
Hình ảnh của Editor
Bạn đã nghe nói về Andrej Karpathy? Ông là một nhà khoa học máy tính và nhà nghiên cứu AI nổi tiếng với công trình nghiên cứu về mạng lưới thần kinh và học sâu. Ông đóng vai trò quan trọng trong việc phát triển ChatGPT tại OpenAI và trước đây là Giám đốc cấp cao về AI tại Tesla. Trước đó, anh đã thiết kế và là người hướng dẫn chính cho lớp deep learning đầu tiên Stanford – CS 231n: Mạng thần kinh tích chập để nhận dạng hình ảnh. Lớp học này đã trở thành một trong những lớp học lớn nhất tại Stanford và đã tăng từ 150 sinh viên đăng ký vào năm 2015 lên 750 sinh viên vào năm 2017. Tôi thực sự khuyên những ai quan tâm đến deep learning hãy xem nội dung này trên YouTube. Tôi sẽ không đi sâu vào chi tiết hơn về anh ấy và chúng tôi sẽ chuyển trọng tâm sang một trong những bài nói chuyện phổ biến nhất của anh ấy trên YouTube. 1.4 triệu lượt xem “Giới thiệu về các mô hình ngôn ngữ lớn.” Buổi nói chuyện này là phần giới thiệu dành cho người bận rộn về LLM và là phần phải xem đối với bất kỳ ai quan tâm đến LLM.
Tôi đã cung cấp một bản tóm tắt ngắn gọn về cuộc nói chuyện này. Nếu điều này thu hút sự quan tâm của bạn thì tôi thực sự khuyên bạn nên xem qua các trang trình bày và liên kết YouTube sẽ được cung cấp ở cuối bài viết này.
Buổi nói chuyện này cung cấp phần giới thiệu toàn diện về LLM, khả năng của chúng và những rủi ro tiềm ẩn liên quan đến việc sử dụng chúng. Nó được chia thành 3 phần chính như sau:
Phần 1: LLM

Các slide của Andrej Karpathy
LLM được đào tạo trên một kho văn bản lớn để tạo ra phản hồi giống con người. Trong phần này, Andrej thảo luận cụ thể về mô hình Llama 2-70b. Đây là một trong những LLM lớn nhất với 70 tỷ thông số. Mô hình bao gồm XNUMX thành phần chính: file tham số và file run. Tệp tham số là tệp nhị phân lớn chứa trọng số và độ lệch của mô hình. Những trọng số và độ lệch này về cơ bản là “kiến thức” mà mô hình đã học được trong quá trình đào tạo. Tệp chạy là một đoạn mã được sử dụng để tải tệp tham số và chạy mô hình. Quá trình huấn luyện mô hình có thể chia làm XNUMX giai đoạn sau:
1. Huấn luyện trước
Điều này liên quan đến việc thu thập một đoạn văn bản lớn, khoảng 10 terabyte, từ Internet, sau đó sử dụng cụm GPU để huấn luyện mô hình trên dữ liệu này. Kết quả của quá trình huấn luyện là một mô hình cơ sở được nén có tổn hao trên Internet. Nó có khả năng tạo ra văn bản mạch lạc và phù hợp nhưng không trả lời trực tiếp các câu hỏi.
2. Tinh chỉnh
Mô hình được đào tạo trước sẽ được đào tạo thêm trên bộ dữ liệu chất lượng cao để làm cho nó hữu ích hơn. Điều này dẫn đến một mô hình trợ lý. Andrej cũng đề cập đến giai đoạn tinh chỉnh thứ ba, bao gồm việc sử dụng nhãn so sánh. Thay vì tạo câu trả lời từ đầu, mô hình được đưa ra nhiều câu trả lời ứng viên và được yêu cầu chọn câu trả lời đúng nhất. Điều này có thể dễ dàng và hiệu quả hơn so với việc tạo ra câu trả lời và có thể cải thiện hơn nữa hiệu suất của mô hình. Quá trình này được gọi là học tăng cường từ phản hồi của con người (RLHF).
Phần 2: Tương lai của LLM
Các slide của Andrej Karpathy
Trong khi thảo luận về tương lai của các mô hình ngôn ngữ lớn và khả năng của chúng, các điểm chính sau sẽ được thảo luận:
1. Luật mở rộng quy mô
Hiệu suất của mô hình tương quan với hai biến—số lượng tham số và lượng văn bản huấn luyện. Các mô hình lớn hơn được đào tạo trên nhiều dữ liệu hơn có xu hướng đạt được hiệu suất tốt hơn.
2. Sử dụng Công cụ
Các LLM như ChatGPT có thể sử dụng các công cụ như trình duyệt, máy tính và thư viện Python để thực hiện các tác vụ mà nếu chỉ riêng mô hình đó là thách thức hoặc không thể thực hiện được.
3. Tư duy Hệ thống Một và Hệ thống Hai trong LLM
Hiện tại, LLM chủ yếu sử dụng tư duy hệ thống một—nhanh, bản năng và dựa trên khuôn mẫu. Tuy nhiên, người ta quan tâm đến việc phát triển LLM có khả năng tham gia vào tư duy hệ thống hai — chậm hơn, hợp lý và đòi hỏi nỗ lực có ý thức.
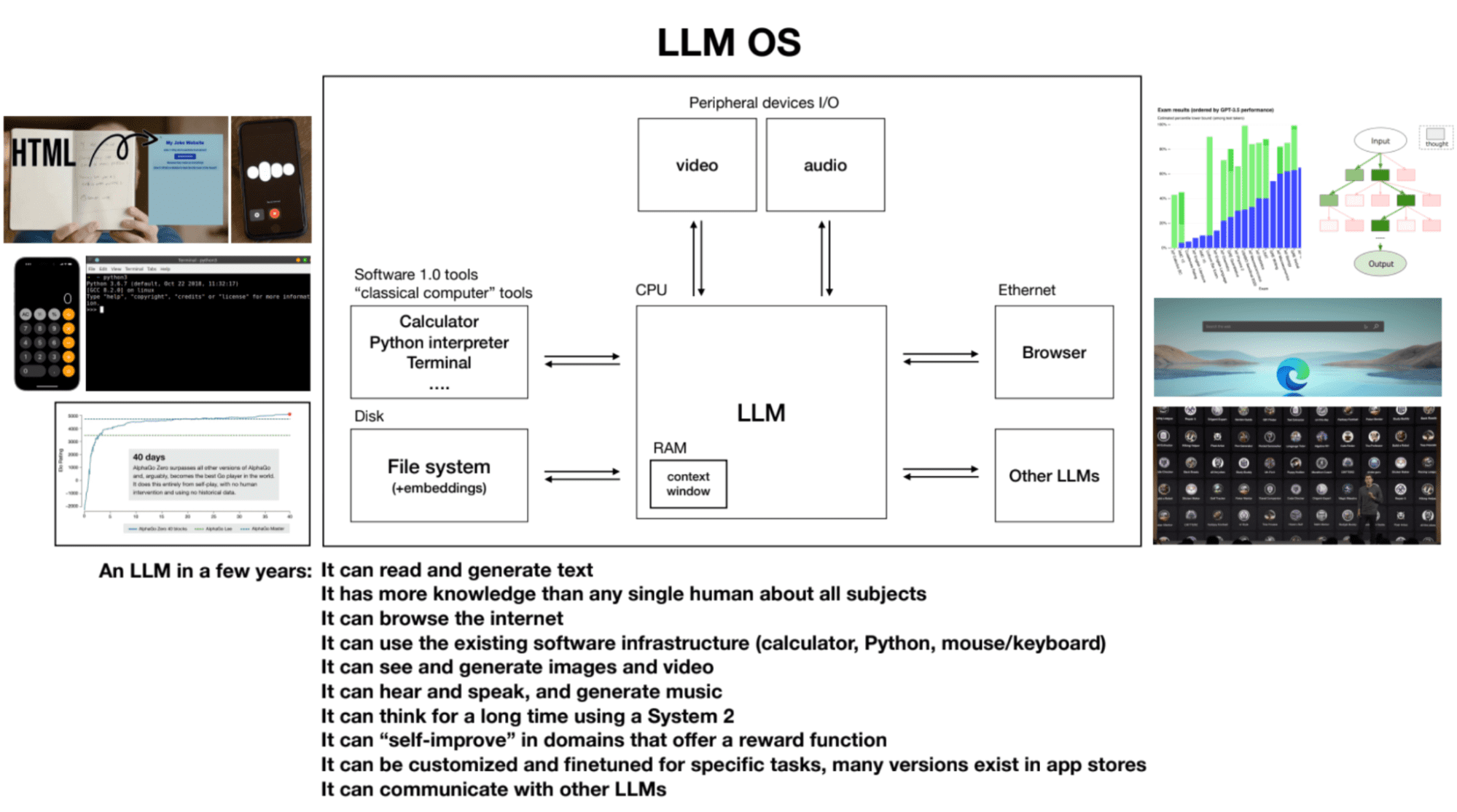
4. Hệ điều hành LLM
LLM có thể được coi là tiến trình cốt lõi của một hệ điều hành mới nổi. Họ có thể đọc và tạo văn bản, có kiến thức sâu rộng về nhiều chủ đề khác nhau, duyệt internet hoặc tham khảo các tệp cục bộ, sử dụng cơ sở hạ tầng phần mềm hiện có, tạo hình ảnh và video, nghe, nói và suy nghĩ trong thời gian dài bằng cách sử dụng hệ thống 2. Cửa sổ ngữ cảnh của một LLM tương tự như RAM trong máy tính và quy trình kernel cố gắng phân loại thông tin liên quan vào và ra khỏi cửa sổ ngữ cảnh của nó để thực hiện các tác vụ.
Phần 3: Bảo mật LLM

Các slide của Andrej Karpathy
Andrej nhấn mạnh những nỗ lực nghiên cứu đang diễn ra trong việc giải quyết các thách thức bảo mật liên quan đến LLM. Các cuộc tấn công sau đây sẽ được thảo luận:
1. Bẻ khóa
Cố gắng bỏ qua các biện pháp an toàn trong LLM để trích xuất thông tin có hại hoặc không phù hợp. Các ví dụ bao gồm nhập vai để đánh lừa mô hình và thao túng các phản hồi bằng cách sử dụng chuỗi từ hoặc hình ảnh được tối ưu hóa.
2. Tiêm nhanh
Liên quan đến việc đưa các hướng dẫn hoặc lời nhắc mới vào LLM để thao tác các phản hồi của nó. Những kẻ tấn công có thể ẩn hướng dẫn trong hình ảnh hoặc trang web, dẫn đến việc đưa nội dung không liên quan hoặc có hại vào câu trả lời của mô hình.
3. Ngộ độc dữ liệu/Tấn công cửa sau/Tấn công tác nhân ngủ
Liên quan đến việc đào tạo một mô hình ngôn ngữ lớn về dữ liệu độc hại hoặc bị thao túng có chứa các cụm từ kích hoạt. Khi mô hình gặp cụm từ kích hoạt, nó có thể bị thao túng để thực hiện các hành động không mong muốn hoặc đưa ra dự đoán không chính xác.
Bạn có thể xem video đầy đủ trên YouTube bằng cách nhấp vào bên dưới:
[nội dung được nhúng] [nội dung được nhúng]
Trang trình bày: Bấm vào đây
Nếu bạn là người mới làm quen với LLM và đang tìm kiếm tài nguyên để bắt đầu hành trình của mình thì danh sách toàn diện này là một nơi tuyệt vời để bắt đầu! Nó chứa cả các khóa học cơ bản và dành riêng cho LLM sẽ giúp bạn xây dựng một nền tảng vững chắc. Ngoài ra, nếu bạn quan tâm đến trải nghiệm học tập có cấu trúc chặt chẽ hơn, Maxime Labonne gần đây đã triển khai khóa học LLM của mình với ba lộ trình khác nhau để bạn lựa chọn dựa trên nhu cầu và mức độ kinh nghiệm của mình. Dưới đây là các liên kết đến cả hai tài nguyên để thuận tiện cho bạn:
- Danh sách tài nguyên toàn diện để làm chủ các mô hình ngôn ngữ lớn của Kanwal Mehreen
- Khóa học mô hình ngôn ngữ lớn của Maxime Labonne
Kanwal Mehreen là một nhà phát triển phần mềm đầy tham vọng, rất quan tâm đến khoa học dữ liệu và các ứng dụng của AI trong y học. Kanwal đã được chọn là Google Generation Scholar 2022 cho khu vực APAC. Kanwal thích chia sẻ kiến thức kỹ thuật bằng cách viết các bài báo về các chủ đề thịnh hành và đam mê cải thiện sự đại diện của phụ nữ trong ngành công nghệ.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy?utm_source=rss&utm_medium=rss&utm_campaign=unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy

