Khối lượng dữ liệu được tạo ra trên toàn cầu tiếp tục tăng, từ trò chơi, bán lẻ và tài chính đến sản xuất, chăm sóc sức khỏe và du lịch. Các tổ chức đang tìm kiếm nhiều cách hơn để nhanh chóng sử dụng luồng dữ liệu liên tục nhằm đổi mới cho doanh nghiệp và khách hàng của họ. Họ phải nắm bắt, xử lý, phân tích và tải dữ liệu vào vô số kho dữ liệu một cách đáng tin cậy, tất cả đều theo thời gian thực.
Apache Kafka là một lựa chọn phổ biến cho các nhu cầu phát trực tuyến theo thời gian thực này. Tuy nhiên, việc thiết lập cụm Kafka cùng với các thành phần xử lý dữ liệu khác có thể tự động mở rộng quy mô tùy thuộc vào nhu cầu ứng dụng của bạn có thể là một thách thức. Bạn có nguy cơ cung cấp dưới mức cho lưu lượng truy cập cao điểm, điều này có thể dẫn đến thời gian ngừng hoạt động hoặc cung cấp quá mức cho tải cơ sở, dẫn đến lãng phí. AWS cung cấp nhiều dịch vụ serverless như Truyền trực tuyến được quản lý của Amazon cho Apache Kafka (Amazon MSK), Firehose dữ liệu của Amazon, Máy phát điện Amazonvà AWS Lambda quy mô đó tự động tùy thuộc vào nhu cầu của bạn.
Trong bài đăng này, chúng tôi giải thích cách bạn có thể sử dụng một số dịch vụ này, bao gồm MSK không có máy chủ, để xây dựng nền tảng dữ liệu không có máy chủ nhằm đáp ứng nhu cầu thời gian thực của bạn.
Tổng quan về giải pháp
Hãy tưởng tượng một kịch bản. Bạn chịu trách nhiệm quản lý hàng nghìn modem cho một nhà cung cấp dịch vụ Internet được triển khai trên nhiều khu vực địa lý. Bạn muốn giám sát chất lượng kết nối của modem có tác động đáng kể đến năng suất và sự hài lòng của khách hàng. Việc triển khai của bạn bao gồm các modem khác nhau cần được theo dõi và bảo trì để đảm bảo thời gian ngừng hoạt động ở mức tối thiểu. Mỗi thiết bị truyền hàng nghìn bản ghi 1 KB mỗi giây, chẳng hạn như mức sử dụng CPU, mức sử dụng bộ nhớ, cảnh báo và trạng thái kết nối. Bạn muốn truy cập theo thời gian thực vào dữ liệu này để có thể theo dõi hiệu suất trong thời gian thực, đồng thời phát hiện và giảm thiểu sự cố một cách nhanh chóng. Bạn cũng cần có quyền truy cập lâu dài hơn vào dữ liệu này cho các mô hình máy học (ML) để chạy các đánh giá bảo trì mang tính dự đoán, tìm cơ hội tối ưu hóa và dự báo nhu cầu.
Những khách hàng thu thập dữ liệu tại chỗ của bạn được viết bằng Python và họ có thể gửi tất cả dữ liệu dưới dạng chủ đề Apache Kafka tới Amazon MSK. Để truy cập dữ liệu theo thời gian thực và độ trễ thấp cho ứng dụng của bạn, bạn có thể sử dụng Lambda và DynamoDB. Để lưu trữ dữ liệu lâu dài hơn, bạn có thể sử dụng dịch vụ trình kết nối serverless được quản lý Firehose dữ liệu của Amazon để gửi dữ liệu đến hồ dữ liệu của bạn.
Sơ đồ sau đây cho thấy cách bạn có thể xây dựng ứng dụng serverless toàn diện này.
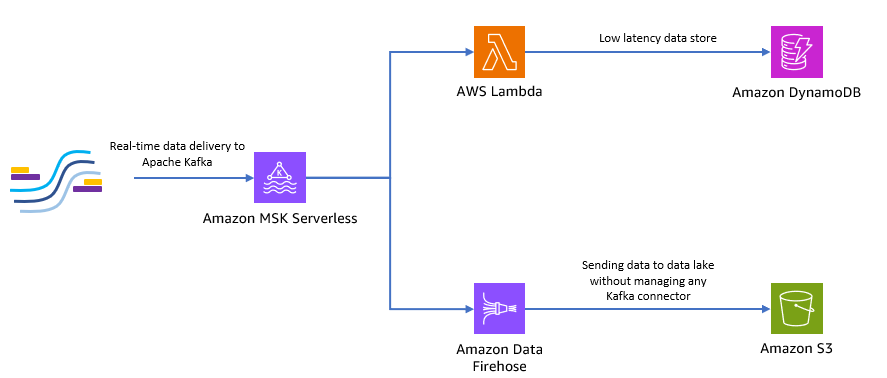
Hãy làm theo các bước trong các phần sau để triển khai kiến trúc này.
Tạo cụm Kafka không có máy chủ trên Amazon MSK
Chúng tôi sử dụng Amazon MSK để nhập dữ liệu đo từ xa theo thời gian thực từ modem. Việc tạo cụm Kafka không có máy chủ trên Amazon MSK rất đơn giản. Chỉ mất vài phút sử dụng Bảng điều khiển quản lý AWS hoặc AWS SDK. Để sử dụng bảng điều khiển, hãy tham khảo Bắt đầu sử dụng các cụm MSK Serverless. Bạn tạo một cụm không có máy chủ, Quản lý truy cập và nhận dạng AWS (IAM) và máy khách.
Tạo chủ đề Kafka bằng Python
Khi cụm và máy khách của bạn đã sẵn sàng, hãy SSH vào máy khách của bạn và cài đặt Kafka Python cũng như thư viện MSK IAM cho Python.
- Chạy các lệnh sau để cài đặt Kafka Python và Thư viện MSK IAM:
- Tạo một tệp mới gọi là
createTopic.py. - Sao chép đoạn mã sau vào tập tin này, thay thế
bootstrap_serversvàregionthông tin chi tiết cho cụm của bạn. Để biết hướng dẫn truy xuấtbootstrap_serversthông tin cho cụm MSK của bạn, xem Nhận trình môi giới bootstrap cho cụm Amazon MSK.
- Chạy
createTopic.pytập lệnh để tạo một chủ đề Kafka mới có tênmytopictrên cụm không có máy chủ của bạn:
Tạo bản ghi bằng Python
Hãy tạo một số dữ liệu đo từ xa mẫu của modem.
- Tạo một tệp mới gọi là
kafkaDataGen.py. - Sao chép đoạn mã sau vào tập tin này, cập nhật
BROKERSvàregionthông tin chi tiết cho cụm của bạn:
- Chạy
kafkaDataGen.pyđể liên tục tạo dữ liệu ngẫu nhiên và xuất bản nó lên chủ đề Kafka được chỉ định:
Lưu trữ sự kiện trong Amazon S3
Bây giờ bạn lưu trữ tất cả dữ liệu sự kiện thô trong một Dịch vụ lưu trữ đơn giản của Amazon Hồ dữ liệu (Amazon S3) để phân tích. Bạn có thể sử dụng cùng một dữ liệu để huấn luyện các mô hình ML. Các tích hợp với Amazon Data Firehose cho phép Amazon MSK tải dữ liệu liền mạch từ các cụm Apache Kafka của bạn vào hồ dữ liệu S3. Hoàn thành các bước sau để liên tục truyền dữ liệu từ Kafka đến Amazon S3, loại bỏ nhu cầu xây dựng hoặc quản lý các ứng dụng trình kết nối của riêng bạn:
- Trên bảng điều khiển Amazon S3, tạo một nhóm mới. Bạn cũng có thể sử dụng nhóm hiện có.
- Tạo một thư mục mới trong nhóm S3 của bạn có tên là
streamingDataLake. - Trên bảng điều khiển Amazon MSK, chọn cụm MSK Serverless của bạn.
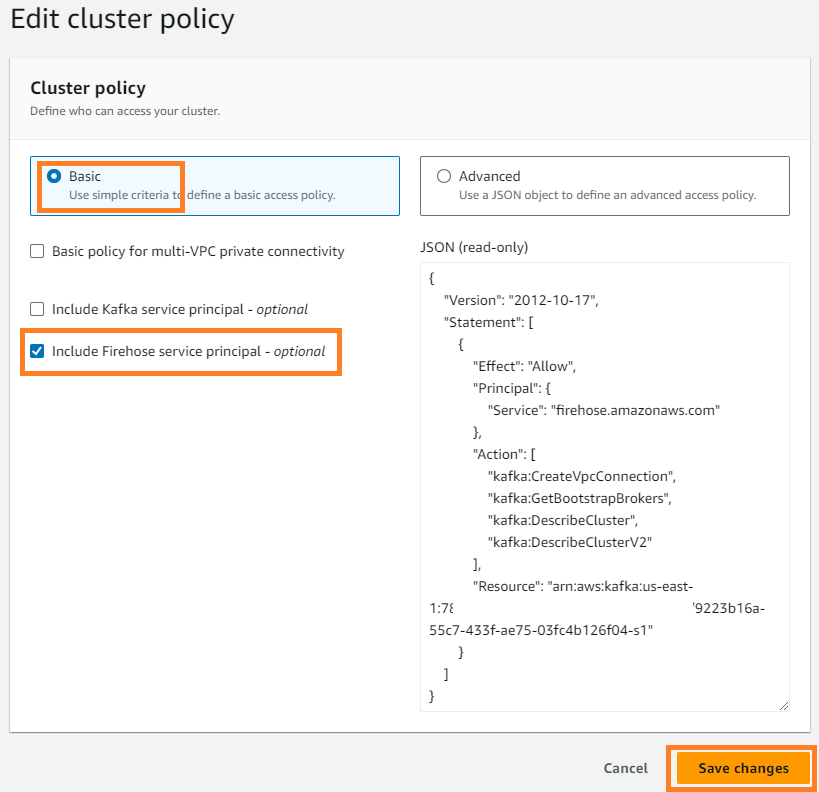
- trên Hoạt động menu, chọn Chỉnh sửa chính sách cụm.

- Chọn Bao gồm dịch vụ chính của Firehose Và chọn Lưu các thay đổi.
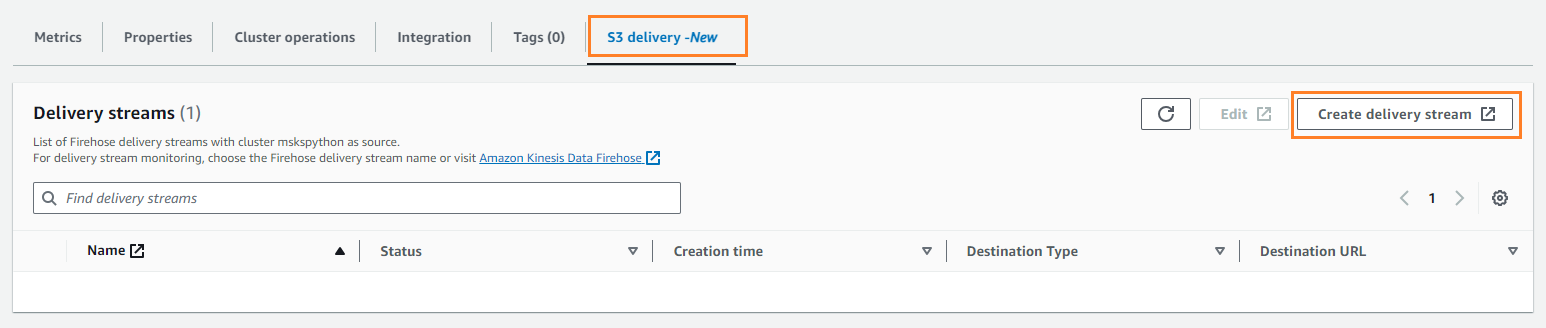
- trên Giao hàng S3 tab, chọn Tạo luồng phân phối.
- Trong nguồn, chọn Amazon MSK.
- Trong Nơi đến, chọn Amazon S3.

- Trong Kết nối cụm Amazon MSK, lựa chọn Môi giới bootstrap tư nhân.
- Trong Đề tài, nhập tên chủ đề (đối với bài đăng này,
mytopic).
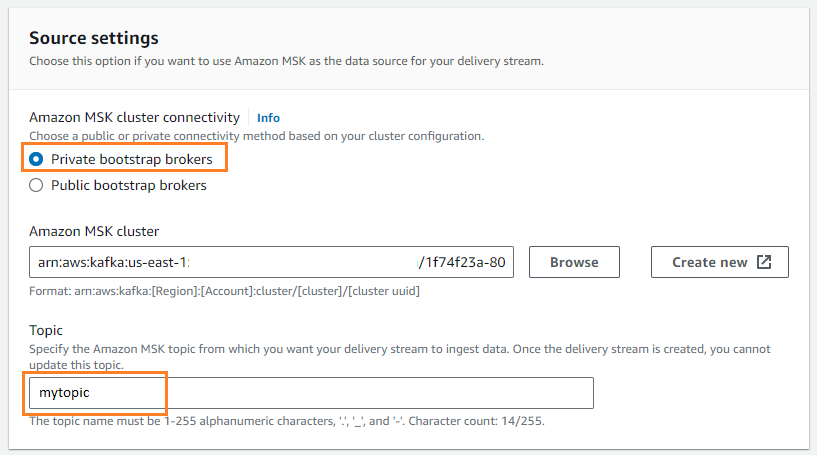
- Trong Xô S3, chọn Xem và chọn nhóm S3 của bạn.
- đăng ký hạng mục thi
streamingDataLakelàm tiền tố nhóm S3 của bạn. - đăng ký hạng mục thi
streamingDataLakeErrlàm tiền tố đầu ra lỗi nhóm S3 của bạn.

- Chọn Tạo luồng phân phối.
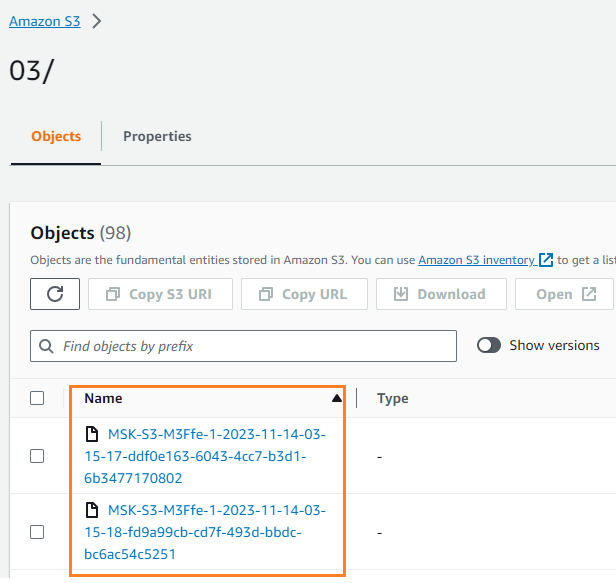
Bạn có thể xác minh rằng dữ liệu đã được ghi vào bộ chứa S3 của bạn. Bạn nên thấy rằng streamingDataLake thư mục đã được tạo và các tập tin được lưu trữ trong các phân vùng.
Lưu trữ sự kiện trong DynamoDB
Ở bước cuối cùng, bạn lưu trữ dữ liệu modem gần đây nhất trong DynamoDB. Điều này cho phép ứng dụng khách truy cập trạng thái modem và tương tác với modem từ xa từ mọi nơi, với độ trễ thấp và tính sẵn sàng cao. Lambda hoạt động liền mạch với Amazon MSK. Lambda thăm dò nội bộ để tìm tin nhắn mới từ nguồn sự kiện, sau đó gọi hàm Lambda đích một cách đồng bộ. Lambda đọc tin nhắn theo đợt và cung cấp những tin nhắn này cho hàm của bạn dưới dạng trọng tải sự kiện.
Trước tiên hãy tạo một bảng trong DynamoDB. tham khảo Quyền API DynamoDB: Tham chiếu hành động, tài nguyên và điều kiện để xác minh rằng máy khách của bạn có các quyền cần thiết.
- Tạo một tệp mới gọi là
createTable.py. - Sao chép đoạn mã sau vào tệp, cập nhật
regionthông tin:
- Chạy
createTable.pytập lệnh để tạo một bảng có têndevice_statustrong DynamoDB:
Bây giờ hãy cấu hình hàm Lambda.
- Trên bảng điều khiển Lambda, chọn Chức năng trong khung điều hướng.
- Chọn Tạo chức năng.
- Chọn Tác giả từ đầu.
- Trong Tên chức năng¸ nhập tên (ví dụ:
my-notification-kafka). - Trong Runtime, chọn Python 3.11.
- Trong Quyền, lựa chọn Sử dụng vai trò hiện có và chọn một vai trò với quyền đọc từ cụm của bạn.
- Tạo chức năng.
Trên trang cấu hình hàm Lambda, giờ đây bạn có thể định cấu hình nguồn, đích và mã ứng dụng của mình.
- Chọn Thêm trình kích hoạt.
- Trong cấu hình kích hoạt, đi vào
MSKđể đặt cấu hình Amazon MSK làm trình kích hoạt cho hàm nguồn Lambda. - Trong cụm MSK, đi vào
myCluster. - Bỏ chọn Kích hoạt trình kích hoạt, vì bạn chưa định cấu hình hàm Lambda của mình.
- Trong Kích thước lô, đi vào
100. - Trong Điểm xuất phát, chọn Mới nhất.
- Trong Tên chủ đề¸ nhập tên (ví dụ:
mytopic). - Chọn Thêm.
- Trên trang chi tiết hàm Lambda, trên Mã tab, nhập mã sau đây:
- Triển khai hàm Lambda.
- trên Cấu hình tab, chọn Chỉnh sửa để chỉnh sửa trình kích hoạt.
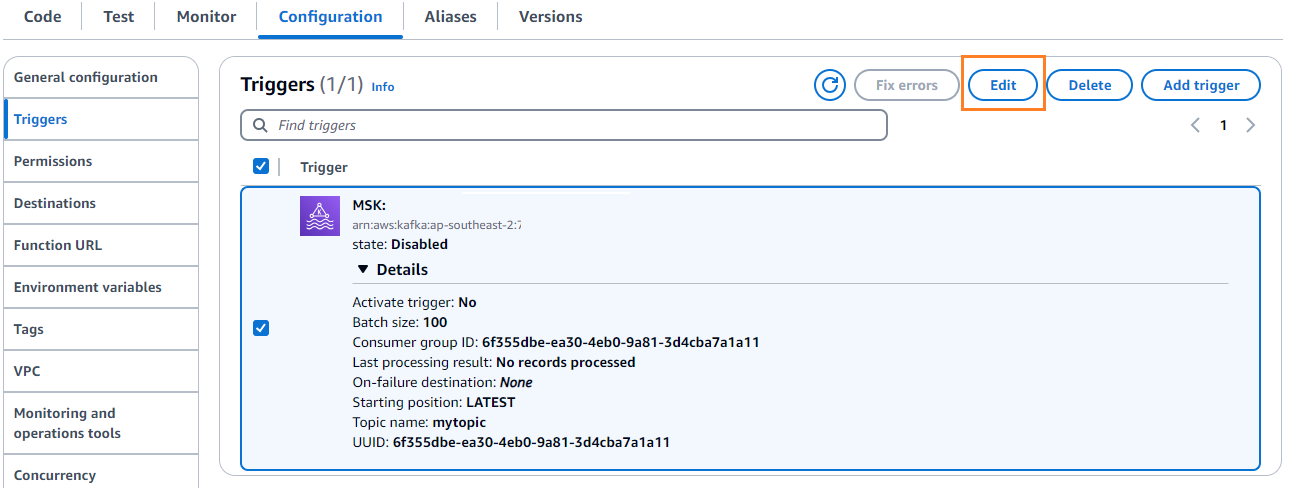
- Chọn trình kích hoạt, sau đó chọn Lưu.
- Trên bảng điều khiển DynamoDB, chọn Khám phá các mục trong khung điều hướng.
- Chọn bàn
device_status.
Bạn sẽ thấy Lambda đang ghi các sự kiện được tạo trong chủ đề Kafka vào DynamoDB.

Tổng kết
Đường truyền dữ liệu truyền trực tuyến rất quan trọng để xây dựng các ứng dụng thời gian thực. Tuy nhiên, việc thiết lập và quản lý cơ sở hạ tầng có thể khó khăn. Trong bài đăng này, chúng tôi đã hướng dẫn cách xây dựng đường truyền phát trực tuyến không có máy chủ trên AWS bằng cách sử dụng Amazon MSK, Lambda, DynamoDB, Amazon Data Firehose và các dịch vụ khác. Những lợi ích chính là không cần quản lý máy chủ, khả năng mở rộng tự động của cơ sở hạ tầng và mô hình trả tiền theo nhu cầu sử dụng các dịch vụ được quản lý hoàn toàn.
Bạn đã sẵn sàng xây dựng quy trình thời gian thực của riêng mình chưa? Hãy bắt đầu ngay hôm nay với tài khoản AWS miễn phí. Với sức mạnh của serverless, bạn có thể tập trung vào logic ứng dụng của mình trong khi AWS xử lý những công việc nặng nhọc không phân biệt. Hãy cùng xây dựng điều gì đó tuyệt vời trên AWS!
Về các tác giả
 Masudur Rahaman Sayem là Kiến trúc sư truyền dữ liệu tại AWS. Anh làm việc với khách hàng AWS trên toàn cầu để thiết kế và xây dựng kiến trúc truyền dữ liệu nhằm giải quyết các vấn đề kinh doanh trong thế giới thực. Ông chuyên về các giải pháp tối ưu hóa sử dụng dịch vụ truyền dữ liệu trực tuyến và NoSQL. Sayem rất đam mê điện toán phân tán.
Masudur Rahaman Sayem là Kiến trúc sư truyền dữ liệu tại AWS. Anh làm việc với khách hàng AWS trên toàn cầu để thiết kế và xây dựng kiến trúc truyền dữ liệu nhằm giải quyết các vấn đề kinh doanh trong thế giới thực. Ông chuyên về các giải pháp tối ưu hóa sử dụng dịch vụ truyền dữ liệu trực tuyến và NoSQL. Sayem rất đam mê điện toán phân tán.
 Michael Oguike là Giám đốc sản phẩm của Amazon MSK. Anh ấy đam mê sử dụng dữ liệu để khám phá những hiểu biết sâu sắc thúc đẩy hành động. Anh ấy thích giúp đỡ khách hàng từ nhiều ngành khác nhau cải thiện hoạt động kinh doanh của họ bằng cách sử dụng truyền dữ liệu. Michael cũng thích tìm hiểu về khoa học hành vi và tâm lý học từ sách và podcast.
Michael Oguike là Giám đốc sản phẩm của Amazon MSK. Anh ấy đam mê sử dụng dữ liệu để khám phá những hiểu biết sâu sắc thúc đẩy hành động. Anh ấy thích giúp đỡ khách hàng từ nhiều ngành khác nhau cải thiện hoạt động kinh doanh của họ bằng cách sử dụng truyền dữ liệu. Michael cũng thích tìm hiểu về khoa học hành vi và tâm lý học từ sách và podcast.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

