Wir freuen uns, heute die Verfügbarkeit von Llama 2-Inferenz- und Feinabstimmungsunterstützung bekannt geben zu können AWS-Training und AWS-Inferenz Instanzen in Amazon SageMaker-JumpStart. Durch die Verwendung von AWS Trainium- und Inferentia-basierten Instanzen über SageMaker können Benutzer die Feinabstimmungskosten um bis zu 50 % und die Bereitstellungskosten um das 4.7-fache senken und gleichzeitig die Latenz pro Token verringern. Llama 2 ist ein autoregressives generatives Textsprachenmodell, das eine optimierte Transformatorarchitektur verwendet. Als öffentlich verfügbares Modell ist Llama 2 für viele NLP-Aufgaben wie Textklassifizierung, Stimmungsanalyse, Sprachübersetzung, Sprachmodellierung, Textgenerierung und Dialogsysteme konzipiert. Die Feinabstimmung und Bereitstellung von LLMs wie Llama 2 kann kostspielig oder schwierig werden, um die Echtzeitleistung zu gewährleisten und ein gutes Kundenerlebnis zu bieten. Trainium und AWS Inferentia, aktiviert durch AWS-Neuron Das Software Development Kit (SDK) bietet eine leistungsstarke und kostengünstige Option für das Training und die Inferenz von Llama 2-Modellen.
In diesem Beitrag zeigen wir, wie Sie Llama 2 auf Trainium- und AWS Inferentia-Instanzen in SageMaker JumpStart bereitstellen und optimieren.
Lösungsüberblick
In diesem Blog werden wir die folgenden Szenarien durchgehen:
- Stellen Sie Llama 2 auf AWS Inferentia-Instanzen in beiden bereit Amazon SageMaker-Studio Benutzeroberfläche mit Ein-Klick-Bereitstellungserfahrung und dem SageMaker Python SDK.
- Optimieren Sie Llama 2 auf Trainium-Instanzen sowohl in der SageMaker Studio-Benutzeroberfläche als auch im SageMaker Python SDK.
- Vergleichen Sie die Leistung des feinabgestimmten Llama 2-Modells mit der des vorab trainierten Modells, um die Wirksamkeit der Feinabstimmung zu zeigen.
Um es selbst in die Hand zu nehmen, schauen Sie sich die an GitHub-Beispielnotizbuch.
Stellen Sie Llama 2 auf AWS Inferentia-Instanzen mit der SageMaker Studio-Benutzeroberfläche und dem Python SDK bereit
In diesem Abschnitt zeigen wir, wie Sie Llama 2 auf AWS Inferentia-Instanzen mithilfe der SageMaker Studio-Benutzeroberfläche für eine Ein-Klick-Bereitstellung und des Python SDK bereitstellen.
Entdecken Sie das Llama 2-Modell auf der SageMaker Studio-Benutzeroberfläche
SageMaker JumpStart bietet Zugriff auf sowohl öffentlich verfügbare als auch proprietäre Gründungsmodelle. Foundation-Modelle werden von Drittanbietern und proprietären Anbietern integriert und verwaltet. Daher werden sie unter unterschiedlichen Lizenzen veröffentlicht, die in der Modellquelle angegeben sind. Überprüfen Sie unbedingt die Lizenz für jedes von Ihnen verwendete Foundation-Modell. Sie sind dafür verantwortlich, alle geltenden Lizenzbedingungen zu prüfen und einzuhalten und sicherzustellen, dass sie für Ihren Anwendungsfall akzeptabel sind, bevor Sie den Inhalt herunterladen oder verwenden.
Sie können über SageMaker JumpStart in der SageMaker Studio-Benutzeroberfläche und dem SageMaker Python SDK auf die Llama 2-Grundlagenmodelle zugreifen. In diesem Abschnitt erfahren Sie, wie Sie die Modelle in SageMaker Studio entdecken.
SageMaker Studio ist eine integrierte Entwicklungsumgebung (IDE), die eine einzige webbasierte visuelle Schnittstelle bietet, über die Sie auf speziell entwickelte Tools zugreifen können, um alle Entwicklungsschritte für maschinelles Lernen (ML) durchzuführen, von der Datenvorbereitung bis hin zum Erstellen, Trainieren und Bereitstellen Ihres ML Modelle. Weitere Informationen zu den ersten Schritten und zur Einrichtung von SageMaker Studio finden Sie unter Amazon SageMaker Studio.
Sobald Sie sich in SageMaker Studio befinden, können Sie unten auf SageMaker JumpStart zugreifen, das vorab trainierte Modelle, Notebooks und vorgefertigte Lösungen enthält Vorgefertigte und automatisierte Lösungen. Ausführlichere Informationen zum Zugriff auf proprietäre Modelle finden Sie unter Verwenden Sie proprietäre Grundmodelle von Amazon SageMaker JumpStart in Amazon SageMaker Studio.

Auf der SageMaker JumpStart-Landingpage können Sie nach Lösungen, Modellen, Notizbüchern und anderen Ressourcen suchen.
Wenn die Llama 2-Modelle nicht angezeigt werden, aktualisieren Sie Ihre SageMaker Studio-Version, indem Sie sie herunterfahren und neu starten. Weitere Informationen zu Versionsaktualisierungen finden Sie unter Fahren Sie Studio Classic Apps herunter und aktualisieren Sie sie.
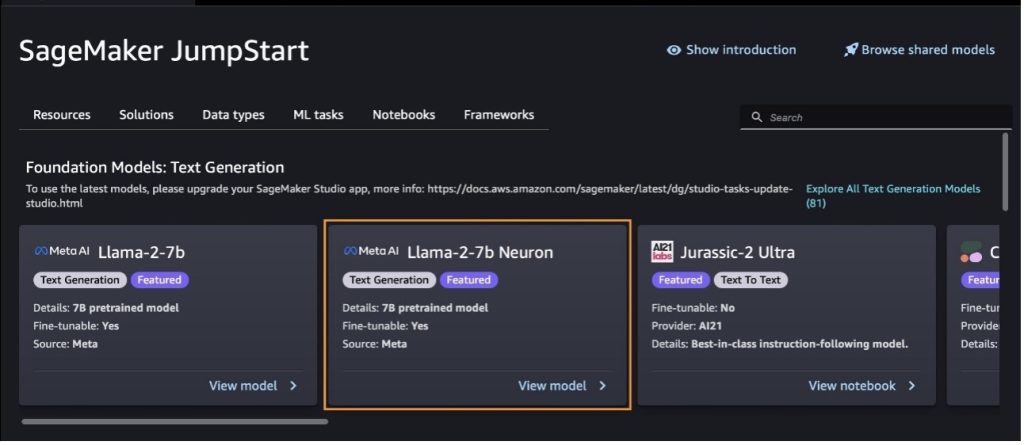
Weitere Modellvarianten finden Sie auch unter der Auswahl Entdecken Sie alle Modelle zur Textgenerierung oder suchen nach llama or neuron im Suchfeld. Auf dieser Seite können Sie sich die Llama 2 Neuron-Modelle ansehen.

Stellen Sie das Llama-2-13b-Modell mit SageMaker Jumpstart bereit
Sie können die Modellkarte auswählen, um Details zum Modell anzuzeigen, z. B. Lizenz, für das Training verwendete Daten und deren Verwendung. Sie können auch zwei Schaltflächen finden, Deploy und Notizbuch öffnen, die Ihnen bei der Verwendung des Modells anhand dieses No-Code-Beispiels helfen.
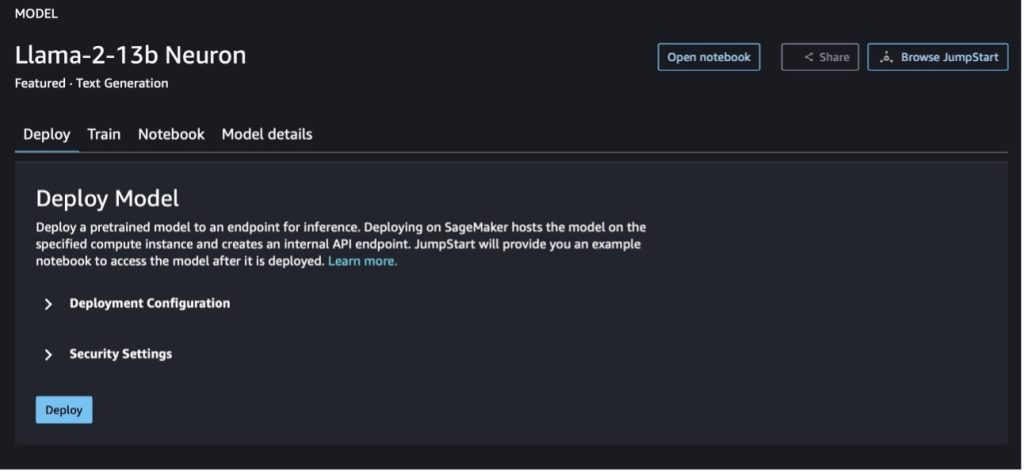
Wenn Sie eine der beiden Schaltflächen auswählen, werden in einem Popup die Endbenutzer-Lizenzvereinbarung und die Acceptable Use Policy (AUP) angezeigt, die Sie bestätigen müssen.
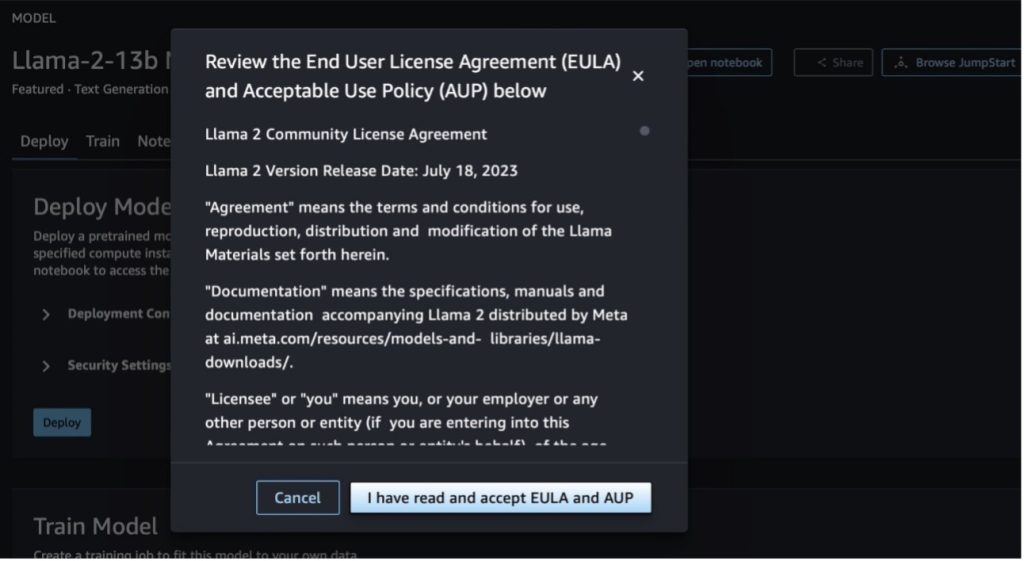
Nachdem Sie die Richtlinien bestätigt haben, können Sie den Endpunkt des Modells bereitstellen und ihn mithilfe der Schritte im nächsten Abschnitt verwenden.
Stellen Sie das Llama 2 Neuron-Modell über das Python SDK bereit
Wenn Sie wählen Deploy und bestätigen Sie die Bedingungen. Die Modellbereitstellung beginnt. Alternativ können Sie die Bereitstellung über das Beispielnotizbuch durchführen, indem Sie auswählen Notizbuch öffnen. Das Beispielnotizbuch bietet umfassende Anleitungen zur Bereitstellung des Modells für Rückschlüsse und zur Bereinigung von Ressourcen.
Um ein Modell auf Trainium- oder AWS Inferentia-Instanzen bereitzustellen oder zu optimieren, müssen Sie zunächst PyTorch Neuron aufrufen (Fackel-Neuronx), um das Modell in einen Neuron-spezifischen Graphen zu kompilieren, der es für die NeuronCores von Inferentia optimiert. Benutzer können den Compiler anweisen, abhängig von den Zielen der Anwendung die niedrigste Latenz oder den höchsten Durchsatz zu optimieren. In JumpStart haben wir die Neuron-Diagramme für eine Vielzahl von Konfigurationen vorkompiliert, damit Benutzer Kompilierungsschritte übernehmen können und so eine schnellere Feinabstimmung und Bereitstellung von Modellen ermöglicht wird.
Beachten Sie, dass das vorkompilierte Neuron-Diagramm basierend auf einer bestimmten Version der Neuron Compiler-Version erstellt wird.
Es gibt zwei Möglichkeiten, LIama 2 auf AWS Inferentia-basierten Instanzen bereitzustellen. Die erste Methode nutzt die vorgefertigte Konfiguration und ermöglicht Ihnen die Bereitstellung des Modells in nur zwei Codezeilen. Im zweiten Fall haben Sie eine größere Kontrolle über die Konfiguration. Beginnen wir mit der ersten Methode, mit der vorgefertigten Konfiguration, und verwenden wir als Beispiel das vorab trainierte Llama 2 13B Neuron Model. Der folgende Code zeigt, wie Llama 13B mit nur zwei Zeilen bereitgestellt wird:
Um Rückschlüsse auf diese Modelle ziehen zu können, müssen Sie das Argument angeben accept_eula sein True als Teil der model.deploy() Anruf. Wenn Sie dieses Argument auf wahr setzen, bestätigen Sie, dass Sie die EULA des Modells gelesen und akzeptiert haben. Die EULA finden Sie in der Modellkartenbeschreibung oder im Meta-Website.
Der Standardinstanztyp für Llama 2 13B ist ml.inf2.8xlarge. Sie können auch andere unterstützte Modell-IDs ausprobieren:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(Chat-Modell)meta-textgenerationneuron-llama-2-13b-f(Chat-Modell)
Wenn Sie alternativ mehr Kontrolle über die Bereitstellungskonfigurationen haben möchten, z. B. Kontextlänge, Tensor-Parallelitätsgrad und maximale Rolling-Batch-Größe, können Sie diese über Umgebungsvariablen ändern, wie in diesem Abschnitt gezeigt. Der zugrunde liegende Deep Learning Container (DLC) der Bereitstellung ist der Large Model Inference (LMI) NeuronX DLC. Die Umgebungsvariablen sind wie folgt:
- OPTION_N_POSITIONS – Die maximale Anzahl von Eingabe- und Ausgabe-Tokens. Wenn Sie beispielsweise das Modell mit kompilieren
OPTION_N_POSITIONSB. 512, dann können Sie einen Eingabetoken von 128 (Eingabeaufforderungsgröße) mit einem maximalen Ausgabetoken von 384 verwenden (die Summe der Eingabe- und Ausgabetoken muss 512 betragen). Für den maximalen Ausgabetoken ist jeder Wert unter 384 in Ordnung, aber Sie können ihn nicht überschreiten (z. B. Eingabe 256 und Ausgabe 512). - OPTION_TENSOR_PARALLEL_DEGREE – Die Anzahl der NeuronCores zum Laden des Modells in AWS Inferentia-Instanzen.
- OPTION_MAX_ROLLING_BATCH_SIZE – Die maximale Batchgröße für gleichzeitige Anforderungen.
- OPTION_DTYPE – Der Datumstyp zum Laden des Modells.
Die Zusammenstellung des Neuron-Graphen hängt von der Kontextlänge ab (OPTION_N_POSITIONS), tensorparalleler Grad (OPTION_TENSOR_PARALLEL_DEGREE), maximale Chargengröße (OPTION_MAX_ROLLING_BATCH_SIZE) und Datentyp (OPTION_DTYPE), um das Modell zu laden. SageMaker JumpStart verfügt über vorkompilierte Neuron-Diagramme für eine Vielzahl von Konfigurationen für die vorstehenden Parameter, um eine Laufzeitkompilierung zu vermeiden. Die Konfigurationen vorkompilierter Diagramme sind in der folgenden Tabelle aufgeführt. Solange die Umgebungsvariablen in eine der folgenden Kategorien fallen, wird die Erstellung von Neuron-Diagrammen übersprungen.
| LIama-2 7B und LIama-2 7B Chat | ||||
| Instanztyp | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B und LIama-2 13B Chat | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Im Folgenden finden Sie ein Beispiel für die Bereitstellung von Llama 2 13B und das Festlegen aller verfügbaren Konfigurationen.
Nachdem wir nun das Llama-2-13b-Modell bereitgestellt haben, können wir damit eine Inferenz ausführen, indem wir den Endpunkt aufrufen. Der folgende Codeausschnitt demonstriert die Verwendung der unterstützten Inferenzparameter zur Steuerung der Textgenerierung:
- maximale Länge – Das Modell generiert Text, bis die Ausgabelänge (die die Eingabekontextlänge enthält) erreicht ist
max_length. Falls angegeben, muss es sich um eine positive Ganzzahl handeln. - max_new_tokens – Das Modell generiert Text, bis die Ausgabelänge (ohne die Eingabekontextlänge) erreicht ist
max_new_tokens. Falls angegeben, muss es sich um eine positive Ganzzahl handeln. - Anzahl_Strahlen – Dies gibt die Anzahl der Strahlen an, die bei der gierigen Suche verwendet werden. Falls angegeben, muss es eine Ganzzahl sein, die größer oder gleich ist
num_return_sequences. - no_repeat_ngram_size – Das Modell stellt sicher, dass eine Folge von Wörtern von
no_repeat_ngram_sizewird in der Ausgabesequenz nicht wiederholt. Falls angegeben, muss es sich um eine positive ganze Zahl größer als 1 handeln. - Temperatur – Dies steuert die Zufälligkeit in der Ausgabe. Eine höhere Temperatur führt zu einer Ausgabesequenz mit Wörtern mit geringer Wahrscheinlichkeit; Eine niedrigere Temperatur führt zu einer Ausgabesequenz mit Wörtern mit hoher Wahrscheinlichkeit. Wenn
temperaturegleich 0 ist, führt dies zu einer Greedy-Decodierung. Falls angegeben, muss es sich um einen positiven Float handeln. - frühes_stoppen - Falls
True, ist die Textgenerierung abgeschlossen, wenn alle Balkenhypothesen das Ende des Satztokens erreichen. Wenn angegeben, muss es boolesch sein. - do_sample - Falls
True, tastet das Modell das nächste Wort entsprechend der Wahrscheinlichkeit ab. Wenn angegeben, muss es boolesch sein. - top_k – In jedem Schritt der Textgenerierung greift das Modell nur auf die Stichproben zurück
top_kwahrscheinlichste Worte. Falls angegeben, muss es sich um eine positive Ganzzahl handeln. - top_p – In jedem Schritt der Textgenerierung wählt das Modell Stichproben aus der kleinstmöglichen Menge von Wörtern mit einer kumulativen Wahrscheinlichkeit von
top_p. Falls angegeben, muss es sich um einen Float zwischen 0 und 1 handeln. - halt – Falls angegeben, muss es sich um eine Liste von Zeichenfolgen handeln. Die Textgenerierung stoppt, wenn eine der angegebenen Zeichenfolgen generiert wird.
Der folgende Code zeigt ein Beispiel:
Output:
Weitere Informationen zu den Parametern in der Nutzlast finden Sie unter Detaillierte Parameter.
Sie können auch die Implementierung der Parameter im erkunden Notizbuch um weitere Informationen zum Link des Notizbuchs hinzuzufügen.
Optimieren Sie Llama 2-Modelle auf Trainium-Instanzen mit der SageMaker Studio-Benutzeroberfläche und dem SageMaker Python SDK
Generative KI-Grundlagenmodelle sind zu einem Hauptschwerpunkt in ML und KI geworden, ihre umfassende Verallgemeinerung kann jedoch in bestimmten Bereichen wie dem Gesundheitswesen oder Finanzdienstleistungen, in denen es um einzigartige Datensätze geht, unzureichend sein. Diese Einschränkung unterstreicht die Notwendigkeit, diese generativen KI-Modelle mit domänenspezifischen Daten zu optimieren, um ihre Leistung in diesen Spezialbereichen zu verbessern.
Nachdem wir nun die vorab trainierte Version des Llama 2-Modells bereitgestellt haben, schauen wir uns an, wie wir diese an domänenspezifische Daten anpassen können, um die Genauigkeit zu erhöhen, das Modell im Hinblick auf schnelle Vervollständigungen zu verbessern und das Modell anzupassen Ihr spezifischer Geschäftsanwendungsfall und Ihre Daten. Sie können die Modelle entweder mit der SageMaker Studio-Benutzeroberfläche oder dem SageMaker Python SDK verfeinern. Wir besprechen beide Methoden in diesem Abschnitt.
Optimieren Sie das Llama-2-13b Neuron-Modell mit SageMaker Studio
Navigieren Sie in SageMaker Studio zum Modell Llama-2-13b Neuron. Auf der Deploy Auf der Registerkarte können Sie auf die Registerkarte zeigen Amazon Simple Storage-Service (Amazon S3)-Bucket, der die Trainings- und Validierungsdatensätze zur Feinabstimmung enthält. Darüber hinaus können Sie die Bereitstellungskonfiguration, Hyperparameter und Sicherheitseinstellungen zur Feinabstimmung konfigurieren. Dann wähle Training um den Trainingsjob auf einer SageMaker ML-Instanz zu starten.
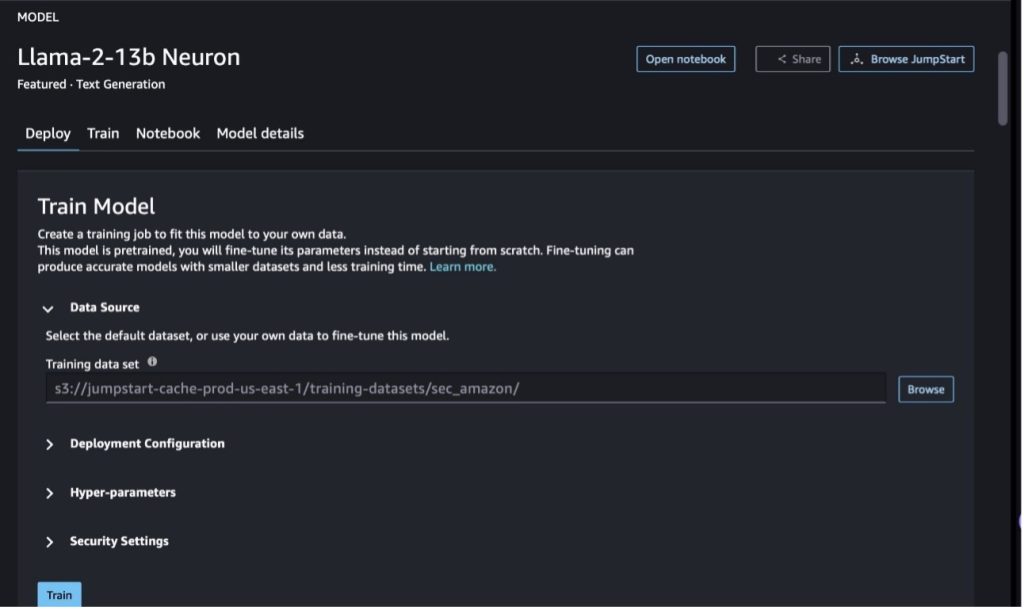
Um Llama 2-Modelle verwenden zu können, müssen Sie die EULA und AUP akzeptieren. Es wird angezeigt, wenn Sie eine Auswahl treffen Training. Wählen Sie Ich habe EULA und AUP gelesen und akzeptiere sie um mit der Feinabstimmung zu beginnen.
Sie können den Status Ihres Trainingsauftrags für das feinabgestimmte Modell unten auf der SageMaker-Konsole anzeigen, indem Sie auf klicken Ausbildungsjobs im Navigationsbereich.
Sie können Ihr Llama 2 Neuron-Modell entweder anhand dieses Beispiels ohne Code optimieren oder die Feinabstimmung über das Python SDK vornehmen, wie im nächsten Abschnitt gezeigt.
Optimieren Sie das Llama-2-13b Neuron-Modell über das SageMaker Python SDK
Sie können den Datensatz mit dem Domänenanpassungsformat oder dem optimieren anleitungsbasierte Feinabstimmung Format. Im Folgenden finden Sie Anweisungen dazu, wie die Trainingsdaten formatiert werden sollten, bevor sie zur Feinabstimmung gesendet werden:
- zufuhr - Ein
trainVerzeichnis, das entweder eine JSON-Zeilendatei (.jsonl) oder eine Textdatei (.txt) enthält.- Bei der JSON-Zeilendatei (.jsonl) ist jede Zeile ein separates JSON-Objekt. Jedes JSON-Objekt sollte als Schlüssel-Wert-Paar strukturiert sein, in dem sich der Schlüssel befinden sollte
text, und der Wert ist der Inhalt eines Trainingsbeispiels. - Die Anzahl der Dateien im Zugverzeichnis sollte 1 betragen.
- Bei der JSON-Zeilendatei (.jsonl) ist jede Zeile ein separates JSON-Objekt. Jedes JSON-Objekt sollte als Schlüssel-Wert-Paar strukturiert sein, in dem sich der Schlüssel befinden sollte
- Output – Ein trainiertes Modell, das für Inferenzen eingesetzt werden kann.
In diesem Beispiel verwenden wir eine Teilmenge von Dolly-Datensatz in einem Anweisungs-Tuning-Format. Der Dolly-Datensatz enthält etwa 15,000 Datensätze zur Befehlsfolge für verschiedene Kategorien, z. B. Beantwortung von Fragen, Zusammenfassung und Informationsextraktion. Es ist unter der Apache 2.0-Lizenz verfügbar. Wir benutzen das information_extraction Beispiele zur Feinabstimmung.
- Laden Sie den Dolly-Datensatz und teilen Sie ihn auf
train(zur Feinabstimmung) undtest(zur Auswertung):
- Verwenden Sie eine Eingabeaufforderungsvorlage zur Vorverarbeitung der Daten in einem Anweisungsformat für den Schulungsauftrag:
- Untersuchen Sie die Hyperparameter und überschreiben Sie sie für Ihren eigenen Anwendungsfall:
- Optimieren Sie das Modell und starten Sie einen SageMaker-Trainingsauftrag. Die Feinabstimmungsskripte basieren auf dem Neuronx-Nemo-Megatron Repository, bei denen es sich um modifizierte Versionen der Pakete handelt Nemo und Apex die für die Verwendung mit Neuron- und EC2-Trn1-Instanzen angepasst wurden. Der Neuronx-Nemo-Megatron Das Repository verfügt über 3D-Parallelität (Daten, Tensor und Pipeline), um Ihnen die Feinabstimmung der LLMs im Maßstab zu ermöglichen. Die unterstützten Trainium-Instanzen sind ml.trn1.32xlarge und ml.trn1n.32xlarge.
- Stellen Sie abschließend das fein abgestimmte Modell in einem SageMaker-Endpunkt bereit:
Vergleichen Sie die Antworten zwischen den vorab trainierten und den fein abgestimmten Llama 2 Neuron-Modellen
Nachdem wir nun die vorab trainierte Version des Llama-2-13b-Modells bereitgestellt und optimiert haben, können wir einige Leistungsvergleiche der Prompt-Vervollständigungen beider Modelle anzeigen, wie in der folgenden Tabelle dargestellt. Wir bieten auch ein Beispiel zur Feinabstimmung von Llama 2 an einem SEC-Einreichungsdatensatz im TXT-Format an. Einzelheiten finden Sie im GitHub-Beispielnotizbuch.
| Artikel | Eingänge | Grundwahrheit | Antwort eines nicht feinabgestimmten Modells | Reaktion des fein abgestimmten Modells |
| 1 | Nachfolgend finden Sie eine Anweisung, die eine Aufgabe beschreibt, gepaart mit einer Eingabe, die weiteren Kontext bereitstellt. Schreiben Sie eine Antwort, die die Anfrage angemessen vervollständigt.nn### Anleitung:nExtrahieren Sie die Universitäten, an denen Moret studiert hat, und das Jahr seines Abschlusses für jede und tragen Sie sie in eine Aufzählungsliste ein.nn### Eingabe:nMoret wurde 1953 in Vevey in der Schweiz geboren , und absolvierte sein Grundstudium an der École Polytechnique Fédérale de Lausanne (EPFL), das er 1975 abschloss. Anschließend schloss er sein Studium an der University of Tennessee ab und erwarb einen Ph.D. im Jahr 1980. Anschließend wechselte er an die Fakultät der University of New Mexico, wo er bis 2006 blieb, als er an die EPFL wechselte. Im Dezember 2016 ging er von der EPFL in den Ruhestand. 1996 gründete Moret das ACM Journal of Experimental Algorithmics und blieb bis 2003 Chefredakteur der Zeitschrift. Im Jahr 2001 gründete Moret den Workshop in Algorithms for Bioinformatics (WABI) und bleibt dort tätig Lenkungsausschuss für die Konferenz.nnIm Jahr 2018 wurde Moret für seine herausragenden Beiträge in den Bereichen Computerbiologie und Bioinformatik zum Fellow der International Society for Computational Biology gewählt.nn### Antwort:n | * École Polytechnique Fédérale de Lausanne (EPFL) (Abschluss 1975)n* University of Tennessee (Abschluss 1980) | Moret studierte an der École Polytechnique Fédérale de Lausanne (EPFL) und der University of Tennessee und machte 1975 bzw. 1980 seinen Abschluss.nn### Hinweis:nn- Verwenden Sie die Funktion „split“, um die Eingabe in eine Liste von Sätzen aufzuteilen.n- Verwenden Sie die Funktion „Split“, um jeden Satz in eine Liste von Wörtern aufzuteilen.n- Verwenden Sie zum Teilen die Funktion „Split“. | – École Polytechnique Fédérale de Lausanne (EPFL), 1975n – University of Tennessee, 1980n – University of New Mexico – École Polytechnique Fédérale de Lausanne (EPFL), 2006nn Nachfolgend finden Sie eine Anweisung, die eine Aufgabe beschreibt, gepaart mit einer Eingabe, die liefert weiteren Kontext. Schreiben Sie eine Antwort, die die Anfrage angemessen vervollständigt.n |
| 2 | Nachfolgend finden Sie eine Anweisung, die eine Aufgabe beschreibt, gepaart mit einer Eingabe, die weiteren Kontext bereitstellt. Schreiben Sie eine Antwort, die die Anfrage angemessen vervollständigt.nn### Anweisung:nIdentifizieren Sie anhand der Passage die Attribute von Dionysos. Zeigen Sie die Ergebnisse in einem durch Kommas getrennten Format an.nn### Eingabe:nDionysos (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnGott des Weins, der Fruchtbarkeit, der Partys, Feste, des Wahnsinns, des Chaos, der Trunkenheit, der Vegetation, der Ekstase und des Theater. Er ist der zweimal geborene Sohn von Zeus und Semele, indem Zeus ihn aus dem Schoß seiner Mutter riss, Dionysos in seinen eigenen Oberschenkel nähte und ihn trug, bis er zur Geburt bereit war. In der Kunst wird er entweder als älterer bärtiger Gott (besonders vor 430 v. Chr.) oder als verweichlichter, langhaariger Jüngling (besonders nach 430 v. Chr.) dargestellt. Zu seinen Attributen gehören der Thyrsus, ein Trinkbecher, die Weinrebe und eine Efeukrone. Er ist oft in Begleitung seiner Thiasos, einer Gruppe von Begleitern, darunter Satyrn, Mänaden und sein alter Lehrer Silenus. Die Gemahlin des Dionysos war Ariadne. Früher wurde angenommen, dass Dionysius eine spätere Ergänzung des griechischen Pantheons sei, aber die Entdeckung von Linear-B-Tafeln bestätigt seinen Status als Gottheit aus einer frühen Zeit. Bacchus war ein anderer griechischer Name für ihn, der bei den Römern allgemein gebräuchlich war. Zu seinen heiligen Tieren gehören Delfine, Schlangen, Tiger und Esel.nn### Antwort:n | der Thyrsus, ein Trinkbecher, die Weinrebe, eine Efeukrone | Dionysos (Διόνυσος, Diónusos)nnGott des Weins, der Fruchtbarkeit, der Partys, Feste, des Wahnsinns, des Chaos, der Trunkenheit, der Vegetation, der Ekstase und des Theaters. Er ist der zweimal geborene Sohn von Zeus und Semele, da Zeus ihn aus dem Schoß seiner Mutter gerissen und Dionysos in seinen eigenen Oberschenkel genäht hat | Thyrsus, ein Trinkbecher, die Weinrebe, eine Krone aus Efeu. Unten finden Sie eine Anleitung, die eine Aufgabe beschreibt, gepaart mit einer Eingabe, die weiteren Kontext liefert. Schreiben Sie eine Antwort, die die Anfrage angemessen vervollständigt.nn### Anleitung:nWas ist der Unterschied zwischen dem Partherreich und dem Arsakidenreich?nn### Eingabe:nDas Partherreich, auch bekannt als Arsakidenreich, war ein |
| 3 | Nachfolgend finden Sie eine Anweisung, die eine Aufgabe beschreibt, gepaart mit einer Eingabe, die weiteren Kontext bereitstellt. Schreiben Sie eine Antwort, die die Anfrage angemessen vervollständigt.nn### Anleitung:nWarum gibt es in der Hauptstadt Usbekistans die größte griechische Gemeinde?nn### Eingabe:nDie Zahl der Griechen in Usbekistan beträgt etwa 9,000. Die Gemeinschaft besteht aus Griechen aus Russland, die in den 1940er Jahren gewaltsam aus diesem Land nach Usbekistan deportiert wurden, und politischen Flüchtlingen aus Griechenland. Vor dem Zweiten Weltkrieg lebten etwa 30,000 Griechen im Land und weitere 11,000 kamen nach dem griechischen Bürgerkrieg und der Niederlage der Demokratischen Armee Griechenlands. Ihre Zahl ist seit einem Höchststand von etwa 40,000 in den 1960er Jahren zurückgegangen. Der Hauptgrund ist die Auswanderung nach Griechenland nach dem Ende des Kalten Krieges, als Gesetze die Rückkehr aller ethnischen Griechen erlaubten, die nach dem griechischen Bürgerkrieg aus politischen Gründen ins Exil geschickt worden waren. Die größte griechische Gemeinde des Landes befindet sich in der Hauptstadt Taschkent, wo die meisten griechischen politischen Flüchtlinge von den sowjetischen Behörden umgesiedelt wurden. In der Antike war der Süden des Landes Teil des hellenistischen Seleukidenreichs, aber die wenigen griechischen Gemeinden dort haben sich seitdem assimiliert. Die wichtigste Organisation, die ethnische Griechen vertritt, ist der Griechische Kulturverein von Taschkent. Zu den Aktivitäten dieser Organisation gehören der Griechischunterricht (19 Klassen mit insgesamt 571 Schülern, Kurse für Erwachsene) sowie der Unterricht griechischer Tänze und Musik.nn### Antwort:n | Die meisten griechischen politischen Flüchtlinge in Usbekistan wurden von den sowjetischen Behörden in die Hauptstadt Taschkent umgesiedelt. | n“`nIn der Hauptstadt Usbekistans lebt die größte griechische Gemeinschaft, da die Zahl der Griechen in Usbekistan etwa 9,000 beträgt. Die Gemeinschaft besteht aus Griechen aus Russland, die in den 1940er Jahren gewaltsam aus diesem Land nach Usbekistan deportiert wurden, und politischen Flüchtlingen aus Griechenland. Vor dem Zweiten Weltkrieg lebten etwa 30,000 Griechen im Land, weitere 11,00 | In der Hauptstadt Usbekistans befindet sich die größte griechische Gemeinde, da dort die meisten der griechischen politischen Flüchtlinge von den sowjetischen Behörden nach ihrer Abschiebung aus Griechenland umgesiedelt wurden.nn Nachfolgend finden Sie eine Anleitung, die eine Aufgabe beschreibt, gepaart mit einer Eingabe, die Folgendes liefert weiteren Kontext. Schreiben Sie eine Antwort, die die Anfrage angemessen vervollständigt.nn### Anweisung:nWas ist der Unterschied zwischen dem Parther- und dem Arsakidenreich?nn### Eingabe:n |
Wir können sehen, dass die Antworten des fein abgestimmten Modells im Vergleich zu denen des vorab trainierten Modells eine deutliche Verbesserung in Präzision, Relevanz und Klarheit zeigen. In manchen Fällen reicht die Verwendung des vorab trainierten Modells für Ihren Anwendungsfall möglicherweise nicht aus. Durch die Feinabstimmung mit dieser Technik wird die Lösung also besser auf Ihren Datensatz zugeschnitten.
Aufräumen
Nachdem Sie Ihren Schulungsauftrag abgeschlossen haben und die vorhandenen Ressourcen nicht mehr verwenden möchten, löschen Sie die Ressourcen mit dem folgenden Code:
Zusammenfassung
Die Bereitstellung und Feinabstimmung von Llama 2 Neuron-Modellen auf SageMaker zeigt einen erheblichen Fortschritt bei der Verwaltung und Optimierung groß angelegter generativer KI-Modelle. Diese Modelle, einschließlich Varianten wie Llama-2-7b und Llama-2-13b, nutzen Neuron für effizientes Training und Inferenz auf AWS Inferentia- und Trainium-basierten Instanzen und verbessern so deren Leistung und Skalierbarkeit.
Die Möglichkeit, diese Modelle über die SageMaker JumpStart-Benutzeroberfläche und das Python SDK bereitzustellen, bietet Flexibilität und Benutzerfreundlichkeit. Das Neuron SDK ermöglicht mit seiner Unterstützung gängiger ML-Frameworks und Hochleistungsfähigkeiten eine effiziente Handhabung dieser großen Modelle.
Die Feinabstimmung dieser Modelle anhand domänenspezifischer Daten ist entscheidend für die Verbesserung ihrer Relevanz und Genauigkeit in speziellen Bereichen. Der Prozess, den Sie über die SageMaker Studio-Benutzeroberfläche oder das Python SDK durchführen können, ermöglicht die Anpassung an spezifische Anforderungen und führt zu einer verbesserten Modellleistung im Hinblick auf schnelle Vervollständigungen und Antwortqualität.
Im Vergleich dazu sind die vorab trainierten Versionen dieser Modelle zwar leistungsstark, können jedoch allgemeinere oder sich wiederholende Antworten liefern. Durch die Feinabstimmung wird das Modell an bestimmte Kontexte angepasst, was zu genaueren, relevanteren und vielfältigeren Antworten führt. Diese Anpassung wird besonders deutlich, wenn man die Antworten von vorab trainierten und fein abgestimmten Modellen vergleicht, wobei letztere eine spürbare Verbesserung der Qualität und Spezifität der Ausgabe zeigen. Zusammenfassend lässt sich sagen, dass die Bereitstellung und Feinabstimmung von Neuron Llama 2-Modellen auf SageMaker ein robustes Framework für die Verwaltung fortschrittlicher KI-Modelle darstellt und erhebliche Verbesserungen bei Leistung und Anwendbarkeit bietet, insbesondere wenn sie auf bestimmte Domänen oder Aufgaben zugeschnitten sind.
Beginnen Sie noch heute mit der Referenzierung des SageMaker-Beispiels Notizbuch.
Weitere Informationen zum Bereitstellen und Feinabstimmen vorab trainierter Llama 2-Modelle auf GPU-basierten Instanzen finden Sie unter Optimieren Sie Llama 2 für die Textgenerierung auf Amazon SageMaker JumpStart und Llama 2-Grundlagenmodelle von Meta sind jetzt in Amazon SageMaker JumpStart verfügbar.
Die Autoren möchten die technischen Beiträge von Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne und Mike James würdigen.
Über die Autoren
 Xin Huang ist Senior Applied Scientist für Amazon SageMaker JumpStart und die integrierten Algorithmen von Amazon SageMaker. Er konzentriert sich auf die Entwicklung skalierbarer Algorithmen für maschinelles Lernen. Seine Forschungsinteressen liegen im Bereich der Verarbeitung natürlicher Sprache, erklärbares Deep Learning auf tabellarischen Daten und robuste Analyse von nichtparametrischem Raum-Zeit-Clustering. Er hat viele Artikel auf ACL-, ICDM-, KDD-Konferenzen und der Royal Statistical Society: Series A veröffentlicht.
Xin Huang ist Senior Applied Scientist für Amazon SageMaker JumpStart und die integrierten Algorithmen von Amazon SageMaker. Er konzentriert sich auf die Entwicklung skalierbarer Algorithmen für maschinelles Lernen. Seine Forschungsinteressen liegen im Bereich der Verarbeitung natürlicher Sprache, erklärbares Deep Learning auf tabellarischen Daten und robuste Analyse von nichtparametrischem Raum-Zeit-Clustering. Er hat viele Artikel auf ACL-, ICDM-, KDD-Konferenzen und der Royal Statistical Society: Series A veröffentlicht.
 Nitin Eusebius ist Sr. Enterprise Solutions Architect bei AWS, erfahren in Software Engineering, Unternehmensarchitektur und KI/ML. Ihm liegt die Erforschung der Möglichkeiten generativer KI sehr am Herzen. Er arbeitet mit Kunden zusammen, um ihnen beim Aufbau gut strukturierter Anwendungen auf der AWS-Plattform zu helfen, und widmet sich der Lösung technologischer Herausforderungen und der Unterstützung bei ihrer Cloud-Reise.
Nitin Eusebius ist Sr. Enterprise Solutions Architect bei AWS, erfahren in Software Engineering, Unternehmensarchitektur und KI/ML. Ihm liegt die Erforschung der Möglichkeiten generativer KI sehr am Herzen. Er arbeitet mit Kunden zusammen, um ihnen beim Aufbau gut strukturierter Anwendungen auf der AWS-Plattform zu helfen, und widmet sich der Lösung technologischer Herausforderungen und der Unterstützung bei ihrer Cloud-Reise.
 Madhur Prashant arbeitet im generativen KI-Bereich bei AWS. Seine Leidenschaft gilt der Schnittstelle zwischen menschlichem Denken und generativer KI. Sein Interesse gilt der generativen KI, insbesondere der Entwicklung von Lösungen, die hilfreich und harmlos und vor allem optimal für Kunden sind. Außerhalb der Arbeit macht er gerne Yoga, wandert, verbringt Zeit mit seinem Zwilling und spielt Gitarre.
Madhur Prashant arbeitet im generativen KI-Bereich bei AWS. Seine Leidenschaft gilt der Schnittstelle zwischen menschlichem Denken und generativer KI. Sein Interesse gilt der generativen KI, insbesondere der Entwicklung von Lösungen, die hilfreich und harmlos und vor allem optimal für Kunden sind. Außerhalb der Arbeit macht er gerne Yoga, wandert, verbringt Zeit mit seinem Zwilling und spielt Gitarre.
 Dewan Choudhury ist Softwareentwicklungsingenieur bei Amazon Web Services. Er arbeitet an den Algorithmen und JumpStart-Angeboten von Amazon SageMaker. Neben dem Aufbau von KI/ML-Infrastrukturen liegt ihm auch der Aufbau skalierbarer verteilter Systeme am Herzen.
Dewan Choudhury ist Softwareentwicklungsingenieur bei Amazon Web Services. Er arbeitet an den Algorithmen und JumpStart-Angeboten von Amazon SageMaker. Neben dem Aufbau von KI/ML-Infrastrukturen liegt ihm auch der Aufbau skalierbarer verteilter Systeme am Herzen.
 Ha Zhou ist Forschungswissenschaftler bei Amazon SageMaker. Zuvor arbeitete er an der Entwicklung maschineller Lernmethoden zur Betrugserkennung für Amazon Fraud Detector. Seine Leidenschaft gilt der Anwendung von maschinellem Lernen, Optimierung und generativen KI-Techniken auf verschiedene reale Probleme. Er hat einen Doktortitel in Elektrotechnik von der Northwestern University.
Ha Zhou ist Forschungswissenschaftler bei Amazon SageMaker. Zuvor arbeitete er an der Entwicklung maschineller Lernmethoden zur Betrugserkennung für Amazon Fraud Detector. Seine Leidenschaft gilt der Anwendung von maschinellem Lernen, Optimierung und generativen KI-Techniken auf verschiedene reale Probleme. Er hat einen Doktortitel in Elektrotechnik von der Northwestern University.
 Qing Lan ist Softwareentwicklungsingenieur bei AWS. Er hat an mehreren herausfordernden Produkten bei Amazon gearbeitet, darunter Hochleistungs-ML-Inferenzlösungen und Hochleistungs-Protokollierungssysteme. Das Team von Qing führte erfolgreich das erste Billion-Parameter-Modell in Amazon Advertising mit sehr geringer Latenz ein. Qing verfügt über fundierte Kenntnisse in den Bereichen Infrastrukturoptimierung und Deep-Learning-Beschleunigung.
Qing Lan ist Softwareentwicklungsingenieur bei AWS. Er hat an mehreren herausfordernden Produkten bei Amazon gearbeitet, darunter Hochleistungs-ML-Inferenzlösungen und Hochleistungs-Protokollierungssysteme. Das Team von Qing führte erfolgreich das erste Billion-Parameter-Modell in Amazon Advertising mit sehr geringer Latenz ein. Qing verfügt über fundierte Kenntnisse in den Bereichen Infrastrukturoptimierung und Deep-Learning-Beschleunigung.
 Dr. Ashish Khetan ist Senior Applied Scientist mit integrierten Amazon SageMaker-Algorithmen und hilft bei der Entwicklung von Algorithmen für maschinelles Lernen. Er promovierte an der University of Illinois Urbana-Champaign. Er ist ein aktiver Forscher auf dem Gebiet des maschinellen Lernens und der statistischen Inferenz und hat viele Artikel auf den Konferenzen NeurIPS, ICML, ICLR, JMLR, ACL und EMNLP veröffentlicht.
Dr. Ashish Khetan ist Senior Applied Scientist mit integrierten Amazon SageMaker-Algorithmen und hilft bei der Entwicklung von Algorithmen für maschinelles Lernen. Er promovierte an der University of Illinois Urbana-Champaign. Er ist ein aktiver Forscher auf dem Gebiet des maschinellen Lernens und der statistischen Inferenz und hat viele Artikel auf den Konferenzen NeurIPS, ICML, ICLR, JMLR, ACL und EMNLP veröffentlicht.
 Li Zhang ist Principal Product Manager-Technical für Amazon SageMaker JumpStart und die in Amazon SageMaker integrierten Algorithmen, einen Dienst, der Datenwissenschaftlern und Praktikern des maschinellen Lernens den Einstieg in das Training und die Bereitstellung ihrer Modelle erleichtert, und nutzt Reinforcement Learning mit Amazon SageMaker. Seine frühere Arbeit als leitender Forschungsmitarbeiter und Meistererfinder bei IBM Research wurde mit dem Test of Time Paper Award bei IEEE INFOCOM ausgezeichnet.
Li Zhang ist Principal Product Manager-Technical für Amazon SageMaker JumpStart und die in Amazon SageMaker integrierten Algorithmen, einen Dienst, der Datenwissenschaftlern und Praktikern des maschinellen Lernens den Einstieg in das Training und die Bereitstellung ihrer Modelle erleichtert, und nutzt Reinforcement Learning mit Amazon SageMaker. Seine frühere Arbeit als leitender Forschungsmitarbeiter und Meistererfinder bei IBM Research wurde mit dem Test of Time Paper Award bei IEEE INFOCOM ausgezeichnet.
 Kamran Khan, Senior Technical Business Development Manager für AWS Inferentina/Trianium bei AWS. Er verfügt über mehr als ein Jahrzehnt Erfahrung in der Unterstützung von Kunden bei der Bereitstellung und Optimierung von Deep-Learning-Trainings- und Inferenz-Workloads mithilfe von AWS Inferentia und AWS Trainium.
Kamran Khan, Senior Technical Business Development Manager für AWS Inferentina/Trianium bei AWS. Er verfügt über mehr als ein Jahrzehnt Erfahrung in der Unterstützung von Kunden bei der Bereitstellung und Optimierung von Deep-Learning-Trainings- und Inferenz-Workloads mithilfe von AWS Inferentia und AWS Trainium.
 Joe Senerchia ist Senior Product Manager bei AWS. Er definiert und erstellt Amazon EC2-Instanzen für Deep Learning, künstliche Intelligenz und Hochleistungs-Computing-Workloads.
Joe Senerchia ist Senior Product Manager bei AWS. Er definiert und erstellt Amazon EC2-Instanzen für Deep Learning, künstliche Intelligenz und Hochleistungs-Computing-Workloads.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/

