Tác giả: Vitalik Buterin thông qua Blog Vitalik Buterin
Đặc biệt cảm ơn nhóm Worldcoin và Modulus Labs, Xinyuan Sun, Martin Koeppelmann và Illia Polosukhin vì đã phản hồi và thảo luận.
Nhiều người trong nhiều năm đã hỏi tôi một câu hỏi tương tự: cái gì là nút giao thông giữa tiền điện tử và AI mà tôi cho là hiệu quả nhất? Đó là một câu hỏi hợp lý: tiền điện tử và AI là hai xu hướng công nghệ (phần mềm) sâu chính của thập kỷ qua và có cảm giác như vậy phải là một loại kết nối nào đó giữa hai người. Thật dễ dàng để đạt được sự phối hợp ở mức độ rung cảm hời hợt: phân cấp tiền điện tử có thể cân bằng việc tập trung AI, AI mờ đục và tiền điện tử mang lại sự minh bạch, AI cần dữ liệu và chuỗi khối rất tốt cho việc lưu trữ và theo dõi dữ liệu. Nhưng qua nhiều năm, khi mọi người yêu cầu tôi đào sâu hơn và nói về các ứng dụng cụ thể, câu trả lời của tôi thật đáng thất vọng: “ừ, có một vài thứ nhưng không nhiều đến thế”.
Trong ba năm qua, với sự phát triển của AI mạnh mẽ hơn nhiều dưới dạng công nghệ hiện đại LLMvà sự nổi lên của tiền điện tử mạnh mẽ hơn nhiều dưới dạng không chỉ các giải pháp mở rộng quy mô blockchain mà còn ZKP, FHE, (hai bên và bên N) MPC, Tôi bắt đầu thấy sự thay đổi này. Thực sự có một số ứng dụng đầy hứa hẹn của AI bên trong hệ sinh thái blockchain, hoặc AI cùng với mật mã, mặc dù điều quan trọng là phải cẩn thận về cách áp dụng AI. Một thách thức cụ thể là: trong mật mã, nguồn mở là cách duy nhất để làm cho thứ gì đó thực sự an toàn, nhưng trong AI, một mô hình (hoặc thậm chí dữ liệu đào tạo của nó) là mở tăng lên rất nhiều tính dễ bị tổn thương của nó đối với máy học đối thủ các cuộc tấn công. Bài đăng này sẽ phân loại các cách khác nhau mà tiền điện tử + AI có thể giao nhau, cũng như triển vọng và thách thức của từng danh mục.
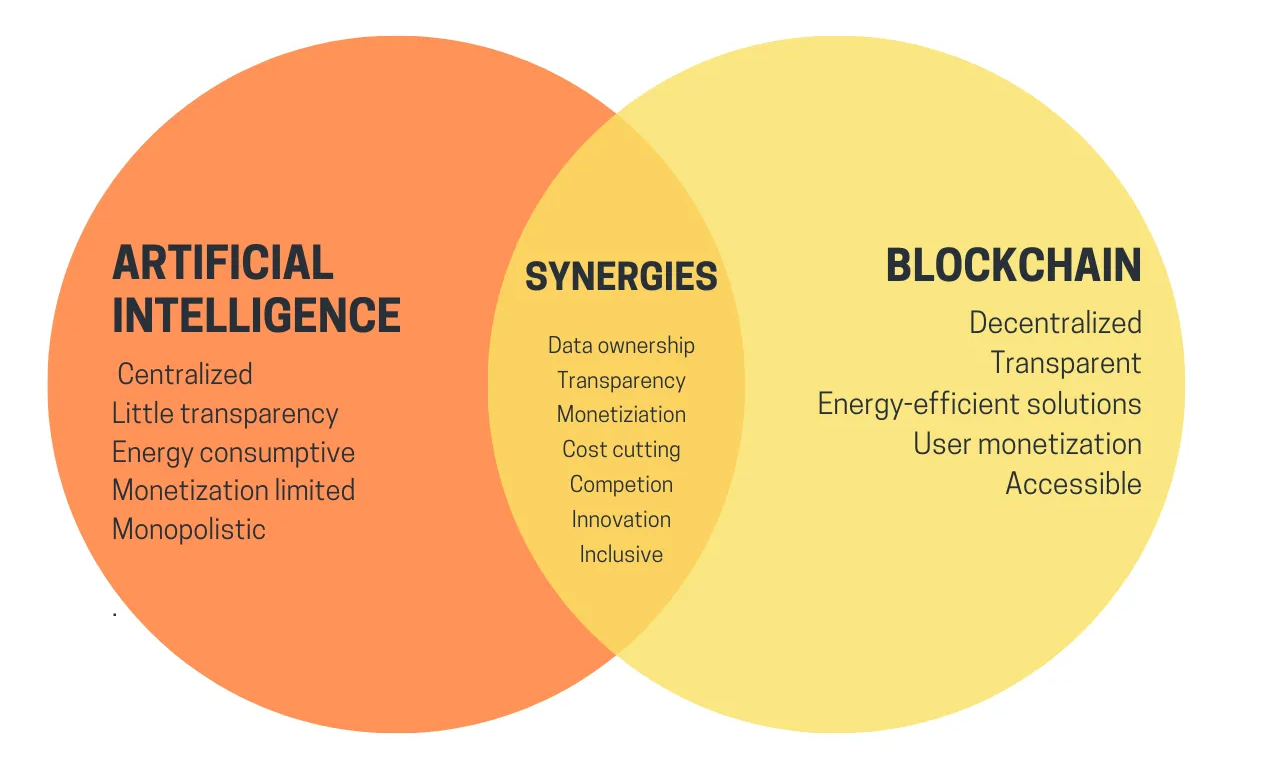
Bốn loại chính
AI là một khái niệm rất rộng: bạn có thể nghĩ “AI” là tập hợp các thuật toán mà bạn tạo ra không phải bằng cách chỉ định chúng một cách rõ ràng mà bằng cách khuấy động một khối súp tính toán lớn và đặt vào một loại áp lực tối ưu hóa nào đó để thúc đẩy khối súp tiến tới. tạo ra các thuật toán với các thuộc tính mà bạn muốn. Sự mô tả này chắc chắn không nên được coi là một cách bác bỏ: nó bao gồm các quá trình việc này tạo ra con người chúng ta ngay từ đầu! Nhưng điều đó có nghĩa là các thuật toán AI có một số đặc tính chung: khả năng thực hiện những việc cực kỳ mạnh mẽ, cùng với những giới hạn về khả năng của chúng ta trong việc biết hoặc hiểu những gì đang diễn ra bên trong.
Có nhiều cách để phân loại AI; vì mục đích của bài đăng này, nói về sự tương tác giữa AI và chuỗi khối (được mô tả là nền tảng cho tạo ra “trò chơi”), tôi sẽ phân loại nó như sau:
- AI với tư cách là người chơi trong trò chơi [khả năng tồn tại cao nhất]: AI tham gia vào các cơ chế trong đó nguồn khuyến khích cuối cùng đến từ giao thức có đầu vào của con người.
- AI là giao diện của trò chơi [tiềm năng cao nhưng có rủi ro]: AI giúp người dùng hiểu thế giới tiền điện tử xung quanh họ và đảm bảo rằng hành vi của họ (tức là các tin nhắn và giao dịch đã ký) phù hợp với ý định của họ và họ không bị lừa hoặc lừa đảo.
- AI là luật chơi [đi rất cẩn thận]: chuỗi khối, DAO và các cơ chế tương tự gọi trực tiếp vào AI. Hãy suy nghĩ ví dụ. “Thẩm phán AI”
- AI là mục tiêu của trò chơi [dài hạn nhưng hấp dẫn]: thiết kế chuỗi khối, DAO và các cơ chế tương tự với mục tiêu xây dựng và duy trì AI có thể được sử dụng cho các mục đích khác, sử dụng các bit tiền điện tử để khuyến khích đào tạo tốt hơn hoặc để ngăn AI rò rỉ dữ liệu riêng tư hoặc bị lạm dụng.
Chúng ta hãy đi qua từng cái một.
AI với tư cách là người chơi trong trò chơi
Đây thực chất là một thể loại đã tồn tại gần chục năm, ít nhất là từ sàn giao dịch phi tập trung trên chuỗi (DEXes) bắt đầu thấy công dụng đáng kể. Bất cứ khi nào có một cuộc trao đổi, sẽ có cơ hội kiếm tiền thông qua chênh lệch giá và bot có thể thực hiện chênh lệch giá tốt hơn nhiều so với con người. Trường hợp sử dụng này đã tồn tại từ lâu, ngay cả với những AI đơn giản hơn nhiều so với những gì chúng ta có ngày nay, nhưng cuối cùng nó là một sự giao thoa AI + tiền điện tử rất thực tế. Gần đây hơn, chúng ta đã thấy các bot kinh doanh chênh lệch giá MEV thường lợi dụng nhau. Bất cứ khi nào bạn có một ứng dụng blockchain liên quan đến đấu giá hoặc giao dịch, bạn sẽ có các bot chênh lệch giá.
Nhưng các bot chênh lệch giá AI chỉ là ví dụ đầu tiên của một danh mục lớn hơn nhiều mà tôi mong đợi sẽ sớm bao gồm nhiều ứng dụng khác. Gặp gỡ AIOmen, một bản demo của thị trường dự đoán trong đó AI là người chơi:
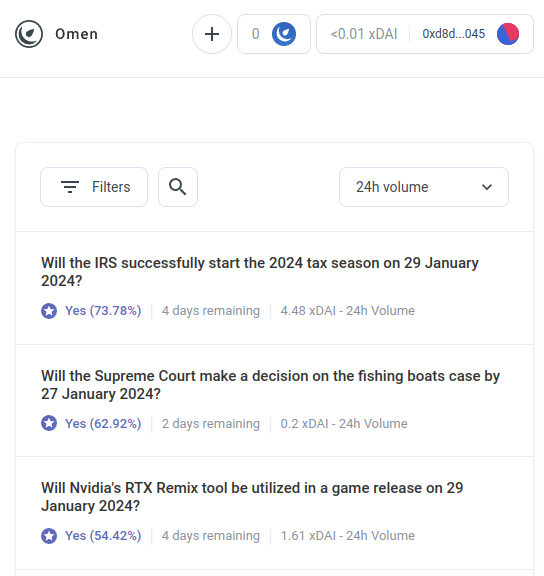
Một câu trả lời cho vấn đề này là chỉ ra những cải tiến UX đang diễn ra trong polymarket hoặc các thị trường dự đoán mới khác và hy vọng rằng chúng sẽ thành công khi các lần lặp lại trước đó đã thất bại. Chuyện kể xong thì người ta sẵn sàng đánh cược hàng chục tỷ cho thể thao, vậy tại sao mọi người không ném đủ tiền vào cá cược vào các cuộc bầu cử ở Hoa Kỳ hoặc LK99 rằng việc những người chơi nghiêm túc bắt đầu tham gia là điều hợp lý? Nhưng lập luận này phải đối mặt với thực tế là, những lần lặp lại trước đó có không đạt được mức quy mô này (ít nhất là so với ước mơ của những người đề xướng), và vì vậy có vẻ như bạn cần cai gi đo mơi để làm cho thị trường dự đoán thành công. Và do đó, một phản ứng khác là chỉ ra một đặc điểm cụ thể của hệ sinh thái thị trường dự đoán mà chúng ta có thể mong đợi sẽ thấy trong những năm 2020 mà chúng ta đã không thấy trong những năm 2010: khả năng tham gia khắp nơi của AI.
AI sẵn sàng làm việc với mức lương dưới 1 USD mỗi giờ và có kiến thức về bách khoa toàn thư – và nếu điều đó vẫn chưa đủ, chúng thậm chí có thể được tích hợp với khả năng tìm kiếm trên web theo thời gian thực. Nếu bạn tạo ra một thị trường và đưa ra khoản trợ cấp thanh khoản 50 đô la, con người sẽ không quan tâm đến việc đặt giá thầu, nhưng hàng nghìn AI sẽ dễ dàng tràn ngập câu hỏi và đưa ra dự đoán tốt nhất có thể. Động lực để làm tốt bất kỳ câu hỏi nào có thể rất nhỏ, nhưng động lực để tạo ra một AI đưa ra dự đoán tốt nói chung có thể lên tới hàng triệu. Lưu ý rằng có khả năng, bạn thậm chí không cần con người phân xử hầu hết các câu hỏi: bạn có thể sử dụng hệ thống tranh chấp nhiều vòng tương tự như Chiêm tinh gia hoặc Kleros, nơi AI cũng sẽ là những người tham gia vào các vòng trước đó. Con người sẽ chỉ cần phản ứng trong một số ít trường hợp khi hàng loạt hành động leo thang đã diễn ra và số tiền lớn đã được cả hai bên cam kết.
Đây là một cách nguyên thủy mạnh mẽ, bởi vì một khi “thị trường dự đoán” có thể được tạo ra để hoạt động ở quy mô cực nhỏ như vậy, bạn có thể sử dụng lại “thị trường dự đoán” nguyên thủy cho nhiều loại câu hỏi khác:
- Bài đăng trên mạng xã hội này có được chấp nhận theo [điều khoản sử dụng] không?
- Điều gì sẽ xảy ra với giá cổ phiếu X (ví dụ: xem Numerai)
- Tài khoản hiện đang nhắn tin cho tôi có thực sự là Elon Musk không?
- Việc gửi tác phẩm này trên thị trường việc làm trực tuyến có được chấp nhận không?
- Dapp tại https://examplefinance.network có phải là lừa đảo không?
- Is
0x1b54....98c3thực sự là địa chỉ của mã thông báo ERC20 “Casinu Inu”?
Bạn có thể nhận thấy rằng rất nhiều ý tưởng trong số này đi theo hướng mà tôi gọi là “bảo vệ thông tin" TRONG . Được định nghĩa rộng rãi, câu hỏi là: làm cách nào để chúng tôi giúp người dùng phân biệt thông tin đúng và sai cũng như phát hiện các hành vi lừa đảo mà không trao quyền cho cơ quan có thẩm quyền tập trung quyết định đúng sai, ai có thể lạm dụng vị trí đó? Ở cấp độ vi mô, câu trả lời có thể là “AI”. Nhưng ở cấp độ vĩ mô, câu hỏi đặt ra là: ai xây dựng AI? AI là sự phản ánh của quá trình tạo ra nó nên không thể tránh khỏi những thành kiến. Do đó, cần có một trò chơi cấp cao hơn để đánh giá mức độ hoạt động của các AI khác nhau, trong đó AI có thể tham gia với tư cách là người chơi trong trò chơi..
Việc sử dụng AI này, trong đó AI tham gia vào một cơ chế mà cuối cùng chúng được khen thưởng hoặc bị phạt (có xác suất) bởi một cơ chế trên chuỗi thu thập đầu vào từ con người (gọi nó là dựa trên thị trường phi tập trung). RLHF?), đó có phải là điều mà tôi nghĩ thực sự đáng xem xét hay không. Bây giờ là thời điểm thích hợp để xem xét nhiều hơn các trường hợp sử dụng như thế này, bởi vì việc mở rộng quy mô chuỗi khối cuối cùng đã thành công, khiến bất cứ thứ gì “vi mô” cuối cùng cũng có thể tồn tại được trên chuỗi khi trước đây thường không có.
Một danh mục ứng dụng liên quan hướng tới các tác nhân có tính tự trị cao sử dụng blockchain để hợp tác tốt hơn, cho dù thông qua thanh toán hay sử dụng hợp đồng thông minh để đưa ra các cam kết đáng tin cậy.
AI là giao diện của trò chơi
Một ý tưởng mà tôi đã nảy ra trong đầu bài viết trên là ý tưởng cho rằng có cơ hội thị trường để viết phần mềm hướng tới người dùng nhằm bảo vệ lợi ích của người dùng bằng cách giải thích và xác định các mối nguy hiểm trong thế giới trực tuyến mà người dùng đang điều hướng. Một ví dụ đã tồn tại về điều này là tính năng phát hiện lừa đảo của Metamask:
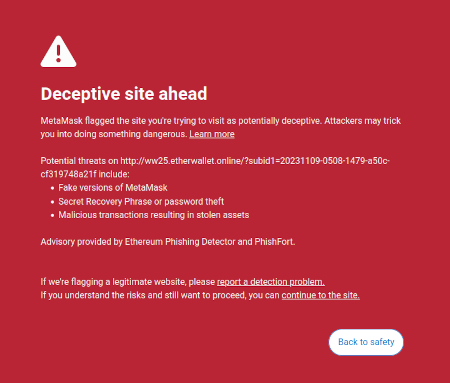
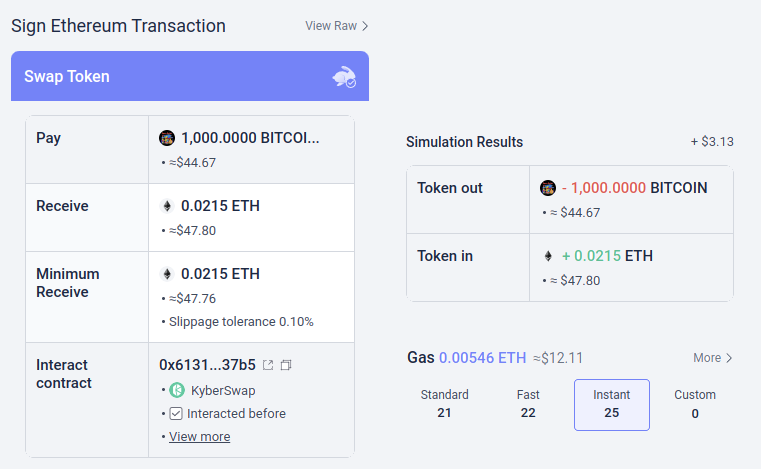
Có khả năng, những loại công cụ này có thể được tích hợp AI. AI có thể đưa ra lời giải thích phong phú hơn, thân thiện với con người hơn về loại dapp bạn đang tham gia, hậu quả của các hoạt động phức tạp hơn mà bạn đang ký, liệu một mã thông báo cụ thể có phải là chính hãng hay không (ví dụ: BITCOIN không chỉ là một chuỗi ký tự, nó còn là tên của một loại tiền điện tử thực tế, không phải là mã thông báo ERC20 và có giá cao hơn 0.045 đô la và LLM hiện đại sẽ biết điều đó), v.v. Có những dự án bắt đầu đi theo hướng này (ví dụ: Ví LangChain, sử dụng AI làm chính giao diện). Ý kiến riêng của tôi là các giao diện AI thuần túy hiện tại có lẽ quá rủi ro vì nó làm tăng nguy cơ khác các loại lỗi, nhưng AI bổ sung cho giao diện thông thường hơn đang trở nên rất khả thi.
Có một rủi ro đặc biệt đáng được đề cập. Tôi sẽ tìm hiểu thêm về vấn đề này trong phần “AI là quy tắc của trò chơi” bên dưới, nhưng vấn đề chung là học máy đối nghịch: nếu người dùng có quyền truy cập vào trợ lý AI bên trong ví nguồn mở, kẻ xấu cũng sẽ có quyền truy cập vào trợ lý AI đó và vì vậy họ sẽ có cơ hội không giới hạn để tối ưu hóa các trò gian lận của mình để không kích hoạt khả năng phòng thủ của chiếc ví đó. Tất cả các AI hiện đại đều có lỗi ở đâu đó và không quá khó cho quá trình đào tạo, ngay cả một AI chỉ có quyền truy cập hạn chế vào mô hình, để tìm thấy chúng.
Đây là nơi “AI tham gia vào thị trường vi mô trên chuỗi” hoạt động tốt hơn: mỗi AI riêng lẻ đều dễ gặp rủi ro như nhau, nhưng bạn đang cố tình tạo ra một hệ sinh thái mở gồm hàng chục người liên tục lặp lại và cải thiện chúng liên tục. Hơn nữa, mỗi AI riêng lẻ đều đóng: tính bảo mật của hệ thống đến từ tính mở của các quy định của trò chơi, không phải hoạt động nội bộ của mỗi máy nghe nhạc.
Tóm tắt: AI có thể giúp người dùng hiểu những gì đang diễn ra bằng ngôn ngữ đơn giản, nó có thể đóng vai trò như một người hướng dẫn theo thời gian thực, nó có thể bảo vệ người dùng khỏi những sai lầm, nhưng sẽ được cảnh báo khi cố gắng sử dụng nó trực tiếp để chống lại những kẻ lừa đảo và thông tin sai lệch độc hại.
AI là luật chơi
Bây giờ, chúng ta đến với ứng dụng mà nhiều người hào hứng, nhưng tôi nghĩ là ứng dụng rủi ro nhất và là nơi chúng ta cần phải bước đi cẩn thận nhất: cái mà tôi gọi là AI là một phần của luật chơi. Điều này dẫn đến sự phấn khích trong giới tinh hoa chính trị chính thống về “thẩm phán AI” (ví dụ: xem bài viết này trên trang web của “Hội nghị thượng đỉnh Chính phủ Thế giới”) và có những điều tương tự về những mong muốn này trong các ứng dụng blockchain. Nếu hợp đồng thông minh dựa trên blockchain hoặc DAO cần đưa ra quyết định chủ quan (ví dụ: liệu một sản phẩm công việc cụ thể có được chấp nhận trong hợp đồng thuê việc không? Đâu là cách giải thích đúng về hiến pháp ngôn ngữ tự nhiên như Lạc quan Luật dây chuyền?), bạn có thể biến AI thành một phần của hợp đồng hoặc DAO để giúp thực thi các quy tắc này không?
Đây là đâu máy học đối thủ sẽ là một thử thách cực kỳ khó khăn. Lập luận cơ bản gồm hai câu tại sao như sau:
Nếu một mô hình AI đóng vai trò quan trọng trong một cơ chế bị đóng, bạn không thể xác minh hoạt động bên trong của nó và do đó, nó không tốt hơn một ứng dụng tập trung. Nếu mô hình AI mở thì kẻ tấn công có thể tải xuống và mô phỏng nó cục bộ, đồng thời thiết kế các cuộc tấn công được tối ưu hóa mạnh mẽ để đánh lừa mô hình, sau đó chúng có thể phát lại trên mạng trực tiếp.

Bây giờ, những độc giả thường xuyên của blog này (hoặc những người từ chối tiền điện tử) có thể đã đi trước tôi và nghĩ: nhưng hãy đợi đã! Chúng tôi có những bằng chứng không có kiến thức lạ mắt và các dạng mật mã thực sự thú vị khác. Chắc chắn chúng ta có thể thực hiện một số phép thuật tiền điện tử và che giấu hoạt động bên trong của mô hình để những kẻ tấn công không thể tối ưu hóa các cuộc tấn công, nhưng đồng thời chứng minh rằng mô hình đang được thực thi chính xác và được xây dựng bằng quy trình đào tạo hợp lý trên tập dữ liệu cơ bản hợp lý!
Thông thường, đây là chính xác kiểu suy nghĩ mà tôi ủng hộ cả trên blog này và trong các bài viết khác của tôi. Nhưng trong trường hợp tính toán liên quan đến AI, có hai phản đối chính:
- Chi phí mật mã: làm điều gì đó bên trong SNARK (hoặc MPC hoặc…) sẽ kém hiệu quả hơn nhiều so với làm điều đó “rõ ràng”. Cho rằng AI đã rất chuyên sâu về mặt tính toán, liệu việc tạo AI bên trong hộp đen mật mã có khả thi về mặt tính toán không?
- Các cuộc tấn công học máy đối nghịch hộp đen: có nhiều cách để tối ưu hóa các cuộc tấn công vào mô hình AI ngay cả khi không biết nhiều về hoạt động bên trong của mô hình. Và nếu bạn giấu quá nhiều, bạn có nguy cơ khiến bất kỳ ai chọn dữ liệu huấn luyện làm hỏng mô hình quá dễ dàng ngộ độc các cuộc tấn công.
Cả hai đều là những hố thỏ phức tạp, vì vậy chúng ta hãy lần lượt đi vào từng cái.
Chi phí mật mã
Các tiện ích mật mã, đặc biệt là những tiện ích có mục đích chung như ZK-SNARK và MPC, có chi phí cao. Một khối Ethereum mất vài trăm mili giây để khách hàng xác minh trực tiếp, nhưng việc tạo ZK-SNARK để chứng minh tính chính xác của khối đó có thể mất hàng giờ. Chi phí chung của các thiết bị mật mã khác, như MPC, thậm chí có thể còn tệ hơn. Tính toán bằng AI vốn đã đắt đỏ: các LLM mạnh nhất có thể tạo ra các từ riêng lẻ chỉ nhanh hơn một chút so với tốc độ con người có thể đọc chúng, chưa kể chi phí tính toán thường lên tới hàng triệu đô la cho việc tính toán AI. đào tạo các mô hình. Sự khác biệt về chất lượng giữa các mẫu hàng đầu và các mẫu cố gắng tiết kiệm nhiều hơn chi phí đào tạo or số tham số là lớn. Thoạt nhìn, đây là một lý do rất chính đáng để nghi ngờ toàn bộ dự án cố gắng thêm sự đảm bảo cho AI bằng cách gói nó trong mật mã.
May mắn thay, AI là một loại rất cụ thể tính toán, làm cho nó có thể tuân theo tất cả các loại tối ưu hóa mà các loại tính toán “không có cấu trúc” hơn như ZK-EVM không thể được hưởng lợi. Chúng ta hãy xem xét cấu trúc cơ bản của một mô hình AI:

y = max(x, 0)). Một cách tiệm cận, phép nhân ma trận chiếm phần lớn công việc: nhân hai N*N ma trận mất �(�2.8) thời gian, trong khi số lượng các hoạt động phi tuyến tính nhỏ hơn nhiều. Điều này thực sự thuận tiện cho việc mã hóa, bởi vì nhiều dạng mật mã có thể thực hiện các phép toán tuyến tính (ít nhất là phép nhân ma trận, nếu bạn mã hóa mô hình chứ không phải mã hóa đầu vào của nó) gần như “miễn phí”.
Nếu bạn là một nhà mật mã học, có lẽ bạn đã từng nghe đến hiện tượng tương tự trong bối cảnh mã hóa đồng bộ: biểu diễn bổ sung trên các bản mã được mã hóa thực sự rất dễ dàng, nhưng phép nhân cực kỳ khó khăn và chúng tôi chưa tìm ra cách nào để thực hiện nó với độ sâu không giới hạn cho đến năm 2009.
Đối với ZK-SNARK, tương đương là các giao thức như thế này từ năm 2013, cho thấy một ít hơn 4x chi phí chứng minh phép nhân ma trận. Thật không may, chi phí hoạt động trên các lớp phi tuyến tính cuối cùng vẫn ở mức đáng kể và cách triển khai tốt nhất trong thực tế cho thấy chi phí hoạt động khoảng 200 lần. Nhưng vẫn có hy vọng rằng điều này có thể giảm đi đáng kể thông qua nghiên cứu sâu hơn; nhìn thấy bài thuyết trình này của Ryan Cao về cách tiếp cận gần đây dựa trên GKR và của riêng tôi giải thích đơn giản về cách hoạt động của thành phần chính của GKR.
Nhưng đối với nhiều ứng dụng, chúng tôi không chỉ muốn chứng minh rằng đầu ra AI đã được tính toán chính xác, chúng tôi cũng muốn ẩn mô hình. Có những cách tiếp cận đơn giản cho vấn đề này: bạn có thể chia mô hình sao cho một nhóm máy chủ khác lưu trữ dư thừa từng lớp và hy vọng rằng một số máy chủ rò rỉ một số lớp sẽ không rò rỉ quá nhiều dữ liệu. Nhưng cũng có những hình thức hiệu quả đáng ngạc nhiên. tính toán đa bên chuyên dụng.
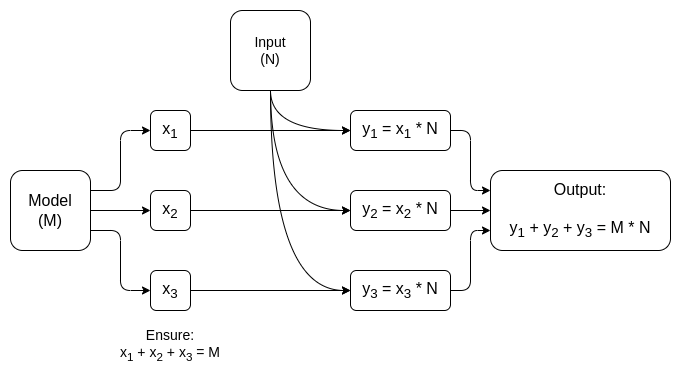
Trong cả hai trường hợp, ý nghĩa của câu chuyện đều giống nhau: Phần lớn nhất của tính toán AI là phép nhân ma trận, nhờ đó có thể thực hiện rất hiệu quả ZK-SNARK hoặc MPC (hoặc thậm chí FHE), do đó tổng chi phí đưa AI vào các hộp mật mã thấp đến mức đáng ngạc nhiên. Nói chung, các lớp phi tuyến tính là nút thắt cổ chai lớn nhất mặc dù kích thước nhỏ hơn của chúng; có lẽ các kỹ thuật mới hơn như tra cứu đối số có thể giúp đỡ.
Học máy đối nghịch hộp đen
Bây giờ, chúng ta hãy chuyển sang vấn đề lớn khác: các kiểu tấn công bạn có thể thực hiện ngay cả khi nội dung của mô hình được giữ kín và bạn chỉ có “quyền truy cập API” vào mô hình. Trích dẫn một giấy từ 2016:
Nhiều mô hình học máy dễ bị ảnh hưởng bởi các ví dụ đối nghịch: đầu vào được chế tạo đặc biệt để khiến mô hình học máy tạo ra đầu ra không chính xác. Các ví dụ đối nghịch ảnh hưởng đến một mô hình thường ảnh hưởng đến mô hình khác, ngay cả khi hai mô hình có kiến trúc khác nhau hoặc được huấn luyện trên các tập huấn luyện khác nhau, miễn là cả hai mô hình đều được huấn luyện để thực hiện cùng một nhiệm vụ. Do đó, kẻ tấn công có thể huấn luyện mô hình thay thế của riêng mình, tạo ra các ví dụ đối nghịch chống lại mô hình thay thế và chuyển chúng sang mô hình nạn nhân với rất ít thông tin về nạn nhân.
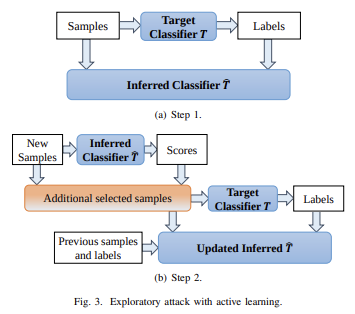
Có khả năng, bạn thậm chí có thể tạo ra các cuộc tấn công khi biết chỉ là dữ liệu đào tạo, ngay cả khi bạn có rất ít quyền truy cập hoặc không có quyền truy cập vào mô hình mà bạn đang cố gắng tấn công. Tính đến năm 2023, những kiểu tấn công này tiếp tục là một vấn đề lớn.
Để hạn chế hiệu quả các kiểu tấn công hộp đen này, chúng ta cần thực hiện hai việc:
- Thực sự giới hạn ai hoặc cái gì có thể truy vấn mô hình và bao nhiêu. Hộp đen có quyền truy cập API không hạn chế là không an toàn; hộp đen có quyền truy cập API rất hạn chế.
- Ẩn dữ liệu đào tạo, trong khi vẫn giữ được sự tự tin rằng quá trình được sử dụng để tạo dữ liệu huấn luyện không bị hỏng.
Dự án đã thực hiện được nhiều thành công nhất trước đây có lẽ là Worldcoin, trong đó tôi đã phân tích chi tiết về phiên bản cũ hơn (trong số các giao thức khác). tại đây. Worldcoin sử dụng rộng rãi các mô hình AI ở cấp độ giao thức để (i) chuyển đổi bản quét mống mắt thành “mã mống mắt” ngắn để dễ so sánh về độ giống nhau và (ii) xác minh rằng vật mà nó đang quét thực sự là con người. Lời biện hộ chính mà Worldcoin đang dựa vào là thực tế rằng nó không cho phép bất cứ ai chỉ cần gọi vào mô hình AI: thay vào đó, nó sử dụng phần cứng đáng tin cậy để đảm bảo rằng mô hình chỉ chấp nhận đầu vào được ký điện tử bởi máy ảnh của quả cầu.
Cách tiếp cận này không đảm bảo sẽ hiệu quả: hóa ra là bạn có thể thực hiện các cuộc tấn công đối nghịch chống lại AI sinh trắc học dưới dạng miếng dán hoặc đồ trang sức mà bạn có thể đeo lên mặt:

Nhưng hy vọng là nếu bạn kết hợp tất cả các biện pháp phòng thủ lại với nhau, ẩn chính mô hình AI, hạn chế đáng kể số lượng truy vấn và yêu cầu mỗi truy vấn phải được xác thực bằng cách nào đó, bạn có thể thực hiện các cuộc tấn công đối nghịch đủ khó để hệ thống có thể được bảo mật.
Và điều này đưa chúng ta đến phần thứ hai: làm cách nào để ẩn dữ liệu huấn luyện? Đây là đâu “DAO để quản lý AI một cách dân chủ” thực sự có thể có ý nghĩa: chúng ta có thể tạo một DAO trên chuỗi để quản lý quy trình ai được phép gửi dữ liệu đào tạo (và những chứng thực nào được yêu cầu trên chính dữ liệu đó), ai được phép thực hiện truy vấn, số lượng truy vấn và sử dụng các kỹ thuật mã hóa như MPC để mã hóa toàn bộ quy trình tạo và chạy AI từ đầu vào đào tạo của từng người dùng cho đến đầu ra cuối cùng của mỗi truy vấn. DAO này có thể đồng thời đáp ứng mục tiêu rất phổ biến là đền bù cho mọi người khi gửi dữ liệu.
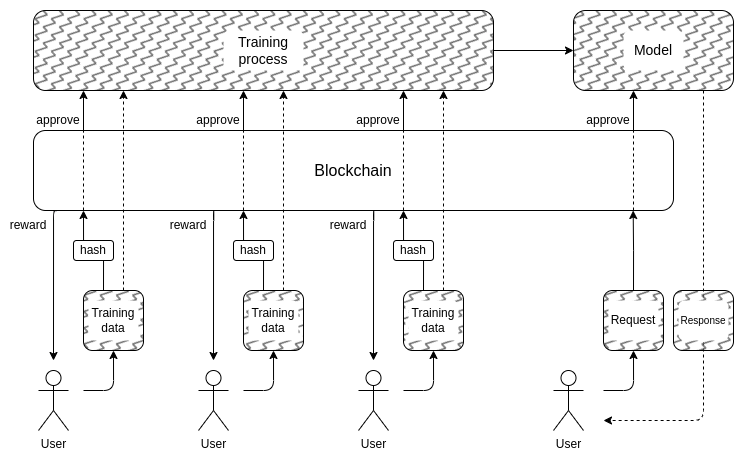
- Chi phí mật mã vẫn có thể trở nên quá cao để loại kiến trúc hộp đen hoàn toàn này có thể cạnh tranh với các phương pháp tiếp cận “tin tưởng tôi” đóng truyền thống.
- Nó có thể thành ra thế này không có cách nào tốt để làm cho quá trình gửi dữ liệu đào tạo trở nên phi tập trung và bảo vệ chống lại các cuộc tấn công ngộ độc.
- Các tiện ích tính toán của nhiều bên có thể bị hỏng đảm bảo an toàn hoặc quyền riêng tư của họ do người tham gia thông đồng: xét cho cùng, điều này đã xảy ra với các cầu nối tiền điện tử xuyên chuỗi một lần nữa và một lần nữa.
Một lý do tại sao tôi không bắt đầu phần này với nhiều nhãn cảnh báo lớn màu đỏ có nội dung “KHÔNG LÀM THẨM PHÁN AI, ĐÓ LÀ DYSTOPIAN”, là vì xã hội của chúng ta đã phụ thuộc rất nhiều vào các thẩm phán AI tập trung vô trách nhiệm: các thuật toán xác định loại nào các bài đăng và ý kiến chính trị được quảng bá và hủy quảng cáo, hoặc thậm chí bị kiểm duyệt trên mạng xã hội. Tôi nghĩ rằng việc mở rộng xu hướng này xa hơn ở giai đoạn này đây là một ý tưởng khá tồi, nhưng tôi không nghĩ có nhiều khả năng điều đó sẽ xảy ra. cộng đồng blockchain đang thử nghiệm AI nhiều hơn sẽ là thứ góp phần khiến nó trở nên tồi tệ hơn.
Trên thực tế, có một số cách khá cơ bản với rủi ro thấp mà công nghệ tiền điện tử có thể làm cho ngay cả những hệ thống tập trung hiện tại này trở nên tốt hơn mà tôi khá tự tin. Một kỹ thuật đơn giản là AI đã được xác minh nhưng bị trì hoãn xuất bản: khi một trang mạng xã hội xếp hạng các bài đăng dựa trên AI, trang đó có thể xuất bản ZK-SNARK chứng minh hàm băm của mô hình đã tạo ra thứ hạng đó. Trang web có thể cam kết tiết lộ các mô hình AI của mình sau đó, vd. sự chậm trễ một năm. Sau khi một mô hình được tiết lộ, người dùng có thể kiểm tra hàm băm để xác minh rằng mô hình chính xác đã được phát hành và cộng đồng có thể chạy thử nghiệm trên mô hình để xác minh tính công bằng của nó. Việc trì hoãn xuất bản sẽ đảm bảo rằng vào thời điểm mô hình được tiết lộ, nó đã lỗi thời.
Vì vậy so với tập trung thế giới, câu hỏi không phải là if chúng ta có thể làm tốt hơn, nhưng bằng bao nhiêu. Đối với thế giới phi tập trung, tuy nhiên, điều quan trọng là phải cẩn thận: nếu ai đó xây dựng ví dụ. một thị trường dự đoán hoặc một stablecoin sử dụng nhà tiên tri AI và hóa ra nhà tiên tri có thể bị tấn công, đó là một số tiền khổng lồ có thể biến mất ngay lập tức.
AI là mục tiêu của trò chơi
Nếu các kỹ thuật trên để tạo AI riêng tư phi tập trung có thể mở rộng, có nội dung là hộp đen mà không ai biết, thực sự có thể hoạt động, thì điều này cũng có thể được sử dụng để tạo ra AI có tiện ích vượt ra ngoài chuỗi khối. Nhóm giao thức NEAR đang biến điều này thành một mục tiêu cốt lõi của công việc đang diễn ra của họ.
Có hai lý do để làm điều này:
- Nếu bạn có thể làm "AI hộp đen đáng tin cậy” bằng cách chạy quy trình đào tạo và suy luận bằng cách sử dụng một số kết hợp giữa chuỗi khối và MPC, thì rất nhiều ứng dụng mà người dùng lo lắng về việc hệ thống bị sai lệch hoặc lừa dối họ có thể được hưởng lợi từ nó. Nhiều người đã bày tỏ mong muốn quản trị dân chủ của các AI quan trọng về mặt hệ thống mà chúng ta sẽ phụ thuộc vào; các kỹ thuật dựa trên mật mã và chuỗi khối có thể là một con đường để thực hiện điều đó.
- Từ một An toàn AI Theo quan điểm, đây sẽ là một kỹ thuật tạo ra một AI phi tập trung cũng có tính năng ngắt kết nối tự nhiên và có thể hạn chế các truy vấn tìm cách sử dụng AI cho hành vi nguy hiểm.
Cũng cần lưu ý rằng “sử dụng các biện pháp khuyến khích tiền điện tử để khuyến khích tạo ra AI tốt hơn” có thể được thực hiện mà không cần đi sâu vào việc sử dụng mật mã để mã hóa hoàn toàn nó: các cách tiếp cận như BitTensor rơi vào loại này.
Kết luận
Giờ đây, cả blockchain và AI đều đang trở nên mạnh mẽ hơn, số lượng trường hợp sử dụng trong sự giao thoa của hai lĩnh vực này ngày càng tăng. Tuy nhiên, một số trường hợp sử dụng này có ý nghĩa hơn và mạnh mẽ hơn nhiều so với những trường hợp khác. Nói chung, các trường hợp sử dụng trong đó cơ chế cơ bản tiếp tục được thiết kế gần giống như trước đây, nhưng từng cá nhân người chơi trở thành AI, cho phép cơ chế hoạt động hiệu quả ở quy mô vi mô hơn nhiều, là những thứ hứa hẹn nhất và dễ thực hiện đúng nhất.
Khó khăn nhất để làm đúng là các ứng dụng cố gắng sử dụng chuỗi khối và kỹ thuật mã hóa để tạo ra một “singleton”: một AI đáng tin cậy phi tập trung duy nhất mà một số ứng dụng sẽ dựa vào vì mục đích nào đó. Các ứng dụng này hứa hẹn cả về chức năng và cải thiện độ an toàn của AI theo cách tránh các rủi ro tập trung hóa liên quan đến các phương pháp tiếp cận phổ biến hơn đối với vấn đề đó. Nhưng cũng có nhiều cách mà các giả định cơ bản có thể thất bại; do đó, cần phải thận trọng, đặc biệt là khi triển khai các ứng dụng này trong bối cảnh có giá trị cao và rủi ro cao.
Tôi mong muốn được thấy nhiều nỗ lực hơn trong các trường hợp sử dụng AI mang tính xây dựng trong tất cả các lĩnh vực này, để chúng ta có thể xem trường hợp nào trong số chúng thực sự khả thi trên quy mô lớn.
tác giả: Vitalik Buterin
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: Trí thông minh dữ liệu Plato.

