Giới thiệu
Với sự ra đời của Mô hình ngôn ngữ lớn (LLM), chúng đã thâm nhập vào nhiều ứng dụng, thay thế các mẫu máy biến áp nhỏ hơn như Chứng nhận hoặc Mô hình dựa trên quy tắc trong nhiều Xử lý ngôn ngữ tự nhiên (NLP) nhiệm vụ. LLM rất linh hoạt, có khả năng xử lý các tác vụ như Phân loại văn bản, Tóm tắt, Phân tích tình cảm và Mô hình hóa chủ đề, nhờ được đào tạo trước rộng rãi. Tuy nhiên, bất chấp khả năng rộng rãi của chúng, LLM thường có độ chính xác thấp hơn so với các đối tác nhỏ hơn.
Để giải quyết hạn chế này, một chiến lược hiệu quả là tinh chỉnh các LLM được đào tạo trước để vượt trội trong các nhiệm vụ cụ thể. Tinh chỉnh các mô hình lớn thường mang lại kết quả tối ưu. Đáng chú ý, Gemini của Google, cùng với các mô hình lớn khác, hiện cung cấp cho người dùng khả năng tinh chỉnh các mô hình này bằng dữ liệu đào tạo của riêng họ. Trong hướng dẫn này, chúng tôi sẽ hướng dẫn quy trình tinh chỉnh mô hình Gemini cho các vấn đề cụ thể cũng như cách quản lý tập dữ liệu bằng cách sử dụng tài nguyên từ HuggingFace.
Mục tiêu học tập
- Hiểu hiệu suất của các mô hình Gemini của Google.
- Tìm hiểu Chuẩn bị tập dữ liệu để tinh chỉnh mô hình Gemini.
- Định cấu hình các tham số để tinh chỉnh mô hình Gemini.
- Theo dõi tiến độ và số liệu tinh chỉnh.
- Kiểm tra hiệu suất của mô hình Gemini trên dữ liệu mới.
- Khám phá các ứng dụng mô hình Gemini để tạo mặt nạ PII.

Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Google công bố điều chỉnh Gemini
Gemini có hai phiên bản: Pro và Ultra. Ở phiên bản Pro có Gemini 1.0 Pro và Gemini 1.5 Pro mới. Các mô hình này của Google cạnh tranh với các mô hình tiên tiến khác như ChatGPT và Claude. Mọi người đều có thể dễ dàng truy cập các mô hình Gemini thông qua giao diện người dùng AI Studio và API miễn phí.
Gần đây, Google đã công bố một tính năng mới dành cho các mẫu Gemini: tinh chỉnh. Điều này có nghĩa là bất kỳ ai cũng có thể điều chỉnh mô hình Gemini cho phù hợp với nhu cầu của mình. Bạn có thể tinh chỉnh Gemini bằng giao diện người dùng AI Studio hoặc API của họ. Tinh chỉnh là khi chúng ta cung cấp dữ liệu của riêng mình cho Song Tử để nó có thể hoạt động theo cách chúng ta muốn. Google sử dụng Điều chỉnh hiệu quả tham số (PET) để nhanh chóng điều chỉnh một số phần quan trọng của mô hình Gemini, giúp mô hình này trở nên hữu ích cho các tác vụ khác nhau.
Chuẩn bị tập dữ liệu
Trước khi bắt đầu tinh chỉnh mô hình, chúng ta sẽ bắt đầu cài đặt các thư viện cần thiết. Nhân tiện, chúng tôi sẽ làm việc với Colab để thực hiện hướng dẫn này.
Cài đặt các thư viện cần thiết
Sau đây là các mô-đun Python cần thiết để bắt đầu:
!pip install -q google-generativeai datasets- google-generativeai: Đó là một thư viện của nhóm Google cho phép chúng tôi truy cập Mô hình Google Gemini. Bạn có thể sử dụng cùng một thư viện để hoàn thiện Mô hình Song Tử.
- bộ dữ liệu: Đây là thư viện từ HuggingFace mà chúng ta có thể sử dụng để tải xuống nhiều tập dữ liệu khác nhau từ trung tâm HuggingFace. Chúng tôi sẽ làm việc với thư viện bộ dữ liệu này để tải xuống bộ dữ liệu PII (Thông tin nhận dạng cá nhân) và cung cấp cho Mô hình Gemini để Tinh chỉnh.
Việc chạy đoạn mã sau sẽ tải xuống và cài đặt thư viện Google Generative AI và Bộ dữ liệu trong Môi trường Python của chúng tôi.
Thiết lập OAuth
Trong bước tiếp theo, chúng ta cần thiết lập OAuth cho hướng dẫn này. OAuth là cần thiết để dữ liệu chúng tôi gửi tới Google để Tinh chỉnh Gemini được an toàn. Để có được OAuth, hãy làm theo điều này Link. Sau đó tải xuống client_secret.json sau khi tạo OAuth. Lưu nội dung của client_secrent.json trong Colab Secrets dưới tên CLIENT_SECRET và chạy mã bên dưới:
import os
if 'COLAB_RELEASE_TAG' in os.environ:
from google.colab import userdata
import pathlib
pathlib.Path('client_secret.json').write_text(userdata.get('CLIENT_SECRET'))
# Use `--no-browser` in colab
!gcloud auth application-default login --no-browser
--client-id-file client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'
else:
!gcloud auth application-default login --client-id-file
client_secret.json --scopes=
'https://www.googleapis.com/auth/cloud-platform,
https://www.googleapis.com/auth/generative-language.tuning'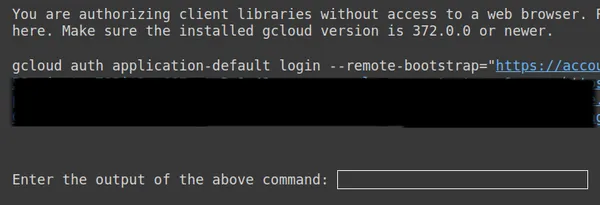
Ở trên, sao chép liên kết thứ hai và dán nó vào hệ thống cục bộ CMD của bạn và chạy nó.
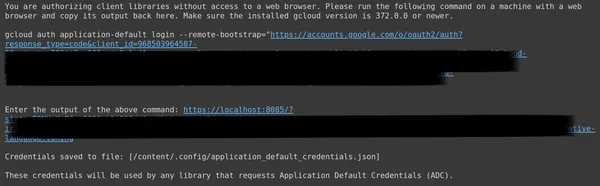
Sau đó, bạn sẽ được chuyển hướng đến Trình duyệt web để đăng nhập bằng email mà bạn đã thiết lập OAuth. Sau khi đăng nhập vào CMD chúng ta nhận được một URL, bây giờ dán URL đó vào dòng thứ 3 rồi nhấn enter. Bây giờ chúng ta đã hoàn tất việc thực hiện OAuth với Google.
Tải xuống và chuẩn bị bộ dữ liệu
Đầu tiên, chúng tôi sẽ bắt đầu bằng cách tải xuống tập dữ liệu mà chúng tôi sẽ làm việc để điều chỉnh nó cho phù hợp với Mô hình Song Tử. Để làm điều này, chúng tôi làm việc với thư viện bộ dữ liệu. Mã cho việc này sẽ là:
from datasets import load_dataset
dataset = load_dataset("ai4privacy/pii-masking-200k")
print(dataset)- Ở đây chúng ta bắt đầu bằng cách nhập hàm Load_dataset từ thư viện bộ dữ liệu.
- Đối với hàm Load_dataset() này, chúng tôi chuyển vào tập dữ liệu mà chúng tôi muốn tải xuống. Ở đây, trong ví dụ của chúng tôi, đó là “ai4privacy/pii-masking-200k”, chứa 200 nghìn hàng dữ liệu PII được che và không được che.
- Sau đó chúng tôi in tập dữ liệu.

Chúng tôi thấy rằng tập dữ liệu chứa 209261 hàng dữ liệu huấn luyện và không có dữ liệu kiểm tra. Và mỗi hàng chứa các cột khác nhau như Masked_text, unmasked_text, Privacy_mask, span_labels, bio_labels và tokenised_text. Dữ liệu mẫu được đề cập dưới đây:
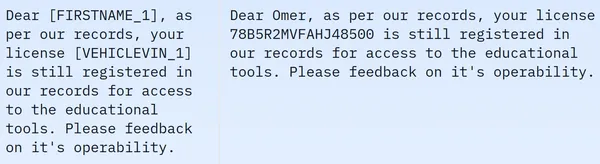
Trong hình ảnh hiển thị, chúng ta quan sát cả câu có mặt nạ và câu không có mặt nạ. Cụ thể, trong câu bị che, một số thành phần nhất định như tên người và số xe bị che khuất bởi các thẻ cụ thể. Để chuẩn bị dữ liệu cho quá trình xử lý tiếp theo, bây giờ chúng ta cần thực hiện một số quá trình tiền xử lý dữ liệu. Dưới đây là mã cho bước tiền xử lý này:
df = dataset['train'].to_pandas()
df = df[['unmasked_text','masked_text']][:2000]
df.columns = ['input','output']
- Đầu tiên, chúng tôi lấy phần đào tạo của dữ liệu từ tập dữ liệu (tập dữ liệu chúng tôi đã tải xuống chỉ chứa phần đào tạo). Sau đó, chúng tôi chuyển đổi nó thành Pandas Dataframe.
- Ở đây để tinh chỉnh Gemini, chúng ta chỉ cần cột unmasked_text và Masked_text, vì vậy chúng ta chỉ lấy hai cột này.
- Sau đó, chúng tôi nhận được 2000 hàng dữ liệu đầu tiên. Chúng tôi sẽ làm việc với 2000 hàng đầu tiên để tinh chỉnh Gemini.
- Sau đó, chúng tôi chỉnh sửa tên cột từ unmasked_text và Masked_text thành cột đầu vào và đầu ra, bởi vì khi chúng tôi cung cấp dữ liệu văn bản đầu vào chứa PII (Thông tin nhận dạng cá nhân) cho Mô hình Gemini, chúng tôi hy vọng nó sẽ tạo ra dữ liệu văn bản đầu ra trong đó PII bị che đậy.
Định dạng dữ liệu để tinh chỉnh Gemini
Bước tiếp theo là định dạng dữ liệu của chúng tôi. Để làm điều này, chúng ta sẽ tạo một hàm định dạng:
def formatter(x):
text = f"""
Given the information below, mask the personal identifiable information.
Input:
{x['input']}
Output:
"""
return text
df['text_input'] = df.apply(formatter,axis=1)
print(df['text_input'][0])- Ở đây chúng ta xác định một trình định dạng hàm, hàm này nhận x, một hàng dữ liệu của chúng ta.
- Sau đó, nó xác định một văn bản biến có chuỗi f, trong đó chúng tôi cung cấp ngữ cảnh, theo sau là dữ liệu đầu vào từ khung dữ liệu.
- Cuối cùng, chúng tôi trả lại văn bản được định dạng.
- Dòng cuối cùng áp dụng hàm định dạng cho từng hàng của khung dữ liệu mà chúng ta đã tạo thông qua hàm apply().
- Trục=1 cho biết rằng hàm sẽ được áp dụng cho từng hàng của khung dữ liệu.
Việc chạy mã sẽ tạo ra một cột mới có tên là "train" chứa văn bản được định dạng cho mỗi hàng bao gồm cả trường đầu vào. Hãy thử quan sát một trong các thành phần của khung dữ liệu:
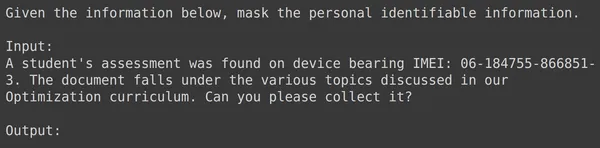
Phân chia dữ liệu thành các tập huấn luyện và thử nghiệm
Chúng ta có thể thấy rằng text_input chứa dữ liệu trong đó mỗi hàng chứa ngữ cảnh khi bắt đầu dữ liệu yêu cầu che giấu PII, sau đó là dữ liệu đầu vào và theo sau là đầu ra Word, nơi mô hình cần tạo đầu ra. Bây giờ chúng ta cần chia khung dữ liệu thành huấn luyện và kiểm tra:
df = df[['text_input','output']]
df_train = df.iloc[:1900,:]
df_test = df.iloc[1900:,:]- Chúng tôi bắt đầu bằng cách lọc dữ liệu sao cho dữ liệu chứa cột text_input và cột đầu ra. Đây là những cột được thư viện Google Fine-Tune mong đợi để huấn luyện Song Tử
- Song Tử sẽ lấy text_input và học cách viết đầu ra
- Chúng tôi chia dữ liệu thành df_train chứa 1900 hàng dữ liệu gốc của chúng tôi
- Và một df_test chứa khoảng 100 hàng dữ liệu gốc
- Chúng tôi huấn luyện Gemini trên df_train và sau đó kiểm tra nó bằng cách lấy 3-4 ví dụ từ df_test để xem kết quả do nó tạo ra
Vì vậy, việc chạy mã sẽ lọc dữ liệu của chúng tôi và chia nó thành huấn luyện và kiểm tra. Cuối cùng, chúng ta đã hoàn thành phần tiền xử lý dữ liệu.
Tinh chỉnh mô hình Song Tử
Hãy làm theo các bước được đề cập bên dưới để tinh chỉnh Mô hình Song Tử của bạn:
Thiết lập thông số điều chỉnh
Trong phần này, chúng ta sẽ thực hiện quá trình Điều chỉnh Mô hình Song Tử. Đối với điều này, chúng tôi sẽ làm việc với đoạn mã sau:
import google.generativeai as genai
bm_name = "models/gemini-1.0-pro-001"
name = 'pii-model'
operation = genai.create_tuned_model(
source_model=bm_name,
training_data=df_train,
id = name,
epoch_count = 2,
batch_size=4,
learning_rate=0.001,
)
- Nhập thư viện google.generativeai: Thư viện này cung cấp API để tương tác với các dịch vụ Generative AI của Google.
- Cung cấp Tên mô hình cơ sở: Đây là tên của mô hình được đào tạo trước mà chúng tôi muốn làm việc với điểm bắt đầu cho mô hình đã tinh chỉnh của chúng tôi. Hiện tại, mô hình có thể điều chỉnh duy nhất là models/gemini-1.0-pro-001, chúng tôi lưu trữ mô hình này trong biến bm_name.
- Cung cấp tên của mô hình đã tinh chỉnh: Đây là tên mà chúng tôi muốn đặt cho mô hình đã tinh chỉnh của mình. Ở đây chúng tôi đặt tên cho nó là “pii-model”.
- Tạo một đối tượng Vận hành Mô hình Điều chỉnh: Đối tượng này thể hiện hoạt động tạo một mô hình đã được tinh chỉnh. Phải có các đối số sau:
- source_model: Tên của Model cơ sở
- Training_data: Dữ liệu huấn luyện cho mô hình tinh chỉnh mà chúng ta vừa tạo là df_train
- id: ID/tên của model đã tinh chỉnh
- epoch_count: Số lượng kỷ nguyên đào tạo. Đối với ví dụ này, chúng tôi sẽ có 2 kỷ nguyên
- batch_size: Kích thước lô để đào tạo. Trong ví dụ này, chúng tôi sẽ sử dụng giá trị 4
- learning_rate: Tỷ lệ học tập cho đào tạo. Ở đây chúng tôi đang cung cấp cho nó giá trị 0.001
- Chúng ta đã hoàn tất việc cung cấp các thông số. Chạy mã này sẽ tạo ra một đối tượng mô hình được tinh chỉnh. Bây giờ chúng ta cần bắt đầu quá trình đào tạo Gemini LLM. Đối với điều này, chúng tôi làm việc với đoạn mã sau.
Vậy là chúng ta đã thiết lập xong các thông số. Chạy mã này sẽ tạo ra một đối tượng mô hình được điều chỉnh. Bây giờ chúng ta cần bắt đầu quá trình đào tạo Gemini LLM. Đối với điều này, chúng tôi làm việc với đoạn mã sau:
model = genai.get_tuned_model(f'tunedModels/{name}')
print(model)Tạo một mô hình điều chỉnh
Ở đây, chúng tôi sử dụng hàm .get_tuned_model() từ thư viện genai, chuyển tên mô hình đã xác định của chúng tôi, bắt đầu quá trình đào tạo. Sau đó, chúng tôi in mô hình, như trong hình bên dưới:
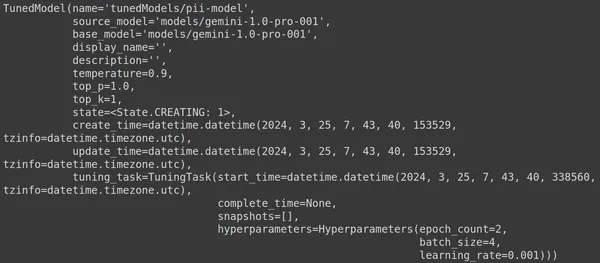
Mô hình thuộc loại TunedModel. Ở đây chúng ta có thể quan sát các tham số khác nhau cho mô hình mà chúng ta đã xác định. Họ đang:
- tên: Biến này chứa tên mà chúng tôi đã cung cấp cho mô hình đã điều chỉnh của mình
- source_model: Đây là mô hình nguồn mà chúng tôi đang tinh chỉnh, trong ví dụ của chúng tôi là models/gemini-1.0-pro
- base_model: Đây lại là mô hình cơ sở mà chúng tôi đang tinh chỉnh, trong ví dụ của chúng tôi là models/Gemini-1.0-pro. Mô hình cơ sở thậm chí có thể là mô hình đã được tinh chỉnh trước đó. Ở đây chúng ta đều giống nhau cho cả hai
- display_name: Tên hiển thị của model đã điều chỉnh
- mô tả: Nó chứa bất kỳ mô tả nào về mô hình của chúng tôi và nội dung của mô hình đó
- nhiệt độ: Giá trị càng cao thì câu trả lời được tạo ra từ Mô hình Ngôn ngữ Lớn càng sáng tạo. Ở đây nó được đặt thành 0.9 theo mặc định
- top_p: Xác định xác suất cao nhất cho việc lựa chọn mã thông báo trong khi tạo văn bản. Top_p càng có nhiều mã thông báo được chọn, tức là mã thông báo được chọn từ mẫu dữ liệu lớn hơn
- top_k: Nó yêu cầu lấy mẫu từ k mã thông báo tiếp theo có khả năng xảy ra nhất ở mỗi bước. Ở đây top_k là 1, ngụ ý rằng mã thông báo tiếp theo có khả năng xảy ra cao nhất là mã thông báo sẽ được chọn, tức là mã thông báo có xác suất cao nhất sẽ luôn được chọn
- state: Trạng thái đang tạo, ngụ ý rằng mô hình hiện đang được tinh chỉnh
- create_time: Thời điểm tạo mô hình
- update_time: Đây là thời điểm mô hình được điều chỉnh lần cuối
- điều chỉnh_task: Chứa các tham số mà chúng tôi đã xác định để điều chỉnh, bao gồm nhiệt độ, kỷ nguyên và kích thước lô
Bắt đầu quá trình đào tạo
Chúng tôi thậm chí có thể lấy trạng thái và siêu dữ liệu của mô hình đã điều chỉnh thông qua mã sau:
print(operation.metadata)
Ở đây nó hiển thị tổng số bước, tức là 950, có thể dự đoán được. Bởi vì trong ví dụ của chúng tôi, chúng tôi có 1900 hàng dữ liệu huấn luyện. Trong mỗi bước, chúng tôi lấy một lô gồm 4, tức là 4 hàng, vì vậy đối với một kỷ nguyên hoàn chỉnh, chúng tôi có 1900/4 tức là 475 bước. Chúng tôi đã đặt 2 kỷ nguyên cho việc đào tạo, ngụ ý rằng 2*475 = 950 bước.
Giám sát tiến độ đào tạo
Đoạn mã bên dưới tạo một thanh trạng thái cho biết bao nhiêu phần trăm quá trình đào tạo đã hoàn thành và thời gian cần thiết để hoàn thành toàn bộ quá trình đào tạo:
import time
for status in operation.wait_bar():
time.sleep(30)
Đoạn mã trên tạo một thanh tiến trình, khi hoàn thành có nghĩa là quá trình điều chỉnh của chúng tôi đã kết thúc.
Trực quan hóa hiệu suất đào tạo
Đối tượng hoạt động thậm chí còn chứa ảnh chụp nhanh của quá trình đào tạo. Rằng nó sẽ chứa các số liệu đánh giá như giá trị trung bình mỗi kỷ nguyên. Chúng ta có thể hình dung điều này bằng đoạn mã sau:
import pandas as pd
import seaborn as sns
model = operation.result()
snapshots = pd.DataFrame(model.tuning_task.snapshots)
sns.lineplot(data=snapshots, x = 'epoch', y='mean_loss')- Ở đây chúng ta có được mô hình điều chỉnh cuối cùng từ Operation.result()
- Khi chúng tôi huấn luyện mô hình, mô hình sẽ chụp ảnh nhanh theo định kỳ. Những ảnh chụp nhanh này chứa dữ liệu như Mean_loss. Do đó, chúng tôi trích xuất ảnh chụp nhanh của mô hình đã điều chỉnh bằng cách gọi model.tuning_task.snapshots
- Chúng tôi tạo một khung dữ liệu từ các ảnh chụp nhanh này bằng cách chuyển các ảnh chụp nhanh đến pd.DataFrame và lưu trữ chúng trong biến ảnh chụp nhanh
- Cuối cùng, chúng tôi tạo một biểu đồ đường từ dữ liệu ảnh chụp nhanh được trích xuất
Chạy mã sẽ dẫn đến biểu đồ sau:
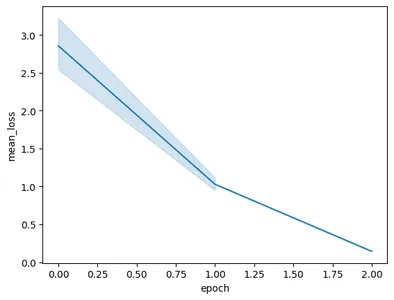
Trong hình ảnh này, chúng ta có thể thấy rằng chúng ta đã giảm tổn thất từ 3 xuống dưới 0.5 chỉ trong 2 kỷ nguyên huấn luyện. Cuối cùng, chúng ta đã hoàn thành việc đào tạo Người mẫu Song Tử
Thử nghiệm Mô hình Song Tử đã được tinh chỉnh
Trong phần này, chúng tôi sẽ kiểm tra mô hình của mình trên dữ liệu thử nghiệm. Bây giờ để làm việc với mô hình đã điều chỉnh, chúng tôi làm việc với đoạn mã sau:
model = genai.GenerativeModel(model_name=f'tunedModels/{name}')Đoạn mã trên sẽ tải mô hình đã điều chỉnh mà chúng tôi vừa đào tạo với dữ liệu Thông tin nhận dạng cá nhân. Bây giờ chúng tôi sẽ thử nghiệm mô hình này với một số ví dụ từ dữ liệu thử nghiệm mà chúng tôi đã bỏ qua. Để làm điều này, hãy in text_input ngẫu nhiên và đầu ra tương ứng của nó từ bộ kiểm tra:
print(df_test['text_input'][1900])
df_test['output'][1900]
Ở trên, chúng ta có thể thấy một text_input ngẫu nhiên và đầu ra được lấy từ bộ kiểm tra. Bây giờ chúng ta sẽ chuyển text_input này cho mô hình và quan sát đầu ra được tạo:
text = df_test['text_input'][1900]
res = model.generate_content(text)
print(res.text)
Chúng tôi thấy rằng mô hình đã thành công trong việc che giấu Thông tin nhận dạng cá nhân cho text_input nhất định và kết quả đầu ra do mô hình tạo ra khớp chính xác với đầu ra từ bộ thử nghiệm. Bây giờ chúng ta hãy thử điều này với một vài ví dụ khác:
print(df_test['text_input'][1969])
print(df_test['output'][1969])
text = df_test['text_input'][1969]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1987])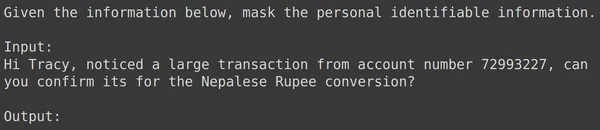
print(df_test['output'][1987])
text = df_test['text_input'][1987]
res = model.generate_content(text)
print(res.text)
print(df_test['text_input'][1933])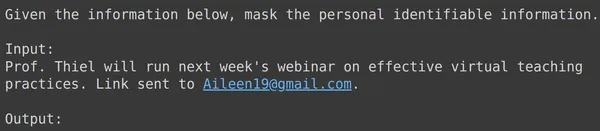
print(df_test['output'][1933])
text = df_test['text_input'][1933]
res = model.generate_content(text)
print(res.text)
Đối với tất cả các ví dụ trên, chúng tôi thấy rằng hiệu suất mô hình tinh chỉnh của chúng tôi là tốt. Mô hình có thể học từ dữ liệu đào tạo nhất định và áp dụng mặt nạ một cách chính xác để ẩn thông tin cá nhân nhạy cảm. Vì vậy, chúng tôi đã thấy từ đầu đến cuối cách tạo tập dữ liệu để tinh chỉnh và cách tinh chỉnh Mô hình Song Tử trên tập dữ liệu và kết quả mà chúng tôi thấy có vẻ rất hứa hẹn đối với một mô hình đã được tinh chỉnh
Kết luận
Tóm lại, hướng dẫn này đã cung cấp hướng dẫn toàn diện về cách tinh chỉnh các mô hình Gemini hàng đầu của Google để che giấu thông tin nhận dạng cá nhân (PII). Chúng tôi bắt đầu bằng cách khám phá bài đăng trên blog của Google về khả năng tinh chỉnh dành cho các mô hình Gemini, nêu bật nhu cầu tinh chỉnh các mô hình này để đạt được độ chính xác theo từng nhiệm vụ cụ thể. Thông qua các bước thực tế được nêu trong hướng dẫn, bao gồm Chuẩn bị tập dữ liệu, tinh chỉnh mô hình Gemini và kiểm tra hiệu suất của nó, người dùng có thể khai thác sức mạnh của các mô hình ngôn ngữ lớn cho các tác vụ che giấu PII.
Dưới đây là những điểm chính từ hướng dẫn này:
- Mô hình Gemini cung cấp một thư viện mạnh mẽ để tinh chỉnh, cho phép người dùng điều chỉnh chúng cho phù hợp với các tác vụ cụ thể, bao gồm cả mặt nạ PII, thông qua Điều chỉnh hiệu quả tham số (PET)
- Chuẩn bị tập dữ liệu là một bước quan trọng, bao gồm việc cài đặt các mô-đun cần thiết, khởi tạo OAuth để bảo mật dữ liệu và định dạng dữ liệu để đào tạo
- Quá trình tinh chỉnh bao gồm việc cung cấp các tham số như Mô hình cơ sở, số lượng kỷ nguyên, kích thước lô và Tốc độ học tập để huấn luyện mô hình Gemini trên Tập dữ liệu đã chuẩn bị
- Việc giám sát tiến trình đào tạo được hỗ trợ thông qua cập nhật trạng thái và trực quan hóa các số liệu như tổn thất trung bình trên mỗi kỷ nguyên
- Việc thử nghiệm mô hình đã tinh chỉnh trên một tập dữ liệu thử nghiệm riêng biệt sẽ xác minh hiệu suất của nó trong việc che giấu PII một cách chính xác trong khi vẫn duy trì tính toàn vẹn của dữ liệu
- Các ví dụ được cung cấp cho thấy tính hiệu quả của mô hình Gemini đã được tinh chỉnh trong việc che giấu thành công thông tin cá nhân nhạy cảm, cho thấy kết quả đầy hứa hẹn cho các ứng dụng trong thế giới thực
Những câu hỏi thường gặp
A. Điều chỉnh hiệu quả tham số (PET) là một trong những kỹ thuật tinh chỉnh chỉ tinh chỉnh một tập hợp nhỏ các tham số của mô hình. Điều này được Google sử dụng để nhanh chóng tinh chỉnh các lớp quan trọng trong mô hình Gemini. Nó điều chỉnh mô hình một cách hiệu quả với dữ liệu của người dùng, cải thiện hiệu suất của nó cho các tác vụ cụ thể
A. Điều chỉnh mô hình Gemini bao gồm việc cung cấp các tham số như tên Mô hình cơ sở, Số lượng kỷ nguyên, Kích thước lô và Tốc độ học tập. Các tham số này ảnh hưởng đến quá trình huấn luyện và cuối cùng ảnh hưởng đến hiệu suất của mô hình
A. Người dùng có thể theo dõi tiến trình đào tạo của mô hình Gemini đã được tinh chỉnh thông qua cập nhật trạng thái, trực quan hóa các số liệu như tổn thất trung bình trên mỗi kỷ nguyên và bằng cách quan sát ảnh chụp nhanh của quá trình đào tạo
A. Trước khi hoàn thiện mô hình Gemini, người dùng cần cài đặt các thư viện cần thiết như google-generativeai và bộ dữ liệu. Ngoài ra, việc khởi tạo OAuth để bảo mật dữ liệu và định dạng tập dữ liệu để đào tạo là những bước quan trọng
A. Mô hình Gemini đã được tinh chỉnh có thể được áp dụng trong các lĩnh vực khác nhau cần che giấu PII, như ẩn danh dữ liệu, bảo vệ quyền riêng tư trong các ứng dụng NLP và tuân thủ các quy định bảo vệ dữ liệu như GDPR
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2024/03/guide-to-fine-tuning-gemini-for-masking-pii-data/

