Các nhà sản xuất chip đang sử dụng cả công nghệ tiến hóa và công nghệ mang tính cách mạng để đạt được những cải tiến lớn về hiệu suất ở mức công suất tương tự hoặc thấp hơn, báo hiệu sự thay đổi cơ bản từ các thiết kế hướng đến sản xuất sang thiết kế do các kiến trúc bán dẫn điều khiển.
Trước đây, hầu hết các con chip đều chứa một hoặc hai công nghệ tiên tiến, chủ yếu là để theo kịp những cải tiến dự kiến về kỹ thuật in thạch bản ở mỗi nút quy trình mới cứ sau vài năm. Những cải tiến đó dựa trên lộ trình của ngành đòi hỏi những lợi ích có thể dự đoán được nhưng không đáng kể theo thời gian. Giờ đây, với sự bùng nổ dữ liệu được thúc đẩy bởi các mô hình ngôn ngữ lớn và nhiều cảm biến hơn - cũng như sự cạnh tranh ngày càng tăng giữa các công ty hệ thống thiết kế chip của riêng họ và sự cạnh tranh quốc tế ngày càng tăng liên quan đến AI - các quy tắc đang thay đổi khá đáng kể ở lĩnh vực thiết kế chip hàng đầu. Những cải tiến gia tăng hiện đang được kết hợp với những bước nhảy vọt về hiệu suất xử lý và mặc dù những cải tiến đó mang lại khả năng tính toán và phân tích ở cấp độ hoàn toàn mới, nhưng chúng cũng đòi hỏi một loạt sự đánh đổi hoàn toàn mới.
Trọng tâm của những thay đổi này là các kiến trúc chip được tùy chỉnh cao, một số liên quan đến các chiplet được phát triển tại các nút quy trình tiên tiến nhất. Việc xử lý song song gần như là điều hiển nhiên và các bộ tăng tốc cũng vậy nhằm vào các loại dữ liệu và hoạt động cụ thể. Trong một số trường hợp, các hệ thống mini này sẽ không được bán thương mại vì chúng mang lại lợi thế cạnh tranh cho các trung tâm dữ liệu. Nhưng chúng cũng có thể bao gồm các công nghệ thương mại sẵn có khác, chẳng hạn như lõi xử lý hoặc bộ tăng tốc hoặc công nghệ tính toán trong hoặc gần bộ nhớ để giảm độ trễ, cũng như các sơ đồ bộ nhớ đệm khác nhau, quang học đóng gói chung và kết nối nhanh hơn nhiều. Nhiều phát triển trong số này đã được nghiên cứu hoặc đứng ngoài lề trong nhiều năm và hiện đang được triển khai đầy đủ.
Amin Vahdat, chuyên gia kỹ thuật và phó chủ tịch hệ thống ML tại Google Research, đã lưu ý trong bài thuyết trình tại hội nghị Hot Chips 2023 gần đây rằng chip ngày nay có thể giải quyết những vấn đề không thể tưởng tượng được một thập kỷ trước và việc học máy sẽ chiếm một vị thế “ngày càng tăng”. phần nhỏ” của chu kỳ tính toán.
Vahdat nói: “Chúng ta cần thay đổi cách nhìn về thiết kế hệ thống. “Nhu cầu điện toán tăng lên trong 1, 10, 50 năm qua thật đáng kinh ngạc… Trong khi có rất nhiều đổi mới về [thuật toán] thưa thớt, khi bạn nhìn vào [hình 60, bên dưới], nó cho thấy gấp XNUMX lần một năm, được duy trì, về số lượng thông số trên mỗi mô hình. Và chúng ta cũng biết rằng chi phí tính toán tăng siêu tuyến tính với số lượng tham số. Vì vậy loại cơ sở hạ tầng máy tính mà chúng ta phải xây dựng để đáp ứng thách thức này phải thay đổi. Điều quan trọng cần lưu ý là chúng tôi sẽ không có được vị trí như ngày hôm nay nếu cố gắng thực hiện điều này trên máy tính có mục đích chung. Trí tuệ tính toán thông thường mà chúng tôi đã phát triển trong XNUMX hoặc XNUMX năm qua đã bị ném ra ngoài cửa sổ.”
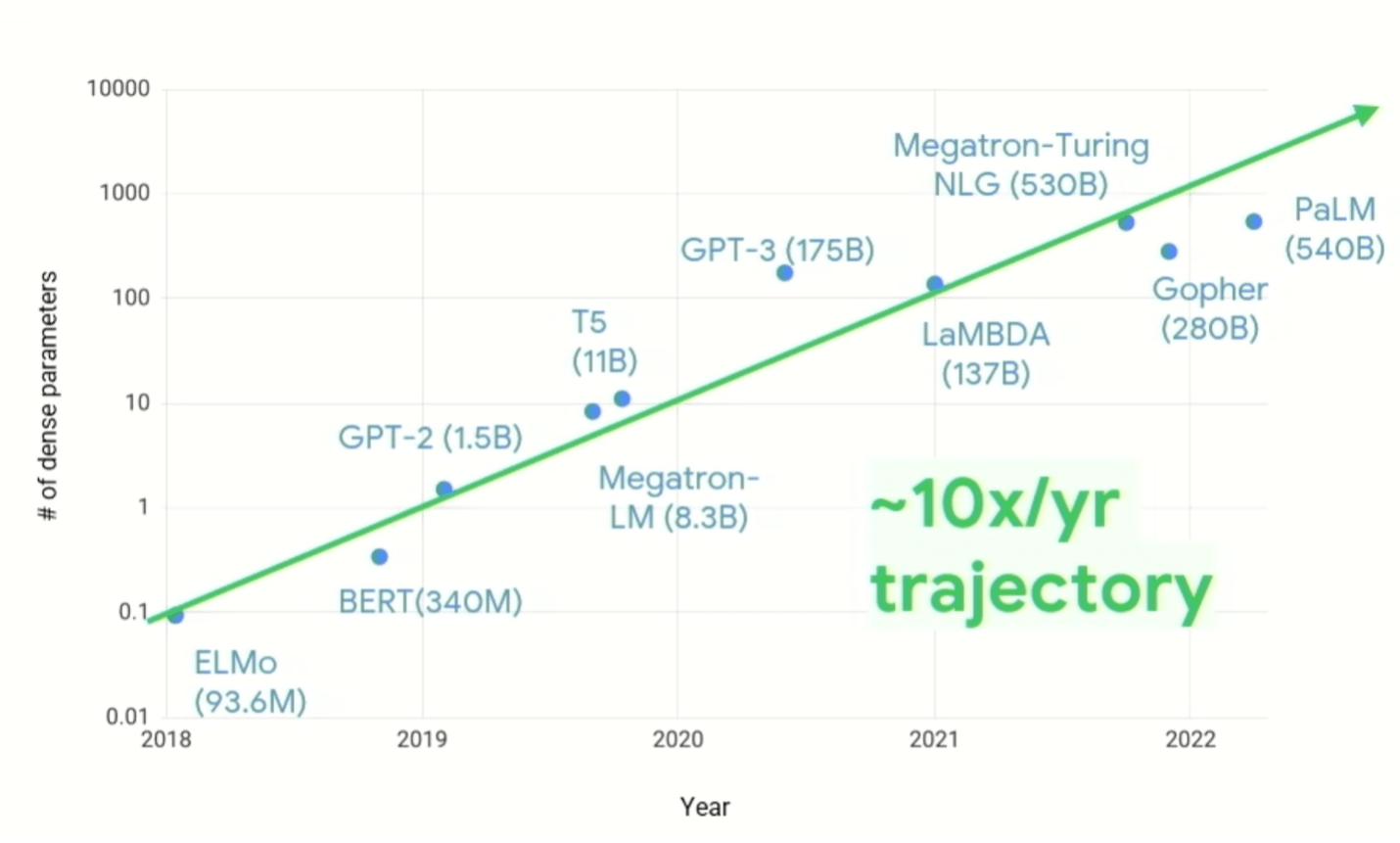
Hình 1: Tăng trưởng nhu cầu về tính toán ML. Nguồn: Nghiên cứu của Google/Hot Chips 2023
Tuy nhiên, điều đó không có nghĩa là các vấn đề cũ biến mất. Năng lượng và tản nhiệt là những vấn đề đau đầu dai dẳng đối với các nhóm thiết kế và chúng trở nên khó giải quyết hơn khi tốc độ và số lượng xử lý tăng lên. Việc tăng tần số xung nhịp không còn là một lựa chọn đơn giản sau khoảng 3GHz do mật độ nhiệt cao hơn và chip không có khả năng tản nhiệt đó. Và trong khi các mô hình dữ liệu thưa thớt và đồng thiết kế phần cứng-phần mềm giải quyết vấn đề hiệu quả của phần mềm chạy trên nhiều phần tử xử lý khác nhau, cũng như khả năng xử lý nhiều hơn trên mỗi chu kỳ điện toán, thì không còn một núm xoay duy nhất nào để cải thiện hiệu suất trên mỗi watt.
Đổi mới bộ nhớ
Tuy nhiên, có rất nhiều núm nhỏ và cỡ trung, một số chưa bao giờ được sử dụng trong hệ thống sản xuất vì không có lý do kinh tế để làm như vậy. Nền kinh tế đó đã thay đổi đáng kể với sự gia tăng dữ liệu và chuyển sang đổi mới kiến trúc, điều này được thể hiện rõ ràng tại hội nghị Hot Chips năm nay.
Trong số các tùy chọn có xử lý trong bộ nhớ/gần bộ nhớ, cũng như xử lý gần nguồn dữ liệu hơn. Vấn đề ở đây là việc di chuyển khối lượng lớn dữ liệu đòi hỏi tài nguyên hệ thống đáng kể - băng thông, năng lượng và thời gian - điều này có tác động kinh tế trực tiếp đến điện toán. Nói chung, phần lớn dữ liệu được thu thập và xử lý là vô ích. Ví dụ: dữ liệu liên quan trong nguồn cấp dữ liệu video trên ô tô hoặc hệ thống an ninh có thể chỉ tồn tại trong một hoặc hai giây, trong khi có thể mất hàng giờ dữ liệu để sắp xếp. Xử lý trước dữ liệu gần nguồn hơn và sử dụng AI để xác định dữ liệu quan tâm, nghĩa là chỉ một phần nhỏ cần được gửi đi để xử lý và lưu trữ thêm.
Jin Hyun Kim, kỹ sư trưởng của Samsung cho biết: “Phần lớn mức tiêu thụ năng lượng đến từ việc di chuyển dữ liệu”. Ông chỉ ra ba giải pháp để nâng cao hiệu quả và tăng cường hiệu suất:
- Xử lý trong bộ nhớ để có băng thông và công suất cực cao, sử dụng HBM;
- Xử lý trong bộ nhớ cho các thiết bị tiêu thụ điện năng thấp yêu cầu dung lượng cao, sử dụng LPDDR và
- Xử lý gần bộ nhớ bằng CXL cho dung lượng cực cao với chi phí vừa phải.
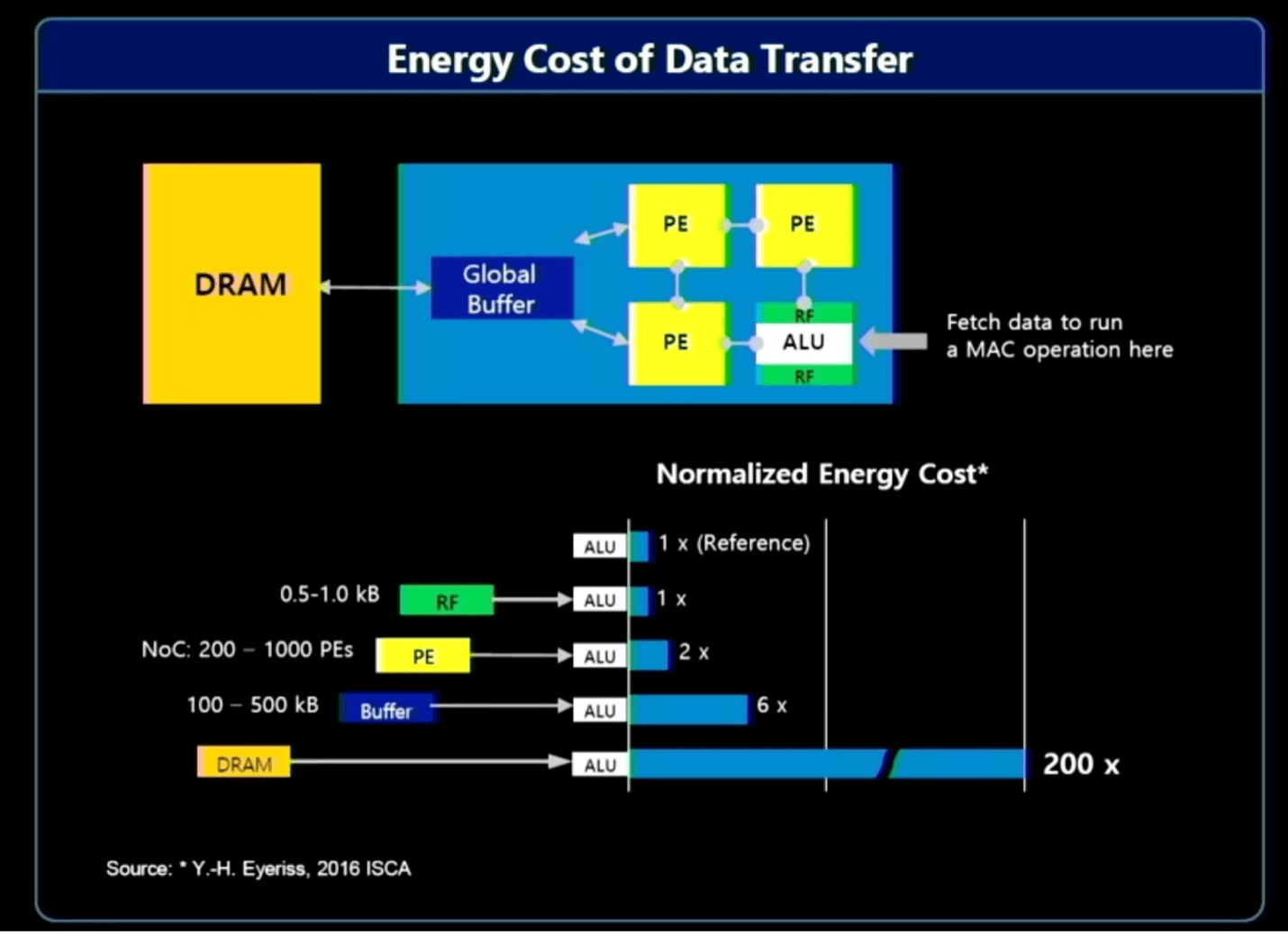
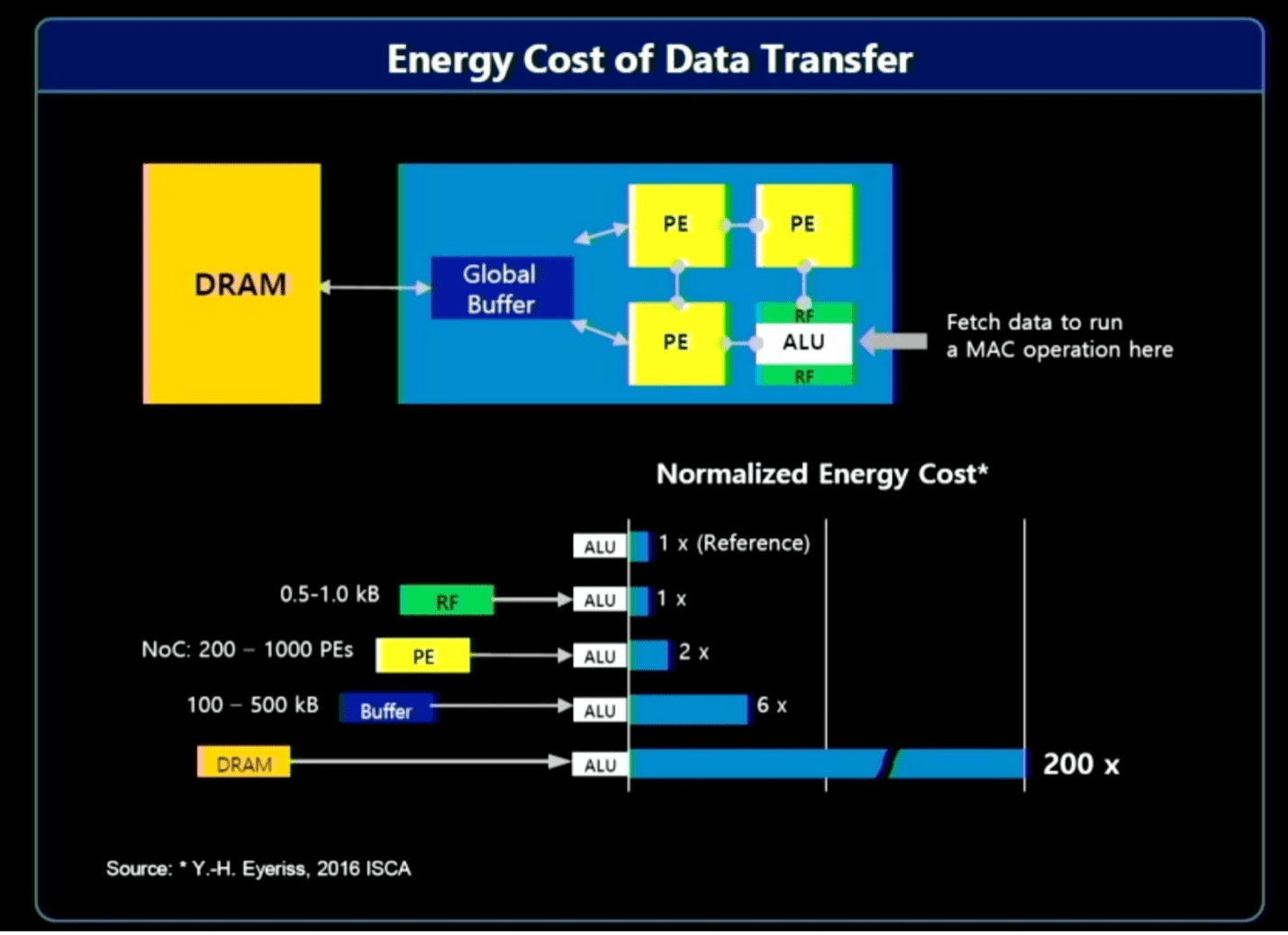
Hình 2: Chi phí tài nguyên cho việc di chuyển dữ liệu. Nguồn: Samsung/Hot Chips 2023
Xử lý trong bộ nhớ đã có từ nhiều năm nay và không có nhiều chuyển biến cho đến gần đây. Các mô hình ngôn ngữ lớn đã thay đổi nền kinh tế một cách mạnh mẽ đến mức giờ đây nó trở nên thú vị hơn nhiều và điều đó vẫn không bị các nhà cung cấp bộ nhớ lớn đánh mất.
Một cải tiến mới cho khái niệm này là khả năng tăng tốc trong bộ nhớ, đặc biệt hữu ích cho các hàm nhân và tích lũy (MAC) cho AI/ML, trong đó lượng dữ liệu cần được xử lý nhanh chóng đang bùng nổ. Với Generative Pre-Trained Transformer 3 (GPT-3) và GPT4, chỉ cần tải dữ liệu cũng cần băng thông lớn. Có nhiều thách thức liên quan đến điều đó, bao gồm cách thực hiện việc này một cách hiệu quả trong khi tối đa hóa hiệu suất và thông lượng, cách mở rộng quy mô để xử lý sự gia tăng nhanh chóng về số lượng tham số trong các mô hình ngôn ngữ lớn và cách xây dựng tính linh hoạt để thích ứng với những thay đổi trong tương lai.
Yonkwee Kwon, giám đốc cảm biến kỹ thuật cấp cao tại SK hynix America, cho biết: “Suy nghĩ ban đầu của chúng tôi coi bộ nhớ như một máy gia tốc. “Mục tiêu đầu tiên là cho phép mở rộng quy mô hiệu quả. Nhưng điều quan trọng là phải có hiệu suất cao. Và cuối cùng, chúng tôi đã thiết kế kiến trúc hệ thống để dễ dàng lập trình đồng thời giảm thiểu chi phí cấu trúc hệ thống nhưng vẫn cho phép xếp chồng phần mềm một cách linh hoạt.
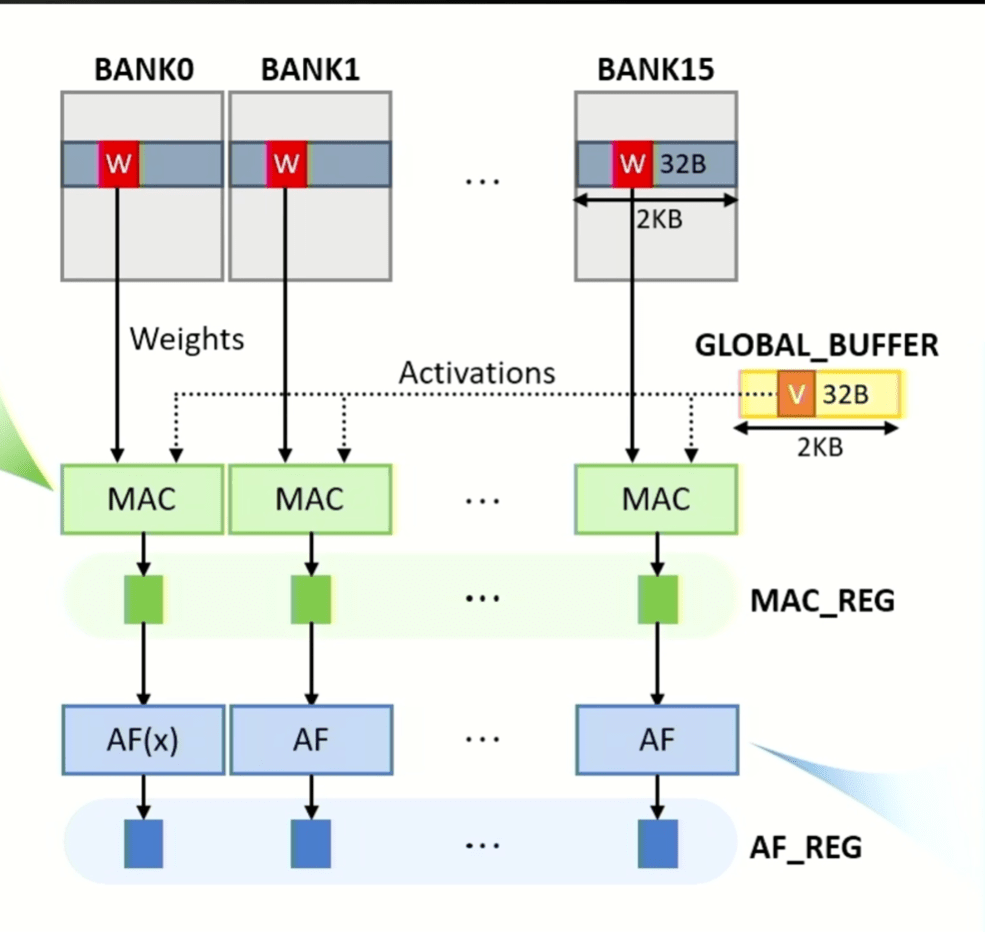
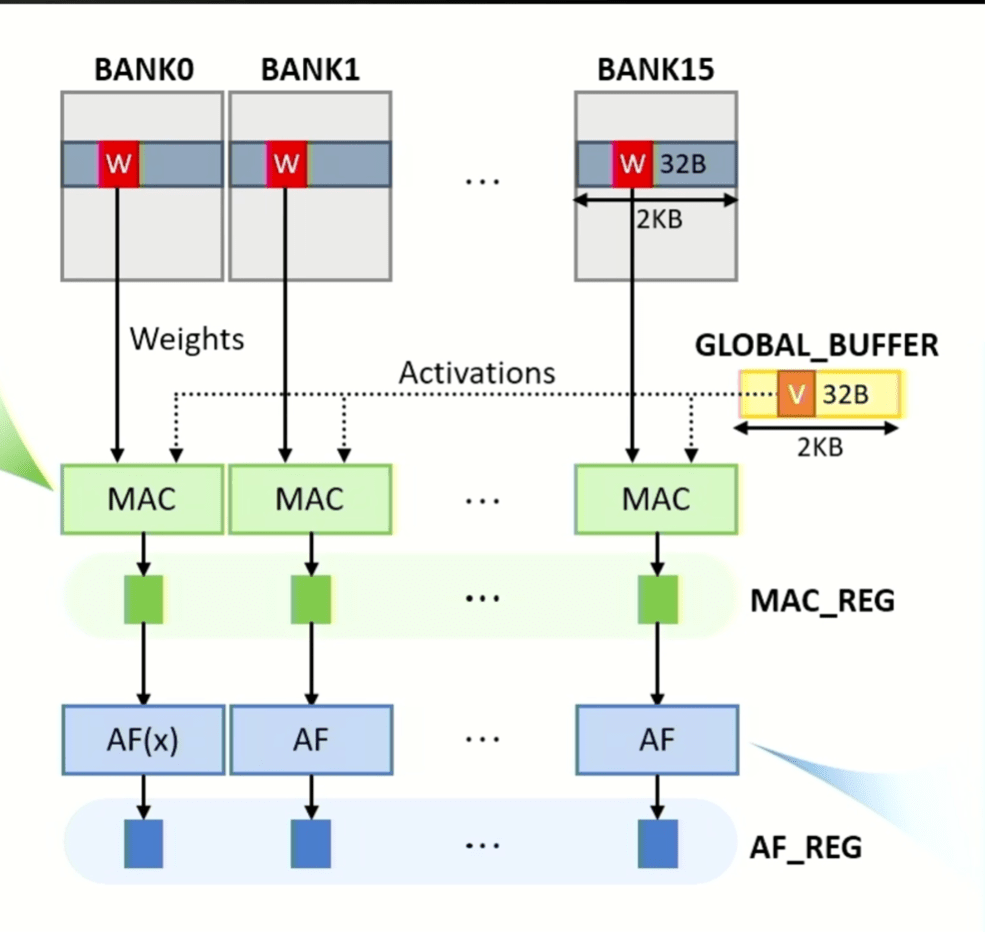
Hình 3: Các hoạt động MAC và kích hoạt có thể được thực hiện song song ở tất cả các ngân hàng, với dữ liệu ma trận trọng số có nguồn gốc từ các ngân hàng và dữ liệu vectơ có nguồn gốc từ bộ đệm toàn cầu. Kết quả MAC và hàm kích hoạt được lưu trữ trong các chốt tương ứng được gọi là MAC_REG và AF_REG. Nguồn: SK hynix/Hot Chips 2023
Cải tiến CPU
Mặc dù những thay đổi trong bộ nhớ giúp giảm lượng dữ liệu cần di chuyển nhưng đó chỉ là một phần của vấn đề. Thử thách tiếp theo là tăng tốc các yếu tố xử lý chính. Một cách để làm điều đó là dự đoán nhánh, về cơ bản dự đoán hoạt động tiếp theo sẽ là gì - gần giống như cách một công cụ tìm kiếm trên internet thực hiện. Tuy nhiên, như với bất kỳ kiến trúc song song nào, điều quan trọng là giữ cho các phần tử xử lý khác nhau hoạt động đầy đủ mà không có thời gian nhàn rỗi để tối đa hóa hiệu suất và hiệu quả.
Arm đang tạo ra một bước ngoặt mới cho khái niệm này với thiết kế Neoverse V2, tách nhánh khỏi tìm nạp. Kết quả là hiệu quả cao hơn bằng cách giảm thiểu tình trạng ngừng hoạt động và phục hồi nhanh hơn sau những dự đoán sai. Magnus Bruce, kiến trúc sư trưởng CPU tại Arm, cho biết: “Cơ chế cấp dữ liệu động cho phép lõi điều chỉnh mức độ tích cực và chủ động ngăn chặn tắc nghẽn hệ thống”. “Những khái niệm cơ bản này cho phép chúng tôi đẩy chiều rộng và chiều sâu của máy trong khi vẫn duy trì quy trình ngắn để phục hồi nhanh chóng khi dự đoán sai.”
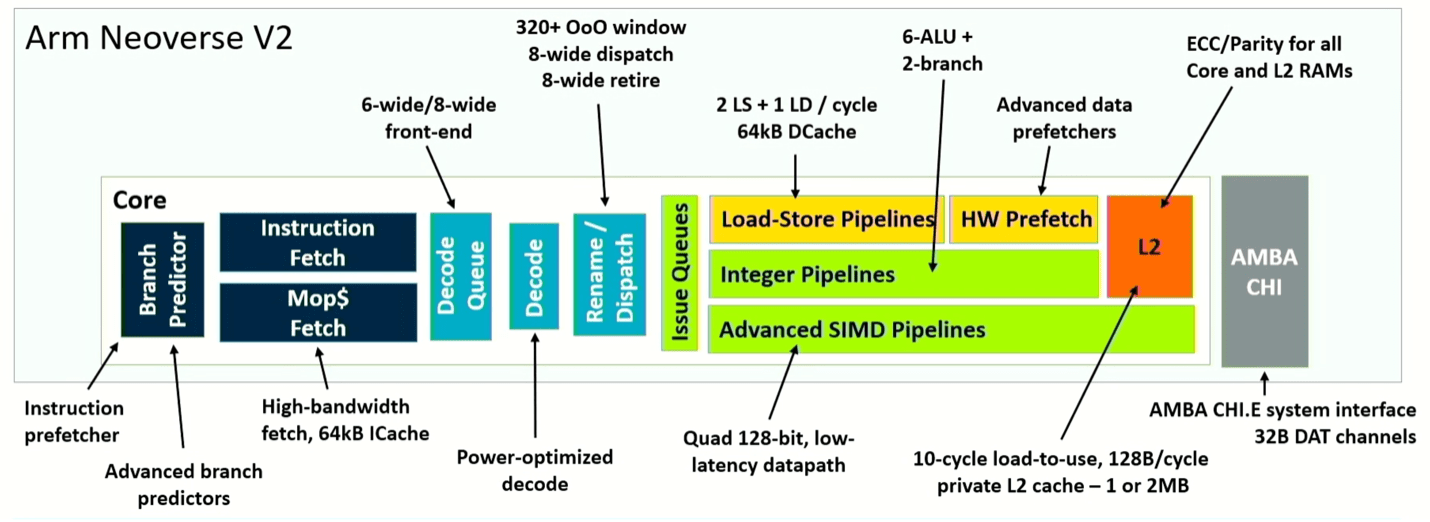
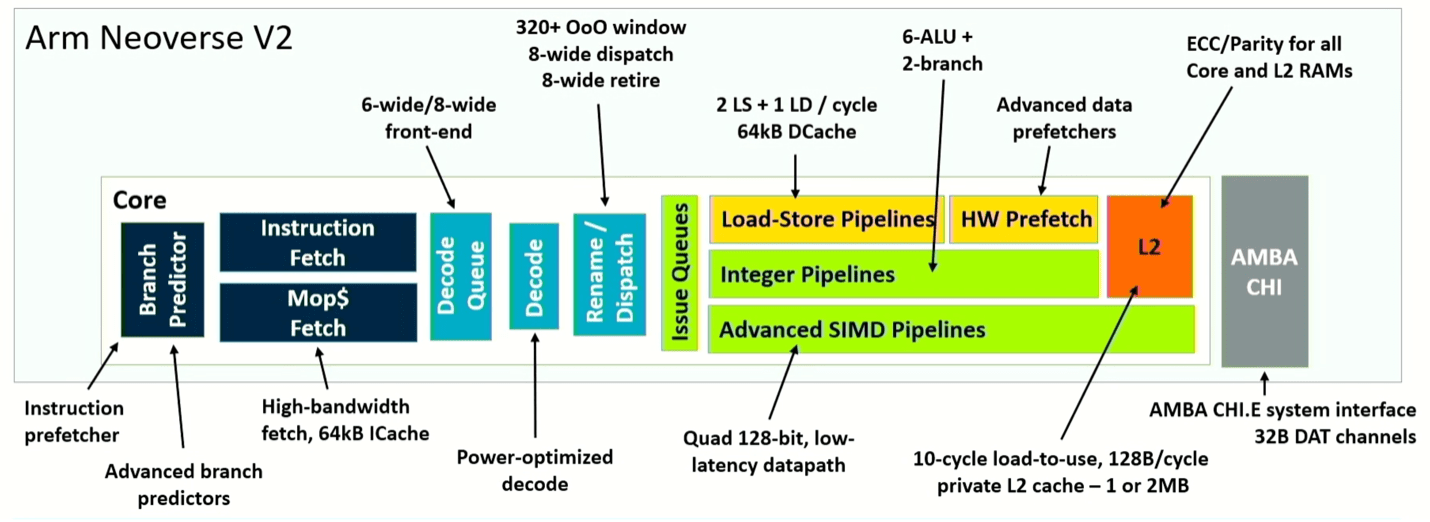
Hình 4: Sơ đồ đường ống của lõi Neoverse V2. Nguồn: Arm/Hot Chips 2023
Điều khác biệt ở đây là việc cải tiến toàn bộ hệ thống đến từ việc điều chỉnh kiến trúc ở nhiều điểm chứ không phải là thay đổi toàn bộ. Ví dụ: việc tách bộ dự đoán nhánh và tìm nạp cho phép bộ đệm mục tiêu nhánh được chia thành hai cấp độ, cho phép nó xử lý nhiều mục nhập hơn 50%. Nó cũng tăng gấp ba lần lịch sử được lưu trữ trong bộ dự đoán và nhân đôi số mục trong hàng đợi tìm nạp, dẫn đến cải thiện hiệu suất trong thế giới thực đáng kể. Để làm cho điều đó trở nên hiệu quả, kiến trúc cũng tăng gấp đôi bộ nhớ đệm L2, giúp phân tách các dự đoán khối dữ liệu được sử dụng một lần và được sử dụng nhiều lần. Cộng thêm nhiều cải tiến khác nhau, Neoverse V2 cho thấy hiệu suất gấp đôi V1, tùy thuộc vào vai trò của nó trong hệ thống.
Trong khi đó, Zen 4 Core thế hệ tiếp theo của AMD tăng khoảng 14% lệnh trên mỗi chu kỳ do cải tiến vi kiến trúc, cung cấp tần số cao hơn 16% ở 5nm ở cùng điện áp do mở rộng quy trình và tiêu thụ điện năng thấp hơn khoảng 60% nhờ vi kiến trúc và cải tiến thiết kế vật lý.
Giống như Arm, AMD đang tập trung vào những cải tiến trong khả năng dự đoán và tìm nạp nhánh. Kai Troester, thành viên AMD và kiến trúc sư trưởng của Zen 4, cho biết độ chính xác của dự đoán nhánh tăng lên do có nhiều nhánh hơn, nhiều dự đoán nhánh hơn trên mỗi chu kỳ và bộ đệm hoạt động lớn hơn cho phép nhiều mục nhập hơn và nhiều thao tác hơn trên mỗi mục nhập. Nó cũng bổ sung bộ đệm 3D V, giúp tăng bộ đệm L3 trên mỗi lõi lên tới 96 Mbyte và cung cấp hỗ trợ cho các hoạt động 512 bit bằng hai chu kỳ liên tiếp trên đường dẫn dữ liệu 256 bit. Nói một cách đơn giản, thiết kế này làm tăng kích thước của các ống dữ liệu và bất cứ khi nào có thể, nó sẽ rút ngắn khoảng cách mà dữ liệu phải di chuyển.
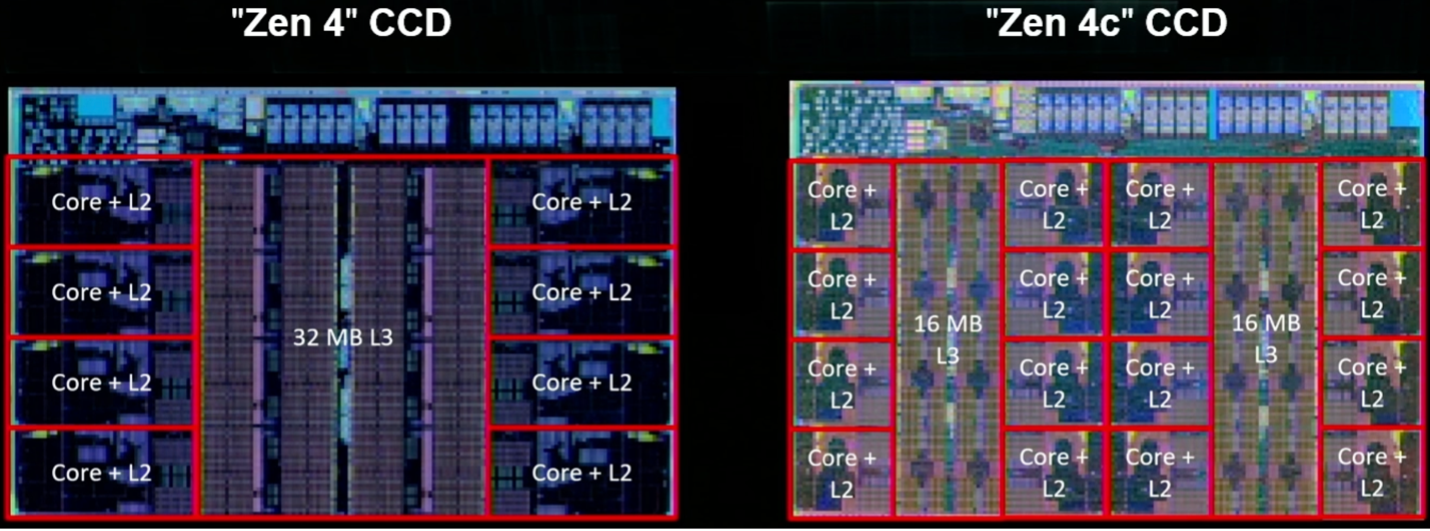
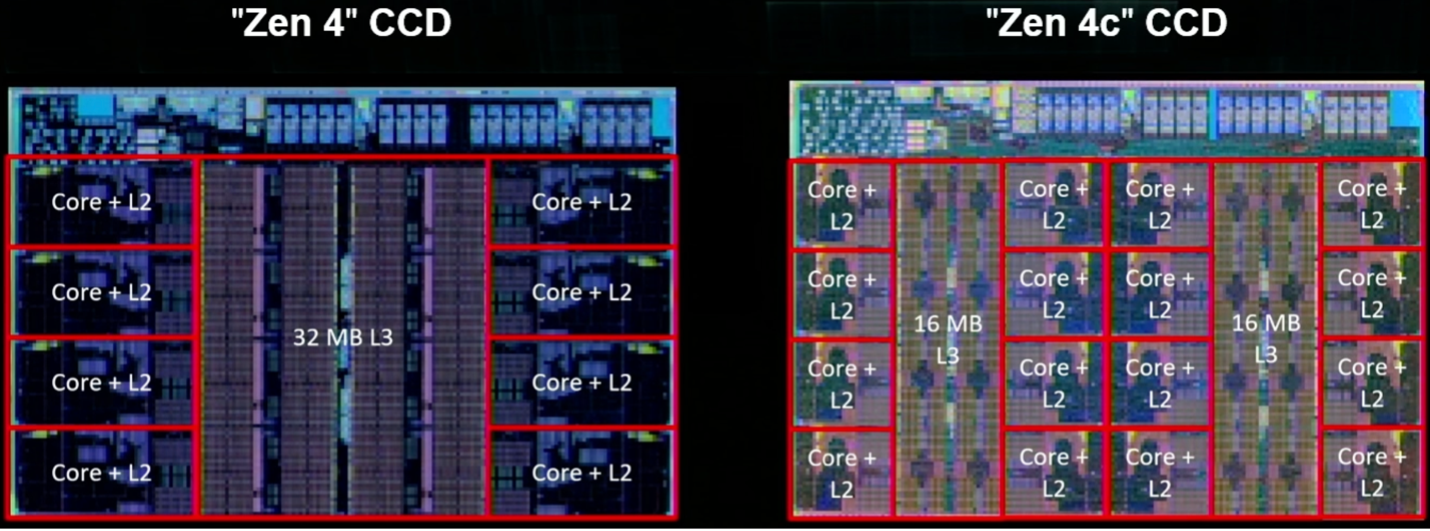
Hình 5: Hai triển khai Zen 4, bao gồm Zen 4c với số lõi tính toán trên mỗi khuôn gấp đôi và bộ nhớ đệm L3 được phân vùng. Nguồn: AMD/Hot Chips 2023
Kiến trúc nền tảng
Một trong những xu hướng chính về phía hệ thống là tăng tính đặc hiệu của miền, điều này đã tàn phá mô hình cũ về phát triển bộ xử lý đa năng hoạt động trên tất cả các ứng dụng. Thách thức hiện nay là làm thế nào để cung cấp những gì về cơ bản là tùy chỉnh hàng loạt và có hai cách tiếp cận chính để thực hiện điều đó — thêm khả năng lập trình, thông qua phần cứng hoặc logic lập trình và phát triển nền tảng cho các bộ phận có thể hoán đổi cho nhau.
Intel đã công bố một khuôn khổ để tích hợp các chiplet vào một gói nâng cao tận dụng Cầu kết nối đa khuôn nhúng để kết nối I/O, lõi bộ xử lý và bộ nhớ tốc độ cao. Mục tiêu của Intel là cung cấp đủ khả năng tùy chỉnh và hiệu suất để làm hài lòng khách hàng, nhưng cung cấp các hệ thống đó nhanh hơn nhiều so với các kiến trúc được tùy chỉnh hoàn toàn và có kết quả có thể dự đoán được.
Chris Gianos, đồng nghiệp của Intel và là kiến trúc sư trưởng Xeon, cho biết: “Đây sẽ là một kiến trúc nhiều khuôn. “Chúng tôi có rất nhiều sự linh hoạt trong cấu trúc mà chúng tôi có thể xây dựng bằng các chiplets này. Tất cả chúng đều tương tác với nhau và nó mang lại cho chúng tôi một trong những chiều hướng đó để tối ưu hóa cụ thể các lõi sản phẩm. Và chúng tôi sẽ tạo ra các chiplet là lõi E (siêu hiệu quả) và các chiplet là lõi P (hiệu suất cao).”
Intel cũng tạo ra một loại vải lưới mô-đun để liên kết các thành phần khác nhau lại với nhau, cũng như một bộ điều khiển chung hỗ trợ bộ nhớ DDR hoặc MCR và bộ nhớ được gắn thông qua CXL.
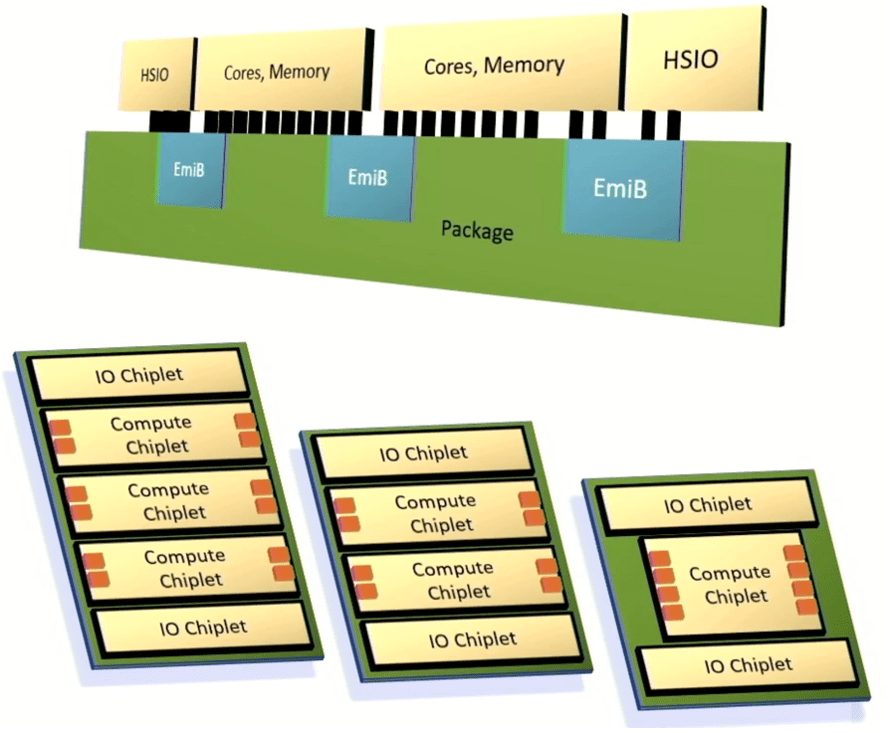
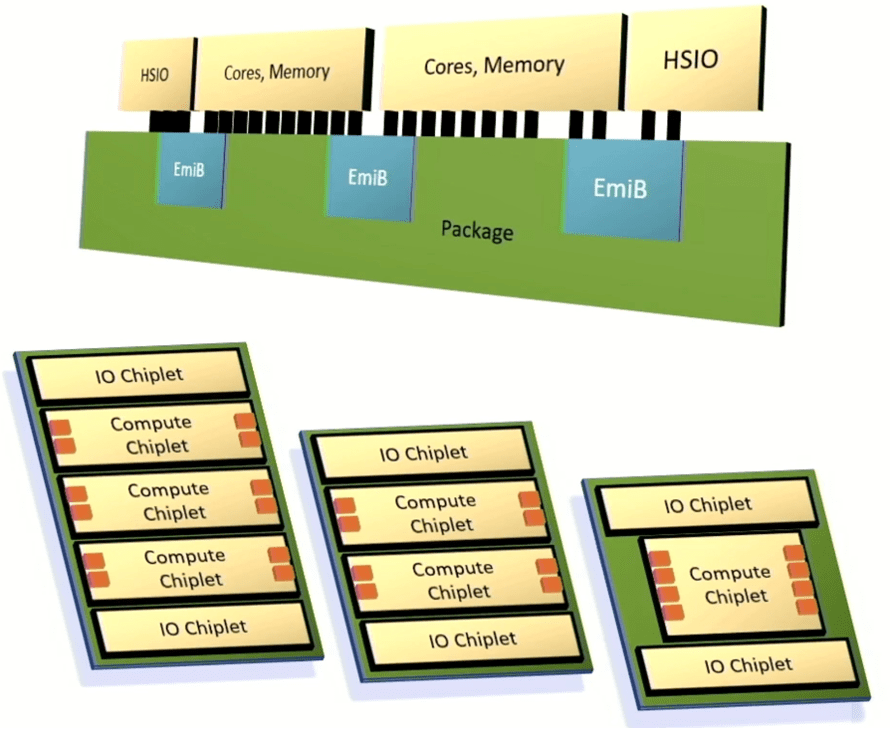
Hình 6: Kiến trúc chiplet có thể tùy chỉnh của Intel. Các ô màu cam tượng trưng cho các kênh bộ nhớ. Nguồn: Intel/Hot Chips 2023
Bộ xử lý thần kinh, kết nối quang học
Danh sách các phương pháp tiếp cận và công nghệ mới là chưa từng có, ngay cả đối với hội nghị Hot Chips. Những gì nó cho thấy là ngành công nghiệp này đang tìm kiếm những cách mới để tăng và giảm công suất ở mức độ rộng rãi như thế nào, trong khi vẫn chú ý đến diện tích và chi phí. PPAC vẫn là trọng tâm nhưng sự đánh đổi giữa các ứng dụng và trường hợp sử dụng khác nhau có thể rất khác nhau.
Dharmendra Modha, thành viên của IBM cho biết: “OpEx và CapEx của AI đang trở nên không bền vững”. Ông nói thêm rằng “kiến trúc vượt trội hơn Định luật Moore”.
Độ chính xác cũng rất quan trọng đối với các ứng dụng AI/ML. Thiết kế của IBM bao gồm một bộ nhân ma trận vectơ cho phép đạt được độ chính xác hỗn hợp, các đơn vị tính toán vectơ và các đơn vị chức năng kích hoạt với độ chính xác FP16. Ngoài ra, quá trình xử lý được thực hiện cách bộ nhớ vài micron. Ông nói: “Không có sự phân nhánh có điều kiện phụ thuộc vào dữ liệu. “Không có lỗi bộ nhớ đệm, không có tình trạng ngừng hoạt động, không có hoạt động thực thi mang tính suy đoán.”

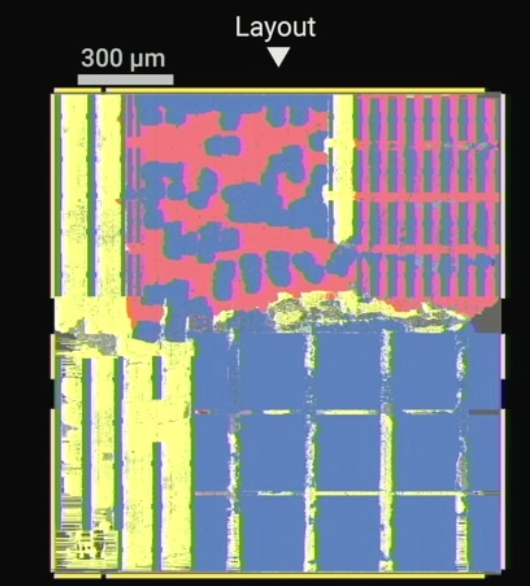
Hình 7: Chip Bắc Cực của IBM, hiển thị tính toán đan xen (màu đỏ) và bộ nhớ (màu xanh). Nguồn: IBM/Hot Chips 2023
Thách thức chính đối với các chip phức tạp không chỉ là việc di chuyển dữ liệu giữa bộ nhớ và bộ xử lý mà còn ở khắp xung quanh chip. Mạng trên chip và các kết cấu kết nối khác đơn giản hóa quá trình này. Quang tử silicon đã được sử dụng một thời gian, đặc biệt là cho các chip mạng tốc độ cao và quang tử đóng vai trò giữa các máy chủ trong một giá đỡ. Nhưng liệu nó có chuyển sang cấp độ chip hay không thì vẫn chưa chắc chắn. Tuy nhiên, công việc vẫn tiếp tục trong lĩnh vực này và dựa trên nhiều cuộc phỏng vấn trong ngành công nghiệp chip, quang tử học đang được nhiều công ty quan tâm.
Maurice Steinman, phó chủ tịch kỹ thuật của Lightelligence, cho biết công ty của ông đã phát triển các bộ tăng tốc dựa trên quang tử học chuyên dụng, nhanh hơn 100 lần so với GPU với công suất thấp hơn đáng kể. Công ty cũng đã phát triển mạng quang trên chip, thiên về sử dụng bộ chuyển đổi silicon làm phương tiện để kết nối các chiplet bằng cách sử dụng photon thay vì electron.
Steinman cho biết: “Thách thức đối với giải pháp thuần điện là với sự suy giảm theo khoảng cách, việc chỉ thực hiện liên lạc giữa những người hàng xóm gần nhất thực sự trở nên thiết thực”. “Nếu có một kết quả ở phía trên bên trái [của một con chip] cần giao tiếp với phía dưới bên phải thì nó cần phải đi qua nhiều bước nhảy. Điều đó tạo ra vấn đề cho các thành phần phần mềm chịu trách nhiệm phân bổ tài nguyên, bởi vì nó cần phải tính toán trước một số nước cờ để tránh tắc nghẽn.”
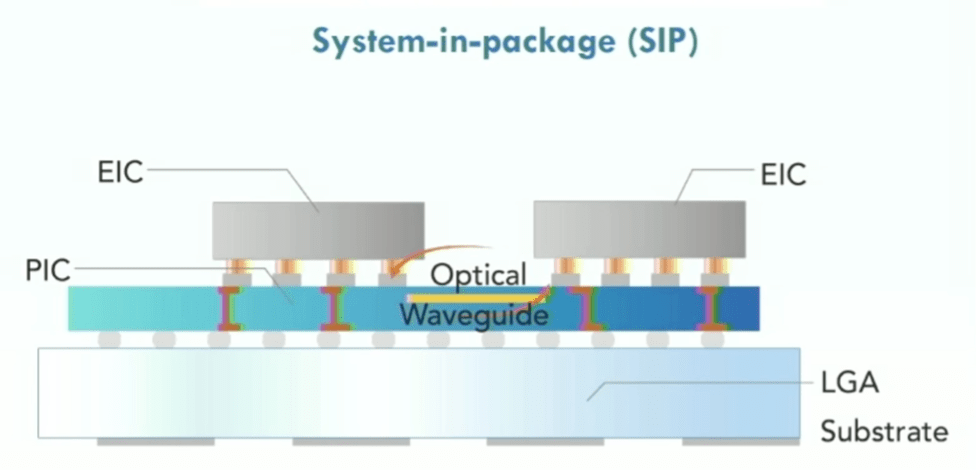
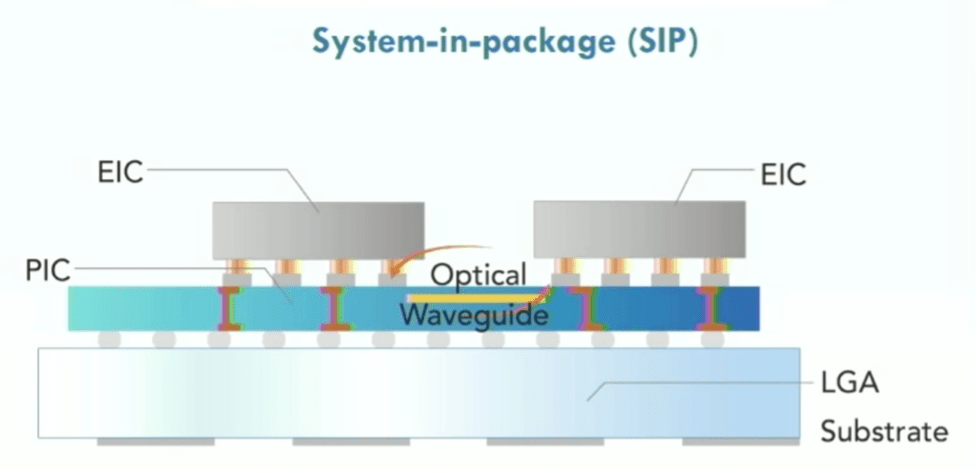
Hình 8: Mạng quang trên chip hiển thị mạch tích hợp quang tử (PIC), mạch tích hợp điện tử (EIC), sử dụng đế mảng lưới mặt đất (LGA). Nguồn: Lightellectence/Hot Chips 2023
Tính bền vững, độ tin cậy và tương lai
Với tất cả những thay đổi này, hai vấn đề khác đã xuất hiện. Một là tính bền vững. Khi nhiều dữ liệu được xử lý bởi nhiều chip hơn, thách thức sẽ là duy trì mức tiêu thụ năng lượng, chưa nói đến việc giảm lượng khí thải carbon. Nhiều thiết bị hiệu quả hơn không nhất thiết phải sử dụng ít năng lượng hơn và cần có năng lượng để sản xuất tất cả chúng.
Các trung tâm dữ liệu đã là mục tiêu được quan tâm trong một thời gian. Một thập kỷ trước, số liệu thống kê được mọi người thống nhất chung là các trung tâm dữ liệu tiêu thụ 2% đến 3% tổng lượng điện được tạo ra trên hành tinh. Văn phòng Hiệu quả Năng lượng và Năng lượng tái tạo Hoa Kỳ cho biết các trung tâm dữ liệu chiếm khoảng 2% tổng lượng điện sử dụng của Hoa Kỳ. Những con số này không phải lúc nào cũng chính xác vì có nhiều nguồn năng lượng xanh và cần năng lượng để sản xuất và tái chế các tấm pin mặt trời cũng như cánh quạt gió. Nhưng rõ ràng là lượng năng lượng tiêu thụ sẽ tiếp tục tăng cùng với dữ liệu, ngay cả khi nó không theo dõi ở cùng tốc độ.
Nhiều bài thuyết trình tại Hot Chips cũng như các hội nghị khác đều coi tính bền vững là mục tiêu. Và mặc dù dữ liệu cơ bản có thể khác nhau, nhưng thực tế là đây hiện là nhiệm vụ của công ty đối với nhiều nhà sản xuất chip là rất quan trọng.
Vấn đề thứ hai vẫn chưa được giải quyết là độ tin cậy. Nhiều thiết kế chip mới cũng phức tạp hơn nhiều so với các thế hệ chip trước. Trước đây, vấn đề chính là có thể nhồi nhét bao nhiêu bóng bán dẫn trên một đế và làm thế nào để tránh làm nóng chảy con chip. Ngày nay, có rất nhiều đường dẫn và phân vùng dữ liệu mà tản nhiệt chỉ là một trong nhiều yếu tố. Và khi khối lượng dữ liệu ngày càng tăng được phân vùng, xử lý, tổng hợp và phân tích, độ chính xác và tính nhất quán của kết quả có thể khó xác định và đảm bảo hơn, đặc biệt khi các thiết bị cũ đi và tương tác theo những cách không mong muốn.
Ngoài ra, các mô hình đang chuyển từ mô hình đơn lẻ sang nhiều phương thức - hình ảnh, văn bản, âm thanh và video - và từ mô hình dày đặc sang mô hình thưa thớt, theo Jeff Dean, thành viên cấp cao và phó chủ tịch cấp cao của Google Research. Ông nói: “Sức mạnh, tính bền vững và độ tin cậy thực sự quan trọng”, đồng thời lưu ý rằng phần lớn dữ liệu về đào tạo AI và CO2 lượng khí thải gây hiểu lầm. “Nếu bạn sử dụng dữ liệu chính xác thì mọi chuyện gần như không đến nỗi quá tệ.”>
Kết luận
Từ quan điểm thuần túy công nghệ, những tiến bộ về sức mạnh, hiệu suất và diện tích/chi phí trong kiến trúc chip là một sự khác biệt rõ rệt so với những thành quả đạt được trong quá khứ. Sự đổi mới đang diễn ra ở khắp mọi nơi và các lộ trình chỉ ra rằng hiệu suất sẽ tiếp tục tăng vọt, mức tiêu thụ năng lượng trên mỗi lần tính toán thấp hơn và tổng chi phí sở hữu giảm.
Trong nhiều năm, đã có suy đoán rằng các kiến trúc sư có thể cải thiện đáng kể phương trình PPAC. Hot Chips 2023 cung cấp cái nhìn sơ lược về cách triển khai trong thế giới thực có chứa những cải tiến đó. Sự đổi mới rõ ràng đã được chuyển giao cho các kiến trúc sư. Câu hỏi lớn hiện nay là điều gì sẽ xảy ra tiếp theo, công nghệ này sẽ được áp dụng như thế nào và những thay đổi này sẽ mở ra những khả năng nào khác. Với loại sức mạnh tính toán này, dường như mọi thứ đều có thể xảy ra.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- ChartPrime. Nâng cao trò chơi giao dịch của bạn với ChartPrime. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://semiengineering.com/sweeping-changes-for-leading-edge-chip-architectures/

