Introduction
The advent of AI and machine learning has revolutionized how we interact with information, making it easier to retrieve, understand, and utilize. In this hands-on guide, we explore creating a sophisticated Q&A assistant powered by LLamA2 and LLamAIndex, leveraging state-of-the-art language models and indexing frameworks to navigate a sea of PDF documents effortlessly. This tutorial is designed to empower developers, data scientists, and tech enthusiasts with the tools and knowledge to build a Retrieval-Augmented Generation (RAG) System that stands on the shoulders of giants in the NLP domain.
In our quest to demystify the creation of an AI-driven Q&A assistant, this guide stands as a bridge between complex theoretical concepts and their practical application in real-world scenarios. By integrating LLamA2’s advanced language comprehension with LLamAIndex’s efficient information retrieval capabilities, we aim to construct a system that answers questions with precision and deepens our understanding of the potential and challenges within the field of NLP. This article serves as a comprehensive roadmap for enthusiasts and professionals, highlighting the synergy between cutting-edge models and the ever-evolving demands of information technology.

Learning Objectives
- Develop an RAG System using the LLamA2 model from Hugging Face.
- Integrate multiple PDF documents.
- Index documents for efficient retrieval.
- Craft a query system.
- Create a robust assistant capable of answering various questions.
- Focus on practical implementation rather than just theoretical aspects.
- Engage in hands-on coding and real-world applications.
- Make the complex world of NLP accessible and engaging.
Table of contents
LLamA2 Model
LLamA2 is a beacon of innovation in natural language processing, pushing the boundaries of what’s possible with language models. Its architecture, designed for both efficiency and effectiveness, allows for an unprecedented understanding and generation of human-like text. Unlike its predecessors like BERT and GPT, LLamA2 offers a more nuanced approach to processing language, making it particularly adept at tasks requiring deep comprehension, such as question answering. Its utility in various NLP tasks, from summarization to translation, showcases its versatility and capability in tackling complex linguistic challenges.

Understanding LLamAIndex
Indexing is the backbone of any efficient information retrieval system. LLamAIndex, a framework designed for document indexing and querying, stands out by providing a seamless way to manage vast collections of documents. It’s not just about storing information; it’s about making it accessible and retrievable in the blink of an eye.

LLamAIndex’s importance cannot be overstated, as it enables real-time query processing across extensive databases, ensuring that our Q&A assistant can provide prompt and accurate responses drawn from a comprehensive knowledge base.
Tokenization and Embeddings
The first step in understanding language models involves breaking down text into manageable pieces, a process known as tokenization. This foundational task is crucial for preparing data for further processing. Following tokenization, the concept of embeddings comes into play, translating words and sentences into numerical vectors.
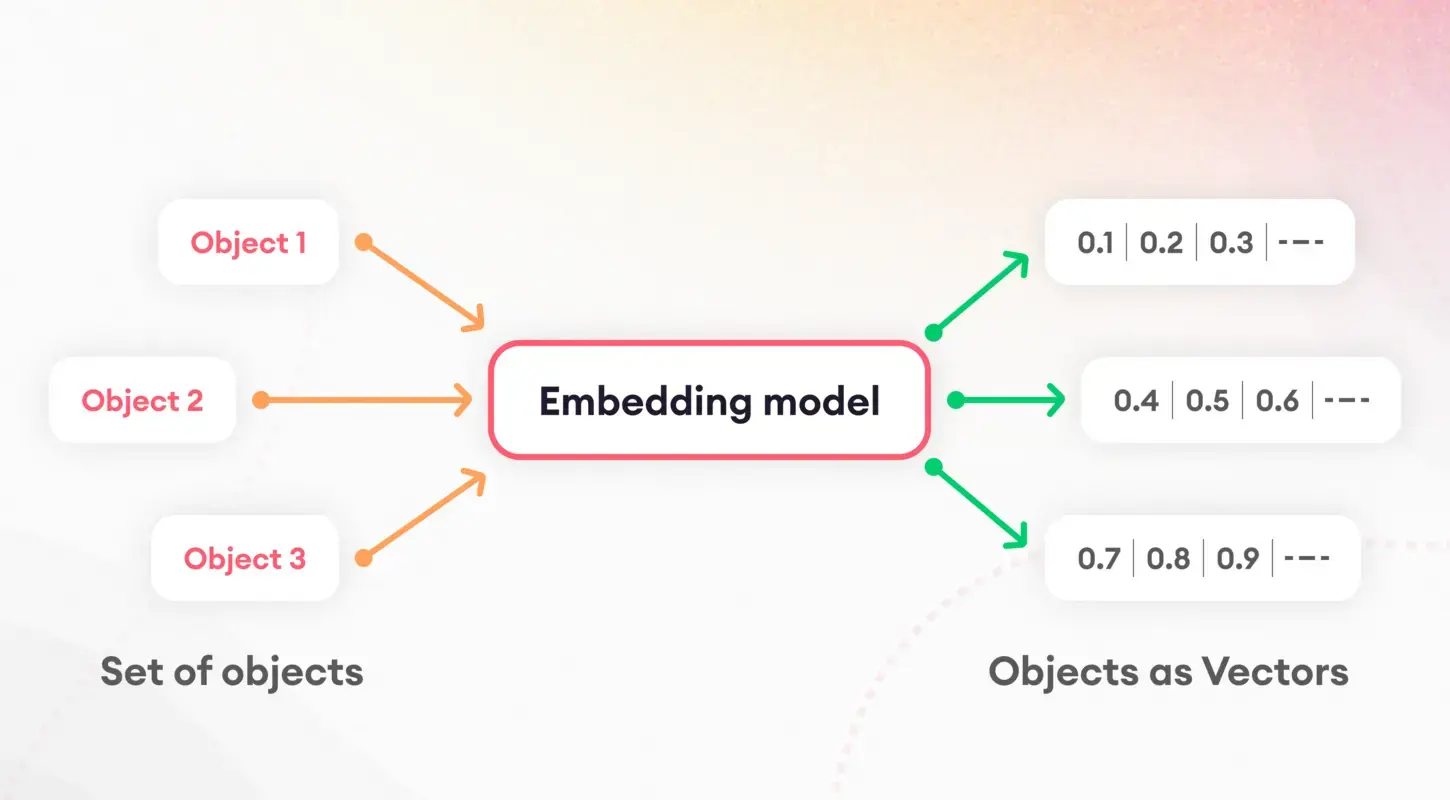
These embeddings capture the essence of linguistic features, enabling models to discern and utilize the underlying semantic properties of text. Particularly, sentence embeddings play a pivotal role in tasks like document similarity and retrieval, forming the basis of our indexing strategy.
Model Quantization
Model quantization presents a strategy to enhance the performance and efficiency of our Q&A assistant. By reducing the precision of the model’s numerical computations, we can significantly decrease its size and speed up inference times. While introducing a trade-off between precision and efficiency, this process is especially valuable in resource-constrained environments such as mobile devices or web applications. Through careful application, quantization allows us to maintain high levels of accuracy while benefiting from reduced latency and storage requirements.
ServiceContext and Query Engine
The ServiceContext within LLamAIndex is a central hub for managing resources and configurations, ensuring that our system operates smoothly and efficiently. The glue holds our application together, enabling seamless integration between the LLamA2 model, the embedding process, and the indexed documents. On the other hand, the query engine is the workhorse that processes user queries, leveraging the indexed data to fetch relevant information swiftly. This dual setup ensures that our Q&A assistant can easily handle complex queries, providing quick and accurate answers to users.
Implementation
Let’s dive into the implementation. Please note that I’ve used Google Colab to create this project.
!pip install pypdf
!pip install -q transformers einops accelerate langchain bitsandbytes
!pip install sentence_transformers
!pip install llama_indexThese commands set the stage by installing the necessary libraries, including transformers for model interaction and sentence_transformers for embeddings. The installation of llama_index is crucial for our indexing framework.
Next, we initialize our components (Make sure to create a folder named “data” in the Files section in Google Colab, and then upload the PDF into the folder):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.prompts.prompts import SimpleInputPrompt
# Reading documents and setting up the system prompt
documents = SimpleDirectoryReader("/content/data").load_data()
system_prompt = """
You are a Q&A assistant. Your goal is to answer questions based on the given documents.
"""
query_wrapper_prompt = SimpleInputPromptAfter setting up our environment and reading the documents, we craft a system prompt to guide the LLamA2 model’s responses. This template is instrumental in ensuring the model’s output aligns with our expectations for accuracy and relevance.
!huggingface-cli login
The above command is a gateway to accessing Hugging Face’s vast repository of models. It requires a token for authentication.
You need to visit the following link: Hugging Face (make sure you first sign on Hugging Face), then create a New Token, provide a Name for the project, select Type as Read, and then click on Generate a token.
This step underscores the importance of securing and personalizing your development environment.
import torch
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.0, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
model_name="meta-llama/Llama-2-7b-chat-hf",
device_map="auto",
model_kwargs={"torch_dtype": torch.float16, "load_in_8bit":True}
)Here, we initialize the LLamA2 model with specific parameters tailored for our Q&A system. This setup highlights the model’s versatility and ability to adapt to different contexts and applications.
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.embeddings.langchain import LangchainEmbedding
embed_model = LangchainEmbedding(
HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"))The choice of embedding model is critical for capturing the semantic essence of our documents. By employing Sentence Transformers, we ensure that our system can accurately gauge the similarity and relevance of textual content, thereby enhancing the efficacy of the indexing process.
service_context = ServiceContext.from_defaults(
chunk_size=1024,
llm=llm,
embed_model=embed_model
)The ServiceContext is instantiated with default settings, linking our LLamA2 model and embedding the model within a cohesive framework. This step ensures that all system components are harmonized and ready for indexing and querying operations.
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()These lines mark the culmination of our setup process, where we index our documents and prepare the query engine. This setup is pivotal for transitioning data preparation to actionable insights, enabling our Q&A assistant to respond to queries based on the indexed content.
response = query_engine.query("Give me a Summary of the PDF in 10 pointers.")
print(response)Finally, we tested our system by querying it for summaries and insights derived from our document collection. This interaction demonstrates the practical utility of our Q&A assistant and showcases the seamless integration of LLamA2, LLamAIndex, and the underlying NLP technologies that make it possible.
Output:

Ethical and Legal Implications
Developing AI-powered Q&A systems brings several ethical and legal considerations to the forefront. Addressing potential biases in the training data is crucial, as well as ensuring fairness and neutrality in responses. Additionally, adherence to data privacy regulations is paramount, as these systems often handle sensitive information. Developers must navigate these challenges with diligence and integrity, committing to ethical principles that safeguard users and the integrity of the information provided.
Future Directions and Challenges
The field of Q&A systems is ripe with opportunities for innovation, from multi-modal interactions to domain-specific applications. However, these advancements come with their own challenges, including scaling to accommodate vast document collections and ensuring diversity in user queries. The ongoing development and refinement of models like LLamA2 and indexing frameworks like LLamAIndex are critical for overcoming these hurdles and pushing the boundaries of what’s possible in NLP.
Case Studies and Examples
Real-world implementations of Q&A systems, such as customer service bots and educational tools, underscore the versatility and impact of technologies like LLamA2 and LLamAIndex. These case studies demonstrate the practical applications of AI in diverse industries and highlight the success stories and lessons learned, providing valuable insights for future developments.
Conclusion
This guide has traversed the landscape of creating a PDF-based Q&A assistant, from the foundational concepts of LLamA2 and LLamAIndex to the practical implementation steps. As we continue to explore and expand AI’s capabilities in information retrieval and processing, the potential to transform our interaction with knowledge is limitless. Armed with these tools and insights, the journey towards more intelligent and responsive systems is just beginning.
Key Takeaways
- Revolutionizing Information Interaction: The integration of AI and machine learning, exemplified by LLamA2 and LLamAIndex, has transformed how we access and utilize information, paving the way for sophisticated Q&A assistants capable of effortlessly navigating vast collections of PDF documents.
- Practical Bridge between Theory and Application: This guide bridges the gap between theoretical concepts and practical implementation, empowering developers and tech enthusiasts to build Retrieval-Augmented Generation (RAG) Systems that leverage state-of-the-art NLP models and indexing frameworks.
- Importance of Efficient Indexing: LLamAIndex plays a crucial role in efficient information retrieval by indexing vast document collections. This ensures prompt and accurate responses to user queries and enhances the overall functionality of the Q&A assistant.
- Optimization for Performance and Efficiency: Techniques such as model quantization enhance the performance and efficiency of Q&A assistants, allowing for reduced latency and storage requirements without compromising on accuracy.
- Ethical Considerations and Future Directions: Developing AI-powered Q&A systems necessitates addressing ethical and legal implications, including bias mitigation and data privacy. Looking ahead, advancements in Q&A systems present opportunities for innovation while also posing challenges in the scalability and diversity of user queries
Frequently Asked Question
Ans. LLamA2 offers a more nuanced approach to language processing, enabling deep comprehension tasks such as question answering. Its architecture prioritizes efficiency and effectiveness, making it versatile across various NLP tasks.
Ans. LLamAIndex is a framework for document indexing and querying, facilitating real-time query processing across extensive databases. It ensures that Q&A assistants can swiftly retrieve relevant information from comprehensive knowledge bases.
Ans. Embeddings, particularly sentence embeddings, capture the semantic essence of textual content, enabling accurate gauging of similarity and relevance. This enhances the efficacy of the indexing process, improving the assistant’s ability to provide relevant responses.
Ans. Model quantization optimizes performance and efficiency by reducing the size of numerical computations, thereby decreasing latency and storage requirements. While introducing a trade-off between precision and efficiency, it’s valuable in resource-constrained environments.
Ans. Developers must address potential biases in training data, ensure fairness and neutrality in responses, and adhere to data privacy regulations. Upholding ethical principles safeguards users and maintains the integrity of information provided by the Q&A assistant.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.analyticsvidhya.com/blog/2024/04/a-hands-on-guide-to-creating-a-pdf-based-qa-assistant-with-llama-and-llamaindex/

