At AWS re: Invent Năm 2023, chúng tôi đã công bố tính khả dụng rộng rãi của Cơ sở kiến thức về Amazon Bedrock. Với Cơ sở kiến thức dành cho Amazon Bedrock, bạn có thể kết nối các mô hình nền tảng (FM) một cách an toàn trong nền tảng Amazon vào dữ liệu công ty của bạn bằng cách sử dụng mô hình Thế hệ tăng cường truy xuất (RAG) được quản lý hoàn toàn.
Đối với các ứng dụng dựa trên RAG, độ chính xác của phản hồi được tạo từ FM phụ thuộc vào ngữ cảnh được cung cấp cho mô hình. Bối cảnh được lấy từ các cửa hàng vectơ dựa trên truy vấn của người dùng. Trong tính năng được phát hành gần đây cho Cơ sở Kiến thức dành cho Amazon Bedrock, tìm kiếm kết hợp, bạn có thể kết hợp tìm kiếm ngữ nghĩa với tìm kiếm từ khóa. Tuy nhiên, trong nhiều trường hợp, bạn có thể cần truy xuất các tài liệu được tạo trong một khoảng thời gian xác định hoặc được gắn thẻ với các danh mục nhất định. Để tinh chỉnh kết quả tìm kiếm, bạn có thể lọc dựa trên siêu dữ liệu tài liệu để cải thiện độ chính xác khi truy xuất, từ đó dẫn đến các thế hệ FM phù hợp hơn phù hợp với sở thích của bạn.
Trong bài đăng này, chúng tôi thảo luận về tính năng lọc siêu dữ liệu tùy chỉnh mới trong Cơ sở kiến thức dành cho Amazon Bedrock. Bạn có thể sử dụng tính năng này để cải thiện kết quả tìm kiếm bằng cách lọc trước các truy xuất của mình từ các cửa hàng vectơ.
Tổng quan về lọc siêu dữ liệu
Trước khi phát hành tính năng lọc siêu dữ liệu, tất cả các đoạn có liên quan về mặt ngữ nghĩa đạt đến mức tối đa được đặt trước sẽ được trả về dưới dạng ngữ cảnh để FM sử dụng để tạo phản hồi. Giờ đây, với các bộ lọc siêu dữ liệu, bạn có thể truy xuất không chỉ các đoạn có liên quan về mặt ngữ nghĩa mà còn có thể truy xuất một tập hợp con được xác định rõ ràng của các đoạn có liên quan đó dựa trên các bộ lọc siêu dữ liệu được áp dụng và các giá trị liên quan.
Với tính năng này, giờ đây bạn có thể cung cấp tệp siêu dữ liệu tùy chỉnh (mỗi tệp tối đa 10 KB) cho mỗi tài liệu trong cơ sở kiến thức. Bạn có thể áp dụng các bộ lọc cho các lần truy xuất của mình, hướng dẫn kho vectơ lọc trước dựa trên siêu dữ liệu tài liệu và sau đó tìm kiếm các tài liệu có liên quan. Bằng cách này, bạn có quyền kiểm soát các tài liệu được truy xuất, đặc biệt nếu các truy vấn của bạn không rõ ràng. Ví dụ: bạn có thể sử dụng các văn bản pháp luật có thuật ngữ tương tự cho các bối cảnh khác nhau hoặc các bộ phim có cốt truyện tương tự được phát hành vào các năm khác nhau. Ngoài ra, bằng cách giảm số lượng khối đang được tìm kiếm, bạn sẽ đạt được các lợi thế về hiệu suất như giảm chu kỳ CPU và chi phí truy vấn kho lưu trữ vectơ, bên cạnh việc cải thiện độ chính xác.

Để sử dụng tính năng lọc siêu dữ liệu, bạn cần cung cấp các tệp siêu dữ liệu bên cạnh các tệp dữ liệu nguồn có cùng tên với tệp dữ liệu nguồn và .metadata.json hậu tố. Siêu dữ liệu có thể là chuỗi, số hoặc Boolean. Sau đây là ví dụ về nội dung tệp siêu dữ liệu:
Tính năng lọc siêu dữ liệu của Cơ sở kiến thức dành cho Amazon Bedrock hiện có tại Khu vực AWS Miền Đông Hoa Kỳ (Bắc Virginia) và Miền Tây Hoa Kỳ (Oregon).
Sau đây là các trường hợp sử dụng phổ biến để lọc siêu dữ liệu:
- Tài liệu chatbot cho công ty phần mềm – Điều này cho phép người dùng tìm kiếm thông tin sản phẩm và hướng dẫn khắc phục sự cố. Ví dụ: các bộ lọc trên hệ điều hành hoặc phiên bản ứng dụng có thể giúp tránh truy xuất các tài liệu lỗi thời hoặc không liên quan.
- Tìm kiếm hội thoại của ứng dụng của một tổ chức – Điều này cho phép người dùng tìm kiếm thông qua các tài liệu, thẻ Kanban, bản ghi âm cuộc họp và các nội dung khác. Bằng cách sử dụng bộ lọc siêu dữ liệu trên nhóm làm việc, đơn vị kinh doanh hoặc ID dự án, bạn có thể cá nhân hóa trải nghiệm trò chuyện và cải thiện khả năng cộng tác. Một ví dụ sẽ là “Trạng thái của dự án Sphinx và rủi ro phát sinh” trong đó người dùng có thể lọc tài liệu cho một dự án hoặc loại nguồn cụ thể (chẳng hạn như email hoặc tài liệu cuộc họp).
- Tìm kiếm thông minh dành cho nhà phát triển phần mềm – Điều này cho phép các nhà phát triển tìm kiếm thông tin của một bản phát hành cụ thể. Các bộ lọc trên phiên bản phát hành, loại tài liệu (chẳng hạn như mã, tham chiếu API hoặc vấn đề) có thể giúp xác định chính xác các tài liệu có liên quan.
Tổng quan về giải pháp
Trong các phần sau, chúng tôi trình bày cách chuẩn bị tập dữ liệu để sử dụng làm cơ sở kiến thức và sau đó truy vấn bằng tính năng lọc siêu dữ liệu. Bạn có thể truy vấn bằng cách sử dụng Bảng điều khiển quản lý AWS hoặc SDK.
Chuẩn bị tập dữ liệu cho Cơ sở tri thức cho Amazon Bedrock
Đối với bài đăng này, chúng tôi sử dụng tập dữ liệu mẫu về trò chơi điện tử hư cấu để minh họa cách nhập và truy xuất siêu dữ liệu bằng Cơ sở kiến thức dành cho Amazon Bedrock. Nếu bạn muốn theo dõi bằng tài khoản AWS của mình, hãy tải xuống tệp.
Nếu bạn muốn thêm siêu dữ liệu vào tài liệu của mình trong cơ sở kiến thức hiện có, hãy tạo tệp siêu dữ liệu với tên tệp và lược đồ dự kiến, sau đó chuyển sang bước đồng bộ hóa dữ liệu của bạn với cơ sở kiến thức để bắt đầu quá trình nhập tăng dần.
Trong tập dữ liệu mẫu của chúng tôi, tài liệu của mỗi trò chơi là một tệp CSV riêng biệt (ví dụ: s3://$bucket_name/video_game/$game_id.csv) với các cột sau:
title, description, genres, year, publisher, score
Siêu dữ liệu của mỗi trò chơi có hậu tố .metadata.json (ví dụ, s3://$bucket_name/video_game/$game_id.csv.metadata.json) với lược đồ sau:
Tạo cơ sở kiến thức cho Amazon Bedrock
Để biết hướng dẫn tạo cơ sở kiến thức mới, hãy xem Tạo cơ sở kiến thức. Đối với ví dụ này, chúng tôi sử dụng các cài đặt sau:
- trên Thiết lập nguồn dữ liệu trang, dưới Chiến lược chia nhỏ, lựa chọn Không phân chia, vì bạn đã xử lý trước tài liệu ở bước trước.
- Trong tạp chí Mô hình nhúng phần, chọn Phần nhúng Titan G1 – Văn bản.
- Trong tạp chí Cơ sở dữ liệu vectơ phần, chọn Tạo nhanh một cửa hàng vector mới. Tính năng lọc siêu dữ liệu có sẵn cho tất cả các cửa hàng vectơ được hỗ trợ.
Đồng bộ hóa tập dữ liệu với cơ sở kiến thức
Sau khi bạn tạo cơ sở kiến thức, các tệp dữ liệu và tệp siêu dữ liệu của bạn ở dạng Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), bạn có thể bắt đầu nhập tăng dần. Để biết hướng dẫn, xem Đồng bộ hóa để nhập nguồn dữ liệu của bạn vào cơ sở kiến thức.
Truy vấn có tính năng lọc siêu dữ liệu trên bảng điều khiển Amazon Bedrock
Để sử dụng các tùy chọn lọc siêu dữ liệu trên bảng điều khiển Amazon Bedrock, hãy hoàn thành các bước sau:
- Trên bảng điều khiển Amazon Bedrock, chọn Cơ sở kiến thức trong khung điều hướng.
- Chọn cơ sở kiến thức bạn đã tạo.
- Chọn Kiểm tra cơ sở kiến thức.
- Chọn cấu hình biểu tượng, sau đó mở rộng Bộ lọc.
- Nhập điều kiện theo định dạng: key = value (ví dụ: thể loại = Chiến lược) và nhấn đăng ký hạng mục thi.
- Để thay đổi khóa, giá trị hoặc toán tử, hãy chọn điều kiện.
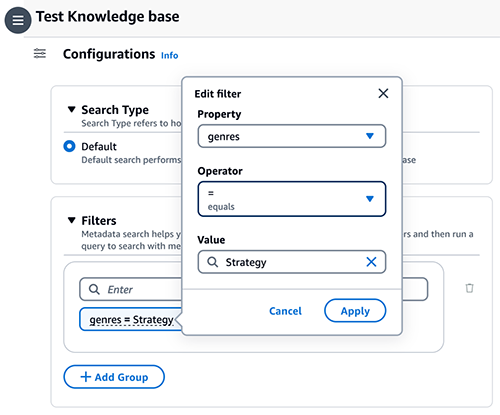
- Tiếp tục với các điều kiện còn lại (ví dụ: (thể loại = Chiến lược VÀ năm >= 2023) HOẶC (xếp hạng >= 9))

- Khi hoàn tất, hãy nhập truy vấn của bạn vào hộp thông báo, sau đó chọn chạy.
Đối với bài đăng này, chúng tôi nhập truy vấn “Một trò chơi chiến lược có đồ họa thú vị được phát hành sau năm 2023”.
Truy vấn có lọc siêu dữ liệu bằng SDK
Để sử dụng SDK, trước tiên hãy tạo ứng dụng khách cho Đại lý cho Amazon Bedrock thời gian chạy:
Sau đó xây dựng bộ lọc (sau đây là một số ví dụ):
Truyền bộ lọc tới retrievalConfiguration của API truy xuất or Truy xuất và tạo API:
Bảng sau liệt kê một số phản hồi với các điều kiện lọc siêu dữ liệu khác nhau.
| Query | Lọc siêu dữ liệu | Tài liệu được truy xuất | Các quan sát |
| “Một game chiến thuật với đồ họa cực ngầu ra mắt sau năm 2023” | tắt |
* Viking Saga: The Sea Raider, năm:2023, thể loại: Chiến thuật * Lâu đài thời trung cổ: Cuộc vây hãm và chinh phục, năm:2022, thể loại: Chiến lược * Cách mạng điện tử: Sự trỗi dậy của máy móc, năm:2022, thể loại: Chiến lược |
2/5 game đáp ứng điều kiện (thể loại = Chiến lược và năm >= 2023) |
| On | * Viking Saga: The Sea Raider, năm:2023, thể loại: Chiến thuật * Fantasy Kingdoms: Chronicles of Eldoria, năm:2023, thể loại: Chiến thuật |
2/2 game đáp ứng điều kiện (thể loại = Chiến lược và năm >= 2023) |
Ngoài siêu dữ liệu tùy chỉnh, bạn cũng có thể lọc bằng tiền tố S3 (là siêu dữ liệu tích hợp sẵn nên bạn không cần cung cấp bất kỳ tệp siêu dữ liệu nào). Ví dụ: nếu bạn sắp xếp tài liệu trò chơi thành các tiền tố theo nhà xuất bản (ví dụ: s3://$bucket_name/video_game/$publisher/$game_id.csv), bạn có thể lọc theo nhà xuất bản cụ thể (ví dụ: neo_tokyo_games) bằng cú pháp sau:
Làm sạch
Để dọn dẹp tài nguyên của bạn, hãy hoàn thành các bước sau:
- Xóa cơ sở kiến thức:
- Trên bảng điều khiển Amazon Bedrock, chọn Cơ sở kiến thức Dưới Dàn nhạc trong khung điều hướng.
- Chọn cơ sở kiến thức bạn đã tạo.
- Hãy lưu ý Quản lý truy cập và nhận dạng AWS (IAM) tên vai trò dịch vụ trong Tổng quan về cơ sở kiến thức phần.
- Trong tạp chí Cơ sở dữ liệu vectơ phần, hãy lưu ý đến bộ sưu tập ARN.
- Chọn Xóa bỏ, sau đó nhập xóa để xác nhận.
- Xóa cơ sở dữ liệu vectơ:
- trên Dịch vụ Tìm kiếm Mở của Amazon bảng điều khiển, chọn Bộ sưu tập Dưới Không có máy chủ trong khung điều hướng.
- Nhập bộ sưu tập ARN bạn đã lưu vào thanh tìm kiếm.
- Chọn bộ sưu tập và chọn Xóa bỏ.
- Nhập xác nhận trong lời nhắc xác nhận, sau đó chọn Xóa bỏ.
- Xóa vai trò dịch vụ IAM:
- Trên bảng điều khiển IAM, chọn Vai trò trong khung điều hướng.
- Tìm kiếm tên vai trò bạn đã lưu ý trước đó.
- Chọn vai trò và chọn Xóa bỏ.
- Nhập tên vai trò trong lời nhắc xác nhận và xóa vai trò.
- Xóa tập dữ liệu mẫu:
- Trên bảng điều khiển Amazon S3, hãy điều hướng đến vùng lưu trữ S3 mà bạn đã sử dụng.
- Chọn tiền tố và tập tin, sau đó chọn Xóa bỏ.
- Nhập xóa vĩnh viễn trong lời nhắc xác nhận để xóa.
Kết luận
Trong bài đăng này, chúng tôi đã đề cập đến tính năng lọc siêu dữ liệu trong Cơ sở kiến thức dành cho Amazon Bedrock. Bạn đã tìm hiểu cách thêm siêu dữ liệu tùy chỉnh vào tài liệu và sử dụng chúng làm bộ lọc trong khi truy xuất và truy vấn tài liệu bằng bảng điều khiển Amazon Bedrock và SDK. Điều này giúp cải thiện độ chính xác của ngữ cảnh, làm cho các phản hồi truy vấn trở nên phù hợp hơn đồng thời giảm được chi phí truy vấn cơ sở dữ liệu vectơ.
Để biết thêm tài nguyên, hãy tham khảo các tài liệu sau:
Về các tác giả
 Corvus Lee là Kiến trúc sư giải pháp phòng thí nghiệm GenAI cấp cao có trụ sở tại London. Anh ấy đam mê thiết kế và phát triển các nguyên mẫu sử dụng AI tổng hợp để giải quyết các vấn đề của khách hàng. Anh ấy cũng theo kịp những phát triển mới nhất về AI tổng quát và kỹ thuật truy xuất bằng cách áp dụng chúng vào các tình huống trong thế giới thực.
Corvus Lee là Kiến trúc sư giải pháp phòng thí nghiệm GenAI cấp cao có trụ sở tại London. Anh ấy đam mê thiết kế và phát triển các nguyên mẫu sử dụng AI tổng hợp để giải quyết các vấn đề của khách hàng. Anh ấy cũng theo kịp những phát triển mới nhất về AI tổng quát và kỹ thuật truy xuất bằng cách áp dụng chúng vào các tình huống trong thế giới thực.
 Ahmed Ewis là Kiến trúc sư giải pháp cấp cao tại Phòng thí nghiệm AWS GenAI, giúp khách hàng xây dựng các nguyên mẫu AI tổng quát để giải quyết các vấn đề kinh doanh. Khi không cộng tác với khách hàng, anh thích chơi với con và nấu ăn.
Ahmed Ewis là Kiến trúc sư giải pháp cấp cao tại Phòng thí nghiệm AWS GenAI, giúp khách hàng xây dựng các nguyên mẫu AI tổng quát để giải quyết các vấn đề kinh doanh. Khi không cộng tác với khách hàng, anh thích chơi với con và nấu ăn.
 Chris Pecora là Nhà khoa học dữ liệu AI sáng tạo tại Amazon Web Services. Anh ấy đam mê xây dựng các sản phẩm và giải pháp sáng tạo đồng thời tập trung vào ngành khoa học luôn quan tâm đến khách hàng. Khi không chạy thử nghiệm và cập nhật những phát triển mới nhất về GenAI, anh ấy thích dành thời gian cho các con mình.
Chris Pecora là Nhà khoa học dữ liệu AI sáng tạo tại Amazon Web Services. Anh ấy đam mê xây dựng các sản phẩm và giải pháp sáng tạo đồng thời tập trung vào ngành khoa học luôn quan tâm đến khách hàng. Khi không chạy thử nghiệm và cập nhật những phát triển mới nhất về GenAI, anh ấy thích dành thời gian cho các con mình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-metadata-filtering-to-improve-retrieval-accuracy/

