Dữ liệu là nền tảng cho các thuật toán máy học (ML). Một trong những định dạng phổ biến nhất để lưu trữ lượng lớn dữ liệu là Apache Parquet do định dạng nhỏ gọn và hiệu quả cao của nó. Điều này có nghĩa là các nhà phân tích kinh doanh muốn trích xuất thông tin chi tiết từ khối lượng dữ liệu lớn trong kho dữ liệu của họ phải thường xuyên sử dụng dữ liệu được lưu trữ trong Parquet.
Để đơn giản hóa việc truy cập vào các tệp Parquet, Canvas SageMaker của Amazon đã thêm khả năng nhập dữ liệu từ hơn 40 nguồn dữ liệu, Bao gồm cả amazon Athena, hỗ trợ Apache Parquet.
Canvas cung cấp trình kết nối tới các nguồn dữ liệu AWS như Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), Athena và Amazon RedShift. Trong bài đăng này, chúng tôi mô tả cách truy vấn các tệp Parquet với Athena bằng cách sử dụng Sự hình thành hồ AWS và sử dụng Canvas đầu ra để đào tạo một mô hình.
Tổng quan về giải pháp
Athena là một dịch vụ phân tích tương tác, không có máy chủ được xây dựng trên các khung nguồn mở, hỗ trợ các định dạng tệp và bảng mở. Nhiều nhóm đang chuyển sang Athena để cho phép truy vấn tương tác và phân tích dữ liệu của họ trong kho lưu trữ dữ liệu tương ứng mà không cần tạo nhiều bản sao dữ liệu.
Athena cho phép các ứng dụng sử dụng SQL tiêu chuẩn để truy vấn lượng dữ liệu khổng lồ trên kho dữ liệu S3. Athena hỗ trợ nhiều định dạng dữ liệu khác nhau, bao gồm:
- CSV
- TSV
- JSON
- tập tin văn bản
- Các định dạng cột mã nguồn mở, chẳng hạn như ORC và Parquet
- Dữ liệu được nén ở các định dạng Snappy, Zlib, LZO và GZIP
tập tin sàn gỗ tổ chức dữ liệu thành các cột và sử dụng các lược đồ mã hóa và nén dữ liệu hiệu quả để lưu trữ và truy xuất dữ liệu nhanh chóng. Bạn có thể giảm thời gian nhập trong Canvas bằng cách sử dụng tệp Parquet để nhập dữ liệu hàng loạt và với các cột cụ thể.
Lake Formation là một dịch vụ hồ dữ liệu tích hợp giúp bạn dễ dàng nhập, dọn dẹp, lập danh mục, chuyển đổi và bảo mật dữ liệu của mình, đồng thời cung cấp dữ liệu đó để phân tích và ML. Lake Formation tự động quản lý quyền truy cập vào dữ liệu đã đăng ký trong Amazon S3 thông qua các dịch vụ bao gồm Keo AWS, Athena, Dịch chuyển đỏ của Amazon, Amazon QuickSightvà Amazon EMR sử dụng sổ ghi chép Zeppelin với Apache Spark để đảm bảo tuân thủ các chính sách đã xác định của bạn.
Trong bài đăng này, chúng tôi chỉ cho bạn cách nhập dữ liệu Sàn gỗ vào Canvas từ Athena, nơi Lake Formation cho phép quản trị dữ liệu.
Để minh họa, chúng tôi sử dụng dữ liệu hoạt động của một doanh nghiệp điện tử tiêu dùng. Chúng tôi tạo một mô hình để ước tính nhu cầu đối với các sản phẩm điện tử bằng cách sử dụng dữ liệu chuỗi thời gian lịch sử của chúng.
Giải pháp này được minh họa trong ba bước:
- Thiết lập sự hình thành hồ.
- Cấp quyền truy cập Lake Formation cho Canvas.
- Nhập dữ liệu Parquet vào Canvas bằng Athena.
- Sử dụng dữ liệu Sàn gỗ đã nhập để tạo mô hình ML bằng Canvas.
Sơ đồ sau minh họa kiến trúc giải pháp.
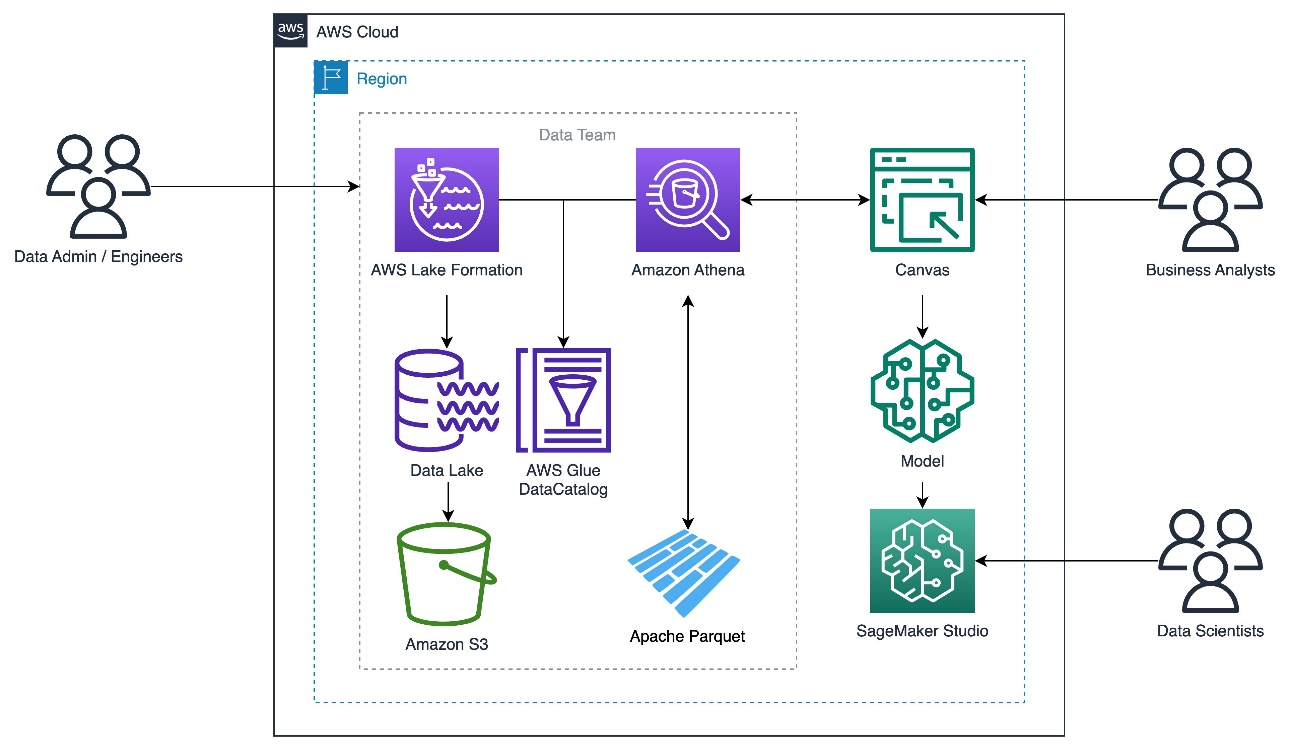
Thiết lập cơ sở dữ liệu Lake Formation
Các bước được liệt kê ở đây tạo thành quá trình thiết lập một lần để hiển thị cho bạn hồ dữ liệu lưu trữ dữ liệu Parquet, dữ liệu này có thể được các nhà phân tích của bạn sử dụng để hiểu rõ hơn bằng cách sử dụng Canvas. Kỹ sư đám mây hoặc quản trị viên có thể thực hiện tốt nhất các điều kiện tiên quyết này. Các nhà phân tích có thể truy cập trực tiếp vào Canvas và nhập dữ liệu từ Athena.
Dữ liệu được sử dụng trong bài đăng này bao gồm hai bộ dữ liệu có nguồn gốc từ Amazon S3. Các bộ dữ liệu này đã được tạo tổng hợp cho bài đăng này.
- Chuỗi thời gian mục tiêu điện tử tiêu dùng (TTS) – Dữ liệu lịch sử của đại lượng cần dự báo được gọi là Chuỗi thời gian mục tiêu (TTS). Trong trường hợp này, đó là nhu cầu về một mặt hàng.
- Chuỗi thời gian liên quan đến điện tử tiêu dùng (RTS) – Dữ liệu lịch sử khác được biết chính xác cùng thời điểm với mọi giao dịch bán hàng được gọi là Chuỗi thời gian liên quan (RTS). Trong trường hợp sử dụng của chúng tôi, đó là giá của một mặt hàng. Tập dữ liệu RTS bao gồm dữ liệu chuỗi thời gian không có trong tập dữ liệu TTS và có thể cải thiện độ chính xác của công cụ dự đoán của bạn.
- Tải dữ liệu lên Amazon S3 dưới dạng tệp Parquet từ hai thư mục sau:
- chứng chỉ – Chứa chuỗi thời gian liên quan đến điện tử gia dụng (RTS).
- ce-tts – Chứa Chuỗi Thời gian Mục tiêu Điện tử Tiêu dùng (TTS).
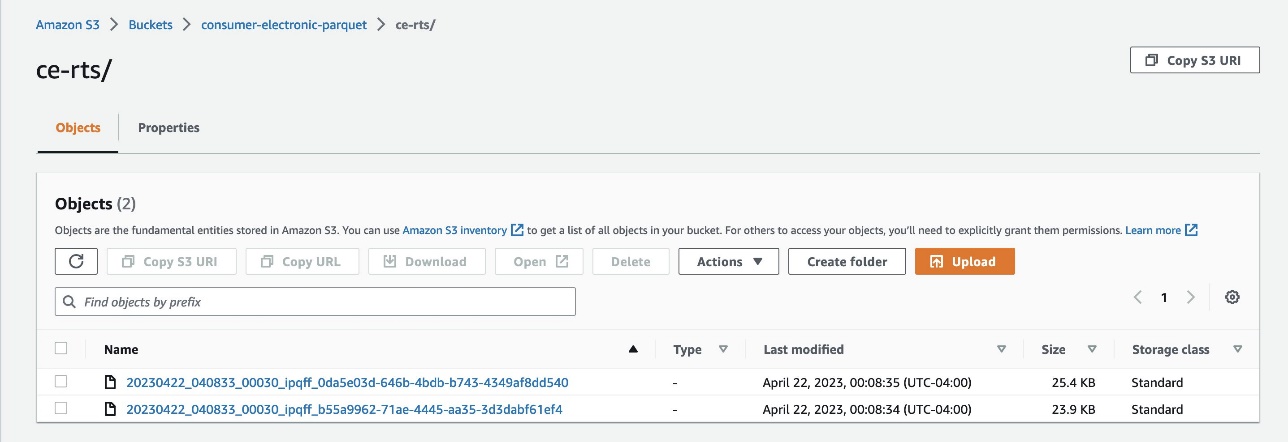
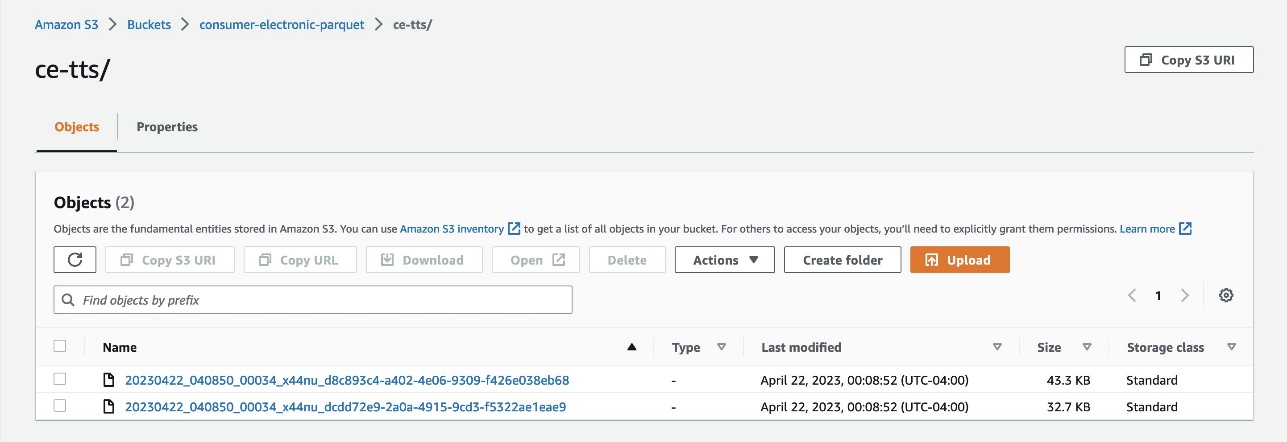
- Tạo một hồ dữ liệu với Lake Formation.
- Trên bảng điều khiển Lake Formation, tạo một cơ sở dữ liệu gọi là
consumer-electronics.
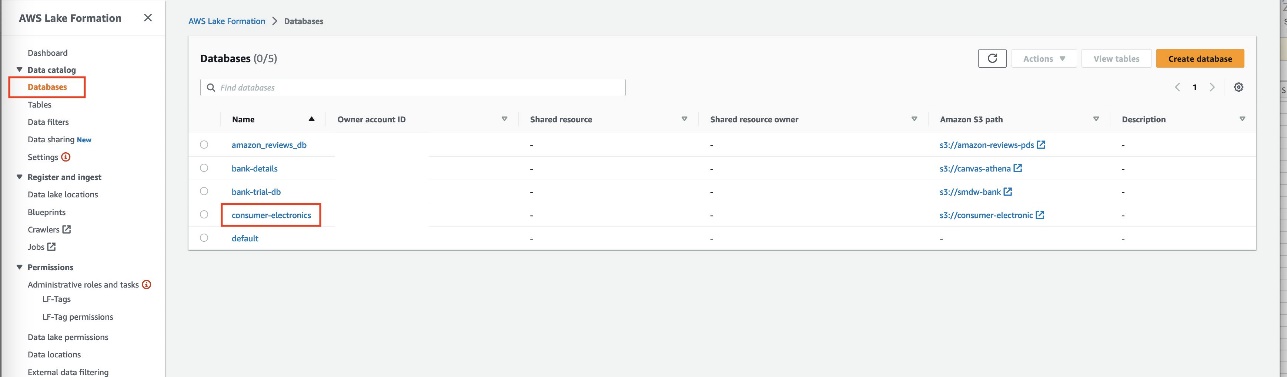
- Tạo hai bảng cho bộ dữ liệu điện tử tiêu dùng có tên
ce-rts-Parquetvàce-tts-Parquetvới dữ liệu được lấy từ bộ chứa S3.
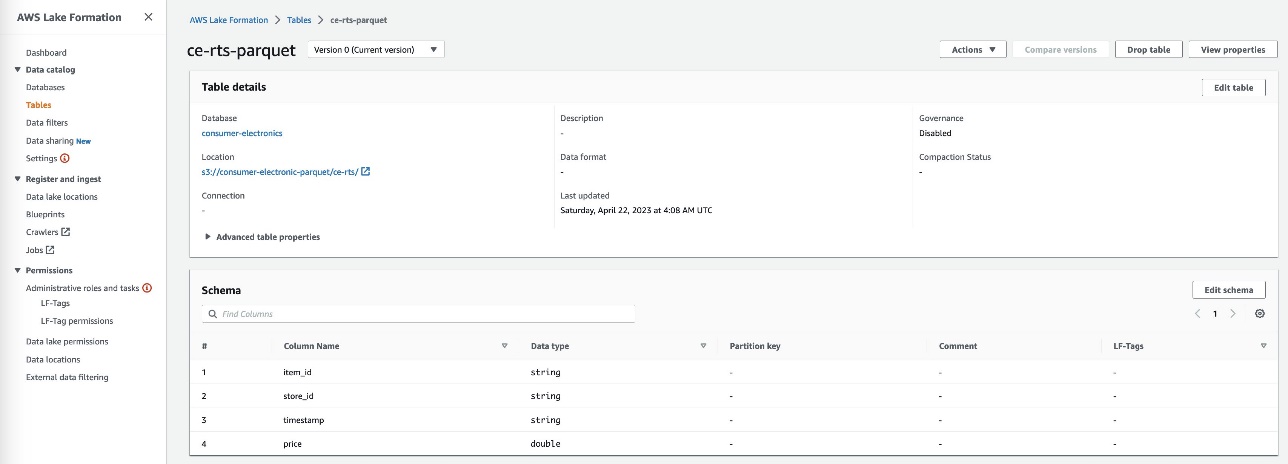
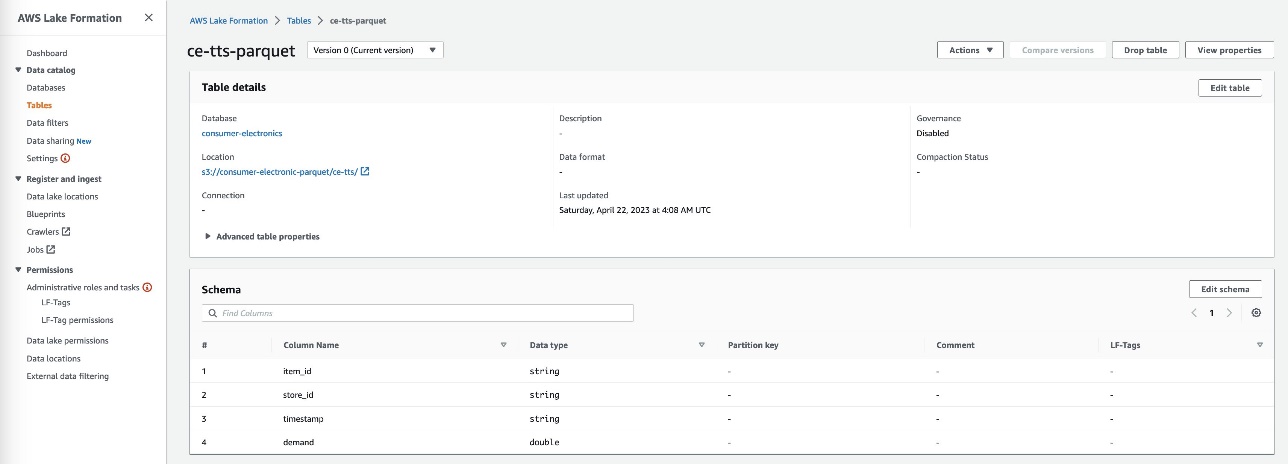
Chúng tôi sử dụng cơ sở dữ liệu mà chúng tôi đã tạo ở bước này trong bước sau để nhập dữ liệu Sàn gỗ vào Canvas bằng Athena.
Cấp quyền truy cập Lake Formation cho Canvas
Đây là thiết lập một lần do kỹ sư đám mây hoặc quản trị viên thực hiện.
- Cấp quyền truy cập hồ dữ liệu để truy cập Canvas để truy cập dữ liệu Parquet điện tử tiêu dùng.
- Trong tạp chí Miền SageMaker Studio, Xem Chi tiết người dùng canvas.
- Sao chép tên vai trò thực thi.
- Đảm bảo vai trò thực thi có đủ quyền để truy cập các dịch vụ sau:
- Canvas
- Bộ chứa S3 nơi lưu trữ dữ liệu Parquet.
- Athena để kết nối từ Canvas.
- AWS Glue để truy cập dữ liệu Parquet bằng trình kết nối Athena.

- Trong Lake Formation, chọn Quyền đối với hồ dữ liệu trong khung điều hướng.
- Chọn Cấp.
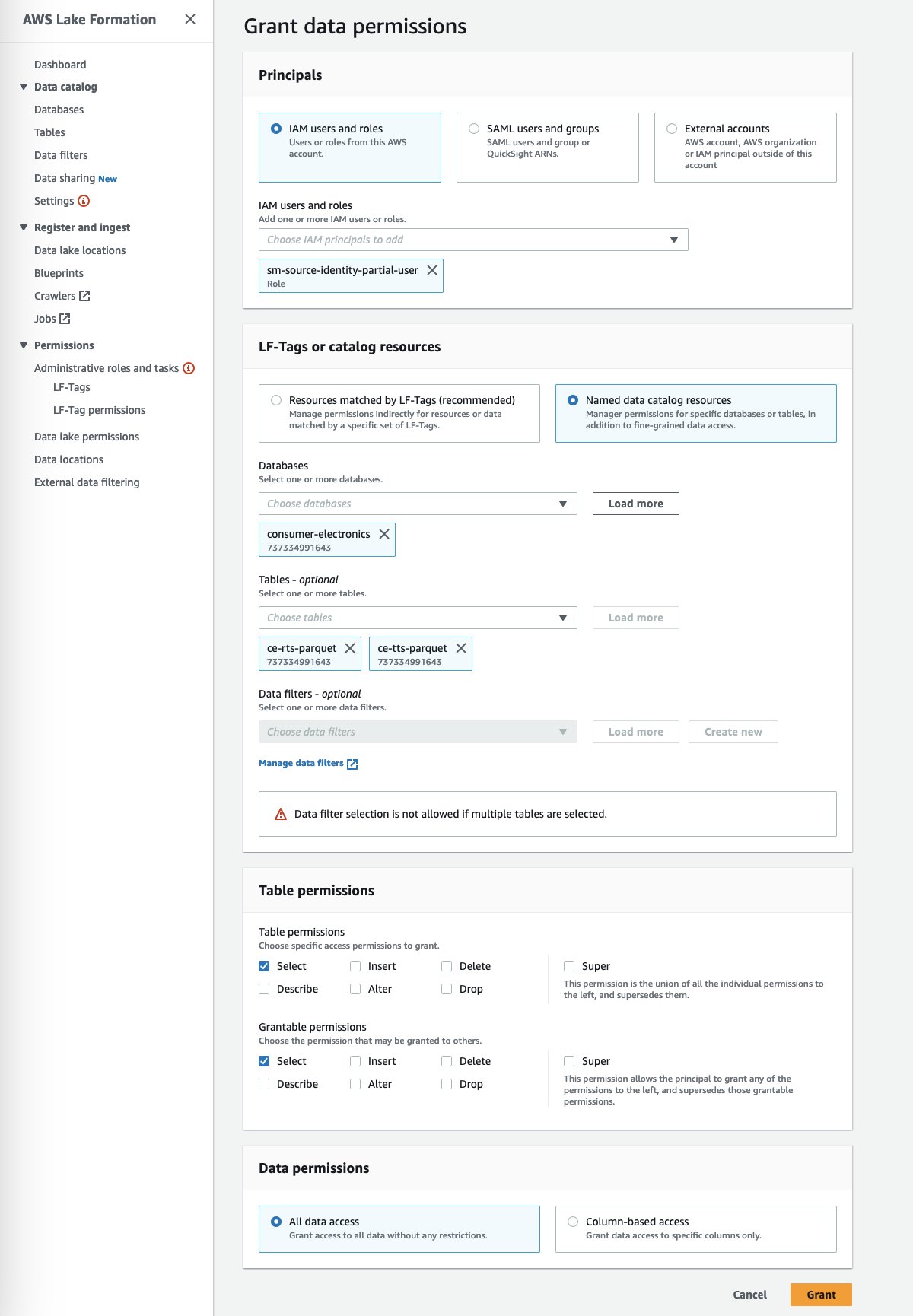
- Trong Hiệu trưởng, lựa chọn Người dùng IAM và vai trò để cung cấp quyền truy cập Canvas vào các tạo phẩm dữ liệu của bạn.
- Chỉ định vai trò thực thi của người dùng trong miền SageMaker Studio của bạn.
- Chỉ định cơ sở dữ liệu và bảng.
- Chọn Cấp.
Bạn có thể cấp các hành động chi tiết trên bảng, cột và dữ liệu. Tùy chọn này cung cấp cấu hình truy cập chi tiết cho dữ liệu nhạy cảm của bạn bằng cách phân tách các vai trò mà bạn đã xác định.
Sau khi bạn thiết lập môi trường bắt buộc để tích hợp Canvas và Athena, hãy chuyển sang bước tiếp theo để nhập dữ liệu vào Canvas bằng Athena.
Nhập dữ liệu bằng Athena
Hoàn thành các bước sau để nhập các tệp Parquet do Lake Formation quản lý:
- Trong Canvas, hãy chọn Bộ dữ liệu trong khung điều hướng.
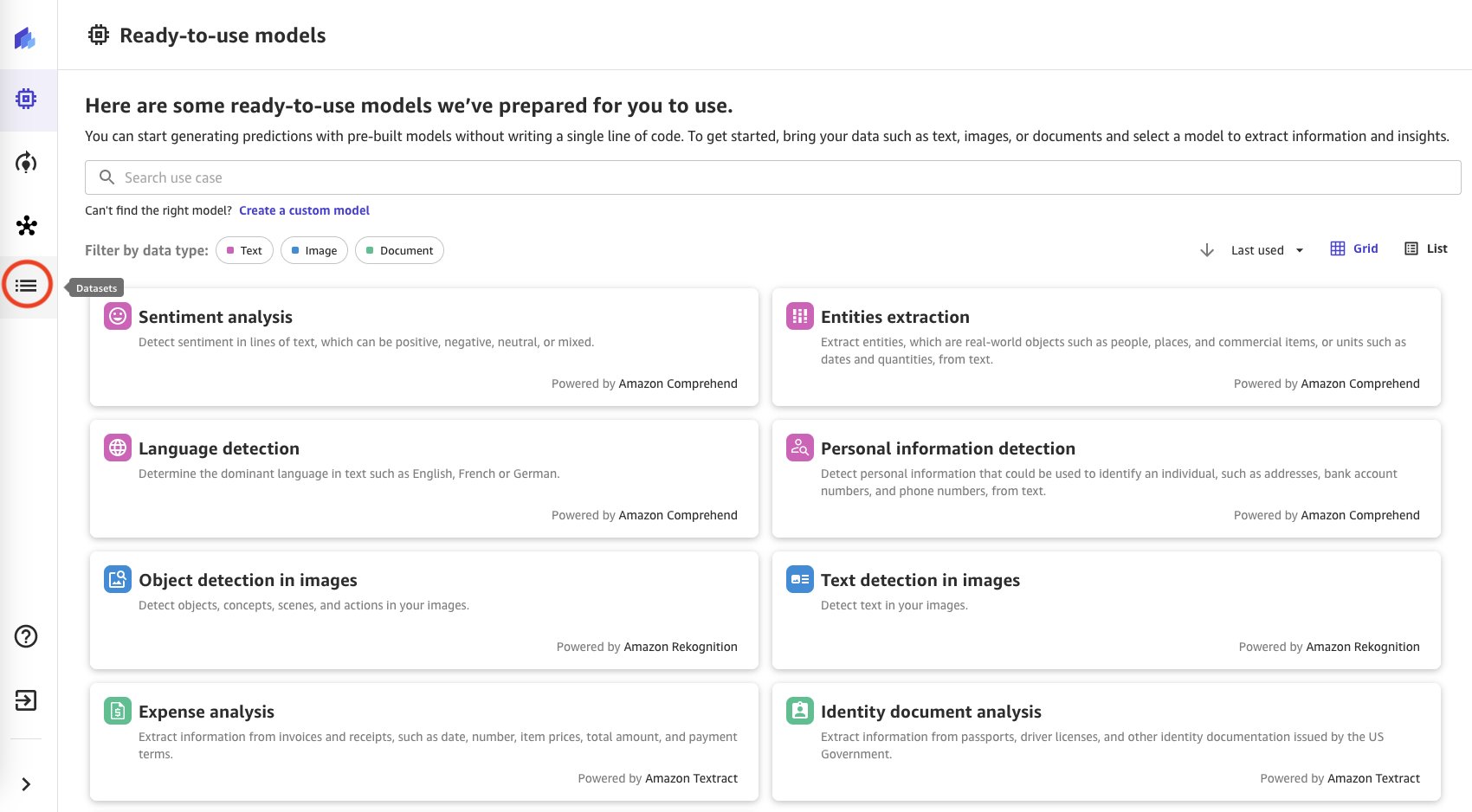
- Chọn + Nhập khẩu để nhập bộ dữ liệu Sàn gỗ do Lake Formation quản lý.
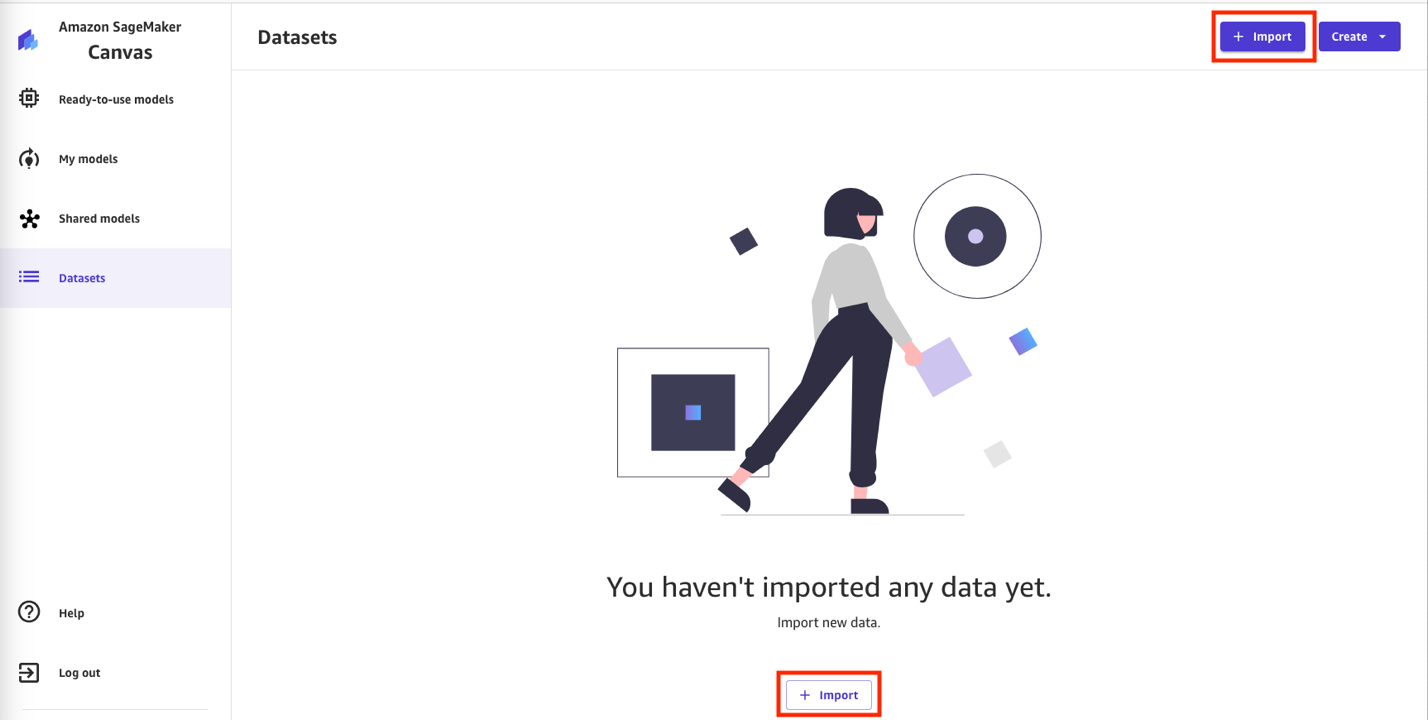
- Chọn Athena làm nguồn dữ liệu.
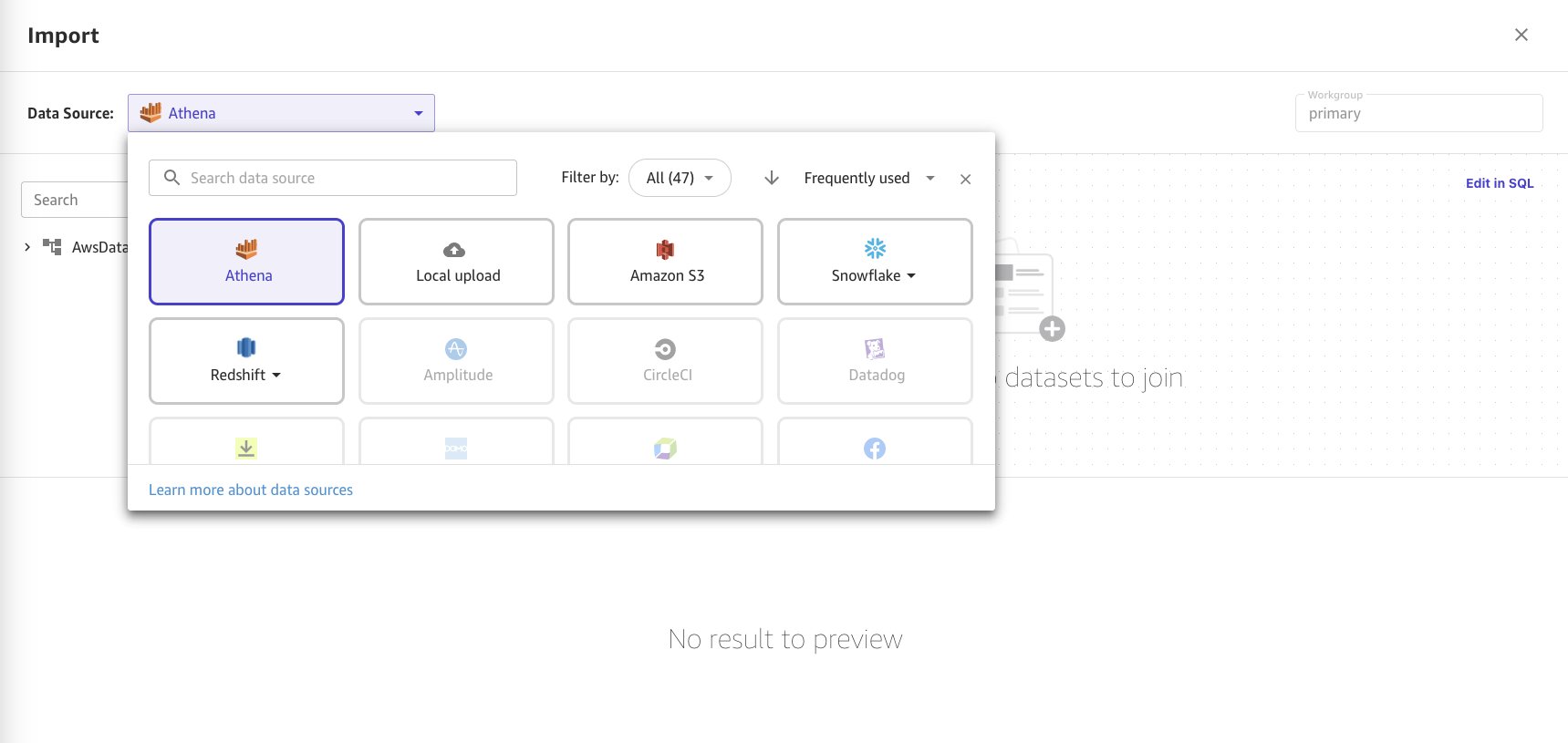
- Chọn
consumer-electronicstập dữ liệu ở định dạng Parquet từ danh mục dữ liệu Athena và chi tiết bảng trong menu. - Nhập hai bộ dữ liệu. Kéo và thả nguồn dữ liệu để chọn nguồn đầu tiên.

Khi bạn kéo và thả tập dữ liệu, bản xem trước dữ liệu sẽ xuất hiện ở khung dưới cùng của trang.
- Chọn Nhập dữ liệu.
- đăng ký hạng mục thi
consumer-electronics-rtslàm tên cho tập dữ liệu bạn đang nhập.
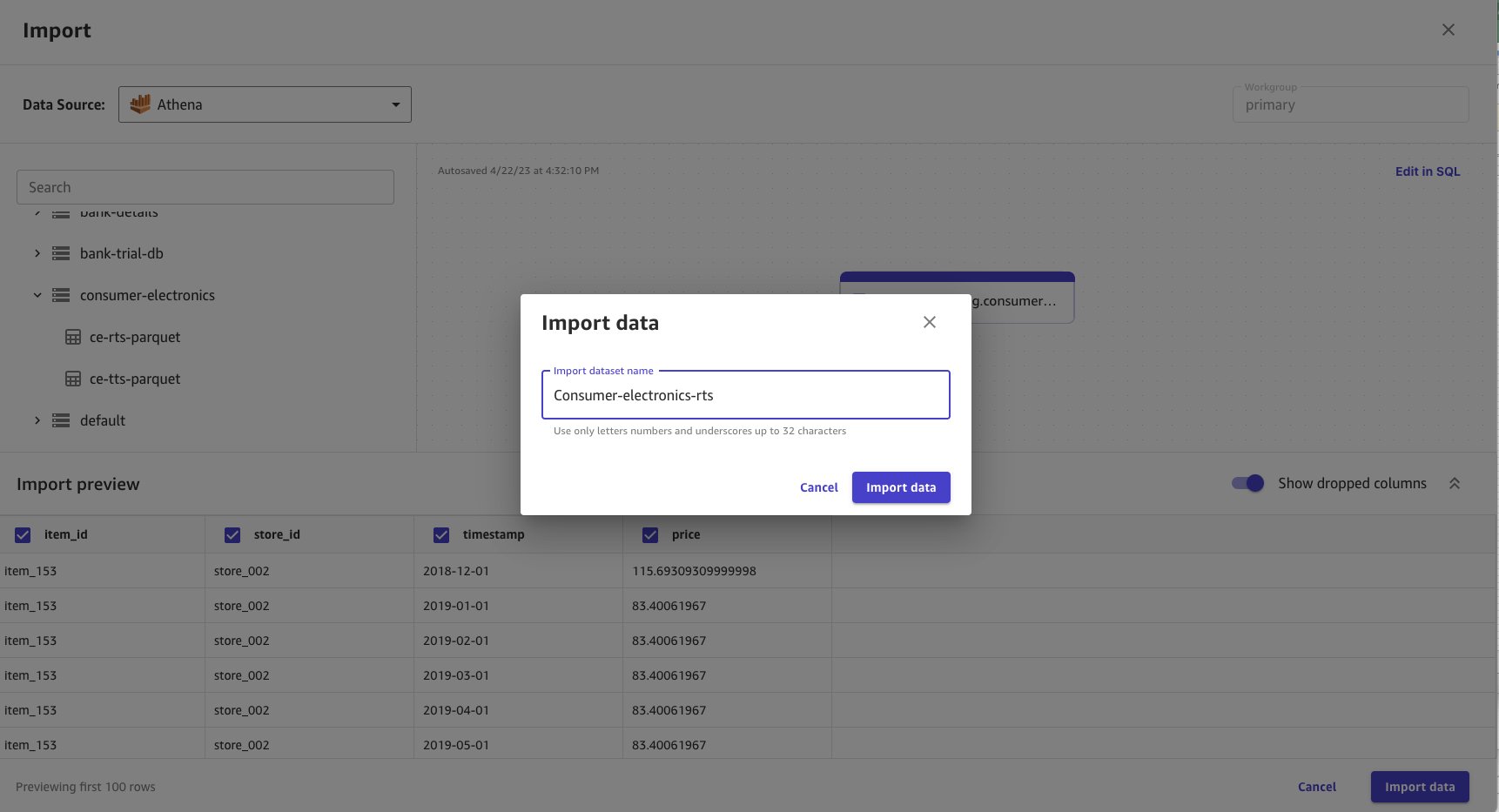
Nhập dữ liệu mất thời gian dựa trên kích thước dữ liệu. Tập dữ liệu trong ví dụ này nhỏ nên quá trình nhập mất vài giây. Khi nhập dữ liệu hoàn tất, trạng thái chuyển từ Chế biến đến Sẵn sàng.
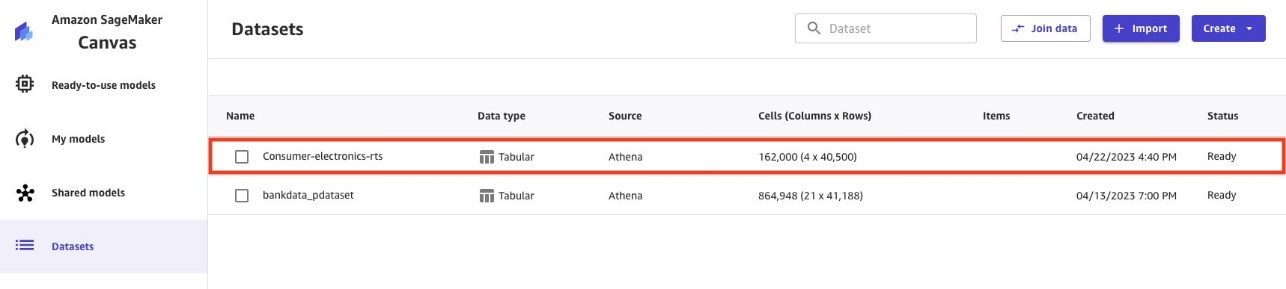
- Lặp lại quy trình nhập cho tập dữ liệu thứ hai (
ce-tts).
Khi ce-tts Dữ liệu sàn gỗ được nhập khẩu, Bộ dữ liệu pageshow cả hai bộ dữ liệu.
Các bộ dữ liệu đã nhập chứa dữ liệu chuỗi thời gian được nhắm mục tiêu và có liên quan. Bộ dữ liệu RTS có thể giúp các mô hình học sâu cải thiện độ chính xác của dự báo.
Hãy tham gia các bộ dữ liệu để chuẩn bị cho phân tích của chúng tôi.
- Chọn bộ dữ liệu.
- Chọn Tham gia dữ liệu.
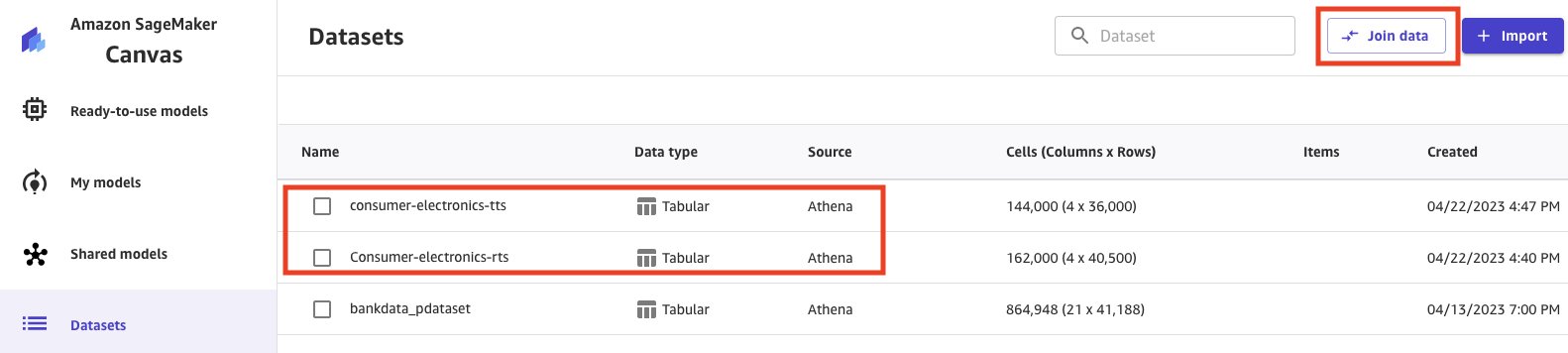
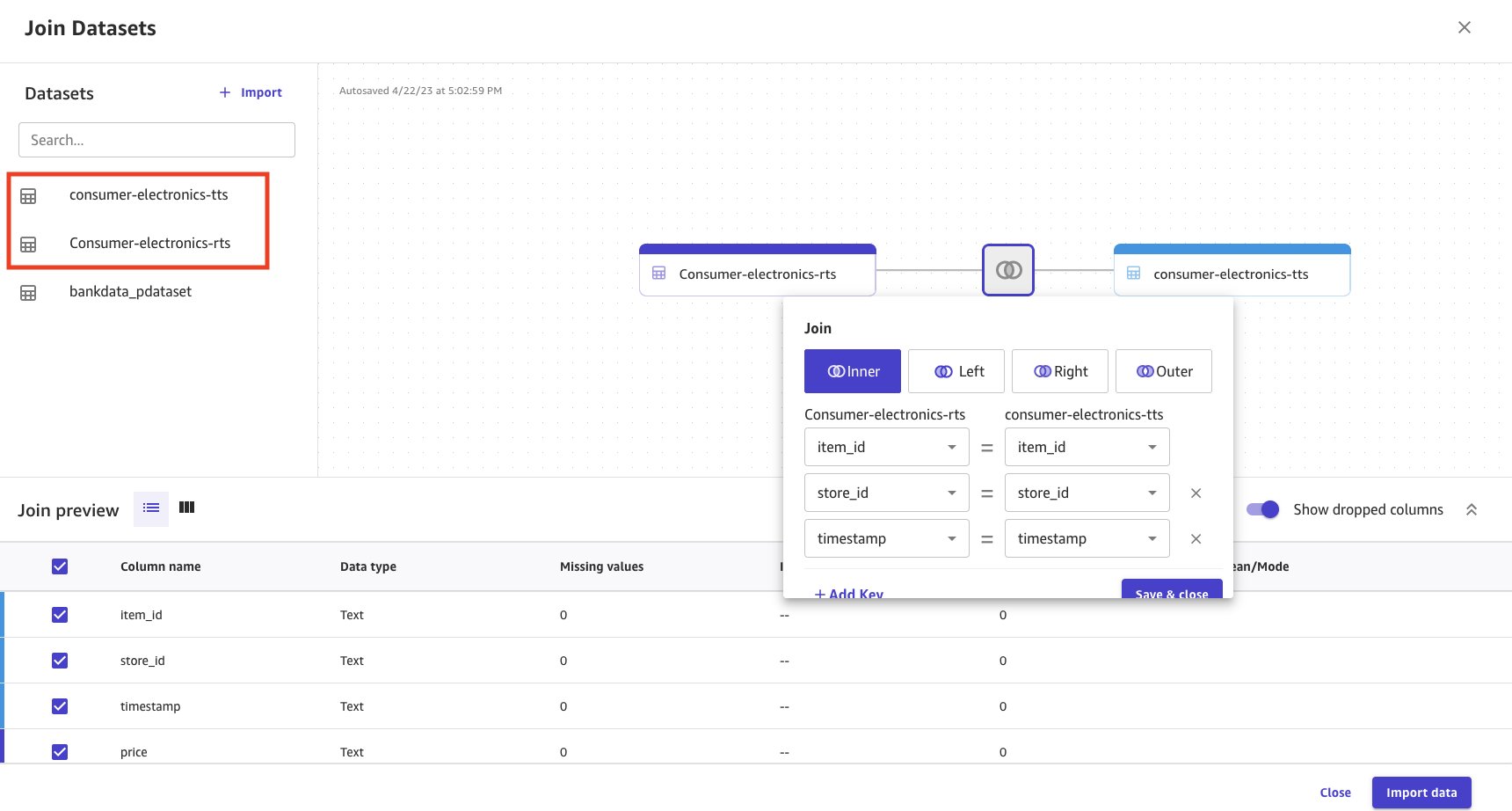
- Chọn và kéo cả hai bộ dữ liệu vào ngăn giữa, áp dụng phép nối bên trong.
- Chọn Tham gia để xem các điều kiện nối được áp dụng và để đảm bảo rằng nối bên trong được áp dụng và các cột bên phải được nối.
- Chọn Lưu và đóng để áp dụng điều kiện tham gia.
- Cung cấp tên cho tập dữ liệu đã tham gia.
- Chọn Nhập dữ liệu.
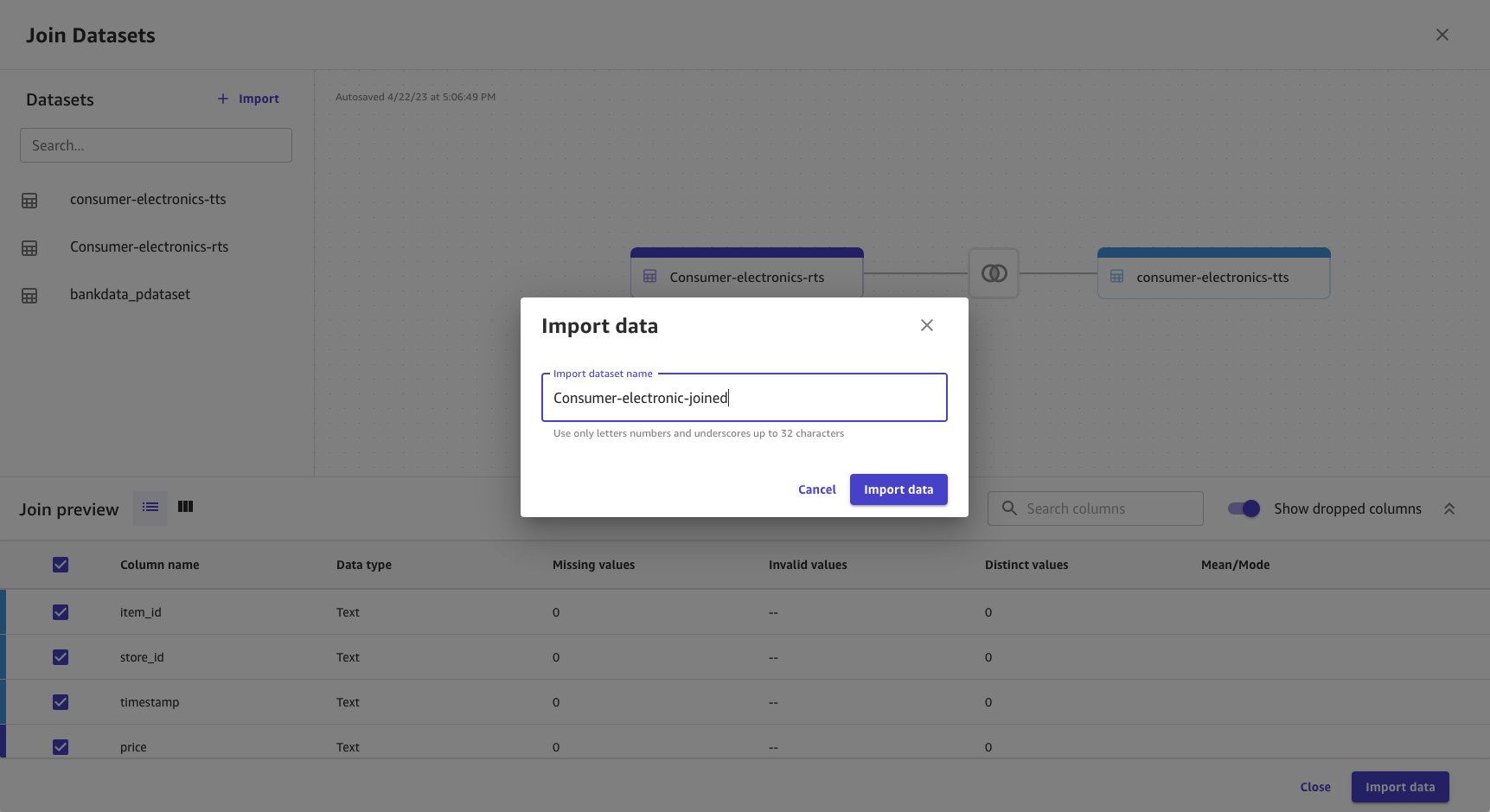
Dữ liệu đã tham gia được nhập và tạo dưới dạng tập dữ liệu mới. Nguồn tập dữ liệu đã tham gia được hiển thị dưới dạng Tham gia.
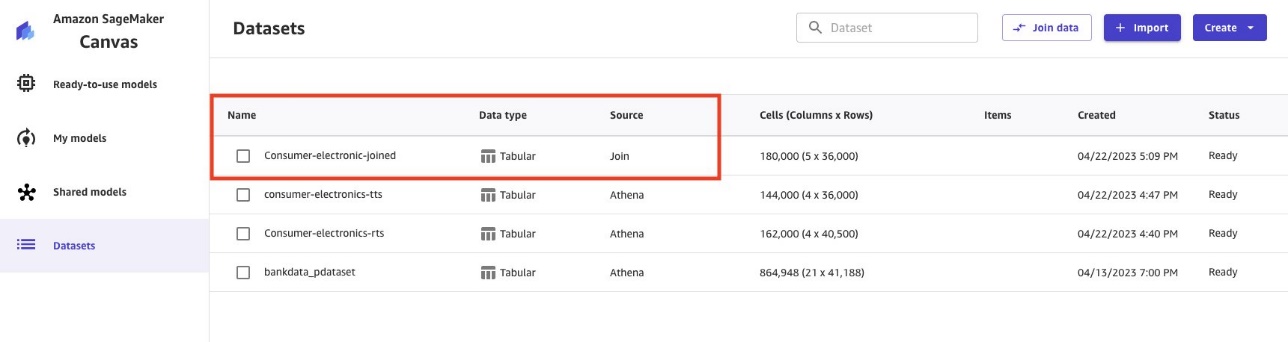
Sử dụng dữ liệu Parquet để tạo mô hình ML với Canvas
Dữ liệu Sàn gỗ từ Lake Formation hiện đã có trên Canvas. Bây giờ bạn có thể chạy phân tích ML của mình trên dữ liệu.
- Chọn Tạo một mô hình tùy chỉnh in Các mẫu sẵn sàng sử dụng khỏi Canvas sau khi nhập dữ liệu thành công.
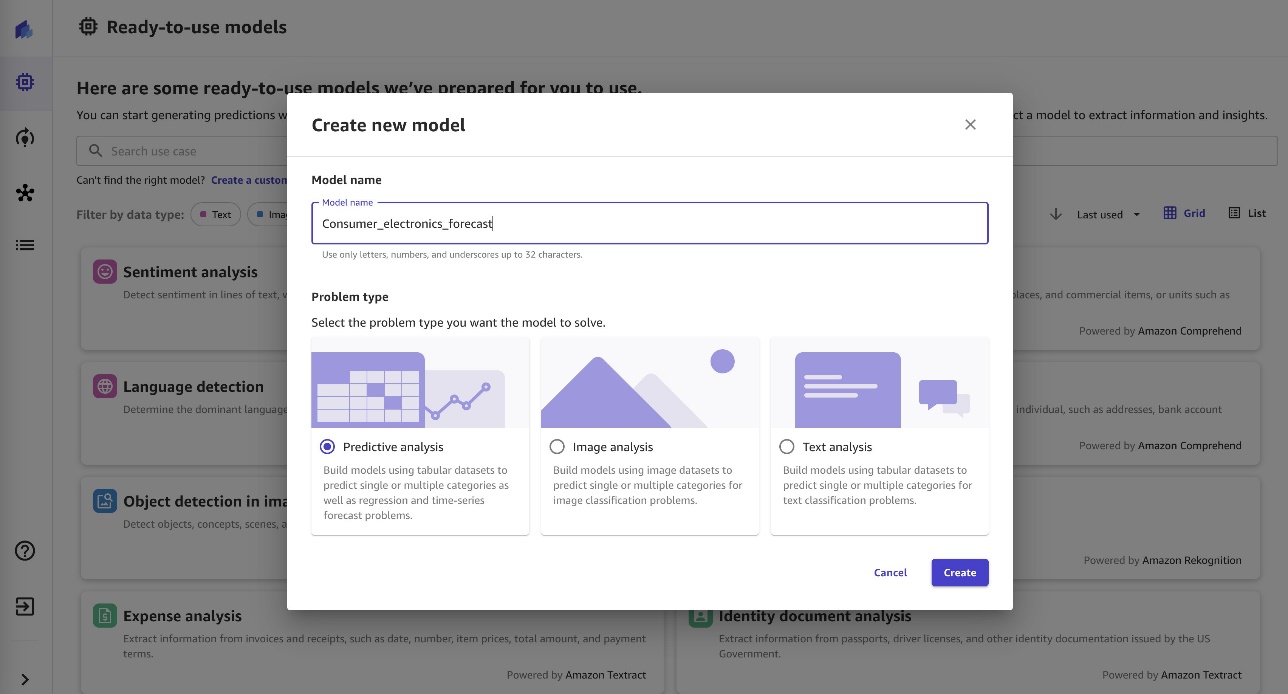
- Nhập tên cho mô hình.
- Chọn loại sự cố của bạn (đối với bài đăng này, Phân tích tiên đoán).
- Chọn Tạo.
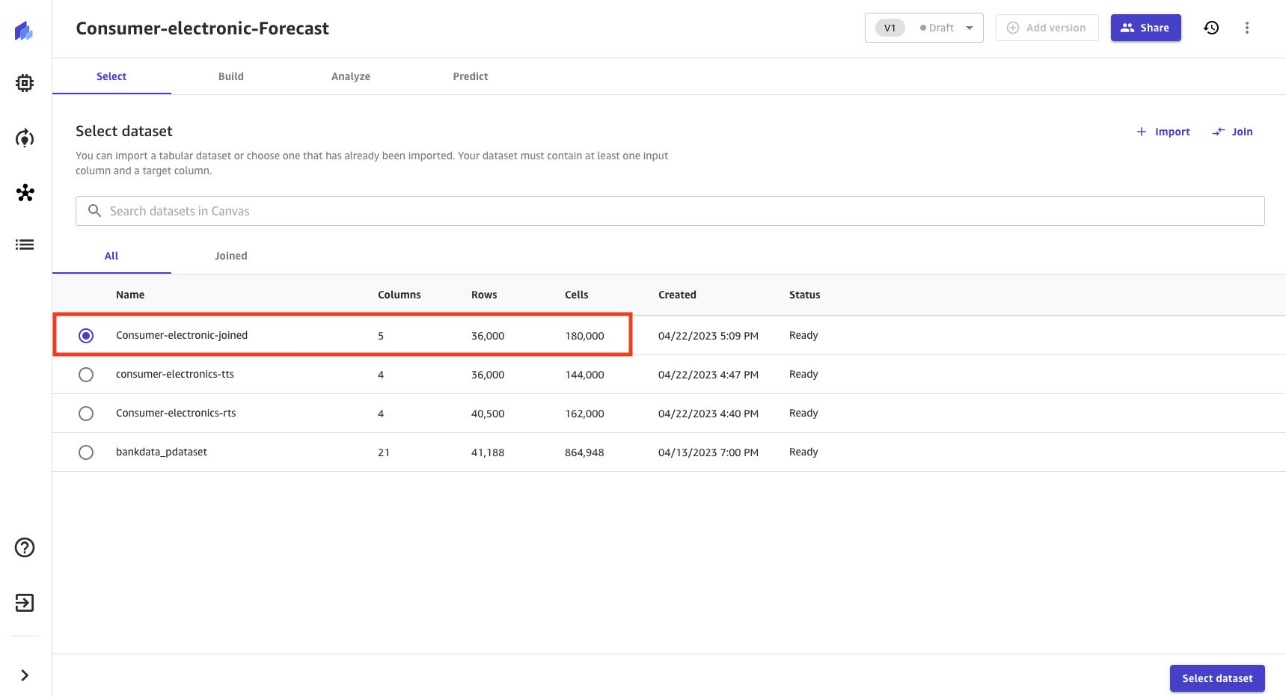
- Chọn hình ba gạch
consumer-electronic-joinedtập dữ liệu để đào tạo mô hình dự đoán nhu cầu đối với các mặt hàng điện tử.
- Chọn nhu cầu làm cột mục tiêu để dự báo nhu cầu cho các mặt hàng điện tử tiêu dùng.
Dựa trên dữ liệu được cung cấp cho Canvas, Loại mô hình được tự động dẫn xuất như Dự báo chuỗi thời gian và cung cấp một Định cấu hình mô hình chuỗi thời gian tùy chọn.
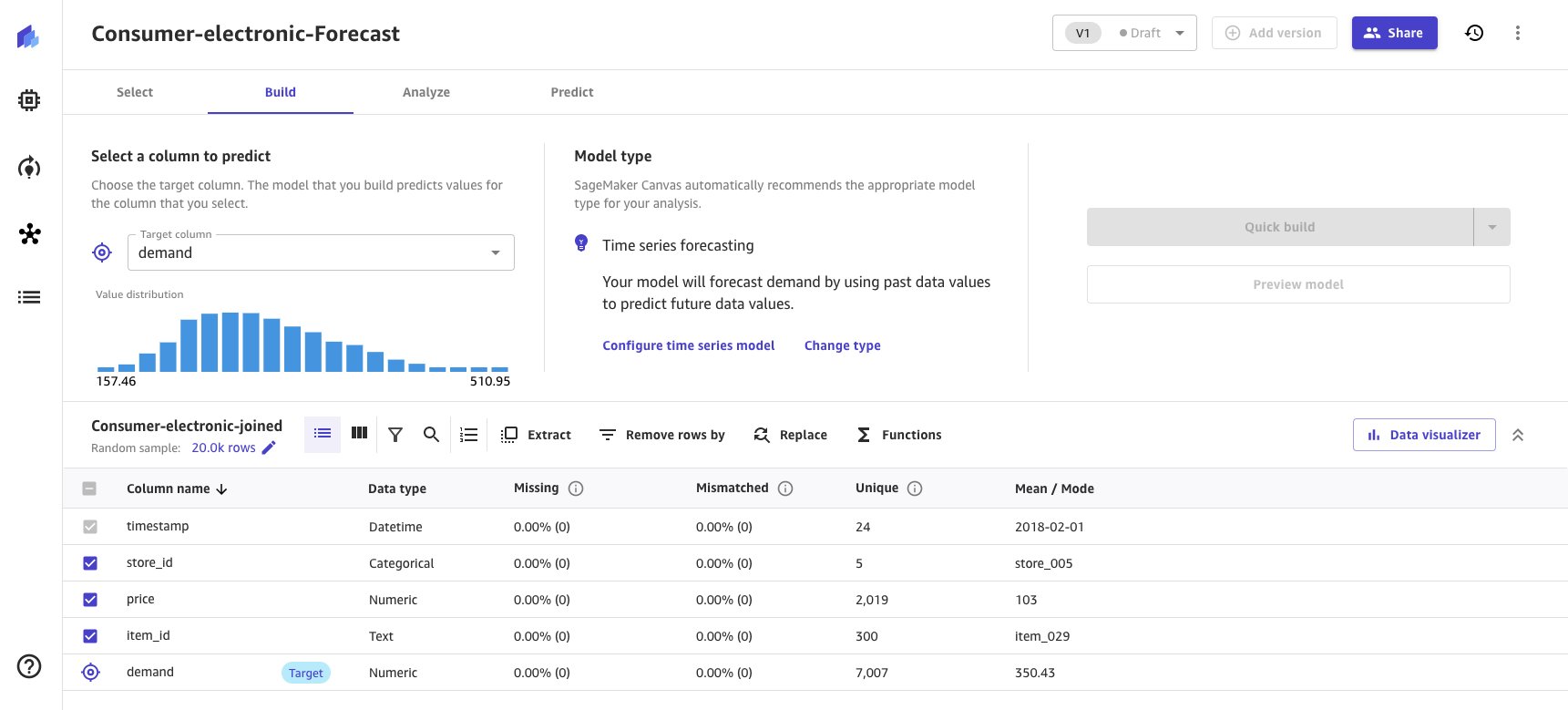
- Chọn Định cấu hình mô hình chuỗi thời gian liên kết để cung cấp các tùy chọn mô hình chuỗi thời gian.
- Nhập cấu hình dự báo như trong ảnh chụp màn hình sau.
- Loại trừ cột nhóm vì không có nhóm logic nào được thực thi cho tập dữ liệu.
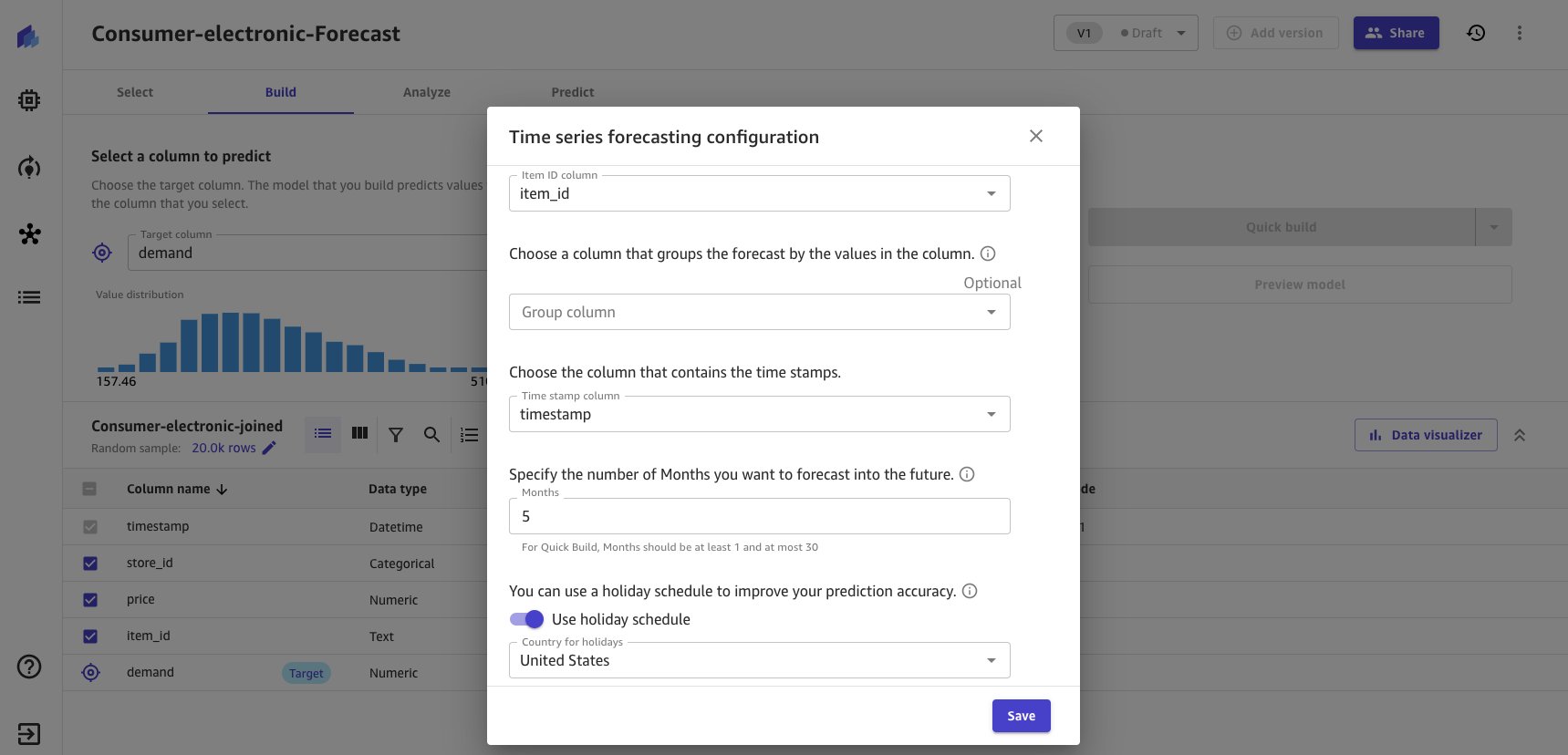
Để xây dựng mô hình, Canvas cung cấp hai tùy chọn xây dựng. Chọn tùy chọn theo sở thích của bạn. Quá trình xây dựng nhanh thường mất khoảng 15–20 phút, trong khi Tiêu chuẩn mất khoảng 4 giờ.
-
- Xây dựng nhanh chóng – Xây dựng mô hình trong thời gian ngắn so với xây dựng tiêu chuẩn; độ chính xác tiềm năng được trao đổi cho tốc độ
- Xây dựng tiêu chuẩn – Xây dựng mô hình tốt nhất từ quy trình được tối ưu hóa do AutoML cung cấp; tốc độ được trao đổi cho độ chính xác cao nhất
- Đối với bài viết này, chúng tôi chọn Xây dựng nhanh chóng cho mục đích minh họa.

Khi quá trình xây dựng nhanh hoàn tất, các chỉ số đánh giá mô hình được trình bày trong Phân tích phần.
- Chọn Dự đoán để chạy một dự đoán hoặc dự đoán hàng loạt.
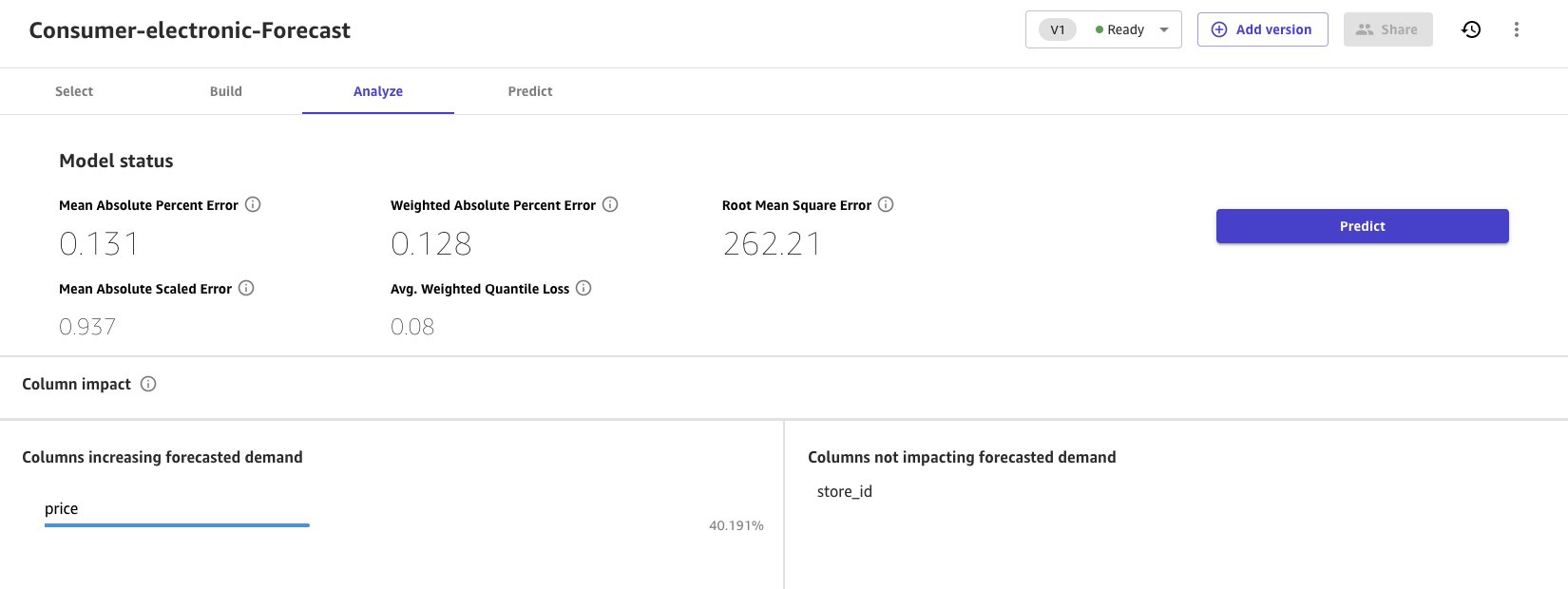
Làm sạch
Đăng xuất khỏi Canvas để tránh các khoản phí trong tương lai.
Kết luận
Doanh nghiệp có dữ liệu trong hồ dữ liệu ở nhiều định dạng khác nhau, bao gồm định dạng Sàn gỗ hiệu quả cao. Canvas đã ra mắt hơn 40 nguồn dữ liệu, bao gồm cả Athena, từ đó bạn có thể dễ dàng lấy dữ liệu ở nhiều định dạng khác nhau từ kho dữ liệu. Để tìm hiểu thêm, hãy tham khảo Nhập dữ liệu từ hơn 40 nguồn dữ liệu cho machine learning không dùng mã với Amazon SageMaker Canvas.
Trong bài đăng này, chúng tôi đã lấy các tệp Parquet do Lake Formation quản lý và nhập chúng vào Canvas bằng Athena. Mô hình Canvas ML dự báo nhu cầu của thiết bị điện tử tiêu dùng bằng cách sử dụng dữ liệu giá và nhu cầu lịch sử. Nhờ giao diện thân thiện với người dùng và hình ảnh trực quan sống động, chúng tôi đã hoàn thành việc này mà không cần viết một dòng mã nào. Canvas hiện cho phép các nhà phân tích kinh doanh sử dụng các tệp Parquet từ các nhóm kỹ thuật dữ liệu và xây dựng các mô hình ML, tiến hành phân tích và trích xuất thông tin chuyên sâu độc lập với các nhóm khoa học dữ liệu.
Để tìm hiểu thêm về Canvas, hãy tham khảo Dự đoán các loại lỗi máy bằng học máy không mã sử dụng Canvas. tham khảo Công bố Amazon SageMaker Canvas – Khả năng học máy trực quan, không dùng mã cho các nhà phân tích kinh doanh để biết thêm thông tin về cách tạo các mô hình ML bằng giải pháp không cần mã.
Giới thiệu về tác giả
 Gopi Mudiyala là Giám đốc tài khoản kỹ thuật cao cấp tại AWS. Anh ấy giúp khách hàng trong ngành Dịch vụ tài chính thực hiện các hoạt động của họ trong AWS. Là một người đam mê máy học, Gopi nỗ lực giúp khách hàng thành công trong hành trình ML của họ. Khi rảnh rỗi, anh ấy thích chơi cầu lông, dành thời gian cho gia đình và đi du lịch.
Gopi Mudiyala là Giám đốc tài khoản kỹ thuật cao cấp tại AWS. Anh ấy giúp khách hàng trong ngành Dịch vụ tài chính thực hiện các hoạt động của họ trong AWS. Là một người đam mê máy học, Gopi nỗ lực giúp khách hàng thành công trong hành trình ML của họ. Khi rảnh rỗi, anh ấy thích chơi cầu lông, dành thời gian cho gia đình và đi du lịch.
 Hariharan Suresh là Kiến trúc sư giải pháp cấp cao tại AWS. Anh ấy đam mê cơ sở dữ liệu, học máy và thiết kế các giải pháp sáng tạo. Trước khi gia nhập AWS, Hariharan là kiến trúc sư sản phẩm, chuyên gia triển khai ngân hàng lõi và nhà phát triển, đồng thời làm việc với các tổ chức BFSI trong hơn 11 năm. Ngoài công nghệ, anh ấy thích dù lượn và đạp xe.
Hariharan Suresh là Kiến trúc sư giải pháp cấp cao tại AWS. Anh ấy đam mê cơ sở dữ liệu, học máy và thiết kế các giải pháp sáng tạo. Trước khi gia nhập AWS, Hariharan là kiến trúc sư sản phẩm, chuyên gia triển khai ngân hàng lõi và nhà phát triển, đồng thời làm việc với các tổ chức BFSI trong hơn 11 năm. Ngoài công nghệ, anh ấy thích dù lượn và đạp xe.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/use-amazon-sagemaker-canvas-to-build-machine-learning-models-using-parquet-data-from-amazon-athena-and-aws-lake-formation/

