Giới thiệu
Sự ra đời của AI và học máy đã cách mạng hóa cách chúng ta tương tác với thông tin, giúp việc truy xuất, hiểu và sử dụng thông tin trở nên dễ dàng hơn. Trong hướng dẫn thực hành này, chúng tôi khám phá việc tạo một trợ lý Hỏi & Đáp phức tạp được hỗ trợ bởi LLamA2 và LLamAIndex, tận dụng các mô hình ngôn ngữ và khung lập chỉ mục hiện đại để điều hướng một biển tài liệu PDF một cách dễ dàng. Hướng dẫn này được thiết kế để trao quyền cho các nhà phát triển, nhà khoa học dữ liệu và những người đam mê công nghệ các công cụ và kiến thức để xây dựng Hệ thống Thế hệ tăng cường truy xuất (RAG) đứng trên vai những người khổng lồ trong miền NLP.
Trong nỗ lực làm sáng tỏ việc tạo ra trợ lý Hỏi & Đáp do AI điều khiển, hướng dẫn này đóng vai trò là cầu nối giữa các khái niệm lý thuyết phức tạp và ứng dụng thực tế của chúng trong các tình huống thực tế. Bằng cách tích hợp khả năng hiểu ngôn ngữ nâng cao của LLamA2 với khả năng truy xuất thông tin hiệu quả của LLamAIndex, chúng tôi mong muốn xây dựng một hệ thống trả lời các câu hỏi một cách chính xác và nâng cao hiểu biết của chúng tôi về tiềm năng và thách thức trong lĩnh vực NLP. Bài viết này đóng vai trò như một lộ trình toàn diện dành cho những người đam mê và các chuyên gia, nêu bật sức mạnh tổng hợp giữa các mô hình tiên tiến và nhu cầu ngày càng phát triển của công nghệ thông tin.

Mục tiêu học tập
- Phát triển Hệ thống RAG bằng mô hình LLamA2 từ Ôm mặt.
- Tích hợp nhiều tài liệu PDF.
- Tài liệu chỉ mục để truy xuất hiệu quả.
- Tạo một hệ thống truy vấn.
- Tạo một trợ lý mạnh mẽ có khả năng trả lời các câu hỏi khác nhau.
- Tập trung vào việc thực hiện thực tế hơn là chỉ các khía cạnh lý thuyết.
- Tham gia vào việc viết mã thực hành và các ứng dụng trong thế giới thực.
- Làm cho thế giới phức tạp của NLP có thể tiếp cận và hấp dẫn.
Mục lục
Mô hình LLamA2
LLamA2 là ngọn hải đăng của sự đổi mới trong xử lý ngôn ngữ tự nhiên, vượt qua ranh giới của những gì có thể làm được với các mô hình ngôn ngữ. Kiến trúc của nó, được thiết kế để mang lại cả hiệu suất và hiệu quả, cho phép hiểu biết và tạo ra văn bản giống con người chưa từng có. Không giống như các phiên bản tiền nhiệm như BERT và GPT, LLamA2 cung cấp một cách tiếp cận đa sắc thái hơn để xử lý ngôn ngữ, khiến nó đặc biệt thành thạo trong các nhiệm vụ đòi hỏi sự hiểu biết sâu sắc, chẳng hạn như trả lời câu hỏi. Tiện ích của nó trong các nhiệm vụ NLP khác nhau, từ tóm tắt đến dịch thuật, thể hiện tính linh hoạt và khả năng của nó trong việc giải quyết các thách thức ngôn ngữ phức tạp.

Tìm hiểu LLamAIndex
Lập chỉ mục là xương sống của bất kỳ hệ thống truy xuất thông tin hiệu quả nào. LLamAIndex, một khung được thiết kế để lập chỉ mục và truy vấn tài liệu, nổi bật bằng cách cung cấp một cách liền mạch để quản lý các bộ sưu tập tài liệu khổng lồ. Nó không chỉ là lưu trữ thông tin; đó là về việc làm cho nó có thể truy cập và truy xuất được trong chớp mắt.

Không thể phóng đại tầm quan trọng của LLamAIndex vì nó cho phép xử lý truy vấn theo thời gian thực trên cơ sở dữ liệu mở rộng, đảm bảo rằng trợ lý Hỏi & Đáp của chúng tôi có thể cung cấp phản hồi nhanh chóng và chính xác được rút ra từ cơ sở kiến thức toàn diện.
Token hóa và nhúng
Bước đầu tiên để hiểu các mô hình ngôn ngữ bao gồm việc chia văn bản thành các phần có thể quản lý được, một quá trình được gọi là mã thông báo. Nhiệm vụ cơ bản này rất quan trọng để chuẩn bị dữ liệu cho quá trình xử lý tiếp theo. Sau quá trình mã hóa, khái niệm nhúng phát huy tác dụng, dịch các từ và câu thành các vectơ số.
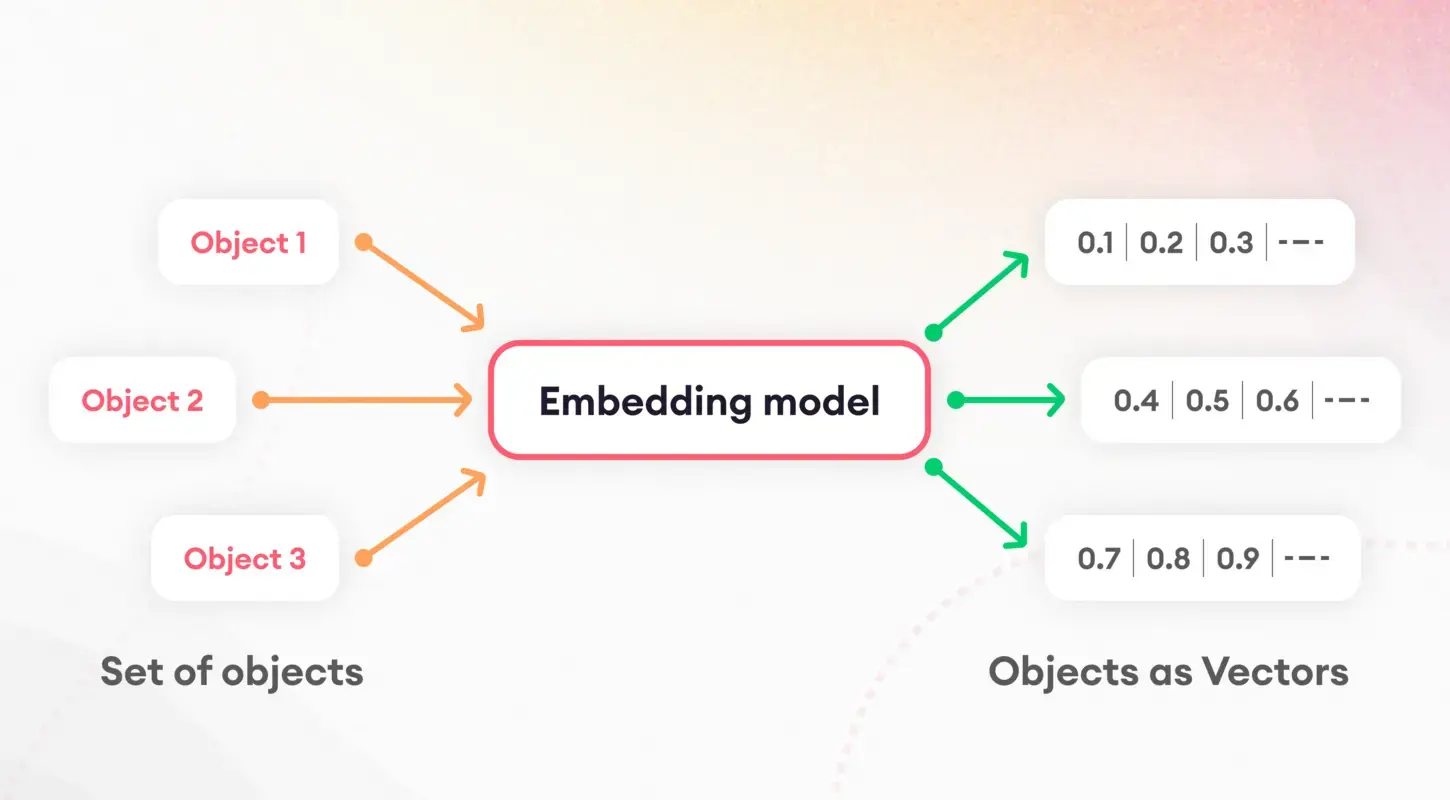
Những phần nhúng này nắm bắt được bản chất của các đặc điểm ngôn ngữ, cho phép các mô hình phân biệt và sử dụng các thuộc tính ngữ nghĩa cơ bản của văn bản. Đặc biệt, việc nhúng câu đóng vai trò then chốt trong các nhiệm vụ như truy xuất và tương tự tài liệu, tạo thành nền tảng cho chiến lược lập chỉ mục của chúng tôi.
Lượng tử hóa mô hình
Lượng tử hóa mô hình trình bày một chiến lược nhằm nâng cao hiệu suất và hiệu quả của trợ lý Hỏi & Đáp của chúng tôi. Bằng cách giảm độ chính xác của các phép tính số của mô hình, chúng ta có thể giảm đáng kể kích thước của mô hình và tăng tốc thời gian suy luận. Mặc dù đưa ra sự cân bằng giữa độ chính xác và hiệu quả, quy trình này đặc biệt có giá trị trong các môi trường hạn chế về tài nguyên như thiết bị di động hoặc ứng dụng web. Thông qua ứng dụng cẩn thận, lượng tử hóa cho phép chúng tôi duy trì mức độ chính xác cao đồng thời hưởng lợi từ việc giảm độ trễ và yêu cầu lưu trữ.
ServiceContext và Công cụ truy vấn
ServiceContext trong LLamAIndex là trung tâm quản lý tài nguyên và cấu hình, đảm bảo hệ thống của chúng tôi hoạt động trơn tru và hiệu quả. Chất keo giữ ứng dụng của chúng ta lại với nhau, cho phép tích hợp liền mạch giữa Mô hình LLamA2, quá trình nhúng và các tài liệu được lập chỉ mục. Mặt khác, công cụ truy vấn là công cụ xử lý các truy vấn của người dùng, tận dụng dữ liệu được lập chỉ mục để tìm nạp thông tin liên quan một cách nhanh chóng. Thiết lập kép này đảm bảo rằng trợ lý Hỏi & Đáp của chúng tôi có thể dễ dàng xử lý các truy vấn phức tạp, cung cấp câu trả lời nhanh chóng và chính xác cho người dùng.
Thực hiện
Hãy đi sâu vào việc thực hiện. Xin lưu ý rằng tôi đã sử dụng Google Colab để tạo dự án này.
!pip install pypdf
!pip install -q transformers einops accelerate langchain bitsandbytes
!pip install sentence_transformers
!pip install llama_indexCác lệnh này thiết lập giai đoạn bằng cách cài đặt các thư viện cần thiết, bao gồm các bộ chuyển đổi để tương tác mô hình và các bộ chuyển đổi câu để nhúng. Việc cài đặt llama_index rất quan trọng đối với khung lập chỉ mục của chúng tôi.
Tiếp theo, chúng tôi khởi tạo các thành phần của mình (Đảm bảo tạo thư mục có tên “dữ liệu” trong phần Tệp trong Google Colab, sau đó tải tệp PDF lên thư mục):
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.prompts.prompts import SimpleInputPrompt
# Reading documents and setting up the system prompt
documents = SimpleDirectoryReader("/content/data").load_data()
system_prompt = """
You are a Q&A assistant. Your goal is to answer questions based on the given documents.
"""
query_wrapper_prompt = SimpleInputPromptSau khi thiết lập môi trường và đọc tài liệu, chúng tôi tạo lời nhắc hệ thống để hướng dẫn phản hồi của mô hình LLamA2. Mẫu này là công cụ đảm bảo đầu ra của mô hình phù hợp với kỳ vọng của chúng tôi về độ chính xác và mức độ liên quan.
!huggingface-cli login
Lệnh trên là một cổng để truy cập vào kho mô hình khổng lồ của Ôm Mặt. Nó yêu cầu một mã thông báo để xác thực.
Bạn cần truy cập vào liên kết sau: Ôm mặt (đảm bảo trước tiên bạn đăng nhập vào Ôm mặt), sau đó tạo Mã thông báo mới, cung cấp Tên cho dự án, chọn Nhập là Đã đọc, sau đó nhấp vào Tạo mã thông báo.
Bước này nhấn mạnh tầm quan trọng của việc bảo mật và cá nhân hóa môi trường phát triển của bạn.
import torch
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=256,
generate_kwargs={"temperature": 0.0, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name="meta-llama/Llama-2-7b-chat-hf",
model_name="meta-llama/Llama-2-7b-chat-hf",
device_map="auto",
model_kwargs={"torch_dtype": torch.float16, "load_in_8bit":True}
)Ở đây, chúng tôi khởi tạo mô hình LLamA2 với các tham số cụ thể được điều chỉnh cho hệ thống Hỏi đáp của chúng tôi. Thiết lập này làm nổi bật tính linh hoạt và khả năng thích ứng của mô hình với các bối cảnh và ứng dụng khác nhau.
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.embeddings.langchain import LangchainEmbedding
embed_model = LangchainEmbedding(
HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2"))Việc lựa chọn mô hình nhúng là rất quan trọng để nắm bắt được bản chất ngữ nghĩa của tài liệu của chúng ta. Bằng cách sử dụng Công cụ chuyển đổi câu, chúng tôi đảm bảo rằng hệ thống của chúng tôi có thể đánh giá chính xác mức độ tương tự và mức độ liên quan của nội dung văn bản, từ đó nâng cao hiệu quả của quy trình lập chỉ mục.
service_context = ServiceContext.from_defaults(
chunk_size=1024,
llm=llm,
embed_model=embed_model
)ServiceContext được khởi tạo bằng các cài đặt mặc định, liên kết mô hình LLamA2 của chúng tôi và nhúng mô hình đó vào một khung gắn kết. Bước này đảm bảo rằng tất cả các thành phần hệ thống được hài hòa và sẵn sàng cho các hoạt động lập chỉ mục và truy vấn.
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()Những dòng này đánh dấu đỉnh cao của quá trình thiết lập của chúng tôi, nơi chúng tôi lập chỉ mục các tài liệu của mình và chuẩn bị công cụ truy vấn. Thiết lập này có vai trò then chốt trong việc chuyển việc chuẩn bị dữ liệu sang thông tin chi tiết hữu ích, cho phép trợ lý Hỏi đáp của chúng tôi trả lời các truy vấn dựa trên nội dung được lập chỉ mục.
response = query_engine.query("Give me a Summary of the PDF in 10 pointers.")
print(response)Cuối cùng, chúng tôi đã kiểm tra hệ thống của mình bằng cách truy vấn nó để tìm các bản tóm tắt và thông tin chi tiết thu được từ bộ sưu tập tài liệu của chúng tôi. Sự tương tác này thể hiện tiện ích thực tế của trợ lý Hỏi & Đáp của chúng tôi và thể hiện sự tích hợp liền mạch của LLamA2, LLamAIndex và cơ sở công nghệ NLP điều đó làm cho nó có thể.
Đầu ra:

Ý nghĩa đạo đức và pháp lý
Việc phát triển các hệ thống Hỏi & Đáp được hỗ trợ bởi AI đặt lên hàng đầu một số cân nhắc về đạo đức và pháp lý. Việc giải quyết những thành kiến tiềm ẩn trong dữ liệu đào tạo là rất quan trọng, cũng như đảm bảo tính công bằng và trung lập trong các phản hồi. Ngoài ra, việc tuân thủ các quy định về quyền riêng tư dữ liệu là điều tối quan trọng vì các hệ thống này thường xử lý thông tin nhạy cảm. Các nhà phát triển phải vượt qua những thách thức này một cách siêng năng và liêm chính, cam kết tuân thủ các nguyên tắc đạo đức nhằm bảo vệ người dùng và tính toàn vẹn của thông tin được cung cấp.
Định hướng và thách thức trong tương lai
Lĩnh vực hệ thống Hỏi đáp đang có rất nhiều cơ hội đổi mới, từ tương tác đa phương thức đến các ứng dụng dành riêng cho từng miền. Tuy nhiên, những tiến bộ này đi kèm với những thách thức riêng, bao gồm việc mở rộng quy mô để phù hợp với bộ sưu tập tài liệu khổng lồ và đảm bảo tính đa dạng trong truy vấn của người dùng. Sự phát triển và cải tiến liên tục của các mô hình như LLamA2 và các khung lập chỉ mục như LLamAIndex là rất quan trọng để vượt qua những rào cản này và mở rộng ranh giới của những gì có thể có trong NLP.
Nghiên cứu điển hình và ví dụ
Việc triển khai các hệ thống Hỏi & Đáp trong thế giới thực, chẳng hạn như bot dịch vụ khách hàng và các công cụ giáo dục, nhấn mạnh tính linh hoạt và tác động của các công nghệ như LLamA2 và LLamAIndex. Những nghiên cứu điển hình này chứng minh các ứng dụng thực tế của AI trong các ngành công nghiệp khác nhau và nêu bật những câu chuyện thành công cũng như bài học kinh nghiệm, cung cấp những hiểu biết sâu sắc có giá trị cho sự phát triển trong tương lai.
Kết luận
Hướng dẫn này đã trình bày tổng quan về cách tạo trợ lý Hỏi & Đáp dựa trên PDF, từ các khái niệm cơ bản về LLamA2 và LLamAIndex cho đến các bước triển khai thực tế. Khi chúng ta tiếp tục khám phá và mở rộng khả năng của AI trong việc truy xuất và xử lý thông tin, tiềm năng biến đổi sự tương tác của chúng ta với kiến thức là vô hạn. Được trang bị những công cụ và hiểu biết sâu sắc này, hành trình hướng tới các hệ thống thông minh và phản ứng nhanh hơn chỉ mới bắt đầu.
Chìa khóa chính
- Cách mạng hóa tương tác thông tin: Việc tích hợp AI và máy học, được minh họa bằng LLamA2 và LLamAIndex, đã thay đổi cách chúng ta truy cập và sử dụng thông tin, mở đường cho các trợ lý Hỏi & Đáp tinh vi có khả năng điều hướng dễ dàng các bộ sưu tập tài liệu PDF khổng lồ.
- Cầu nối thực tế giữa lý thuyết và ứng dụng: Hướng dẫn này thu hẹp khoảng cách giữa các khái niệm lý thuyết và cách triển khai thực tế, trao quyền cho các nhà phát triển và những người đam mê công nghệ xây dựng Hệ thống Thế hệ tăng cường truy xuất (RAG) tận dụng các mô hình NLP và khung lập chỉ mục hiện đại.
- Tầm quan trọng của việc lập chỉ mục hiệu quả: LLamAIndex đóng một vai trò quan trọng trong việc truy xuất thông tin hiệu quả bằng cách lập chỉ mục các bộ sưu tập tài liệu khổng lồ. Điều này đảm bảo phản hồi nhanh chóng và chính xác cho các truy vấn của người dùng, đồng thời nâng cao chức năng tổng thể của trợ lý Hỏi đáp.
- Tối ưu hóa hiệu suất và hiệu quả: Các kỹ thuật như lượng tử hóa mô hình nâng cao hiệu suất và hiệu quả của trợ lý Hỏi đáp, cho phép giảm độ trễ và yêu cầu lưu trữ mà không ảnh hưởng đến độ chính xác.
- Những cân nhắc về đạo đức và định hướng trong tương lai: Việc phát triển hệ thống hỏi đáp được hỗ trợ bởi AI đòi hỏi phải giải quyết các vấn đề liên quan đến đạo đức và pháp lý, bao gồm giảm thiểu thành kiến và quyền riêng tư dữ liệu. Nhìn về phía trước, những tiến bộ trong hệ thống Hỏi & Đáp mang lại cơ hội đổi mới, đồng thời đặt ra những thách thức về khả năng mở rộng và tính đa dạng của các truy vấn của người dùng
Câu hỏi thường gặp
Trả lời. LLamA2 cung cấp một cách tiếp cận đa sắc thái hơn để xử lý ngôn ngữ, cho phép thực hiện các tác vụ hiểu sâu như trả lời câu hỏi. Kiến trúc của nó ưu tiên hiệu suất và hiệu quả, làm cho nó trở nên linh hoạt trong nhiều nhiệm vụ NLP khác nhau.
Trả lời. LLamAIndex là một khuôn khổ để lập chỉ mục và truy vấn tài liệu, tạo điều kiện thuận lợi cho việc xử lý truy vấn theo thời gian thực trên các cơ sở dữ liệu mở rộng. Nó đảm bảo rằng trợ lý hỏi đáp có thể nhanh chóng truy xuất thông tin liên quan từ cơ sở kiến thức toàn diện.
Trả lời. Các phần nhúng, đặc biệt là các phần nhúng câu, nắm bắt được bản chất ngữ nghĩa của nội dung văn bản, cho phép đánh giá chính xác mức độ tương tự và mức độ liên quan. Điều này nâng cao hiệu quả của quá trình lập chỉ mục, cải thiện khả năng của trợ lý trong việc đưa ra các phản hồi phù hợp.
Trả lời. Lượng tử hóa mô hình tối ưu hóa hiệu suất và hiệu quả bằng cách giảm kích thước của các phép tính số, từ đó giảm độ trễ và yêu cầu lưu trữ. Mặc dù đưa ra sự cân bằng giữa độ chính xác và hiệu quả, nhưng nó có giá trị trong môi trường hạn chế về tài nguyên.
Trả lời. Các nhà phát triển phải giải quyết những thành kiến tiềm ẩn trong dữ liệu đào tạo, đảm bảo tính công bằng và trung lập trong phản hồi cũng như tuân thủ các quy định về quyền riêng tư dữ liệu. Việc đề cao các nguyên tắc đạo đức sẽ bảo vệ người dùng và duy trì tính toàn vẹn của thông tin do trợ lý Hỏi đáp cung cấp.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2024/04/a-hands-on-guide-to-creating-a-pdf-based-qa-assistant-with-llama-and-llamaindex/

