Dieser Beitrag wurde gemeinsam mit Andries Engelbrecht und Scott Teal von Snowflake verfasst.
Unternehmen entwickeln sich ständig weiter und Datenverantwortliche stehen täglich vor der Herausforderung, neue Anforderungen zu erfüllen. Für viele Unternehmen und große Organisationen ist es nicht möglich, über eine einzige Verarbeitungs-Engine oder ein einziges Tool zu verfügen, um die verschiedenen Geschäftsanforderungen zu bewältigen. Sie verstehen, dass ein einheitlicher Ansatz nicht mehr funktioniert, und erkennen den Wert der Einführung skalierbarer, flexibler Tools und offener Datenformate, um die Interoperabilität in einer modernen Datenarchitektur zu unterstützen und die Bereitstellung neuer Lösungen zu beschleunigen.
Kunden nutzen AWS und Snowflake, um speziell entwickelte Datenarchitekturen zu entwickeln, die die Leistung bieten, die für moderne Anwendungsfälle in den Bereichen Analyse und künstliche Intelligenz (KI) erforderlich ist. Die Implementierung dieser Lösungen erfordert den Datenaustausch zwischen speziell entwickelten Datenspeichern. Aus diesem Grund bieten Snowflake und AWS erweiterte Unterstützung für Apache Iceberg, um die Dateninteroperabilität zwischen Datendiensten zu ermöglichen und zu erleichtern.
Apache Iceberg ist ein Open-Source-Tabellenformat, das Zuverlässigkeit, Einfachheit und hohe Leistung für große Datensätze mit Transaktionsintegrität zwischen verschiedenen Verarbeitungs-Engines bietet. In diesem Beitrag besprechen wir Folgendes:
- Vorteile von Iceberg-Tabellen für Data Lakes
- Zwei Architekturmuster für die gemeinsame Nutzung von Iceberg-Tabellen zwischen AWS und Snowflake:
- Verwalten Sie Ihre Iceberg-Tische mit AWS-Kleber Datenkatalog
- Verwalten Sie Ihre Iceberg-Tische mit Snowflake
- Der Prozess der Konvertierung bestehender Data Lakes-Tabellen in Iceberg-Tabellen ohne Kopieren der Daten
Da Sie nun ein umfassendes Verständnis der Themen haben, wollen wir uns mit den einzelnen Themen im Detail befassen.
Vorteile von Apache Iceberg
Apache Iceberg ist ein verteiltes, von der Community betriebenes, von Apache 2.0 lizenziertes, 100 % Open-Source-Datentabellenformat, das die Datenverarbeitung für große, in Data Lakes gespeicherte Datensätze vereinfacht. Dateningenieure verwenden Apache Iceberg, weil es in jeder Größenordnung schnell, effizient und zuverlässig ist und Aufzeichnungen darüber führt, wie sich Datensätze im Laufe der Zeit ändern. Apache Iceberg bietet Integrationen mit gängigen Datenverarbeitungs-Frameworks wie Apache Spark, Apache Flink, Apache Hive, Presto und mehr.
Iceberg-Tabellen verwalten Metadaten, um große Dateisammlungen zu abstrahieren, und bieten Datenverwaltungsfunktionen wie Zeitreisen, Rollback, Datenkomprimierung und vollständige Schemaentwicklung, wodurch der Verwaltungsaufwand reduziert wird. Apache Iceberg wurde ursprünglich bei Netflix entwickelt, bevor es der Apache Software Foundation als Open Source zur Verfügung gestellt wurde. Es war ein unbeschriebenes Design zur Lösung häufiger Data-Lake-Herausforderungen wie User Experience, Zuverlässigkeit und Leistung, und wird jetzt von einer starken Entwicklergemeinschaft unterstützt, die sich darauf konzentriert, das Projekt kontinuierlich zu verbessern und neue Funktionen hinzuzufügen, echte Benutzerbedürfnisse zu erfüllen und ihnen Optionen zu bieten.
Transaktionale Data Lakes auf Basis von AWS und Snowflake
Snowflake bietet verschiedene Integrationen für Iceberg-Tabellen mit mehreren Speicheroptionen, darunter Amazon S3und mehrere Katalogoptionen, einschließlich AWS Glue-Datenkatalog und Schneeflocke. AWS bietet Integrationen für verschiedene AWS-Dienste auch mit Iceberg-Tabellen, einschließlich AWS Glue Data Catalog zur Verfolgung von Tabellenmetadaten. Die Kombination von Snowflake und AWS bietet Ihnen mehrere Optionen zum Aufbau eines transaktionalen Data Lake für analytische und andere Anwendungsfälle wie Datenfreigabe und Zusammenarbeit. Durch das Hinzufügen einer Metadatenebene zu Data Lakes erhalten Sie eine bessere Benutzererfahrung, eine vereinfachte Verwaltung sowie eine verbesserte Leistung und Zuverlässigkeit bei sehr großen Datensätzen.
Verwalten Sie Ihren Iceberg-Tisch mit AWS Glue
Sie können AWS Glue zum Erfassen, Katalogisieren, Transformieren und Verwalten der Daten verwenden Amazon Simple Storage-Service (Amazon S3). AWS Glue ist ein serverloser Datenintegrationsdienst, der es Ihnen ermöglicht, ETL-Pipelines (Extrahieren, Transformieren und Laden) visuell zu erstellen, auszuführen und zu überwachen, um Daten im Iceberg-Format in Ihre Data Lakes zu laden. Mit AWS Glue können Sie mehr als 70 verschiedene Datenquellen entdecken und mit ihnen verbinden und Ihre Daten in einem zentralen Datenkatalog verwalten. Snowflake lässt sich in AWS Glue Data Catalog integrieren um für analytische Abfragen auf den Iceberg-Tabellenkatalog und die Dateien auf Amazon S3 zuzugreifen. Dies verbessert die Leistung und die Rechenkosten im Vergleich zu erheblich externe Tabellen auf Snowflake, da die zusätzlichen Metadaten die Bereinigung in Abfrageplänen verbessern.
Sie können dieselbe Integration verwenden, um die Funktionen zur Datenfreigabe und Zusammenarbeit in Snowflake zu nutzen. Dies kann sehr leistungsstark sein, wenn Sie Daten in Amazon S3 haben und die gemeinsame Nutzung von Snowflake-Daten mit anderen Geschäftsbereichen, Partnern, Lieferanten oder Kunden aktivieren müssen.
Das folgende Architekturdiagramm bietet einen allgemeinen Überblick über dieses Muster.
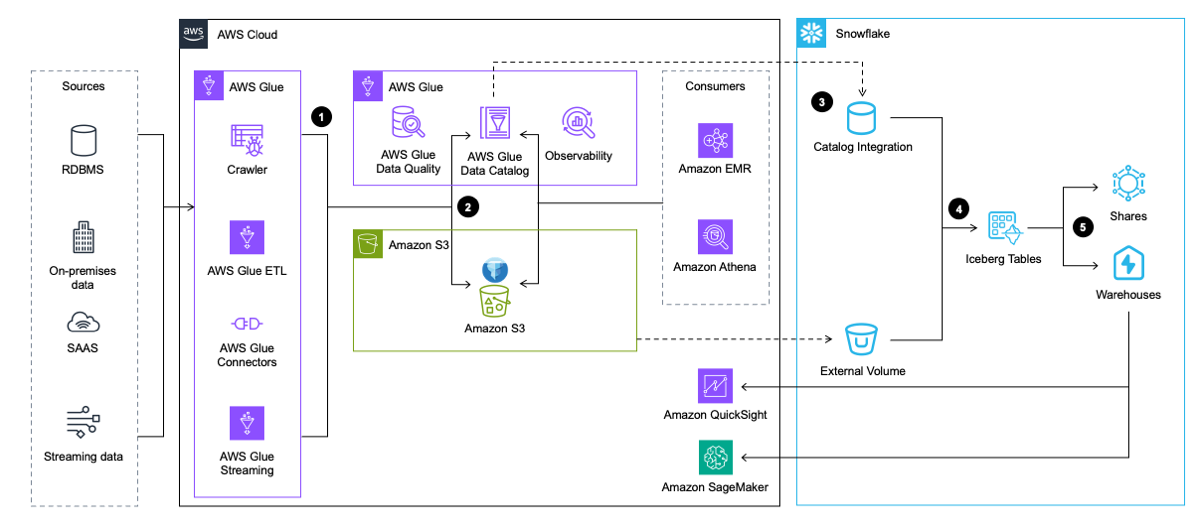
Der Workflow umfasst die folgenden Schritte:
- AWS Glue extrahiert Daten aus Anwendungen, Datenbanken und Streaming-Quellen. AWS Glue transformiert es dann und lädt es im Iceberg-Tabellenformat in den Data Lake in Amazon S3, während die Metadaten über die Iceberg-Tabelle in AWS Glue Data Catalog eingefügt und aktualisiert werden.
- Der AWS Glue-Crawler generiert und aktualisiert Iceberg-Tabellenmetadaten und speichert sie im AWS Glue Data Catalog für vorhandene Iceberg-Tabellen in einem S3-Data-Lake.
- Snowflake lässt sich in AWS Glue Data Catalog integrieren, um den Snapshot-Speicherort abzurufen.
- Im Falle einer Abfrage verwendet Snowflake den Snapshot-Speicherort aus AWS Glue Data Catalog, um Iceberg-Tabellendaten in Amazon S3 zu lesen.
- Snowflake kann Abfragen in den Tabellenformaten Iceberg und Snowflake durchführen. Du kannst Daten teilen für die Zusammenarbeit mit einem oder mehreren Konten in derselben Snowflake-Region. Sie können Daten auch in Snowflake für verwenden Visualisierung Verwendung von Amazon QuickSight, oder verwenden Sie es für Für Zwecke des maschinellen Lernens (ML) und der künstlichen Intelligenz (KI). mit Amazon Sage Maker.
Verwalten Sie Ihren Iceberg-Tisch mit Snowflake
Ein zweites Muster bietet ebenfalls Interoperabilität zwischen AWS und Snowflake, implementiert jedoch Data-Engineering-Pipelines für die Aufnahme und Transformation in Snowflake. Bei diesem Muster werden Daten von Snowflake durch Integrationen mit AWS-Diensten wie AWS Glue oder über andere Quellen wie Snowpipe in Iceberg-Tabellen geladen. Anschließend schreibt Snowflake die Daten im Iceberg-Format direkt in Amazon S3 für den Downstream-Zugriff durch Snowflake und verschiedene AWS-Dienste, und Snowflake verwaltet den Iceberg-Katalog, der Snapshot-Standorte tabellenübergreifend verfolgt, damit AWS-Dienste darauf zugreifen können.
Wie beim vorherigen Muster können Sie von Snowflake verwaltete Iceberg-Tabellen mit Snowflake-Datenfreigabe verwenden, aber Sie können S3 auch zum Teilen von Datensätzen verwenden, wenn eine Partei keinen Zugriff auf Snowflake hat.
Das folgende Architekturdiagramm bietet einen Überblick über dieses Muster mit von Snowflake verwalteten Iceberg-Tabellen.
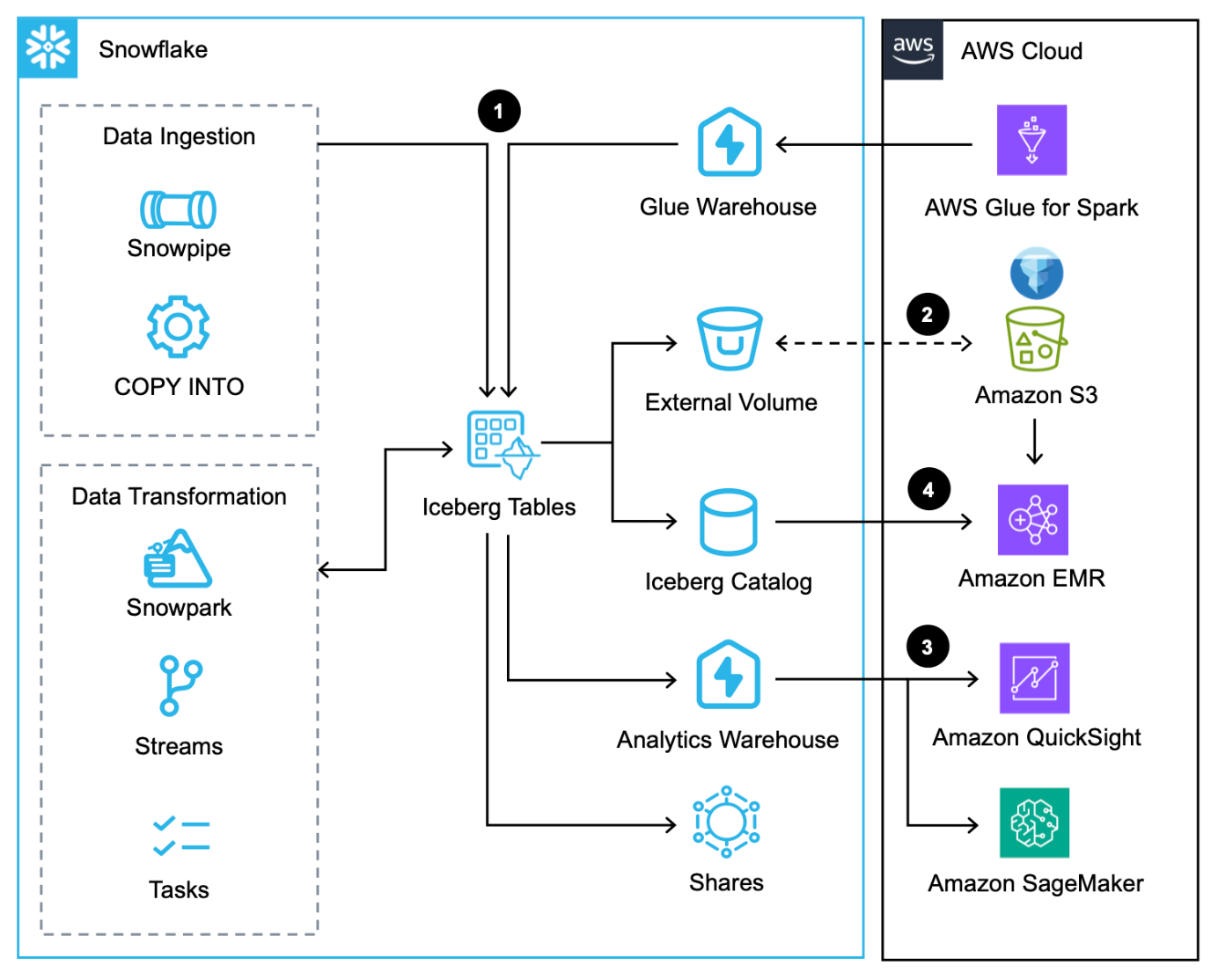
Dieser Workflow besteht aus den folgenden Schritten:
- Zusätzlich zum Laden von Daten über die COPY-Befehl, Schneepfeife und der native Snowflake-Connector für AWS Gluekönnen Sie Daten über die Snowflake integrieren Datenübertragung.
- Snowflake schreibt Iceberg-Tabellen in Amazon S3 und aktualisiert Metadaten automatisch bei jeder Transaktion.
- Iceberg-Tabellen in Amazon S3 werden von Snowflake mithilfe von Diensten wie QuickSight und SageMaker auf Analyse- und ML-Workloads abgefragt.
- Apache Spark-Dienste auf AWS können Greifen Sie über Snowflak auf Snapshot-Standorte zue über ein Snowflake Iceberg Catalog SDK und scannen Sie die Iceberg-Tabellendateien direkt in Amazon S3.
Lösungen vergleichen
Diese beiden Muster verdeutlichen die Optionen, die Data Personas heute zur Verfügung stehen, um ihre Dateninteroperabilität zwischen Snowflake und AWS mithilfe von Apache Iceberg zu maximieren. Doch welches Muster ist für Ihren Anwendungsfall ideal? Wenn Sie AWS Glue Data Catalog bereits verwenden und Snowflake nur für Leseabfragen benötigen, kann das erste Muster Snowflake mit AWS Glue und Amazon S3 integrieren, um Iceberg-Tabellen abzufragen. Wenn Sie AWS Glue Data Catalog noch nicht verwenden und Snowflake Lese- und Schreibvorgänge ausführen muss, ist das zweite Muster wahrscheinlich eine gute Lösung, die das Speichern und Zugreifen auf Daten von AWS ermöglicht.
In Anbetracht der Tatsache, dass Lese- und Schreibvorgänge wahrscheinlich auf Tabellenbasis und nicht auf der gesamten Datenarchitektur erfolgen, empfiehlt es sich, eine Kombination beider Muster zu verwenden.
Migrieren Sie vorhandene Data Lakes mit Apache Iceberg zu einem transaktionalen Data Lake
Sie können vorhandene Parquet-, ORC- und Avro-basierte Data-Lake-Tabellen auf Amazon S3 in das Iceberg-Format konvertieren, um die Vorteile der Transaktionsintegrität zu nutzen und gleichzeitig die Leistung und Benutzererfahrung zu verbessern. Es gibt mehrere Optionen für die Migration von Iceberg-Tabellen (SCHNAPPSCHUSS, WANDERN und DATEIEN HINZUFÜGEN) für die direkte Migration bestehender Data-Lake-Tabellen in das Iceberg-Format, das dem Neuschreiben aller zugrunde liegenden Datendateien vorzuziehen ist – ein kostspieliger und zeitaufwändiger Aufwand bei großen Datensätzen. In diesem Abschnitt konzentrieren wir uns auf ADD_FILES, da es für benutzerdefinierte Migrationen nützlich ist.
Für ADD_FILES-Optionen können Sie AWS Glue verwenden, um Iceberg-Metadaten und -Statistiken für eine vorhandene Data Lake-Tabelle zu generieren und neue Iceberg-Tabellen in AWS Glue Data Catalog für die zukünftige Verwendung zu erstellen, ohne die zugrunde liegenden Daten neu schreiben zu müssen. Anweisungen zum Generieren von Iceberg-Metadaten und -Statistiken mit AWS Glue finden Sie unter Migrieren Sie einen vorhandenen Data Lake mit Apache Iceberg zu einem Transaktions-Data Lake or Konvertieren Sie vorhandene Amazon S3 Data Lake-Tabellen mit AWS Glue in Snowflake Unmanaged Iceberg-Tabellen.
Diese Option erfordert, dass Sie die Datenpipelines anhalten, während Sie die Dateien in Iceberg-Tabellen konvertieren. Dies ist in AWS Glue ein unkomplizierter Vorgang, da nur das Ziel in eine Iceberg-Tabelle geändert werden muss.
Zusammenfassung
In diesem Beitrag haben Sie die beiden Architekturmuster für die Implementierung von Apache Iceberg in einem Data Lake für eine bessere Interoperabilität zwischen AWS und Snowflake gesehen. Wir haben auch Anleitungen zur Migration vorhandener Data Lake-Tabellen in das Iceberg-Format bereitgestellt.
Für e-news registrieren AWS Dev Day am 10. April um nicht nur Apache Iceberg, sondern auch Streaming-Datenpipelines praktisch auszuprobieren Amazon Data Firehose und Snowpipe-Streamingund generative KI-Anwendungen mit Streamlit in Schneeflocke und Amazonas Grundgestein.
Über die Autoren
 Andries Engelbrecht ist Principal Partner Solutions Architect bei Snowflake und arbeitet mit strategischen Partnern zusammen. Er arbeitet aktiv mit strategischen Partnern wie AWS zusammen, um Produkt- und Serviceintegrationen sowie die Entwicklung gemeinsamer Lösungen mit Partnern zu unterstützen. Andries verfügt über mehr als 20 Jahre Erfahrung im Bereich Daten und Analytik.
Andries Engelbrecht ist Principal Partner Solutions Architect bei Snowflake und arbeitet mit strategischen Partnern zusammen. Er arbeitet aktiv mit strategischen Partnern wie AWS zusammen, um Produkt- und Serviceintegrationen sowie die Entwicklung gemeinsamer Lösungen mit Partnern zu unterstützen. Andries verfügt über mehr als 20 Jahre Erfahrung im Bereich Daten und Analytik.
 Deenbandhu Prasad ist Senior Analytics Specialist bei AWS und auf Big-Data-Dienste spezialisiert. Es ist ihm eine Leidenschaft, Kunden beim Aufbau moderner Datenarchitekturen in der AWS Cloud zu unterstützen. Er hat Kunden jeder Größe bei der Implementierung von Datenmanagement-, Data Warehouse- und Data Lake-Lösungen unterstützt.
Deenbandhu Prasad ist Senior Analytics Specialist bei AWS und auf Big-Data-Dienste spezialisiert. Es ist ihm eine Leidenschaft, Kunden beim Aufbau moderner Datenarchitekturen in der AWS Cloud zu unterstützen. Er hat Kunden jeder Größe bei der Implementierung von Datenmanagement-, Data Warehouse- und Data Lake-Lösungen unterstützt.
 Brian Dolan kam 2012 nach seiner ersten Karriere als Marineflieger als Military Relations Manager zu Amazon. Im Jahr 2014 wechselte Brian zu Amazon Web Services, wo er kanadischen Kunden von Startups bis hin zu Unternehmen dabei half, die AWS Cloud zu erkunden. Zuletzt war Brian als Go-To-Market-Spezialist für Amazon DynamoDB und Amazon Keyspaces Mitglied des Non-Relational Business Development-Teams, bevor er 2022 als Go-To-Market-Spezialist für AWS Glue zur Analytics Worldwide Specialist Organization wechselte.
Brian Dolan kam 2012 nach seiner ersten Karriere als Marineflieger als Military Relations Manager zu Amazon. Im Jahr 2014 wechselte Brian zu Amazon Web Services, wo er kanadischen Kunden von Startups bis hin zu Unternehmen dabei half, die AWS Cloud zu erkunden. Zuletzt war Brian als Go-To-Market-Spezialist für Amazon DynamoDB und Amazon Keyspaces Mitglied des Non-Relational Business Development-Teams, bevor er 2022 als Go-To-Market-Spezialist für AWS Glue zur Analytics Worldwide Specialist Organization wechselte.
 Nidhi Gupta ist Senior Partner Solution Architect bei AWS. Sie verbringt ihre Tage damit, mit Kunden und Partnern zusammenzuarbeiten und architektonische Herausforderungen zu lösen. Ihre Leidenschaft gilt der Datenintegration und -orchestrierung, serverloser und Big-Data-Verarbeitung sowie maschinellem Lernen. Nidhi verfügt über umfangreiche Erfahrung in der Leitung des Architekturdesigns sowie der Produktionsfreigabe und -bereitstellung für Daten-Workloads.
Nidhi Gupta ist Senior Partner Solution Architect bei AWS. Sie verbringt ihre Tage damit, mit Kunden und Partnern zusammenzuarbeiten und architektonische Herausforderungen zu lösen. Ihre Leidenschaft gilt der Datenintegration und -orchestrierung, serverloser und Big-Data-Verarbeitung sowie maschinellem Lernen. Nidhi verfügt über umfangreiche Erfahrung in der Leitung des Architekturdesigns sowie der Produktionsfreigabe und -bereitstellung für Daten-Workloads.
 Scott Teal ist Produktmarketingleiter bei Snowflake und konzentriert sich auf Data Lakes, Speicher und Governance.
Scott Teal ist Produktmarketingleiter bei Snowflake und konzentriert sich auf Data Lakes, Speicher und Governance.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-your-data-lake-with-amazon-s3-aws-glue-and-snowflake/

