Unternehmen müssen häufig große Datenmengen verwalten, die außerordentlich schnell wachsen. Gleichzeitig müssen sie die Betriebskosten optimieren, um den Wert dieser Daten für zeitnahe Erkenntnisse zu erschließen und dies mit einer konsistenten Leistung zu tun.
Bei diesem massiven Datenwachstum kann die Datenvermehrung in Ihren Datenspeichern, Data Warehouses und Data Lakes gleichermaßen zu einer Herausforderung werden. Mit einem Moderne Datenarchitektur Auf AWS können Sie schnell skalierbare Data Lakes aufbauen. Nutzen Sie eine breite und umfassende Sammlung speziell entwickelter Datendienste. Gewährleistung der Compliance durch einheitlichen Datenzugriff, Sicherheit und Governance; Skalieren Sie Ihre Systeme kostengünstig, ohne Kompromisse bei der Leistung einzugehen. und teilen Sie Daten problemlos über Unternehmensgrenzen hinweg, sodass Sie schnell und flexibel Entscheidungen in großem Maßstab treffen können.
Sie können alle Ihre Daten aus verschiedenen Silos übernehmen, diese Daten in Ihrem Data Lake aggregieren und direkt auf diesen Daten Analysen und maschinelles Lernen (ML) durchführen. Sie können auch andere Daten in speziell entwickelten Datenspeichern speichern, um sowohl strukturierte als auch unstrukturierte Daten zu analysieren und schnelle Erkenntnisse daraus zu gewinnen. Diese Datenbewegung kann von innen nach außen, von außen nach innen, um den Umfang herum oder bei der gemeinsamen Nutzung erfolgen.
Beispielsweise können Anwendungsprotokolle und Spuren von Webanwendungen direkt in einem Data Lake gesammelt werden, und ein Teil dieser Daten kann zur täglichen Analyse in einen Protokollanalysespeicher wie Amazon OpenSearch Service verschoben werden. Wir betrachten dieses Konzept als von innen nach außen Datenbewegung. Die im Amazon OpenSearch Service gespeicherten analysierten und aggregierten Daten können erneut in den Data Lake verschoben werden, um ML-Algorithmen für die nachgelagerte Nutzung durch Anwendungen auszuführen. Wir bezeichnen dieses Konzept als Außenseite nach innen Datenbewegung.
Schauen wir uns einen Beispielanwendungsfall an. Beispiel Corp. ist ein führendes Fortune-500-Unternehmen, das sich auf soziale Inhalte spezialisiert hat. Sie verfügen über Hunderte von Anwendungen, die Daten und Traces mit etwa 500 TB pro Tag generieren und die folgenden Kriterien erfüllen:
- Halten Sie Protokolle für eine schnelle Analyse 2 Tage lang bereit
- Halten Sie die Daten länger als 2 Tage in einer Speicherebene bereit, die mit einem angemessenen SLA für Analysen zur Verfügung gestellt werden kann
- Bewahren Sie die Daten über eine Woche hinaus 1 Tage lang im Kühlspeicher auf (zu Compliance-, Audit- und anderen Zwecken).
In den folgenden Abschnitten diskutieren wir drei mögliche Lösungen für ähnliche Anwendungsfälle:
- Abgestufter Speicher im Amazon OpenSearch Service und Datenlebenszyklusverwaltung
- On-Demand-Aufnahme von Protokollen mit Amazon OpenSearch-Aufnahme
- Amazon OpenSearch Service-Direktabfragen mit Amazon Simple Storage Service (Amazon S3)
Lösung 1: Tiered Storage im OpenSearch Service und Datenlebenszyklusmanagement
OpenSearch Service unterstützt drei integrierte Speicherebenen: Hot-, UltraWarm- und Cold-Storage. Basierend auf Ihren Datenaufbewahrungs-, Abfragelatenz- und Budgetanforderungen können Sie die beste Strategie wählen, um Kosten und Leistung in Einklang zu bringen. Sie können Daten auch zwischen verschiedenen Speicherebenen migrieren.
Hot Storage wird zur Indizierung und Aktualisierung verwendet und bietet den schnellsten Zugriff auf Daten. Hot Storage hat die Form eines Instanzspeichers oder Amazon Elastic Block-Shop (Amazon EBS)-Volumes, die an jeden Knoten angeschlossen sind.
UltraWarm bietet deutlich niedrigere Kosten pro GiB für schreibgeschützte Daten, die Sie seltener abfragen und nicht die gleiche Leistung wie Hot Storage benötigen. UltraWarm-Knoten nutzen Amazon S3 mit zugehörigen Caching-Lösungen, um die Leistung zu verbessern.
Cold Storage ist für die Speicherung selten aufgerufener oder historischer Daten optimiert. Wenn Sie Cold Storage verwenden, trennen Sie Ihre Indizes von der UltraWarm-Ebene, sodass auf sie nicht mehr zugegriffen werden kann. Sie können diese Indizes in wenigen Sekunden wieder anhängen, wenn Sie diese Daten abfragen müssen.
Weitere Einzelheiten zu Datenebenen innerhalb des OpenSearch-Dienstes finden Sie unter Wählen Sie im Amazon OpenSearch Service die richtige Speicherebene für Ihre Anforderungen.
Lösungsüberblick
Der Workflow für diese Lösung besteht aus den folgenden Schritten:
- Von den Anwendungen generierte eingehende Daten werden an einen S3-Datensee gestreamt.
- Daten werden mithilfe von in Amazon OpenSearch aufgenommen S3-SQS-Aufnahme nahezu in Echtzeit durch Benachrichtigungen, die auf den S3-Buckets eingerichtet sind.
- Nach 2 Tagen werden heiße Daten in den UltraWarm-Speicher migriert, um Leseabfragen zu unterstützen.
- Nach 5 Tagen in UltraWarm werden die Daten für 21 Tage in den Cold Storage migriert und von jeglicher Rechenleistung getrennt. Die Daten können bei Bedarf erneut an UltraWarm angehängt werden. Die Daten werden nach 21 Tagen aus dem Cold Storage gelöscht.
- Für einen einfachen Rollover werden tägliche Indizes verwaltet. Eine Index State Management (ISM)-Richtlinie automatisiert das Rollover oder Löschen von Indizes, die älter als 2 Tage sind.
Das Folgende ist ein Beispiel für eine ISM-Richtlinie, die Daten nach 2 Tagen in die UltraWarm-Ebene überträgt, nach 5 Tagen in den Cold Storage verschiebt und nach 21 Tagen aus dem Cold Storage löscht:
Überlegungen
UltraWarm verwendet ausgefeilte Caching-Techniken, um die Abfrage von Daten zu ermöglichen, auf die selten zugegriffen wird. Obwohl der Datenzugriff selten erfolgt, muss die Rechenleistung für UltraWarm-Knoten ständig ausgeführt werden, um diesen Zugriff zu ermöglichen.
Beim Betrieb im PB-Maßstab empfehlen wir zur Reduzierung des Wirkungsbereichs von Fehlern, die Implementierung in mehrere OpenSearch-Service-Domänen zu zerlegen, wenn mehrstufiger Speicher verwendet wird.
Die nächsten beiden Muster machen die Notwendigkeit einer lang laufenden Rechenleistung überflüssig und beschreiben On-Demand-Techniken, bei denen die Daten entweder bei Bedarf bereitgestellt oder direkt dort abgefragt werden, wo sie sich befinden.
Lösung 2: On-Demand-Aufnahme von Protokolldaten über OpenSearch Ingestion
OpenSearch Ingestion ist ein vollständig verwalteter Datensammler, der Protokoll- und Trace-Daten in Echtzeit an OpenSearch-Service-Domänen liefert. OpenSearch Ingestion wird vom Open-Source-Datenkollektor unterstützt Daten-Prepper. Data Prepper ist Teil der Open-Source-OpenSearch-Projekt.
Mit OpenSearch Ingestion können Sie Ihre Daten filtern, anreichern, transformieren und für die nachgelagerte Analyse und Visualisierung bereitstellen. Sie konfigurieren Ihre Datenproduzenten so, dass sie Daten an OpenSearch Ingestion senden. Die Daten werden automatisch an die von Ihnen angegebene Domäne oder Sammlung übermittelt. Sie können OpenSearch Ingestion auch so konfigurieren, dass Ihre Daten vor der Übermittlung transformiert werden. OpenSearch Ingestion ist serverlos, sodass Sie sich keine Gedanken über die Skalierung Ihrer Infrastruktur, den Betrieb Ihrer Ingestion-Flotte und das Patchen oder Aktualisieren der Software machen müssen.
Es gibt zwei Möglichkeiten, Amazon S3 als Quelle für die Datenverarbeitung mit OpenSearch Ingestion zu verwenden. Die erste Option ist die S3-SQS-Verarbeitung. Sie können die S3-SQS-Verarbeitung verwenden, wenn Sie Dateien nahezu in Echtzeit scannen möchten, nachdem sie in S3 geschrieben wurden. Es erfordert eine Amazon Simple Queue-Dienst (Amazon S3) Warteschlange, die empfängt S3-Ereignisbenachrichtigungen. Sie können S3-Buckets so konfigurieren, dass jedes Mal ein Ereignis ausgelöst wird, wenn ein Objekt zur Verarbeitung im Bucket gespeichert oder geändert wird.
Alternativ können Sie einen einmaligen oder wiederkehrenden geplanten Scan verwenden, um Daten in einem S3-Bucket stapelweise zu verarbeiten. Um einen geplanten Scan einzurichten, konfigurieren Sie Ihre Pipeline mit einem Zeitplan auf Scan-Ebene, der für alle Ihre S3-Buckets gilt, oder auf Bucket-Ebene. Sie können geplante Scans entweder mit einem einmaligen Scan oder einem wiederkehrenden Scan für die Stapelverarbeitung konfigurieren.
Eine umfassende Übersicht über die OpenSearch-Aufnahme finden Sie unter Amazon OpenSearch-Aufnahme. Weitere Informationen zum Open-Source-Projekt Data Prepper finden Sie unter Daten-Prepper.
Lösungsüberblick
Wir präsentieren ein Architekturmuster mit den folgenden Schlüsselkomponenten:
- Anwendungsprotokolle werden in den Data Lake gestreamt, wodurch mithilfe von OpenSearch Ingestion wichtige Daten nahezu in Echtzeit in den OpenSearch-Dienst eingespeist werden können S3-SQS-Verarbeitung.
- ISM-Richtlinien innerhalb des OpenSearch-Dienstes behandeln Index-Rollovers oder -Löschungen. Mit ISM-Richtlinien können Sie diese regelmäßigen Verwaltungsvorgänge automatisieren, indem Sie sie basierend auf Änderungen des Indexalters, der Indexgröße oder der Anzahl der Dokumente auslösen. Sie können beispielsweise eine Richtlinie definieren, die Ihren Index nach zwei Tagen in den schreibgeschützten Zustand versetzt und ihn dann nach einem festgelegten Zeitraum von drei Tagen löscht.
- Kalte Daten sind im S3-Datensee verfügbar und können bei Bedarf mithilfe von OpenSearch Ingestion in OpenSearch Service verarbeitet werden geplante Scans.
Das folgende Diagramm zeigt die Lösungsarchitektur.
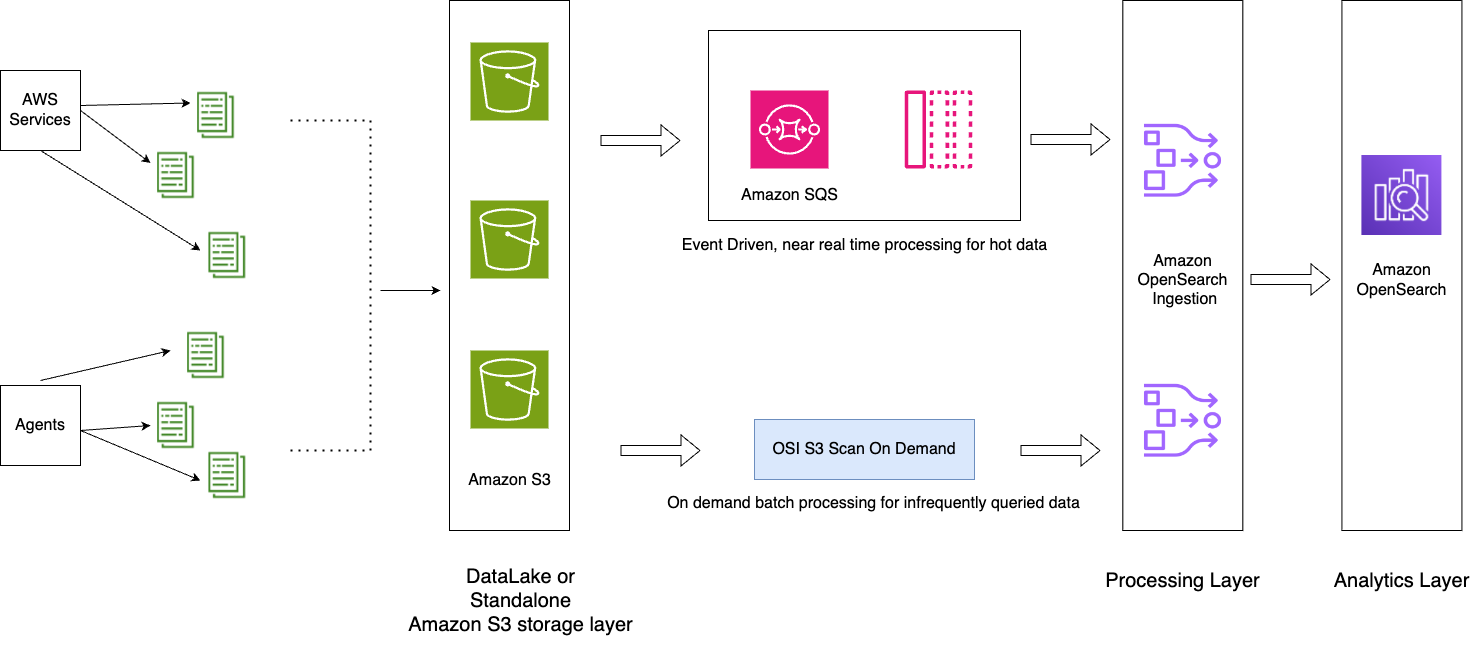
Der Workflow umfasst die folgenden Schritte:
- Eingehende Daten, die von den Anwendungen generiert werden, werden an den S3 Data Lake gestreamt.
- Für den aktuellen Tag werden die Daten mithilfe von S3-SQS nahezu in Echtzeit über in den S3-Buckets eingerichtete Benachrichtigungen in den OpenSearch-Dienst aufgenommen.
- Für einen einfachen Rollover werden tägliche Indizes verwaltet. Eine ISM-Richtlinie automatisiert das Rollover oder Löschen von Indizes, die älter als zwei Tage sind.
- Wenn eine Anfrage zur Analyse von Daten gestellt wird, die über 2 Tage hinausgehen und sich die Daten nicht in der UltraWarm-Stufe befinden, werden die Daten zwischen dem bestimmten Zeitfenster mithilfe der einmaligen Scanfunktion von Amazon S3 erfasst.
Wenn der heutige Tag beispielsweise der 10. Januar 2024 ist und Sie Daten vom 6. Januar 2024 in einem bestimmten Intervall zur Analyse benötigen, können Sie in Ihrer YAML-Konfiguration eine OpenSearch-Ingestion-Pipeline mit einem Amazon S3-Scan erstellen start_time und end_time um anzugeben, wann die Objekte im Bucket gescannt werden sollen:
Überlegungen
Nutzen Sie die Komprimierung
Daten in Amazon S3 können komprimiert werden, was Ihren gesamten Datenbedarf reduziert und zu erheblichen Kosteneinsparungen führt. Wenn Sie beispielsweise 15 PB rohe JSON-Anwendungsprotokolle pro Monat generieren, können Sie einen Komprimierungsmechanismus wie GZIP verwenden, der die Größe auf etwa 1 PB oder weniger reduzieren kann, was zu erheblichen Kosteneinsparungen führt.
Stoppen Sie die Pipeline, wenn möglich
OpenSearch Ingestion skaliert automatisch zwischen den für die Pipeline festgelegten minimalen und maximalen OCUs. Nachdem die Pipeline den Amazon S3-Scan für die in der Pipeline-Konfiguration angegebene angegebene Dauer abgeschlossen hat, wird die Pipeline zur kontinuierlichen Überwachung mit den minimalen OCUs weiter ausgeführt.
Für die On-Demand-Erfassung für vergangene Zeiträume, in denen Sie nicht damit rechnen, dass neue Objekte erstellt werden, sollten Sie die Verwendung unterstützter Pipeline-Metriken in Betracht ziehen, z recordsOut.count erschaffen Amazon CloudWatch Alarme, die die Pipeline stoppen können. Eine Liste der unterstützten Metriken finden Sie unter Überwachen von Pipeline-Metriken.
CloudWatch-Alarme führen eine Aktion aus, wenn eine CloudWatch-Metrik für einen bestimmten Zeitraum einen bestimmten Wert überschreitet. Beispielsweise möchten Sie möglicherweise überwachen recordsOut.count länger als 0 Minuten 5 sein, um eine Anfrage zu initiieren Stoppen Sie die Pipeline durch das AWS-Befehlszeilenschnittstelle (AWS CLI) oder API.
Lösung 3: OpenSearch Service-Direktabfragen mit Amazon S3
OpenSearch Service-Direktabfragen mit Amazon S3 (Vorschau) ist eine neue Möglichkeit, Betriebsprotokolle in Amazon S3 und S3 Data Lakes abzufragen, ohne zwischen Diensten wechseln zu müssen. Sie können jetzt selten abgefragte Daten in Cloud-Objektspeichern analysieren und gleichzeitig die betrieblichen Analyse- und Visualisierungsfunktionen von OpenSearch Service nutzen.
OpenSearch Service bietet direkte Abfragen mit Amazon S3 Zero-ETL-Integration Reduzieren Sie die betriebliche Komplexität durch die Duplizierung von Daten oder die Verwaltung mehrerer Analysetools, indem Sie Ihre Betriebsdaten direkt abfragen und so Kosten und Zeit bis zum Handeln reduzieren. Diese Zero-ETL-Integration ist im OpenSearch Service konfigurierbar, wo Sie verschiedene Protokolltypvorlagen, einschließlich vordefinierter Dashboards, nutzen und auf diesen Protokolltyp zugeschnittene Datenbeschleunigungen konfigurieren können. Vorlagen enthalten VPC-Flussprotokolle, Elastischer Lastausgleich Protokolle und NGINX-Protokolle sowie Beschleunigungen umfassen das Überspringen von Indizes, materialisierten Ansichten und abgedeckten Indizes.
Mit OpenSearch Service-Direktabfragen mit Amazon S3 können Sie komplexe Abfragen durchführen, die für die Sicherheitsforensik und Bedrohungsanalyse von entscheidender Bedeutung sind, und Daten über mehrere Datenquellen hinweg korrelieren, was Teams bei der Untersuchung von Dienstausfallzeiten und Sicherheitsereignissen unterstützt. Nachdem Sie eine Integration erstellt haben, können Sie mit der Abfrage Ihrer Daten direkt über OpenSearch-Dashboards oder die OpenSearch-API beginnen. Sie können Verbindungen prüfen, um sicherzustellen, dass sie skalierbar, kosteneffizient und sicher eingerichtet sind.
Direkte Abfragen vom OpenSearch Service an Amazon S3 verwenden Spark-Tabellen innerhalb des AWS-Kleber Datenkatalog. Nachdem die Tabelle in Ihrem AWS Glue-Metadatenkatalog katalogisiert wurde, können Sie über OpenSearch-Dashboards direkt Abfragen für Ihre Daten in Ihrem S3-Data-Lake ausführen.
Lösungsüberblick
Das folgende Diagramm zeigt die Lösungsarchitektur.
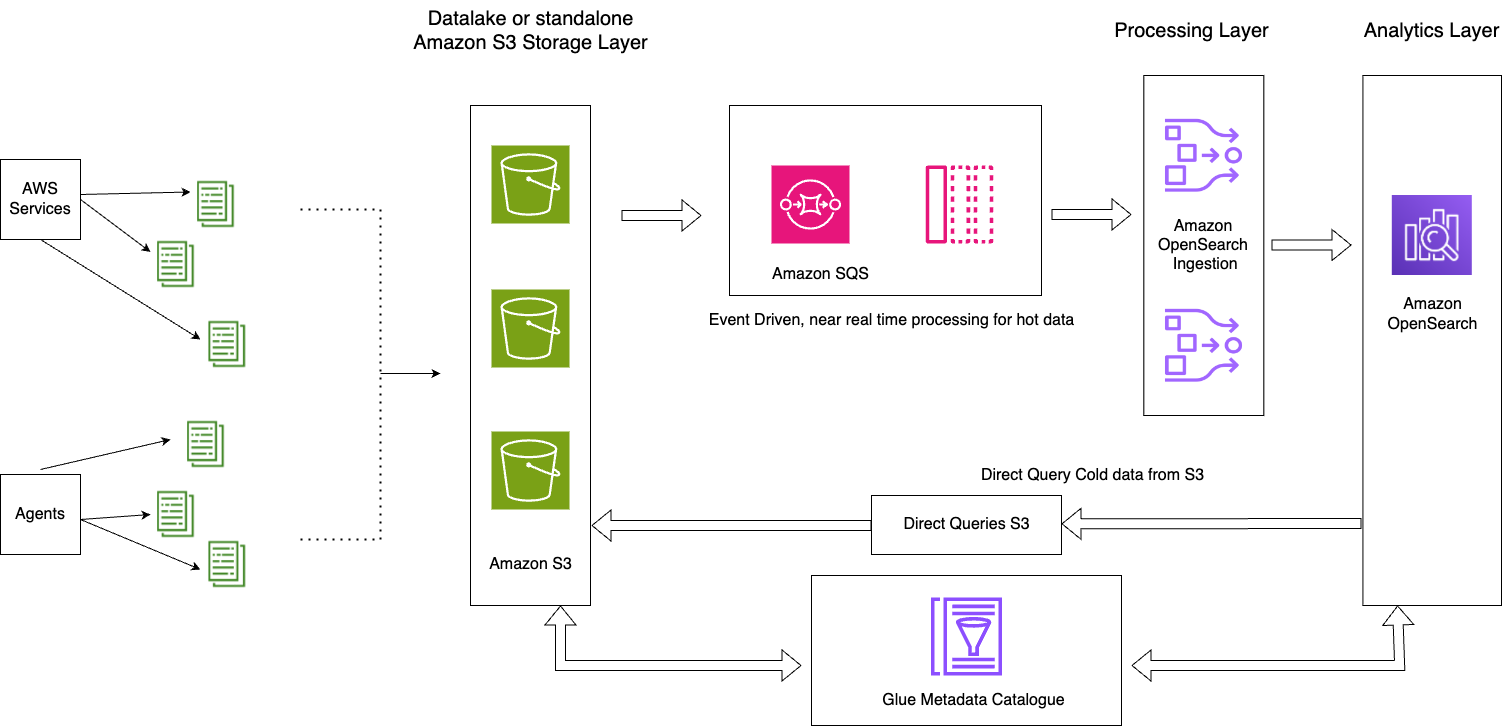
Diese Lösung besteht aus den folgenden Schlüsselkomponenten:
- Die aktuellen Daten für den aktuellen Tag werden über das ereignisgesteuerte Architekturmuster mithilfe der OpenSearch Ingestion S3-SQS-Verarbeitungsfunktion per Stream in OpenSearch Service-Domänen verarbeitet
- Der Hot-Data-Lebenszyklus wird durch ISM-Richtlinien verwaltet, die den täglichen Indizes zugeordnet sind
- Die kalten Daten befinden sich in Ihrem Amazon S3-Bucket und sind partitioniert und katalogisiert
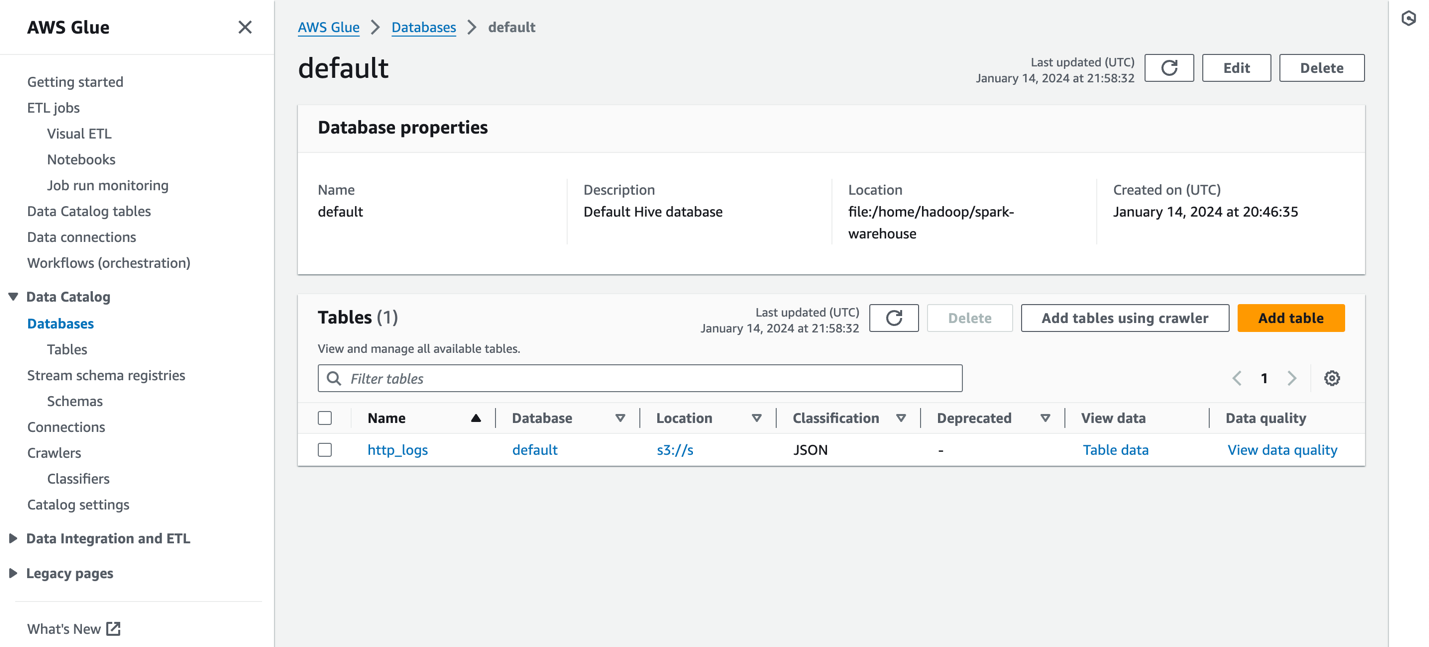
Der folgende Screenshot zeigt ein Beispiel http_logs Tabelle, die im AWS Glue-Metadatenkatalog katalogisiert ist. Detaillierte Schritte finden Sie unter Datenkatalog und Crawler in AWS Glue.
Bevor Sie eine Datenquelle erstellen, sollten Sie über eine OpenSearch Service-Domäne mit Version 2.11 oder höher und eine Ziel-S3-Tabelle im AWS Glue Data Catalog mit der entsprechenden Version verfügen AWS Identity and Access Management and (IAM)-Berechtigungen. IAM benötigt Zugriff auf die gewünschten S3-Buckets und verfügt über Lese- und Schreibzugriff auf den AWS Glue Data Catalog. Im Folgenden finden Sie eine Beispielrolle und eine Vertrauensrichtlinie mit den entsprechenden Berechtigungen für den Zugriff auf den AWS Glue-Datenkatalog über OpenSearch Service:
Im Folgenden finden Sie ein Beispiel für eine benutzerdefinierte Richtlinie mit Zugriff auf Amazon S3 und AWS Glue:
Um eine neue Datenquelle in der OpenSearch Service-Konsole zu erstellen, geben Sie den Namen Ihrer neuen Datenquelle an und geben Sie den Datenquellentyp als an Amazon S3 mit dem AWS Glue Data Catalogund wählen Sie die IAM-Rolle für Ihre Datenquelle aus.
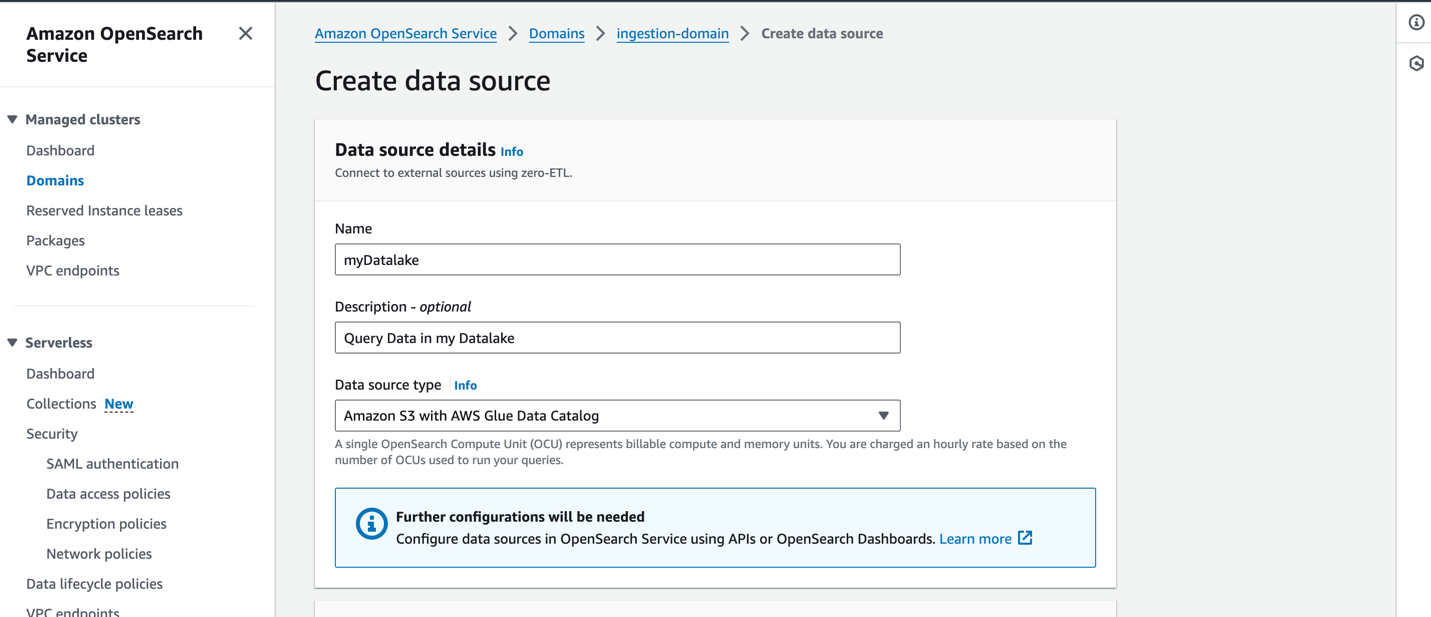
Nachdem Sie eine Datenquelle erstellt haben, können Sie zum OpenSearch-Dashboard der Domäne wechseln, mit dem Sie die Zugriffskontrolle konfigurieren, Tabellen definieren, protokolltypbasierte Dashboards für gängige Protokolltypen einrichten und Ihre Daten abfragen können.

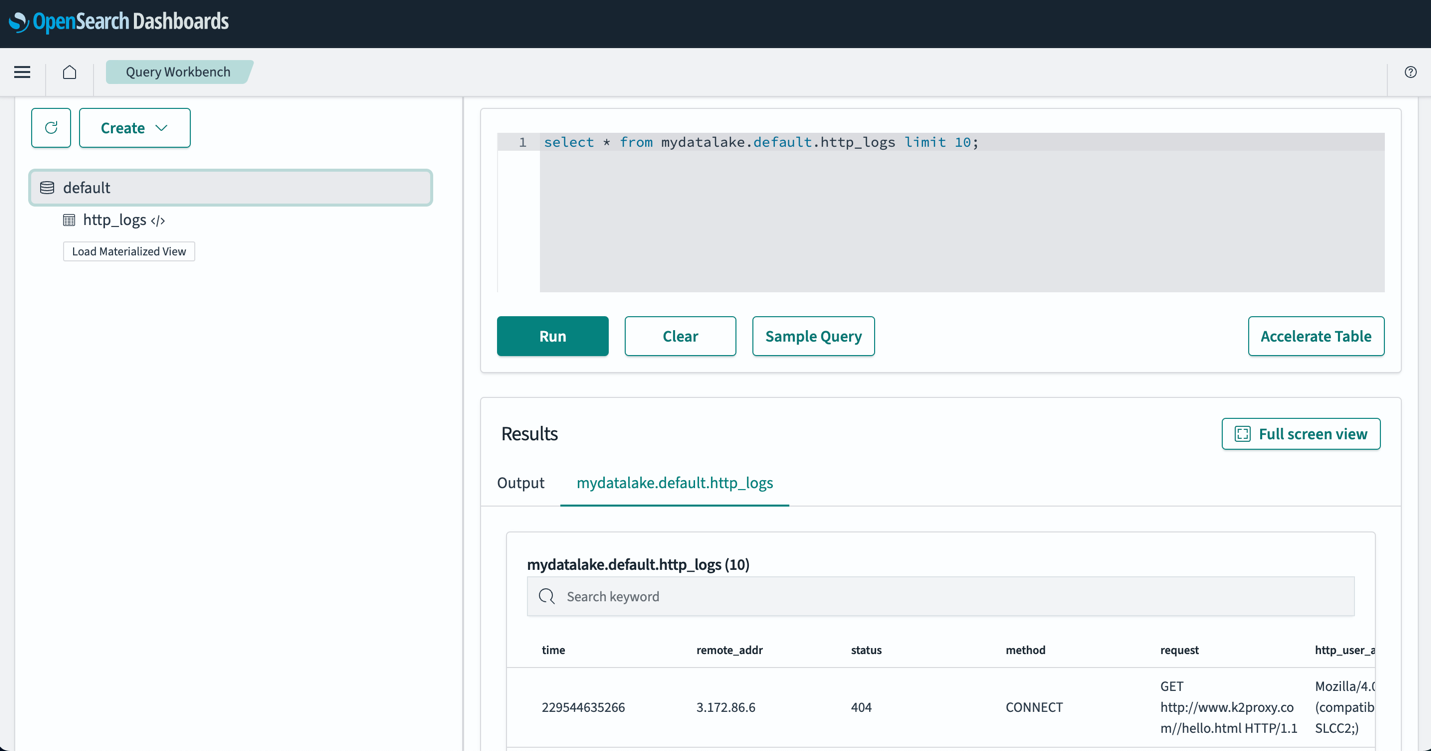
Nachdem Sie Ihre Tabellen eingerichtet haben, können Sie Ihre Daten in Ihrem S3-Datensee über OpenSearch-Dashboards abfragen. Sie können eine Beispiel-SQL-Abfrage für ausführen http_logs Tabelle, die Sie in den AWS Glue Data Catalog-Tabellen erstellt haben, wie im folgenden Screenshot gezeigt.
Best Practices
Nehmen Sie nur die Daten auf, die Sie benötigen
Arbeiten Sie ausgehend von Ihren Geschäftsanforderungen rückwärts und erstellen Sie die richtigen Datensätze, die Sie benötigen. Bewerten Sie, ob Sie die Aufnahme verrauschter Daten vermeiden und nur kuratierte, abgetastete oder aggregierte Daten aufnehmen können. Durch die Verwendung dieser bereinigten und kuratierten Datensätze können Sie die für die Aufnahme dieser Daten erforderlichen Rechen- und Speicherressourcen optimieren.
Reduzieren Sie die Datengröße vor der Aufnahme
Verwenden Sie beim Entwerfen Ihrer Datenaufnahmepipelines Strategien wie Komprimierung, Filterung und Aggregation, um die Größe der aufgenommenen Daten zu reduzieren. Dadurch können kleinere Datenmengen über das Netzwerk übertragen und in Ihrer Datenschicht gespeichert werden.
Zusammenfassung
In diesem Beitrag haben wir Lösungen besprochen, die Protokollanalysen im Petabyte-Bereich mithilfe von OpenSearch Service in einer modernen Datenarchitektur ermöglichen. Sie haben gelernt, wie Sie eine serverlose Aufnahmepipeline erstellen, um Protokolle an eine OpenSearch-Service-Domäne zu liefern, Indizes über ISM-Richtlinien zu verwalten, IAM-Berechtigungen für den Start der OpenSearch-Aufnahme zu konfigurieren und die Pipeline-Konfiguration für Daten in Ihrem Data Lake zu erstellen. Sie haben außerdem erfahren, wie Sie die OpenSearch Service-Direktabfragen mit der Amazon S3-Funktion (Vorschau) einrichten und verwenden, um Daten aus Ihrem Data Lake abzufragen.
Berücksichtigen Sie bei der Auswahl des richtigen Architekturmusters für Ihre Arbeitslasten bei der skalierten Nutzung von OpenSearch Service das Wachstum von Leistung, Latenz, Kosten und Datenvolumen im Laufe der Zeit, um die richtige Entscheidung zu treffen.
- Verwenden Sie eine mehrstufige Speicherarchitektur mit Richtlinien zur Indexstatusverwaltung, wenn Sie schnellen Zugriff auf Ihre aktuellen Daten benötigen und Kosten und Leistung mit UltraWarm-Knoten für schreibgeschützte Daten in Einklang bringen möchten.
- Verwenden Sie die On-Demand-Aufnahme Ihrer Daten in den OpenSearch-Dienst, wenn Sie Aufnahmelatenzzeiten tolerieren können, um Ihre Daten abzufragen, die nicht in Ihren Hot Nodes gespeichert sind. Sie können erhebliche Kosteneinsparungen erzielen, wenn Sie komprimierte Daten in Amazon S3 verwenden und Daten bei Bedarf in OpenSearch Service aufnehmen.
- Verwenden Sie die Direktabfrage mit der S3-Funktion, wenn Sie Ihre Betriebsprotokolle in Amazon S3 mit den umfangreichen Analyse- und Visualisierungsfunktionen von OpenSearch Service direkt analysieren möchten.
Als nächsten Schritt beziehen Sie sich auf die Amazon OpenSearch-Entwicklerhandbuch um Protokolle und Metrik-Pipelines zu untersuchen, die Sie verwenden können, um eine skalierbare Beobachtbarkeitslösung für Ihre Unternehmensanwendungen zu erstellen.
Über die Autoren
 Jagadish Kumar (Jag) ist Senior Specialist Solutions Architect bei AWS mit Schwerpunkt auf Amazon OpenSearch Service. Er hat eine große Leidenschaft für Datenarchitektur und hilft Kunden beim Aufbau maßstabsgetreuer Analyselösungen auf AWS.
Jagadish Kumar (Jag) ist Senior Specialist Solutions Architect bei AWS mit Schwerpunkt auf Amazon OpenSearch Service. Er hat eine große Leidenschaft für Datenarchitektur und hilft Kunden beim Aufbau maßstabsgetreuer Analyselösungen auf AWS.
 Muthu Pitchaimani ist Senior Specialist Solutions Architect bei Amazon OpenSearch Service. Er entwickelt umfangreiche Suchanwendungen und -lösungen. Muthu interessiert sich für die Themen Netzwerke und Sicherheit und hat seinen Sitz in Austin, Texas.
Muthu Pitchaimani ist Senior Specialist Solutions Architect bei Amazon OpenSearch Service. Er entwickelt umfangreiche Suchanwendungen und -lösungen. Muthu interessiert sich für die Themen Netzwerke und Sicherheit und hat seinen Sitz in Austin, Texas.
 Sam Selvan ist Principal Specialist Solution Architect bei Amazon OpenSearch Service.
Sam Selvan ist Principal Specialist Solution Architect bei Amazon OpenSearch Service.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/petabyte-scale-log-analytics-with-amazon-s3-amazon-opensearch-service-and-amazon-opensearch-ingestion/

