違いをモデルが認識できるように、データベース バックエンドの種類 (Amazon RDS、PostgreSQL、Amazon Redshift など) を含める必要があります。
- 説明書 – このセクションでは、モデルのタスク境界とドメイン認識を定義する必要があり、モデルが細かく調整された SQL クエリを生成するためのガイドとなるいくつかのショットの例が含まれる場合があります。
- データベーススキーマ – このセクションでは、モデルがデータベース構造を理解するのに役立つように、ウェアハウス データベース スキーマを詳しく説明し、テーブルと列の間の関係を概説します。
- 回答 – このセクションは、自然言語入力に対する SQL クエリ応答を出力するモデルのために予約されています。
このセクションで使用されるデータベース スキーマとプロンプトの例は、次の場所にあります。 GitHubリポジトリ.
プロンプトエンジニアリングとは、単に質問や発言を作成することだけではありません。これは微妙な芸術と科学であり、AI モデルとのインタラクションの品質に大きな影響を与えます。プロンプトの作成方法は、AI の応答の性質と有用性に大きく影響する可能性があります。このスキルは、特に専門的な理解と詳細な応答が必要な複雑なタスクにおいて、AI インタラクションの可能性を最大化する上で極めて重要です。
特定のプロンプトに対するモデルの応答を迅速に構築してテストし、応答に基づいてプロンプトを最適化するオプションがあることが重要です。 JupyterLab ノートブックは、ローカル コンピューティングで実行されているモデルから即座にモデル フィードバックを受け取り、プロンプトを最適化し、モデルの応答をさらに調整したり、モデルを完全に変更したりする機能を提供します。この投稿では、ml.g5.2xlarge の NVIDIA A10G 24 GB GPU を搭載した SageMaker Studio JupyterLab ノートブックを使用して、ノートブック上で Text-to-SQL モデル推論を実行し、モデルの応答が十分に調整されて提供されるまで対話的にモデル プロンプトを構築します。 JupyterLab の SQL セルで直接実行可能な応答。モデル推論を実行し、同時にモデル応答をストリーミングするには、次の組み合わせを使用します。 model.generate & TextIteratorStreamer 次のコードで定義されているように:
モデルの出力は SageMaker SQL マジックで装飾できます %%sm_sql ...これにより、JupyterLab ノートブックがセルを SQL セルとして識別できるようになります。
Text-to-SQL モデルを SageMaker エンドポイントとしてホストする
プロトタイピング段階の終わりに、推奨する Text-to-SQL LLM、効果的なプロンプト形式、およびモデルをホストするための適切なインスタンス タイプ (シングル GPU またはマルチ GPU) を選択しました。 SageMaker は、SageMaker エンドポイントの使用を通じてカスタム モデルのスケーラブルなホスティングを容易にします。これらのエンドポイントは特定の基準に従って定義でき、LLM をエンドポイントとして展開できます。この機能により、ソリューションをより幅広いユーザーに拡張できるようになり、ユーザーはカスタム ホスト型 LLM を使用して自然言語入力から SQL クエリを生成できるようになります。次の図は、このアーキテクチャを示しています。

LLM を SageMaker エンドポイントとしてホストするには、いくつかのアーティファクトを生成します。
最初の成果物はモデルの重みです。 SageMaker Deep Java Library (DJL) の提供 コンテナを使用すると、メタを通じて構成をセットアップできます。 サービング.プロパティ このファイルを使用すると、Hugging Face Hub から直接、または Amazon S3 からモデル アーティファクトをダウンロードすることによって、モデルを調達する方法を指定できます。指定する場合 model_id=defog/sqlcoder-7b-2, DJL Serving は、Hugging Face Hub からこのモデルを直接ダウンロードしようとします。ただし、エンドポイントが展開されたり、柔軟に拡張されたりするたびに、ネットワークのイングレス/エグレス料金が発生する可能性があります。これらの料金を回避し、モデル アーティファクトのダウンロードを潜在的に高速化するには、使用をスキップすることをお勧めします。 model_id in serving.properties モデルの重みを S3 アーティファクトとして保存し、それらを指定するだけです s3url=s3://path/to/model/bin.
モデル (トークナイザーを含む) をディスクに保存し、Amazon S3 にアップロードすることは、わずか数行のコードで実行できます。
データベース プロンプト ファイルも使用します。このセットアップでは、データベース プロンプトは次のもので構成されます。 Task, Instructions, Database Schema, Answer sections。現在のアーキテクチャでは、データベース スキーマごとに個別のプロンプト ファイルを割り当てます。ただし、このセットアップを拡張してプロンプト ファイルごとに複数のデータベースを含める柔軟性があり、モデルで同じサーバー上のデータベース間で複合結合を実行できるようになります。プロトタイピング段階では、データベース プロンプトを次の名前のテキスト ファイルとして保存します。 <Database-Glue-Connection-Name>.promptここで、 Database-Glue-Connection-Name は、JupyterLab 環境で表示される接続名に対応します。たとえば、この投稿では、という名前の Snowflake 接続について言及しています。 Airlines_Datasetしたがって、データベース プロンプト ファイルの名前は次のようになります。 Airlines_Dataset.prompt。このファイルは Amazon S3 に保存され、その後モデル提供ロジックによって読み取られてキャッシュされます。
さらに、このアーキテクチャにより、このエンドポイントの許可されたユーザーは、モデルを複数回再デプロイすることなく、SQL クエリに対する自然言語を定義、保存、生成することができます。私たちは以下を使用します データベースプロンプトの例 Text-to-SQL 機能をデモンストレーションします。
次に、カスタム モデル サービス ロジックを生成します。このセクションでは、という名前のカスタム推論ロジックの概要を説明します。 モデル.py。このスクリプトは、Text-to-SQL サービスのパフォーマンスと統合を最適化するように設計されています。
- データベース プロンプト ファイル キャッシュ ロジックを定義する – 遅延を最小限に抑えるために、データベース プロンプト ファイルをダウンロードしてキャッシュするためのカスタム ロジックを実装します。このメカニズムにより、プロンプトがすぐに利用できるようになり、頻繁なダウンロードに伴うオーバーヘッドが軽減されます。
- カスタムモデル推論ロジックを定義する – 推論速度を向上させるために、テキストから SQL へのモデルは float16 精度形式でロードされ、DeepSpeed モデルに変換されます。このステップにより、より効率的な計算が可能になります。さらに、このロジック内で、ユーザーが推論呼び出し中に調整して、ニーズに応じて機能を調整できるパラメーターを指定します。
- カスタム入出力ロジックを定義する – 明確でカスタマイズされた入出力形式を確立することは、下流のアプリケーションとスムーズに統合するために不可欠です。そのようなアプリケーションの 1 つが JupyterAI であり、これについては次のセクションで説明します。
さらに、 serving.properties ファイル。これは、DJL サービングを使用してホストされるモデルのグローバル構成ファイルとして機能します。詳細については、以下を参照してください。 構成と設定.
最後に、以下を含めることもできます。 requirements.txt ファイルを使用して推論に必要な追加モジュールを定義し、デプロイメント用にすべてを tarball にパッケージ化します。
次のコードを参照してください。
エンドポイントを SageMaker Studio Jupyter AI アシスタントと統合する
ジュピター AI は、生成 AI を Jupyter ノートブックに導入するオープンソース ツールで、生成 AI モデルを探索するための堅牢でユーザー フレンドリーなプラットフォームを提供します。ノートブック内に生成的な AI プレイグラウンドを作成するための %%ai マジック、会話アシスタントとして AI と対話するための JupyterLab のネイティブ チャット UI、およびさまざまな LLM のサポートなどの機能を提供することで、JupyterLab および Jupyter ノートブックの生産性が向上します。のようなプロバイダー アマゾンタイタン、AI21、Anthropic、Cohere、Hugging Face、または次のようなマネージド サービス アマゾンの岩盤 SageMaker エンドポイント。この投稿では、Jupyter AI のすぐに使える SageMaker エンドポイントとの統合を使用して、Text-to-SQL 機能を JupyterLab ノートブックに導入します。 Jupyter AI ツールは、すべての SageMaker Studio JupyterLab Spaces にプリインストールされています。 SageMaker 配布イメージ;エンドユーザーは、Jupyter AI 拡張機能を使用して SageMaker でホストされるエンドポイントと統合するために追加の構成を行う必要はありません。このセクションでは、統合された Jupyter AI ツールを使用する 2 つの方法について説明します。
魔法を使用したノートブック内の Jupyter AI
ジュピターAI %%ai マジック コマンドを使用すると、SageMaker Studio JupyterLab ノートブックを再現可能な生成 AI 環境に変換できます。 AI マジックの使用を開始するには、使用する jupyter_ai_magics 拡張機能がロードされていることを確認してください。 %%ai 魔法、追加ロード amazon_sagemaker_sql_magic 使用する %%sm_sql マジック:
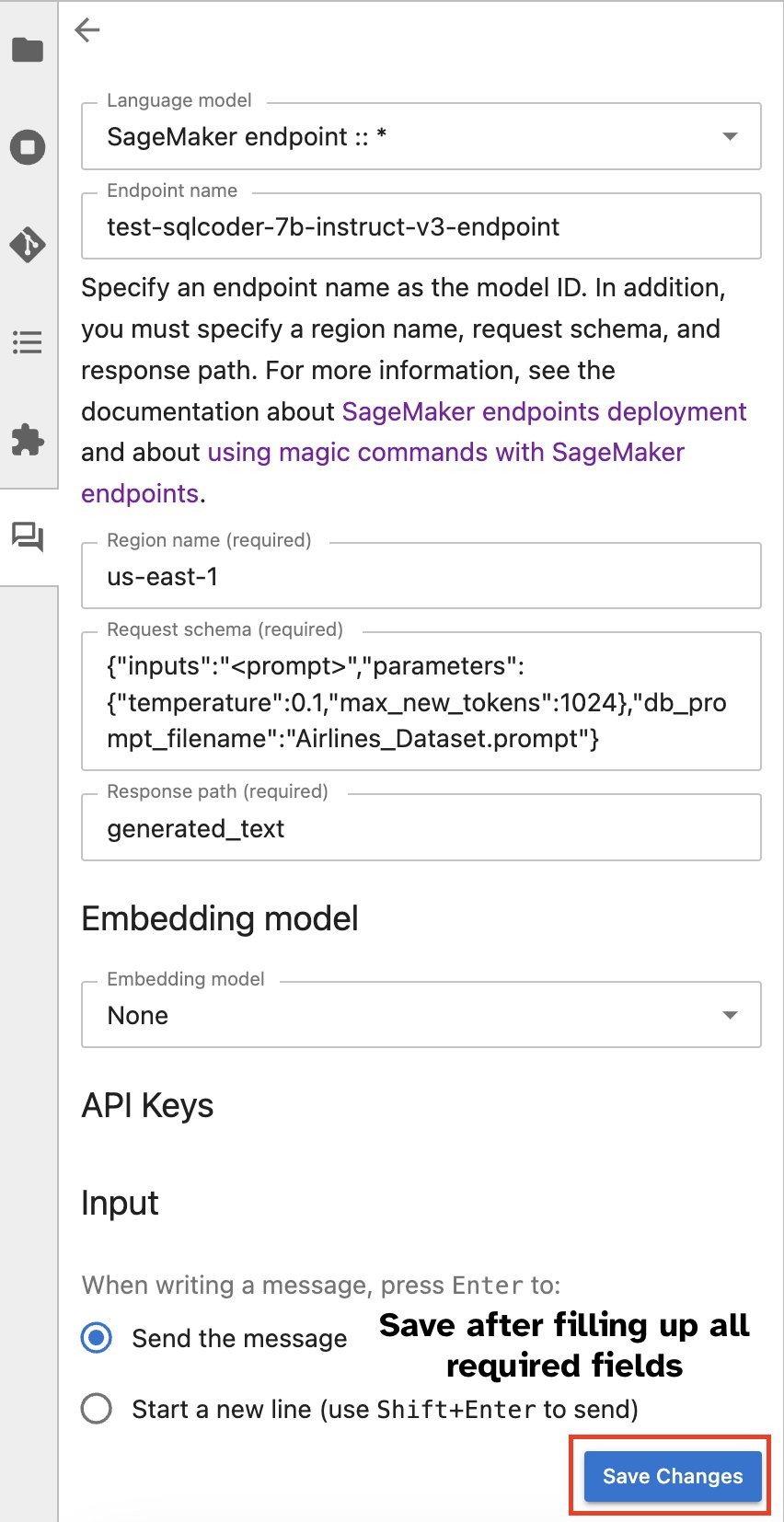
ノートブックから SageMaker エンドポイントへの呼び出しを実行するには、 %%ai マジック コマンドでは、次のパラメータを指定し、コマンドを次のように構造化します。
- –地域名 – エンドポイントがデプロイされるリージョンを指定します。これにより、リクエストが正しい地理的位置にルーティングされるようになります。
- –リクエストスキーマ – 入力データのスキーマを含めます。このスキーマは、モデルがリクエストを処理するために必要な入力データの予期される形式とタイプの概要を示します。
- –応答パス – モデルの出力が配置される応答オブジェクト内のパスを定義します。このパスは、モデルから返された応答から関連データを抽出するために使用されます。
- -f (オプション) - これは 出力フォーマッタ モデルによって返される出力のタイプを示すフラグ。 Jupyter ノートブックのコンテキストでは、出力がコードの場合、このフラグを適切に設定して、Jupyter ノートブックのセルの先頭に実行可能コードとして出力をフォーマットし、その後にユーザー対話用の自由テキスト入力領域を配置する必要があります。
たとえば、Jupyter ノートブックのセル内のコマンドは次のコードのようになります。
Jupyter AI チャット ウィンドウ
あるいは、組み込みのユーザー インターフェイスを通じて SageMaker エンドポイントと対話し、クエリの生成や対話のプロセスを簡素化することもできます。 SageMaker エンドポイントとのチャットを開始する前に、次のスクリーンショットに示すように、Jupyter AI で SageMaker エンドポイントに関連する設定を構成します。
 |
 |
まとめ
SageMaker Studio は、SQL サポートを JupyterLab ノートブックに統合することで、データ サイエンティストのワークフローを簡素化および合理化します。これにより、データ サイエンティストは複数のツールを管理する必要がなく、自分のタスクに集中できるようになります。さらに、SageMaker Studio の新しい組み込み SQL 統合により、データ ペルソナは自然言語テキストを入力として使用して SQL クエリを簡単に生成できるため、ワークフローが高速化されます。
SageMaker Studio でこれらの機能を試してみることをお勧めします。詳細については、以下を参照してください。 Studio で SQL を使用してデータを準備する.
付録
カスタム環境で SQL ブラウザとノートブック SQL セルを有効にする
SageMaker ディストリビューション イメージを使用していない場合、またはディストリビューション イメージ 1.5 以前を使用している場合は、次のコマンドを実行して、JupyterLab 環境内で SQL 参照機能を有効にします。
SQL ブラウザ ウィジェットを再配置する
JupyterLab ウィジェットでは再配置が可能です。好みに応じて、ウィジェットを JupyterLab ウィジェット ペインのどちらかの側に移動できます。必要に応じて、ウィジェット アイコンを右クリックして選択するだけで、SQL ウィジェットの方向をサイドバーの反対側 (右から左) に移動できます。 サイドバー側を切り替える.
 |
 |
著者について
 プラナフ・ムルティ AWS の AI/ML スペシャリスト ソリューション アーキテクトです。 彼は、顧客が機械学習 (ML) ワークロードを構築、トレーニング、デプロイし、SageMaker に移行できるよう支援することに重点を置いています。 以前は半導体業界で、最先端の ML 技術を使用して半導体プロセスを改善するための大規模コンピューター ビジョン (CV) および自然言語処理 (NLP) モデルの開発に従事していました。 自由時間には、チェスをしたり、旅行を楽しんでいます。 プラナフは次のサイトで見つけることができます LinkedIn.
プラナフ・ムルティ AWS の AI/ML スペシャリスト ソリューション アーキテクトです。 彼は、顧客が機械学習 (ML) ワークロードを構築、トレーニング、デプロイし、SageMaker に移行できるよう支援することに重点を置いています。 以前は半導体業界で、最先端の ML 技術を使用して半導体プロセスを改善するための大規模コンピューター ビジョン (CV) および自然言語処理 (NLP) モデルの開発に従事していました。 自由時間には、チェスをしたり、旅行を楽しんでいます。 プラナフは次のサイトで見つけることができます LinkedIn.
 ヴァルン・シャー は、アマゾン ウェブ サービスの Amazon SageMaker Studio に取り組むソフトウェア エンジニアです。彼は、データ処理とデータ準備作業を簡素化するインタラクティブな ML ソリューションの構築に重点を置いています。ヴァルンは余暇には、ハイキングやスキーなどのアウトドア アクティビティを楽しんでおり、常に新しいエキサイティングな場所を発見することに熱心です。
ヴァルン・シャー は、アマゾン ウェブ サービスの Amazon SageMaker Studio に取り組むソフトウェア エンジニアです。彼は、データ処理とデータ準備作業を簡素化するインタラクティブな ML ソリューションの構築に重点を置いています。ヴァルンは余暇には、ハイキングやスキーなどのアウトドア アクティビティを楽しんでおり、常に新しいエキサイティングな場所を発見することに熱心です。
 スメダ・スワミー 彼はアマゾン ウェブ サービスのプリンシパル プロダクト マネージャーであり、データ サイエンスと機械学習に最適な IDE を開発するという使命において SageMaker Studio チームを率いています。彼は過去 15 年間、機械学習ベースの消費者向けおよび企業向け製品の構築に専念してきました。
スメダ・スワミー 彼はアマゾン ウェブ サービスのプリンシパル プロダクト マネージャーであり、データ サイエンスと機械学習に最適な IDE を開発するという使命において SageMaker Studio チームを率いています。彼は過去 15 年間、機械学習ベースの消費者向けおよび企業向け製品の構築に専念してきました。
 ボスコ・アルバカーキ AWS のシニア パートナー ソリューション アーキテクトであり、エンタープライズ データベース ベンダーおよびクラウド プロバイダーのデータベースおよび分析製品を 20 年以上使用してきた経験があります。 彼は、テクノロジー企業がデータ分析ソリューションと製品を設計および実装するのを支援してきました。
ボスコ・アルバカーキ AWS のシニア パートナー ソリューション アーキテクトであり、エンタープライズ データベース ベンダーおよびクラウド プロバイダーのデータベースおよび分析製品を 20 年以上使用してきた経験があります。 彼は、テクノロジー企業がデータ分析ソリューションと製品を設計および実装するのを支援してきました。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

