One of the most common applications of generative AI and large language models (LLMs) is answering questions based on a specific external knowledge corpus. Retrieval-Augmented Generation (RAG) is a popular technique for building question answering systems that use an external knowledge base. To learn more, refer to Build a powerful question answering bot with Amazon SageMaker, Amazon OpenSearch Service, Streamlit, and LangChain.
Traditional RAG systems often struggle to provide satisfactory answers when users ask vague or ambiguous questions without providing sufficient context. This leads to unhelpful responses like “I don’t know” or incorrect, made-up answers provided by an LLM. In this post, we demonstrate a solution to improve the quality of answers in such use cases over traditional RAG systems by introducing an interactive clarification component using LangChain.
The key idea is to enable the RAG system to engage in a conversational dialogue with the user when the initial question is unclear. By asking clarifying questions, prompting the user for more details, and incorporating the new contextual information, the RAG system can gather the necessary context to provide an accurate, helpful answer—even from an ambiguous initial user query.
Solution overview
To demonstrate our solution, we have set up an Amazon Kendra index (composed of the AWS online documentation for Amazon Kendra, Amazon Lex, and Amazon SageMaker), a LangChain agent with an Amazon Bedrock LLM, and a straightforward Streamlit user interface.
Prerequisites
To run this demo in your AWS account, complete the following prerequisites:
- Clone the GitHub repository and follow the steps explained in the README.
- Deploy an Amazon Kendra index in your AWS account. You can use the following AWS CloudFormation template to create a new index or use an already running index. Deploying a new index might add additional charges to your bill, therefore we recommend deleting it if you don’t longer need it. Note that the data within the index will be sent to the selected Amazon Bedrock foundation model (FM).
- The LangChain agent relies on FMs available in Amazon Bedrock, but this can be adapted to any other LLM that LangChain supports.
- To experiment with the sample front end shared with the code, you can use Amazon SageMaker Studio to run a local deployment of the Streamlit app. Note that running this demo will incur some additional costs.
Implement the solution
Traditional RAG agents are often designed as follows. The agent has access to a tool that is used to retrieve documents relevant to a user query. The retrieved documents are then inserted into the LLM prompt, so that the agent can provide an answer based on the retrieved document snippets.
In this post, we implement an agent that has access to KendraRetrievalTool and derives relevant documents from the Amazon Kendra index and provides the answer given the retrieved context:
Refer to the GitHub repo for the full implementation code. To learn more about traditional RAG use cases, refer to Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart.
Consider the following example. A user asks “How many GPUs does my EC2 instance have?” As shown in the following screenshot, the agent is looking for the answer using KendraRetrievalTool. However, the agent realizes it doesn’t know which Amazon Elastic Compute Cloud (Amazon EC2) instance type the user is referencing and therefore provides no helpful answer to the user, leading to a poor customer experience.

To address this problem, we define an additional custom tool called AskHumanTool and provide it to the agent. The tool instructs an LLM to read the user question and ask a follow-up question to the user if KendraRetrievalTool is not able to return a good answer. This implies that the agent will now have two tools at its disposal:
This allows the agent to either refine the question or provide additional context that is needed to respond to the prompt. To guide the agent to use AskHumanTool for this purpose, we provide the following tool description to the LLM:
Use this tool if you don’t find an answer using the KendraRetrievalTool. Ask the human to clarify the question or provide the missing information. The input should be a question for the human.
As illustrated in the following screenshot, by using AskHumanTool, the agent is now identifying vague user questions and returning a follow-up question to the user asking to specify what EC2 instance type is being used.

After the user has specified the instance type, the agent is incorporating the additional answer into the context for the original question, before deriving the correct answer.
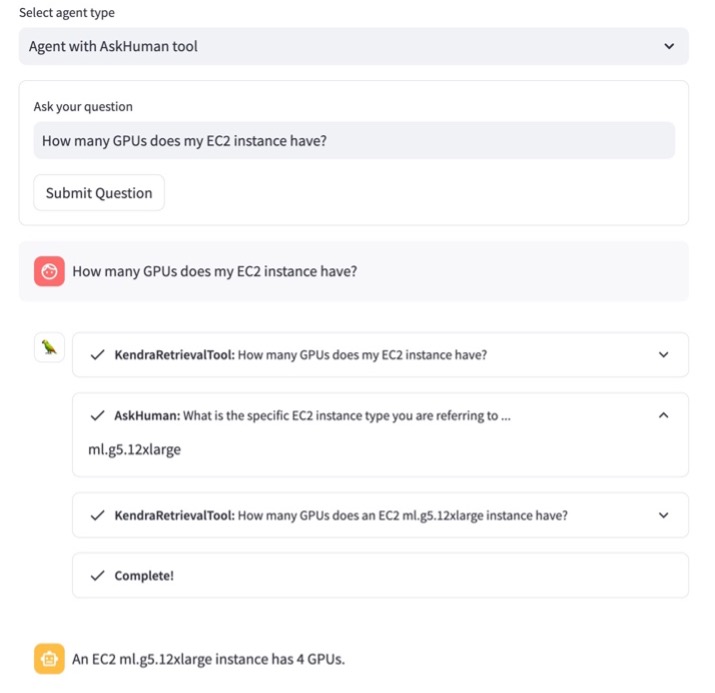
Note that the agent can now decide whether to use KendraRetrievalTool to retrieve the relevant documents or ask a clarifying question using AskHumanTool. The agent’s decision is based on whether it finds the document snippets inserted into the prompt sufficient to provide the final answer. This flexibility allows the RAG system to support different queries a user may submit, including both well-formulated and vague questions.
In our example, the full agent workflow is as follows:
- The user makes a request to the RAG app, asking “How many GPUs does my EC2 instance have?”
- The agent uses the LLM to decide what action to take: Find relevant information to answer the user’s request by calling the
KendraRetrievalTool. - The agent retrieves information from the Amazon Kendra index using the tool. The snippets from the retrieved documents are inserted into the agent prompt.
- The LLM (of the agent) derives that the retrieved documents from Amazon Kendra aren’t helpful or don’t contain enough context to provide an answer to the user’s request.
- The agent uses
AskHumanToolto formulate a follow-up question: “What is the specific EC2 instance type you are using? Knowing the instance type would help answer how many GPUs it has.” The user provides the answer “ml.g5.12xlarge,” and the agent callsKendraRetrievalToolagain, but this time adding the EC2 instance type into the search query. - After running through Steps 2–4 again, the agent derives a useful answer and sends it back to the user.
The following diagram illustrates this workflow.
The example described in this post illustrates how the addition of the custom AskHumanTool allows the agent to request clarifying details when needed. This can improve the reliability and accuracy of the responses, leading to a better customer experience in a growing number of RAG applications across different domains.
Clean up
To avoid incurring unnecessary costs, delete the Amazon Kendra index if you’re not using it anymore and shut down the SageMaker Studio instance if you used it to run the demo.
Conclusion
In this post, we showed how to enable a better customer experience for the users of a RAG system by adding a custom tool that enables the system to ask a user for a missing piece of information. This interactive conversational approach represents a promising direction for improving traditional RAG architectures. The ability to resolve vagueness through a dialogue can lead to delivering more satisfactory answers from a knowledge base.
Note that this approach is not limited to RAG use cases; you can use it in other generative AI use cases that depend on an agent at its core, where a custom AskHumanTool can be added.
For more information about using Amazon Kendra with generative AI, refer to Quickly build high-accuracy Generative AI applications on enterprise data using Amazon Kendra, LangChain, and large language models.
About the authors
 Antonia Wiebeler is a Data Scientist at the AWS Generative AI Innovation Center, where she enjoys building proofs of concept for customers. Her passion is exploring how generative AI can solve real-world problems and create value for customers. While she is not coding, she enjoys running and competing in triathlons.
Antonia Wiebeler is a Data Scientist at the AWS Generative AI Innovation Center, where she enjoys building proofs of concept for customers. Her passion is exploring how generative AI can solve real-world problems and create value for customers. While she is not coding, she enjoys running and competing in triathlons.
 Nikita Kozodoi is an Applied Scientist at the AWS Generative AI Innovation Center, where he develops ML solutions to solve customer problems across industries. In his role, he focuses on advancing generative AI to tackle real-world challenges. In his spare time, he loves playing beach volleyball and reading.
Nikita Kozodoi is an Applied Scientist at the AWS Generative AI Innovation Center, where he develops ML solutions to solve customer problems across industries. In his role, he focuses on advancing generative AI to tackle real-world challenges. In his spare time, he loves playing beach volleyball and reading.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/improve-llm-responses-in-rag-use-cases-by-interacting-with-the-user/

