
Hình ảnh của Freepik
Xử lý ngôn ngữ tự nhiên, hay NLP, là một lĩnh vực trong trí tuệ nhân tạo để máy móc có khả năng hiểu dữ liệu văn bản. Nghiên cứu NLP đã có từ lâu nhưng chỉ gần đây nó mới trở nên nổi bật hơn với sự ra đời của dữ liệu lớn và khả năng xử lý tính toán cao hơn.
Khi lĩnh vực NLP ngày càng mở rộng, nhiều nhà nghiên cứu sẽ cố gắng cải thiện khả năng của máy để hiểu dữ liệu văn bản tốt hơn. Trải qua nhiều tiến bộ, nhiều kỹ thuật được đề xuất và áp dụng trong lĩnh vực NLP.
Bài viết này sẽ so sánh các kỹ thuật khác nhau để xử lý dữ liệu văn bản trong trường NLP. Bài viết này sẽ tập trung thảo luận về RNN, Transformers và BERT vì đây là những thứ thường được sử dụng trong nghiên cứu. Hãy đi sâu vào nó.
Mạng thần kinh tái diễn hay RNN được phát triển từ năm 1980 nhưng gần đây mới gây được sức hút trong lĩnh vực NLP. RNN là một loại cụ thể trong họ mạng thần kinh được sử dụng cho dữ liệu tuần tự hoặc dữ liệu không thể độc lập với nhau. Ví dụ về dữ liệu tuần tự là dữ liệu chuỗi thời gian, âm thanh hoặc câu văn bản, về cơ bản là bất kỳ loại dữ liệu nào có thứ tự có ý nghĩa.
RNN khác với các mạng thần kinh chuyển tiếp nguồn cấp dữ liệu thông thường vì chúng xử lý thông tin khác nhau. Trong quá trình chuyển tiếp thông thường, thông tin được xử lý theo các lớp. Tuy nhiên, RNN đang sử dụng chu kỳ vòng lặp trên thông tin đầu vào để xem xét. Để hiểu sự khác biệt, chúng ta hãy xem hình ảnh dưới đây.
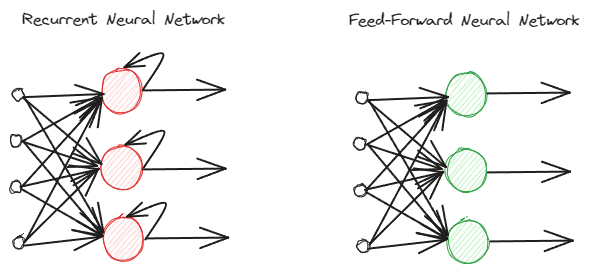
Hình ảnh của Tác giả
Như bạn có thể thấy, mô hình RNN thực hiện một chu trình vòng lặp trong quá trình xử lý thông tin. RNN sẽ xem xét dữ liệu đầu vào hiện tại và trước đó khi xử lý thông tin này. Đó là lý do tại sao mô hình này phù hợp với mọi loại dữ liệu tuần tự.
Nếu chúng ta lấy một ví dụ trong dữ liệu văn bản, hãy tưởng tượng chúng ta có câu “Tôi thức dậy lúc 7 giờ sáng” và chúng ta có từ này làm đầu vào. Trong mạng nơ ron chuyển tiếp nguồn cấp dữ liệu, khi chúng ta chạm đến từ “lên”, mô hình sẽ quên các từ “I”, “wake” và “up”. Tuy nhiên, RNN sẽ sử dụng mọi đầu ra cho mỗi từ và lặp lại chúng để mô hình không bị quên.
Trong lĩnh vực NLP, RNN thường được sử dụng trong nhiều ứng dụng văn bản, chẳng hạn như phân loại và tạo văn bản. Nó thường được sử dụng trong các ứng dụng cấp độ từ như gắn thẻ Một phần của lời nói, tạo từ tiếp theo, v.v.
Nhìn vào RNN sâu hơn trên dữ liệu văn bản, có nhiều loại RNN. Ví dụ: hình ảnh bên dưới là loại nhiều-nhiều.
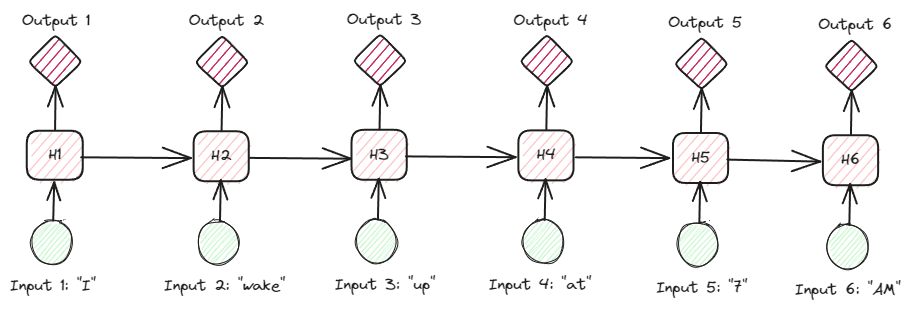
Hình ảnh của Tác giả
Nhìn vào hình trên, chúng ta có thể thấy đầu ra của mỗi bước (bước thời gian trong RNN) được xử lý từng bước một và mỗi lần lặp luôn xem xét thông tin trước đó.
Một loại RNN khác được sử dụng trong nhiều ứng dụng NLP là loại bộ mã hóa-giải mã (Sequence-to-Sequence). Cấu trúc được hiển thị trong hình ảnh dưới đây.
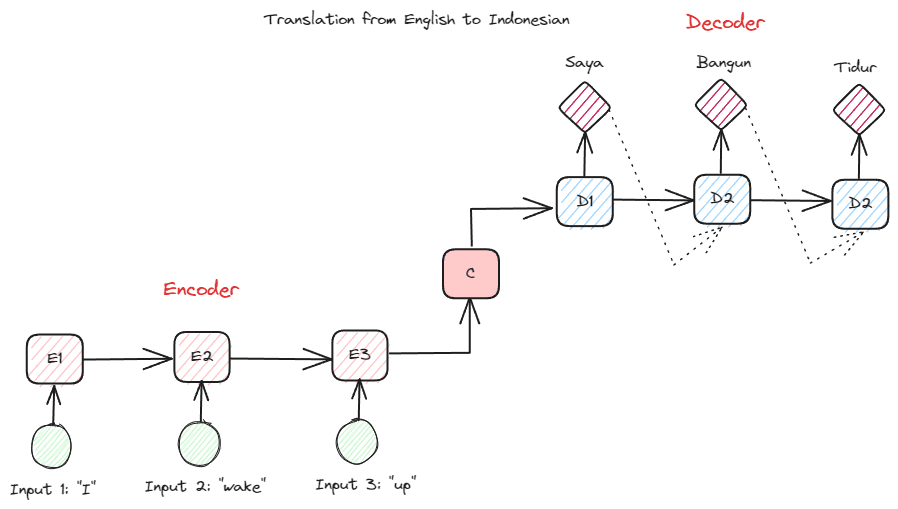
Hình ảnh của Tác giả
Cấu trúc này giới thiệu hai phần được sử dụng trong mô hình. Phần đầu tiên được gọi là Bộ mã hóa, là phần nhận chuỗi dữ liệu và tạo biểu diễn mới dựa trên chuỗi đó. Việc biểu diễn sẽ được sử dụng trong phần thứ hai của mô hình, đó là bộ giải mã. Với cấu trúc này, độ dài đầu vào và đầu ra không nhất thiết phải bằng nhau. Trường hợp sử dụng ví dụ là bản dịch ngôn ngữ, thường không có cùng độ dài giữa đầu vào và đầu ra.
Có nhiều lợi ích khác nhau khi sử dụng RNN để xử lý dữ liệu ngôn ngữ tự nhiên, bao gồm:
- RNN có thể được sử dụng để xử lý văn bản nhập mà không bị giới hạn độ dài.
- Mô hình chia sẻ cùng trọng số trên tất cả các bước thời gian, điều này cho phép mạng nơ-ron sử dụng cùng một tham số trong mỗi bước.
- Việc có bộ nhớ về dữ liệu đầu vào trong quá khứ giúp RNN phù hợp với mọi dữ liệu tuần tự.
Nhưng, cũng có một số nhược điểm:
- RNN dễ bị biến mất và bùng nổ độ dốc. Đây là nơi kết quả độ dốc là giá trị gần bằng XNUMX (biến mất), khiến trọng số mạng chỉ được cập nhật với một lượng rất nhỏ hoặc kết quả độ dốc quá quan trọng (bùng nổ) đến mức nó gán tầm quan trọng to lớn phi thực tế cho mạng.
- Thời gian đào tạo dài do tính chất tuần tự của mô hình.
- Bộ nhớ ngắn hạn có nghĩa là mô hình bắt đầu quên khi mô hình được huấn luyện càng lâu. Có một phần mở rộng của RNN được gọi là LSTM để giảm bớt vấn đề này.
Transformers là một kiến trúc mô hình NLP cố gắng giải quyết các tác vụ theo trình tự đã gặp trước đây trong RNN. Như đã đề cập ở trên, RNN gặp vấn đề với bộ nhớ ngắn hạn. Dữ liệu đầu vào càng dài thì mô hình càng dễ quên thông tin. Đây là lúc cơ chế chú ý có thể giúp giải quyết vấn đề.
Cơ chế chú ý được giới thiệu trong bài báo bởi Bahdanau et al. (2014) để giải quyết vấn đề đầu vào dài, đặc biệt là với loại RNN mã hóa-giải mã. Tôi sẽ không giải thích chi tiết cơ chế chú ý. Về cơ bản, nó là một lớp cho phép mô hình tập trung vào phần quan trọng của đầu vào mô hình trong khi có dự đoán đầu ra. Ví dụ: từ đầu vào “Đồng hồ” sẽ có mối tương quan cao với “Jam” trong tiếng Indonesia nếu tác vụ là dịch thuật.
Mô hình máy biến áp được giới thiệu bởi Vaswani et al. (2017). Kiến trúc được lấy cảm hứng từ bộ mã hóa-giải mã RNN và được xây dựng dựa trên cơ chế chú ý và không xử lý dữ liệu theo thứ tự tuần tự. Mô hình máy biến áp tổng thể có cấu trúc như hình bên dưới.
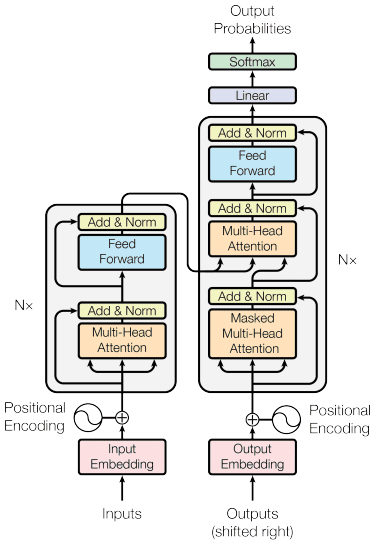
Kiến trúc máy biến áp (Vaswani et al. 2017)
Trong cấu trúc trên, các bộ chuyển đổi mã hóa chuỗi vectơ dữ liệu thành từ nhúng với mã hóa vị trí tại chỗ trong khi sử dụng bộ giải mã để chuyển đổi dữ liệu thành dạng ban đầu. Với cơ chế chú ý được áp dụng, việc mã hóa có thể có tầm quan trọng tùy theo đầu vào.
Máy biến áp cung cấp một số lợi thế so với mô hình khác, bao gồm:
- Quá trình song song hóa làm tăng tốc độ đào tạo và suy luận.
- Có khả năng xử lý đầu vào dài hơn, giúp hiểu rõ hơn về ngữ cảnh
Vẫn còn một số nhược điểm của mô hình máy biến áp:
- Yêu cầu và xử lý tính toán cao.
- Cơ chế chú ý có thể yêu cầu phân tách văn bản do giới hạn độ dài mà nó có thể xử lý.
- Ngữ cảnh có thể bị mất nếu việc phân chia được thực hiện sai.
Chứng nhận
BERT, hay Biểu diễn bộ mã hóa hai chiều từ Transformers, là một mô hình được phát triển bởi Devlin et al. (2019) bao gồm hai bước (đào tạo trước và tinh chỉnh) để tạo mô hình. Nếu chúng ta so sánh, BERT là một bộ mã hóa máy biến áp (BERT Base có 12 lớp trong khi BERT Large có 24 lớp).
Quá trình phát triển mô hình tổng thể của BERT có thể được hiển thị trong hình ảnh bên dưới.
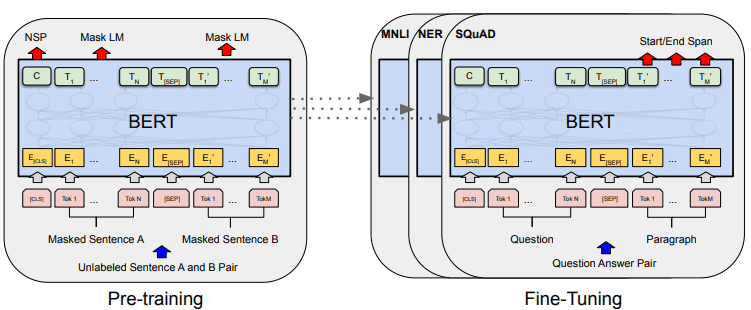
Thủ tục tổng thể của BERT (Devlin et al. (2019)
Các nhiệm vụ đào tạo trước sẽ bắt đầu quá trình đào tạo của mô hình cùng một lúc và sau khi hoàn thành, mô hình có thể được tinh chỉnh cho các nhiệm vụ tiếp theo khác nhau (trả lời câu hỏi, phân loại, v.v.).
Điều làm cho BERT trở nên đặc biệt là đây là mô hình ngôn ngữ hai chiều không giám sát đầu tiên được đào tạo trước về dữ liệu văn bản. BERT trước đây đã được đào tạo trước về toàn bộ Wikipedia và kho sách, bao gồm hơn 3000 triệu từ.
BERT được coi là hai chiều vì nó không đọc dữ liệu đầu vào một cách tuần tự (từ trái sang phải hoặc ngược lại), nhưng bộ mã hóa máy biến áp đọc toàn bộ chuỗi cùng một lúc.
Không giống như các mô hình định hướng đọc văn bản đầu vào theo tuần tự (từ trái sang phải hoặc từ phải sang trái), bộ mã hóa Transformer đọc đồng thời toàn bộ chuỗi từ. Đó là lý do tại sao mô hình được coi là hai chiều và cho phép mô hình hiểu được toàn bộ bối cảnh của dữ liệu đầu vào.
Để đạt được hai chiều, BERT sử dụng hai kỹ thuật:
- Mô hình ngôn ngữ mặt nạ (MLM) - Kỹ thuật che dấu từ. Kỹ thuật này sẽ che dấu 15% số từ đầu vào và cố gắng dự đoán từ bị che này dựa trên từ không bị che.
- Dự đoán câu tiếp theo (NSP) — BERT cố gắng tìm hiểu mối quan hệ giữa các câu. Mô hình có các cặp câu làm dữ liệu đầu vào và cố gắng dự đoán xem câu tiếp theo có tồn tại trong tài liệu gốc hay không.
Có một số lợi thế khi sử dụng BERT trong lĩnh vực NLP, bao gồm:
- BERT rất dễ sử dụng cho các nhiệm vụ hạ nguồn NLP khác nhau được đào tạo trước.
- Hai chiều làm cho BERT hiểu ngữ cảnh văn bản tốt hơn.
- Là mô hình phổ biến được cộng đồng ủng hộ nhiều
Tuy nhiên, vẫn còn một số nhược điểm, bao gồm:
- Đòi hỏi sức mạnh tính toán cao và thời gian huấn luyện dài để tinh chỉnh một số tác vụ tiếp theo.
- Mô hình BERT có thể tạo ra một mô hình lớn đòi hỏi dung lượng lưu trữ lớn hơn nhiều.
- Tốt hơn nên sử dụng cho các tác vụ phức tạp vì hiệu suất cho các tác vụ đơn giản không khác nhiều so với việc sử dụng các mô hình đơn giản hơn.
NLP gần đây đã trở nên nổi bật hơn và nhiều nghiên cứu đã tập trung vào việc cải thiện các ứng dụng. Trong bài viết này, chúng tôi thảo luận về ba kỹ thuật NLP thường được sử dụng:
- RNN
- Máy biến áp
- Chứng nhận
Mỗi kỹ thuật đều có ưu điểm và nhược điểm, nhưng nhìn chung, chúng ta có thể thấy mô hình đang phát triển theo hướng tốt hơn.
Cornellius Yudha Wijaya là trợ lý quản lý khoa học dữ liệu và người viết dữ liệu. Trong khi làm việc toàn thời gian tại Allianz Indonesia, anh ấy thích chia sẻ các mẹo về Python và Dữ liệu qua mạng xã hội và phương tiện viết lách.
Cornellius Yudha Wijaya là trợ lý quản lý khoa học dữ liệu và người viết dữ liệu. Trong khi làm việc toàn thời gian tại Allianz Indonesia, anh ấy thích chia sẻ các mẹo về Python và Dữ liệu qua mạng xã hội và phương tiện viết lách.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/comparing-natural-language-processing-techniques-rnns-transformers-bert?utm_source=rss&utm_medium=rss&utm_campaign=comparing-natural-language-processing-techniques-rnns-transformers-bert

