This post is co-written with Amir Souchami and Fabian Szenkier from Unity.
Aura from Unity (formerly known as ironSource) is the market standard for creating rich device experiences that engage and retain customers. With a powerful set of solutions, Aura enables complete digital transformation, letting operators promote key services outside the store, directly on-device.
Amazon Redshift is a recommended service for online analytical processing (OLAP) workloads such as cloud data warehouses, data marts, and other analytical data stores. You can use simple SQL to analyze structured and semi-structured data, operational databases, and data lakes to deliver the best price/performance at any scale. The Amazon Redshift data sharing feature provides instant, granular, and high-performance access without data copies and data movement across multiple Redshift data warehouses in the same or different AWS accounts and across AWS Regions. Data sharing provides live access to data so that you always see the most up-to-date and consistent information as it’s updated in the data warehouse.
Amazon Redshift Serverless makes it straightforward to run and scale analytics in seconds without the need to set up and manage data warehouse clusters. Redshift Serverless automatically provisions and intelligently scales data warehouse capacity to deliver fast performance for even the most demanding and unpredictable workloads, and you pay only for what you use. You can load your data and start querying right away in the Amazon Redshift Query Editor or in your favorite business intelligence (BI) tool and continue to enjoy the best price/performance and familiar SQL features in an easy-to-use, zero administration environment.
In this post, we describe Aura’s successful and swift adoption of Redshift Serverless, which allowed them to optimize their overall bidding advertisement campaigns’ time to market from 24 hours to 2 hours. We explore why Aura chose this solution and what technological challenges it helped solve.
Aura’s initial data pipeline
Aura is a pioneer in using Redshift RA3 clusters with data sharing for extract, transform, and load (ETL) and BI workloads. One of Aura’s operations is bidding advertisement campaigns. These campaigns are optimized by using an AI-based bid process that requires running hundreds of analytical queries per campaign. These queries are run on data that resides in an RA3 provisioned Redshift cluster.
The integrated pipeline is comprised of various AWS services:
The following diagram illustrates this architecture.
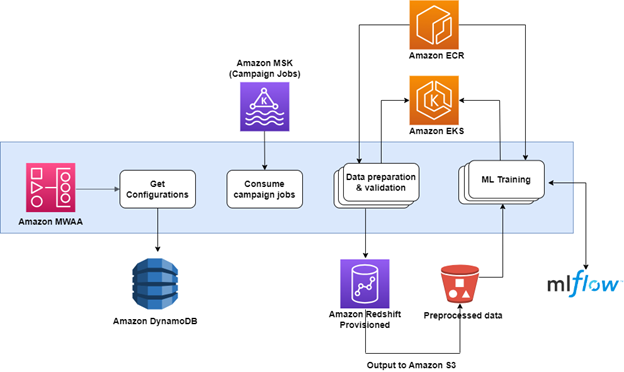
Challenges of the initial architecture
The queries for each campaign run in the following manner:
First, a preparation query filters and aggregates raw data, preparing it for the subsequent operation. This is followed by the main query, which carries out the logic according to the preparation query result set.
As the number of campaigns grew, Aura’s Data team was required to run hundreds of concurrent queries for each of these steps. Aura’s existing provisioned cluster was already heavily utilized with data ingestion, ETL, and BI workloads, so they were looking for cost-effective ways to isolate this workload with dedicated compute resources.
The team evaluated a variety of options, including unloading data to Amazon S3 and a multi-cluster architecture using data sharing and Redshift serverless. The team gravitated towards the multi-cluster architecture with data sharing, as it requires no query rewrite, allows for dedicated compute for this specific workload, avoids the need to duplicate or move data from the main cluster, and provides high concurrency and automatic scaling. Lastly, it’s billed in a pay-for-what-you-use model, and provisioning is straightforward and quick.
Proof of concept
After evaluating the options, Aura’s Data team decided to conduct a proof of concept using Redshift Serverless as a consumer of their main Redshift provisioned cluster, sharing just the relevant tables for running the required queries. Redshift Serverless measures data warehouse capacity in Redshift Processing Units (RPUs). A single RPU provides 16 GB of memory and a serverless endpoint can range from 8 RPU to 512 RPU.
Aura’s Data team started the proof of concept using a 256 RPU Redshift Serverless endpoint and gradually lowered the RPU to reduce costs while making sure the query runtime was below the required target.
Eventually, the team decided to use a 128 RPU (2 TB RAM) Redshift Serverless endpoint as the base RPU, while using the Redshift Serverless auto scaling feature, which allows hundreds of concurrent queries to run by automatically upscaling the RPU as needed.
Aura’s new solution with Redshift Serverless
After a successful proof of concept, the production setup included adding code to switch between the provisioned Redshift cluster and the Redshift Serverless endpoint. This was done using a configurable threshold based on the number of queries waiting to be processed in a specific MSK topic consumed at the beginning of the pipeline. Small-scale campaign queries would still run on the provisioned cluster, and large-scale queries would use the Redshift Serverless endpoint. The new solution uses an Amazon MWAA pipeline that fetches configuration information from a DynamoDB table, consumes jobs that represent ad campaigns, and then runs hundreds of EKS jobs triggered using EKSPodOperator. Each job runs the two serial queries (the preparation query followed by a main query, which outputs the results to Amazon S3). This happens several hundred times concurrently using Redshift Serverless compute resources.
Then the process initiates another set of EKSPodOperator operators to run the AI training code based on the data result that was saved on Amazon S3.
The following diagram illustrates the solution architecture.
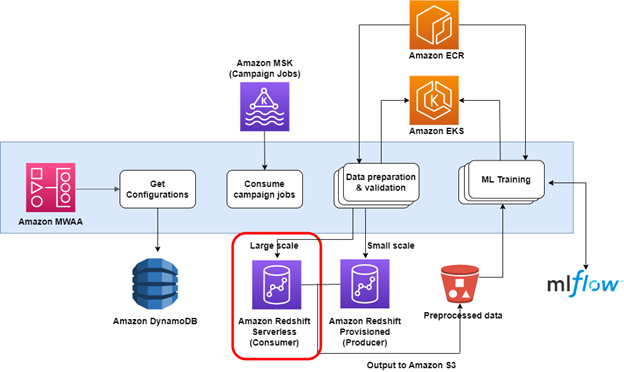
Outcome
The overall runtime of the pipeline was reduced from 24 hours to just 2 hours, a 12-times improvement. This integration of Redshift Serverless, coupled with data sharing, led to a 90% reduction in pipeline duration, negating the necessity for data duplication or query rewriting. Moreover, the introduction of a dedicated consumer as an exclusive compute resource significantly eased the load of the producer cluster, enabling running small-scale queries even faster.
“Redshift Serverless and data sharing enabled us to provision and scale our data warehouse capacity to deliver fast performance, high concurrency and handle challenging ML workloads with very minimal effort.”
– Amir Souchami, Aura’s Principal Technical Systems Architect.
Learnings
Aura’s Data team is highly focused on working in a cost-effective manner and has therefore implemented several cost controls in their Redshift Serverless endpoint:
- Limit the overall spend by setting a maximum RPU-hour usage limit (per day, week, month) for the workgroup. Aura configured that limit so when it is reached, Amazon Redshift will send an alert to the relevant Amazon Redshift administrator team. This feature also allows writing an entry to a system table and even turning off user queries.
- Use a maximum RPU configuration, which defines the upper limit of compute resources that Redshift Serverless can use at any given time. When the maximum RPU limit is set for the workgroup, Redshift Serverless scales within that limit to continue to run the workload.
- Implement query monitoring rules that prevent wasteful resource utilization and runaway costs caused by poorly written queries.
Conclusion
A data warehouse is a crucial part of any modern data-driven company, enabling you to answer complex business questions and provide insights. The evolution of Amazon Redshift allowed Aura to quickly adapt to business requirements by combining data sharing between provisioned and Redshift Serverless data warehouses. Aura’s journey with Redshift Serverless underscores the vast potential of strategic tech integration in driving efficiency and operational excellence.
If Aura’s journey has sparked your interest and you are considering implementing a similar solution in your organization, here are some strategic steps to consider:
- Start by thoroughly understanding your organization’s data needs and how such a solution can address them.
- Reach out to AWS experts, who can provide you with guidance based on their own experiences. Consider engaging in seminars, workshops, or online forums that discuss these technologies. The following resources are recommended for getting started:
- An important part of this journey would be to implement a proof of concept. Such hands-on experience will provide valuable insights before moving to production.
Elevate your Redshift expertise. Already enjoying the power of Amazon Redshift? Enhance your data journey with the latest features and expert guidance. Reach out to your dedicated AWS account team for personalized support, discover cutting-edge capabilities, and unlock even greater value from your data with Amazon Redshift.
About the Authors
 Amir Souchami, Chief Architect of Aura from Unity, focusing on creating resilient and performant cloud systems and mobile apps at major scale.
Amir Souchami, Chief Architect of Aura from Unity, focusing on creating resilient and performant cloud systems and mobile apps at major scale.
 Fabian Szenkier is the ML and Big Data Architect at Aura by Unity, works on building modern AI/ML solutions and state of the art data engineering pipelines at scale.
Fabian Szenkier is the ML and Big Data Architect at Aura by Unity, works on building modern AI/ML solutions and state of the art data engineering pipelines at scale.
 Liat Tzur is a Senior Technical Account Manager at Amazon Web Services. She serves as the customer’s advocate and assists her customers in achieving cloud operational excellence in alignment with their business goals.
Liat Tzur is a Senior Technical Account Manager at Amazon Web Services. She serves as the customer’s advocate and assists her customers in achieving cloud operational excellence in alignment with their business goals.
 Adi Jabkowski is a Sr. Redshift Specialist in EMEA, part of the Worldwide Specialist Organization (WWSO) at AWS.
Adi Jabkowski is a Sr. Redshift Specialist in EMEA, part of the Worldwide Specialist Organization (WWSO) at AWS.
 Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. He is located in Israel and helps customers harness AWS analytical services to leverage data, gain insights, and derive value.
Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. He is located in Israel and helps customers harness AWS analytical services to leverage data, gain insights, and derive value.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/how-aura-from-unity-revolutionized-their-big-data-pipeline-with-amazon-redshift-serverless/

