Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.

Giới thiệu
Mỗi Kỹ sư ML và Nhà khoa học Dữ liệu phải hiểu tầm quan trọng của “Điều chỉnh siêu tham số (HPs-T)” trong khi chọn đúng máy / mô hình học sâu và cải thiện hiệu suất của (các) mô hình.
Nói một cách đơn giản, đối với mỗi mô hình học máy, việc lựa chọn mô hình học máy là một bài tập lớn và nó hoàn toàn phụ thuộc vào việc chọn tập hợp các siêu tham số tương đương và tất cả những điều này là không thể thiếu để đào tạo một mô hình. Nó luôn đề cập đến các tham số của mô hình đã chọn và hãy nhớ rằng nó không thể học được từ dữ liệu và nó cần được cung cấp trước khi mô hình đi vào giai đoạn đào tạo, cuối cùng thì hiệu suất của mô hình học máy được cải thiện với mức độ dễ chấp nhận hơn lựa chọn kỹ thuật điều chỉnh và lựa chọn siêu tham số. Mục đích chính của bài viết này là làm cho tất cả các bạn biết về điều chỉnh siêu tham số.
Điều chỉnh siêu tham số về cơ bản được gọi là tinh chỉnh các thông số của mô hình, về cơ bản đây là một quá trình kéo dài.
Trước khi đi vào chi tiết, chúng ta hãy tự hỏi một số câu hỏi tự có giá trị về điều chỉnh siêu thông số, tôi chắc chắn rằng điều này sẽ giúp bạn rất nhiều về từ kỳ diệu này. Cá nhân, tôi đã trải nghiệm điều đó và giải thích nó ở đây.
Hyperparameters là gì? Làm thế nào để khác với tham số mô hình?
Như chúng ta biết rằng có những tham số được học nội bộ từ tập dữ liệu đã cho và bắt nguồn từ tập dữ liệu, chúng được thể hiện trong việc đưa ra dự đoán, phân loại, v.v., Chúng được gọi là Thông số mô hình, và chúng thay đổi theo bản chất của dữ liệu mà chúng tôi không thể kiểm soát điều này vì nó phụ thuộc vào dữ liệu. Như 'm'Và'C'trong phương trình tuyến tính, là giá trị của các hệ số học được từ tập dữ liệu đã cho.
Một số bộ thông số được sử dụng để kiểm soát hành vi của mô hình / thuật toán và có thể điều chỉnh để có được một mô hình ứng biến với hiệu suất tối ưu được gọi là Siêu tham số.
(Các) thuật toán mô hình tốt nhất sẽ lấp lánh nếu lựa chọn tốt nhất của bạn về các tham số Siêu
Vòng đời ML
Nếu bạn hỏi tôi là gì Siêu tham số nói một cách đơn giản, câu trả lời một từ là Cấu hình.
Không cần suy nghĩ nhiều, tôi có thể nói Hyperparameter nhanh là “Tỷ lệ phân chia thử nghiệm tàu (80-20) ” trong mô hình hồi quy tuyến tính đơn giản của chúng tôi.

Hình ảnh được thiết kế bởi tác giả - Shanthababu
VÂNG! bây giờ tôi có thể thấy điều đó, bạn thực sự bắt đầu cảm thấy đâu có thể là HP và nó sẽ tối ưu hóa mô hình như thế nào. Đó là lý do tại sao tôi đã đề cập trước đó bằng ngôn ngữ dễ hiểu, đây là cấu hình các giá trị.
Hãy để tôi đưa ra một ví dụ nữa - Bạn có thể so sánh điều này với việc chọn cài đặt font chữ và của mình kích thước để dễ đọc và rõ ràng hơn trong khi bạn lập tài liệu cho nội dung của mình trở nên hoàn hảo và chính xác.
Quay trở lại với học máy và nhớ lại hồi quy Ridge (Điều hòa L2) và Hồi quy Lasso (Điều hòa L1), Theo thuật ngữ chính quy mà chúng ta sử dụng để có lambda (λ) Ý tôi là Hệ số hình phạt giúp chúng ta có được bề mặt nhẵn thay vì đồ thị không đều.
Thuật ngữ này được sử dụng để đẩy các giá trị của hệ số (β) gần bằng XNUMX về độ lớn, Để biết thêm chi tiết, vui lòng tham khảo các bài viết trước đây của tôi https://www.analyticsvidhya.com/blog/2021/11/study-of-regularization-techniques-of-linear-model-and-its-roles/. Đây không phải là gì ngoài siêu mét.

Hình ảnh được thiết kế bởi tác giả - Shanthababu
Để hiểu rõ hơn và hiểu rõ hơn, đây là một cách biểu diễn cổ điển hơn dành cho bạn.

Từ phương trình trên, bạn có thể hiểu rõ hơn về MÔ HÌNH và THÔNG SỐ HYPER là.
Siêu tham số được cung cấp dưới dạng đối số cho thuật toán mô hình trong quá trình khởi tạo chúng dưới dạng khóa, giá trị và giá trị của chúng được chọn bởi nhà khoa học dữ liệu, người đang xây dựng mô hình ở chế độ lặp lại.
Không gian siêu tham số
Như chúng ta biết rằng có một danh sách các HP cho bất kỳ (các) thuật toán đã chọn nào và công việc của chúng tôi là tìm ra sự kết hợp tốt nhất giữa các HP và để có được kết quả tối ưu bằng cách điều chỉnh chúng một cách chiến lược, quá trình này sẽ cung cấp cho chúng ta nền tảng Không gian siêu tham số và sự kết hợp này dẫn đến việc cung cấp kết quả tối ưu tốt nhất, không nghi ngờ gì nữa, nhưng việc tìm ra combo này không phải là dễ dàng, chúng tôi phải tìm kiếm khắp không gian. Ở đây, mọi kết hợp của giá trị HP đã chọn được cho là “MÔ HÌNH”Và phải đánh giá ngay tại chỗ. Vì lý do này, có hai cách tiếp cận chung để tìm kiếm hiệu quả trong không gian HP là LướiTìm kiếm CV và Tìm kiếm ngẫu nhiên CV. Ở đây CV biểu thị Xác thực chéo.

Hình ảnh được thiết kế bởi tác giả - Shanthababu
Trước khi áp dụng các tùy chọn tìm kiếm nêu trên trên dữ liệu / mô hình, chúng ta phải chia dữ liệu thành 3 bộ khác nhau. Tôi có thể hiểu được tiếng nói tâm trí của bạn, chúng tôi đang chia nhỏ tập dữ liệu thành Luyện tập và Kiểm tra, bây giờ có thêm một bài hát? Vâng, có một lý do chính đáng ở đó, đó là không gì khác ngoài việc ngăn chặn “RÒ RỈ DỮ LIỆU" suốt trong Đào tạo, xác thực và kiểm tra. hãy nhớ rằng chúng ta không nên chạm vào tập dữ liệu thử nghiệm cho đến khi chúng ta chuyển mô hình vào triển khai sản xuất.
Rò rỉ dữ liệu
Tốt! Bây giờ sẽ nhanh chóng hiểu Rò rỉ dữ liệu trong ML là gì, điều này chủ yếu là do không tuân theo một số phương pháp hay nhất được đề xuất trong vòng đời của Khoa học dữ liệu / Học máy. Kết quả
là Rò rỉ dữ liệu, không sao cả, vấn đề ở đây là gì, sau khi thử nghiệm thành công với độ chính xác hoàn hảo, tiếp theo là đào tạo mô hình, sau đó mô hình đã được lên kế hoạch chuyển sang sản xuất. Tại thời điểm này, tất cả đều ổn.
Tuy nhiên, dữ liệu thực tế / thời gian thực được áp dụng cho mô hình này trong môi trường sản xuất, bạn sẽ nhận được điểm kém. Đến lúc này, bạn có thể nghĩ rằng tại sao điều này lại xảy ra và cách khắc phục điều này. Tất cả là do dữ liệu mà chúng tôi chia dữ liệu thành các tập con đào tạo và thử nghiệm. Trong quá trình đào tạo, mô hình có kiến thức về dữ liệu mà mô hình đang cố gắng dự đoán, điều này dẫn đến kết quả dự đoán không chính xác và xấu sau khi mô hình được triển khai vào sản xuất.
Nguyên nhân rò rỉ dữ liệu
- Xử lý trước dữ liệu
- Nguyên nhân gốc rễ chính là thực hiện tất cả các quy trình EDA trước khi tách tập dữ liệu thành thử nghiệm và đào tạo
- Thực hiện chuẩn hóa hoặc thay đổi tỷ lệ đơn giản trên một tập dữ liệu nhất định
- Thực hiện các giá trị Tối thiểu / Tối đa của một đối tượng địa lý
- Xử lý các giá trị bị thiếu mà không cần bảo lưu bài kiểm tra và đào tạo
- Loại bỏ các ngoại lệ và Điểm bất thường trên một tập dữ liệu nhất định
- Áp dụng bộ chia tỷ lệ chuẩn, chia tỷ lệ, khẳng định phân phối chuẩn trên tập dữ liệu đầy đủ

Điểm mấu chốt là, chúng ta nên tránh làm bất cứ điều gì đối với tập dữ liệu đào tạo của mình liên quan đến việc có kiến thức về tập dữ liệu kiểm tra. Vì vậy, mô hình của chúng tôi sẽ hoạt động trong sản xuất như một mô hình tổng quát.
sẽ xem xét các Siêu tham số có sẵn trên các thuật toán khác nhau và cách chúng tôi có thể triển khai tất cả các yếu tố này và tác động đến mô hình.
Các bước để thực hiện điều chỉnh siêu tham số
- Chọn loại mô hình phù hợp.
- Xem lại danh sách các thông số của mô hình và xây dựng không gian HP
- Tìm các phương pháp tìm kiếm không gian siêu tham số
- Áp dụng phương pháp tiếp cận lược đồ xác thực chéo
- Đánh giá điểm mô hình để đánh giá mô hình

Hình ảnh được thiết kế bởi tác giả - Shanthababu
Bây giờ, đã đến lúc thảo luận về một vài Hyperparameters và ảnh hưởng của chúng đối với mô hình.
Đào tạo, Thử nghiệm Công cụ Ước tính Phân tách: Với sự trợ giúp của điều này, chúng tôi sử dụng để đặt kích thước thử nghiệm và huấn luyện cho tập dữ liệu đã cho và cùng với trạng thái ngẫu nhiên, đây là các hoán vị để tạo ra cùng một tập hợp các phân tách, nếu không bạn sẽ nhận được một tập thử nghiệm và tập huấn luyện khác, Việc theo dõi mô hình của bạn trong quá trình đánh giá hơi phức tạp hoặc nếu chúng tôi bỏ qua hệ thống này sẽ tạo ra con số này và dẫn đến hành vi không thể đoán trước của mô hình. Trạng thái ngẫu nhiên cung cấp hạt giống, cho trình tạo số ngẫu nhiên, để ổn định mô hình.
train_test_split (X, y, test_size = 0.4, random_state = 0)
Bộ phân loại hồi quy logistic: Tham số C trong Logistic Regression Classifier liên quan trực tiếp đến tham số chính quy λ nhưng tỷ lệ nghịch với C = 1 / λ.
LogisticRegression (C = 1000.0, random_state = 0) LogisticRegression (C = 1000.0, random_state = 0)
Bộ phân loại KNN (k-Hàng xóm gần nhất): Như chúng ta đã biết, thuật toán k-lân cận (KNN) là một phương pháp không tham số được sử dụng cho các bài toán hồi quy và phân loại. Về cơ bản, điều này được sử dụng cho các bài toán phân loại, trong đó số lượng lân cận và tham số công suất
KNeighborsClassifier (n_neighbors = 5, p = 2, metric = 'minkowski')
- n_neighbors là số hàng xóm
- p là Minkowski (tham số sức mạnh)
Nếu p = 1 Tương đương với manhattan_distance,
p = 2. Đối với Euclidean_distance
Hỗ trợ máy phân loại vector
SVC (kernel = 'tuyến tính', C = 1.0, random_state = 0)
- kernel chỉ định loại kernel sẽ được sử dụng trong thuật toán đã chọn,
kernel = 'linear', dành cho Phân loại tuyến tính
kernel = 'rbf' cho Phân loại Không tuyến tính.
C là tham số hình phạt (lỗi)
random_state là một trình tạo số giả ngẫu nhiên
Bộ phân loại cây quyết định
Ở đây, tiêu chí là hàm để đo chất lượng của một phân tách, max_depth là độ sâu tối đa của cây và random_state là hạt giống được sử dụng bởi trình tạo số ngẫu nhiên.
DecisionTreeClassifier (tiêu chí = 'entropy', max_depth = 3, random_state = 0)
Hồi quy Lasso
Lasso (alpha = 0.1) tham số chính quy là alpha.
Phân tích thành phần chính
PCA (n_components = 4)
Bộ phân loại Perceptron
Perceptron (n_iter = 40, eta0 = 0.1, random_state = 0)
- n_iter là số lần lặp lại,
-eta0 là tỷ lệ học tập,
-random_state là trình tạo số ngẫu nhiên.
Ảnh hưởng đến người mẫu
Nhìn chung, Hyperparameters đang ảnh hưởng đến các yếu tố dưới đây trong khi thiết kế mô hình của bạn. Xin hãy nhớ điều này.
- Mô hình tuyến tính
- Mức độ nào của các đối tượng đa thức nên sử dụng?
- Cây quyết định
- Độ sâu tối đa cho phép là bao nhiêu?
- Số lượng mẫu tối thiểu cần thiết tại một nút lá trong cây quyết định là bao nhiêu?
- Rừng ngẫu nhiên
- Chúng ta nên bao gồm bao nhiêu cây?
- Mạng thần kinh
- Chúng ta nên giữ bao nhiêu tế bào thần kinh trong một lớp?
- Có bao nhiêu lớp, nên giữ trong một lớp?
- Xuống dốc
- Chúng ta nên học theo tỷ lệ nào?
Vì vậy, một khi chúng tôi bắt đầu nghĩ đến việc giới thiệu các siêu tham số trong mô hình của mình thì mô hình kiến trúc tổng thể sẽ giống như bên dưới.
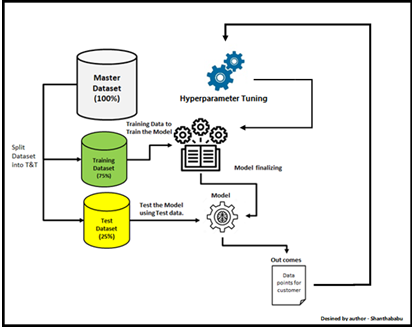
Hình ảnh được thiết kế bởi tác giả - Shanthababu
Kỹ thuật tối ưu hóa siêu tham số
Trong thế giới ML, có rất nhiều kỹ thuật tối ưu hóa Hyperparameter.
- Tìm kiếm thủ công
- Tìm kiếm ngẫu nhiên
- Tìm kiếm lưới
- Giảm một nửa
- Tìm kiếm lưới
- Tìm kiếm ngẫu nhiên
- Điều chỉnh Hyperparameter tự động
- Tối ưu hóa Bayes
- Thuật toán di truyền
- Điều chỉnh mạng thần kinh nhân tạo
- HyperOpt-Sklearn
- Tìm kiếm Bayes

Lưu ý: Khi chúng tôi triển khai các kỹ thuật tối ưu hóa Hyperparameters, chúng tôi cũng phải có các kỹ thuật Cross-Validation trong quy trình vì chúng tôi có thể không bỏ lỡ các kết hợp tốt nhất hoạt động trong các bài kiểm tra và đào tạo.
Tìm kiếm thủ công: Bản thân tên gọi này đã tự giải thích rằng nhà khoa học dữ liệu có thể thực hiện thử nghiệm với các kết hợp khác nhau của các siêu tham số và các giá trị của nó cho mô hình đã chọn thực hiện đào tạo và chọn mô hình tốt nhất với hiệu suất tốt nhất và đi thử nghiệm và chuyển sang triển khai sản xuất . Tất nhiên, những gì bạn nghĩ là hoàn toàn đúng là phương pháp này sẽ tiêu tốn công sức vô cùng.
Hãy thử điều này với một tập dữ liệu đơn giản
# Nhập các gói cần thiết nhập gấu trúc dưới dạng pd từ sklearn.model_selection nhập train_test_split từ sklearn.tree nhập Quyết địnhTreeClassifier từ sklearn.metrics import precision_score df = pd.read_csv ("pima-indians-diab.data.csv")
Khung dữ liệu đã sẵn sàng sau khi tải CSV và các thư viện cần thiết cho các hoạt động tiếp theo
# Phân tách Thử nghiệm Tàu #df = df.drop (['name', 'origin', 'model_year'], axis = 1) y = df ['class'] X = df.drop (['class'], axis = 1) X_train, X_test, y_train, y_test = train_test_split (X, y, test_size = 0.3, random_state = 30)
Huấn luyện và Kiểm tra được thực hiện với việc xác định các biến mục tiêu và phụ thuộc.
Vì chúng tôi đang lên kế hoạch cho tìm kiếm thủ công, tôi đang tạo 3 bộ cho Trình phân loại Quyết định và điều chỉnh mô hình
# bộ siêu tham số tham số_1 = {'tiêu chí': 'gini', 'bộ chia': 'tốt nhất', 'max_depth': 50} params_2 = {'tiêu chí': 'entropy', 'bộ chia': 'ngẫu nhiên', 'max_depth ': 70} params_3 = {' tiêu chí ':' gini ',' bộ chia ':' ngẫu nhiên ',' max_depth ': 60} params_4 = {' tiêu chí ':' entropy ',' bộ chia ':' tốt nhất ',' max_depth ': 80} params_5 = {' criteria ':' gini ',' splitter ':' best ',' max_depth ': 40} # Các mô hình riêng biệt model_1 = Quyết địnhTreeClassifier (** params_1) model_2 = Quyết địnhTreeClassifier (** params_2) model_3 = Quyết địnhTreeClassifier (** params_3) model_4 = Quyết địnhTreeClassifier (** params_4) model_5 = Quyết địnhTreeClassifier (** params_5) model_1.fit (X_train, y_train) model_2.fit (X_train, y_train) model_3.fit (X_train, y_train) model_4.fit (X_train, y_train) X_train, y_train) model_5.fit (X_train, y_train) # Bộ dự đoán preds_1 = model_1.p Dự đoán (X_test) preds_2 = model_3.p Dự đoán (X_test) preds_3 = model_3.p Dự đoán (X_test) preds_4 = model_4.p dự đoán (X_test) preds_5 = model_5 .p Dự đoán (X_test) in (f'Accuracy trên Mô hình 1: {rou nd (precision_score (y_test, preds_1), 3)} ') print (f'Accuracy trên Model 2: {round (precision_score (y_test, preds_2), 3)}') print (f'Accuracy trên Model 3: {round ( precision_score (y_test, preds_3), 3)} ') print (f'Accuracy trên Model 4: {round (precision_score (y_test, preds_4), 3)}') print (f'Accuracy trên Model 5: {round (precision_score ( y_test, preds_5), 3)} ')
Đầu ra
Độ chính xác trên Mẫu 1: 0.693 Độ chính xác trên Mẫu 2: 0.693 Độ chính xác trên Mẫu 3: 0.693 Độ chính xác trên Mẫu 4: 0.736 Độ chính xác trên Mẫu 5: 0.688
Nhìn vào độ chính xác và sự khác biệt của nó với các thông số khác nhau mà chúng tôi đã chuyển qua danh sách. Nhưng đây là một công việc tẻ nhạt và chạy đằng sau một số hoán vị và kết hợp và tìm ra cách tốt nhất, hy vọng bạn có thể hiểu được nỗi đau và quản lý mã.
Tìm kiếm theo lưới: Để triển khai Grid-Search, chúng tôi có một thư viện Scikit-Learn được gọi là GridSearchCV. Thời gian tính toán sẽ lâu, nhưng nó sẽ giảm bớt các nỗ lực thủ công bằng cách tránh số dòng mã 'n'. Thư viện tự thực hiện các hoạt động tìm kiếm và trả về mô hình hoạt động và điểm số của nó. Trong đó mỗi mô hình được xây dựng cho mỗi hoán vị của một siêu tham số nhất định, bên trong nó sẽ được đánh giá và xếp hạng trên các nếp gấp xác thực chéo đã cho.
Hãy thực hiện điều này với tập dữ liệu đã cho.
Lấy đối tượng KNeighborsClassifier cho hoạt động của tôi.
from sklearn.neighbors import KNeighborsClassifier knn_clf = KNeighborsClassifier ()
Chỉ định Chuyến tàu và Bài kiểm tra của tôi đã tràn vào đối tượng KNN của tôi
knn_clf.fit (X_train, y_train)
Đầu ra
KNeighborsClassifier ()
Nhập các thư viện bắt buộc khác
từ sklearn.metrics nhập precision_score từ sklearn.model_selection nhập GridSearchCV
Xác định một số thư mục cho GridSearchCV và gán TT.
gs = GridSearchCV (knn_clf, param_grid, cv = 10) gs.fit (X_train, y_train)
Chuẩn bị danh sách các siêu tham số cho các hành động tiếp theo của tôi với 4 thuật toán khác nhau
param_grid = {'n_neighbors': list (range (1,9)), 'math': ('auto', 'ball_tree', 'kd_tree', 'brute')}
Đầu ra
GridSearchCV (cv = 10, ước lượng = KNeighborsClassifier (), param_grid = {'giải thuật': ('auto', 'ball_tree', 'kd_tree', 'brute'), 'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8]})
Chúng tôi sẽ in tất cả 4 thuật toán cho 8 tập con.
gs.cv_results _ ['params']
Đầu ra 32 kết hợp
[{'giải thuật': 'tự động', 'n_neighbors': 1}, {'giải thuật': 'tự động', 'n_neighbors': 2}, {'thuật toán': 'tự động', 'n_neighbors': 3}, { 'thuật toán': 'tự động', 'n_neighbors': 4}, {'thuật toán': 'tự động', 'n_neighbors': 5}, {'thuật toán': 'tự động', 'n_neighbors': 6}, {'thuật toán ':' auto ',' n_neighbors ': 7}, {' math ':' auto ',' n_neighbors ': 8}, {' math ':' ball_tree ',' n_neighbors ': 1}, {' giải thuật ': 'ball_tree', 'n_neighbors': 2}, {'giải thuật': 'ball_tree', 'n_neighbors': 3}, {'giải thuật': 'ball_tree', 'n_neighbors': 4}, {'giải thuật': 'ball_tree ',' n_neighbors ': 5}, {' giải thuật ':' ball_tree ',' n_neighbors ': 6}, {' giải thuật ':' ball_tree ',' n_neighbors ': 7}, {' giải thuật ':' ball_tree ', 'n_neighbors': 8}, {'giải thuật': 'kd_tree', 'n_neighbors': 1}, {'giải thuật': 'kd_tree', 'n_neighbors': 2}, {'thuật toán': 'kd_tree', 'n_neighbors ': 3}, {' giải thuật ':' kd_tree ',' n_neighbors ': 4}, {' giải thuật ':' kd_tree ',' n_neighbors ': 5}, {' giải thuật ':' kd_tree ',' n_neighbors ': 6}, {'giải thuật': 'kd_tree', 'n_neighbors':7}, {'giải thuật': 'kd_tree', 'n_neighbors': 8}, {'giải thuật': 'brute', 'n_neighbors': 1}, {'giải thuật': 'brute', 'n_neighbors': 2} , {'giải thuật': 'brute', 'n_neighbors': 3}, {'giải thuật': 'brute', 'n_neighbors': 4}, {'giải thuật': 'brute', 'n_neighbors': 5}, { 'giải thuật': 'brute', 'n_neighbors': 6}, {'giải thuật': 'brute', 'n_neighbors': 7}, {'giải thuật': 'brute', 'n_neighbors': 8}]
Hãy lấy tham số tốt nhất từ danh sách
gs.best_params_
Đầu ra
{'giải thuật': 'tự động', 'n_neighbors': 6}
Theo quy trình Xác thực chéo, sẽ tìm ra giá trị trung bình và nhận được kết quả
gs.cv_results _ ['mean_test_score']
Đầu ra
mảng ([0.68134172, 0.71701607, 0.71331237, 0.71509434, 0.72075472, 0.73944794, 0.72085954, 0.73392732, 0.68134172, 0.71701607, 0.71331237, 0.71509434, 0.72075472, 0.73944794, 0.72085954, 0.73392732, 0.68134172, 0.71701607, 0.71331237, 0.71509434, 0.72075472, 0.73944794, 0.72085954, 0.73392732 , 0.68134172, 0.71701607, 0.71331237, 0.71509434, 0.72075472, 0.73944794, 0.72085954, 0.73392732])
Tốt rồi. cái nào có độ chính xác tốt nhất từ danh sách trên, điều này thật đơn giản, chúng tôi đã tìm thấy tham số tốt nhất từ danh sách là {'math': 'auto', 'n_neighbors': 6}, Vì vậy, hãy so sánh 32 sự kết hợp của các tham số khác nhau và danh sách độ chính xác. câu trả lời này là 0.73944794. là giá trị cao nhất trong danh sách và đây là độ chính xác TỐT NHẤT của mô hình đào tạo.
Độ chính xác tốt nhất từ đào tạo
print (gs.score (X_test, y_test))
Đầu ra
0.70129870
Tìm kiếm ngẫu nhiên: Sản phẩm Tìm kiếm lưới một mà chúng ta đã thảo luận ở trên thường làm tăng độ phức tạp về quy trình tính toán, Vì vậy, đôi khi GS được coi là không hiệu quả vì nó thử tất cả các kết hợp của các siêu tham số đã cho. Nhưng Tìm kiếm ngẫu nhiên được sử dụng để đào tạo các mô hình dựa trên các siêu tham số và kết hợp ngẫu nhiên. rõ ràng, số lượng mô hình đào tạo là cột nhỏ hơn so với tìm kiếm lưới.
Nói một cách dễ hiểu, Trong Tìm kiếm Ngẫu nhiên, trong một lưới nhất định, danh sách các siêu tham số được đào tạo và kiểm tra mô hình của chúng tôi trên sự kết hợp ngẫu nhiên của các siêu tham số đã cho.
Lấy đối tượng RandomForestClassifier cho hoạt động của tôi.
từ sklearn.model_selection nhập RandomizedSearchCV
từ sklearn.ensemble nhập RandomForestClassifier
từ scipy.stats nhập randint dưới dạng sp_randint
Việc chỉ định Chuyến tàu và Bài kiểm tra của tôi đã tràn vào đối tượng RandomForestClassifier của tôi
# build a RandomForestClassifier clf = RandomForestClassifier (n_estimators = 50)
Chỉ định danh sách các tham số và phân phối
param_dist = {"max_depth": [3, None], "max_features": sp_randint (1, 11), "min_samples_split": sp_randint (2, 11), "min_samples_leaf": sp_randint (1, 11), "bootstrap": [Đúng, Sai], "tiêu chí": ["gini", "entropy"]}
Xác định mẫu, phân phối và xác nhận chéo
mẫu = 8 # số mẫu ngẫu nhiên randomCV = RandomizedSearchCV (clf, param_distributions = param_dist, n_iter = samples, cv = 3)
Tất cả các thông số đã được thiết lập và chúng ta hãy thực hiện mô hình phù hợp
randomCV.fit (X, y) print (randomCV.best_params_)
Đầu ra
{'bootstrap': False, 'criteria': 'gini', 'max_depth': 3, 'max_features': 3, 'min_samples_leaf': 7, 'min_samples_split': 8}
Theo quy trình Xác thực chéo, sẽ tìm ra giá trị trung bình và nhận được kết quả
randomCV.cv_results _ ['mean_test_score']
Đầu ra
mảng ([0.73828125, 0.69010417, 0.7578125, 0.75911458, 0.73828125, nan, nan, 0.7421875])
Độ chính xác tốt nhất từ đào tạo
print (randomCV.score (X_test, y_test))
Đầu ra
0.8744588744588745
Bạn có thể có một câu hỏi, bây giờ kỹ thuật nào là tốt nhất để thực hiện. Câu trả lời thẳng thắn là Tìm kiếm ngẫu nhiênCV, hãy xem tại sao?
Nghiên cứu so sánh của GridSearchCV và RandomSearshCV
| LướiTìm kiếmCV |
Tìm kiếm ngẫu nhiênCV |
| Lưới được xác định rõ ràng | Lưới không được xác định rõ |
| Giá trị rời rạc cho HP-params | Giá trị Continuos và phân phối thống kê |
| Kích thước xác định cho không gian Hyperparameter | Không có hạn chế như vậy |
| Lựa chọn của sự kết hợp tốt nhất từ HP-Space | Nhận các mẫu từ HP-Space |
| Các mẫu không được tạo | Các mẫu được tạo và chỉ định bởi phạm vi và n_iter |
| Hiệu suất thấp hơn RSCV | Hiệu suất và kết quả tốt hơn |
| Quy trình có hướng dẫn để tìm kiếm sự kết hợp tốt nhất | Bản thân cái tên đã nói lên điều đó, không cần hướng dẫn. |
Biểu diễn hình ảnh đòn sẽ cho bạn hiểu rõ nhất về GridSearchCV và RandomSearshCV.

Kết luận
Các bạn ơi! Cho đến nay, chúng ta đã thảo luận trong một nghiên cứu chi tiết về tầm nhìn Siêu tham số liên quan đến quan điểm Học máy, vui lòng ghi nhớ một số điều trước khi chúng ta đi
- Mỗi mô hình có một tập hợp các siêu tham số, vì vậy chúng tôi đã chọn chúng một cách cẩn thận và tinh chỉnh chúng trong quá trình điều chỉnh siêu tham số. Ý tôi là xây dựng không gian HP.
- Tất cả các siêu tham số KHÔNG quan trọng như nhau và không có quy tắc xác định cho việc này. cố gắng sử dụng các giá trị liên tục thay vì các giá trị rời rạc.
- Đảm bảo sử dụng K-Fold trong khi sử dụng điều chỉnh Hyperparameter để tùy chỉnh điều chỉnh hyperparameter và bao phủ của không gian hyperparameter.
- Đi với sự kết hợp tốt hơn cho siêu tham số và xây dựng kết quả mạnh mẽ.
Tôi tin tưởng, bài viết này sẽ giúp bạn hiểu các khái niệm và cách thực hiện tương tự.
Cảm ơn vì đã dành thời gian và sẽ kết nối về các chủ đề khác nhau. Cho đến khi đó, tạm biệt! Chúc mừng! - Shanthababu
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Coinsmart. Sàn giao dịch Bitcoin và tiền điện tử tốt nhất Châu Âu.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. TRUY CẬP MIỄN PHÍ.
- CryptoHawk. Radar Altcoin. Dùng thử miễn phí.
- Nguồn: https://www.analyticsvidhya.com/blog/2022/02/a-comprehensive-guide-on-hyperparameter-tuning-and-its-techniques/

