生成 AI アプリケーションの急速な導入に伴い、これらのアプリケーションは、より高いスループットで知覚される待ち時間を短縮するために時間内に応答する必要があります。基礎モデル (FM) は、多くの場合、数百万から数十億、あるいはそれを超える規模のパラメーターを含む膨大なデータのコーパスで事前トレーニングされます。大規模言語モデル (LLM) は、ユーザー推論の応答としてテキストを生成する FM の一種です。さまざまな構成の推論パラメータを使用してこれらのモデルを推論すると、レイテンシが不均一になる可能性があります。不一致の原因としては、モデルから期待される応答トークンの数が異なること、またはモデルがデプロイされているアクセラレータの種類が原因である可能性があります。
どちらの場合も、完全な応答を待つのではなく、推論に応答ストリーミングのアプローチを採用して、情報のチャンクが生成されるとすぐに送り返すことができます。これにより、遅延した完全な応答ではなく、リアルタイムでストリーミングされた部分的な応答を確認できるため、インタラクティブなエクスペリエンスが作成されます。
という公式発表により、 Amazon SageMaker リアルタイム推論が応答ストリーミングをサポートするようになりましたを使用するときに、推論応答をクライアントに継続的にストリーミングできるようになりました。 アマゾンセージメーカー 応答ストリーミングによるリアルタイム推論。このソリューションは、チャットボット、仮想アシスタント、音楽ジェネレーターなど、さまざまな生成型 AI アプリケーションのインタラクティブなエクスペリエンスを構築するのに役立ちます。この投稿では、最初のバイトまでの時間 (TTFB) の形式で応答時間を高速化し、Llama 2 モデルの推論中に知覚される全体的な遅延を削減する方法を示します。
ソリューションを実装するために、フルマネージド インフラストラクチャ、ツール、ワークフローを使用してデータを準備し、あらゆるユースケース向けの機械学習 (ML) モデルを構築、トレーニング、デプロイするためのフルマネージド サービスである SageMaker を使用します。 SageMaker が提供するさまざまなデプロイメント オプションの詳細については、以下を参照してください。 Amazon SageMaker モデルホスティングに関するよくある質問。応答ストリーミングによるリアルタイム推論を使用して、遅延の問題にどのように対処できるかを理解しましょう。
ソリューションの概要
LLM によるリアルタイム推論に関連する前述の遅延に対処したいため、まず、Llama 2 のリアルタイム推論に応答ストリーミング サポートを使用する方法を理解しましょう。ただし、どの LLM も、実際の推論で応答ストリーミング サポートを利用できます。 -時間の推論。
Llama 2 は、事前トレーニングされ、微調整された生成テキスト モデルのコレクションであり、その規模は 7 億から 70 億のパラメーターに及びます。 Llama 2 モデルは、デコーダのみのアーキテクチャを備えた自己回帰モデルです。プロンプトと推論パラメーターが提供されると、Llama 2 モデルはテキスト応答を生成できます。これらのモデルは、翻訳、要約、質問応答、チャットに使用できます。
この投稿では、Llama 2 Chat モデルをデプロイします。 meta-llama/Llama-2-13b-chat-hf SageMaker では、応答ストリーミングを使用したリアルタイム推論が可能です。
SageMaker エンドポイントにモデルをデプロイする場合、専用のツールを使用してモデルをコンテナ化できます。 AWSディープラーニングコンテナ (DLC) イメージは、一般的なオープンソース ライブラリで利用できます。 Llama 2 モデルはテキスト生成モデルです。どちらかを使用できます SageMaker 上の Hugging Face LLM 推論コンテナ powered by ハグフェイス テキスト生成の推論 (TGI) または AWS DLC 大規模モデルの推論 (LMI)。
この投稿では、G2 インスタンスによるリアルタイム推論のために、SageMaker Hosting 上の DLC を使用して Llama 13 5B チャット モデルをデプロイします。 G5 インスタンスは、グラフィックスを多用するアプリケーションおよび ML 推論用の高性能 GPU ベースのインスタンスです。インスタンス構成に応じて適切な変更を加えて、サポートされているインスタンス タイプ p4d、p3、g5、および g4dn を使用することもできます。
前提条件
このソリューションを実装するには、次のものが必要です。
- AWS アカウント AWS IDおよびアクセス管理 ソリューションの一部として作成されたリソースを管理する権限を持つ (IAM) ロール。
- 初めて作業する場合 Amazon SageMakerスタジオ、まず、 SageMakerドメイン.
- ハグフェイスアカウント。 ユーザー登録 まだアカウントをお持ちでない場合は、メールアドレスをお知らせください。
- 微調整や推論を目的として、Hugging Face で利用可能なモデル、特に Llama などのゲート モデルにシームレスにアクセスするには、読み取りアクセス トークンを取得するための Hugging Face アカウントが必要です。ハグフェイスアカウントにサインアップすると、 ログイン 訪問します https://huggingface.co/settings/tokens 読み取りアクセス トークンを作成します。
- Hugging Face へのサインアップに使用したのと同じ電子メール ID を使用して、Llama 2 にアクセスします。
- Hugging Face から入手できる Llama 2 モデルはゲート付きモデルです。 Llama モデルの使用はメタ ライセンスによって管理されます。モデルの重みとトークナイザーをダウンロードするには、 ラマへのアクセスをリクエストする そしてライセンスに同意します。
- アクセスが許可されると (通常は数日以内)、確認メールが届きます。この例では、次のモデルを使用します。
Llama-2-13b-chat-hf, ただし、他のバリアントにもアクセスできるはずです。
アプローチ 1: ハグフェイス TGI
このセクションでは、 meta-llama/Llama-2-13b-chat-hf Hugging Face TGI を使用した応答ストリーミングを使用してモデルを SageMaker リアルタイム エンドポイントに送信します。次の表は、この展開の仕様の概要を示しています。
| 製品仕様 | 値 |
| コンテナ | ハグフェイス TGI |
| モデル名 | メタラマ/ラマ-2-13b-チャット-hf |
| ML インスタンス | ml.g5.12xラージ |
| 推論 | 応答ストリーミングによるリアルタイム |
モデルを展開する
まず、展開する LLM の基本イメージを取得します。次に、ベースイメージ上にモデルを構築します。最後に、リアルタイム推論のためにモデルを SageMaker Hosting の ML インスタンスにデプロイします。
プログラムでデプロイメントを実現する方法を見てみましょう。簡潔にするために、このセクションでは展開手順に役立つコードのみを説明します。デプロイメント用の完全なソース コードはノートブックで入手できます。 llama-2-hf-tgi/llama-2-13b-chat-hf/1-deploy-llama-2-13b-chat-hf-tgi-sagemaker.ipynb.
TGI を利用した最新の Hugging Face LLM DLC を事前構築済み経由で取得します SageMaker DLC。このイメージを使用して、 meta-llama/Llama-2-13b-chat-hf SageMaker のモデル。次のコードを参照してください。
次のように定義された構成パラメーターを使用して、モデルの環境を定義します。
交換する <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> 設定パラメータの場合 HUGGING_FACE_HUB_TOKEN この投稿の前提条件セクションで詳しく説明されているように、Hugging Face プロフィールから取得したトークンの値を使用します。構成では、モデルのレプリカごとに使用される GPU の数を 4 として定義します。 SM_NUM_GPUS。その後、デプロイできます meta-llama/Llama-2-13b-chat-hf 5.12 つの GPU を備えた ml.g4xlarge インスタンス上のモデル。
これで、次のインスタンスを構築できるようになります。 HuggingFaceModel 前述の環境構成では次のようになります。
最後に、モデルで使用可能なデプロイ メソッドに次のようなさまざまなパラメーター値を引数として指定して、モデルをデプロイします。 endpoint_name, initial_instance_count, instance_type:
推論を実行する
Hugging Face TGI DLC には、モデルのカスタマイズやコード変更を行わずに応答をストリーミングする機能が付属しています。使用できます invoke_endpoint_with_response_stream Boto3 を使用している場合、または InvokeEndpointWithResponseStream SageMaker Python SDK を使用してプログラミングする場合。
InvokeEndpointWithResponseStream SageMaker の API を使用すると、開発者は SageMaker モデルから応答をストリーミングして戻すことができます。これにより、体感的な待ち時間が短縮され、顧客満足度の向上に役立ちます。これは、応答全体を待つよりも即時処理の方が重要な、生成 AI モデルで構築されたアプリケーションの場合に特に重要です。
この例では、Boto3 を使用してモデルを推論し、SageMaker API を使用します。 invoke_endpoint_with_response_stream 次のように:
議論 CustomAttributes 値に設定されます accept_eula=false. accept_eula パラメータを次のように設定する必要があります true Llama 2 モデルからの応答を正常に取得します。を使用して呼び出しが成功した後、 invoke_endpoint_with_response_streamの場合、メソッドはバイトの応答ストリームを返します。
次の図は、このワークフローを示しています。
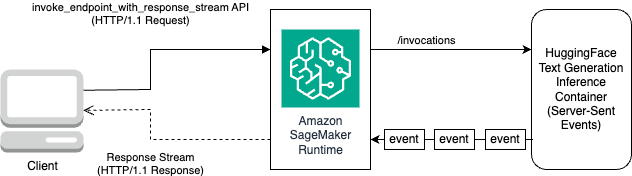
バイトのストリームをループし、読み取り可能なテキストに解析するイテレータが必要です。の LineIterator 実装は次の場所にあります llama-2-hf-tgi/llama-2-13b-chat-hf/utils/LineIterator.py。これで、モデルの推論中にペイロードとして使用するためのプロンプトと指示を準備する準備が整いました。
プロンプトと指示を準備する
このステップでは、LLM のプロンプトと手順を準備します。 Llama 2 にプロンプトを表示するには、次のプロンプト テンプレートが必要です。
メソッドでプログラム的に定義されたプロンプト テンプレートを構築します。 build_llama2_prompt、これは前述のプロンプト テンプレートと一致します。次に、ユースケースに従って命令を定義します。この場合、「」で説明されているように、マーケティング キャンペーン用の電子メールを生成するようにモデルに指示しています。 get_instructions 方法。これらのメソッドのコードは、 llama-2-hf-tgi/llama-2-13b-chat-hf/2-sagemaker-realtime-inference-llama-2-13b-chat-hf-tgi-streaming-response.ipynb ノート。詳細については、実行するタスクと組み合わせた命令を作成します。 user_ask_1 次のように:
build_llama2_prompt によって生成されたプロンプト テンプレートに従って、プロンプトを構築するための指示を渡します。
キーを使用してプロンプトとともに推論パラメータをクラブ化します stream 値で True 最終的なペイロードを形成します。ペイロードの送信先 get_realtime_response_streamこれは、応答ストリーミングでエンドポイントを呼び出すために使用されます。
LLM から生成されたテキストは、次のアニメーションに示すように出力にストリーミングされます。
アプローチ 2: DJL サービスを使用した LMI
このセクションでは、 meta-llama/Llama-2-13b-chat-hf DJL Serving を備えた LMI を使用した応答ストリーミングにより、モデルを SageMaker リアルタイム エンドポイントに送信します。次の表は、この展開の仕様の概要を示しています。
| 製品仕様 | 値 |
| コンテナ | DJL Serving を使用した LMI コンテナー イメージ |
| モデル名 | メタラマ/ラマ-2-13b-チャット-hf |
| ML インスタンス | ml.g5.12xラージ |
| 推論 | 応答ストリーミングによるリアルタイム |
まずモデルをダウンロードして保存します。 Amazon シンプル ストレージ サービス (アマゾンS3)。次に、モデルの S3 プレフィックスを示す S3 URI を指定します。 serving.properties ファイル。次に、展開する LLM の基本イメージを取得します。次に、ベースイメージ上にモデルを構築します。最後に、リアルタイム推論のためにモデルを SageMaker Hosting の ML インスタンスにデプロイします。
前述の展開手順をプログラムで実行する方法を見てみましょう。簡潔にするために、このセクションでは展開手順に役立つコードのみを詳しく説明します。このデプロイメントの完全なソース コードはノートブックで入手できます。 llama-2-lmi/llama-2-13b-chat/1-deploy-llama-2-13b-chat-lmi-response-streaming.ipynb.
Hugging Face からモデルのスナップショットをダウンロードし、Amazon S3 にモデルのアーティファクトをアップロードします。
前述の前提条件を満たしているので、モデルを SageMaker ノートブック インスタンスにダウンロードし、その後のデプロイのために S3 バケットにアップロードします。
有効なアクセス トークンを指定しなくても、モデルはダウンロードされることに注意してください。しかし、そのようなモデルをデプロイすると、モデルの提供は成功しません。したがって、交換することをお勧めします <YOUR_HUGGING_FACE_READ_ACCESS_TOKEN> 議論のために token 前提条件で詳述されているように、Hugging Face プロファイルから取得したトークンの値を使用します。この投稿では、Hugging Face で識別される Llama 2 の公式モデル名を次の値で指定します。 meta-llama/Llama-2-13b-chat-hf。非圧縮モデルは次の場所にダウンロードされます。 local_model_path 前述のコードを実行した結果。
ファイルを Amazon S3 にアップロードし、後で使用する URI を取得します。 serving.properties.
梱包していただきます meta-llama/Llama-2-13b-chat-hf で指定された構成を使用した DJL Serving を使用した LMI コンテナー イメージのモデル serving.properties。次に、モデルを、SageMaker ML インスタンス ml.g5.12xlarge のコンテナー イメージにパッケージ化されたモデル アーティファクトとともにデプロイします。次に、この ML インスタンスを SageMaker Hosting のリアルタイム推論に使用します。
DJL Serving 用のモデル アーティファクトを準備する
を作成してモデル アーティファクトを準備します。 serving.properties 設定ファイル:
この構成ファイルでは次の設定を使用します。
- エンジン – これは、DJL が使用するランタイム エンジンを指定します。可能な値は次のとおりです。
Python,DeepSpeed,FasterTransformer,MPI。この場合、次のように設定します。MPI。モデルの並列化と推論 (MPI) により、利用可能なすべての GPU にわたるモデルの分割が容易になり、推論が高速化されます。 - オプション.エントリポイント – このオプションは、DJL Serving が提供するどのハンドラーを使用するかを指定します。可能な値は次のとおりです。
djl_python.huggingface,djl_python.deepspeed,djl_python.stable-diffusion。 を使用しておりますdjl_python.huggingfaceハグフェイスアクセラレート用。 - オプション.tensor_Parallel_degree – このオプションは、モデルで実行されるテンソル並列分割の数を指定します。 Accelerate がモデルを分割する必要がある GPU デバイスの数を設定できます。このパラメーターは、DJL サービングの実行時に起動されるモデルごとのワーカーの数も制御します。たとえば、4 GPU マシンがあり、XNUMX つのパーティションを作成している場合、モデルごとに XNUMX つのワーカーがリクエストに対応することになります。
- option.low_cpu_mem_usage – これにより、モデルをロードする際の CPU メモリの使用量が削減されます。これを次のように設定することをお勧めします
TRUE. - オプション.ローリングバッチ – これにより、サポートされている戦略の 1 つを使用した反復レベルのバッチ処理が可能になります。値には以下が含まれます
auto,scheduler,lmi-dist。 を使用しておりますlmi-distLlama 2 の連続バッチ処理を有効にするため。 - option.max_rolling_batch_size – これにより、連続バッチ内の同時リクエストの数が制限されます。値のデフォルトは 32 です。
- オプション.モデルID – 交換する必要があります
{{model_id}}内部でホストされている事前トレーニング済みモデルのモデル ID を使用します。 Hugging Face のモデル リポジトリ またはモデルアーティファクトへの S3 パス。
その他の構成オプションは次の場所にあります。 構成と設定.
DJL Serving はモデルアーティファクトが .tar ファイルにパッケージ化されフォーマットされることを想定しているため、次のコードスニペットを実行して .tar ファイルを圧縮し、Amazon S3 にアップロードします。
DJL Serving を使用して最新の LMI コンテナー イメージを取得する
次に、SageMaker for LMI で利用可能な DLC を使用してモデルをデプロイします。の SageMaker イメージ URI を取得します。 djl-deepspeed 次のコードを使用してプログラムでコンテナを作成します。
前述のイメージを使用して、 meta-llama/Llama-2-13b-chat-hf SageMaker のモデル。これで、モデルの作成に進むことができます。
モデルを作成する
を使用してコンテナが構築されるモデルを作成できます。 inference_image_uri で示される S3 URI にあるモデル提供コード s3_code_artifact:
これで、エンドポイント構成のすべての詳細を含むモデル構成を作成できます。
モデル構成を作成する
次のコードを使用して、によって識別されるモデルのモデル構成を作成します。 model_name:
モデル構成は、 ProductionVariants パラメーター InstanceType ML インスタンス ml.g5.12xlarge の場合。また、 ModelName 前の手順でモデルの作成に使用したのと同じ名前を使用して、モデルとエンドポイント構成の間の関係を確立します。
モデルとモデル構成を定義したので、SageMaker エンドポイントを作成できます。
SageMaker エンドポイントを作成する
次のコード スニペットを使用して、モデルをデプロイするためのエンドポイントを作成します。
次のコード スニペットを使用して、展開の進行状況を確認できます。
デプロイが成功すると、エンドポイントのステータスは次のようになります。 InService。エンドポイントの準備ができたので、応答ストリーミングを使用して推論を実行しましょう。
応答ストリーミングによるリアルタイム推論
Hugging Face TGI の以前のアプローチで説明したように、同じ方法を使用できます。 get_realtime_response_stream SageMaker エンドポイントからの応答ストリーミングを呼び出します。 LMI アプローチを使用した推論のコードは、 llama-2-lmi/llama-2-13b-chat/2-inference-llama-2-13b-chat-lmi-response-streaming.ipynb ノート。の LineIterator 実装は次の場所にあります llama-2-lmi/utils/LineIterator.py。 なお、 LineIterator LMI コンテナにデプロイされた Llama 2 チャット モデルの場合は、 LineIterator ハグフェイス TGI セクションで参照されています。の LineIterator Llama 2 Chat モデルからのバイト ストリームをループし、LMI コンテナで推論します。 djl-deepspeed バージョン0.25.0。次のヘルパー関数は、 invoke_endpoint_with_response_stream API:
前述のメソッドは、 LineIterator 人間が読める形式で。
モデルの推論中にプロンプトとそれらをペイロードとして使用するための指示を準備する方法を見てみましょう。
Hugging Face TGI と LMI の両方で同じモデルを推論しているため、プロンプトと指示を準備するプロセスは同じです。したがって、次のメソッドを使用できます get_instructions および build_llama2_prompt 推論のため。
get_instructions メソッドは命令を返します。詳細については、実行するタスクと組み合わせた指示を作成します。 user_ask_2 次のように:
によって生成されたプロンプト テンプレートに従ってプロンプトを構築するための指示を渡します。 build_llama2_prompt:
最終的なペイロードを形成するためのプロンプトとともに推論パラメーターを組み合わせます。次に、ペイロードをに送信します get_realtime_response_stream, これは、応答ストリーミングでエンドポイントを呼び出すために使用されます。
LLM から生成されたテキストは、次のアニメーションに示すように出力にストリーミングされます。

クリーンアップ
不必要な料金の発生を避けるために、 AWSマネジメントコンソール 投稿で言及されているアプローチの実行中に作成されたエンドポイントとそれに関連するリソースを削除します。どちらの展開方法でも、次のクリーンアップ ルーチンを実行します。
交換する <SageMaker_Real-time_Endpoint_Name> 変数の場合 endpoint_name 実際のエンドポイントを使用します。
3 番目のアプローチでは、モデルとコードのアーティファクトを Amazon S3 に保存しました。次のコードを使用して SXNUMX バケットをクリーンアップできます。
まとめ
この投稿では、応答トークンの数の変化や推論パラメーターの異なるセットが LLM に関連するレイテンシにどのように影響するかについて説明しました。応答ストリーミングを利用して問題に対処する方法を示しました。次に、AWS DLC を使用して Llama 2 Chat モデルをデプロイおよび推論するための XNUMX つのアプローチ、LMI と Hugging Face TGI を特定しました。
ストリーミング応答の重要性と、ストリーミング応答によって知覚される遅延がどのように短縮されるかが理解できたはずです。ストリーミング応答によりユーザー エクスペリエンスが向上します。ストリーミング応答を使用しないと、LLM が応答全体を構築するまで待たされることになります。さらに、応答ストリーミングを備えた Llama 2 Chat モデルを導入すると、ユーザー エクスペリエンスが向上し、顧客を満足させることができます。
公式の aws-samples を参照できます amazon-sagemaker-llama2-response-streaming-recipes これには、他の Llama 2 モデル バリアントの展開も含まれます。
参考文献
著者について
 パヴァン・クマール・ラオ・ナヴール アマゾン ウェブ サービスのソリューション アーキテクトです。彼はインドの ISV と協力して、AWS でのイノベーションを支援しています。彼は「V プログラミング入門」という本の著者です。彼は、ハイデラバードのインド工科大学 (IIT) でデータ サイエンスの上級修士号を取得しました。また、インド経営管理大学院で IT 専門分野のエグゼクティブ MBA を取得し、ヴァーグデヴィ工科大学で電子通信工学の学士号を取得しています。 Pavan は、AWS 認定ソリューションアーキテクトプロフェッショナルであり、AWS 認定機械学習スペシャリティ、Microsoft Certified Professional (MCP)、Microsoft Certified Technology Specialist (MCTS) などの他の認定資格も保持しています。彼はオープンソースの愛好家でもあります。自由時間には、シーアとリアーナの素晴らしい魔法の声を聴くのが大好きです。
パヴァン・クマール・ラオ・ナヴール アマゾン ウェブ サービスのソリューション アーキテクトです。彼はインドの ISV と協力して、AWS でのイノベーションを支援しています。彼は「V プログラミング入門」という本の著者です。彼は、ハイデラバードのインド工科大学 (IIT) でデータ サイエンスの上級修士号を取得しました。また、インド経営管理大学院で IT 専門分野のエグゼクティブ MBA を取得し、ヴァーグデヴィ工科大学で電子通信工学の学士号を取得しています。 Pavan は、AWS 認定ソリューションアーキテクトプロフェッショナルであり、AWS 認定機械学習スペシャリティ、Microsoft Certified Professional (MCP)、Microsoft Certified Technology Specialist (MCTS) などの他の認定資格も保持しています。彼はオープンソースの愛好家でもあります。自由時間には、シーアとリアーナの素晴らしい魔法の声を聴くのが大好きです。
 スダンシュ・ヘイト は AWS の主任 AI/ML スペシャリストであり、クライアントと連携して MLOps と生成 AI の取り組みについてアドバイスを行っています。 Amazon 入社前の役職では、オープンソースベースの AI およびゲーミフィケーション プラットフォームを根本から構築するチームを概念化し、作成し、主導し、100 を超えるクライアントで商用化に成功しました。 Sudhanshu はいくつかの特許を取得しており、25 冊の本といくつかの論文やブログを執筆し、さまざまな技術フォーラムで自身の見解を発表しています。彼は思想的リーダーであり講演者でもあり、この業界に 1000 年近く携わっています。彼は世界中のフォーチュン XNUMX のクライアントと仕事をしてきましたが、最近ではインドのデジタル ネイティブのクライアントと仕事をしてきました。
スダンシュ・ヘイト は AWS の主任 AI/ML スペシャリストであり、クライアントと連携して MLOps と生成 AI の取り組みについてアドバイスを行っています。 Amazon 入社前の役職では、オープンソースベースの AI およびゲーミフィケーション プラットフォームを根本から構築するチームを概念化し、作成し、主導し、100 を超えるクライアントで商用化に成功しました。 Sudhanshu はいくつかの特許を取得しており、25 冊の本といくつかの論文やブログを執筆し、さまざまな技術フォーラムで自身の見解を発表しています。彼は思想的リーダーであり講演者でもあり、この業界に 1000 年近く携わっています。彼は世界中のフォーチュン XNUMX のクライアントと仕事をしてきましたが、最近ではインドのデジタル ネイティブのクライアントと仕事をしてきました。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/inference-llama-2-models-with-real-time-response-streaming-using-amazon-sagemaker/

