Hôm nay, chúng tôi vui mừng thông báo rằng các mô hình nền tảng Code Llama do Meta phát triển đã có sẵn cho khách hàng thông qua Khởi động Amazon SageMaker để triển khai chỉ bằng một cú nhấp chuột để chạy suy luận. Code Llama là một mô hình ngôn ngữ lớn (LLM) hiện đại có khả năng tạo mã và ngôn ngữ tự nhiên về mã từ cả lời nhắc mã và ngôn ngữ tự nhiên. Bạn có thể dùng thử mô hình này với SageMaker JumpStart, một trung tâm máy học (ML) cung cấp quyền truy cập vào các thuật toán, mô hình và giải pháp ML để bạn có thể nhanh chóng bắt đầu với ML. Trong bài đăng này, chúng tôi hướng dẫn cách khám phá và triển khai mô hình Code Llama thông qua SageMaker JumpStart.
Mã Llama
Code Llama là một mô hình được phát hành bởi Siêu dữ liệu được xây dựng dựa trên Llama 2. Mô hình tiên tiến này được thiết kế để cải thiện năng suất thực hiện các tác vụ lập trình cho nhà phát triển bằng cách giúp họ tạo mã chất lượng cao, được ghi chép đầy đủ. Các mô hình này vượt trội về Python, C++, Java, PHP, C#, TypeScript và Bash, đồng thời có khả năng tiết kiệm thời gian của nhà phát triển và giúp quy trình làm việc phần mềm hiệu quả hơn.
Nó có ba biến thể, được thiết kế để bao gồm nhiều ứng dụng: mô hình nền tảng (Code Llama), mô hình chuyên biệt về Python (Code Llama Python) và mô hình tuân theo hướng dẫn để hiểu hướng dẫn ngôn ngữ tự nhiên (Code Llama Instruct). Tất cả các biến thể Code Llama đều có bốn kích cỡ: tham số 7B, 13B, 34B và 70B. Các biến thể hướng dẫn và cơ sở 7B và 13B hỗ trợ việc điền dựa trên nội dung xung quanh, khiến chúng trở nên lý tưởng cho các ứng dụng trợ lý mã. Các mô hình được thiết kế sử dụng Llama 2 làm cơ sở và sau đó được đào tạo trên 500 tỷ mã thông báo dữ liệu mã, với phiên bản chuyên dụng Python được đào tạo trên 100 tỷ mã thông báo tăng dần. Các mô hình Code Llama cung cấp các thế hệ ổn định với tối đa 100,000 mã thông báo ngữ cảnh. Tất cả các mô hình đều được đào tạo theo chuỗi 16,000 mã thông báo và hiển thị các cải tiến về đầu vào với tối đa 100,000 mã thông báo.
Mô hình này được cung cấp theo cùng giấy phép cộng đồng như Llama 2.
Các mô hình nền tảng trong SageMaker
SageMaker JumpStart cung cấp quyền truy cập vào nhiều mô hình từ các trung tâm mô hình phổ biến, bao gồm Hugging Face, PyTorch Hub và TensorFlow Hub mà bạn có thể sử dụng trong quy trình phát triển ML của mình trong SageMaker. Những tiến bộ gần đây trong ML đã tạo ra một loại mô hình mới được gọi là mô hình nền tảng, thường được đào tạo về hàng tỷ tham số và có thể thích ứng với nhiều loại trường hợp sử dụng, chẳng hạn như tóm tắt văn bản, tạo tác phẩm kỹ thuật số và dịch ngôn ngữ. Bởi vì việc đào tạo những mô hình này tốn kém nên khách hàng muốn sử dụng các mô hình nền tảng được đào tạo trước hiện có và tinh chỉnh chúng khi cần, thay vì tự đào tạo những mô hình này. SageMaker cung cấp danh sách mô hình được tuyển chọn mà bạn có thể chọn trên bảng điều khiển SageMaker.
Bạn có thể tìm thấy các mô hình nền tảng từ các nhà cung cấp mô hình khác nhau trong SageMaker JumpStart, cho phép bạn bắt đầu nhanh chóng với các mô hình nền tảng. Bạn có thể tìm thấy các mô hình nền tảng dựa trên các nhiệm vụ hoặc nhà cung cấp mô hình khác nhau và dễ dàng xem xét các đặc điểm cũng như điều khoản sử dụng của mô hình. Bạn cũng có thể dùng thử các mô hình này bằng tiện ích giao diện người dùng thử nghiệm. Khi muốn sử dụng mô hình nền tảng trên quy mô lớn, bạn có thể làm như vậy mà không cần rời khỏi SageMaker bằng cách sử dụng sổ ghi chép dựng sẵn từ các nhà cung cấp mô hình. Vì các mô hình được lưu trữ và triển khai trên AWS nên bạn có thể yên tâm rằng dữ liệu của bạn, dù dùng để đánh giá hay sử dụng mô hình trên quy mô lớn, sẽ không bao giờ được chia sẻ với bên thứ ba.
Khám phá mô hình Code Llama trong SageMaker JumpStart
Để triển khai mô hình Code Llama 70B, hãy hoàn thành các bước sau trong Xưởng sản xuất Amazon SageMaker:
- Trên trang chủ SageMaker Studio, chọn Khởi động trong khung điều hướng.
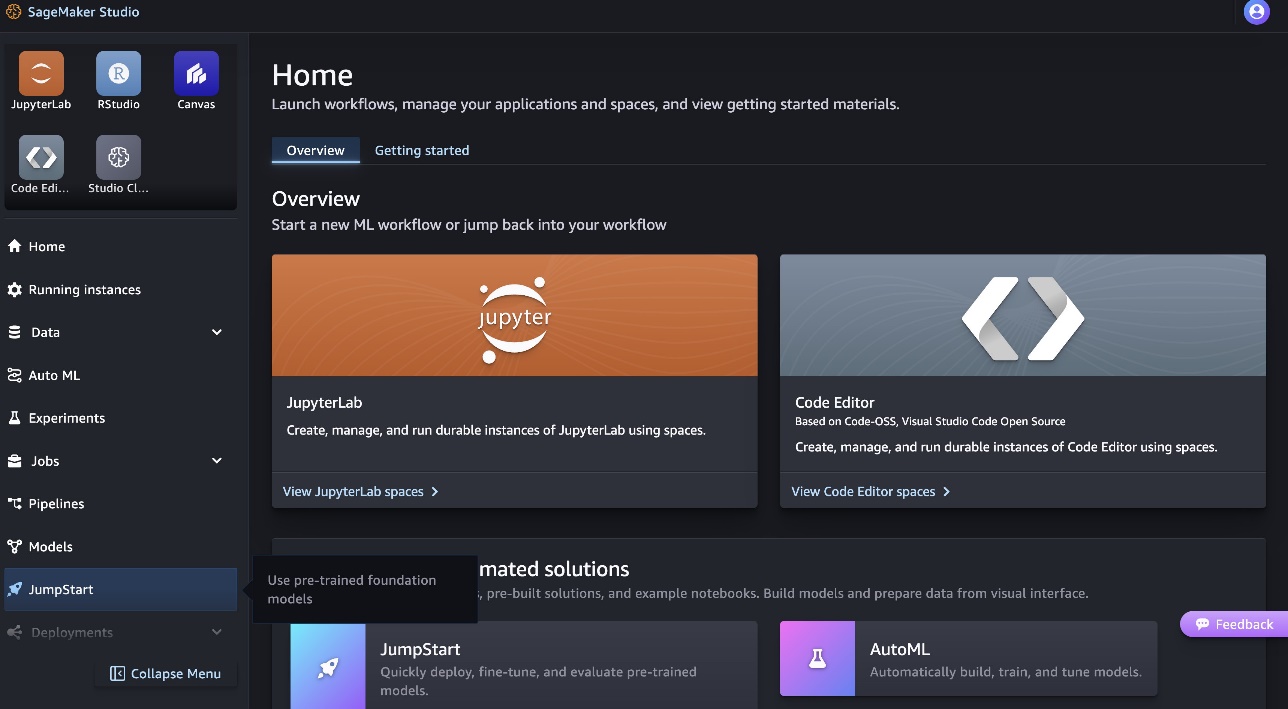
- Tìm kiếm mẫu Code Llama và chọn mẫu Code Llama 70B từ danh sách mẫu được hiển thị.
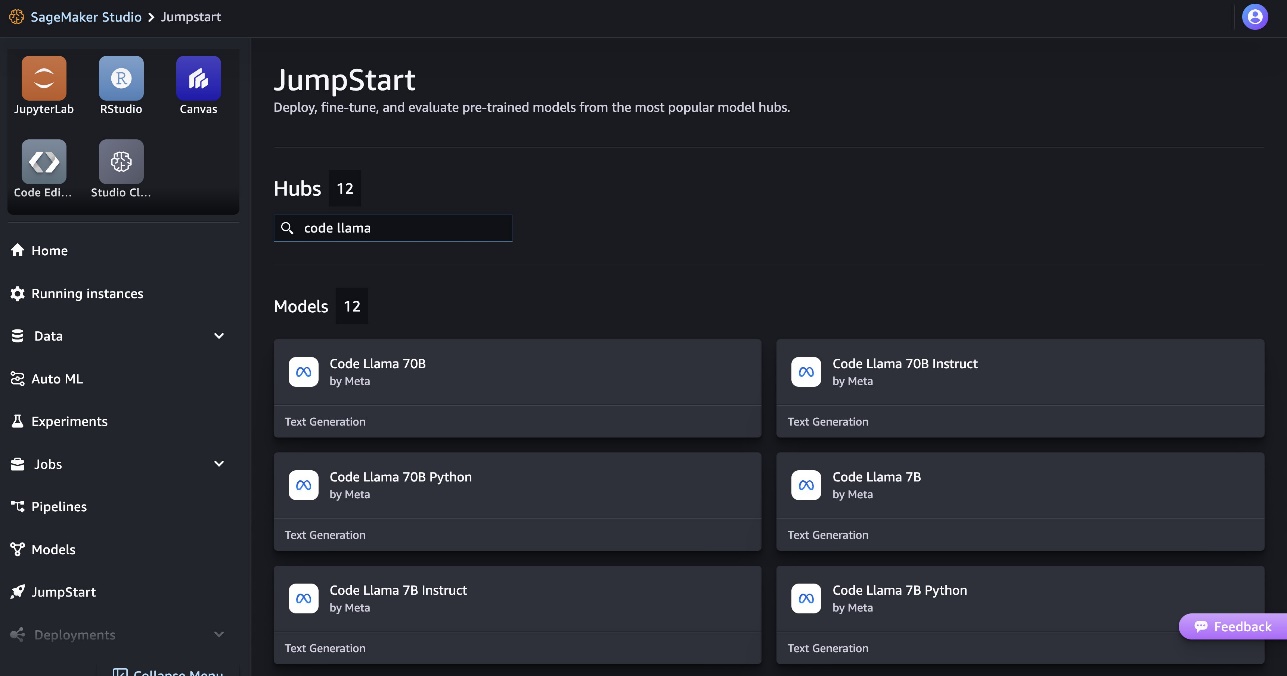
Bạn có thể tìm thêm thông tin về mô hình trên thẻ mô hình Code Llama 70B.
Ảnh chụp màn hình sau đây hiển thị cài đặt điểm cuối. Bạn có thể thay đổi các tùy chọn hoặc sử dụng các tùy chọn mặc định.
- Chấp nhận Thỏa thuận cấp phép người dùng cuối (EULA) và chọn Triển khai.
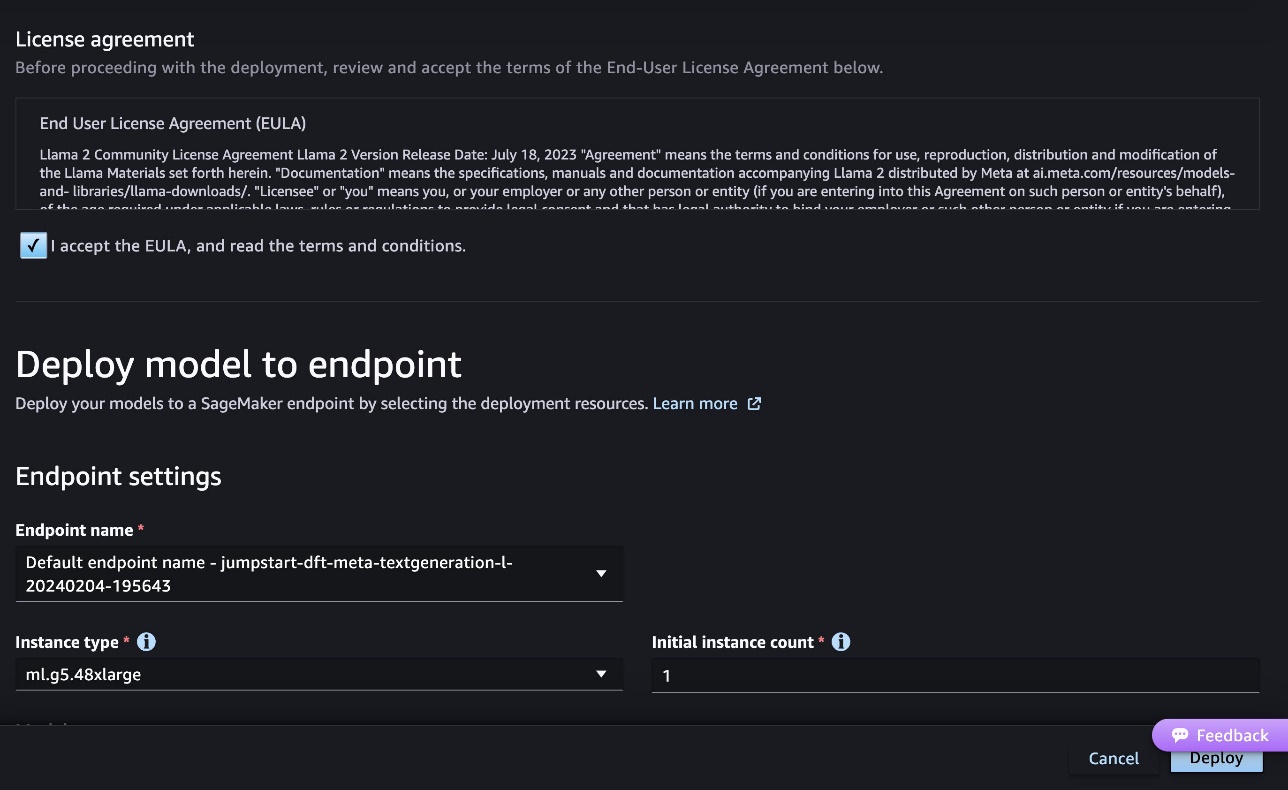
Thao tác này sẽ bắt đầu quá trình triển khai điểm cuối, như minh họa trong ảnh chụp màn hình sau.
Triển khai mô hình bằng SDK Python của SageMaker
Ngoài ra, bạn có thể triển khai thông qua sổ tay mẫu bằng cách chọn Mở Notebook trong trang chi tiết mô hình của Classic Studio. Sổ tay ví dụ cung cấp hướng dẫn toàn diện về cách triển khai mô hình để suy luận và dọn dẹp tài nguyên.
Để triển khai bằng sổ ghi chép, chúng tôi bắt đầu bằng cách chọn một mô hình thích hợp, được chỉ định bởi model_id. Bạn có thể triển khai bất kỳ mô hình đã chọn nào trên SageMaker bằng mã sau:
Điều này triển khai mô hình trên SageMaker với cấu hình mặc định, bao gồm loại phiên bản mặc định và cấu hình VPC mặc định. Bạn có thể thay đổi các cấu hình này bằng cách chỉ định các giá trị không mặc định trong JumpStartMô hình. Lưu ý rằng theo mặc định, accept_eula được thiết lập để False. Bạn cần đặt accept_eula=True để triển khai điểm cuối thành công. Bằng cách đó, bạn chấp nhận thỏa thuận cấp phép người dùng và chính sách sử dụng được chấp nhận như đã đề cập trước đó. Bạn cũng có thể tải về thỏa thuận cấp phép.
Gọi điểm cuối SageMaker
Sau khi triển khai điểm cuối, bạn có thể tiến hành suy luận bằng cách sử dụng Boto3 hoặc SageMaker Python SDK. Trong đoạn mã sau, chúng tôi sử dụng SageMaker Python SDK để gọi mô hình để suy luận và in phản hồi:
Các chức năng print_response nhận một tải trọng bao gồm tải trọng và phản hồi của mô hình và in kết quả đầu ra. Code Llama hỗ trợ nhiều tham số khi thực hiện suy luận:
- chiều dài tối đa – Mô hình tạo văn bản cho đến khi đạt đến độ dài đầu ra (bao gồm cả độ dài ngữ cảnh đầu vào)
max_length. Nếu được chỉ định, nó phải là một số nguyên dương. - max_new_tokens – Mô hình tạo văn bản cho đến khi đạt độ dài đầu ra (không bao gồm độ dài ngữ cảnh đầu vào)
max_new_tokens. Nếu được chỉ định, nó phải là một số nguyên dương. - số_dầm – Điều này chỉ định số lượng chùm tia được sử dụng trong tìm kiếm tham lam. Nếu được chỉ định, nó phải là số nguyên lớn hơn hoặc bằng
num_return_sequences. - no_repeat_ngram_size – Mô hình đảm bảo rằng một chuỗi các từ của
no_repeat_ngram_sizekhông được lặp lại trong chuỗi đầu ra. Nếu được chỉ định, nó phải là số nguyên dương lớn hơn 1. - nhiệt độ – Điều này kiểm soát tính ngẫu nhiên trong đầu ra. Cao hơn
temperaturedẫn đến một chuỗi đầu ra với các từ có xác suất thấp và thấp hơntemperaturedẫn đến một chuỗi đầu ra với các từ có xác suất cao. Nếu nhưtemperaturelà 0, nó dẫn đến giải mã tham lam. Nếu được chỉ định, nó phải là số float dương. - dừng sớm - Nếu
True, việc tạo văn bản kết thúc khi tất cả các giả thuyết chùm đạt đến cuối mã thông báo câu. Nếu được chỉ định, nó phải là Boolean. - làm_mẫu - Nếu
True, mô hình sẽ lấy mẫu từ tiếp theo tùy theo khả năng. Nếu được chỉ định, nó phải là Boolean. - đầu_k – Trong mỗi bước tạo văn bản, mô hình chỉ lấy mẫu từ
top_knhững từ có khả năng nhất. Nếu được chỉ định, nó phải là một số nguyên dương. - đầu_p – Trong mỗi bước tạo văn bản, mô hình lấy mẫu từ tập hợp từ nhỏ nhất có thể có xác suất tích lũy
top_p. Nếu được chỉ định, nó phải là số float trong khoảng từ 0 đến 1. - return_full_text - Nếu
True, văn bản đầu vào sẽ là một phần của văn bản được tạo đầu ra. Nếu được chỉ định, nó phải là Boolean. Giá trị mặc định cho nó làFalse. - dừng lại – Nếu được chỉ định thì phải là danh sách các chuỗi. Việc tạo văn bản sẽ dừng nếu bất kỳ một trong các chuỗi được chỉ định nào được tạo.
Bạn có thể chỉ định bất kỳ tập hợp con nào của các tham số này trong khi gọi điểm cuối. Tiếp theo, chúng tôi trình bày một ví dụ về cách gọi điểm cuối bằng các đối số này.
Hoàn thành mã
Các ví dụ sau đây minh họa cách thực hiện hoàn thành mã trong đó phản hồi điểm cuối dự kiến là sự tiếp nối tự nhiên của lời nhắc.
Đầu tiên chúng ta chạy đoạn mã sau:
Chúng tôi nhận được kết quả sau:
Đối với ví dụ tiếp theo, chúng tôi chạy đoạn mã sau:
Chúng tôi nhận được kết quả sau:
Tạo mã
Các ví dụ sau đây cho thấy việc tạo mã Python bằng Code Llama.
Đầu tiên chúng ta chạy đoạn mã sau:
Chúng tôi nhận được kết quả sau:
Đối với ví dụ tiếp theo, chúng tôi chạy đoạn mã sau:
Chúng tôi nhận được kết quả sau:
Đây là một số ví dụ về các tác vụ liên quan đến mã sử dụng Mã Llama 70B. Bạn có thể sử dụng mô hình này để tạo mã phức tạp hơn nữa. Chúng tôi khuyến khích bạn dùng thử bằng cách sử dụng các trường hợp và ví dụ sử dụng liên quan đến mã của riêng bạn!
Làm sạch
Sau khi bạn đã kiểm tra các điểm cuối, hãy đảm bảo bạn xóa các điểm cuối suy luận SageMaker và mô hình để tránh phát sinh phí. Sử dụng mã sau đây:
Kết luận
Trong bài đăng này, chúng tôi đã giới thiệu Code Llama 70B trên SageMaker JumpStart. Code Llama 70B là một mô hình tiên tiến để tạo mã từ các lời nhắc cũng như mã bằng ngôn ngữ tự nhiên. Bạn có thể triển khai mô hình bằng một vài bước đơn giản trong SageMaker JumpStart, sau đó sử dụng mô hình đó để thực hiện các tác vụ liên quan đến mã như tạo mã và điền mã. Bước tiếp theo, hãy thử sử dụng mô hình với dữ liệu và trường hợp sử dụng liên quan đến mã của riêng bạn.
Giới thiệu về tác giả
 Tiến sĩ Kyle Ulrich là Nhà khoa học ứng dụng của nhóm Amazon SageMaker JumpStart. Lĩnh vực nghiên cứu của ông bao gồm các thuật toán học máy có thể mở rộng, thị giác máy tính, chuỗi thời gian, phi tham số Bayesian và quy trình Gaussian. Tiến sĩ của anh ấy đến từ Đại học Duke và anh ấy đã xuất bản các bài báo trên NeurIPS, Cell và Neuron.
Tiến sĩ Kyle Ulrich là Nhà khoa học ứng dụng của nhóm Amazon SageMaker JumpStart. Lĩnh vực nghiên cứu của ông bao gồm các thuật toán học máy có thể mở rộng, thị giác máy tính, chuỗi thời gian, phi tham số Bayesian và quy trình Gaussian. Tiến sĩ của anh ấy đến từ Đại học Duke và anh ấy đã xuất bản các bài báo trên NeurIPS, Cell và Neuron.
 Tiến sĩ Farooq Sabir là Kiến trúc sư giải pháp chuyên gia trí tuệ nhân tạo và học máy cao cấp tại AWS. Ông có bằng Tiến sĩ và Thạc sĩ Kỹ thuật Điện của Đại học Texas ở Austin và bằng Thạc sĩ Khoa học Máy tính của Viện Công nghệ Georgia. Anh ấy có hơn 15 năm kinh nghiệm làm việc và cũng thích giảng dạy và cố vấn cho sinh viên đại học. Tại AWS, anh giúp khách hàng hình thành và giải quyết các vấn đề kinh doanh của họ trong khoa học dữ liệu, máy học, thị giác máy tính, trí tuệ nhân tạo, tối ưu hóa số học và các lĩnh vực liên quan. Có trụ sở tại Dallas, Texas, anh ấy và gia đình thích đi du lịch và thực hiện các chuyến đi đường dài.
Tiến sĩ Farooq Sabir là Kiến trúc sư giải pháp chuyên gia trí tuệ nhân tạo và học máy cao cấp tại AWS. Ông có bằng Tiến sĩ và Thạc sĩ Kỹ thuật Điện của Đại học Texas ở Austin và bằng Thạc sĩ Khoa học Máy tính của Viện Công nghệ Georgia. Anh ấy có hơn 15 năm kinh nghiệm làm việc và cũng thích giảng dạy và cố vấn cho sinh viên đại học. Tại AWS, anh giúp khách hàng hình thành và giải quyết các vấn đề kinh doanh của họ trong khoa học dữ liệu, máy học, thị giác máy tính, trí tuệ nhân tạo, tối ưu hóa số học và các lĩnh vực liên quan. Có trụ sở tại Dallas, Texas, anh ấy và gia đình thích đi du lịch và thực hiện các chuyến đi đường dài.
 tháng sáu thắng là người quản lý sản phẩm với SageMaker JumpStart. Ông tập trung vào việc tạo ra các mô hình nền tảng có thể dễ dàng khám phá và sử dụng được để giúp khách hàng xây dựng các ứng dụng AI tổng quát. Kinh nghiệm của anh ấy tại Amazon cũng bao gồm ứng dụng mua sắm trên thiết bị di động và giao hàng chặng cuối.
tháng sáu thắng là người quản lý sản phẩm với SageMaker JumpStart. Ông tập trung vào việc tạo ra các mô hình nền tảng có thể dễ dàng khám phá và sử dụng được để giúp khách hàng xây dựng các ứng dụng AI tổng quát. Kinh nghiệm của anh ấy tại Amazon cũng bao gồm ứng dụng mua sắm trên thiết bị di động và giao hàng chặng cuối.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/code-llama-70b-is-now-available-in-amazon-sagemaker-jumpstart/

