Apache Hive ist ein SQL-basiertes Data-Warehouse-System zur Verarbeitung stark verteilter Datensätze auf der Apache Hadoop-Plattform. Apache Hive besteht aus zwei Schlüsselkomponenten: der Hive SQL-Abfrage-Engine und dem Hive-Metastore (HMS). Der Hive-Metastore ist ein Repository mit Metadaten zu den SQL-Tabellen, wie Datenbanknamen, Tabellennamen, Schema, Serialisierungs- und Deserialisierungsinformationen, Datenspeicherort und Partitionsdetails jeder Tabelle. Apache Hive, Apache Spark, Presto und Trino können alle einen Hive-Metastore verwenden, um Metadaten zum Ausführen von Abfragen abzurufen. Der Hive-Metastore kann auf einem Apache Hadoop-Cluster gehostet werden oder durch eine relationale Datenbank gestützt werden, die außerhalb eines Hadoop-Clusters liegt. Obwohl der Hive-Metastore die Metadaten von Tabellen speichert, könnten sich die tatsächlichen Daten der Tabelle darin befinden Amazon Simple Storage-Service (Amazon S3), das Hadoop Distributed File System (HDFS) des Hadoop-Clusters oder alle anderen von Hive unterstützten Datenspeicher.
Da Apache Hive auf Apache Hadoop aufbaute, nutzen viele Unternehmen die Software seit der Zeit, als sie Hadoop für die Verarbeitung großer Datenmengen nutzten. Darüber hinaus bietet Hive Metastore eine flexible Integration mit vielen anderen Open-Source-Big-Data-Software wie Apache HBase, Apache Spark, Presto und Apache Impala. Daher sind Unternehmen dazu übergegangen, riesige Mengen an Metadaten ihrer strukturierten Datensätze im Hive-Metastore zu hosten. Ein Metastore ist ein wichtiger Teil eines Datensees und es ist wichtig, dass diese Informationen überall verfügbar sind, wo sie sich befinden. Allerdings lassen sich viele AWS-Analysedienste nicht nativ in den Hive-Metastore integrieren, weshalb Unternehmen ihre Daten in den Hive-Metastore migrieren mussten AWS-Kleber Data Catalog, um diese Dienste zu nutzen.
AWS Lake-Formation hat Unterstützung für gestartet Verwalten des Benutzerzugriffs auf Apache Hive-Metastores über eine föderierte AWS Glue-Verbindung. Bisher konnten Sie Lake Formation zum Verwalten von Benutzerberechtigungen verwenden AWS Glue-Datenkatalog Nur Ressourcen. Mit der Hive-Metastore-Verbindung von AWS Glue können Sie eine Verbindung zu einer Datenbank in einem Hive-Metastore außerhalb des Datenkatalogs herstellen, sie einer Verbunddatenbank im Datenkatalog zuordnen, Lake Formation-Berechtigungen auf die Hive-Datenbank und -Tabellen anwenden, sie mit anderen AWS-Konten teilen und sie mithilfe von Diensten wie … abfragen Amazonas Athena, Amazon Redshift-Spektrum, Amazon EMRund AWS Glue ETL (Extrahieren, Transformieren und Laden). Weitere Einzelheiten zur Funktionsweise der Hive-Metastore-Integration mit Lake Formation finden Sie unter Verwalten von Berechtigungen für Datensätze, die externe Metastores verwenden.
Zu den Anwendungsfällen für die Hive-Metastore-Integration mit dem Datenkatalog gehören die folgenden:
- Ein externer Apache Hive-Metastore, der für ältere Big-Data-Workloads wie lokale Hadoop-Cluster mit Daten in Amazon S3 verwendet wird
- Vorübergehende Amazon EMR-Workloads mit zugrunde liegenden Daten in Amazon S3 und dem Hive-Metastore Relationaler Amazon-Datenbankdienst (Amazon RDS)-Cluster.
In diesem Beitrag zeigen wir, wie man Lake Formation-Berechtigungen auf eine Hive-Metastore-Datenbank und -Tabellen anwendet und diese mit Athena abfragt. Wir veranschaulichen einen Anwendungsfall für die kontoübergreifende gemeinsame Nutzung, bei dem ein Lake Formation-Verwalter in Produzentenkonto A eine föderierte Hive-Datenbank und Tabellen mithilfe von LF-Tags für Verbraucherkonto B freigibt.
Lösungsüberblick
Produzentenkonto A hostet einen Apache Hive-Metastore in einem EMR-Cluster mit zugrunde liegenden Daten in Amazon S3. Wir starten den AWS Glue Hive-Metastore-Connector von AWS serverloses Anwendungs-Repository in Konto A und erstellen Sie die Hive-Metastore-Verbindung im Datenkatalog von Konto A. Nachdem wir die HMS-Verbindung erstellt haben, erstellen wir eine Datenbank im Datenkatalog von Konto A (die sogenannte Verbunddatenbank) und ordnen sie mithilfe der Verbindung einer Datenbank im Hive-Metastore zu. Die Tabellen aus der Hive-Datenbank sind dann für den Lake Formation-Administrator in Konto A zugänglich, genau wie alle anderen Tabellen im Datenkatalog. Der Administrator richtet weiterhin die Tag-basierte Zugriffskontrolle (LF-TBAC) von Lake Formation für die föderierte Hive-Datenbank ein und gibt sie an Konto B weiter.
Die Data Lake-Benutzer in Konto B greifen auf die Hive-Datenbank und die Tabellen von Konto A zu, genau wie beim Abfragen jeder anderen freigegebenen Data Catalog-Ressource mithilfe von Lake Formation-Berechtigungen.
Das folgende Diagramm veranschaulicht diese Architektur.

Die Lösung besteht aus Schritten in beiden Konten. Führen Sie in Konto A die folgenden Schritte aus:
- Erstellen Sie einen S3-Bucket zum Hosten der Beispieldaten.
- Starten Sie einen EMR 6.10-Cluster mit Hive. Laden Sie die Beispieldaten in den S3-Bucket herunter. Erstellen Sie im Hive-Metastore eine Datenbank und externe Tabellen, die auf die heruntergeladenen Beispieldaten verweisen.
- Stellen Sie die Anwendung bereit GlueDataCatalogFederation-HiveMetastore aus dem AWS Serverless Application Repository und konfigurieren Sie es für die Verwendung des Amazon EMR Hive-Metastores. Dadurch wird eine AWS Glue-Verbindung zum Hive-Metastore hergestellt, der auf der Lake Formation-Konsole angezeigt wird.
- Erstellen Sie mithilfe der Hive-Metastore-Verbindung eine Verbunddatenbank im AWS Glue Data Catalog.
- Erstellen Sie LF-Tags und verknüpfen Sie sie mit der Verbunddatenbank.
- Erteilen Sie Konto B Berechtigungen für die LF-Tags. Gewähren Sie Konto B mithilfe von LF-Tag-Ausdrücken Datenbank- und Tabellenberechtigungen.
Führen Sie in Konto B die folgenden Schritte aus:
- Lesen und akzeptieren Sie als Data Lake-Administrator die AWS-Ressourcenzugriffsmanager (AWS RAM) lädt für die Aktien von Konto A ein.
- Der Data-Lake-Administrator sieht dann die freigegebene Datenbank und die freigegebenen Tabellen. Der Administrator erstellt einen Ressourcenlink zur Datenbank und erteilt einem Datenanalysten in diesem Konto detaillierte Berechtigungen.
- Sowohl der Data-Lake-Administrator als auch der Datenanalyst fragen mit Athena die Hive-Tabellen ab, die ihnen zur Verfügung stehen.
Konto A hat die folgenden Personas:
- hmsblog-producersteward – Verwaltet den Data Lake im Produzentenkonto A
Konto B hat die folgenden Personas:
- hmsblog-consumersteward – Verwaltet den Data Lake im Consumer-Konto B
- hmsblog-Analyst – Ein Datenanalyst, der Zugriff auf ausgewählte Hive-Tabellen benötigt
Voraussetzungen:
Um dem Tutorial in diesem Beitrag folgen zu können, benötigen Sie Folgendes:
Einrichtung von Lake Formation und AWS CloudFormation in Konto A
Um die Einrichtung einfach zu halten, haben wir einen IAM-Administrator als Data Lake-Administrator registriert. Führen Sie die folgenden Schritte aus:
- Melden Sie sich in der AWS-Managementkonsole und wähle das
us-west-2Region. - Auf der Lake Formation-Konsole unter Berechtigungen Wählen Sie im Navigationsbereich Administrative Rollen und Aufgaben.
- Auswählen Verwalten Administratoren der Data Lake Administratoren .
- Der IAM-Benutzer und -Rollen, wählen Sie den IAM-Administratorbenutzer aus, als den Sie angemeldet sind, und wählen Sie Speichern.
- Auswählen
Stack starten So stellen Sie die CloudFormation-Vorlage bereit:

- Auswählen Weiter.
- Geben Sie einen Namen für den Stack ein und wählen Sie aus Weiter.
- Wählen Sie auf der nächsten Seite Weiter.
- Überprüfen Sie die Details auf der letzten Seite und wählen Sie Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen erstellt.
- Auswählen Erstellen.
Die Stapelerstellung dauert etwa 10 Minuten. Der Stack richtet das Setup des Produzentenkontos A wie folgt ein:
- Erstellt einen S3-Data-Lake-Bucket
- Registriert den Data Lake Bucket bei Lake Formation mit dem Katalogföderation aktivieren Flagge
- Startet einen EMR 6.10-Cluster mit Hive und führt zwei Schritte in Amazon EMR aus:
- Lädt die Beispieldaten vom öffentlichen S3-Bucket in den neu erstellten Bucket herunter
- Erstellt mithilfe eines HQL-Skripts eine Hive-Datenbank und vier externe Tabellen für die Daten in Amazon S3
- Erstellt einen IAM-Benutzer (
hmsblog-producersteward) und legt diesen Benutzer als Lake Formation-Administrator fest - Erstellt LF-Tags (
LFHiveBlogCampaignRole=Admin,Analyst)
Überprüfen Sie die CloudFormation-Stack-Ausgabe in Konto A
Um die Ausgabe Ihres CloudFormation-Stacks zu überprüfen, führen Sie die folgenden Schritte aus:
- Melden Sie sich bei der Konsole als der IAM-Administratorbenutzer an, den Sie zuvor zum Ausführen der CloudFormation-Vorlage verwendet haben.
- Öffnen Sie die CloudFormation-Konsole in einem anderen Browser-Tab.
- Überprüfen Sie den Stapel und notieren Sie ihn Ausgänge Registerkarte Details.

- Wählen Sie den Link unten Wert für
ProducerStewardCredentials.
Dies öffnet den AWS Secrets Manager Konsole.
- Auswählen
Wert abrufen und notieren Sie sich die Anmeldeinformationen von
hmsblog-producersteward.

Richten Sie eine föderierte AWS Glue-Verbindung in Konto A ein
Um eine föderierte AWS Glue-Verbindung einzurichten, führen Sie die folgenden Schritte aus:
- Öffnen Sie die AWS Serverless Application Repository-Konsole in einem anderen Browser-Tab.
- Wählen Sie im Navigationsbereich Verfügbare Anwendungen.
- Auswählen Apps anzeigen, die benutzerdefinierte IAM-Rollen oder Ressourcenrichtlinien erstellen.
- Geben Sie in der Suchleiste Kleber ein.
Hier werden verschiedene Anwendungen aufgelistet.
- Wählen Sie die genannte Anwendung aus
GlueDataCatalogFederation-HiveMetastore.
Dies öffnet den AWS Lambda Konsolenkonfigurationsseite für eine Lambda-Funktion, die den Connector-Anwendungscode ausführt.

Um die Lambda-Funktion zu konfigurieren, benötigen Sie Details zum EMR-Cluster, der vom CloudFormation-Stack gestartet wird.
- Öffnen Sie auf einer anderen Registerkarte Ihres Browsers die Amazon EMR-Konsole.
- Navigieren Sie zu dem Cluster, der für diesen Beitrag gestartet wurde, und notieren Sie die folgenden Details auf der Cluster-Detailseite:
- Öffentliches DNS des Primärknotens
- Subnetz-ID
- Sicherheitsgruppen-ID des Primärknotens


- Zurück auf der Lambda-Konfigurationsseite unter Überprüfen, konfigurieren und bereitstellenIn der Anwendungseinstellungen Geben Sie im Abschnitt die folgenden Details an. Behalten Sie den Rest als Standardwerte bei.
- Aussichten für GlueConnectionName, eingeben
hive-metastore-connection. - Aussichten für HiveMetastoreURIs eingeben
thrift://<Primary-node-public-DNS-of your-EMR>:9083. For example, thrift://ec2-54-70-203-146.us-west-2.compute.amazonaws.com:9083, Wobei9083ist der Hive-Metastore-Port im EMR-Cluster. - Aussichten für VPCSecurityGroupIdsGeben Sie die Sicherheitsgruppen-ID des EMR-Primärknotens ein.
- Aussichten für VPCSubnetIdsGeben Sie die Subnetz-ID des EMR-Clusters ein.
- Aussichten für GlueConnectionName, eingeben
- Auswählen
Deploy.

Warte auf die Erstellen abgeschlossen Status der Lambda-Anwendung. Sie können die Details der Lambda-Anwendung auf der Lambda-Konsole überprüfen.

- Öffnen Sie die Lake Formation-Konsole und wählen Sie im Navigationsbereich Datenübertragung.
Das solltest du sehen hive-metastore-connection für Verbindungen.

- Wählen Sie es aus und überprüfen Sie die Details.

- Im Navigationsbereich unter Administrative Rollen und Aufgaben, wählen LF-Tags.
Sie sollten das erstellte LF-Tag sehen LFHiveBlogCampaignRole mit zwei Werten: Analyst und Admin.

- Auswählen LF-Tag-Berechtigungen und wählen Sie Gewähren.
- Auswählen
IAM-Benutzer und -Rollen und gib ein
hmsblog-producersteward. - Der LF-Tags, wählen LF-Tag hinzufügen.
- Enter
LFHiveBlogCampaignRolefür Wesentliche und gib einAnalystundAdminfür Werte. - Der BerechtigungenWählen Beschreiben und Partnerschaftsräte für LF-Tag-Berechtigungen und Erteilbare Berechtigungen.
- Auswählen
Gewähren.
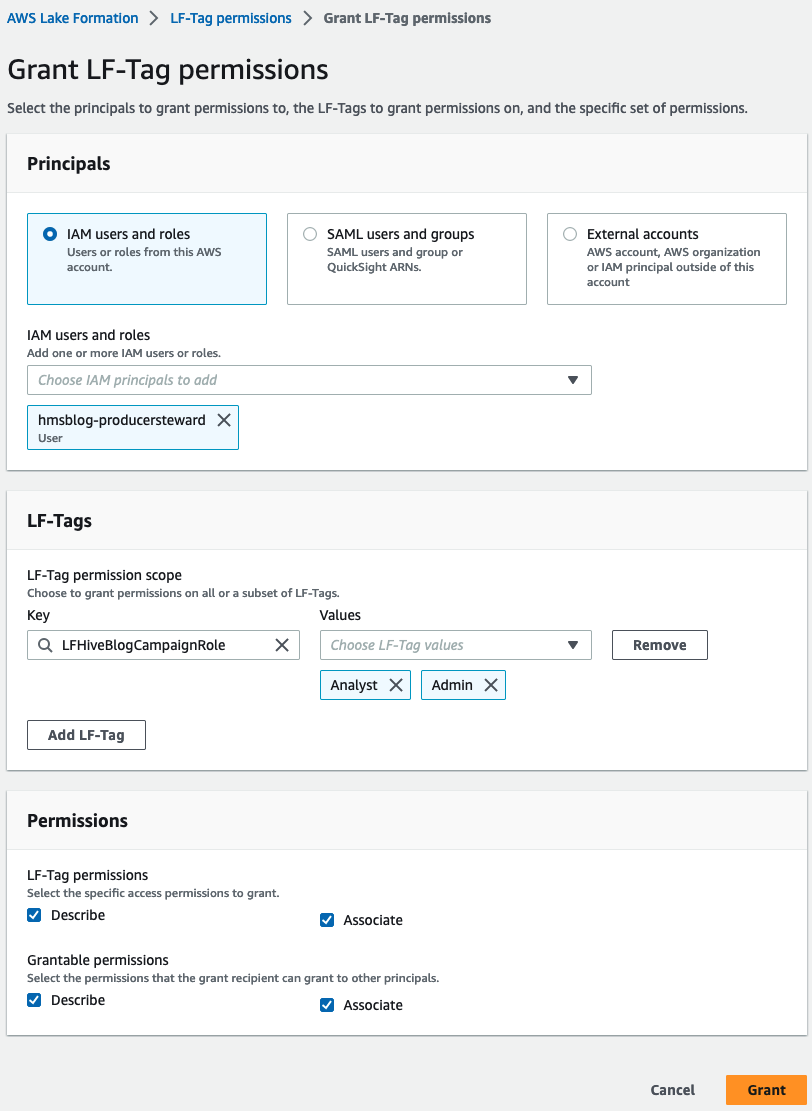
Dadurch erhält der Producer Steward LF-Tags-Berechtigungen.
- Melden Sie sich als IAM-Administratorbenutzer ab.
Gewähren Sie Lake Formation-Genehmigungen als Produzentenverwalter
Führen Sie die folgenden Schritte aus:
- Melden Sie sich bei der Konsole an als
hmsblog-producersteward, unter Verwendung der Anmeldeinformationen aus dem CloudFormation-Stack Output Tab, den Sie zuvor notiert haben. - Wählen Sie in der Lake Formation-Konsole im Navigationsbereich die Option Administrative Rollen und Aufgaben.
- Der Datenbankersteller, wählen Gewähren.

- Speichern
hmsblog-producerstewardals Datenbankersteller.
- Wählen Sie im Navigationsbereich Datenübertragung.
- Der Verbindungen, wählen Sie das
hive-metastore-connectionHyperlink.
- Auf dem Verbindungsdetails Seite wählen Datenbank erstellen.
- Aussichten für Name der Datenbank, eingeben
federated_emrhivedb.
Dies ist die Verbunddatenbank im lokalen AWS Glue-Datenkatalog, die auf eine Hive-Metastore-Datenbank verweist. Dabei handelt es sich um eine Eins-zu-eins-Zuordnung einer Datenbank im Datenkatalog zu einer Datenbank im externen Hive-Metastore.
- Aussichten für Datenbank-IDGeben Sie den Namen der Datenbank im EMR Hive-Metastore ein, der vom Hive SQL-Skript erstellt wurde. Für diesen Beitrag verwenden wir
emrhms_salesdb.
- Wählen Sie nach der Erstellung aus
federated_emrhivedbund wählen Sie Tabellen anzeigen.
Dadurch werden die Datenbank- und Tabellenmetadaten aus dem Hive-Metastore im EMR-Cluster abgerufen und die vom Hive-Skript erstellten Tabellen angezeigt.

Jetzt verknüpfen Sie die vom CloudFormation-Skript erstellten LF-Tags mit dieser Verbunddatenbank und geben sie mithilfe von LF-Tag-Ausdrücken für das Verbraucherkonto B frei.
- Wählen Sie im Navigationsbereich Datenbanken.
- Auswählen
federated_emrhivedbund auf der Aktionen Menü, wählen Sie LF-Tags bearbeiten. - Auswählen Neuen LF-Tag zuweisen.
- Enter
LFHiveBlogCampaignRolefür Zugewiesene Tasten undAdminfür Werte, Dann wählen Speichern.
- Wählen Sie im Navigationsbereich Data Lake-Berechtigungen.
- Auswählen Gewähren.
- Auswählen Externe Konten und geben Sie die B-Nummer des Verbraucherkontos ein.
- Der LF-Tags oder Katalogressourcen, wählen Von LF-Tags abgeglichene Ressource.
- Auswählen LF-Tag hinzufügen.
- Enter
LFHiveBlogCampaignRolefür Wesentliche undAdminfür Werte.
- Im Datenbankberechtigungen Abschnitt auswählen Beschreiben für Datenbankberechtigungen und Erteilbare Berechtigungen.
- Im Tabellenberechtigungen Abschnitt auswählen Auswählen und beschreiben für Tabellenberechtigungen und Erteilbare Berechtigungen.
- Auswählen
Gewähren.

- Im Navigationsbereich unter Administrative Rollen und Aufgaben, wählen LF-Tag-Berechtigungen.
- Auswählen Gewähren.
- Auswählen Externe Konten und geben Sie die Konto-ID des Verbraucherkontos B ein.
- Der LF-Tags, eingeben
LFHiveBlogCampaignRolefür Wesentliche und gib einAnalystundAdminfür Werte. - Der BerechtigungenWählen Beschreiben und Partnerschaftsräte für LF-Tag-Berechtigungen und Erteilbare Berechtigungen.
- Auswählen
Gewähren und überprüfen Sie, ob die erteilten LF-Tag-Berechtigungen korrekt angezeigt werden.

- Wählen Sie im Navigationsbereich Data Lake-Berechtigungen.
Sie können die Berechtigungen überprüfen und verifizieren, die Konto B gewährt wurden.
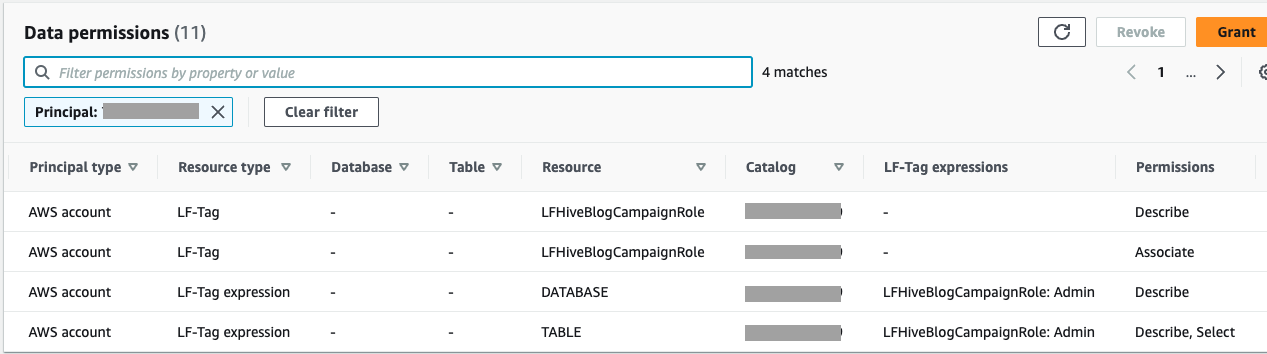
- Im Navigationsbereich unter Administrative Rollen und Aufgaben, wählen LF-Tag-Berechtigungen.
Sie können die Berechtigungen überprüfen und verifizieren, die Konto B gewährt wurden.

- Melden Sie sich von Konto A ab.
Einrichtung von Lake Formation und AWS CloudFormation in Konto B
Um die Einrichtung einfach zu halten, verwenden wir einen IAM-Administrator, der als Data Lake-Administrator registriert ist.
- Melden Sie sich in der AWS-Managementkonsole von Konto B und wählen Sie das aus
us-west-2Region. - Auf der Lake Formation-Konsole unter Berechtigungen Wählen Sie im Navigationsbereich Administrative Rollen und Aufgaben.
- Auswählen Administratoren verwalten der Data Lake Administratoren .
- Wählen Sie unter IAM-Benutzer und -Rollen den IAM-Administratorbenutzer aus, als den Sie angemeldet sind, und wählen Sie Speichern.
- Auswählen
Stack starten So stellen Sie die CloudFormation-Vorlage bereit:
- Auswählen Weiter.
- Geben Sie einen Namen für den Stack ein und wählen Sie aus Weiter.
- Wählen Sie auf der nächsten Seite Weiter.
- Überprüfen Sie die Details auf der letzten Seite und wählen Sie Ich erkenne an, dass AWS CloudFormation möglicherweise IAM-Ressourcen erstellt.
- Auswählen Erstellen.
Die Stapelerstellung sollte etwa 5 Minuten dauern. Der Stack richtet die Einrichtung des Produzentenkontos B wie folgt ein:
- Erstellt einen IAM-Benutzer
hmsblog-consumerstewardund legt diesen Benutzer als Lake Formation-Administrator fest - Erstellt einen weiteren IAM-Benutzer
hmsblog-analyst - Erstellt einen S3-Data-Lake-Bucket zum Speichern von Athena-Abfrageergebnissen
ListBucketund schreiben Sie Objektberechtigungen für beidehmsblog-consumerstewardundhmsblog-analyst
Notieren Sie sich die Stack-Ausgabedetails.

Akzeptieren Sie Ressourcenanteile in Konto B
Melden Sie sich bei der Konsole an als hmsblog-consumersteward und führen Sie die folgenden Schritte aus:
- Navigieren Sie in der AWS CloudFormation-Konsole zum Stack Ausgänge Tab.
- Wählen Sie den Link für
ConsumerStewardCredentialszur Secrets Manager-Konsole umgeleitet werden. - Wählen Sie in der Secrets Manager-Konsole aus Geheime Werte abrufen und kopieren Sie das Passwort für den Consumer-Steward-Benutzer.
- Verwenden Sie das
ConsoleIAMLoginURLWert aus der CloudFormation-Vorlage Output um sich mit dem Benutzernamen „Consumer Steward“ bei Konto B anzumeldenhmsblog-consumerstewardund das Passwort, das Sie aus Secrets Manager kopiert haben. - Öffnen Sie die AWS RAM-Konsole in einem anderen Browser-Tab.
- Im Navigationsbereich unter Mit mir geteilt, wählen Ressourcenfreigaben , um die ausstehenden Einladungen anzuzeigen.
Sie sollten zwei Einladungen zur Ressourcenfreigabe vom Produzentenkonto A sehen: eine für eine Freigabe auf Datenbankebene und eine für eine Freigabe auf Tabellenebene.

- Wählen Sie jeden Ressourcenfreigabe-Link aus, überprüfen Sie die Details und wählen Sie aus Akzeptieren.

Nachdem Sie die Einladungen angenommen haben, ändert sich der Status der Ressourcenfreigaben von Zu überprüfen zu Aktives.
- Öffnen Sie die Lake Formation-Konsole in einem anderen Browser-Tab.
- Wählen Sie im Navigationsbereich Datenbanken.
Sie sollten die freigegebene Datenbank sehen federated_emrhivedb vom Produzentenkonto A.
- Wählen Sie die Datenbank aus und wählen Sie Tabellen anzeigen um die Liste der in dieser Datenbank freigegebenen Tabellen zu überprüfen.

Sie sollten die vier Tabellen der Hive-Datenbank sehen, die auf dem EMR-Cluster im Produzentenkonto gehostet wird.

Gewähren Sie Berechtigungen für Konto B
Um Berechtigungen in Konto B zu erteilen, führen Sie die folgenden Schritte aus: hmsblog-consumersteward:
- Wählen Sie in der Lake Formation-Konsole im Navigationsbereich die Option Administrative Rollen und Aufgaben.
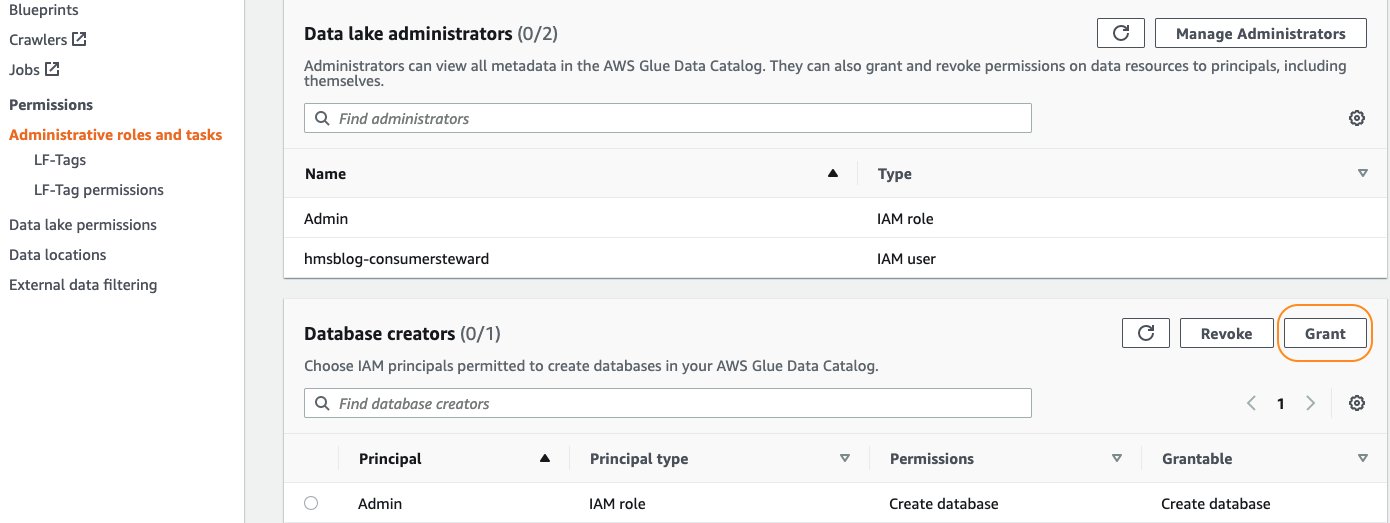
- Der Datenbankersteller, wählen Gewähren.
- Aussichten für IAM-Benutzer und -Rollen, eingeben
hmsblog-consumersteward. - Aussichten für KatalogberechtigungenWählen Datenbank erstellen.
- Auswählen
Gewähren.

Dies erlaubt hmsblog-consumersteward um eine Datenbankressourcenverknüpfung zu erstellen.
- Wählen Sie im Navigationsbereich Datenbanken.
- Auswählen
federated_emrhivedbund auf der Aktionen Menü, wählen Sie Ressourcenlink erstellen.
- Enter
rl_federatedhivedbfür Name des Ressourcenlinks und wählen Sie Erstellen.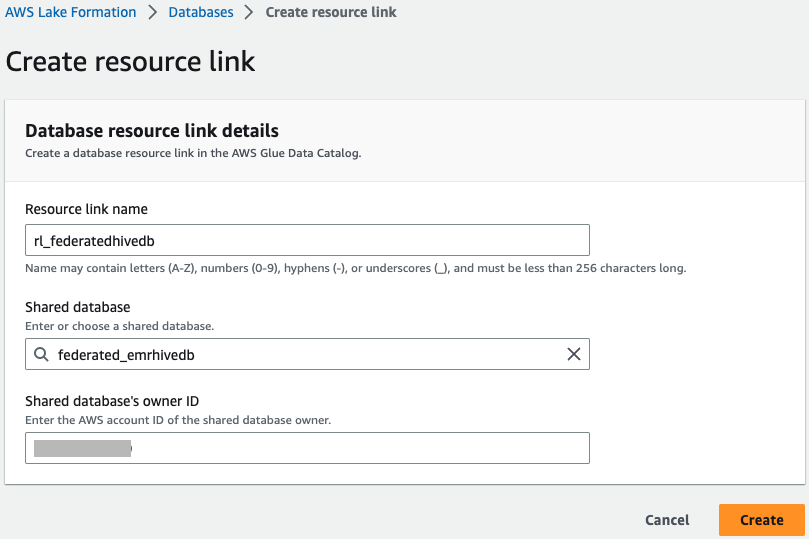
- Auswählen Datenbanken im Navigationsbereich.
- Wählen Sie den Ressourcenlink aus
rl_federatedhivedbund auf der Aktionen Menü, wählen Sie Gewähren. - Auswählen
hmsblog-analystfür IAM-Benutzer und -Rollen.
- Der Berechtigungen für RessourcenlinksWählen Beschreiben, Dann wählen Gewähren.
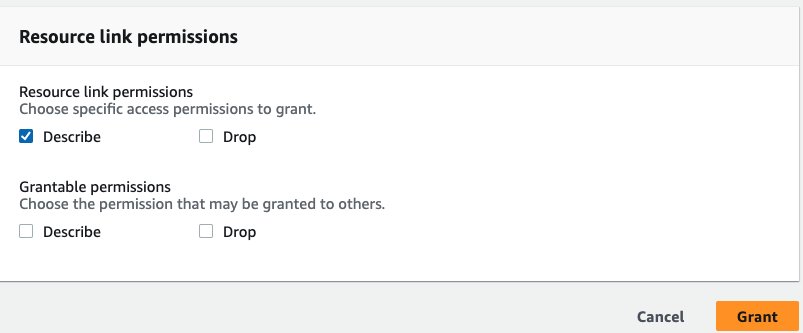
- Auswählen Datenbanken im Navigationsbereich.
- Wählen Sie den Ressourcenlink aus
rl_federatedhivedbund auf der Aktionen Menü, wählen Sie Grant hat das Ziel erreicht. - Auswählen
hmsblog-analystfür IAM-Benutzer und -Rollen. - Auswählen
hms_productcategoryundhms_supplierfür Tische.
- Aussichten für TabellenberechtigungenWählen Auswählen und Beschreiben, Dann wählen Gewähren.

- Wählen Sie im Navigationsbereich Data Lake-Berechtigungen und überprüfen Sie die erteilten Berechtigungen
hms-analyst.
Fragen Sie die Apache Hive-Datenbank des Herstellers vom Verbraucher Athena ab
Führen Sie die folgenden Schritte aus:
- Navigieren Sie in der Athena-Konsole zum Abfrageeditor.
- Auswählen
Einstellungen bearbeiten um die Ergebnisse der Athena-Abfrage zu konfigurieren.

- Durchsuchen Sie den S3-Bucket und wählen Sie ihn aus
hmsblog-athenaresults-<your-account-B>-us-west-2dass die CloudFormation-Vorlage erstellt wurde. - Auswählen
Speichern.

hmsblog-consumersteward hat Zugriff auf alle vier Tabellen unten federated_emrhivedb vom Produzentenkonto.
- Wählen Sie im Athena-Abfrageeditor die Datenbank aus
rl_federatedhivedbund führen Sie eine Abfrage für eine der Tabellen aus.
Sie konnten eine externe Apache Hive-Metastore-Datenbank des Produzentenkontos über die AWS Glue Data Catalog- und Lake Formation-Berechtigungen mithilfe von Athena vom Empfänger-Konsumentenkonto abfragen.
- Melden Sie sich von der Konsole ab als
hmsblog-consumerstewardund melden Sie sich erneut an alshmsblog-analyst. - Verwenden Sie dieselbe Methode wie zuvor erläutert, um die Anmeldeinformationen vom CloudFormation-Stack abzurufen Ausgänge Tab.
hmsblog-analyst verfügt über Describe-Berechtigungen für den Ressourcenlink und Zugriff auf zwei der vier Hive-Tabellen. Sie können überprüfen, ob Sie sie auf der Seite sehen Datenbanken und Tische Seiten auf der Lake Formation-Konsole.


Auf der Athena-Konsole konfigurieren Sie nun den Athena-Abfrageergebnis-Bucket, ähnlich wie Sie ihn konfiguriert haben hmsblog-consumersteward.
- Wählen Sie im Abfrageeditor Einstellungen bearbeiten.
- Durchsuchen Sie den S3-Bucket und wählen Sie ihn aus
hmsblog-athenaresults-<your-account-B>-us-west-2dass die CloudFormation-Vorlage erstellt wurde. - Auswählen Speichern.
- Wählen Sie im Athena-Abfrageeditor die Datenbank aus
rl_federatedhivedbund führen Sie eine Abfrage für die beiden Tabellen aus.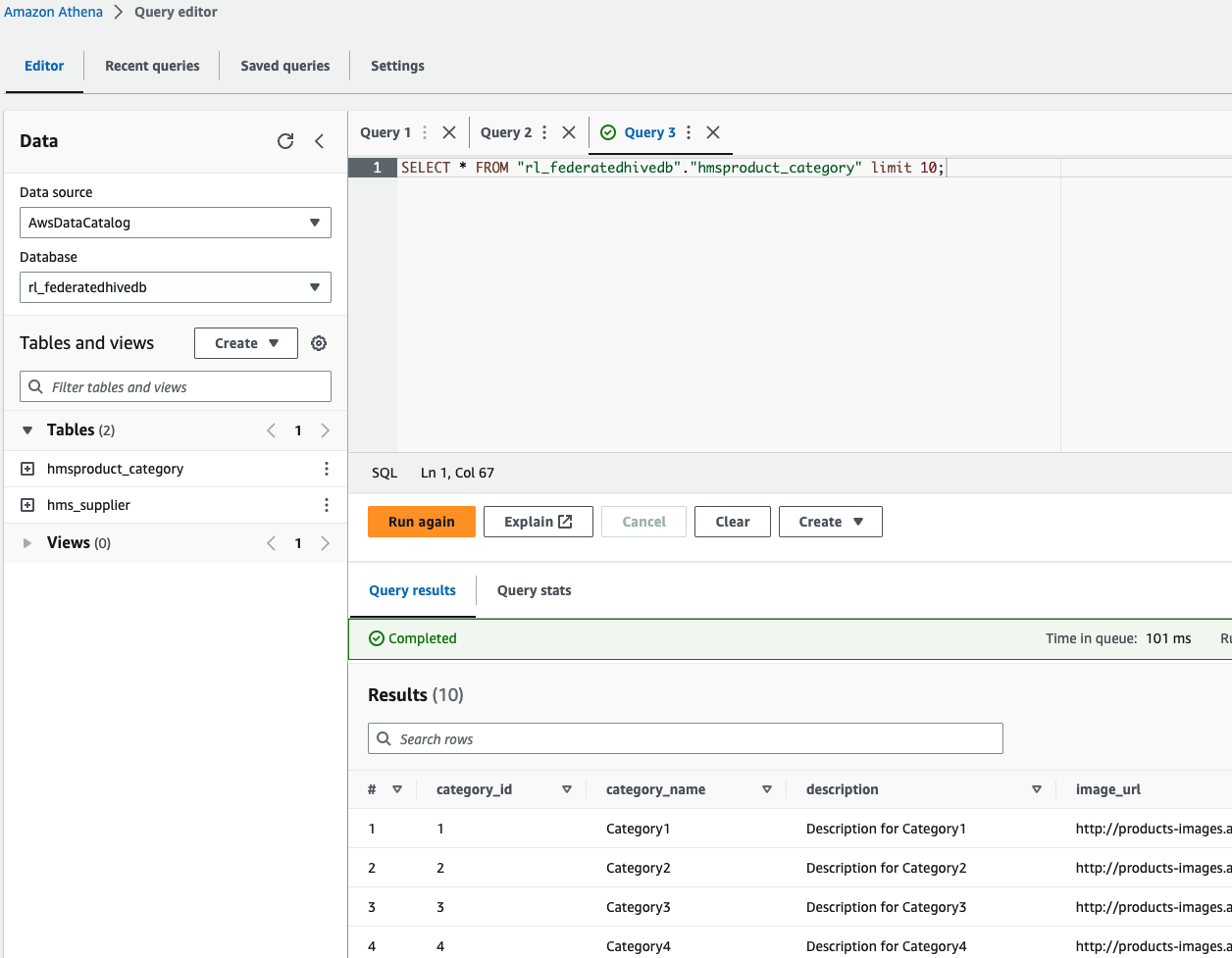
- Melden Sie sich von der Konsole ab als
hmsblog-analyst.
Sie konnten die Freigabe der externen Apache Hive-Metastore-Tabellen mithilfe von Lake Formation-Berechtigungen von einem Konto auf ein anderes beschränken und diese mithilfe von Athena abfragen. Sie können die Hive-Tabellen auch mit Redshift Spectrum, Amazon EMR und AWS Glue ETL vom Verbraucherkonto aus abfragen.
Aufräumen
Um Gebühren für die in diesem Beitrag erstellten AWS-Ressourcen zu vermeiden, können Sie die folgenden Schritte ausführen.
Bereinigen Sie die Ressourcen in Konto A
Dem Produzentenkonto A sind zwei CloudFormation-Stacks zugeordnet. Sie müssen die Abhängigkeiten und die beiden Stacks in der richtigen Reihenfolge löschen.
- Melden Sie sich als Administrator bei Produzentenkonto B an.
- Wählen Sie in der Lake Formation-Konsole aus Data Lake-Berechtigungen im Navigationsbereich.
- Auswählen Gewähren.
- Gewähren Sie Ihrer Rolle oder Ihrem Benutzer Drop-Berechtigungen
federated_emrhivedb.
- Wählen Sie im Navigationsbereich Datenbanken.
- Auswählen
federated_emrhivedbund auf der Aktionen Menü, wählen Sie Löschen um die Verbunddatenbank zu löschen, die der Hive-Metastore-Verbindung zugeordnet ist.
Dadurch ist der CloudFormation-Stack der AWS Glue-Verbindung zum Löschen bereit.

- Wählen Sie im Navigationsbereich Administrative Rollen und Aufgaben.
- Der DatenbankerstellerWählen Widerrufen und entfernen
hmsblog-producerstewardBerechtigungen. - Löschen Sie in der CloudFormation-Konsole den genannten Stack
serverlessrepo-GlueDataCatalogFederation-HiveMetastorezuerst.
Dies ist diejenige, die von Ihrer AWS SAM-Anwendung für die Hive-Metastore-Verbindung erstellt wurde. Warten Sie, bis der Löschvorgang abgeschlossen ist.
- Löschen Sie den CloudFormation-Stack, den Sie für das eingerichtete Produzentenkonto erstellt haben.
Dadurch werden die S3-Buckets, der EMR-Cluster, benutzerdefinierte IAM-Rollen und -Richtlinien sowie die LF-Tags, Datenbank, Tabellen und Berechtigungen gelöscht.
Bereinigen Sie die Ressourcen in Konto B
Führen Sie in Konto B die folgenden Schritte aus:
- Widerrufen Sie die Erlaubnis zu
hmsblog-consumerstewardals Datenbankersteller, ähnlich den Schritten im vorherigen Abschnitt. - Löschen Sie den CloudFormation-Stack, den Sie für die Einrichtung des Verbraucherkontos erstellt haben.
Dadurch werden die IAM-Benutzer, der S3-Bucket und alle Berechtigungen aus Lake Formation gelöscht.
Wenn noch Ressourcenlinks und Berechtigungen vorhanden sind, löschen Sie diese manuell in Lake Formation aus beiden Konten.
Zusammenfassung
In diesem Beitrag haben wir Ihnen gezeigt, wie Sie die AWS Glue Hive-Metastore-Verbundanwendung aus dem AWS Serverless Application Repository starten, sie mit einem Hive-Metastore konfigurieren, der auf einem EMR-Cluster ausgeführt wird, eine föderierte Datenbank im AWS Glue-Datenkatalog erstellen und sie einer Hive-Metastore-Datenbank im EMR-Cluster zuordnen. Wir haben gezeigt, wie Sie die Hive-Datenbanktabellen für ein kontenübergreifendes Szenario freigeben und darauf zugreifen können und welche Vorteile die Verwendung von Lake Formation zum Einschränken von Berechtigungen bietet.
Alle Lake Formation-Funktionen wie die Freigabe für IAM-Prinzipale innerhalb desselben Kontos, die Freigabe für externe Konten, die Freigabe für IAM-Prinzipale für externe Konten, das Einschränken des Spaltenzugriffs und das Festlegen von Datenfiltern funktionieren auf föderierten Hive-Datenbanken und -Tabellen. Sie können alle in Lake Formation integrierten AWS-Analysedienste wie Athena, Redshift Spectrum, AWS Glue ETL und Amazon EMR verwenden, um die föderierte Hive-Datenbank und -Tabellen abzufragen.
Wir empfehlen Ihnen, sich die Funktionen des AWS Glue Hive-Metastore-Föderations-Connectors anzusehen und die Lake Formation-Berechtigungen für Ihre Hive-Datenbank und -Tabellen zu erkunden. Bitte kommentieren Sie diesen Beitrag oder sprechen Sie mit Ihrem AWS-Account-Team, um Feedback zu dieser Funktion abzugeben.
Für weitere Einzelheiten siehe Verwalten von Berechtigungen für Datensätze, die externe Metastores verwenden.
Über die Autoren
 Aarthi Srinivasan ist Senior Big Data Architect bei AWS Lake Formation. Sie entwickelt gerne Data-Lake-Lösungen für AWS-Kunden und -Partner. Wenn sie nicht an der Tastatur sitzt, erforscht sie die neuesten Wissenschafts- und Technologietrends und verbringt Zeit mit ihrer Familie.
Aarthi Srinivasan ist Senior Big Data Architect bei AWS Lake Formation. Sie entwickelt gerne Data-Lake-Lösungen für AWS-Kunden und -Partner. Wenn sie nicht an der Tastatur sitzt, erforscht sie die neuesten Wissenschafts- und Technologietrends und verbringt Zeit mit ihrer Familie.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Automobil / Elektrofahrzeuge, Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- BlockOffsets. Modernisierung des Eigentums an Umweltkompensationen. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/query-your-apache-hive-metastore-with-aws-lake-formation-permissions/

