生成言語モデルは、論理的および分析的な自然言語処理 (NLP) タスクを解決するのに非常に優れていることが証明されています。さらに、 迅速なエンジニアリング パフォーマンスを著しく向上させることができます。例えば、 思考の連鎖 (CoT) は、複雑な複数ステップの問題に対するモデルの能力を向上させることが知られています。推論を伴うタスクの精度をさらに高めるには、 一貫性 言語生成時に貪欲を確率的デコードに置き換えるプロンプトアプローチが提案されています。
アマゾンの岩盤 は、単一の API を介して大手 AI 企業と Amazon の高性能基盤モデルの選択肢を提供するフルマネージド サービスであり、構築するための幅広い機能セットも提供します。 generative AI セキュリティ、プライバシー、責任ある AI を備えたアプリケーション。とともに バッチ推論 API を使用すると、Amazon Bedrock を使用して基礎モデルを使用して推論をバッチで実行し、より効率的に応答を取得できます。この投稿では、Amazon Bedrock でバッチ推論を介して自己一貫性プロンプトを実装し、算術および複数選択推論タスクでのモデルのパフォーマンスを向上させる方法を示します。
ソリューションの概要
言語モデルの自己一貫性プロンプトは、最終的な回答に集約される複数の応答の生成に依存しています。 CoT のような単一世代のアプローチとは対照的に、自己一貫性のあるサンプルとマージナライズの手順では、より一貫性のあるソリューションにつながるさまざまなモデル完成が作成されます。貪欲ではなく確率的なデコード戦略を使用することにより、特定のプロンプトに対してさまざまな応答を生成することが可能になります。
次の図は、自己一貫性が多様な推論パスのセットを生成し、それらを集約して最終的な答えを生成するという点で、貪欲な CoT とどのように異なるかを示しています。

テキスト生成のためのデコード戦略
デコーダ専用言語モデルによって生成されたテキストは単語ごとに展開され、後続のトークンは前のコンテキストに基づいて予測されます。モデルは、特定のプロンプトに対して、各トークンがシーケンス内で次に出現する可能性を示す確率分布を計算します。デコードには、これらの確率分布を実際のテキストに変換することが含まれます。テキストの生成は、次のセットによって仲介されます。 推論パラメータ これらは多くの場合、デコード方法自体のハイパーパラメータです。一例としては、 温度、次のトークンの確率分布を調整し、モデルの出力のランダム性に影響を与えます。
貪欲なデコード は、各ステップで最も高い確率でトークンを選択する決定論的なデコード戦略です。このアプローチは単純で効率的ではありますが、より広い確率空間を無視するため、反復的なパターンに陥る危険性があります。推論時に温度パラメータを 0 に設定することは、本質的に貪欲なデコードを実装することと同じです。
サンプリング 予測された確率分布に基づいて後続の各トークンをランダムに選択することにより、復号プロセスに確率性を導入します。このランダム性により、出力の変動が大きくなります。確率的デコードは、潜在的な出力の多様性をより巧みに捕捉することが証明されており、多くの場合、より想像力豊かな応答が得られます。温度値が高くなると、より多くの変動が生じ、モデルの応答の創造性が高まります。
プロンプト手法: CoT と自己一貫性
言語モデルの推論能力は、迅速なエンジニアリングによって強化できます。特に、CoT は次のことを示しています。 推論を導き出す 複雑な NLP タスクで。を実装する 1 つの方法 ゼロショット CoT は、「段階的に考える」という指示によるプロンプト拡張を介して行われます。もう 1 つは、モデルを中間推論ステップのサンプルに公開することです。 数回のプロンプト ファッション。どちらのシナリオでも通常、貪欲なデコードが使用されます。 CoT は、算術、常識、記号推論タスクに関する単純な命令プロンプトと比較して、パフォーマンスの大幅な向上につながります。
自己一貫性のプロンプト は、推論プロセスに多様性を導入すると、モデルが正しい答えに収束するのに有益であるという仮定に基づいています。この手法では、確率的デコードを使用して、次の 3 つのステップでこの目標を達成します。
- CoT イグゼンプラを使用して言語モデルにプロンプトを出し、推論を導き出します。
- 貪欲なデコーディングをサンプリング戦略に置き換えて、多様な推論パスのセットを生成します。
- 結果を集計して、応答セット内で最も一貫した回答を見つけます。
自己一貫性は、一般的な算術推論および常識的推論のベンチマークで CoT プロンプトを上回るパフォーマンスを示すことが示されています。このアプローチの制限は、計算コストが大きくなることです。
この投稿では、自己一貫性プロンプトが 2 つの NLP 推論タスク (算術問題解決と多肢選択ドメイン固有の質問応答) における生成言語モデルのパフォーマンスをどのように向上させるかを示します。 Amazon Bedrock でバッチ推論を使用したアプローチを示します。
- JupyterLab の Amazon Bedrock Python SDK にアクセスします。 アマゾンセージメーカー ノートブック インスタンス。
- 算術推論の場合、プロンプトを表示します。 コヒアコマンド 小学校の算数の問題の GSM8K データセットについて。
- 多肢選択推論の場合、プロンプトを表示します。 AI21 ラボ ジュラシック 2 ミッド AWS 認定ソリューションアーキテクト – アソシエイト試験の質問の小さなサンプルについて説明します。
前提条件
このチュートリアルでは、次の前提条件を前提としています。

この投稿に示されているコードの実行コストの見積もりは、温度ベースのサンプリングに 100 つの値を使用して 30 の推論パスで自己整合性プロンプトを XNUMX 回実行すると仮定すると、XNUMX ドルです。
算術推論機能を調査するためのデータセット
GSM8K は、高度な言語多様性を特徴とする、人間が組み立てた小学校の算数の問題のデータセットです。各問題を解決するには 2 ~ 8 のステップが必要で、基本的な算術演算を使用した一連の初歩的な計算を実行する必要があります。このデータは、生成言語モデルの複数ステップの算術推論機能のベンチマークに一般的に使用されます。の GSM8K列車セット 7,473 レコードで構成されます。以下は例です。
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
Amazon Bedrock でバッチ推論を実行するためのセットアップ
バッチ推論を使用すると、Amazon Bedrock への複数の推論呼び出しを非同期に実行でき、大規模なデータセットでのモデル推論のパフォーマンスが向上します。このサービスはこの記事の執筆時点ではプレビュー段階にあり、API を通じてのみ利用できます。参照する バッチ推論を実行する カスタム SDK 経由でバッチ推論 API にアクセスします。
ダウンロードして解凍したら、 Python SDK SageMaker ノートブック インスタンスでは、Jupyter ノートブック セルで次のコードを実行することでインストールできます。
入力データをフォーマットして Amazon S3 にアップロードする
バッチ推論の入力データは、次のような JSONL 形式で準備する必要があります。 recordId & modelInput キー。後者は、Amazon Bedrock で呼び出されるモデルの body フィールドと一致する必要があります。特に、いくつかの Cohereコマンドでサポートされている推論パラメータ temperature ランダム性のために、 max_tokens 出力の長さの場合、および num_generations 複数の応答を生成し、それらはすべて一緒に渡されます。 prompt as modelInput:
見る 基礎モデルの推論パラメータ 他のモデルプロバイダーなどの詳細については、をご覧ください。
算術推論の実験は、Cohere コマンドをカスタマイズしたり微調整したりすることなく、数ショット設定で実行されます。思考の連鎖からの 8 つの少数ショットのサンプルからなる同じセットを使用します (テーブル20) と自己一貫性 (テーブル17) 書類。プロンプトは、GSM8K トレイン セットからの各質問とイグザンプラを連結することによって作成されます。
設定します max_tokens 512に num_generations Cohereコマンドで許可される最大値である5まで。貪欲なデコードの場合、次のように設定します。 temperature 自己一貫性を保つために、温度 0、0.5、および 0.7 で 1 つの実験を実行します。各設定では、それぞれの温度値に応じて異なる入力データが生成されます。データは JSONL としてフォーマットされ、Amazon S3 に保存されます。
Amazon Bedrock でバッチ推論ジョブを作成して実行する
バッチ推論ジョブの作成には、Amazon Bedrock クライアントが必要です。 S3 の入力パスと出力パスを指定し、各呼び出しジョブに一意の名前を付けます。
仕事というのは、 作成した IAM ロール、モデル ID、ジョブ名、入出力設定をパラメータとして Amazon Bedrock API に渡します。
リスト, モニタリング, 停止 バッチ推論ジョブは、それぞれの API 呼び出しによってサポートされます。作成時に、ジョブは最初に次のように表示されます。 Submitted、その後、 InProgress、そして最後に Stopped, Failedまたは Completed.
ジョブが正常に完了すると、生成されたコンテンツは、一意の出力場所を使用して Amazon S3 から取得できます。
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
自己一貫性により、算術タスクにおけるモデルの精度が向上します
Cohere Command の自己一貫性プロンプトは、GSM8K データセットの精度の点で貪欲な CoT ベースラインを上回ります。自己一貫性を保つために、30 つの異なる温度で XNUMX の独立した推論パスをサンプリングしました。 topP & topK 彼らに設定 デフォルト値。最終的なソリューションは、多数決によって最も一貫した出現を選択することによって集約されます。同点の場合は、多数の回答のうち 100 つをランダムに選択します。 XNUMX 回の実行で平均した精度と標準偏差の値を計算します。
次の図は、グリーディ CoT (青) と温度値 8 (黄)、0.5 (緑)、0.7 (オレンジ) での自己無矛盾性をプロンプトした Cohere コマンドからの GSM1.0K データセットの精度をサンプル数の関数として示しています。推論パス。
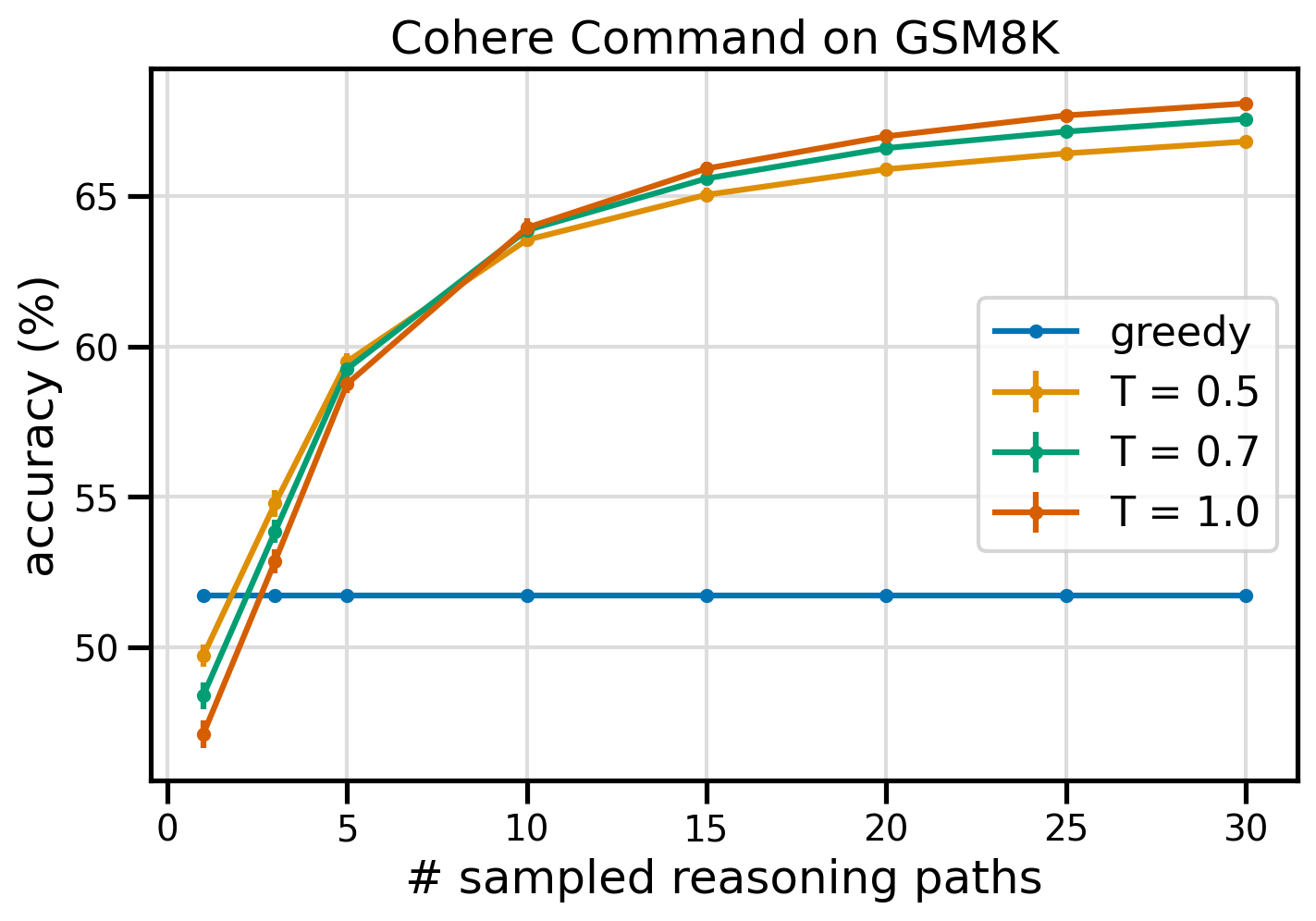
上の図は、サンプリングされたパスの数が 8 つと少ない場合、自己無撞着性によってグリーディ CoT よりも算術精度が向上することを示しています。推論パスをさらに進めるとパフォーマンスが一貫して向上し、思考生成に多様性を導入することの重要性が確認されました。 Cohere Command は、CoT でプロンプトを表示した場合、GSM51.7K 質問セットを 68% の精度で解決します。一方、T=30 で 1.0 の自己矛盾のない推論パスを使用した場合は XNUMX% の精度で解決します。調査された XNUMX つの温度値はすべて同様の結果をもたらし、サンプル数が少ないパスでは温度が低いほどパフォーマンスが比較的高くなります。
効率とコストに関する実際的な考慮事項
自己一貫性は、プロンプトごとに複数の出力を生成するときに発生する応答時間とコストの増加によって制限されます。実際の例として、7,473 個の GSM8K レコードに対する Cohere コマンドを使用した貪欲な生成のバッチ推論は 20 分未満で終了しました。このジョブは 5.5 万個のトークンを入力として受け取り、630,000 個の出力トークンを生成しました。現在のところ Amazon Bedrock の推論価格、かかった合計費用は約9.50ドルでした。
Cohereコマンドとの一貫性を保つために、推論パラメータを使用します num_generations プロンプトごとに複数の補完を作成します。この記事の執筆時点では、Amazon Bedrock では最大 5 世代と 3 つの同時実行が可能です。 Submitted バッチ推論ジョブ。ジョブは次へ進みます。 InProgress ステータスを順番にサンプリングするため、5 つを超えるパスをサンプリングするには複数回の呼び出しが必要になります。
次の図は、GSM8K データセットでの Cohere コマンドのランタイムを示しています。合計実行時間が x 軸に表示され、サンプリングされた推論パスごとの実行時間が y 軸に表示されます。貪欲な生成は最短時間で実行されますが、サンプリングされたパスあたりの時間コストが高くなります。

Greedy 生成は、完全な GSM20K セットに対して 8 分未満で完了し、独自の推論パスをサンプリングします。 50 つのサンプルで自己一貫性を実現するには、完了までに約 14.50% の時間がかかり、約 500 ドルのコストがかかりますが、その間に 1 つのパス (2% 以上) が生成されます。合計実行時間とコストは、サンプリングされたパスが 5 つ増えるごとに段階的に増加します。費用対効果の分析によると、自己一貫性を実際に実装するには、10 ~ XNUMX 個のサンプル パスを含む XNUMX ~ XNUMX 個のバッチ推論ジョブが推奨される設定です。これにより、コストと遅延を抑えながらモデルのパフォーマンスが向上します。
自己一貫性により、算術推論を超えてモデルのパフォーマンスが向上します
自己一貫性プロンプトの適切性を証明するための重要な問題は、この方法がさらなる NLP タスクおよび言語モデルにわたって成功するかどうかです。 Amazon 関連のユースケースの拡張として、Amazon からのサンプル質問に対して小規模な分析を実行します。 AWS ソリューションアーキテクトアソシエイト認定資格。これは、AWS のテクノロジーとサービスに関する多肢選択試験で、ドメインの知識と、いくつかの選択肢の中から推論して決定する能力が必要です。
データセットを準備します SAA-C01 & SAA-C03 サンプル試験問題。利用可能な 20 個の質問のうち、最初の 4 個を少数ショットの例として使用し、モデルに残りの 16 個の回答を求めます。今回は、AI21 Labs Jurassic-2 Mid モデルを使用して推論を実行し、最大 10 個の推論パスを生成します。気温0.7。結果は、自己一貫性によってパフォーマンスが向上することを示しています。貪欲な CoT は 11 個の正解を生成しますが、自己一貫性はさらに 2 つで成功します。
次の表は、5 回の実行で平均化された 10 および 100 のサンプリングされたパスの精度結果を示しています。
| . | 貪欲なデコード | T = 0.7 |
| サンプリングされたパスの数: 5 | 68.6 | 74.1±0.7 |
| サンプリングされたパスの数: 10 | 68.6 | 78.9 ±0.3 |
次の表では、自己整合性は成功しているものの、貪欲な CoT によって不正解となった 5 つの試験問題を示し、それぞれのケースで、モデルが正しい応答または不正確な応答を生成する原因となった正しい (緑) または不正確な (赤) 推論トレースを強調表示しています。自己無撞着性によって生成されたすべてのサンプリングされたパスが正しいわけではありませんが、サンプリングされたパスの数が増加するにつれて、大部分は真の答えに収束します。通常、貪欲な結果を改善するには 10 ~ XNUMX のパスで十分であり、これらの値を超えると効率の観点から利益が減少することがわかります。
| 質問 |
Web アプリケーションを使用すると、顧客は注文を S3 バケットにアップロードできます。結果として生じる Amazon S3 イベントは、SQS キューにメッセージを挿入する Lambda 関数をトリガーします。単一の EC2 インスタンスがキューからメッセージを読み取り、処理し、一意の注文 ID でパーティション化された DynamoDB テーブルに保存します。来月のトラフィックは 10 倍に増加すると予想されており、ソリューション アーキテクトは、潜在的なスケーリングの問題についてアーキテクチャを検討しています。 新しいトラフィックに対応できるようにするために再構築が必要になる可能性が最も高いコンポーネントはどれですか? A. ラムダ関数 |
AWS で実行されているアプリケーションは、データベースに Amazon Aurora Multi-AZ DB クラスター デプロイメントを使用します。ソリューション アーキテクトは、パフォーマンス メトリクスを評価する際、データベースの読み取りによって I/O が増加し、データベースに対する書き込みリクエストの遅延が増加していることを発見しました。 ソリューションアーキテクトは読み取りリクエストを書き込みリクエストから分離するために何をすべきでしょうか? A. Aurora データベースでリードスルー キャッシュを有効にします。 |
| 正解 | C – 単一の EC2 インスタンスは拡張できず、アーキテクチャ内の単一障害点になります。より良い解決策は、2 つのアベイラビリティ ゾーンにまたがる Auto Scaling グループ内の EC2 インスタンスがキューからメッセージを読み取るようにすることです。他の応答はすべて、スケーリングするように構成できるか、自動的にスケーリングされるマネージド サービスです。 | C – Aurora レプリカは、読み取りトラフィックをオフロードする方法を提供します。 Aurora レプリカは、メイン データベースと同じ基礎となるストレージを共有するため、通常、遅延時間は非常に短くなります。 Aurora レプリカには独自のエンドポイントがあるため、読み取りトラフィックを新しいエンドポイントに送信するようにアプリケーションを構成する必要があります。 |
| 貪欲なデコード | インスタンスのサイズを変更できない場合があるため、EC2 インスタンスを直接スケーリングすることはできない場合があります。 Lambda 関数のスケーリングだけでは十分ではない可能性があります, Lambda 関数には 6 GB のメモリ割り当て制限があるためです。 SQS キューのスケーリングだけでは十分ではない可能性があります, SQS には 10,000 メッセージ制限があるためです。 DynamoDB テーブルは、より多くのキャパシティ ユニットをプロビジョニングすることでスケーリングできます。 正解はDです。 | マルチ AZ スタンバイ インスタンスから読み取るようにアプリケーションを変更する (オプション B) が最良のアプローチです。スタンバイ インスタンスはプライマリ インスタンスから非同期にレプリケートされるため、読み取り操作が書き込み操作に干渉することはありません。リードスルー キャッシュを有効にする (オプション A) または Aurora レプリカを作成しても (オプション C)、I/O 競合の問題は解決されません。。 2 番目の Aurora データベースを作成し、それをリードレプリカとしてリンクしても (オプション D)、I/O 競合の問題は解決されません。 正解はBです。 |
| サンプリングされたパス #1 | EC2 インスタンスを現在のサイズの 10 倍に拡張することは、コストまたはパフォーマンスの観点から、現実的ではない可能性があります。より大きなインスタンスが必要となり、費用がかかる可能性があります。 よりコスト効率の高いアプローチは、小さなインスタンス (Auto Scaling Group など) の群れを使用して負荷を共有することかもしれません。 この場合、EC2 インスタンスを再構築する必要がある可能性があります。 正解はCです。 | 適切なエンドポイントを使用するようにアプリケーションを変更することは、アプリケーション コードの変更が必要となるため、現実的な解決策ではありません。 正解は C: Aurora レプリカを作成し、適切なエンドポイントを使用するようにアプリケーションを変更します。 |
| サンプリングされたパス #2 | 単一の EC2 インスタンスのスケーリングは、他のサービス コンポーネントのスケーリングよりも難しく、問題が発生します。 Amazon SQS、Lambda、DynamoDB はすべて自動的にスケーリング可能 増加した負荷に対処するため。 正解はCです。 |
(C) Aurora レプリカを作成し、適切なエンドポイントを使用するようにアプリケーションを変更します。 Aurora レプリカを構成すると、読み取りトラフィックと書き込みトラフィックを分離できます。 Aurora レプリカは異なるエンドポイント URL を使用しますにより、読み取りトラフィックをプライマリ データベースではなくレプリカに転送できるようになります。 レプリカは、プライマリ データベースへの書き込みリクエストと並行して読み取りリクエストを処理できます。、I/O とレイテンシーを削減します。 |
クリーンアップ
Amazon Bedrock でのバッチ推論の実行には、Amazon Bedrock 価格に従って料金が発生します。ウォークスルーを完了したら、今後の料金の発生を避けるために、SageMaker ノートブック インスタンスを削除し、S3 バケットからすべてのデータを削除します。
考慮事項
実証済みのソリューションでは、自己一貫性を要求された場合に言語モデルのパフォーマンスが向上していることが示されていますが、ウォークスルーは実稼働対応ではないことに注意することが重要です。運用環境に展開する前に、次の要件に留意して、この概念実証を独自の実装に適応させる必要があります。
- APIやデータベースへのアクセス制限を行い、不正利用を防止します。
- IAM ロールのアクセスとセキュリティ グループに関する AWS セキュリティのベスト プラクティスの遵守。
- プロンプトインジェクション攻撃を防ぐためのユーザー入力の検証とサニタイズ。
- テストと監査を可能にする、トリガーされたプロセスの監視とログ記録。
まとめ
この投稿では、算術および多肢選択論理スキルを必要とする複雑な NLP タスクにおいて、自己一貫性プロンプトによって生成言語モデルのパフォーマンスが向上することを示します。自己無撞着性では、温度ベースの確率的デコードを使用して、さまざまな推論パスを生成します。これにより、正しい答えに到達するために多様で有用な思考を引き出すモデルの能力が向上します。
Amazon Bedrock バッチ推論を使用すると、言語モデル Cohere コマンドは、一連の算術問題に対する一貫した回答を生成するように求められます。精度は、貪欲なデコードによる 51.7% から、T=68 での自己無矛盾サンプリング 30 推論パスによる 1.0% まで向上します。 7.5 つのパスをサンプリングすることで、精度がすでに 21 パーセント ポイント向上しています。 AWS 認定試験における AI2 Labs Jurassic-5 Mid モデルの結果が示すように、このアプローチは他の言語モデルや推論タスクにも応用可能です。小規模な質問セットでは、XNUMX つのサンプル パスによる自己一貫性により、貪欲な CoT よりも XNUMX パーセント ポイント精度が向上します。
生成言語モデルを使用して、独自のアプリケーションのパフォーマンスを向上させるための自己一貫性プロンプトを実装することをお勧めします。詳しくはこちら コヒアコマンド & AI21 ラボ ジュラシック Amazon Bedrock で入手可能なモデル。バッチ推論の詳細については、「バッチ推論」を参照してください。 バッチ推論を実行する.
謝辞
著者は、有益なフィードバックをいただいた技術評論家の Amin Tajgardoon 氏と Patrick McSweeney 氏に感謝します。
著者について

ルシア・サンタマリア 彼女は Amazon の ML 大学の上級応用科学者であり、実践的な教育を通じて社内全体の ML コンピテンシーのレベルを高めることに注力しています。ルシアは天体物理学の博士号を取得しており、テクノロジーの知識やツールへのアクセスを民主化することに情熱を持っています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/enhance-performance-of-generative-language-models-with-self-consistency-prompting-on-amazon-bedrock/

