Giới thiệu
Trong lĩnh vực trí tuệ nhân tạo, Mô hình ngôn ngữ lớn (LLM) và mô hình Generative AI như GPT-4 của OpenAI, Claude 2 của Anthropic, Llama của Meta, Falcon, Palm của Google, v.v., đã cách mạng hóa cách chúng ta giải quyết vấn đề. LLM sử dụng các kỹ thuật học sâu để thực hiện các tác vụ xử lý ngôn ngữ tự nhiên. Bài viết này sẽ hướng dẫn bạn xây dựng Ứng dụng LLM bằng cơ sở dữ liệu vectơ. Bạn có thể đã tương tác với một chatbot như dịch vụ khách hàng của Amazon hoặc Trợ lý quyết định Flipkart. Chúng tạo ra văn bản giống con người và cung cấp trải nghiệm người dùng tương tác gần như không thể phân biệt được với các cuộc trò chuyện trong đời thực. Tuy nhiên, các LLM này cần được tối ưu hóa để chúng tạo ra các kết quả cụ thể và có liên quan cao nhằm thực sự hữu ích cho các trường hợp sử dụng cụ thể.

Ví dụ: nếu bạn hỏi: “Làm cách nào để thay đổi ngôn ngữ của tôi trong ứng dụng Android?” đối với ứng dụng dịch vụ khách hàng của Amazon, nó có thể chưa được đào tạo về văn bản chính xác này và do đó có thể không trả lời được. Đây là lúc cơ sở dữ liệu vectơ ra tay giải cứu. Cơ sở dữ liệu vectơ lưu trữ văn bản tên miền (trong trường hợp này là tài liệu trợ giúp) và các truy vấn trước đây của tất cả người dùng, bao gồm cả lịch sử đặt hàng, v.v., dưới dạng nhúng số và cung cấp tra cứu các vectơ tương tự trong thời gian thực. Trong trường hợp này, nó mã hóa truy vấn này thành một vectơ số và sử dụng nó để thực hiện tìm kiếm tương tự trong cơ sở dữ liệu các vectơ của nó và tìm các lân cận gần nhất của nó. Với sự trợ giúp này, chatbot có thể hướng dẫn người dùng chính xác đến phần “Thay đổi tùy chọn ngôn ngữ của bạn” trên ứng dụng Amazon.
Mục tiêu học tập
- LLM hoạt động như thế nào, hạn chế của chúng là gì và tại sao chúng cần cơ sở dữ liệu vectơ?
- Giới thiệu về các mô hình nhúng cũng như cách mã hóa và sử dụng chúng trong các ứng dụng.
- Tìm hiểu cơ sở dữ liệu vectơ là gì và chúng là một phần của kiến trúc ứng dụng LLM như thế nào.
- Tìm hiểu cách mã hóa các ứng dụng LLM/Generative AI bằng cách sử dụng cơ sở dữ liệu vectơ và tensorflow.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
LLM là gì?
Mô hình ngôn ngữ lớn (LLM) là các mô hình máy học nền tảng sử dụng các thuật toán học sâu để xử lý và hiểu ngôn ngữ tự nhiên. Các mô hình này được đào tạo trên một lượng lớn dữ liệu văn bản để tìm hiểu các mẫu và mối quan hệ thực thể trong ngôn ngữ. LLM có thể thực hiện nhiều loại tác vụ ngôn ngữ, chẳng hạn như dịch ngôn ngữ, phân tích cảm xúc, hội thoại chatbot, v.v. Họ có thể hiểu dữ liệu văn bản phức tạp, xác định các thực thể và mối quan hệ giữa chúng, đồng thời tạo văn bản mới mạch lạc và chính xác về mặt ngữ pháp.
Đọc thêm về LLM tại đây.
LLM hoạt động như thế nào?
LLM được đào tạo bằng cách sử dụng một lượng lớn dữ liệu, thường là terabyte, thậm chí petabyte, với hàng tỷ hoặc hàng nghìn tỷ tham số, cho phép chúng dự đoán và tạo phản hồi có liên quan dựa trên lời nhắc hoặc truy vấn của người dùng. Họ xử lý dữ liệu đầu vào thông qua việc nhúng từ, các lớp tự chú ý và mạng chuyển tiếp để tạo ra văn bản có ý nghĩa. Bạn có thể đọc thêm về kiến trúc LLM tại đây.
Hạn chế của LLM
Trong khi LLM dường như tạo ra phản hồi với độ chính xác khá cao, thậm chí hơn hơn con người ở nhiều tiêu chuẩn kiểm tra, các mô hình này vẫn còn những hạn chế. Thứ nhất, họ chỉ dựa vào dữ liệu huấn luyện để xây dựng lý luận và do đó có thể thiếu thông tin cụ thể hoặc thông tin hiện tại trong dữ liệu. Điều này dẫn đến việc mô hình tạo ra phản hồi không chính xác hoặc bất thường, hay còn gọi là “ảo giác”. Đã có một sự việc đang diễn ra nỗ lực để giảm thiểu điều này. Thứ hai, mô hình có thể không hoạt động hoặc phản hồi theo cách phù hợp với mong đợi của người dùng.
Để giải quyết vấn đề này, cơ sở dữ liệu vectơ và mô hình nhúng nâng cao kiến thức về LLM/AI sáng tạo bằng cách cung cấp tra cứu bổ sung cho các phương thức tương tự (văn bản, hình ảnh, video, v.v.) mà người dùng đang tìm kiếm thông tin. Đây là một ví dụ trong đó LLM không có phản hồi mà người dùng yêu cầu và thay vào đó dựa vào cơ sở dữ liệu vectơ để tìm thông tin đó.

Cơ sở dữ liệu LLM và Vector
Mô hình ngôn ngữ lớn (LLM) đang được sử dụng hoặc tích hợp trong nhiều lĩnh vực của ngành, chẳng hạn như thương mại điện tử, du lịch, tìm kiếm, tạo nội dung và tài chính. Các mô hình này dựa trên một loại cơ sở dữ liệu tương đối mới hơn, được gọi là cơ sở dữ liệu vectơ, lưu trữ biểu diễn số của văn bản, hình ảnh, video và dữ liệu khác trong biểu diễn nhị phân được gọi là nhúng. Phần này nêu bật các nguyên tắc cơ bản của cơ sở dữ liệu vectơ và phần nhúng, đồng thời quan trọng hơn là tập trung vào cách sử dụng chúng để tích hợp với các ứng dụng LLM.
Cơ sở dữ liệu vectơ là cơ sở dữ liệu lưu trữ và tìm kiếm các phần nhúng bằng không gian nhiều chiều. Các vectơ này là biểu diễn bằng số của các tính năng hoặc thuộc tính của dữ liệu. Sử dụng các thuật toán tính toán khoảng cách hoặc độ tương tự giữa các vectơ trong không gian nhiều chiều, cơ sở dữ liệu vectơ có thể truy xuất dữ liệu tương tự một cách nhanh chóng và hiệu quả. Không giống như cơ sở dữ liệu dựa trên vô hướng truyền thống lưu trữ dữ liệu theo hàng hoặc cột và sử dụng các phương pháp tìm kiếm dựa trên từ khóa hoặc đối sánh chính xác, cơ sở dữ liệu vectơ hoạt động khác. Họ sử dụng cơ sở dữ liệu vectơ để tìm kiếm và so sánh một tập hợp lớn các vectơ trong một khoảng thời gian rất ngắn (thứ tự mili giây) bằng cách sử dụng các kỹ thuật như Hàng xóm gần nhất gần đúng (ANN).
Hướng dẫn nhanh về nhúng
Các mô hình AI tạo ra các phần nhúng bằng cách nhập dữ liệu thô như văn bản, video, hình ảnh vào thư viện nhúng vectơ, chẳng hạn như từ2vec và Trong bối cảnh AI và học máy, các tính năng này thể hiện các chiều khác nhau của dữ liệu cần thiết để hiểu các mối quan hệ mẫu và cấu trúc cơ bản.
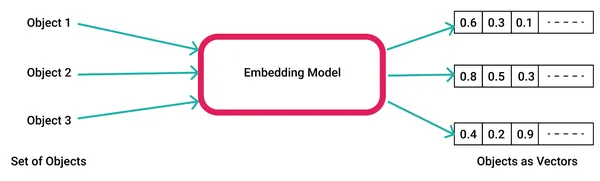
Dưới đây là ví dụ về cách tạo từ nhúng bằng word2vec.
1. Tạo mô hình bằng cách sử dụng kho dữ liệu tùy chỉnh của bạn hoặc sử dụng mô hình dựng sẵn mẫu từ Google hoặc FastText. Nếu bạn tự tạo, bạn có thể lưu nó vào hệ thống tệp của mình dưới dạng tệp “word2vec.model”.
import gensim # Create a word2vec model
model = gensim.models.Word2Vec(corpus) # Save the model file
model.save('word2vec.model')2. Tải mô hình, tạo một vectơ nhúng cho một từ đầu vào và sử dụng nó để lấy các từ tương tự trong không gian nhúng vectơ.
import gensim
import numpy as np # Load the word2vec model
model = gensim.models.Word2Vec.load('word2vec.model') # Get the vector for the word "king"
king_vector = model['king'] # Get the most similar vectors to the king vector
similar_vectors = model.similar_by_vector(king_vector, topn=5) # Print the most similar vectors
for vector in similar_vectors: print(vector[0], vector[1]) 3. Dưới đây là 5 từ đứng đầu gần với từ đầu vào.
Output: man 0.85
prince 0.78
queen 0.75
lord 0.74
emperor 0.72Kiến trúc ứng dụng LLM sử dụng cơ sở dữ liệu vectơ
Ở mức độ cao, cơ sở dữ liệu vectơ dựa vào các mô hình nhúng để xử lý cả việc tạo và truy vấn các phần nhúng. Trên đường dẫn nhập, nội dung kho văn bản được mã hóa thành vectơ bằng mô hình nhúng và được lưu trữ trong cơ sở dữ liệu vectơ như Pinecone, ChromaDB, Weaviate, v.v. Trên đường dẫn đọc, ứng dụng tạo một truy vấn bằng cách sử dụng câu hoặc từ và nó lại được mã hóa bằng mô hình nhúng vào một vectơ sau đó được truy vấn vào vectơ db để lấy kết quả.
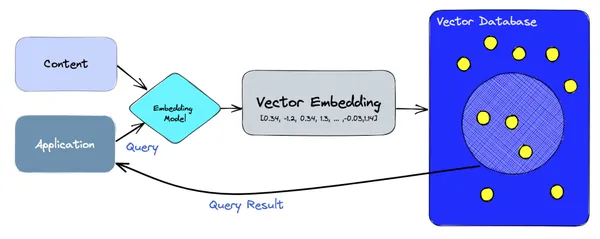
Ứng dụng LLM sử dụng cơ sở dữ liệu vectơ
LLM hỗ trợ các nhiệm vụ ngôn ngữ và được nhúng vào một lớp mô hình rộng hơn, chẳng hạn như Trí tuệ nhân tạo có thể tạo ra hình ảnh và video ngoài văn bản. Trong phần này, chúng ta sẽ tìm hiểu cách xây dựng các ứng dụng LLM/Generative AI thực tế bằng cách sử dụng cơ sở dữ liệu vectơ. Tôi đã sử dụng máy biến áp và lib đèn pin cho các mô hình ngôn ngữ và pinecone như một cơ sở dữ liệu vector. Bạn có thể chọn bất kỳ mô hình ngôn ngữ nào cho LLM/phần nhúng và bất kỳ cơ sở dữ liệu vectơ nào để lưu trữ và tìm kiếm.
Ứng dụng Chatbot
Để xây dựng chatbot bằng cơ sở dữ liệu vector, bạn có thể làm theo các bước sau:
- Chọn cơ sở dữ liệu vectơ như Pinecone, Chroma, Weaviate, AWS Kendra, v.v.
- Tạo chỉ mục vector cho chatbot của bạn.
- Huấn luyện mô hình ngôn ngữ bằng cách sử dụng kho văn bản lớn mà bạn chọn. Ví dụ: đối với một chatbot tin tức, bạn có thể cung cấp dữ liệu tin tức.
- Tích hợp cơ sở dữ liệu vector và mô hình ngôn ngữ.
Dưới đây là một ví dụ đơn giản về ứng dụng chatbot sử dụng cơ sở dữ liệu vectơ và mô hình ngôn ngữ:
import pinecone
import transformers # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the language model
model = transformers.AutoModelForCausalLM.from_pretrained("google/bigbird-roberta-base") # Define a function to generate text
def generate_text(prompt): inputs = model.prepare_inputs_for_generation(prompt, return_tensors="pt") outputs = model.generate(inputs, max_length=100) return outputs[0].decode("utf-8") # Define a function to retrieve the most similar vectors to the user's query vector
def retrieve_similar_vectors(query_vector): results = client.search("my_index", query_vector) return results # Define a function to generate a response to the user's query
def generate_response(query): # Retrieve the most similar vectors to the user's query vector similar_vectors = retrieve_similar_vectors(query) # Generate text based on the retrieved vectors response = generate_text(similar_vectors[0]) return response # Start the chatbot
while True: # Get the user's query query = input("What is your question? ") # Generate a response to the user's query response = generate_response(query) # Print the response print(response)Ứng dụng chatbot này sẽ truy xuất các vectơ giống nhất với vectơ truy vấn của người dùng từ cơ sở dữ liệu vectơ và sau đó tạo văn bản bằng mô hình ngôn ngữ dựa trên các vectơ được truy xuất.
ChatBot > What is your question?
User_A> How tall is the Eiffel Tower?
ChatBot>The height of the Eiffel Tower measures 324 meters (1,063 feet) from its base to the top of its antenna. Ứng dụng tạo hình ảnh
Hãy cùng khám phá cách xây dựng ứng dụng Image Generator sử dụng cả hai Trí tuệ nhân tạo và thư viện LLM.
- Tạo cơ sở dữ liệu vectơ để lưu trữ vectơ hình ảnh của bạn.
- Trích xuất vectơ hình ảnh từ dữ liệu đào tạo của bạn.
- Chèn các vectơ hình ảnh vào cơ sở dữ liệu vectơ.
- Huấn luyện một mạng lưới đối thủ tổng quát (GAN). Đọc tại đây nếu bạn cần giới thiệu về GAN.
- Tích hợp cơ sở dữ liệu vector và GAN.
Đây là một ví dụ đơn giản về chương trình tích hợp cơ sở dữ liệu vectơ và GAN để tạo hình ảnh:
import pinecone
import torch
from torchvision import transforms # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the GAN
generator = torch.load("generator.pt") # Define a function to generate an image from a vector
def generate_image(vector): # Convert the vector to a tensor tensor = torch.from_numpy(vector).float() # Generate the image image = generator(tensor) # Transform the image to a PIL image image = transforms.ToPILImage()(image) return image # Start the image generator
while True: # Get the user's query query = input("What kind of image would you like to generate? ") # Retrieve the most similar vector to the user's query vector similar_vectors = client.search("my_index", query) # Generate an image from the retrieved vector image = generate_image(similar_vectors[0]) # Display the image image.show()Chương trình này sẽ truy xuất vectơ tương tự nhất với vectơ truy vấn của người dùng từ cơ sở dữ liệu vectơ và sau đó tạo hình ảnh bằng GAN dựa trên vectơ được truy xuất.
ImageBot>What kind of image would you like to generate?
Me>An idyllic image of a mountain with a flowing river.
ImageBot> Wait a minute! Here you go...
Bạn có thể tùy chỉnh chương trình này để đáp ứng nhu cầu cụ thể của bạn. Ví dụ: bạn có thể đào tạo GAN chuyên tạo ra một loại hình ảnh cụ thể, chẳng hạn như chân dung hoặc phong cảnh.
Ứng dụng đề xuất phim
Hãy cùng khám phá cách xây dựng ứng dụng đề xuất phim từ kho phim. Bạn có thể sử dụng ý tưởng tương tự để xây dựng hệ thống đề xuất cho sản phẩm hoặc các thực thể khác.
- Tạo cơ sở dữ liệu vectơ để lưu trữ vectơ phim của bạn.
- Trích xuất vectơ phim từ siêu dữ liệu phim của bạn.
- Chèn các vectơ phim vào cơ sở dữ liệu vectơ.
- Đề xuất phim cho người dùng.
Dưới đây là ví dụ về cách sử dụng API Pinecone để giới thiệu phim cho người dùng:
import pinecone # Create an API client
client = pinecone.Client(api_key="YOUR_API_KEY") # Get the user's vector
user_vector = client.get_vector("user_index", user_id) # Recommend movies to the user
results = client.search("movie_index", user_vector) # Print the results
for result in results: print(result["title"])Đây là một đề xuất mẫu cho người dùng
The Shawshank Redemption
The Dark Knight
Inception
The Godfather
Pulp FictionCác trường hợp sử dụng LLM trong thế giới thực bằng cách sử dụng Cơ sở dữ liệu/Tìm kiếm Vector
- Microsoft và TikTok sử dụng cơ sở dữ liệu vector như Pinecone để có trí nhớ dài hạn và tra cứu nhanh hơn. Đây là điều mà LLM không thể làm một mình nếu không có cơ sở dữ liệu vectơ. Nó giúp người dùng lưu các câu hỏi/câu trả lời trước đây của họ và tiếp tục phiên của họ. Ví dụ: người dùng có thể hỏi: “Hãy cho tôi biết thêm về công thức mì ống mà chúng ta đã thảo luận tuần trước”. Đọc tại đây.

- Trợ lý Quyết định của Flipkart đề xuất sản phẩm cho người dùng bằng cách trước tiên mã hóa truy vấn dưới dạng nhúng vectơ và thực hiện tra cứu dựa trên các vectơ lưu trữ các sản phẩm có liên quan trong không gian nhiều chiều. Ví dụ: nếu bạn tìm kiếm “Áo khoác da nam màu nâu trung bình của Wrangler”, nó sẽ đề xuất các sản phẩm có liên quan cho người dùng bằng cách sử dụng tìm kiếm vectơ tương tự. Nếu không, LLM sẽ không có bất kỳ đề xuất nào vì không có danh mục sản phẩm nào chứa tiêu đề hoặc chi tiết sản phẩm như vậy. Bạn có thể đọc nó tại đây.
- Chipper Cash, một công ty fintech ở Châu Phi, sử dụng cơ sở dữ liệu vectơ để giảm số lần đăng ký gian lận của người dùng xuống 10 lần. Nó thực hiện điều này bằng cách lưu trữ tất cả hình ảnh của những lần đăng ký của người dùng trước đó dưới dạng nhúng vectơ. Sau đó, khi người dùng mới đăng ký, nó sẽ mã hóa nó dưới dạng vectơ và so sánh với người dùng hiện tại để phát hiện gian lận. Bạn có thể đọc nó tại đây.

- Facebook đã sử dụng thư viện tìm kiếm vector có tên là THẤT BẠI ( Blog của chúng tôi.) trong nhiều sản phẩm nội bộ, bao gồm Instagram Reels và Facebook Stories, để tra cứu nhanh mọi nội dung đa phương tiện và tìm các ứng cử viên tương tự để hiển thị đề xuất tốt hơn cho người dùng.
Kết luận
Cơ sở dữ liệu vectơ rất hữu ích để xây dựng các ứng dụng LLM khác nhau, chẳng hạn như tạo hình ảnh, đề xuất phim hoặc sản phẩm và chatbot. Họ cung cấp cho LLM thông tin bổ sung hoặc thông tin tương tự mà LLM chưa được đào tạo. Họ lưu trữ các phần nhúng vectơ một cách hiệu quả trong không gian nhiều chiều và sử dụng tìm kiếm lân cận gần nhất để tìm các phần nhúng tương tự với độ chính xác cao.
Chìa khóa chính
Điểm mấu chốt của bài viết này là cơ sở dữ liệu vectơ rất phù hợp với các ứng dụng LLM và cung cấp các tính năng quan trọng sau để người dùng tích hợp:
- HIỆU QUẢ: Cơ sở dữ liệu vectơ được thiết kế đặc biệt để lưu trữ và truy xuất dữ liệu vectơ một cách hiệu quả, điều này rất quan trọng để phát triển các ứng dụng LLM hiệu suất cao.
- Độ chính xác: Cơ sở dữ liệu vectơ có thể khớp chính xác với các vectơ tương tự, ngay cả khi chúng có những thay đổi nhỏ. Họ sử dụng thuật toán lân cận gần nhất để tính toán các vectơ tương tự.
- Đa phương thức: Cơ sở dữ liệu vectơ có thể chứa nhiều dữ liệu đa phương thức khác nhau, bao gồm văn bản, hình ảnh và âm thanh. Tính linh hoạt này khiến chúng trở thành lựa chọn lý tưởng cho các ứng dụng LLM/Generative AI cần làm việc với các loại dữ liệu đa dạng.
- Thân thiện với nhà phát triển: Cơ sở dữ liệu vectơ tương đối thân thiện với người dùng, ngay cả đối với các nhà phát triển có thể không có kiến thức sâu rộng về kỹ thuật học máy.
Ngoài ra, tôi muốn nhấn mạnh rằng nhiều giải pháp SQL/NoSQL hiện có đã thêm tính năng lưu trữ nhúng vectơ, lập chỉ mục và các tính năng tìm kiếm tương tự nhanh hơn, ví dụ: PostgreSQL và Redis. Đây là một không gian đang phát triển nhanh chóng, vì vậy các nhà phát triển ứng dụng sẽ có nhiều lựa chọn trong tương lai gần để xây dựng các ứng dụng sáng tạo.
Những câu hỏi thường gặp
A. Mô hình ngôn ngữ lớn hay LLM là các chương trình Trí tuệ nhân tạo (AI) tiên tiến được đào tạo trên một kho dữ liệu văn bản lớn sử dụng mạng thần kinh để bắt chước các phản ứng giống con người với ngữ cảnh. Họ có thể dự đoán, trả lời và tạo dữ liệu văn bản trong lĩnh vực mà họ đã được đào tạo.
A. Phần nhúng là sự thể hiện bằng số của văn bản, hình ảnh, video hoặc các định dạng dữ liệu khác. Chúng làm cho việc định vị và tìm kiếm các đối tượng có ngữ nghĩa giống nhau dễ dàng hơn trong không gian nhiều chiều.
A. Cơ sở dữ liệu lưu trữ và truy vấn các vectơ nhúng có chiều cao để tìm các vectơ tương tự bằng cách sử dụng các thuật toán lân cận gần nhất chẳng hạn như băm nhạy cảm cục bộ. LLM/Generative AI cần họ để giúp họ cung cấp các tra cứu bổ sung cho các vectơ tương tự thay vì tự tinh chỉnh LLM.
A. Cơ sở dữ liệu vectơ là cơ sở dữ liệu thích hợp giúp lập chỉ mục và tìm kiếm các phần nhúng vectơ. Chúng phổ biến rộng rãi trong cộng đồng nguồn mở và nhiều tổ chức/ứng dụng đang tích hợp với chúng. Tuy nhiên, nhiều cơ sở dữ liệu SQL/NoSQL hiện có đang bổ sung các khả năng tương tự để cộng đồng nhà phát triển sẽ có nhiều lựa chọn trong tương lai gần.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/10/how-to-build-llm-apps-using-vector-database/

