Das weltweit generierte Datenvolumen nimmt weiter zu, von Spielen, Einzelhandel und Finanzen bis hin zu Produktion, Gesundheitswesen und Reisen. Unternehmen suchen nach mehr Möglichkeiten, den ständigen Datenzufluss schnell für Innovationen für ihre Unternehmen und Kunden zu nutzen. Sie müssen die Daten zuverlässig erfassen, verarbeiten, analysieren und in unzählige Datenspeicher laden – und das alles in Echtzeit.
Apache Kafka ist eine beliebte Wahl für diese Echtzeit-Streaming-Anforderungen. Allerdings kann es schwierig sein, einen Kafka-Cluster zusammen mit anderen Datenverarbeitungskomponenten einzurichten, die je nach den Anforderungen Ihrer Anwendung automatisch skaliert werden. Es besteht die Gefahr einer unzureichenden Bereitstellung für Spitzendatenverkehr, was zu Ausfallzeiten führen kann, oder einer übermäßigen Bereitstellung für die Grundlast, was zu Verschwendung führen kann. AWS bietet mehrere serverlose Dienste wie Amazon Managed Streaming für Apache Kafka (Amazon MSK), Amazon Data Firehose, Amazon DynamoDB und AWS Lambda Diese skaliert automatisch entsprechend Ihren Anforderungen.
In diesem Beitrag erklären wir, wie Sie einige dieser Dienste nutzen können, darunter MSK Serverlos, um eine serverlose Datenplattform aufzubauen, die Ihren Echtzeitanforderungen entspricht.
Lösungsüberblick
Stellen wir uns ein Szenario vor. Sie sind für die Verwaltung Tausender Modems für einen Internetdienstanbieter verantwortlich, der in mehreren Regionen eingesetzt wird. Sie möchten die Qualität der Modemverbindung überwachen, die einen erheblichen Einfluss auf die Produktivität und Zufriedenheit der Kunden hat. Ihre Bereitstellung umfasst verschiedene Modems, die überwacht und gewartet werden müssen, um minimale Ausfallzeiten zu gewährleisten. Jedes Gerät überträgt jede Sekunde Tausende von 1-KB-Datensätzen, z. B. CPU-Auslastung, Speichernutzung, Alarm und Verbindungsstatus. Sie möchten Echtzeitzugriff auf diese Daten, damit Sie die Leistung in Echtzeit überwachen und Probleme schnell erkennen und beheben können. Sie benötigen außerdem einen längerfristigen Zugriff auf diese Daten für Modelle des maschinellen Lernens (ML), um vorausschauende Wartungsbewertungen durchzuführen, Optimierungsmöglichkeiten zu finden und den Bedarf zu prognostizieren.
Ihre Clients, die die Daten vor Ort sammeln, sind in Python geschrieben und können alle Daten als Apache Kafka-Themen an Amazon MSK senden. Für die geringe Latenz und den Echtzeit-Datenzugriff Ihrer Anwendung können Sie Folgendes verwenden Lambda und DynamoDB. Für die längerfristige Datenspeicherung können Sie den verwalteten serverlosen Connector-Dienst verwenden Amazon Data Firehose um Daten an Ihren Data Lake zu senden.
Das folgende Diagramm zeigt, wie Sie diese serverlose End-to-End-Anwendung erstellen können.
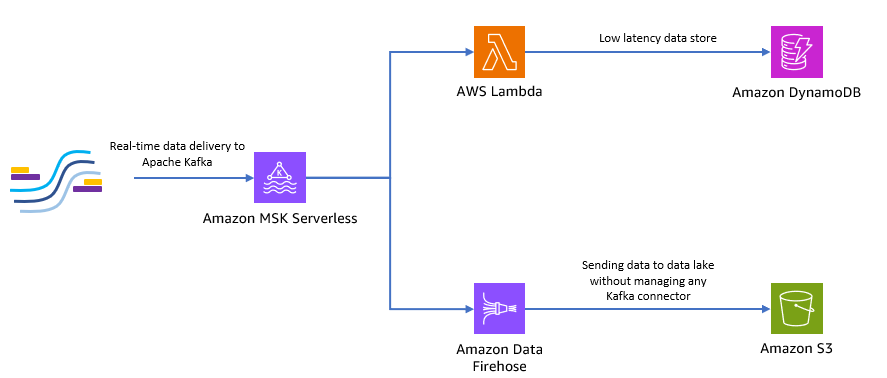
Befolgen wir die Schritte in den folgenden Abschnitten, um diese Architektur zu implementieren.
Erstellen Sie einen serverlosen Kafka-Cluster auf Amazon MSK
Wir verwenden Amazon MSK, um Echtzeit-Telemetriedaten von Modems aufzunehmen. Das Erstellen eines serverlosen Kafka-Clusters ist auf Amazon MSK unkompliziert. Die Verwendung dauert nur wenige Minuten AWS-Managementkonsole oder AWS SDK. Informationen zur Verwendung der Konsole finden Sie unter Erste Schritte mit MSK Serverless-Clustern. Sie erstellen einen serverlosen Cluster, AWS Identity and Access Management and (IAM)-Rolle und Client-Rechner.
Erstellen Sie ein Kafka-Thema mit Python
Wenn Ihr Cluster und Ihr Client-Computer bereit sind, stellen Sie eine SSH-Verbindung zu Ihrem Client-Computer her und installieren Sie Kafka Python und die MSK IAM-Bibliothek für Python.
- Führen Sie die folgenden Befehle aus, um Kafka Python und zu installieren MSK IAM-Bibliothek:
- Erstellen Sie eine neue Datei mit dem Namen
createTopic.py. - Kopieren Sie den folgenden Code in diese Datei und ersetzen Sie den
bootstrap_serversundregionInformationen mit den Details für Ihren Cluster. Anweisungen zum Abrufen derbootstrap_serversInformationen zu Ihrem MSK-Cluster finden Sie unter Abrufen der Bootstrap-Broker für einen Amazon MSK-Cluster.
- Führen Sie die
createTopic.pySkript zum Erstellen eines neuen Kafka-Themas namensmytopicauf Ihrem serverlosen Cluster:
Erstellen Sie Datensätze mit Python
Lassen Sie uns einige Beispielmodem-Telemetriedaten generieren.
- Erstellen Sie eine neue Datei mit dem Namen
kafkaDataGen.py. - Kopieren Sie den folgenden Code in diese Datei und aktualisieren Sie die
BROKERSundregionInformationen mit den Details zu Ihrem Cluster:
- Führen Sie die
kafkaDataGen.pyum kontinuierlich Zufallsdaten zu generieren und diese im angegebenen Kafka-Thema zu veröffentlichen:
Speichern Sie Ereignisse in Amazon S3
Jetzt speichern Sie alle rohen Ereignisdaten in einem Amazon Simple Storage-Service (Amazon S3) Data Lake für Analysen. Sie können dieselben Daten verwenden, um ML-Modelle zu trainieren. Der Integration mit Amazon Data Firehose ermöglicht Amazon MSK das nahtlose Laden von Daten aus Ihren Apache Kafka-Clustern in einen S3-Datensee. Führen Sie die folgenden Schritte aus, um kontinuierlich Daten von Kafka an Amazon S3 zu streamen, sodass Sie keine eigenen Connector-Anwendungen erstellen oder verwalten müssen:
- Erstellen Sie auf der Amazon S3-Konsole einen neuen Bucket. Sie können auch einen vorhandenen Bucket verwenden.
- Erstellen Sie in Ihrem S3-Bucket einen neuen Ordner mit dem Namen
streamingDataLake. - Wählen Sie in der Amazon MSK-Konsole Ihren MSK Serverless-Cluster aus.
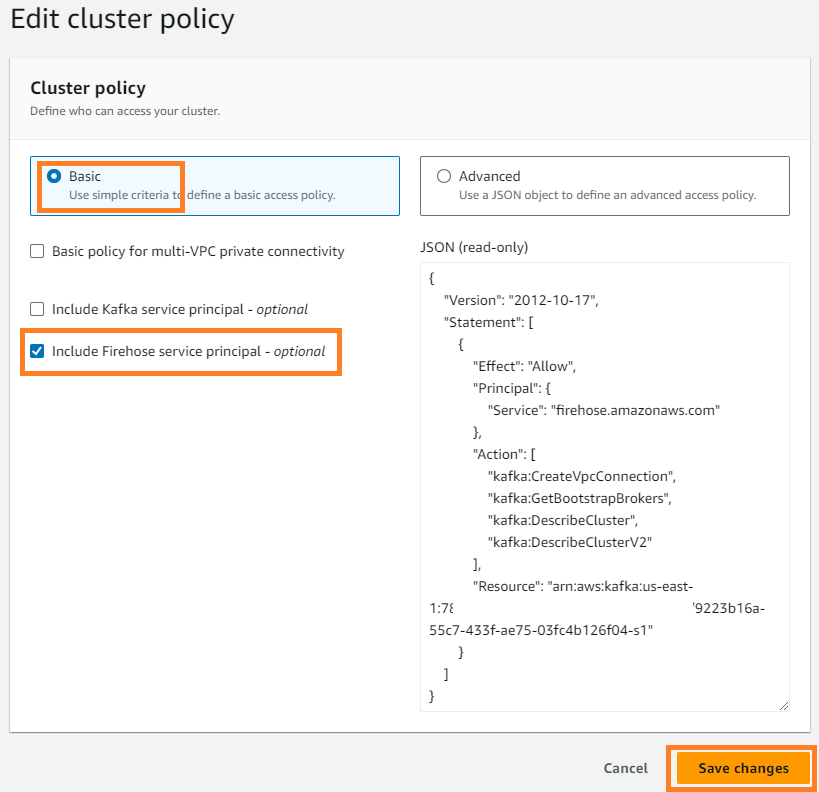
- Auf dem Aktionen Menü, wählen Sie Clusterrichtlinie bearbeiten.

- Auswählen Schließen Sie den Firehose-Dienstprinzipal ein und wählen Sie Änderungen speichern.
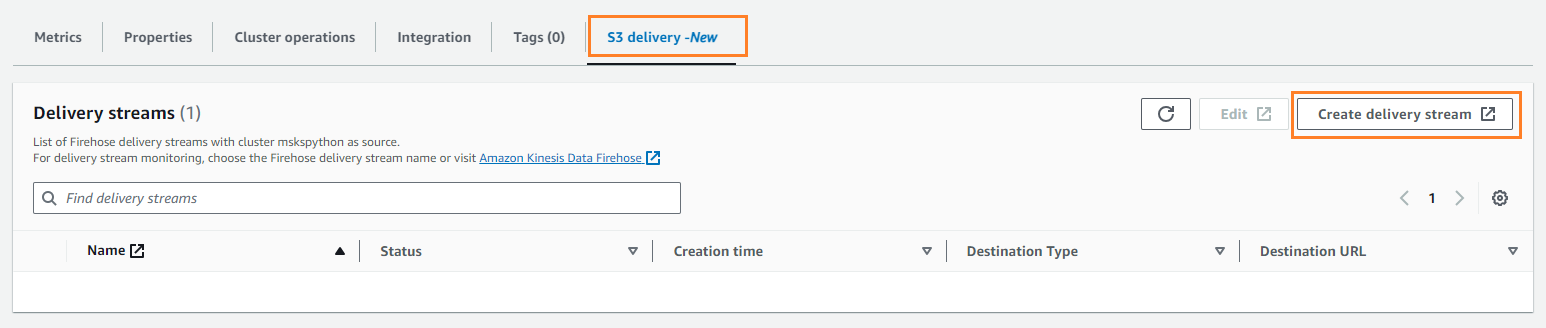
- Auf dem S3-Lieferung Tab, wählen Sie Lieferstrom erstellen.
- Aussichten für Quelle, wählen Amazon MSK.
- Aussichten für Reiseziel, wählen Amazon S3.

- Aussichten für Amazon MSK-Cluster-KonnektivitätWählen Private Bootstrap-Broker.
- Aussichten für Betreff, geben Sie einen Themennamen ein (für diesen Beitrag,
mytopic).
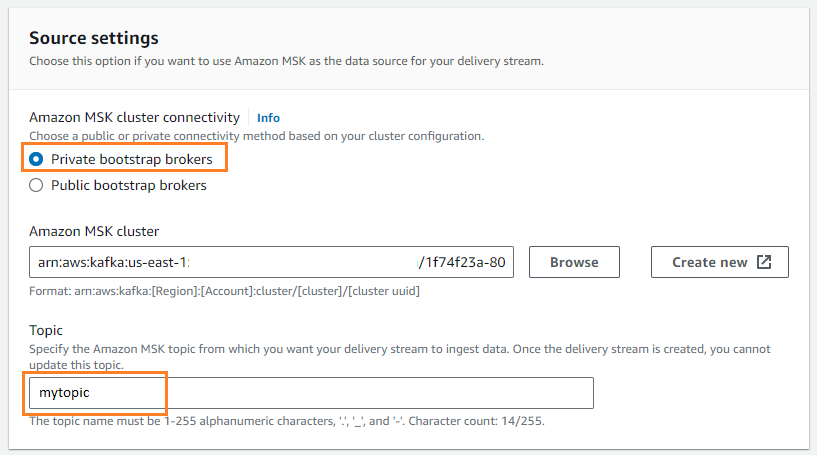
- Aussichten für S3-Eimer, wählen Entdecken und wählen Sie Ihren S3-Bucket aus.
- Enter
streamingDataLakeals Ihr S3-Bucket-Präfix. - Enter
streamingDataLakeErrals Ihr S3-Bucket-Fehlerausgabepräfix.

- Auswählen Lieferstrom erstellen.
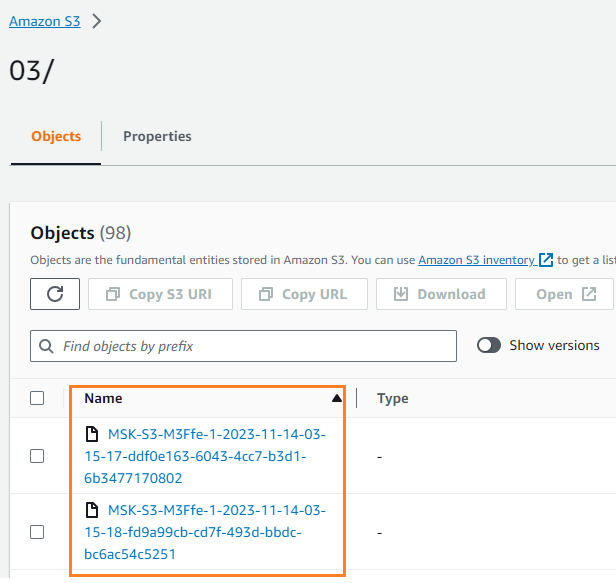
Sie können überprüfen, ob die Daten in Ihren S3-Bucket geschrieben wurden. Das solltest du sehen streamingDataLake Das Verzeichnis wurde erstellt und die Dateien werden in Partitionen gespeichert.
Speichern Sie Ereignisse in DynamoDB
Im letzten Schritt speichern Sie die aktuellsten Modemdaten in DynamoDB. Dadurch kann die Client-Anwendung von überall aus auf den Modemstatus zugreifen und mit dem Modem interagieren, mit geringer Latenz und hoher Verfügbarkeit. Lambda arbeitet nahtlos mit Amazon MSK zusammen. Lambda fragt intern nach neuen Nachrichten von der Ereignisquelle und ruft dann synchron die Ziel-Lambda-Funktion auf. Lambda liest die Nachrichten stapelweise und stellt sie Ihrer Funktion als Ereignisnutzlast zur Verfügung.
Erstellen wir zunächst eine Tabelle in DynamoDB. Beziehen auf DynamoDB-API-Berechtigungen: Referenz zu Aktionen, Ressourcen und Bedingungen um zu überprüfen, ob Ihr Client-Computer über die erforderlichen Berechtigungen verfügt.
- Erstellen Sie eine neue Datei mit dem Namen
createTable.py. - Kopieren Sie den folgenden Code in die Datei und aktualisieren Sie die
regionInformationen:
- Führen Sie die
createTable.pySkript zum Erstellen einer Tabelle namensdevice_statusin DynamoDB:
Lassen Sie uns nun die Lambda-Funktion konfigurieren.
- Wählen Sie auf der Lambda-Konsole Funktionen im Navigationsbereich.
- Auswählen Funktion erstellen.
- Auswählen Autor von Grund auf neu.
- Aussichten für Funktionsname¸ Geben Sie einen Namen ein (z. B.
my-notification-kafka). - Aussichten für Laufzeit, wählen Python 3.11.
- Aussichten für BerechtigungenWählen Verwenden Sie eine vorhandene Rolle und wähle eine Rolle mit Berechtigungen zum Lesen aus Ihrem Cluster.
- Erstellen Sie die Funktion.
Auf der Konfigurationsseite der Lambda-Funktion können Sie jetzt Quellen, Ziele und Ihren Anwendungscode konfigurieren.
- Auswählen Trigger hinzufügen.
- Aussichten für Konfiguration auslösen, eingeben
MSKum Amazon MSK als Auslöser für die Lambda-Quellfunktion zu konfigurieren. - Aussichten für MSK-Cluster, eingeben
myCluster. - Deaktivieren Auslöser aktivieren, weil Sie Ihre Lambda-Funktion noch nicht konfiguriert haben.
- Aussichten für Chargengröße, eingeben
100. - Aussichten für Startposition, wählen Aktuelle.
- Aussichten für Themenname¸ Geben Sie einen Namen ein (z. B.
mytopic). - Auswählen Speichern.
- Auf der Lambda-Funktionsdetailseite auf der Code Geben Sie auf der Registerkarte den folgenden Code ein:
- Stellen Sie die Lambda-Funktion bereit.
- Auf dem Konfiguration Tab, wählen Sie Bearbeiten um den Auslöser zu bearbeiten.
- Wählen Sie den Auslöser aus und wählen Sie dann Speichern.
- Wählen Sie in der DynamoDB-Konsole Gegenstände erkunden im Navigationsbereich.
- Wähle den Tisch aus
device_status.
Sie werden sehen, dass Lambda im Kafka-Thema generierte Ereignisse in DynamoDB schreibt.

Zusammenfassung
Streaming-Datenpipelines sind für die Erstellung von Echtzeitanwendungen von entscheidender Bedeutung. Allerdings kann die Einrichtung und Verwaltung der Infrastruktur entmutigend sein. In diesem Beitrag haben wir erläutert, wie Sie mithilfe von Amazon MSK, Lambda, DynamoDB, Amazon Data Firehose und anderen Diensten eine serverlose Streaming-Pipeline auf AWS erstellen. Die Hauptvorteile sind, dass keine Server verwaltet werden müssen, die Infrastruktur automatisch skalierbar ist und ein Pay-as-you-go-Modell mit vollständig verwalteten Diensten zur Verfügung steht.
Sind Sie bereit, Ihre eigene Echtzeit-Pipeline aufzubauen? Beginnen Sie noch heute mit einem kostenlosen AWS-Konto. Mit der Leistung von Serverless können Sie sich auf Ihre Anwendungslogik konzentrieren, während AWS die undifferenzierte Schwerarbeit übernimmt. Lassen Sie uns etwas Großartiges auf AWS aufbauen!
Über die Autoren
 Masudur Rahaman Sayem ist Streaming Data Architect bei AWS. Er arbeitet weltweit mit AWS-Kunden zusammen, um Daten-Streaming-Architekturen zu entwerfen und aufzubauen, um reale Geschäftsprobleme zu lösen. Er ist spezialisiert auf die Optimierung von Lösungen, die Streaming-Datendienste und NoSQL verwenden. Sayem hat eine große Leidenschaft für verteiltes Rechnen.
Masudur Rahaman Sayem ist Streaming Data Architect bei AWS. Er arbeitet weltweit mit AWS-Kunden zusammen, um Daten-Streaming-Architekturen zu entwerfen und aufzubauen, um reale Geschäftsprobleme zu lösen. Er ist spezialisiert auf die Optimierung von Lösungen, die Streaming-Datendienste und NoSQL verwenden. Sayem hat eine große Leidenschaft für verteiltes Rechnen.
 Michael Oguike ist Produktmanager für Amazon MSK. Seine Leidenschaft besteht darin, Daten zu nutzen, um Erkenntnisse zu gewinnen, die zum Handeln führen. Es macht ihm Spaß, Kunden aus den unterschiedlichsten Branchen dabei zu helfen, ihr Geschäft mithilfe von Daten-Streaming zu verbessern. Michael lernt auch gerne aus Büchern und Podcasts etwas über Verhaltenswissenschaft und Psychologie.
Michael Oguike ist Produktmanager für Amazon MSK. Seine Leidenschaft besteht darin, Daten zu nutzen, um Erkenntnisse zu gewinnen, die zum Handeln führen. Es macht ihm Spaß, Kunden aus den unterschiedlichsten Branchen dabei zu helfen, ihr Geschäft mithilfe von Daten-Streaming zu verbessern. Michael lernt auch gerne aus Büchern und Podcasts etwas über Verhaltenswissenschaft und Psychologie.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

