Các mô hình ngôn ngữ lớn (LLM) có thể được sử dụng để phân tích các tài liệu phức tạp và cung cấp các bản tóm tắt cũng như câu trả lời cho các câu hỏi. Bài Thích ứng miền Tinh chỉnh các Mô hình Nền tảng trong Amazon SageMaker Khởi động về dữ liệu tài chính mô tả cách tinh chỉnh LLM bằng bộ dữ liệu của riêng bạn. Sau khi bạn có LLM vững chắc, bạn sẽ muốn hiển thị LLM đó cho người dùng doanh nghiệp để xử lý các tài liệu mới, có thể dài hàng trăm trang. Trong bài đăng này, chúng tôi trình bày cách xây dựng giao diện người dùng thời gian thực để cho phép người dùng doanh nghiệp xử lý tài liệu PDF có độ dài tùy ý. Sau khi tệp được xử lý, bạn có thể tóm tắt tài liệu hoặc đặt câu hỏi về nội dung. Giải pháp mẫu được mô tả trong bài đăng này có sẵn trên GitHub.
Làm việc với các tài liệu tài chính
Báo cáo tài chính như báo cáo thu nhập hàng quý và báo cáo hàng năm cho các cổ đông thường dài hàng chục hoặc hàng trăm trang. Các tài liệu này chứa rất nhiều ngôn ngữ soạn sẵn như tuyên bố từ chối trách nhiệm và ngôn ngữ pháp lý. Nếu bạn muốn trích xuất các điểm dữ liệu quan trọng từ một trong những tài liệu này, bạn cần cả thời gian và một chút quen thuộc với ngôn ngữ soạn sẵn để bạn có thể xác định các sự kiện thú vị. Và tất nhiên, bạn không thể đặt câu hỏi cho LLM về một tài liệu mà họ chưa từng xem.
Các LLM được sử dụng để tóm tắt có giới hạn về số lượng mã thông báo (ký tự) được chuyển vào mô hình và với một số trường hợp ngoại lệ, chúng thường không quá vài nghìn mã thông báo. Điều đó thường ngăn cản khả năng tóm tắt các tài liệu dài hơn.
Giải pháp của chúng tôi xử lý các tài liệu vượt quá độ dài trình tự mã thông báo tối đa của LLM và cung cấp tài liệu đó cho LLM để trả lời câu hỏi.
Tổng quan về giải pháp
Thiết kế của chúng tôi có ba phần quan trọng:
- Nó có một ứng dụng web tương tác để người dùng doanh nghiệp tải lên và xử lý các tệp PDF
- Nó sử dụng thư viện langchain để chia một tệp PDF lớn thành nhiều phần dễ quản lý hơn
- Nó sử dụng kỹ thuật tạo tăng cường truy xuất để cho phép người dùng đặt câu hỏi về dữ liệu mới mà LLM chưa từng thấy trước đây
Như được hiển thị trong sơ đồ sau, chúng tôi sử dụng giao diện người dùng được triển khai với React JavaScript được lưu trữ trong một Dịch vụ lưu trữ đơn giản của Amazon thùng (Amazon S3) phía trước bởi Amazon CloudFront. Ứng dụng giao diện người dùng cho phép người dùng tải tài liệu PDF lên Amazon S3. Sau khi quá trình tải lên hoàn tất, bạn có thể kích hoạt công việc trích xuất văn bản do Văn bản Amazon. Là một phần của quá trình hậu xử lý, một AWS Lambda chức năng chèn các điểm đánh dấu đặc biệt vào văn bản cho biết ranh giới trang. Khi công việc đó hoàn thành, bạn có thể gọi một API tóm tắt văn bản hoặc trả lời các câu hỏi về nó.

Do một số bước trong số này có thể mất một chút thời gian nên kiến trúc sử dụng phương pháp tiếp cận không đồng bộ tách rời. Ví dụ: lệnh gọi để tóm tắt một tài liệu sẽ gọi một hàm Lambda để đăng một thông báo lên một Dịch vụ xếp hàng đơn giản trên Amazon (Amazon SQS) hàng đợi. Một hàm Lambda khác nhận thông báo đó và bắt đầu một Dịch vụ container đàn hồi Amazon (ECS của Amazon) Cổng xa AWS nhiệm vụ. Nhiệm vụ Fargate gọi Amazon SageMaker điểm cuối suy luận. Chúng tôi sử dụng tác vụ Fargate ở đây vì việc tóm tắt một tệp PDF rất dài có thể tốn nhiều thời gian và bộ nhớ hơn so với chức năng Lambda hiện có. Khi tổng kết xong, ứng dụng front-end có thể lấy kết quả từ một Máy phát điện Amazon bảng.
Để tóm tắt, chúng tôi sử dụng mô hình Tóm tắt của AI21, một trong những mô hình nền tảng có sẵn thông qua Khởi động Amazon SageMaker. Mặc dù mô hình này xử lý các tài liệu có tối đa 10,000 từ (khoảng 40 trang), nhưng chúng tôi sử dụng bộ tách văn bản của langchain để đảm bảo rằng mỗi cuộc gọi tóm tắt tới LLM không dài quá 10,000 từ. Để tạo văn bản, chúng tôi sử dụng mô hình Medium của Cohere và chúng tôi sử dụng GPT-J để nhúng, cả hai đều thông qua JumpStart.
xử lý tóm tắt
Khi xử lý các tài liệu lớn hơn, chúng ta cần xác định cách chia tài liệu thành các phần nhỏ hơn. Khi chúng tôi nhận lại kết quả trích xuất văn bản từ Amazon Textract, chúng tôi sẽ chèn điểm đánh dấu cho các đoạn văn bản lớn hơn (số trang có thể định cấu hình), các trang riêng lẻ và ngắt dòng. Langchain sẽ phân chia dựa trên các điểm đánh dấu đó và tập hợp các tài liệu nhỏ hơn dưới giới hạn mã thông báo. Xem đoạn mã sau:
LLM trong chuỗi tóm tắt là một trình bao bọc mỏng xung quanh điểm cuối SageMaker của chúng tôi:
Câu trả lời câu hỏi
Trong phương pháp tạo tăng cường truy xuất, trước tiên chúng tôi chia tài liệu thành các phân đoạn nhỏ hơn. Chúng tôi tạo các phần nhúng cho từng phân đoạn và lưu trữ chúng trong cơ sở dữ liệu vectơ Chroma nguồn mở thông qua giao diện của langchain. Chúng tôi lưu cơ sở dữ liệu trong một Hệ thống tệp đàn hồi Amazon (Amazon EFS) để sử dụng sau này. Xem đoạn mã sau:
Khi các phần nhúng đã sẵn sàng, người dùng có thể đặt câu hỏi. Chúng tôi tìm kiếm cơ sở dữ liệu vectơ cho các đoạn văn bản phù hợp nhất với câu hỏi:
Chúng tôi lấy đoạn phù hợp nhất và sử dụng nó làm ngữ cảnh cho mô hình tạo văn bản để trả lời câu hỏi:
Kinh nghiệm người dùng
Mặc dù LLM đại diện cho khoa học dữ liệu tiên tiến, hầu hết các trường hợp sử dụng cho LLM cuối cùng đều liên quan đến tương tác với người dùng không có kỹ thuật. Ứng dụng web mẫu của chúng tôi xử lý trường hợp sử dụng tương tác trong đó người dùng doanh nghiệp có thể tải lên và xử lý tài liệu PDF mới.
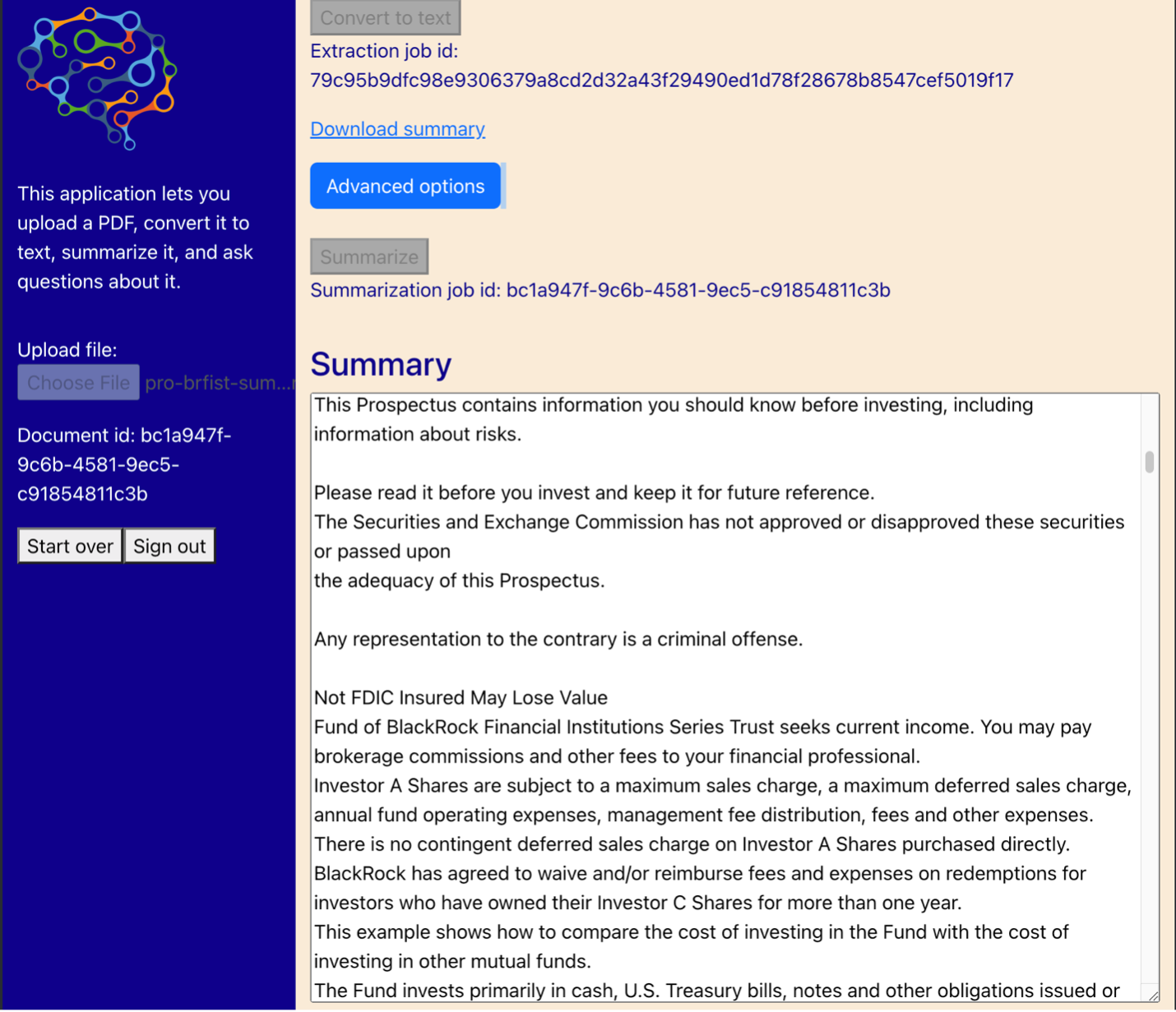
Sơ đồ sau đây cho thấy giao diện người dùng. Người dùng bắt đầu bằng cách tải lên tệp PDF. Sau khi tài liệu được lưu trữ trong Amazon S3, người dùng có thể bắt đầu công việc trích xuất văn bản. Khi hoàn tất, người dùng có thể gọi tác vụ tóm tắt hoặc đặt câu hỏi. Giao diện người dùng hiển thị một số tùy chọn nâng cao như kích thước khối và chồng chéo khối, điều này sẽ hữu ích cho những người dùng nâng cao đang thử nghiệm ứng dụng trên các tài liệu mới.
Các bước tiếp theo
LLM cung cấp khả năng truy xuất thông tin mới đáng kể. Người dùng doanh nghiệp cần truy cập thuận tiện vào các khả năng đó. Có hai hướng cho công việc trong tương lai để xem xét:
- Tận dụng các LLM mạnh mẽ đã có sẵn trong các mô hình nền tảng Khởi động. Chỉ với một vài dòng mã, ứng dụng mẫu của chúng tôi có thể triển khai và tận dụng các LLM nâng cao từ AI21 và Cohere để tóm tắt và tạo văn bản.
- Làm cho những khả năng này có thể truy cập được đối với người dùng không có kỹ thuật. Điều kiện tiên quyết để xử lý tài liệu PDF là trích xuất văn bản từ tài liệu và các công việc tóm tắt có thể mất vài phút để chạy. Điều đó đòi hỏi một giao diện người dùng đơn giản với khả năng xử lý phụ trợ không đồng bộ, dễ thiết kế bằng cách sử dụng các dịch vụ gốc trên đám mây như Lambda và Fargate.
Chúng tôi cũng lưu ý rằng tài liệu PDF là thông tin bán cấu trúc. Các tín hiệu quan trọng như tiêu đề phần rất khó xác định theo chương trình vì chúng dựa vào kích thước phông chữ và các chỉ báo trực quan khác. Việc xác định cấu trúc cơ bản của thông tin giúp LLM xử lý dữ liệu chính xác hơn, ít nhất là cho đến khi LLM có thể xử lý dữ liệu đầu vào có độ dài không giới hạn.
Kết luận
Trong bài đăng này, chúng tôi đã chỉ ra cách xây dựng ứng dụng web tương tác cho phép người dùng doanh nghiệp tải lên và xử lý tài liệu PDF để tóm tắt và trả lời câu hỏi. Chúng tôi đã thấy cách tận dụng các mô hình nền tảng Khởi động để truy cập các LLM nâng cao và sử dụng các kỹ thuật tạo tăng cường truy xuất và phân tách văn bản để xử lý các tài liệu dài hơn và cung cấp chúng dưới dạng thông tin cho LLM.
Tại thời điểm này, không có lý do gì để không cung cấp những khả năng mạnh mẽ này cho người dùng của bạn. Chúng tôi khuyến khích bạn bắt đầu sử dụng Mô hình nền tảng khởi động hôm nay.
Giới thiệu về tác giả
 Randy DeFauw là Kiến trúc sư giải pháp chính cấp cao tại AWS. Anh ấy có bằng MSEE của Đại học Michigan, nơi anh ấy làm việc về thị giác máy tính cho xe tự hành. Ông cũng có bằng MBA của Đại học Bang Colorado. Randy đã đảm nhiệm nhiều vị trí khác nhau trong lĩnh vực công nghệ, từ kỹ thuật phần mềm đến quản lý sản phẩm. Trong không gian Dữ liệu lớn vào năm 2013 và tiếp tục khám phá lĩnh vực đó. Anh ấy đang tích cực làm việc với các dự án trong không gian ML và đã trình bày tại nhiều hội nghị bao gồm Strata và GlueCon.
Randy DeFauw là Kiến trúc sư giải pháp chính cấp cao tại AWS. Anh ấy có bằng MSEE của Đại học Michigan, nơi anh ấy làm việc về thị giác máy tính cho xe tự hành. Ông cũng có bằng MBA của Đại học Bang Colorado. Randy đã đảm nhiệm nhiều vị trí khác nhau trong lĩnh vực công nghệ, từ kỹ thuật phần mềm đến quản lý sản phẩm. Trong không gian Dữ liệu lớn vào năm 2013 và tiếp tục khám phá lĩnh vực đó. Anh ấy đang tích cực làm việc với các dự án trong không gian ML và đã trình bày tại nhiều hội nghị bao gồm Strata và GlueCon.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/use-a-generative-ai-foundation-model-for-summarization-and-question-answering-using-your-own-data/

