Phân tích dữ liệu Amazon Kinesis giúp dễ dàng chuyển đổi và phân tích dữ liệu truyền phát trong thời gian thực.
Trong bài đăng này, chúng tôi thảo luận về lý do AWS khuyến nghị chuyển từ Kinesis Data Analytics cho Ứng dụng SQL sang Phân tích dữ liệu Amazon Kinesis cho Apache Flink để tận dụng các khả năng phát trực tuyến nâng cao của Apache Flink. Chúng tôi cũng trình bày cách sử dụng Kinesis Data Analytics Studio để kiểm tra và điều chỉnh phân tích của bạn trước khi triển khai các ứng dụng đã di chuyển. Nếu bạn không có bất kỳ ứng dụng Kinesis Data Analytics cho SQL nào, thì bài đăng này vẫn cung cấp thông tin cơ bản về nhiều trường hợp sử dụng mà bạn sẽ thấy trong sự nghiệp phân tích dữ liệu của mình và cách các dịch vụ Amazon Data Analytics có thể giúp bạn đạt được mục tiêu của mình.
Kinesis Data Analytics cho Apache Flink là một dịch vụ Apache Flink được quản lý hoàn toàn. Bạn chỉ cần tải tệp JAR hoặc tệp thực thi của ứng dụng lên và AWS sẽ quản lý cơ sở hạ tầng và điều phối công việc Flink. Để đơn giản hóa mọi thứ, Kinesis Data Analytics Studio là một môi trường sổ ghi chép sử dụng Apache Flink và cho phép bạn truy vấn các luồng dữ liệu cũng như phát triển các truy vấn SQL hoặc khối lượng công việc chứng minh khái niệm trước khi mở rộng quy mô ứng dụng của bạn thành sản xuất trong vài phút.
Chúng tôi khuyên bạn nên sử dụng Kinesis Data Analytics cho Apache Flink hoặc Kinesis Data Analytics Studio thay vì Kinesis Data Analytics cho SQL. Điều này là do Kinesis Data Analytics dành cho Apache Flink và Kinesis Data Analytics Studio cung cấp các tính năng xử lý luồng dữ liệu nâng cao, bao gồm ngữ nghĩa xử lý chính xác một lần, khoảng thời gian sự kiện, khả năng mở rộng bằng cách sử dụng hàm do người dùng xác định (UDF) và tích hợp tùy chỉnh, hỗ trợ ngôn ngữ bắt buộc, độ bền cao trạng thái ứng dụng, chia tỷ lệ theo chiều ngang, hỗ trợ nhiều nguồn dữ liệu, v.v. Những điều này rất quan trọng để đảm bảo tính chính xác, đầy đủ, nhất quán và độ tin cậy của quá trình xử lý luồng dữ liệu và không khả dụng với Kinesis Data Analytics cho SQL.
Tổng quan về giải pháp
Đối với trường hợp sử dụng của mình, chúng tôi sử dụng một số dịch vụ AWS để truyền phát, nhập, chuyển đổi và phân tích dữ liệu cảm biến ô tô mẫu trong thời gian thực bằng Kinesis Data Analytics Studio. Kinesis Data Analytics Studio cho phép chúng tôi tạo sổ ghi chép, đây là môi trường phát triển dựa trên web. Với sổ ghi chép, bạn sẽ có được trải nghiệm phát triển tương tác đơn giản kết hợp với các khả năng nâng cao do Apache Flink cung cấp. Kinesis Data Analytics Studio sử dụng Khí cầu Apache như sổ ghi chép, và sử dụng Apache Flash như một công cụ xử lý luồng. Sổ ghi chép Kinesis Data Analytics Studio kết hợp liền mạch các công nghệ này để giúp các nhà phát triển thuộc mọi bộ kỹ năng có thể truy cập phân tích nâng cao trên các luồng dữ liệu. Sổ ghi chép được cung cấp nhanh chóng và cung cấp một cách để bạn xem và phân tích ngay dữ liệu phát trực tuyến của mình. Apache Zeppelin cung cấp cho sổ ghi chép Studio của bạn một bộ công cụ phân tích hoàn chỉnh, bao gồm các công cụ sau:
- Trực quan hóa dữ liệu
- Xuất dữ liệu ra file
- Kiểm soát định dạng đầu ra để phân tích dễ dàng hơn
- Khả năng biến sổ ghi chép thành một ứng dụng sản xuất có thể mở rộng
Không giống như Kinesis Data Analytics cho Ứng dụng SQL, Kinesis Data Analytics cho Apache Flink bổ sung hỗ trợ SQL sau đây:
- Nối luồng dữ liệu giữa nhiều luồng dữ liệu Kinesis hoặc giữa luồng dữ liệu Kinesis và một Truyền trực tuyến được quản lý của Amazon cho Apache Kafka chủ đề (Amazon MSK)
- Trực quan hóa thời gian thực của dữ liệu được chuyển đổi trong luồng dữ liệu
- Sử dụng tập lệnh Python hoặc chương trình Scala trong cùng một ứng dụng
- Thay đổi độ lệch của lớp phát trực tuyến
Một lợi ích khác của Kinesis Data Analytics dành cho Apache Flink là khả năng mở rộng được cải thiện của giải pháp sau khi triển khai, bởi vì bạn có thể mở rộng các tài nguyên cơ bản để đáp ứng nhu cầu. Trong Kinesis Data Analytics cho Ứng dụng SQL, việc mở rộng quy mô được thực hiện bằng cách thêm nhiều máy bơm hơn để thuyết phục ứng dụng thêm nhiều tài nguyên hơn.
Trong giải pháp của mình, chúng tôi tạo sổ ghi chép để truy cập dữ liệu cảm biến ô tô, bổ sung dữ liệu và gửi đầu ra bổ sung từ sổ ghi chép Kinesis Data Analytics Studio tới một Amazon Kinesis Dữ liệu Firehose luồng phân phối để phân phối đến một Dịch vụ lưu trữ đơn giản của Amazon hồ dữ liệu (Amazon S3). Đường ống này có thể tiếp tục được sử dụng để gửi dữ liệu đến Dịch vụ Tìm kiếm Mở của Amazon hoặc các mục tiêu khác để xử lý và trực quan hóa bổ sung.

Kinesis Data Analytics cho Ứng dụng SQL so với Kinesis Data Analytics cho Apache Flink
Trong ví dụ của chúng tôi, chúng tôi thực hiện các hành động sau trên dữ liệu truyền trực tuyến:
- Kết nối với một Luồng dữ liệu Amazon Kinesis dòng dữ liệu.
- Xem dữ liệu luồng.
- Biến đổi và làm giàu dữ liệu.
- Thao tác dữ liệu với Python.
- Truyền lại dữ liệu sang luồng phân phối Firehose.
Để so sánh Kinesis Data Analytics cho Ứng dụng SQL với Kinesis Data Analytics cho Apache Flink, trước tiên hãy thảo luận về cách thức hoạt động của Kinesis Data Analytics cho Ứng dụng SQL.
Cốt lõi của ứng dụng Kinesis Data Analytics cho SQL là khái niệm về luồng trong ứng dụng. Bạn có thể coi luồng trong ứng dụng là một bảng chứa dữ liệu phát trực tuyến để bạn có thể thực hiện các tác vụ trên đó. Luồng trong ứng dụng được ánh xạ tới nguồn phát trực tuyến, chẳng hạn như luồng dữ liệu Kinesis. Để đưa dữ liệu vào luồng trong ứng dụng, trước tiên hãy thiết lập một nguồn trong bảng điều khiển quản lý cho ứng dụng Kinesis Data Analytics cho SQL của bạn. Sau đó, tạo một máy bơm đọc dữ liệu từ luồng nguồn và đặt nó vào bảng. Truy vấn máy bơm chạy liên tục và cung cấp dữ liệu nguồn vào luồng trong ứng dụng. Bạn có thể tạo nhiều máy bơm từ nhiều nguồn để cung cấp luồng trong ứng dụng. Các truy vấn sau đó được chạy trên luồng trong ứng dụng và kết quả có thể được giải thích hoặc gửi đến các đích khác để xử lý hoặc lưu trữ thêm.
SQL sau minh họa việc thiết lập luồng và bơm trong ứng dụng:
CREATE OR REPLACE STREAM "TEMPSTREAM" ( "column1" BIGINT NOT NULL, "column2" INTEGER, "column3" VARCHAR(64)); CREATE OR REPLACE PUMP "SAMPLEPUMP" AS INSERT INTO "TEMPSTREAM" ("column1", "column2", "column3") SELECT STREAM inputcolumn1, inputcolumn2, inputcolumn3
FROM "INPUTSTREAM";Dữ liệu có thể được đọc từ luồng trong ứng dụng bằng truy vấn SQL SELECT:
SELECT *
FROM "TEMPSTREAM"Khi tạo cùng một thiết lập trong Kinesis Data Analytics Studio, bạn sử dụng môi trường Apache Flink cơ bản để kết nối với nguồn phát trực tuyến và tạo luồng dữ liệu trong một câu lệnh bằng trình kết nối. Ví dụ sau đây cho thấy việc kết nối với cùng một nguồn mà chúng tôi đã sử dụng trước đây, nhưng sử dụng Apache Flink:
CREATE TABLE `MY_TABLE` ( "column1" BIGINT NOT NULL, "column2" INTEGER, "column3" VARCHAR(64)
) WITH ( 'connector' = 'kinesis', 'stream' = sample-kinesis-stream', 'aws.region' = 'aws-kinesis-region', 'scan.stream.initpos' = 'LATEST', 'format' = 'json' );MY_TABLE hiện là luồng dữ liệu sẽ liên tục nhận dữ liệu từ luồng dữ liệu Kinesis mẫu của chúng tôi. Nó có thể được truy vấn bằng câu lệnh SQL SELECT:
SELECT column1, column2, column3
FROM MY_TABLE;Mặc dù Kinesis Data Analytics cho Ứng dụng SQL sử dụng một tập con của tiêu chuẩn SQL:2008 với các tiện ích mở rộng để kích hoạt các thao tác trên luồng dữ liệu, Hỗ trợ SQL của Apache Flink được dựa trên Canxit Apache, thực thi tiêu chuẩn SQL.
Điều quan trọng cần đề cập là Kinesis Data Analytics Studio hỗ trợ PyFlink và Scala cùng với SQL trong cùng một sổ ghi chép. Điều này cho phép bạn thực hiện các phương pháp phức tạp, có lập trình trên dữ liệu truyền trực tuyến của mình mà SQL không thể thực hiện được.
Điều kiện tiên quyết
Trong bài tập này, chúng tôi thiết lập các tài nguyên AWS khác nhau và thực hiện các truy vấn phân tích. Để làm theo, bạn cần có tài khoản AWS với quyền truy cập của quản trị viên. Nếu bạn chưa có tài khoản AWS với quyền truy cập của quản trị viên, tạo một thứ ngay bây giờ. Các dịch vụ được nêu trong bài đăng này có thể phát sinh phí đối với tài khoản AWS của bạn. Đảm bảo làm theo hướng dẫn dọn dẹp ở cuối bài đăng này.
Định cấu hình truyền dữ liệu
Trong miền phát trực tuyến, chúng tôi thường được giao nhiệm vụ khám phá, biến đổi và làm phong phú dữ liệu đến từ các cảm biến Internet of Things (IoT). Để tạo dữ liệu cảm biến thời gian thực, chúng tôi sử dụng Trình mô phỏng thiết bị AWS IoT. Trình mô phỏng này chạy trong tài khoản AWS của bạn và cung cấp giao diện web cho phép người dùng khởi chạy các nhóm thiết bị hầu như được kết nối từ mẫu do người dùng xác định, sau đó mô phỏng chúng để xuất bản dữ liệu theo định kỳ lên Lõi AWS IoT. Điều này có nghĩa là chúng ta có thể xây dựng một nhóm thiết bị ảo để tạo dữ liệu mẫu cho bài tập này.
Chúng tôi triển khai Trình mô phỏng thiết bị IoT bằng cách sử dụng như sau Amazon CloudFront mẫu. Nó xử lý việc tạo tất cả các tài nguyên cần thiết trong tài khoản của bạn.
- trên Chỉ định chi tiết ngăn xếp trang, hãy gán tên cho ngăn xếp giải pháp của bạn.
- Theo Thông số, hãy xem lại các tham số cho mẫu giải pháp này và sửa đổi chúng nếu cần.
- Trong Email người dùng, nhập email hợp lệ để nhận liên kết và mật khẩu để đăng nhập vào Giao diện người dùng mô phỏng thiết bị IoT.
- Chọn Sau.
- trên Cấu hình tùy chọn ngăn xếp trang, chọn Sau.
- trên Đánh giá trang, xem lại và xác nhận cài đặt. Chọn các hộp kiểm xác nhận rằng mẫu tạo Quản lý truy cập và nhận dạng AWS (IAM) tài nguyên.
- Chọn Tạo ngăn xếp.
Ngăn xếp mất khoảng 10 phút để cài đặt.
- Khi bạn nhận được email mời, hãy chọn liên kết CloudFront và đăng nhập vào Trình mô phỏng thiết bị IoT bằng thông tin đăng nhập được cung cấp trong email.
Giải pháp chứa một bản demo ô tô dựng sẵn mà chúng tôi có thể sử dụng để bắt đầu phân phối dữ liệu cảm biến một cách nhanh chóng tới AWS.
- trên Loại thiết bị trang, chọn Tạo loại thiết bị.
- Chọn Demo ô tô.
- Tải trọng được điền tự động. Nhập tên cho thiết bị của bạn và nhập
automotive-topicnhư chủ đề.
- Chọn Lưu.
Bây giờ chúng ta tạo một mô phỏng.
- trên Mô phỏng trang, chọn Tạo mô phỏng.
- Trong loại mô phỏng, chọn Demo ô tô.
- Trong Chọn loại thiết bị, hãy chọn thiết bị minh họa mà bạn đã tạo.
- Trong Khoảng thời gian truyền dữ liệu và Thời lượng truyền dữ liệu, hãy nhập các giá trị mong muốn của bạn.
Bạn có thể nhập bất kỳ giá trị nào bạn thích, nhưng sử dụng ít nhất 10 thiết bị truyền cứ sau 10 giây. Bạn sẽ muốn đặt thời lượng truyền dữ liệu của mình thành vài phút hoặc bạn sẽ cần khởi động lại mô phỏng của mình nhiều lần trong phòng thí nghiệm.
- Chọn Lưu.

Bây giờ chúng ta có thể chạy mô phỏng.
- trên Mô phỏng trang, chọn mô phỏng mong muốn và chọn Bắt đầu mô phỏng.
Ngoài ra, hãy chọn Xem bên cạnh mô phỏng bạn muốn chạy, sau đó chọn Bắt đầu để chạy mô phỏng.
- Để xem mô phỏng, chọn Xem bên cạnh mô phỏng mà bạn muốn xem.
Nếu mô phỏng đang chạy, bạn có thể xem bản đồ có vị trí của các thiết bị và tối đa 100 tin nhắn gần đây nhất được gửi đến chủ đề IoT.
Giờ đây, chúng tôi có thể kiểm tra để đảm bảo trình mô phỏng đang gửi dữ liệu cảm biến tới AWS IoT Core.
- Điều hướng đến bảng điều khiển AWS IoT Core.
Đảm bảo rằng bạn đang ở cùng Khu vực mà bạn đã triển khai Trình mô phỏng thiết bị IoT của mình.
- Trong ngăn dẫn hướng, chọn Máy khách thử nghiệm MQTT.
- Nhập bộ lọc chủ đề
automotive-topicVà chọn Theo dõi.
Miễn là bạn đang chạy mô phỏng, các thông báo được gửi đến chủ đề IoT sẽ được hiển thị.

Cuối cùng, chúng ta có thể đặt quy tắc để định tuyến thông báo IoT tới luồng dữ liệu Kinesis. Luồng này sẽ cung cấp dữ liệu nguồn của chúng tôi cho sổ ghi chép Kinesis Data Analytics Studio.
- Trên bảng điều khiển AWS IoT Core, chọn Định tuyến tin nhắn và Nội quy.
- Nhập tên cho quy tắc, chẳng hạn như
automotive_route_kinesis, sau đó chọn Sau.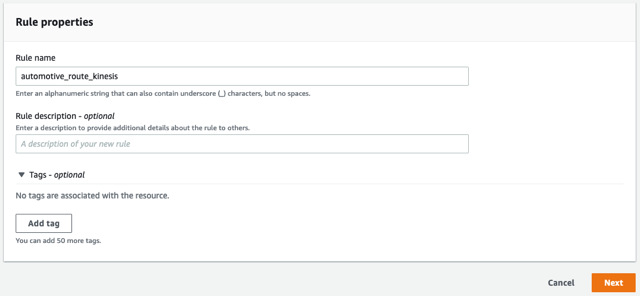
- Cung cấp câu lệnh SQL sau. SQL này sẽ chọn tất cả các cột thông báo từ
automotive-topicTrình mô phỏng thiết bị IoT đang xuất bản:
- Chọn Sau.
- Theo hành động quy tắc, lựa chọn Luồng Kinesis làm nguồn.
- Chọn Tạo Luồng Kinesis mới.
Điều này sẽ mở ra một cửa sổ mới.
- Trong Tên luồng dữ liệu, đi vào
automotive-data.
Chúng tôi sử dụng một luồng được cung cấp cho bài tập này.
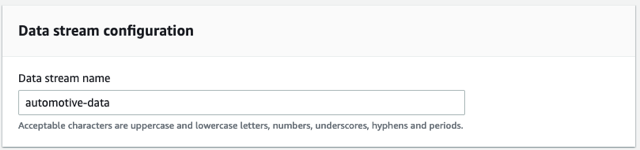
- Chọn Tạo luồng dữ liệu.
Bây giờ, bạn có thể đóng cửa sổ này và quay lại bảng điều khiển AWS IoT Core.
- Chọn nút làm mới bên cạnh Tên luồngvà chọn
automotive-datadòng.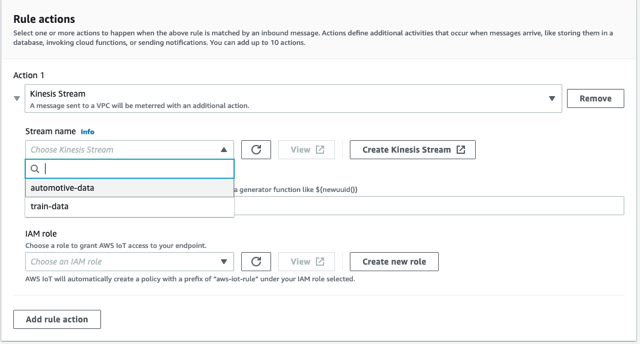
- Chọn Tạo vai trò mới và đặt tên cho vai trò
automotive-role. - Chọn Sau.
- Xem lại các thuộc tính của quy tắc và chọn Tạo.
Quy tắc bắt đầu định tuyến dữ liệu ngay lập tức.
Thiết lập Kinesis Data Analytics Studio
Giờ đây, chúng tôi đã truyền dữ liệu qua AWS IoT Core và vào luồng dữ liệu Kinesis, chúng tôi có thể tạo sổ ghi chép Kinesis Data Analytics Studio của mình.
- Trên bảng điều khiển Amazon Kinesis, chọn Ứng dụng phân tích trong khung điều hướng.
- trên Studio tab, chọn Tạo sổ tay Studio.
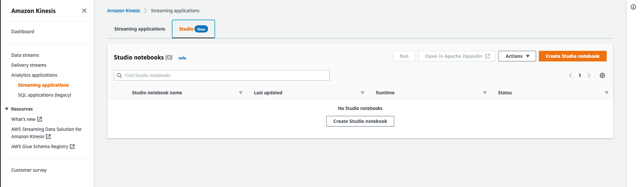
- Rời bỏ Tạo nhanh với mã mẫu đã chọn.
- Đặt tên cho sổ ghi chép
automotive-data-notebook.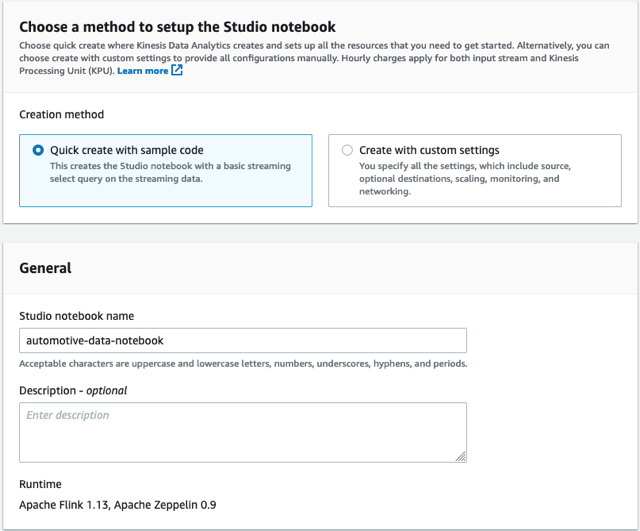
- Chọn Tạo để tạo ra một Keo AWS cơ sở dữ liệu trong một cửa sổ mới.
- Chọn Thêm cơ sở dữ liệu.

- Đặt tên cho cơ sở dữ liệu
automotive-notebook-glue. - Chọn Tạo.
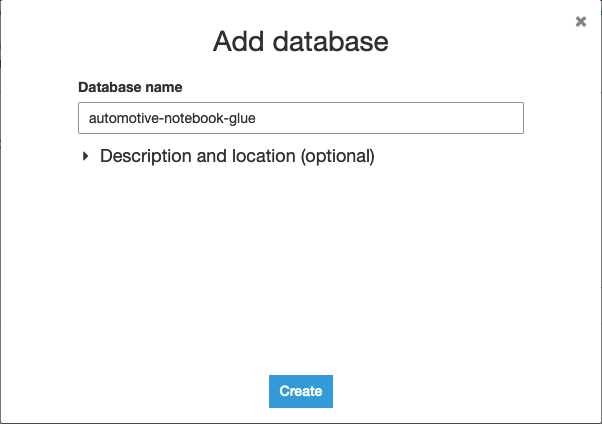
- Quay lại Tạo sổ tay Studio phần.
- Chọn làm mới và chọn cơ sở dữ liệu AWS Glue mới của bạn.
- Chọn Tạo sổ tay Studio.

- Để khởi động sổ ghi chép Studio, hãy chọn chạy Và xác nhận.

- Sau khi sổ ghi chép đang chạy, hãy chọn sổ ghi chép và chọn Mở trong Apache Zeppelin.
- Chọn Ghi chú nhập khẩu.
- Chọn Thêm từ URL.

- Nhập URL sau:
https://aws-blogs-artifacts-public.s3.amazonaws.com/artifacts/BDB-2461/auto-notebook.ipynb. - Chọn Nhập ghi chú.

- Mở ghi chú mới.
Thực hiện phân tích luồng
Trong ứng dụng Kinesis Data Analytics cho SQL, chúng tôi thêm khóa học phát trực tuyến của mình thông qua bảng điều khiển quản lý, sau đó xác định luồng trong ứng dụng và bơm vào luồng dữ liệu từ luồng dữ liệu Kinesis của chúng tôi. Luồng trong ứng dụng hoạt động như một bảng để chứa dữ liệu và cung cấp dữ liệu đó để chúng tôi truy vấn. Máy bơm lấy dữ liệu từ nguồn của chúng tôi và truyền dữ liệu đó tới luồng trong ứng dụng của chúng tôi. Sau đó, các truy vấn có thể được chạy đối với luồng trong ứng dụng bằng cách sử dụng SQL, giống như cách chúng tôi truy vấn bất kỳ bảng SQL nào. Xem đoạn mã sau:
CREATE OR REPLACE STREAM "AUTOSTREAM" ( `trip_id` CHAR(36), `VIN` CHAR(17), `brake` FLOAT, `steeringWheelAngle` FLOAT, `torqueAtTransmission` FLOAT, `engineSpeed` FLOAT, `vehicleSpeed` FLOAT, `acceleration` FLOAT, `parkingBrakeStatus` BOOLEAN, `brakePedalStatus` BOOLEAN, `transmissionGearPosition` VARCHAR(10), `gearLeverPosition` VARCHAR(10), `odometer` FLOAT, `ignitionStatus` VARCHAR(4), `fuelLevel` FLOAT, `fuelConsumedSinceRestart` FLOAT, `oilTemp` FLOAT, `location` VARCHAR(100), `timestamp` TIMESTAMP(3)); CREATE OR REPLACE PUMP "MYPUMP" AS INSERT INTO "AUTOSTREAM" ("trip_id", "VIN", "brake", "steeringWheelAngle", "torqueAtTransmission", "engineSpeed", "vehicleSpeed", "acceleration", "parkingBrakeStatus", "brakePedalStatus", "transmissionGearPosition", "gearLeverPosition", "odometer", "ignitionStatus", "fuelLevel", "fuelConsumedSinceRestart", "oilTemp", "location", "timestamp")
SELECT VIN, brake, steeringWheelAngle, torqueAtTransmission, engineSpeed, vehicleSpeed, acceleration, parkingBrakeStatus, brakePedalStatus, transmissionGearPosition, gearLeverPosition, odometer, ignitionStatus, fuelLevel, fuelConsumedSinceRestart, oilTemp, location, timestamp
FROM "INPUT_STREAM"
Để di chuyển luồng trong ứng dụng và bơm từ ứng dụng Kinesis Data Analytics cho SQL sang Kinesis Data Analytics Studio, chúng tôi chuyển đổi luồng này thành một câu lệnh CREATE duy nhất bằng cách xóa định nghĩa bơm và xác định một kinesis kết nối. Đoạn đầu tiên trong sổ ghi chép Zeppelin thiết lập trình kết nối được trình bày dưới dạng bảng. Chúng tôi có thể xác định các cột cho tất cả các mục trong thư đến hoặc một tập hợp con.

Chạy câu lệnh và kết quả thành công được xuất trong sổ ghi chép của bạn. Bây giờ chúng ta có thể truy vấn bảng này bằng SQL hoặc chúng ta có thể thực hiện các thao tác có lập trình với dữ liệu này bằng PyFlink hoặc Scala.
Trước khi thực hiện phân tích thời gian thực trên dữ liệu phát trực tuyến, hãy xem cách dữ liệu hiện được định dạng. Để thực hiện việc này, chúng tôi chạy một truy vấn Flink SQL đơn giản trên bảng mà chúng tôi vừa tạo. SQL được sử dụng trong ứng dụng phát trực tuyến của chúng tôi giống với những gì được sử dụng trong ứng dụng SQL.

Lưu ý rằng nếu bạn không thấy bản ghi sau vài giây, hãy đảm bảo rằng Trình mô phỏng thiết bị IoT của bạn vẫn đang chạy.
Nếu bạn cũng đang chạy Kinesis Data Analytics cho mã SQL, thì bạn có thể thấy tập hợp kết quả hơi khác. Đây là một điểm khác biệt quan trọng khác trong Kinesis Data Analytics cho Apache Flink, bởi vì Flink của Apache có khái niệm phân phối chính xác một lần. Nếu ứng dụng này được triển khai vào sản xuất và được khởi động lại hoặc nếu xảy ra các hành động thay đổi quy mô, thì Kinesis Data Analytics cho Apache Flink đảm bảo bạn chỉ nhận được mỗi thông báo một lần, trong khi đó, trong ứng dụng Kinesis Data Analytics cho SQL, bạn cần xử lý thêm luồng đến để đảm bảo bạn bỏ qua các tin nhắn lặp lại có thể ảnh hưởng đến kết quả của bạn.
Bạn có thể dừng đoạn hiện tại bằng cách chọn biểu tượng tạm dừng. Bạn có thể thấy một lỗi hiển thị trong sổ ghi chép của mình khi dừng truy vấn, nhưng có thể bỏ qua lỗi đó. Nó chỉ cho bạn biết rằng quá trình đã bị hủy bỏ.

Flink SQL triển khai tiêu chuẩn SQL và cung cấp một cách dễ dàng để thực hiện các phép tính trên dữ liệu luồng giống như khi bạn truy vấn bảng cơ sở dữ liệu. Một nhiệm vụ phổ biến trong khi làm giàu dữ liệu là tạo một trường mới để lưu trữ một phép tính hoặc chuyển đổi (chẳng hạn như từ độ F sang độ C) hoặc tạo dữ liệu mới để cung cấp các truy vấn đơn giản hơn hoặc trực quan hóa được cải thiện ở phía dưới. Chạy đoạn tiếp theo để xem cách chúng ta có thể thêm một giá trị Boolean có tên accelerating, mà chúng ta có thể dễ dàng sử dụng trong bồn rửa của mình để biết liệu một chiếc ô tô hiện đang tăng tốc vào thời điểm cảm biến được đọc. Quy trình ở đây không khác nhau giữa Kinesis Data Analytics cho SQL và Kinesis Data Analytics cho Apache Flink.

Bạn có thể dừng chạy đoạn văn khi bạn đã kiểm tra cột mới, so sánh giá trị Boolean mới của chúng tôi với FLOAT acceleration cột.
Dữ liệu được gửi từ cảm biến thường nhỏ gọn để cải thiện độ trễ và hiệu suất. Có thể làm phong phú luồng dữ liệu bằng dữ liệu bên ngoài và làm phong phú thêm luồng, chẳng hạn như thông tin bổ sung về phương tiện hoặc dữ liệu thời tiết hiện tại, có thể rất hữu ích. Trong ví dụ này, giả sử chúng ta muốn đưa vào dữ liệu hiện được lưu trữ trong CSV ở Amazon S3 và thêm một cột có tên màu phản ánh dải tốc độ động cơ hiện tại.
Apache Flink SQL cung cấp một số kết nối nguồn cho các dịch vụ AWS và các nguồn khác. Tạo một bảng mới giống như chúng tôi đã làm trong đoạn đầu tiên nhưng thay vào đó, sử dụng trình kết nối hệ thống tệp cho phép Flink kết nối trực tiếp với Amazon S3 và đọc dữ liệu nguồn của chúng tôi. Trước đây trong Kinesis Data Analytics cho ứng dụng SQL, bạn không thể thêm nội tuyến tham chiếu mới. thay vào đó, bạn dữ liệu tham chiếu S3 đã xác định và thêm nó vào cấu hình ứng dụng của bạn, sau đó bạn có thể sử dụng cấu hình này làm tham chiếu trong THAM GIA SQL.
LƯU Ý: Nếu bạn không sử dụng vùng us-east-1, bạn có thể tải về csv và đặt đối tượng vào thùng S3 của riêng bạn. Tham khảo tệp csv dưới dạng s3a://<bucket-name>/<key-name>

Dựa trên truy vấn cuối cùng, đoạn tiếp theo thực hiện THAM GIA SQL trên dữ liệu hiện tại của chúng tôi và bảng nguồn tra cứu mới mà chúng tôi đã tạo.

Bây giờ chúng tôi có luồng dữ liệu phong phú, chúng tôi sắp xếp lại dữ liệu này. Trong một tình huống trong thế giới thực, chúng tôi có nhiều lựa chọn về những việc cần làm với dữ liệu của mình, chẳng hạn như gửi dữ liệu đến kho dữ liệu S3, một luồng dữ liệu Kinesis khác để phân tích thêm hoặc lưu trữ dữ liệu trong OpenSearch Service để trực quan hóa. Để đơn giản hóa, chúng tôi gửi dữ liệu đến Kinesis Data Firehose, nơi truyền dữ liệu vào bộ chứa S3 đóng vai trò là kho dữ liệu của chúng tôi.
Kinesis Data Firehose có thể truyền dữ liệu tới Amazon S3, OpenSearch Service, Amazon RedShift kho dữ liệu và Splunk chỉ trong vài cú nhấp chuột.
Tạo luồng phân phối Kinesis Data Firehose
Để tạo luồng phân phối của chúng tôi, hãy hoàn tất các bước sau:
- Trên bảng điều khiển Kinesis Data Firehose, hãy chọn Tạo luồng phân phối.
- Chọn PUT trực tiếp cho nguồn luồng và Amazon S3 làm mục tiêu.

- Đặt tên cho luồng giao hàng của bạn là ô tô-vòi cứu hỏa.

- Theo Cài đặt đích, tạo một nhóm mới hoặc sử dụng một nhóm hiện có.
- Lưu ý URL bộ chứa S3.
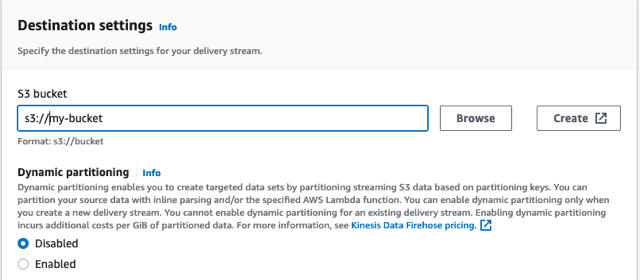
- Chọn Tạo luồng phân phối.
Luồng mất vài giây để tạo.
- Quay lại bảng điều khiển Kinesis Data Analytics và chọn Ứng dụng phát trực tuyến.
- trên Studio và chọn sổ ghi chép Studio của bạn.

- Chọn liên kết bên dưới Vai trò IAM.

- Trong cửa sổ IAM, chọn Thêm quyền và Đính kèm các chính sách.
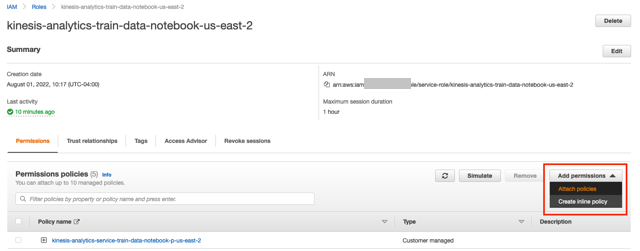
- Tìm kiếm và chọn AmazonKinesisFullAccess và CloudWatchFullAccess, sau đó chọn Đính kèm chính sách.
- Bạn có thể quay lại sổ ghi chép Zeppelin của mình.
Truyền dữ liệu vào Kinesis Data Firehose
Kể từ Apache Flink v1.15, việc tạo trình kết nối với luồng phân phối Firehose hoạt động tương tự như tạo trình kết nối với bất kỳ luồng dữ liệu Kinesis nào. Lưu ý rằng có hai điểm khác biệt: đầu nối là firehose, và thuộc tính stream trở thành delivery-stream.

Sau khi trình kết nối được tạo, chúng ta có thể ghi vào trình kết nối giống như bất kỳ bảng SQL nào.

Để xác thực rằng chúng tôi đang nhận dữ liệu thông qua luồng phân phối, hãy mở bảng điều khiển Amazon S3 và xác nhận rằng bạn thấy các tệp đang được tạo. Mở tệp để kiểm tra dữ liệu mới.
Trong Kinesis Data Analytics cho Ứng dụng SQL, lẽ ra chúng ta phải tạo một đích mới trong bảng điều khiển ứng dụng SQL. Để di chuyển một đích hiện có, bạn thêm một câu lệnh SQL vào sổ ghi chép của mình để xác định đích mới ngay trong mã. Bạn có thể tiếp tục ghi vào đích mới như bạn sẽ làm với INSERT trong khi tham chiếu tên bảng mới.
dữ liệu thời gian
Một thao tác phổ biến khác mà bạn có thể thực hiện trong sổ ghi chép Kinesis Data Analytics Studio là tổng hợp trong một khoảng thời gian. Loại dữ liệu này có thể được sử dụng để gửi đến luồng dữ liệu Kinesis khác nhằm xác định điểm bất thường, gửi cảnh báo hoặc được lưu trữ để xử lý thêm. Đoạn tiếp theo chứa một truy vấn SQL sử dụng cửa sổ lộn xộn và tổng hợp tổng nhiên liệu tiêu thụ cho đội ô tô trong khoảng thời gian 30 giây. Giống như ví dụ trước của chúng tôi, chúng tôi có thể kết nối với một luồng dữ liệu khác và chèn dữ liệu này để phân tích thêm.

Scala và PyFlink
Đôi khi một chức năng bạn muốn thực hiện trên luồng dữ liệu của mình được viết bằng ngôn ngữ lập trình tốt hơn thay vì SQL, để đơn giản và dễ bảo trì. Một số ví dụ bao gồm các phép tính phức tạp mà các hàm SQL không hỗ trợ nguyên bản, một số thao tác chuỗi nhất định, chia dữ liệu thành nhiều luồng và tương tác với các dịch vụ AWS khác (chẳng hạn như dịch văn bản hoặc phân tích cảm tính). Kinesis Data Analytics cho Apache Flink có khả năng sử dụng nhiều Thông dịch viên Flink trong sổ ghi chép Zeppelin không có sẵn trong Kinesis Data Analytics cho Ứng dụng SQL.
Nếu bạn đã chú ý đến dữ liệu của chúng tôi, bạn sẽ thấy rằng trường vị trí là một chuỗi JSON. Trong Kinesis Data Analytics cho SQL, chúng ta có thể sử dụng các hàm chuỗi và xác định một Hàm SQL và ngắt chuỗi JSON. Đây là một cách tiếp cận mong manh tùy thuộc vào tính ổn định của dữ liệu tin nhắn, nhưng điều này có thể được cải thiện bằng một số hàm SQL. Cú pháp tạo hàm trong Kinesis Data Analytics cho SQL tuân theo mẫu sau:
CREATE FUNCTION ''<function_name>'' ( ''<parameter_list>'' ) RETURNS ''<data type>'' LANGUAGE SQL [ SPECIFIC ''<specific_function_name>'' | [NOT] DETERMINISTIC ] CONTAINS SQL [ READS SQL DATA ] [ MODIFIES SQL DATA ] [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ] RETURN ''<SQL-defined function body>''
Trong Kinesis Data Analytics cho Apache Flink, AWS gần đây đã nâng cấp môi trường Apache Flink lên phiên bản 1.15, giúp mở rộng bảng SQL của Apache Flink SQL thành thêm các chức năng JSON tương tự như cú pháp Đường dẫn JSON. Điều này cho phép chúng tôi truy vấn chuỗi JSON trực tiếp trong SQL của chúng tôi. Xem đoạn mã sau:
%flink.ssql(type=update)
SELECT JSON_STRING(location, ‘$.latitude) AS latitude,
JSON_STRING(location, ‘$.longitude) AS longitude
FROM my_tableNgoài ra, và được yêu cầu trước Apache Flink v1.15, chúng tôi có thể sử dụng Scala hoặc PyFlink trong sổ ghi chép của mình để chuyển đổi trường và truyền lại dữ liệu. Cả hai ngôn ngữ đều cung cấp khả năng xử lý chuỗi JSON mạnh mẽ.
Mã PyFlink sau đây xác định hai chức năng do người dùng xác định, trích xuất vĩ độ và kinh độ từ trường vị trí của thông báo của chúng tôi. Các UDF này sau đó có thể được gọi từ việc sử dụng Flink SQL. Chúng tôi tham chiếu biến môi trường st_env. PyFlink tạo sáu biến cho bạn trong sổ ghi chép Zeppelin của bạn. Zeppelin cũng tiết lộ một bối cảnh đối với bạn là biến z.


Lỗi cũng có thể xảy ra khi thư chứa dữ liệu không mong muốn. Kinesis Data Analytics cho Ứng dụng SQL cung cấp luồng lỗi trong ứng dụng. Những lỗi này sau đó có thể được xử lý riêng biệt và phát lại hoặc loại bỏ. Với PyFlink trong các ứng dụng Truyền phát Kinesis Data Analytics, bạn có thể viết các chiến lược xử lý lỗi phức tạp và ngay lập tức khôi phục cũng như tiếp tục xử lý dữ liệu. Khi chuỗi JSON được chuyển vào UDF, nó có thể không đúng định dạng, không đầy đủ hoặc trống. Bằng cách bắt lỗi trong UDF, Python sẽ luôn trả về một giá trị ngay cả khi xảy ra lỗi.
Mã mẫu sau đây hiển thị một đoạn mã PyFlink khác thực hiện phép tính chia trên hai trường. Nếu gặp phải lỗi chia cho XNUMX, nó sẽ cung cấp một giá trị mặc định để luồng có thể tiếp tục xử lý thông báo.
%flink.pyflink
@udf(input_types=[DataTypes.BIGINT()], result_type=DataTypes.BIGINT())
def DivideByZero(price): try: price / 0 except: return -1
st_env.register_function("DivideByZero", DivideByZero)
Các bước tiếp theo
Xây dựng quy trình như chúng tôi đã thực hiện trong bài đăng này cung cấp cho chúng tôi cơ sở để thử nghiệm các dịch vụ bổ sung trong AWS. Tôi khuyến khích bạn tiếp tục tìm hiểu về phân tích phát trực tuyến trước khi chia nhỏ các luồng bạn đã tạo. Hãy xem xét những điều sau đây:
Làm sạch
Để dọn dẹp các dịch vụ được tạo trong bài tập này, hãy hoàn thành các bước sau:
- Điều hướng đến Bảng điều khiển CloudFormation và xóa ngăn xếp Trình mô phỏng thiết bị IoT.
- Trên bảng điều khiển AWS IoT Core, chọn Định tuyến và quy tắc thư rồi xóa quy tắc
automotive_route_kinesis. - Xóa luồng dữ liệu Kinesis
automotive-datatrong bảng điều khiển Kinesis Data Stream. - Xóa vai trò IAM
automotive-roletrong Bảng điều khiển IAM. - Trong bảng điều khiển AWS Glue, hãy xóa
automotive-notebook-gluecơ sở dữ liệu. - Xóa sổ ghi chép Kinesis Data Analytics Studio
automotive-data-notebook. - Xóa luồng phân phối Firehose
automotive-firehose.
Kết luận
Cảm ơn bạn đã theo dõi hướng dẫn này trên Kinesis Data Analytics Studio. Nếu bạn hiện đang sử dụng ứng dụng SQL cũ của Kinesis Data Analytics Studio, tôi khuyên bạn nên liên hệ với người quản lý tài khoản kỹ thuật AWS hoặc Kiến trúc sư giải pháp và thảo luận về việc di chuyển sang Kinesis Data Analytics Studio. Bạn có thể tiếp tục con đường học tập của mình trong Hướng dẫn dành cho nhà phát triển Amazon Kinesis Data Streams, và truy cập của chúng tôi mẫu mã trên GitHub.
Lưu ý
 Đường hầm Nicholas là Kiến trúc sư giải pháp đối tác cho Khu vực công toàn cầu tại AWS. Anh làm việc với các đối tác SI toàn cầu để phát triển kiến trúc trên AWS cho khách hàng trong các lĩnh vực chính phủ, chăm sóc sức khỏe phi lợi nhuận, tiện ích và giáo dục.
Đường hầm Nicholas là Kiến trúc sư giải pháp đối tác cho Khu vực công toàn cầu tại AWS. Anh làm việc với các đối tác SI toàn cầu để phát triển kiến trúc trên AWS cho khách hàng trong các lĩnh vực chính phủ, chăm sóc sức khỏe phi lợi nhuận, tiện ích và giáo dục.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/migrate-from-amazon-kinesis-data-analytics-for-sql-applications-to-amazon-kinesis-data-analytics-studio/

