Giới thiệu
Một kỹ thuật thống kê đáng tin cậy để xác định tầm quan trọng là phân tích phương sai (ANOVA), đặc biệt khi so sánh nhiều hơn hai giá trị trung bình mẫu. Mặc dù phân phối t đủ để so sánh giá trị trung bình của hai mẫu, nhưng cần có ANOVA khi làm việc với ba mẫu trở lên cùng một lúc để xác định xem giá trị trung bình của chúng có giống nhau hay không vì chúng đến từ cùng một quần thể cơ bản.
Ví dụ, ANOVA có thể được sử dụng để xác định xem các loại phân bón khác nhau có tác động khác nhau đến sản lượng lúa mì ở các lô khác nhau hay không và liệu các phương pháp xử lý này có mang lại kết quả khác nhau về mặt thống kê trên cùng một quần thể hay không.

Giáo sư RA Fisher đã giới thiệu thuật ngữ 'Phân tích phương sai' vào năm 1920 khi giải quyết vấn đề phân tích dữ liệu nông học. Tính biến đổi là đặc điểm cơ bản của các sự kiện tự nhiên. Sự thay đổi tổng thể trong bất kỳ tập dữ liệu nhất định nào đều bắt nguồn từ nhiều nguồn, có thể được phân loại rộng rãi thành nguyên nhân có thể ấn định và nguyên nhân ngẫu nhiên.
Sự thay đổi do các nguyên nhân có thể ấn định có thể được phát hiện và đo lường trong khi sự thay đổi do nguyên nhân ngẫu nhiên nằm ngoài tầm kiểm soát của con người và không thể được xử lý riêng biệt.
Theo RA Fisher, Phân tích phương sai (ANOVA) là “Sự tách biệt phương sai có thể quy cho một nhóm nguyên nhân khỏi phương sai có thể quy cho nhóm khác”.
Mục tiêu học tập
- Hiểu khái niệm Phân tích phương sai (ANOVA) và tầm quan trọng của nó trong phân tích thống kê, đặc biệt khi so sánh nhiều mức trung bình mẫu.
- Tìm hiểu các giả định cần thiết để tiến hành thử nghiệm ANOVA và ứng dụng của nó trong các lĩnh vực khác nhau như y học, giáo dục, tiếp thị, sản xuất, tâm lý học và nông nghiệp.
- Khám phá quy trình từng bước thực hiện ANOVA một chiều, bao gồm thiết lập các giả thuyết không và thay thế, thu thập và tổ chức dữ liệu, tính toán thống kê nhóm, xác định tổng bình phương, tính toán bậc tự do, tính bình phương trung bình , tính toán thống kê F, xác định giá trị tới hạn và ra quyết định.
- Đạt được những hiểu biết thực tế về việc triển khai thử nghiệm ANOVA một chiều trong Python bằng thư viện scipy.stats.
- Hiểu mức ý nghĩa và cách giải thích thống kê F và giá trị p trong bối cảnh ANOVA.
- Tìm hiểu về các phương pháp phân tích hậu kiểm như Sự khác biệt đáng kể trung thực (HSD) của Tukey để phân tích sâu hơn về những khác biệt đáng kể giữa các nhóm.
Mục lục
Các giả định cho ANOVA TEST
Kiểm định ANOVA dựa trên thống kê kiểm định F.
Các giả định được đưa ra liên quan đến tính hợp lệ của thử nghiệm F trong ANOVA bao gồm:
- Các quan sát là độc lập.
- Quần thể cha mẹ mà từ đó các quan sát được thực hiện là bình thường.
- Về bản chất, các biện pháp xử lý và tác động môi trường khác nhau có tính chất bổ sung.
ANOVA một chiều
Một cách ANOVA là một kiểm tra thống kê được sử dụng để xác định xem có sự khác biệt có ý nghĩa thống kê về giá trị trung bình của ba nhóm trở lên đối với một yếu tố (biến độc lập) hay không. Nó so sánh phương sai giữa các nhóm với phương sai trong các nhóm để đánh giá xem những khác biệt này có thể là do cơ hội ngẫu nhiên hay do ảnh hưởng hệ thống của yếu tố đó.
Một số trường hợp sử dụng ANOVA một chiều từ các miền khác nhau là:
- Dược phẩm: ANOVA một chiều có thể được sử dụng để so sánh hiệu quả của các phương pháp điều trị khác nhau đối với một tình trạng bệnh lý cụ thể. Ví dụ, nó có thể được sử dụng để xác định xem liệu ba loại thuốc khác nhau có tác dụng khác nhau đáng kể trong việc giảm huyết áp hay không.
- Giáo dục: ANOVA một chiều có thể được sử dụng để phân tích xem liệu có sự khác biệt đáng kể về điểm kiểm tra giữa những học sinh được dạy bằng các phương pháp giảng dạy khác nhau hay không.
- Tiếp thị: ANOVA một chiều có thể được sử dụng để đánh giá xem liệu có sự khác biệt đáng kể về mức độ hài lòng của khách hàng giữa các sản phẩm của các thương hiệu khác nhau hay không.
- sản xuất: ANOVA một chiều có thể được sử dụng để phân tích xem có sự khác biệt đáng kể về độ bền của vật liệu được sản xuất bởi các quy trình sản xuất khác nhau hay không.
- Tâm lý học: ANOVA một chiều có thể được sử dụng để điều tra xem liệu có sự khác biệt đáng kể về mức độ lo lắng giữa những người tham gia tiếp xúc với các yếu tố gây căng thẳng khác nhau hay không.
- Nông nghiệp: ANOVA một chiều có thể được sử dụng để xác định xem liệu các loại phân bón khác nhau có dẫn đến năng suất cây trồng khác nhau đáng kể trong các thí nghiệm canh tác hay không.
Hãy hiểu điều này với ví dụ Nông nghiệp một cách chi tiết:
Trong nghiên cứu nông nghiệp, ANOVA một chiều có thể được sử dụng để đánh giá xem liệu các loại phân bón khác nhau có dẫn đến năng suất cây trồng khác nhau đáng kể hay không.
Tác dụng của phân bón đối với sự phát triển của cây trồng
Hãy tưởng tượng bạn đang nghiên cứu tác động của các loại phân bón khác nhau đến sự phát triển của cây trồng. Bạn bón 3 loại phân (A, B và C) cho từng nhóm cây. Sau một khoảng thời gian nhất định, bạn đo chiều cao trung bình của cây trong mỗi nhóm. Bạn có thể sử dụng ANOVA một chiều để kiểm tra xem có sự khác biệt đáng kể về chiều cao trung bình giữa các cây được trồng bằng các loại phân bón khác nhau hay không.
Bước 1: Giả thuyết không có giá trị và thay thế
Bước đầu tiên là đẩy mạnh các giả thuyết không và thay thế:
- Giả thuyết rỗng(H0): Giá trị trung bình của các nhóm là như nhau (không có sự khác biệt đáng kể về tốc độ sinh trưởng của cây do loại phân bón)
- Giả thuyết thay thế (H1): Ít nhất một nhóm có giá trị trung bình khác với các nhóm còn lại (loại phân bón có ảnh hưởng đáng kể đến sự phát triển của cây trồng).
Bước 2: Thu thập dữ liệu và tổ chức dữ liệu
Sau một thời gian sinh trưởng đã định, hãy đo cẩn thận chiều cao cuối cùng của từng cây trong cả ba nhóm. Bây giờ hãy sắp xếp dữ liệu của bạn. Mỗi cột đại diện cho một loại phân bón (A, B, C) và mỗi hàng chứa chiều cao của từng cây trong nhóm đó.
Bước 3: Tính toán thống kê nhóm
- Tính chiều cao cuối cùng trung bình của cây trong mỗi nhóm phân bón (A, B và C).
- Tính tổng số cây quan sát được (N) ở tất cả các nhóm.
- Xác định tổng số nhóm (K) trong trường hợp của chúng tôi, k=3(A, B, C)
Bước 4: Tính tổng bình phương
Vì vậy, Tổng bình phương, tổng bình phương giữa các nhóm, tổng bình phương trong nhóm sẽ được tính.
Ở đây, Tổng bình phương thể hiện tổng sự thay đổi về chiều cao cuối cùng của tất cả các cây.
Tổng bình phương giữa các nhóm phản ánh sự thay đổi quan sát được giữa chiều cao trung bình của ba nhóm phân bón. Và Tổng bình phương trong nhóm nắm bắt được sự thay đổi về chiều cao cuối cùng trong mỗi nhóm phân bón.
Bước 5: Tính bậc tự do
Bậc tự do xác định số lượng thông tin độc lập được sử dụng để ước tính một tham số tổng thể.
- Mức độ tự do giữa các nhóm: k-1 (số nhóm trừ 1) Vậy ở đây sẽ là 3-1 =2
- Mức độ tự do trong nhóm: Nk (Tổng số quan sát trừ đi số nhóm)
Bước 6: Tính bình phương trung bình
Bình phương trung bình có được bằng cách chia Tổng bình phương tương ứng cho bậc tự do.
- Bình phương trung bình giữa: Giữa các nhóm Tổng bình phương/Bậc tự do giữa các nhóm
- Bình phương trung bình bên trong: Tổng bình phương/Bậc tự do trong nhóm
Bước 7: Tính thống kê F
Thống kê F là thống kê kiểm tra được sử dụng để so sánh sự thay đổi giữa các nhóm với sự thay đổi trong các nhóm. Thống kê F cao hơn cho thấy tác động tiềm tàng mạnh mẽ hơn của loại phân bón đối với sự phát triển của cây trồng.
Thống kê F cho Anova một chiều được tính bằng công thức sau:
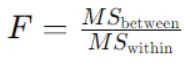
Ở đây,
MSbetween là bình phương trung bình giữa các nhóm, được tính bằng tổng bình phương giữa các nhóm chia cho bậc tự do giữa các nhóm.
MSwithin là bình phương trung bình trong các nhóm, được tính bằng tổng bình phương trong các nhóm chia cho bậc tự do trong các nhóm.
- Mức độ tự do giữa các nhóm(dof_between): dof_between = k-1
Trong đó k là số nhóm (cấp) của biến độc lập.
- Mức độ tự do trong nhóm(dof_within): dof_within = Nk
Trong đó N là số lượng quan sát và k là số nhóm (cấp độ) của biến độc lập.
Đối với ANOVA một chiều, tổng bậc tự do là tổng bậc tự do giữa các nhóm và trong các nhóm:
dof_total=dof_between+dof_within
Bước 8: Xác định giá trị quan trọng và quyết định
Chọn mức ý nghĩa (alpha) cho phân tích, thường chọn 0.05
Tra cứu giá trị F quan trọng ở cấp độ alpha đã chọn và Mức độ tự do được tính toán giữa các nhóm và Mức độ tự do trong nhóm bằng cách sử dụng bảng phân phối F.
So sánh thống kê F được tính toán với giá trị F tới hạn
- Nếu thống kê F được tính toán lớn hơn giá trị F tới hạn, hãy bác bỏ giả thuyết không (H0). Điều này cho thấy sự khác biệt có ý nghĩa thống kê về chiều cao trung bình của cây giữa ba nhóm phân bón.
- Nếu thống kê F được tính toán nhỏ hơn hoặc bằng giá trị F tới hạn thì không thể bác bỏ giả thuyết không (H0). Bạn không thể kết luận một sự khác biệt đáng kể dựa trên dữ liệu này.
Bước 9: Phân tích hậu kỳ (nếu cần)
Nếu giả thuyết khống bị từ chối, biểu thị sự khác biệt tổng thể đáng kể, bạn có thể muốn tìm hiểu sâu hơn. Hậu kỳ như Sự khác biệt đáng kể trung thực (HSD) của Tukey có thể giúp xác định nhóm phân bón cụ thể nào có chiều cao trung bình cây khác nhau về mặt thống kê.
Triển khai bằng Python:
import scipy.stats as stats
# Sample plant height data for each fertilizer type
plant_heights_A = [25, 28, 23, 27, 26]
plant_heights_B = [20, 22, 19, 21, 24]
plant_heights_C = [18, 20, 17, 19, 21]
# Perform one-way ANOVA
f_value, p_value = stats.f_oneway(plant_heights_A, plant_heights_B, plant_heights_C)
# Interpretation
print("F-statistic:", f_value)
print("p-value:", p_value)
# Significance level (alpha) - typically set at 0.05
alpha = 0.05
if p_value < alpha:
print("Reject H0: There is a significant difference in plant growth between the fertilizer groups.")
else:
print("Fail to reject H0: We cannot conclude a significant difference based on this sample.")
Đầu ra:

Bậc tự do giữa K-1 = 3-1 =2, trong đó k là số nhóm phân bón. Bậc tự do bên trong là Nk = 15-3= 12, trong đó N là tổng số điểm dữ liệu.
F-Critical tại dof(2,12) có thể được tính từ Bảng phân phối F ở mức ý nghĩa 0.05.
F-Quan trọng = 9.42
Vì F-Critical < F-statistic Vì vậy, chúng tôi bác bỏ giả thuyết không kết luận rằng có sự khác biệt đáng kể về tốc độ tăng trưởng thực vật giữa các nhóm phân bón.
Với giá trị p dưới 0.05, kết luận của chúng tôi vẫn nhất quán: chúng tôi bác bỏ giả thuyết khống, cho thấy sự khác biệt đáng kể về tốc độ tăng trưởng thực vật giữa các nhóm phân bón.
ANOVA hai chiều
ANOVA một chiều chỉ phù hợp với một yếu tố, nhưng nếu bạn có hai yếu tố ảnh hưởng đến thử nghiệm của mình thì sao? Sau đó, ANOVA hai chiều được sử dụng cho phép bạn phân tích tác động của hai biến độc lập lên một biến phụ thuộc duy nhất.
Bước 1: Thiết lập giả thuyết
- Giả thuyết vô hiệu (H0): Không có sự khác biệt đáng kể về chiều cao trung bình cuối cùng của cây do loại phân bón (A, B, C) hoặc thời điểm trồng (sớm, muộn) hoặc sự tương tác giữa chúng.
- Giả thuyết thay thế (H1): Ít nhất một điều sau đây là đúng:
- Loại phân bón có ảnh hưởng rõ rệt đến chiều cao trung bình cuối cùng.
- Thời điểm trồng có ảnh hưởng đáng kể đến chiều cao trung bình cuối cùng.
- Có sự tương tác đáng kể giữa loại phân bón và thời gian trồng. Điều này có nghĩa là tác động của một yếu tố (phân bón) phụ thuộc vào mức độ của yếu tố kia (thời gian trồng).
Bước 2: Thu thập và tổ chức dữ liệu
- Đo chiều cao cây cuối cùng.
- Sắp xếp dữ liệu của bạn thành một bảng với các hàng đại diện cho từng cây và cột cho:
- Loại phân bón (A, B, C)
- Thời điểm trồng (sớm, muộn)
- Chiều cao cuối cùng (cm)
Đây là bảng:

Bước 3: Tính tổng bình phương
Tương tự như ANOVA một chiều, bạn sẽ phải tính các tổng bình phương khác nhau để đánh giá sự thay đổi về độ cao cuối cùng:
- Tổng bình phương (SST): Đại diện cho tổng số biến thể trên tất cả các nhà máy. Tổng tác dụng chính của hình vuông:
- Các loại phân bón giữa (SSB_F): Phản ánh sự thay đổi do sự khác biệt về loại phân bón (tính trung bình qua các thời điểm trồng)
- Thời gian giữa các lần mạ (SSB_T): Phản ánh sự thay đổi do sự khác biệt về thời gian trồng trọt (tính trung bình giữa các loại phân bón).
- Tổng tương tác của bình phương (SSI): Nắm bắt sự thay đổi do tương tác giữa loại phân bón và thời gian trồng.
- Tổng bình phương trong nhóm (SSW): Thể hiện sự thay đổi về độ cao cuối cùng trong mỗi lần kết hợp thời gian bón phân.
Bước 4: Tính bậc tự do (df):
Bậc tự do xác định số lượng thông tin độc lập cho mỗi hiệu ứng.
- dfTotal: N-1 (tổng số quan sát trừ 1)
- dfPhân bón: Số loại phân bón -1
- dfThời gian trồng: Số lần trồng -1
- tương tác df: (Số loại phân bón -1) * (Số lần trồng -1)
- dfTrong vòng: dfTotal-dfPhân bón-dfplanting-dfTương tác
Bước 5: Tính bình phương trung bình
Chia mỗi Tổng bình phương cho bậc tự do tương ứng của nó.
- MS_Phân bón: SSB_F/dfPhân bón
- MS_Thời gian trồng: SSB_T/dfTrồng
- MS_Tương tác: Tương tác SSI/df
- MS_Trong: SSW/dfTrong
Bước 6: Tính thống kê F
Tính toán thống kê F riêng biệt cho loại phân bón, thời gian trồng và hiệu ứng tương tác:
- F_Bón phân: MS_Phân bón/MS_Within
- F_Thời gian trồng: MS_Thời gian trồng/ MS_Within
- F_Tương tác: MS_Inteaction/MS_Within
- F_Thời gian trồng: MS_Thời gian trồng/MS_Within
- F_Tương tác: MS_Interaction/ MS_Within
Bước 7: Xác định giá trị quan trọng và quyết định:
Chọn mức ý nghĩa (alpha) cho phân tích của bạn, thông thường chúng tôi lấy 0.05
Tra cứu các giá trị F quan trọng cho từng tác động (phân bón, thời gian trồng, tương tác) ở cấp độ alpha đã chọn và mức độ tự do tương ứng của chúng bằng cách sử dụng bảng phân phối F hoặc phần mềm thống kê.
So sánh số liệu thống kê F được tính toán của bạn với các giá trị F quan trọng cho từng hiệu ứng:
- Nếu thống kê F lớn hơn giá trị F tới hạn, hãy bác bỏ giả thuyết khống (H0) cho tác động đó. Điều này cho thấy sự khác biệt có ý nghĩa thống kê.
- Nếu thống kê F nhỏ hơn hoặc bằng giá trị F quan trọng thì không thể loại bỏ H0 vì ảnh hưởng đó. Điều này cho thấy sự khác biệt không có ý nghĩa thống kê.
Bước 8: Phân tích hậu kỳ (nếu cần)
Nếu giả thuyết không bị bác bỏ, biểu thị sự khác biệt tổng thể đáng kể, bạn có thể muốn tìm hiểu sâu hơn. Hậu kỳ như Sự khác biệt đáng kể trung thực (HSD) của Tukey có thể giúp xác định nhóm phân bón cụ thể nào có chiều cao trung bình cây khác nhau về mặt thống kê.
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
# Create a DataFrame from the dictionary
plant_heights = {
'Treatment': ['A', 'A', 'A', 'A', 'A', 'A',
'B', 'B', 'B', 'B', 'B', 'B',
'C', 'C', 'C', 'C', 'C', 'C'],
'Time': ['Early', 'Early', 'Early', 'Late', 'Late', 'Late',
'Early', 'Early', 'Early', 'Late', 'Late', 'Late',
'Early', 'Early', 'Early', 'Late', 'Late', 'Late'],
'Height': [25, 28, 23, 27, 26, 24,
20, 22, 19, 21, 24, 22,
18, 20, 17, 19, 21, 20]
}
df = pd.DataFrame(plant_heights)
# Fit the ANOVA model
model = ols('Height ~ C(Treatment) + C(Time) + C(Treatment):C(Time)', data=df).fit()
# Perform ANOVA
anova_table = sm.stats.anova_lm(model, typ=2)
# Print the ANOVA table
print(anova_table)
# Interpret the results
alpha = 0.05 # Significance level
if anova_table['PR(>F)'][0] < alpha:
print("nReject null hypothesis for Treatment factor.")
else:
print("nFail to reject null hypothesis for Treatment factor.")
if anova_table['PR(>F)'][1] < alpha:
print("Reject null hypothesis for Time factor.")
else:
print("Fail to reject null hypothesis for Time factor.")
if anova_table['PR(>F)'][2] < alpha:
print("Reject null hypothesis for Interaction between Treatment and Time.")
else:
print("Fail to reject null hypothesis for Interaction between Treatment and Time.")
Đầu ra:
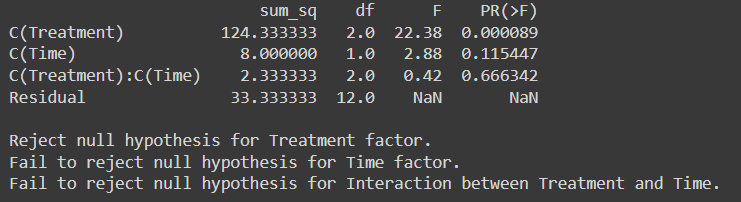
Giá trị tới hạn F đối với Xử lý ở mức tự do (2,12) ở mức ý nghĩa 0.05 từ Bảng phân phối F là 9.42
Giá trị tới hạn F của Thời gian ở bậc tự do (1,12) ở mức ý nghĩa 0.05 là 61.22
F- giá trị tới hạn cho sự tương tác giữa can thiệp và Thời gian ở mức ý nghĩa 0.05 ở mức độ tự do (2,12) là 9.42
Vì F-Critical < F-statistic Vì vậy, chúng tôi bác bỏ giả thuyết khống về Yếu tố điều trị.
Nhưng đối với Yếu tố thời gian và Tương tác giữa Điều trị và yếu tố Thời gian, chúng tôi đã không thể bác bỏ Giả thuyết Null vì giá trị thống kê F > Giá trị tới hạn F
Với giá trị p dưới 0.05, kết luận của chúng tôi vẫn nhất quán: chúng tôi bác bỏ giả thuyết khống về Yếu tố điều trị trong khi với giá trị p trên 0.05, chúng tôi không thể bác bỏ giả thuyết Không về yếu tố Thời gian và sự tương tác giữa Yếu tố điều trị và Thời gian.
Sự khác biệt giữa ANOVA một chiều và ANOVA HAI chiều
ANOVA một chiều và ANOVA hai chiều đều là các kỹ thuật thống kê được sử dụng để phân tích sự khác biệt giữa các nhóm, nhưng chúng khác nhau về số lượng biến độc lập mà chúng xem xét và độ phức tạp của thiết kế thử nghiệm.
Dưới đây là những điểm khác biệt chính giữa ANOVA một chiều và ANOVA hai chiều:
| Aspect | ANOVA một chiều | ANOVA hai chiều |
|---|---|---|
| Số lượng biến | Phân tích một biến độc lập (yếu tố) trên một biến phụ thuộc liên tục | Phân tích hai biến độc lập (yếu tố) trên một biến phụ thuộc liên tục |
| Thiết kế thử nghiệm | Một biến độc lập phân loại có nhiều cấp độ (nhóm) | Hai biến (yếu tố) độc lập có tính phân loại, thường được gắn nhãn là A và B, với nhiều cấp độ. Cho phép kiểm tra các tác dụng chính và tác dụng tương tác |
| Sự giải thích | Cho thấy sự khác biệt đáng kể giữa các phương tiện nhóm | Cung cấp thông tin về tác động chính của các yếu tố (A và B) và sự tương tác của chúng. Giúp đánh giá sự khác biệt giữa các cấp độ yếu tố và sự phụ thuộc lẫn nhau |
| phức tạp | Tương đối đơn giản và dễ hiểu | Phức tạp hơn, phân tích tác động chính của hai yếu tố và sự tương tác của chúng. Yêu cầu xem xét cẩn thận các mối quan hệ yếu tố |
Kết luận
ANOVA là một công cụ mạnh mẽ để phân tích sự khác biệt giữa các giá trị trung bình của nhóm, rất cần thiết khi so sánh nhiều hơn hai giá trị trung bình mẫu. ANOVA một chiều đánh giá tác động của một yếu tố duy nhất đến kết quả liên tục, trong khi ANOVA hai chiều mở rộng phân tích này để xem xét hai yếu tố và tác động tương tác của chúng. Hiểu được những khác biệt này cho phép các nhà nghiên cứu lựa chọn phương pháp phân tích phù hợp nhất cho các thiết kế thử nghiệm và câu hỏi nghiên cứu của họ.
Những câu hỏi thường gặp
A. ANOVA là viết tắt của Phân tích phương sai, một phương pháp thống kê được sử dụng để phân tích sự khác biệt giữa các phương tiện nhóm. Nó được sử dụng khi so sánh các phương tiện giữa ba nhóm trở lên để xác định xem có sự khác biệt đáng kể hay không.
A. ANOVA một chiều được sử dụng khi bạn có một biến (yếu tố) độc lập được phân loại với nhiều cấp độ và bạn muốn so sánh giá trị trung bình của các cấp độ này. Ví dụ: so sánh hiệu quả của các phương pháp điều trị khác nhau trên một kết quả duy nhất.
A. ANOVA hai chiều được sử dụng khi bạn có hai biến (yếu tố) độc lập được phân loại và bạn muốn phân tích tác động của chúng đối với một biến phụ thuộc liên tục, cũng như sự tương tác giữa hai yếu tố. Nó rất hữu ích cho việc nghiên cứu tác động kết hợp của hai yếu tố lên một kết quả.
A. Giá trị p trong ANOVA cho biết xác suất quan sát được dữ liệu nếu giả thuyết khống (không có sự khác biệt đáng kể giữa các giá trị trung bình của nhóm) là đúng. Giá trị p thấp (< 0.05) gợi ý rằng có bằng chứng quan trọng bác bỏ giả thuyết không và kết luận rằng có sự khác biệt giữa các nhóm.)
A. Thống kê F trong ANOVA đo tỷ lệ phương sai giữa các nhóm với phương sai trong các nhóm. Thống kê F cao hơn cho thấy phương sai giữa các nhóm lớn hơn so với phương sai trong các nhóm, cho thấy sự khác biệt đáng kể giữa các phương tiện của nhóm.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2024/04/one-way-and-two-way-analysis-of-variance-anova/

