Trong không gian phân tích dữ liệu, các tổ chức thường xử lý nhiều bảng trong cơ sở dữ liệu và định dạng tệp khác nhau để giữ dữ liệu cho các chức năng kinh doanh khác nhau. Nhu cầu kinh doanh thường thúc đẩy cấu trúc bảng, chẳng hạn như tiến hóa lược đồ (thêm các cột mới, loại bỏ các cột hiện có, cập nhật tên cột, v.v.) cho một số bảng trong một chức năng kinh doanh yêu cầu các chức năng kinh doanh khác sao chép giống nhau . Bài đăng này tập trung vào các thay đổi lược đồ như vậy trong các bảng dựa trên tệp và chỉ ra cách tự động sao chép quá trình phát triển lược đồ của dữ liệu có cấu trúc từ các định dạng bảng trong cơ sở dữ liệu sang các bảng được lưu trữ dưới dạng tệp theo cách tiết kiệm chi phí.
Keo AWS là một dịch vụ tích hợp dữ liệu không có máy chủ giúp dễ dàng khám phá, chuẩn bị và kết hợp dữ liệu để phân tích, học máy (ML) và phát triển ứng dụng. Trong bài đăng này, chúng tôi trình bày cách sử dụng Apache Hudi, lớp cơ sở dữ liệu tự quản lý trên kho dữ liệu dựa trên tệp, trong AWS Glue để tự động biểu thị dữ liệu ở dạng quan hệ và quản lý quá trình phát triển lược đồ của chúng trên quy mô lớn bằng cách sử dụng Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), Dịch vụ di chuyển cơ sở dữ liệu AWS (AWS DMS), AWS Lambda, Keo AWS, Máy phát điện Amazon, Amazon cực quangvà amazon Athena để tự động xác định sự phát triển của lược đồ và áp dụng nó để quản lý tải dữ liệu ở quy mô petabyte.
Apache Hudi hỗ trợ các giao dịch ACID và hoạt động CRUD trên hồ dữ liệu. Điều này đặt nền tảng của kiến trúc hồ dữ liệu bằng cách cho phép hỗ trợ giao dịch, phát triển và quản lý lược đồ, tách bộ lưu trữ khỏi điện toán và đảm bảo hỗ trợ khả năng truy cập thông qua các công cụ kinh doanh thông minh (BI). Trong bài đăng này, chúng tôi triển khai kiến trúc để xây dựng hồ dữ liệu giao dịch dựa trên các tính năng Hudi đã nói ở trên.
Tổng quan về giải pháp
Bài đăng này giả định một kịch bản có nhiều bảng trong cơ sở dữ liệu nguồn và chúng tôi muốn sao chép mọi thay đổi lược đồ trong bất kỳ bảng nào trong bảng Hudi của Apache trong hồ dữ liệu. Nó sử dụng hỗ trợ riêng cho Apache Hudi trên AWS Keo cho Apache Spark.
Trong bài đăng này, quá trình phát triển lược đồ của các bảng nguồn trong cơ sở dữ liệu Aurora được ghi lại qua AWS DMS tải gia tăng hoặc thu thập dữ liệu thay đổi (CDC) và quá trình phát triển lược đồ tương tự được sao chép trong các bảng Hudi của Apache được lưu trữ trong Amazon S3. Các bảng Hudi của Apache được phát hiện bởi AWS Glue Data Catalog và được truy vấn bởi Athena. Một tác vụ AWS Glue, được hỗ trợ bởi một quy trình phối hợp sử dụng Lambda và bảng DynamoDB, đảm nhận việc sao chép tự động quá trình phát triển lược đồ trong các bảng Hudi của Apache.
Chúng tôi sử dụng Aurora làm nguồn dữ liệu mẫu nhưng bất kỳ nguồn dữ liệu nào hỗ trợ các thao tác Tạo, Đọc, Cập nhật và Xóa (CRUD) đều có thể thay thế Aurora trong trường hợp sử dụng của bạn.
Sơ đồ sau minh họa kiến trúc giải pháp của chúng tôi.

Dòng chảy của giải pháp như sau:
- Aurora, dưới dạng nguồn dữ liệu mẫu, chứa bảng RDBMS có nhiều hàng và AWS DMS thực hiện tải toàn bộ dữ liệu đó vào bộ chứa S3 (mà chúng tôi gọi là bộ chứa thô). Chúng tôi hy vọng rằng bạn có thể có nhiều bảng nguồn, nhưng vì mục đích trình diễn, chúng tôi chỉ sử dụng một bảng nguồn trong bài đăng này.
- Chúng tôi kích hoạt một hàm Lambda với tên bảng nguồn làm sự kiện để các tham số tương ứng của bảng nguồn được đọc từ DynamoDB. Để lên lịch hoạt động này cho các khoảng thời gian cụ thể, chúng tôi lịch trình Sự kiện Amazon để kích hoạt Lambda với tên bảng làm tham số.
- Có nhiều bảng trong cơ sở dữ liệu nguồn và chúng tôi muốn chạy một tác vụ AWS Glue cho mỗi bảng nguồn để đơn giản hóa thao tác. Vì chúng tôi sử dụng từng công việc AWS Glue để cập nhật từng bảng Apache Hudi, nên bài đăng này sử dụng bảng DynamoDB để giữ các tham số cấu hình được sử dụng bởi từng công việc AWS Glue cho từng bảng Apache Hudi. Bảng DynamoDB chứa từng tên bảng Apache Hudi, tên tác vụ AWS Glue tương ứng, trạng thái tác vụ AWS Glue, trạng thái tải (đầy đủ hoặc delta), khóa phân vùng, khóa bản ghi và lược đồ để chuyển sang tác vụ AWS Glue của bảng tương ứng. Các giá trị trong bảng DynamoDB là các giá trị tĩnh.
- Để kích hoạt song song từng tác vụ AWS Glue (10 G.1X DPU) nhằm chạy một mã cụ thể của Apache Hudi để chèn dữ liệu vào các bảng Hudi tương ứng, Lambda chuyển các tham số cụ thể của từng bảng Hudi Apache được đọc từ DynamoDB sang từng tác vụ AWS Glue. Dữ liệu nguồn đến từ các bảng trong cơ sở dữ liệu nguồn Aurora thông qua AWS DMS với tải đầy đủ và tải tăng dần hoặc CDC.
Tạo tài nguyên với AWS CloudFormation
Chúng tôi cung cấp một Hình thành đám mây AWS mẫu để tạo các tài nguyên sau:
- Lambda và DynamoDB với vai trò là người điều phối quản lý tải dữ liệu
- Bộ chứa S3 dành cho vùng thô, vùng được tinh chỉnh và nội dung để giữ mã cho quá trình phát triển lược đồ
- Một tác vụ AWS Glue để cập nhật các bảng Hudi và thực hiện quá trình phát triển lược đồ, cả tương thích xuôi và ngược
Bảng Aurora và phiên bản sao chép AWS DMS không được cung cấp qua ngăn xếp này. Để biết hướng dẫn thiết lập Aurora, hãy tham khảo Tạo cụm Amazon Aurora DB.
Khởi chạy ngăn xếp sau và cung cấp tên ngăn xếp của bạn.
eu-west-1 |
Lược đồ tiến hóa
Để truy cập cơ sở dữ liệu Aurora của bạn, hãy tham khảo Làm cách nào để kết nối với phiên bản Amazon RDS cho MySQL của tôi bằng cách sử dụng MySQL Workbench. Sau đó hoàn thành các bước sau:
- Tạo một bảng có tên đối tượng theo các truy vấn trong cơ sở dữ liệu Aurora và thay đổi lược đồ của nó để chúng ta có thể thấy quá trình phát triển của lược đồ được phản ánh ở cấp hồ dữ liệu:
Sau khi bạn tạo ngăn xếp, cần thực hiện một số bước thủ công để chuẩn bị từ đầu đến cuối giải pháp.
- Tạo AWS DMS ví dụ, AWSDMS thiết bị đầu cuốivà AWS DMS công việc với các cấu hình sau:
- Thêm dataFormat dưới dạng Parquet vào điểm cuối đích.
- Trỏ điểm cuối đích của AWS DMS vào bộ chứa thô, được định dạng là
raw-bucket-<account_number>-<region_name>và tên thư mục phải là POC.
- Bắt đầu tác vụ AWS DMS.
- Tạo một sự kiện thử nghiệm trong
HudiLambdaHàm Lambda với nội dung của sự kiện JSON làPOC.dbvà lưu nó. - Chạy hàm Lambda.
Trong bài đăng này, sự phát triển lược đồ được phản ánh thông qua đồng bộ Hudi Hive trong Keo AWS. Bạn không thay đổi riêng các truy vấn trong hồ dữ liệu.
Bây giờ chúng tôi hoàn thành các bước sau để thay đổi lược đồ tại nguồn. Kích hoạt hàm Lambda sau mỗi bước để tạo tệp trong POC/db/object thư mục trong thùng thô. AWS DMS gần như ngay lập tức chọn các thay đổi lược đồ và báo cáo cho bộ chứa thô.
- Thêm một cột được gọi là
test_columnvào bảng nguồnobjecttrong cơ sở dữ liệu Aurora của bạn:
- Đổi tên cột
new_field_1đếnnew_field_2trong đối tượng bảng nguồn:
Cột new_field_1 dự kiến sẽ ở trong bảng Hudi nhưng không có bất kỳ giá trị mới nào được đưa vào bảng nữa.
- Xóa cột
new_field_2từ đối tượng bảng nguồn:
Tương tự như thao tác trước, cột new_field_2 dự kiến sẽ ở trong bảng Hudi nhưng không có bất kỳ giá trị mới nào được đưa vào bảng nữa.
Nếu bạn đã có Sự hình thành hồ AWS quyền dữ liệu được thiết lập trong tài khoản của mình, bạn có thể gặp sự cố về quyền. Trong trường hợp đó, hãy cấp toàn quyền (Super) cho cơ sở dữ liệu mặc định (trước khi kích hoạt hàm Lambda) và tất cả các bảng trong POC.db cơ sở dữ liệu (sau khi tải xong).
Xem lại kết quả
Khi quá trình chạy nói trên xảy ra sau khi lược đồ thay đổi, các kết quả sau đây được tạo trong nhóm đã tinh chỉnh. Chúng ta có thể xem các bảng Apache Hudi với nội dung của nó trong Athena. Để thiết lập Athena, hãy tham khảo Bắt đầu.
Bảng và cơ sở dữ liệu có sẵn trong AWS Glue Data Catalog và sẵn sàng để duyệt lược đồ.
Trước khi lược đồ thay đổi, kết quả Athena trông giống như ảnh chụp màn hình sau.

Sau khi bạn thêm cột test_column và chèn một giá trị vào test_column trường trong bảng đối tượng trong cơ sở dữ liệu Aurora, cột mới (test_column) được phản ánh trong bảng Hudi Apache tương ứng của nó trong hồ dữ liệu.
Ảnh chụp màn hình sau đây hiển thị kết quả trong Athena.

Sau khi bạn đổi tên cột new_field_1 đến new_field_2 và chèn một giá trị vào new_field_2 trường trong bảng đối tượng, cột được đổi tên (new_field_2) được phản ánh trong bảng Apache Hudi tương ứng của nó trong hồ dữ liệu và new_field_1 vẫn còn trong lược đồ, không có giá trị mới nào được điền vào cột.
Ảnh chụp màn hình sau đây hiển thị kết quả trong Athena.
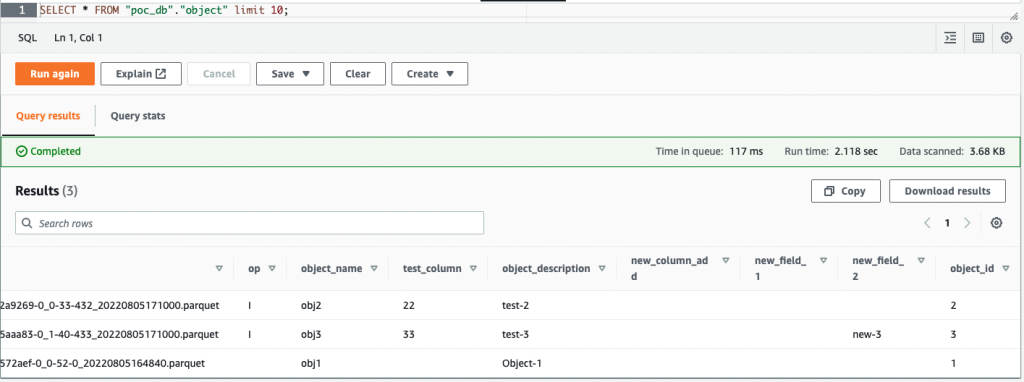
Sau khi bạn xóa cột new_field_2 trong bảng đối tượng và chèn hoặc cập nhật bất kỳ giá trị nào dưới bất kỳ cột nào trong bảng đối tượng, cột đã xóa (new_field_2) vẫn nằm trong lược đồ bảng Apache Hudi tương ứng, không có giá trị mới nào được điền vào cột.
Ảnh chụp màn hình sau đây hiển thị kết quả trong Athena.

Làm sạch
Khi bạn hoàn thành giải pháp này, hãy xóa dữ liệu mẫu trong các bộ chứa S3 thô và tinh chỉnh, đồng thời xóa các bộ chứa.
Ngoài ra, hãy xóa ngăn xếp CloudFormation để xóa tất cả tài nguyên dịch vụ được sử dụng trong giải pháp này.
Kết luận
Bài đăng này cho thấy cách triển khai quá trình phát triển lược đồ bằng giải pháp nguồn mở bằng cách sử dụng Apache Hudi trong môi trường AWS với đường dẫn điều phối.
Bạn có thể khám phá sự khác biệt cấu hình của AWS Glue để thay đổi cấu trúc công việc AWS Glue và triển khai nó cho phân tích dữ liệu của bạn và các trường hợp sử dụng khác.
Về các tác giả
 Subhro Bose là Kiến trúc sư dữ liệu cấp cao trong Nền tảng thông minh và công nghệ mới nổi ở Amazon. Anh ấy thích giải quyết các vấn đề khoa học bằng các công nghệ mới nổi như AI/ML, dữ liệu lớn, lượng tử, v.v. để giúp các doanh nghiệp thuộc các ngành dọc khác nhau thành công trong hành trình đổi mới của họ. Khi rảnh rỗi, anh ấy thích chơi bóng bàn, tìm hiểu các lý thuyết về kinh tế môi trường và khám phá những chiếc bánh nướng xốp ngon nhất khắp thành phố.
Subhro Bose là Kiến trúc sư dữ liệu cấp cao trong Nền tảng thông minh và công nghệ mới nổi ở Amazon. Anh ấy thích giải quyết các vấn đề khoa học bằng các công nghệ mới nổi như AI/ML, dữ liệu lớn, lượng tử, v.v. để giúp các doanh nghiệp thuộc các ngành dọc khác nhau thành công trong hành trình đổi mới của họ. Khi rảnh rỗi, anh ấy thích chơi bóng bàn, tìm hiểu các lý thuyết về kinh tế môi trường và khám phá những chiếc bánh nướng xốp ngon nhất khắp thành phố.
 Ketan Karalkar là Chuyên gia tư vấn giải pháp dữ liệu lớn tại AWS. Ông có gần 2 thập kỷ kinh nghiệm giúp khách hàng thiết kế và xây dựng các giải pháp phân tích dữ liệu và cơ sở dữ liệu. Anh ấy tin vào việc sử dụng công nghệ như một công cụ hỗ trợ để giải quyết các vấn đề kinh doanh thực tế.
Ketan Karalkar là Chuyên gia tư vấn giải pháp dữ liệu lớn tại AWS. Ông có gần 2 thập kỷ kinh nghiệm giúp khách hàng thiết kế và xây dựng các giải pháp phân tích dữ liệu và cơ sở dữ liệu. Anh ấy tin vào việc sử dụng công nghệ như một công cụ hỗ trợ để giải quyết các vấn đề kinh doanh thực tế.
 Phương Eva là Nhà khoa học dữ liệu trong Dịch vụ chuyên nghiệp tại AWS. Cô đam mê sử dụng công nghệ để cung cấp giá trị cho khách hàng và đạt được kết quả kinh doanh. Cô ấy sống ở London, khi rảnh rỗi, cô ấy thích xem phim và nhạc kịch.
Phương Eva là Nhà khoa học dữ liệu trong Dịch vụ chuyên nghiệp tại AWS. Cô đam mê sử dụng công nghệ để cung cấp giá trị cho khách hàng và đạt được kết quả kinh doanh. Cô ấy sống ở London, khi rảnh rỗi, cô ấy thích xem phim và nhạc kịch.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/automate-schema-evolution-at-scale-with-apache-hudi-in-aws-glue/

