Bài đăng này được đồng sáng tác bởi Anshuman Varshney, Trưởng nhóm kỹ thuật tại Gameskraft.
Trò chơi là một trong những công ty trò chơi trực tuyến hàng đầu của Ấn Độ, cung cấp trải nghiệm chơi trò chơi trên nhiều danh mục khác nhau như rummy, ludo, poker và nhiều danh mục khác dưới các thương hiệu RummyVăn hóa, Văn hóa Ludo, túi52và Playship. Gameskraft nắm giữ Guinness World Record để tổ chức giải đấu rummy trực tuyến lớn nhất thế giới và là một trong những công ty trò chơi đầu tiên của Ấn Độ xây dựng nền tảng được chứng nhận ISO.
Amazon RedShift là dịch vụ lưu trữ dữ liệu được quản lý hoàn toàn, cung cấp cả tùy chọn được cung cấp và không có máy chủ, giúp chạy và mở rộng quy mô phân tích hiệu quả hơn mà không cần phải quản lý kho dữ liệu của bạn. Amazon Redshift cho phép bạn sử dụng SQL để phân tích dữ liệu có cấu trúc và bán cấu trúc trên kho dữ liệu, cơ sở dữ liệu vận hành và hồ dữ liệu bằng cách sử dụng phần cứng và máy học (ML) do AWS thiết kế để mang lại hiệu suất giá tốt nhất trên quy mô lớn.
Trong bài đăng này, chúng tôi trình bày cách Gameskraft sử dụng Amazon Redshift chia sẻ dữ liệu cùng với quy mô đồng thời và Tối ưu hóa WLM để hỗ trợ khối lượng công việc phân tích ngày càng tăng của nó.
Trường hợp sử dụng Amazon Redshift
Gameskraft đã sử dụng Amazon Redshift Phiên bản RA3 với Bộ lưu trữ được quản lý Redshift (RMS) cho kho dữ liệu của họ. Đường dẫn dữ liệu ngược dòng là một hệ thống mạnh mẽ tích hợp nhiều nguồn dữ liệu khác nhau, bao gồm Amazon Kinesis và Truyền trực tuyến được quản lý của Amazon cho Apache Kafka (Amazon MSK) để xử lý các sự kiện nhấp chuột, Dịch vụ cơ sở dữ liệu quan hệ của Amazon (Amazon RDS) cho các giao dịch delta và Máy phát điện Amazon để biết thông tin liên quan đến trò chơi delta. Ngoài ra, dữ liệu được trích xuất từ API của nhà cung cấp bao gồm dữ liệu liên quan đến sản phẩm, tiếp thị và trải nghiệm của khách hàng. Tất cả dữ liệu đa dạng này sau đó được hợp nhất thành Dịch vụ lưu trữ đơn giản của Amazon Hồ dữ liệu (Amazon S3) trước khi được tải lên kho dữ liệu Redshift. Các nguồn dữ liệu ngược dòng này tạo thành các thành phần tạo dữ liệu.
Gameskraft đã sử dụng Amazon Redshift quản lý khối lượng công việc (WLM) để quản lý các mức độ ưu tiên trong khối lượng công việc, với mức độ ưu tiên cao hơn được gán cho hàng đợi trích xuất, chuyển đổi và tải (ETL) chạy các công việc quan trọng cho nhà sản xuất dữ liệu. Người tiêu dùng hạ nguồn bao gồm các công cụ thông minh kinh doanh (BI), với nhiều nhóm phân tích dữ liệu và khoa học dữ liệu có hàng đợi WLM riêng với các giá trị ưu tiên phù hợp.
Khi danh mục sản phẩm trò chơi của Gameskraft tăng lên, điều đó dẫn đến sự tăng trưởng xấp xỉ gấp năm lần của các nhóm khoa học dữ liệu và phân tích dữ liệu chuyên dụng. Do đó, số lượt tích hợp dữ liệu đã tăng gấp XNUMX lần và số truy vấn đặc biệt được gửi tới cụm Redshift tăng gấp XNUMX lần. Các mẫu truy vấn và tính đồng thời này về bản chất là không thể đoán trước được. Ngoài ra, theo thời gian, số lượng bảng thông tin BI (cả được lên lịch và đang hoạt động) tăng lên, góp phần khiến nhiều truy vấn được gửi tới cụm Redshift hơn.
Với khối lượng công việc ngày càng tăng này, Gameskraft đang gặp phải những thách thức sau:
- Tăng thời gian chạy công việc ETL quan trọng
- Tăng thời gian chờ truy vấn trong nhiều hàng đợi
- Tác động của khối lượng công việc truy vấn đặc biệt không thể đoán trước trên các hàng đợi khác trong cụm
Gameskraft đang tìm kiếm một giải pháp có thể giúp họ giảm thiểu tất cả những thách thức này và mang lại sự linh hoạt để mở rộng quy mô xử lý khối lượng công việc tiêu thụ và nhập một cách độc lập. Gameskraft cũng đang tìm kiếm một giải pháp có thể phục vụ cho sự phát triển khó lường trong tương lai của họ.
Tổng quan về giải pháp
Gameskraft đã giải quyết những thách thức này theo từng giai đoạn bằng cách sử dụng Mở rộng quy mô đồng thời của Amazon Redshift, Chia sẻ dữ liệu Amazon Redshift, Amazon Redshift không có máy chủvà các cụm được cung cấp Redshift.
Khả năng thay đổi quy mô đồng thời của Amazon Redshift cho phép bạn dễ dàng hỗ trợ hàng nghìn người dùng và truy vấn đồng thời cùng một lúc với hiệu suất truy vấn nhanh và ổn định. Khi tính đồng thời tăng lên, Amazon Redshift sẽ tự động bổ sung sức mạnh xử lý truy vấn trong vài giây để xử lý truy vấn mà không có bất kỳ độ trễ nào. Khi nhu cầu khối lượng công việc giảm xuống, sức mạnh xử lý bổ sung này sẽ tự động bị loại bỏ, do đó bạn chỉ phải trả tiền cho thời gian sử dụng cụm mở rộng quy mô đồng thời. Amazon Redshift cung cấp 1 giờ tín dụng mở rộng đồng thời miễn phí cho mỗi cụm hoạt động mỗi ngày, cho phép bạn tích lũy 30 giờ tín dụng miễn phí mỗi tháng.
Gameskraft cho phép mở rộng quy mô đồng thời trong hàng đợi WLM chọn lọc để giảm bớt thời gian chờ truy vấn trong các hàng đợi đó trong thời gian sử dụng cao điểm và cũng giúp giảm thời gian chạy truy vấn ETL. Trong thiết lập trước, chúng tôi đã duy trì bốn hàng đợi chuyên dụng cho ETL, truy vấn đặc biệt, công cụ BI và khoa học dữ liệu. Để tránh tắc nghẽn cho các quy trình khác, chúng tôi đã áp dụng thời gian chờ truy vấn tối thiểu bằng cách sử dụng quy tắc giám sát truy vấn (QMR). Tuy nhiên, cả hàng đợi công cụ ETL và BI đều liên tục bị chiếm dụng, ảnh hưởng đến hiệu suất của các hàng đợi còn lại.
Mở rộng quy mô đồng thời đã giúp giảm bớt thời gian chờ truy vấn trong hàng đợi truy vấn đặc biệt. Tuy nhiên, thách thức về khối lượng công việc tiêu thụ xuôi dòng (như truy vấn đặc biệt) ảnh hưởng đến quá trình nhập vẫn tồn tại và Gameskraft đang tìm kiếm giải pháp để quản lý các khối lượng công việc này một cách độc lập.
Bảng sau đây tóm tắt cấu hình quản lý khối lượng công việc trước khi triển khai giải pháp.
| Hàng đợi | Sử dụng | Chế độ mở rộng đồng thời | Đồng thời trên Main/Bộ nhớ % | Quy tắc giám sát truy vấn |
etl |
Để nhập từ tích hợp nhiều dữ liệu | off | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 2700 |
report |
Đối với mục đích báo cáo theo lịch trình | off | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 600 |
datascience |
Đối với khối lượng công việc khoa học dữ liệu | off | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 300 |
readonly |
Để phân tích đột xuất và hàng ngày | tự động | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 120 |
bi_tool |
Đối với công cụ BI | tự động | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 300 |
Để đạt được tính linh hoạt trong việc mở rộng quy mô, Gameskraft đã sử dụng Chia sẻ dữ liệu Amazon Redshift. Chia sẻ dữ liệu Amazon Redshift cho phép bạn mở rộng các lợi ích về tính dễ sử dụng, hiệu suất và chi phí do một cụm duy nhất mang lại sang triển khai nhiều cụm trong khi vẫn có thể chia sẻ dữ liệu. Chia sẻ dữ liệu cho phép truy cập dữ liệu tức thì, chi tiết và nhanh chóng trên toàn bộ kho dữ liệu của Amazon Redshift mà không cần sao chép hoặc di chuyển dữ liệu. Chia sẻ dữ liệu cung cấp quyền truy cập trực tiếp vào dữ liệu để người dùng luôn quan sát được thông tin nhất quán và cập nhật nhất khi được cập nhật trong kho dữ liệu. Bạn có thể chia sẻ dữ liệu trực tiếp một cách an toàn trên các cụm được cung cấp, điểm cuối không có máy chủ trong tài khoản AWS, trên các tài khoản AWS và trên khắp các Khu vực AWS.
Tính năng chia sẻ dữ liệu được xây dựng trên Bộ lưu trữ được quản lý Redshift (RMS), làm nền tảng cho các cụm được cung cấp RA3 và nhóm làm việc không có máy chủ, cho phép nhiều kho truy vấn cùng một dữ liệu bằng điện toán biệt lập riêng biệt. Các truy vấn truy cập dữ liệu được chia sẻ chạy trên cụm người tiêu dùng và đọc dữ liệu trực tiếp từ RMS mà không ảnh hưởng đến hiệu suất của cụm nhà sản xuất. Giờ đây, bạn có thể nhanh chóng triển khai khối lượng công việc với các kiểu truy cập dữ liệu đa dạng và yêu cầu SLA mà không phải lo lắng về tranh chấp tài nguyên.
Chúng tôi đã chọn chạy tất cả khối lượng công việc ETL trong cụm nhà sản xuất chính để quản lý ETL một cách độc lập. Chúng tôi đã sử dụng tính năng chia sẻ dữ liệu để chia sẻ quyền truy cập chỉ đọc vào dữ liệu với nhóm làm việc không có máy chủ khoa học dữ liệu, cụm được cung cấp BI, cụm được cung cấp truy vấn đặc biệt và nhóm làm việc không có máy chủ tích hợp dữ liệu. Sau đó, các nhóm sử dụng các tài nguyên điện toán riêng biệt này có thể truy vấn cùng một dữ liệu mà không cần sao chép dữ liệu giữa nhà sản xuất và người tiêu dùng. Ngoài ra, chúng tôi đã giới thiệu khả năng mở rộng đồng thời cho hàng đợi của người tiêu dùng, ưu tiên các công cụ BI và kéo dài thời gian chờ cho các hàng đợi còn lại. Những sửa đổi này đã nâng cao đáng kể hiệu quả và thông lượng tổng thể.
Bảng sau đây tóm tắt cấu hình quản lý khối lượng công việc mới cho cụm nhà sản xuất.
| Hàng đợi | Sử dụng | Chế độ mở rộng đồng thời | Đồng thời trên Main/Bộ nhớ % | Quy tắc giám sát truy vấn |
etl |
Để nhập từ tích hợp nhiều dữ liệu | tự động | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 3600 |
Bảng sau đây tóm tắt cấu hình quản lý khối lượng công việc mới cho cụm người tiêu dùng.
| Hàng đợi | Sử dụng | Chế độ mở rộng đồng thời | Đồng thời trên Main/Bộ nhớ % | Quy tắc giám sát truy vấn |
report |
Đối với mục đích báo cáo theo lịch trình | off | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 1200 Thời gian xếp hàng truy vấn (giây) > 1800 Số hàng quét phổ (hàng) > 100000 Quét phổ (MB) > 3072 |
datascience |
Đối với khối lượng công việc khoa học dữ liệu | off | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 600 Thời gian xếp hàng truy vấn (giây) > 1800 Số hàng quét phổ (hàng) > 100000 Quét phổ (MB) > 3072 |
readonly |
Để phân tích đột xuất và hàng ngày | tự động | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 900 Thời gian xếp hàng truy vấn (giây) > 3600 Quét phổ (MB) > 3072 Số hàng quét phổ (hàng) > 100000 |
bi_tool_live |
Đối với các công cụ BI trực tiếp | tự động | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 900 Thời gian xếp hàng truy vấn (giây) > 1800 Quét phổ (MB) > 1024 Số hàng quét phổ (hàng) > 1000 |
bi_tool_schedule |
Đối với các công cụ BI được lên lịch | tự động | tự động | Dừng hành động trên: Thời gian chạy truy vấn (giây) > 1800 Thời gian xếp hàng truy vấn (giây) > 3600 Quét phổ (MB) > 1024 Số hàng quét phổ (hàng) > 1000 |
Thực hiện giải pháp
Gameskraft chuyên tâm duy trì hoạt động của hệ thống không bị gián đoạn, ưu tiên các giải pháp liền mạch trong thời gian ngừng hoạt động. Để theo đuổi nguyên tắc này, các biện pháp chiến lược đã được thực hiện để đảm bảo quá trình di chuyển suôn sẻ hướng tới việc cho phép chia sẻ dữ liệu, bao gồm các bước sau:
- Lập kế hoạch:
- Sao chép người dùng và nhóm cho người tiêu dùng, để giảm thiểu các biến chứng truy cập tiềm ẩn cho các nhóm phân tích, khoa học dữ liệu và BI.
- Thiết lập thiết lập toàn diện cho người tiêu dùng, bao gồm các thành phần thiết yếu như lược đồ bên ngoài cho Quang phổ dịch chuyển đỏ Amazon.
- Tinh chỉnh cấu hình WLM phù hợp với yêu cầu của người tiêu dùng.
- Thực hiện:
- Giới thiệu bảng điều khiển giám sát chuyên sâu trong Grafana để sử dụng CPU, thông lượng đọc/ghi, IOPS và độ trễ dành riêng cho cụm người tiêu dùng, nâng cao khả năng giám sát.
- Thay đổi tất cả các bảng khóa xen kẽ trên cụm nhà sản xuất thành các bảng khóa sắp xếp phức hợp để chuyển đổi dữ liệu một cách liền mạch.
- Tạo một lược đồ bên ngoài từ cơ sở dữ liệu chia sẻ dữ liệu về người tiêu dùng, phản ánh lược đồ của cụm nhà sản xuất có tên giống hệt nhau. Cách tiếp cận này giảm thiểu nhu cầu thực hiện điều chỉnh truy vấn ở nhiều vị trí.
- Thử nghiệm:
- Tiến hành quy trình kiểm tra và kiểm tra hồi quy nội bộ kéo dài một tuần để xác thực tỉ mỉ tất cả các điểm dữ liệu bằng cách chạy cùng một khối lượng công việc và khối lượng công việc gấp đôi.
- Những thay đổi cuối cùng:
- Cập nhật bản ghi DNS cho điểm cuối cụm, bao gồm việc thay thế điểm cuối của cụm người tiêu dùng thành cùng một miền với điểm cuối của cụm nhà sản xuất, để hợp lý hóa các kết nối và tránh thực hiện thay đổi ở nhiều nơi.
- Đảm bảo bảo mật dữ liệu và kiểm soát truy cập bằng cách thu hồi các đặc quyền của nhóm và người dùng khỏi cụm nhà sản xuất.
Sơ đồ sau đây minh họa kiến trúc chia sẻ dữ liệu Gameskraft Amazon Redshift.
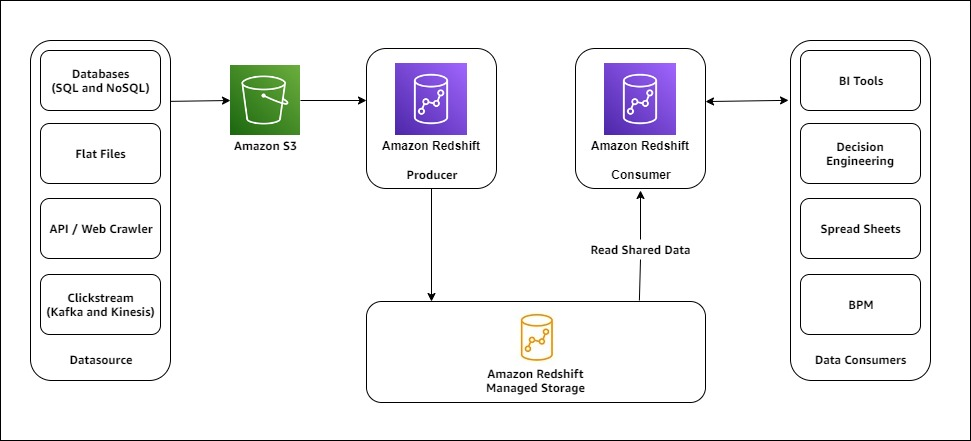
Sơ đồ sau đây minh họa kiến trúc chia sẻ dữ liệu của Amazon Redshift với nhiều cụm người tiêu dùng.
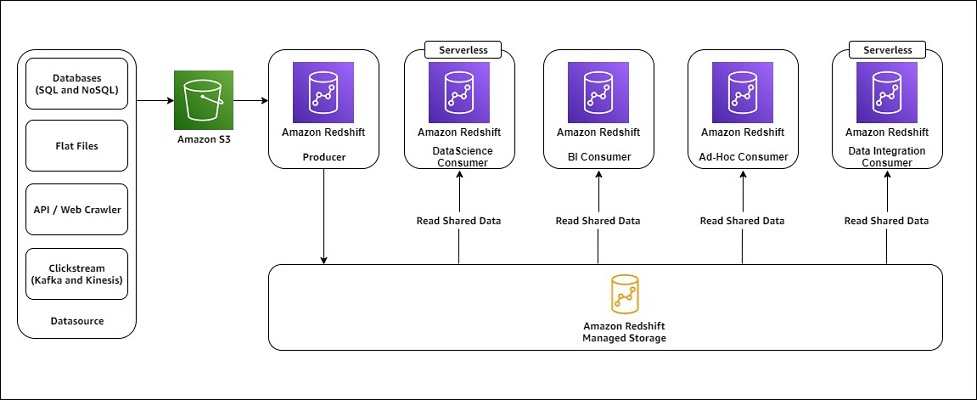
Với việc triển khai chia sẻ dữ liệu, Gameskraft đã có thể tách biệt khối lượng công việc của nhà sản xuất và người tiêu dùng. Chia sẻ dữ liệu cũng mang lại sự linh hoạt để mở rộng quy mô độc lập kho dữ liệu của nhà sản xuất và người tiêu dùng.
Việc triển khai giải pháp tổng thể đã giúp Gameskraft hỗ trợ làm mới dữ liệu thường xuyên hơn (giảm 43% thời gian chạy công việc tổng thể) cho khối lượng công việc ETL chạy trên cụm nhà sản xuất, cùng với khả năng hỗ trợ số lượng người dùng, BI ngày càng tăng (tăng gấp XNUMX lần). khối lượng công việc và truy vấn đặc biệt) và khối lượng công việc không thể đoán trước của người tiêu dùng.
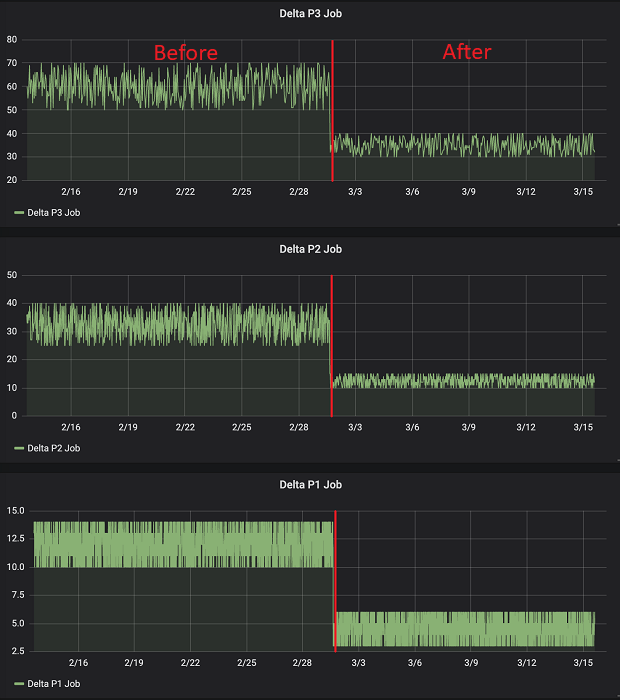
Các bảng thông tin sau hiển thị một số thời gian chạy quy trình ETL quan trọng (trước khi triển khai giải pháp và sau khi triển khai giải pháp).
Phần đầu tiên hiển thị công việc delta P1/P2/P3 chạy trước và sau khi triển khai giải pháp (thời lượng tính bằng phút).
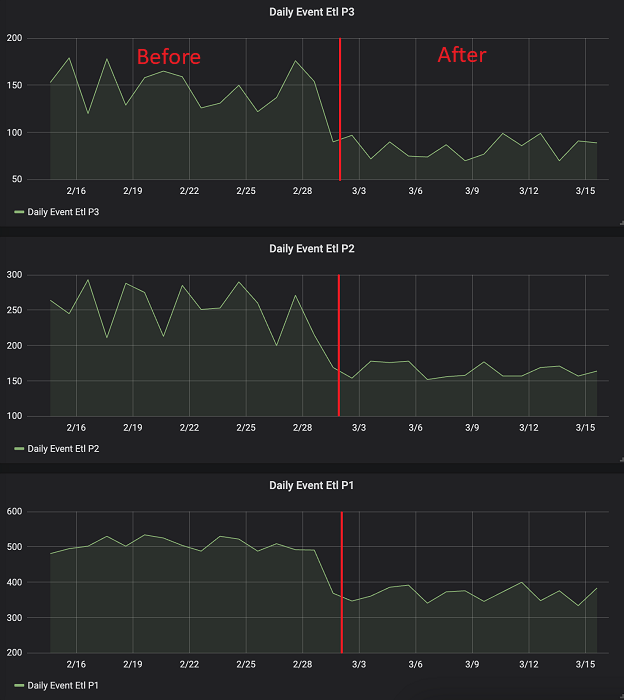
Phần sau đây hiển thị công việc ETL P1/P2/P3 sự kiện hàng ngày chạy trước và sau khi triển khai giải pháp (thời lượng tính bằng phút).
Cân nhắc chính
Gameskraft sử dụng kiến trúc dữ liệu hiện đại, với hồ dữ liệu nằm trong Amazon S3. Để cấp quyền truy cập liền mạch vào hồ dữ liệu, chúng tôi sử dụng các khả năng cải tiến của Redshift Spectrum, là cầu nối giữa kho dữ liệu (Amazon Redshift) và hồ dữ liệu (Amazon S3). Nó cho phép bạn thực hiện chuyển đổi và phân tích dữ liệu trực tiếp trên dữ liệu được lưu trữ trong Amazon S3 mà không cần phải sao chép dữ liệu vào cụm Redshift.
Gameskraft đã rút ra một số bài học quan trọng khi triển khai giải pháp chia sẻ dữ liệu này:
- Đầu tiên, tính đến thời điểm viết bài này, việc chia sẻ dữ liệu Amazon Redshift không hỗ trợ thêm các lược đồ, bảng bên ngoài hoặc chế độ xem liên kết muộn trên các bảng bên ngoài vào phần chia sẻ dữ liệu. Để kích hoạt tính năng này, chúng tôi đã tạo một lược đồ bên ngoài làm con trỏ tới Keo AWS cơ sở dữ liệu. Cơ sở dữ liệu AWS Glue tương tự được tham chiếu trong lược đồ bên ngoài về phía người tiêu dùng.
- Thứ hai, Amazon Redshift không hỗ trợ chia sẻ các bảng có khóa sắp xếp xen kẽ và các dạng xem tham chiếu đến các bảng có khóa sắp xếp xen kẽ. Do sự hiện diện của các khóa sắp xếp xen kẽ trên nhiều bảng và dạng xem, điều kiện tiên quyết để đưa vào chia sẻ dữ liệu bao gồm việc sửa đổi cấu hình khóa sắp xếp để sử dụng khóa sắp xếp kết hợp.
Kết luận
Trong bài đăng này, chúng ta đã biết cách Gameskraft sử dụng tính năng chia sẻ dữ liệu và mở rộng quy mô đồng thời trong Amazon Redshift với kiến trúc cụm nhà sản xuất và người tiêu dùng để đạt được những điều sau:
- Giảm thời gian chờ truy vấn cho tất cả hàng đợi trong nhà sản xuất và người tiêu dùng
- Mở rộng quy mô nhà sản xuất và người tiêu dùng một cách độc lập dựa trên khối lượng công việc và yêu cầu hàng đợi
- Cải thiện hiệu suất đường ống ETL và chu trình làm mới dữ liệu để hỗ trợ làm mới thường xuyên hơn trong cụm nhà sản xuất
- Tích hợp nhiều hàng đợi và khối lượng công việc hơn (hàng đợi công cụ BI, hàng đợi tích hợp dữ liệu, hàng đợi khoa học dữ liệu, hàng đợi của nhóm hạ nguồn, hàng đợi truy vấn đặc biệt) trong ứng dụng tiêu dùng mà không ảnh hưởng đến quy trình ETL trong cụm nhà sản xuất
- Tính linh hoạt để sử dụng nhiều người tiêu dùng với sự kết hợp giữa cụm Redshift được cung cấp và Redshift Serverless
Các tính năng và kiến trúc của Amazon Redshift này có thể giúp hỗ trợ khối lượng công việc phân tích ngày càng tăng và không thể dự đoán được.
Về các tác giả
 Anshuman Varshney là Trưởng nhóm kỹ thuật tại Gameskraft với nền tảng về cả kỹ thuật phụ trợ và dữ liệu. Ông có thành tích đã được chứng minh trong việc lãnh đạo và cố vấn cho các nhóm đa chức năng nhằm cung cấp các giải pháp có hiệu suất cao, có thể mở rộng. Ngoài công việc, anh tận hưởng những khoảnh khắc bên gia đình, đam mê trải nghiệm điện ảnh và tận dụng mọi cơ hội để khám phá những điểm đến mới thông qua du lịch.
Anshuman Varshney là Trưởng nhóm kỹ thuật tại Gameskraft với nền tảng về cả kỹ thuật phụ trợ và dữ liệu. Ông có thành tích đã được chứng minh trong việc lãnh đạo và cố vấn cho các nhóm đa chức năng nhằm cung cấp các giải pháp có hiệu suất cao, có thể mở rộng. Ngoài công việc, anh tận hưởng những khoảnh khắc bên gia đình, đam mê trải nghiệm điện ảnh và tận dụng mọi cơ hội để khám phá những điểm đến mới thông qua du lịch.
 Prafulla Wani là Kiến trúc sư giải pháp chuyên gia Amazon Redshift tại AWS. Anh ấy làm việc với khách hàng AWS về thiết kế kiến trúc phân tích và bằng chứng khái niệm của Amazon Redshift. Trong thời gian rảnh rỗi, anh chơi cờ với con trai.
Prafulla Wani là Kiến trúc sư giải pháp chuyên gia Amazon Redshift tại AWS. Anh ấy làm việc với khách hàng AWS về thiết kế kiến trúc phân tích và bằng chứng khái niệm của Amazon Redshift. Trong thời gian rảnh rỗi, anh chơi cờ với con trai.
 Saurov Nandy là Kiến trúc sư giải pháp tại AWS. Anh làm việc với khách hàng của AWS để thiết kế và triển khai các giải pháp giải quyết các vấn đề kinh doanh phức tạp. Khi rảnh rỗi, anh thích khám phá những địa điểm mới và đam mê chụp ảnh và chỉnh sửa video.
Saurov Nandy là Kiến trúc sư giải pháp tại AWS. Anh làm việc với khách hàng của AWS để thiết kế và triển khai các giải pháp giải quyết các vấn đề kinh doanh phức tạp. Khi rảnh rỗi, anh thích khám phá những địa điểm mới và đam mê chụp ảnh và chỉnh sửa video.
 Shashank Tewari là Giám đốc tài khoản kỹ thuật cấp cao tại AWS. Anh giúp khách hàng AWS tối ưu hóa kiến trúc của họ để đạt được hiệu suất, quy mô và hiệu quả chi phí. Khi rảnh rỗi, anh ấy thích chơi trò chơi điện tử với các con. Trong những kỳ nghỉ, anh ấy thích leo núi và tham gia các môn thể thao mạo hiểm.
Shashank Tewari là Giám đốc tài khoản kỹ thuật cấp cao tại AWS. Anh giúp khách hàng AWS tối ưu hóa kiến trúc của họ để đạt được hiệu suất, quy mô và hiệu quả chi phí. Khi rảnh rỗi, anh ấy thích chơi trò chơi điện tử với các con. Trong những kỳ nghỉ, anh ấy thích leo núi và tham gia các môn thể thao mạo hiểm.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/how-gameskraft-uses-amazon-redshift-data-sharing-to-support-growing-analytics-workloads/

