Giới thiệu
Trong chủ đề thú vị về thị giác máy tính, nơi hình ảnh chứa nhiều bí mật và thông tin, việc phân biệt và làm nổi bật các mục là rất quan trọng. Phân đoạn hình ảnh, quá trình chia hình ảnh thành các vùng hoặc đối tượng có ý nghĩa, là điều cần thiết trong các ứng dụng khác nhau, từ hình ảnh y tế đến lái xe tự động và nhận dạng đối tượng. Phân đoạn chính xác và tự động từ lâu đã là một thách thức, với các phương pháp truyền thống thường không đạt được độ chính xác và hiệu quả. Nhập kiến trúc UNET, một phương pháp thông minh đã cách mạng hóa việc phân đoạn hình ảnh. Với thiết kế đơn giản và các kỹ thuật sáng tạo, UNET đã mở đường cho các kết quả phân đoạn chính xác và mạnh mẽ hơn. Cho dù bạn là người mới tham gia lĩnh vực thú vị về thị giác máy tính hay một học viên có kinh nghiệm đang tìm cách cải thiện khả năng phân đoạn của mình, bài viết chuyên sâu trên blog này sẽ làm sáng tỏ sự phức tạp của UNET và cung cấp sự hiểu biết đầy đủ về kiến trúc, các thành phần và tính hữu dụng của nó.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Hiểu về mạng nơ-ron tích chập
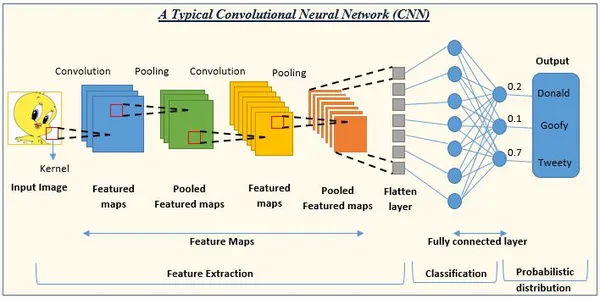
CNN là một mô hình học sâu thường được sử dụng trong các tác vụ thị giác máy tính, bao gồm phân loại hình ảnh, nhận dạng đối tượng và phân đoạn hình ảnh. CNN chủ yếu để tìm hiểu và trích xuất thông tin liên quan từ hình ảnh, làm cho chúng cực kỳ hữu ích trong phân tích dữ liệu trực quan.
Các thành phần quan trọng của CNN
- Lớp tích chập: CNN bao gồm một tập hợp các bộ lọc có thể học được (hạt nhân) kết hợp với hình ảnh đầu vào hoặc bản đồ đặc trưng. Mỗi bộ lọc áp dụng phép nhân và tính tổng theo từng phần tử để tạo ra một bản đồ đặc trưng làm nổi bật các mẫu cụ thể hoặc các đặc điểm cục bộ trong đầu vào. Các bộ lọc này có thể nắm bắt nhiều yếu tố trực quan, chẳng hạn như các cạnh, góc và kết cấu.
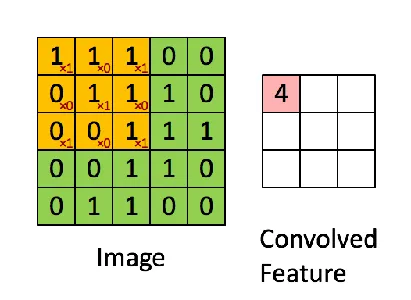
- Lớp tổng hợp: Tạo các bản đồ tính năng bằng các lớp tích chập được lấy mẫu xuống bằng cách sử dụng các lớp tổng hợp. Việc gộp làm giảm kích thước không gian của các bản đồ đặc trưng trong khi vẫn duy trì thông tin quan trọng nhất, giảm độ phức tạp tính toán của các lớp tiếp theo và làm cho mô hình có khả năng chống lại các biến động đầu vào cao hơn. Hoạt động tổng hợp phổ biến nhất là tổng hợp tối đa, có giá trị quan trọng nhất trong một vùng lân cận nhất định.
- Chức năng kích hoạt: Đưa Phi tuyến tính vào mô hình CNN bằng các hàm kích hoạt. Áp dụng chúng cho các kết quả đầu ra của từng phần tử lớp chập hoặc gộp, cho phép mạng hiểu được các liên kết phức tạp và đưa ra các quyết định phi tuyến tính. Do tính đơn giản và hiệu quả của nó trong việc giải quyết vấn đề độ dốc biến mất, chức năng kích hoạt Đơn vị tuyến tính chỉnh lưu (ReLU) phổ biến trong các CNN.
- Các lớp được kết nối đầy đủ: Các lớp được kết nối đầy đủ, còn được gọi là các lớp dày đặc, sử dụng các tính năng được truy xuất để hoàn thành thao tác phân loại hoặc hồi quy cuối cùng. Chúng kết nối mọi nơ-ron trong một lớp với mọi nơ-ron trong lớp tiếp theo, cho phép mạng học các biểu diễn toàn cầu và đưa ra các phán đoán cấp cao dựa trên đầu vào kết hợp của các lớp trước đó.
Mạng bắt đầu với một chồng các lớp tích chập để nắm bắt các tính năng cấp thấp, tiếp theo là các lớp tổng hợp. Các lớp tích chập sâu hơn học các đặc điểm cấp cao hơn khi mạng phát triển. Cuối cùng, sử dụng một hoặc nhiều lớp đầy đủ cho hoạt động phân loại hoặc hồi quy.
Cần một mạng được kết nối đầy đủ
Các CNN truyền thống thường dành cho các công việc phân loại hình ảnh trong đó một nhãn duy nhất được gán cho toàn bộ hình ảnh đầu vào. Mặt khác, kiến trúc CNN truyền thống gặp vấn đề với các tác vụ chi tiết hơn như phân đoạn ngữ nghĩa, trong đó mỗi pixel của hình ảnh phải được sắp xếp thành các lớp hoặc vùng khác nhau. Mạng chuyển đổi hoàn toàn (FCN) ra đời tại đây.
Hạn chế của Kiến trúc CNN truyền thống trong nhiệm vụ phân đoạn
Mất thông tin không gian: Các CNN truyền thống sử dụng các lớp tổng hợp để giảm dần kích thước không gian của các bản đồ đặc trưng. Mặc dù việc lấy mẫu xuống này giúp nắm bắt các tính năng cấp cao, nhưng nó dẫn đến mất thông tin không gian, gây khó khăn cho việc phát hiện và phân tách chính xác các đối tượng ở cấp độ pixel.
Kích thước đầu vào cố định: Kiến trúc CNN thường được xây dựng để chấp nhận hình ảnh có kích thước cụ thể. Tuy nhiên, các hình ảnh đầu vào có thể có nhiều kích thước khác nhau trong các tác vụ phân đoạn, khiến cho các đầu vào có kích thước thay đổi trở nên khó quản lý với các CNN điển hình.
Độ chính xác nội địa hóa hạn chế: Các CNN truyền thống thường sử dụng các lớp được kết nối đầy đủ ở cuối để cung cấp một vectơ đầu ra có kích thước cố định để phân loại. Vì chúng không giữ lại thông tin không gian nên chúng không thể định vị chính xác các đối tượng hoặc vùng trong ảnh.
Mạng kết hợp hoàn toàn (FCN) như một giải pháp cho phân đoạn ngữ nghĩa
Bằng cách làm việc độc quyền trên các lớp tích chập và duy trì thông tin không gian trên toàn mạng, Mạng tích chập hoàn toàn (FCN) giải quyết các hạn chế của kiến trúc CNN cổ điển trong các tác vụ phân đoạn. FCN nhằm mục đích đưa ra các dự đoán theo từng pixel, với mỗi pixel trong hình ảnh đầu vào được gán một nhãn hoặc lớp. FCN cho phép xây dựng bản đồ phân đoạn dày đặc với các dự báo ở cấp độ pixel bằng cách lấy mẫu lên các bản đồ đặc trưng. Các lớp tích chập được chuyển đổi (còn được gọi là lớp giải mã hoặc lớp lấy mẫu) được sử dụng để thay thế các lớp được liên kết hoàn toàn sau thiết kế CNN. Độ phân giải không gian của các bản đồ đặc trưng được tăng lên nhờ các cấu trúc chuyển vị, cho phép chúng có cùng kích thước với hình ảnh đầu vào.
Trong quá trình lấy mẫu, FCN thường sử dụng bỏ qua các kết nối, bỏ qua các lớp cụ thể và liên kết trực tiếp các bản đồ tính năng cấp thấp hơn với các bản đồ cấp cao hơn. Các mối quan hệ bỏ qua này giúp duy trì các chi tiết chi tiết và thông tin theo ngữ cảnh, tăng cường độ chính xác nội địa hóa của các vùng được phân đoạn. FCN cực kỳ hiệu quả trong các ứng dụng phân đoạn khác nhau, bao gồm phân đoạn ảnh y tế, phân tích cú pháp cảnh và phân đoạn phiên bản. Giờ đây, nó có thể xử lý các hình ảnh đầu vào có kích thước khác nhau, cung cấp các dự đoán ở cấp độ pixel và lưu giữ thông tin không gian trên mạng bằng cách tận dụng FCN để phân đoạn ngữ nghĩa.
Phân đoạn hình ảnh
Phân đoạn ảnh là một quá trình cơ bản trong thị giác máy tính trong đó một hình ảnh được chia thành nhiều phần hoặc phân đoạn có ý nghĩa và riêng biệt. Trái ngược với phân loại hình ảnh, cung cấp một nhãn duy nhất cho một hình ảnh hoàn chỉnh, phân đoạn thêm nhãn cho từng pixel hoặc nhóm pixel, về cơ bản là chia hình ảnh thành các phần có ý nghĩa về mặt ngữ nghĩa. Phân đoạn hình ảnh rất quan trọng vì nó cho phép hiểu chi tiết hơn về nội dung của hình ảnh. Chúng ta có thể trích xuất thông tin đáng kể về ranh giới đối tượng, hình thức, kích thước và mối quan hệ không gian bằng cách phân chia ảnh thành nhiều phần. Phân tích chi tiết này rất quan trọng trong các nhiệm vụ thị giác máy tính khác nhau, cho phép các ứng dụng được cải tiến và hỗ trợ diễn giải dữ liệu trực quan cấp cao hơn.

Tìm hiểu kiến trúc UNET
Các công nghệ phân đoạn hình ảnh truyền thống, chẳng hạn như chú thích thủ công và phân loại theo pixel, có nhiều nhược điểm khiến chúng trở nên lãng phí và khó thực hiện các công việc phân đoạn chính xác và hiệu quả. Do những hạn chế này, các giải pháp tiên tiến hơn, chẳng hạn như UNET kiến trúc, đã được phát triển. Chúng ta hãy xem xét những sai sót của những cách trước đây và tại sao UNET được tạo ra để khắc phục những vấn đề này.
- Chú thích thủ công: Chú thích thủ công đòi hỏi phải phác thảo và đánh dấu ranh giới hình ảnh hoặc vùng quan tâm. Mặc dù phương pháp này tạo ra kết quả phân đoạn đáng tin cậy, nhưng nó tốn nhiều thời gian, công sức và dễ mắc sai lầm của con người. Chú thích thủ công không thể mở rộng đối với các tập dữ liệu lớn và việc duy trì tính nhất quán cũng như thỏa thuận giữa các chú thích là khó khăn, đặc biệt là trong các tác vụ phân đoạn phức tạp.
- Phân loại pixel-khôn ngoan: Một cách tiếp cận phổ biến khác là phân loại theo pixel, trong đó mỗi pixel trong ảnh được phân loại độc lập, thường sử dụng các thuật toán như cây quyết định, máy vectơ hỗ trợ (SVM) hoặc rừng ngẫu nhiên. Mặt khác, việc phân loại theo pixel gặp khó khăn trong việc nắm bắt bối cảnh toàn cầu và sự phụ thuộc giữa các pixel xung quanh, dẫn đến các vấn đề về phân đoạn thừa hoặc thiếu. Nó không thể xem xét các mối quan hệ không gian và thường không đưa ra các ranh giới đối tượng chính xác.
vượt qua thử thách
Kiến trúc UNET được phát triển để giải quyết những hạn chế này và khắc phục những thách thức mà các phương pháp truyền thống phải đối mặt để phân đoạn ảnh. Đây là cách UNET giải quyết những vấn đề này:
- Học từ đầu đến cuối: UNET sử dụng kỹ thuật học từ đầu đến cuối, có nghĩa là nó học cách phân đoạn hình ảnh trực tiếp từ các cặp đầu vào-đầu ra mà không cần chú thích của người dùng. UNET có thể tự động trích xuất các tính năng chính và thực hiện phân đoạn chính xác bằng cách đào tạo trên một tập dữ liệu lớn được dán nhãn, loại bỏ nhu cầu chú thích thủ công tốn nhiều công sức.
- Kiến trúc tích chập hoàn toàn: UNET dựa trên kiến trúc tích chập hoàn toàn, ngụ ý rằng nó hoàn toàn được tạo thành từ các lớp tích chập và không bao gồm bất kỳ lớp kết nối đầy đủ nào. Kiến trúc này cho phép UNET hoạt động trên các hình ảnh đầu vào có kích thước bất kỳ, tăng tính linh hoạt và khả năng thích ứng của nó với các tác vụ phân đoạn khác nhau và các biến thể đầu vào.
- Kiến trúc hình chữ U với các kết nối bỏ qua: Kiến trúc đặc trưng của mạng bao gồm một đường dẫn mã hóa (đường dẫn hợp đồng) và một đường dẫn giải mã (đường dẫn mở rộng), cho phép nó thu thập thông tin cục bộ và bối cảnh toàn cầu. Bỏ qua các kết nối thu hẹp khoảng cách giữa các đường dẫn mã hóa và giải mã, duy trì thông tin quan trọng từ các lớp trước đó và cho phép phân đoạn chính xác hơn.
- Thông tin theo ngữ cảnh và bản địa hóa: Các kết nối bỏ qua được UNET sử dụng để tổng hợp các bản đồ tính năng đa tỷ lệ từ nhiều lớp, cho phép mạng hấp thụ thông tin theo ngữ cảnh và nắm bắt chi tiết ở các mức độ trừu tượng khác nhau. Việc tích hợp thông tin này cải thiện độ chính xác của bản địa hóa, cho phép xác định ranh giới đối tượng chính xác và kết quả phân đoạn chính xác.
- Tăng cường dữ liệu và chính quy hóa: UNET sử dụng các kỹ thuật tăng cường và chính quy hóa dữ liệu để cải thiện khả năng phục hồi và khả năng khái quát hóa của nó trong quá trình đào tạo. Để tăng tính đa dạng của dữ liệu đào tạo, việc tăng cường dữ liệu đòi hỏi phải thêm nhiều phép biến đổi vào hình ảnh đào tạo, chẳng hạn như xoay, lật, chia tỷ lệ và biến dạng. Các kỹ thuật chính quy hóa như loại bỏ và chuẩn hóa hàng loạt ngăn chặn quá mức và cải thiện hiệu suất mô hình trên dữ liệu không xác định.
Tổng quan về Kiến trúc UNET
UNET là một kiến trúc mạng thần kinh tích chập hoàn toàn (FCN) được xây dựng cho các ứng dụng phân đoạn ảnh. Nó được đề xuất lần đầu tiên vào năm 2015 bởi Olaf Ronneberger, Philipp Fischer và Thomas Brox. UNET thường được sử dụng vì độ chính xác của nó trong việc phân đoạn ảnh và đã trở thành lựa chọn phổ biến trong các ứng dụng hình ảnh y tế khác nhau. UNET kết hợp một đường dẫn mã hóa, còn được gọi là đường dẫn hợp đồng, với một đường dẫn giải mã được gọi là đường dẫn mở rộng. Kiến trúc được đặt tên theo hình chữ U khi được mô tả trong sơ đồ. Do kiến trúc hình chữ U này, mạng có thể ghi lại cả các tính năng cục bộ và bối cảnh toàn cầu, dẫn đến kết quả phân đoạn chính xác.
Các thành phần quan trọng của Kiến trúc UNET
- Đường dẫn hợp đồng (Đường dẫn mã hóa): Con đường hợp đồng của UNET bao gồm các lớp tích chập theo sau là các hoạt động tổng hợp tối đa. Phương pháp này ghi lại các đặc điểm ở mức độ thấp, độ phân giải cao bằng cách giảm dần kích thước không gian của hình ảnh đầu vào.
- Đường dẫn mở rộng (Đường dẫn giải mã): Các cấu chập được chuyển đổi, còn được gọi là các lớp giải chập hoặc lấy mẫu lên, được sử dụng để lấy mẫu lên các bản đồ đặc trưng từ đường dẫn mã hóa trong đường dẫn mở rộng UNET. Độ phân giải không gian của bản đồ đặc trưng được tăng lên trong giai đoạn lấy mẫu, cho phép mạng tạo lại bản đồ phân đoạn dày đặc.
- Bỏ qua kết nối: Kết nối bỏ qua được sử dụng trong UNET để kết nối các lớp phù hợp từ đường dẫn mã hóa đến giải mã. Các liên kết này cho phép mạng thu thập cả dữ liệu cục bộ và toàn cầu. Mạng giữ lại thông tin không gian cần thiết và cải thiện độ chính xác của phân đoạn bằng cách tích hợp các bản đồ đặc trưng từ các lớp trước đó với các bản đồ trong lộ trình giải mã.
- nối: Ghép nối thường được sử dụng để thực hiện các kết nối bỏ qua trong UNET. Các bản đồ đối tượng từ đường dẫn mã hóa được nối với các bản đồ đối tượng lấy mẫu từ đường dẫn giải mã trong quy trình lấy mẫu lên. Sự kết hợp này cho phép mạng kết hợp thông tin đa tỷ lệ để phân đoạn thích hợp, khai thác các tính năng ngữ cảnh cấp cao và cấp thấp.
- Các lớp tích chập hoàn toàn: UNET bao gồm các lớp tích chập không có lớp kết nối đầy đủ. Kiến trúc tích chập này cho phép UNET xử lý các hình ảnh có kích thước không giới hạn trong khi vẫn bảo toàn thông tin không gian trên mạng, làm cho nó linh hoạt và có thể thích ứng với các tác vụ phân đoạn khác nhau.
Đường dẫn mã hóa, hoặc đường dẫn hợp đồng, là một thành phần thiết yếu của kiến trúc UNET. Nó chịu trách nhiệm trích xuất thông tin cấp cao từ hình ảnh đầu vào trong khi thu nhỏ dần các kích thước không gian.
Các lớp hợp hiến
Quá trình mã hóa bắt đầu với một tập hợp các lớp tích chập. Các lớp tích chập trích xuất thông tin ở nhiều tỷ lệ bằng cách áp dụng một tập hợp các bộ lọc có thể học được cho hình ảnh đầu vào. Các bộ lọc này hoạt động trên trường tiếp nhận cục bộ, cho phép mạng nắm bắt các mẫu không gian và các tính năng phụ. Với mỗi lớp tích chập, độ sâu của các bản đồ đặc trưng tăng lên, cho phép mạng học các biểu diễn phức tạp hơn.
Chức năng kích hoạt
Sau mỗi lớp tích chập, một chức năng kích hoạt chẳng hạn như Đơn vị tuyến tính chỉnh lưu (ReLU) được áp dụng từng phần tử để tạo ra tính phi tuyến tính trong mạng. Chức năng kích hoạt hỗ trợ mạng học các mối tương quan phi tuyến tính giữa hình ảnh đầu vào và các tính năng được truy xuất.
Nhóm các lớp
Các lớp tổng hợp được sử dụng sau các lớp tích chập để giảm kích thước không gian của các bản đồ đối tượng. Các hoạt động, chẳng hạn như tổng hợp tối đa, phân chia các bản đồ đối tượng thành các vùng không chồng lấp và chỉ giữ lại giá trị tối đa bên trong mỗi vùng. Nó làm giảm độ phân giải không gian bằng cách lấy mẫu xuống các bản đồ tính năng, cho phép mạng thu được dữ liệu cấp cao hơn và trừu tượng hơn.
Công việc của đường dẫn mã hóa là nắm bắt các tính năng ở các quy mô và mức độ trừu tượng khác nhau theo cách phân cấp. Quá trình mã hóa tập trung vào việc trích xuất bối cảnh toàn cầu và thông tin cấp cao khi kích thước không gian giảm.
Bỏ qua kết nối
Tính sẵn có của các kết nối bỏ qua kết nối các mức thích hợp từ đường dẫn mã hóa đến đường dẫn giải mã là một trong những đặc điểm nổi bật của kiến trúc UNET. Các liên kết bỏ qua này rất quan trọng trong việc duy trì dữ liệu chính trong quá trình mã hóa.
Bản đồ tính năng từ các lớp trước thu thập các chi tiết cục bộ và thông tin chi tiết trong đường dẫn mã hóa. Các bản đồ tính năng này được nối với các bản đồ tính năng được lấy mẫu trong quy trình giải mã bằng cách sử dụng các kết nối bỏ qua. Điều này cho phép mạng kết hợp dữ liệu đa tỷ lệ, các tính năng cấp thấp và bối cảnh cấp cao vào quá trình phân đoạn.
Bằng cách bảo tồn thông tin không gian từ các lớp trước đó, UNET có thể bản địa hóa các đối tượng một cách đáng tin cậy và giữ các chi tiết tốt hơn trong các kết quả phân đoạn. Hỗ trợ bỏ qua các kết nối của UNET trong việc giải quyết vấn đề mất thông tin do lấy mẫu xuống. Các liên kết bỏ qua cho phép tích hợp thông tin cục bộ và toàn cầu tuyệt vời hơn, cải thiện hiệu suất phân khúc nói chung.
Tóm lại, cách tiếp cận mã hóa UNET là rất quan trọng để nắm bắt các đặc điểm cấp cao và hạ thấp kích thước không gian của hình ảnh đầu vào. Đường dẫn mã hóa trích xuất các biểu diễn trừu tượng dần dần thông qua các lớp tích chập, hàm kích hoạt và lớp tổng hợp. Bằng cách tích hợp các tính năng cục bộ và bối cảnh toàn cầu, việc giới thiệu các liên kết bỏ qua cho phép lưu giữ thông tin không gian quan trọng, tạo điều kiện cho các kết quả phân đoạn đáng tin cậy.
Đường dẫn giải mã trong UNET
Một thành phần quan trọng của kiến trúc UNET là đường giải mã, còn được gọi là đường mở rộng. Nó chịu trách nhiệm lấy mẫu bản đồ đặc trưng của đường dẫn mã hóa và xây dựng mặt nạ phân đoạn cuối cùng.
Lớp lấy mẫu (Chuyển đổi kết hợp)
Để tăng cường độ phân giải không gian của các bản đồ đặc trưng, phương pháp giải mã UNET bao gồm các lớp lấy mẫu ngược, thường được thực hiện bằng cách sử dụng các phép chập hoặc phép giải mã được chuyển đổi. Các kết chập được chuyển đổi về cơ bản là ngược lại với các kết chập thông thường. Chúng tăng cường kích thước không gian thay vì giảm chúng, cho phép lấy mẫu. Bằng cách xây dựng một hạt nhân thưa thớt và áp dụng nó vào bản đồ tính năng đầu vào, các tổ hợp chuyển đổi học cách lấy mẫu các bản đồ tính năng. Mạng học cách lấp đầy khoảng trống giữa các vị trí không gian hiện tại trong quá trình này, do đó tăng cường độ phân giải của bản đồ đặc trưng.
Sự kết hợp
Các bản đồ tính năng từ các lớp trước được nối với các bản đồ tính năng được lấy mẫu trong giai đoạn giải mã. Sự kết hợp này cho phép mạng tổng hợp thông tin đa tỷ lệ để phân đoạn chính xác, tận dụng ngữ cảnh cấp cao và các tính năng cấp thấp. Ngoài việc lấy mẫu lên, đường dẫn giải mã UNET bao gồm các kết nối bỏ qua từ các mức tương đương của đường dẫn mã hóa.
Mạng có thể khôi phục và tích hợp các đặc điểm chi tiết bị mất trong quá trình mã hóa bằng cách ghép các bản đồ đặc trưng từ các kết nối bị bỏ qua. Nó cho phép định vị và mô tả đối tượng chính xác hơn trong mặt nạ phân đoạn.
Quá trình giải mã trong UNET tái tạo lại một bản đồ phân đoạn dày đặc phù hợp với độ phân giải không gian của hình ảnh đầu vào bằng cách lấy mẫu dần dần các bản đồ đặc trưng và bao gồm cả các liên kết bỏ qua.
Chức năng của đường dẫn giải mã là khôi phục thông tin không gian bị mất trong quá trình mã hóa và tinh chỉnh kết quả phân đoạn. Nó kết hợp các chi tiết mã hóa cấp thấp với bối cảnh cấp cao thu được từ các lớp lấy mẫu để cung cấp mặt nạ phân đoạn chính xác và kỹ lưỡng.
UNET có thể tăng độ phân giải không gian của các bản đồ đặc trưng bằng cách sử dụng các cấu trúc chuyển đổi trong quá trình giải mã, do đó lấy mẫu lại chúng để phù hợp với kích thước hình ảnh gốc. Các kết cấu được chuyển đổi hỗ trợ mạng tạo mặt nạ phân đoạn dày đặc và chi tiết bằng cách học cách lấp đầy các khoảng trống và mở rộng các kích thước không gian.
Tóm lại, quá trình giải mã trong UNET tái tạo lại mặt nạ phân đoạn bằng cách nâng cao độ phân giải không gian của các bản đồ đặc trưng thông qua các lớp lấy mẫu và bỏ qua các kết nối. Các phép chập được chuyển đổi rất quan trọng trong giai đoạn này vì chúng cho phép mạng lấy mẫu lại các bản đồ đặc trưng và xây dựng mặt nạ phân đoạn chi tiết phù hợp với hình ảnh đầu vào ban đầu.
Hợp đồng và mở rộng đường dẫn trong UNET
Kiến trúc UNET tuân theo cấu trúc “bộ mã hóa-giải mã”, trong đó đường dẫn hợp đồng đại diện cho bộ mã hóa và đường dẫn mở rộng đại diện cho bộ giải mã. Thiết kế này giống như mã hóa thông tin thành dạng nén và sau đó giải mã nó để tái tạo lại dữ liệu gốc.
Đường dẫn hợp đồng (Bộ mã hóa)
Bộ mã hóa trong UNET là đường dẫn hợp đồng. Nó trích xuất ngữ cảnh và nén hình ảnh đầu vào bằng cách giảm dần kích thước không gian. Phương pháp này bao gồm các lớp tích chập, theo sau là các quy trình tổng hợp, chẳng hạn như tổng hợp tối đa để lấy mẫu xuống các bản đồ tính năng. Đường dẫn hợp đồng chịu trách nhiệm thu được các đặc điểm cấp cao, tìm hiểu bối cảnh toàn cầu và giảm độ phân giải không gian. Nó tập trung vào việc nén và trừu tượng hóa hình ảnh đầu vào, thu thập thông tin liên quan để phân đoạn một cách hiệu quả.
Đường dẫn mở rộng (Bộ giải mã)
Bộ giải mã trong UNET là con đường mở rộng. Bằng cách lấy mẫu các bản đồ tính năng từ đường dẫn hợp đồng, nó sẽ khôi phục thông tin không gian và tạo bản đồ phân đoạn cuối cùng. Lộ trình mở rộng bao gồm các lớp lấy mẫu, thường được thực hiện với các phép chập hoặc phép giải mã được chuyển vị để tăng độ phân giải không gian của các bản đồ đặc trưng. Đường dẫn mở rộng tái tạo lại các kích thước không gian ban đầu thông qua các kết nối bỏ qua bằng cách tích hợp các bản đồ tính năng được lấy mẫu ngược với các bản đồ tương đương từ đường dẫn hợp đồng. Phương pháp này cho phép mạng khôi phục các tính năng chi tiết và bản địa hóa chính xác các mục.
Thiết kế UNET nắm bắt bối cảnh toàn cầu và các chi tiết địa phương bằng cách kết hợp các lộ trình hợp đồng và mở rộng. Đường dẫn hợp đồng nén hình ảnh đầu vào thành một biểu diễn nhỏ gọn, quyết định xây dựng bản đồ phân đoạn chi tiết bằng đường dẫn mở rộng. Con đường mở rộng liên quan đến việc giải mã biểu diễn đã nén thành một bản đồ phân đoạn dày đặc và chính xác. Nó tái tạo lại thông tin không gian còn thiếu và tinh chỉnh kết quả phân đoạn. Cấu trúc bộ mã hóa-giải mã này cho phép phân đoạn chính xác bằng cách sử dụng ngữ cảnh cấp cao và thông tin không gian chi tiết.
Tóm lại, các tuyến mở rộng và hợp đồng của UNET giống như một cấu trúc “bộ mã hóa-giải mã”. Đường dẫn mở rộng là bộ giải mã, khôi phục thông tin không gian và tạo bản đồ phân đoạn cuối cùng. Ngược lại, đường dẫn hợp đồng đóng vai trò là bộ mã hóa, ghi lại ngữ cảnh và nén hình ảnh đầu vào. Kiến trúc này cho phép UNET mã hóa và giải mã thông tin một cách hiệu quả, cho phép phân đoạn hình ảnh chính xác và kỹ lưỡng.
Bỏ qua kết nối trong UNET
Kết nối bỏ qua là điều cần thiết đối với thiết kế UNET vì chúng cho phép thông tin di chuyển giữa các đường dẫn hợp đồng (mã hóa) và mở rộng (giải mã). Chúng rất quan trọng để duy trì thông tin không gian và cải thiện độ chính xác của phân đoạn.
Bảo quản thông tin không gian
Một số thông tin không gian có thể bị mất trong quá trình mã hóa khi các bản đồ đặc trưng trải qua các quy trình lấy mẫu xuống chẳng hạn như tổng hợp tối đa. Việc mất thông tin này có thể dẫn đến độ chính xác nội địa hóa thấp hơn và mất các chi tiết chi tiết trong mặt nạ phân đoạn.
Bằng cách thiết lập kết nối trực tiếp giữa các lớp tương ứng trong quy trình mã hóa và giải mã, bỏ qua kết nối giúp giải quyết vấn đề này. Bỏ qua các kết nối bảo vệ thông tin không gian quan trọng có thể bị mất trong quá trình lấy mẫu xuống. Các kết nối này cho phép thông tin từ luồng mã hóa tránh lấy mẫu xuống và được truyền trực tiếp đến đường giải mã.
Hợp nhất thông tin đa quy mô
Bỏ qua các kết nối cho phép hợp nhất thông tin đa quy mô từ nhiều lớp mạng. Các cấp độ sau của quá trình mã hóa nắm bắt thông tin ngữ nghĩa và ngữ cảnh cấp cao, trong khi các lớp trước đó nắm bắt các chi tiết cục bộ và thông tin chi tiết. UNET có thể kết hợp thành công thông tin cục bộ và toàn cầu bằng cách kết nối các bản đồ đặc trưng này từ đường dẫn mã hóa tới các lớp tương đương trong đường dẫn giải mã. Việc tích hợp thông tin đa tỷ lệ này giúp cải thiện độ chính xác của phân đoạn nói chung. Mạng có thể sử dụng dữ liệu cấp thấp từ đường dẫn mã hóa để tinh chỉnh kết quả phân đoạn trong đường dẫn giải mã, cho phép bản địa hóa chính xác hơn và phân định ranh giới đối tượng tốt hơn.
Kết hợp bối cảnh cấp cao và chi tiết cấp thấp
Bỏ qua kết nối cho phép đường dẫn giải mã kết hợp ngữ cảnh cấp cao và chi tiết cấp thấp. Các bản đồ tính năng được nối từ các kết nối bỏ qua bao gồm các bản đồ tính năng được lấy mẫu ngược của đường dẫn giải mã và các bản đồ tính năng của đường dẫn mã hóa.
Sự kết hợp này cho phép mạng tận dụng ngữ cảnh cấp cao được ghi lại trong đường dẫn giải mã và các tính năng chi tiết được ghi lại trong đường dẫn mã hóa. Mạng có thể kết hợp thông tin ở nhiều kích cỡ, cho phép phân đoạn chính xác và chi tiết hơn.
UNET có thể tận dụng thông tin đa tỷ lệ, bảo toàn các chi tiết không gian và hợp nhất bối cảnh cấp cao với các chi tiết cấp thấp bằng cách thêm các kết nối bỏ qua. Do đó, độ chính xác của phân đoạn được cải thiện, nội địa hóa đối tượng được cải thiện và thông tin chi tiết trong mặt nạ phân đoạn được giữ lại.
Tóm lại, bỏ qua các kết nối trong UNET là rất quan trọng để duy trì thông tin không gian, tích hợp thông tin đa tỷ lệ và tăng độ chính xác của phân đoạn. Chúng cung cấp luồng thông tin trực tiếp qua các tuyến mã hóa và giải mã, cho phép mạng thu thập các chi tiết cục bộ và toàn cầu, dẫn đến phân đoạn hình ảnh chi tiết và chính xác hơn.
Mất chức năng trong UNET
Điều quan trọng là chọn một hàm mất mát thích hợp trong khi đào tạo UNET và tối ưu hóa các tham số của nó cho các tác vụ phân đoạn ảnh. UNET thường xuyên sử dụng các hàm mất mát thân thiện với phân đoạn như hệ số Dice hoặc mất mát entropy chéo.
Tổn thất hệ số xúc xắc
Hệ số Dice là một thống kê tương tự tính toán sự trùng lặp giữa mặt nạ phân đoạn dự đoán và mặt nạ phân đoạn thực. Tổn thất hệ số Xúc xắc, hoặc tổn thất Xúc xắc mềm, được tính bằng cách lấy hệ số Xúc xắc trừ đi một. Khi mặt nạ sự thật dự đoán và mặt đất căn chỉnh tốt, tổn thất sẽ giảm thiểu, dẫn đến hệ số Xúc xắc cao hơn.
Mất hệ số Dice đặc biệt hiệu quả đối với các bộ dữ liệu không cân bằng trong đó lớp nền có nhiều pixel. Bằng cách xử phạt các trường hợp dương tính giả và âm tính giả, nó thúc đẩy mạng phân chia chính xác cả vùng nền trước và vùng nền sau.
Mất Entropy chéo
Sử dụng hàm mất entropy chéo trong các tác vụ phân đoạn ảnh. Nó đo lường sự không giống nhau giữa xác suất lớp dự đoán và nhãn sự thật cơ bản. Coi mỗi pixel là một vấn đề phân loại độc lập trong phân đoạn hình ảnh và tổn thất entropy chéo được tính theo pixel.
Mất entropy chéo khuyến khích mạng gán xác suất cao cho các nhãn lớp chính xác cho mỗi pixel. Nó xử phạt những sai lệch so với sự thật cơ bản, thúc đẩy kết quả phân đoạn chính xác. Hàm mất mát này có hiệu quả khi các lớp tiền cảnh và hậu cảnh được cân bằng hoặc khi nhiều lớp tham gia vào nhiệm vụ phân đoạn.
Sự lựa chọn giữa tổn thất hệ số Dice và tổn thất entropy chéo tùy thuộc vào yêu cầu cụ thể của nhiệm vụ phân đoạn và đặc điểm của tập dữ liệu. Cả hai hàm mất mát đều có ưu điểm và có thể được kết hợp hoặc tùy chỉnh dựa trên các nhu cầu cụ thể.
1: Nhập thư viện
import tensorflow as tf
import os
import numpy as np
from tqdm import tqdm
from skimage.io import imread, imshow
from skimage.transform import resize
import matplotlib.pyplot as plt
import random2: Kích thước hình ảnh – Cài đặt
IMG_WIDTH = 128
IMG_HEIGHT = 128
IMG_CHANNELS = 33: Đặt tính ngẫu nhiên
seed = 42
np.random.seed = seed4: Nhập tập dữ liệu
# Data downloaded from - https://www.kaggle.com/competitions/data-science-bowl-2018/data #importing datasets
TRAIN_PATH = 'stage1_train/'
TEST_PATH = 'stage1_test/'5: Đọc tất cả các hình ảnh có trong Thư mục con
train_ids = next(os.walk(TRAIN_PATH))[1]
test_ids = next(os.walk(TEST_PATH))[1]6: Đào tạo
X_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
Y_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool)7: Thay đổi kích thước hình ảnh
print('Resizing training images and masks')
for n, id_ in tqdm(enumerate(train_ids), total=len(train_ids)): path = TRAIN_PATH + id_ img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS] img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True) X_train[n] = img #Fill empty X_train with values from img mask = np.zeros((IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool) for mask_file in next(os.walk(path + '/masks/'))[2]: mask_ = imread(path + '/masks/' + mask_file) mask_ = np.expand_dims(resize(mask_, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True), axis=-1) mask = np.maximum(mask, mask_) Y_train[n] = mask 8: Kiểm tra hình ảnh
# test images
X_test = np.zeros((len(test_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
sizes_test = []
print('Resizing test images') for n, id_ in tqdm(enumerate(test_ids), total=len(test_ids)): path = TEST_PATH + id_ img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS] sizes_test.append([img.shape[0], img.shape[1]]) img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True) X_test[n] = img print('Done!')9: Kiểm tra hình ảnh ngẫu nhiên
image_x = random.randint(0, len(train_ids))
imshow(X_train[image_x])
plt.show()
imshow(np.squeeze(Y_train[image_x]))
plt.show()10: Xây dựng mô hình
inputs = tf.keras.layers.Input((IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS))
s = tf.keras.layers.Lambda(lambda x: x / 255)(inputs)11: Đường dẫn
#Contraction path
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(s)
c1 = tf.keras.layers.Dropout(0.1)(c1)
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c1)
p1 = tf.keras.layers.MaxPooling2D((2, 2))(c1) c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p1)
c2 = tf.keras.layers.Dropout(0.1)(c2)
c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c2)
p2 = tf.keras.layers.MaxPooling2D((2, 2))(c2) c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p2)
c3 = tf.keras.layers.Dropout(0.2)(c3)
c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c3)
p3 = tf.keras.layers.MaxPooling2D((2, 2))(c3) c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p3)
c4 = tf.keras.layers.Dropout(0.2)(c4)
c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c4)
p4 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(c4) c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p4)
c5 = tf.keras.layers.Dropout(0.3)(c5)
c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c5)12: Đường mở rộng
u6 = tf.keras.layers.Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(c5)
u6 = tf.keras.layers.concatenate([u6, c4])
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u6)
c6 = tf.keras.layers.Dropout(0.2)(c6)
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c6) u7 = tf.keras.layers.Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(c6)
u7 = tf.keras.layers.concatenate([u7, c3])
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u7)
c7 = tf.keras.layers.Dropout(0.2)(c7)
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c7) u8 = tf.keras.layers.Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(c7)
u8 = tf.keras.layers.concatenate([u8, c2])
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u8)
c8 = tf.keras.layers.Dropout(0.1)(c8)
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c8) u9 = tf.keras.layers.Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same')(c8)
u9 = tf.keras.layers.concatenate([u9, c1], axis=3)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u9)
c9 = tf.keras.layers.Dropout(0.1)(c9)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c9)13: Đầu ra
outputs = tf.keras.layers.Conv2D(1, (1, 1), activation='sigmoid')(c9)14: Tóm tắt
model = tf.keras.Model(inputs=[inputs], outputs=[outputs])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()15: Điểm kiểm tra mô hình
checkpointer = tf.keras.callbacks.ModelCheckpoint('model_for_nuclei.h5', verbose=1, save_best_only=True) callbacks = [ tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'), tf.keras.callbacks.TensorBoard(log_dir='logs')] results = model.fit(X_train, Y_train, validation_split=0.1, batch_size=16, epochs=25, callbacks=callbacks)16: Giai đoạn cuối – Dự đoán
idx = random.randint(0, len(X_train)) preds_train = model.predict(X_train[:int(X_train.shape[0]*0.9)], verbose=1)
preds_val = model.predict(X_train[int(X_train.shape[0]*0.9):], verbose=1)
preds_test = model.predict(X_test, verbose=1) preds_train_t = (preds_train > 0.5).astype(np.uint8)
preds_val_t = (preds_val > 0.5).astype(np.uint8)
preds_test_t = (preds_test > 0.5).astype(np.uint8) # Perform a sanity check on some random training samples
ix = random.randint(0, len(preds_train_t))
imshow(X_train[ix])
plt.show()
imshow(np.squeeze(Y_train[ix]))
plt.show()
imshow(np.squeeze(preds_train_t[ix]))
plt.show() # Perform a sanity check on some random validation samples
ix = random.randint(0, len(preds_val_t))
imshow(X_train[int(X_train.shape[0]*0.9):][ix])
plt.show()
imshow(np.squeeze(Y_train[int(Y_train.shape[0]*0.9):][ix]))
plt.show()
imshow(np.squeeze(preds_val_t[ix]))
plt.show()Kết luận
Trong bài đăng blog toàn diện này, chúng tôi đã đề cập đến kiến trúc UNET để phân đoạn ảnh. Bằng cách giải quyết các hạn chế của các phương pháp trước đó, kiến trúc UNET đã cách mạng hóa việc phân đoạn ảnh. Các tuyến mã hóa và giải mã, bỏ qua kết nối và các sửa đổi khác của nó, chẳng hạn như U-Net++, U-Net chú ý và U-Net dày đặc, đã được chứng minh là có hiệu quả cao trong việc nắm bắt ngữ cảnh, duy trì thông tin không gian và tăng cường độ chính xác của phân đoạn. Khả năng phân đoạn chính xác và tự động với UNET cung cấp các lộ trình mới để cải thiện thị giác máy tính và hơn thế nữa. Chúng tôi khuyến khích độc giả tìm hiểu thêm về UNET và thử nghiệm triển khai nó để tối đa hóa tiện ích của nó trong các dự án phân đoạn ảnh của họ.
Chìa khóa chính
1. Phân đoạn hình ảnh là điều cần thiết trong các tác vụ thị giác máy tính, cho phép phân chia hình ảnh thành các vùng hoặc đối tượng có ý nghĩa.
2. Các cách tiếp cận truyền thống để phân đoạn ảnh, chẳng hạn như chú thích thủ công và phân loại theo pixel, có những hạn chế về hiệu quả và độ chính xác.
3. Phát triển kiến trúc UNET để giải quyết những hạn chế này và đạt được kết quả phân đoạn chính xác.
4. Đây là mạng thần kinh tích chập hoàn toàn (FCN) kết hợp đường dẫn mã hóa để nắm bắt các tính năng cấp cao và phương pháp giải mã để tạo mặt nạ phân đoạn.
5. Bỏ qua các kết nối trong UNET bảo toàn thông tin không gian, tăng cường truyền bá tính năng và cải thiện độ chính xác của phân đoạn.
6. Tìm thấy các ứng dụng thành công trong hình ảnh y tế, phân tích hình ảnh vệ tinh và kiểm soát chất lượng công nghiệp, đạt được các tiêu chuẩn đáng chú ý và được công nhận trong các cuộc thi.
Những câu hỏi thường gặp
A. Kiến trúc U-Net là kiến trúc mạng thần kinh tích chập (CNN) phổ biến, phổ biến cho các tác vụ phân đoạn hình ảnh. Ban đầu được phát triển để phân đoạn hình ảnh y sinh, kể từ đó nó đã tìm thấy các ứng dụng trong nhiều lĩnh vực khác nhau. Kiến trúc U-Net xử lý thông tin cục bộ và toàn cầu và có cấu trúc bộ mã hóa-giải mã hình chữ U.
A. Kiến trúc U-Net bao gồm một đường dẫn bộ mã hóa và một đường dẫn giải mã. Đường dẫn bộ mã hóa giảm dần kích thước không gian của hình ảnh đầu vào đồng thời tăng số lượng kênh đặc trưng. Điều này giúp trích xuất các tính năng trừu tượng và cấp cao. Đường dẫn bộ giải mã thực hiện các hoạt động lấy mẫu và ghép nối. Và khôi phục các kích thước không gian trong khi giảm số lượng kênh tính năng. Mạng học cách kết hợp các tính năng cấp thấp từ đường dẫn bộ mã hóa với các tính năng cấp cao từ đường dẫn giải mã để tạo mặt nạ phân đoạn.
A. Kiến trúc U-Net cung cấp một số lợi thế cho các tác vụ phân đoạn hình ảnh. Đầu tiên, thiết kế hình chữ U của nó cho phép kết hợp các tính năng cấp thấp và cấp cao, cho phép bản địa hóa các đối tượng tốt hơn. Thứ hai, các kết nối bỏ qua giữa các đường dẫn bộ mã hóa và bộ giải mã giúp bảo toàn thông tin không gian, cho phép phân đoạn chính xác hơn. Cuối cùng, kiến trúc U-Net có số lượng tham số tương đối nhỏ, làm cho nó hiệu quả hơn về mặt tính toán so với các kiến trúc khác.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/08/unet-architecture-mastering-image-segmentation/

