
Được tạo bằng Midjourney
Hội nghị NeurIPS 2023, được tổ chức tại thành phố New Orleans sôi động từ ngày 10 đến ngày 16 tháng XNUMX, đặc biệt nhấn mạnh vào AI tổng quát và các mô hình ngôn ngữ lớn (LLM). Trước những tiến bộ mang tính đột phá gần đây trong lĩnh vực này, không có gì ngạc nhiên khi những chủ đề này chiếm ưu thế trong các cuộc thảo luận.
Một trong những chủ đề cốt lõi của hội nghị năm nay là tìm kiếm các hệ thống AI hiệu quả hơn. Các nhà nghiên cứu và nhà phát triển đang tích cực tìm cách xây dựng AI không chỉ học nhanh hơn LLM hiện tại mà còn sở hữu khả năng suy luận nâng cao trong khi tiêu tốn ít tài nguyên máy tính hơn. Việc theo đuổi này rất quan trọng trong cuộc đua hướng tới đạt được Trí tuệ nhân tạo tổng hợp (AGI), một mục tiêu dường như ngày càng có thể đạt được trong tương lai gần.
Các cuộc đàm phán được mời tại NeurIPS 2023 phản ánh những mối quan tâm năng động và phát triển nhanh chóng này. Những người thuyết trình từ nhiều lĩnh vực nghiên cứu AI khác nhau đã chia sẻ những thành tựu mới nhất của họ, đưa ra cơ hội tiếp cận những phát triển AI tiên tiến. Trong bài viết này, chúng tôi đi sâu vào các cuộc nói chuyện này, trích xuất và thảo luận về những bài học và bài học quan trọng, cần thiết để hiểu được bối cảnh hiện tại và tương lai của đổi mới AI.
NextGenAI: Ảo tưởng về khả năng mở rộng quy mô và tương lai của AI sáng tạo
In cuộc nói chuyện của anh ấy, Björn Ommer, Trưởng nhóm Học tập & Thị giác Máy tính tại Đại học Ludwig Maximilian ở Munich, đã chia sẻ cách phòng thí nghiệm của ông phát triển Khuếch tán ổn định, một số bài học họ học được từ quá trình này và những phát triển gần đây, bao gồm cả cách chúng ta có thể kết hợp các mô hình khuếch tán với khớp luồng, tăng cường truy xuất và xấp xỉ LoRA, cùng với những thứ khác.
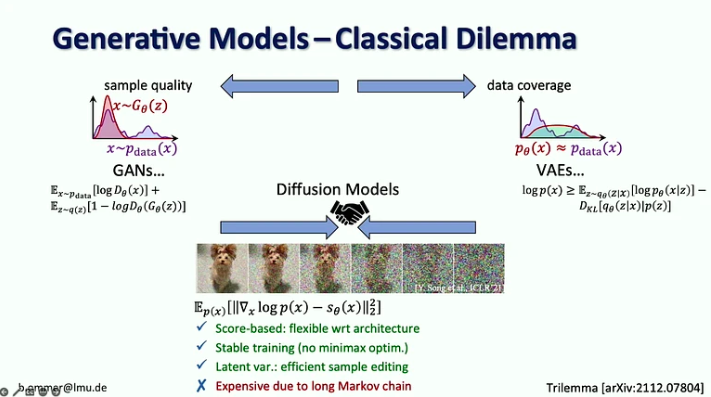
Những điểm chính:
- Trong thời đại AI sáng tạo, chúng tôi đã chuyển từ tập trung vào nhận thức trong các mô hình thị giác (tức là nhận dạng đối tượng) sang dự đoán những phần còn thiếu (ví dụ: tạo hình ảnh và video bằng các mô hình khuếch tán).
- Trong 20 năm, thị giác máy tính đã tập trung vào nghiên cứu điểm chuẩn, giúp tập trung vào những vấn đề nổi bật nhất. Trong Generative AI, chúng tôi không có bất kỳ điểm chuẩn nào để tối ưu hóa, điều này mở ra cơ hội cho mọi người đi theo hướng riêng của họ.
- Các mô hình khuếch tán kết hợp các ưu điểm của các mô hình tổng quát trước đó bằng cách dựa trên điểm số với quy trình huấn luyện ổn định và chỉnh sửa mẫu hiệu quả, nhưng chúng đắt tiền do chuỗi Markov dài.
- Thách thức với các mô hình có khả năng xảy ra cao là hầu hết các bit đều đi vào các chi tiết mà mắt người khó có thể cảm nhận được, trong khi việc mã hóa ngữ nghĩa, điều quan trọng nhất, chỉ mất một vài bit. Chỉ mở rộng quy mô sẽ không giải quyết được vấn đề này vì nhu cầu về tài nguyên máy tính đang tăng nhanh hơn 9 lần so với nguồn cung GPU.
- Giải pháp được đề xuất là kết hợp các điểm mạnh của mô hình Khuếch tán và ConvNet, đặc biệt là hiệu quả của các phép tích chập để thể hiện chi tiết cục bộ và tính biểu cảm của các mô hình Khuếch tán cho bối cảnh tầm xa.
- Björn Ommer cũng đề xuất sử dụng phương pháp kết hợp dòng chảy để cho phép tổng hợp hình ảnh có độ phân giải cao từ các mô hình khuếch tán tiềm ẩn nhỏ.
- Một cách tiếp cận khác để tăng hiệu quả tổng hợp hình ảnh là tập trung vào bố cục cảnh trong khi sử dụng tăng cường truy xuất để điền chi tiết.
- Cuối cùng, anh ấy đã giới thiệu phương pháp iPoke để tổng hợp video ngẫu nhiên có kiểm soát.
Nếu nội dung chuyên sâu này hữu ích cho bạn, đăng ký vào danh sách gửi thư AI của chúng tôi để được cảnh báo khi chúng tôi phát hành tài liệu mới.
Nhiều khía cạnh của AI có trách nhiệm
In bài thuyết trình của cô ấyLora Aroyo, Nhà khoa học nghiên cứu tại Google Research, đã nhấn mạnh một hạn chế chính trong các phương pháp học máy truyền thống: sự phụ thuộc của chúng vào việc phân loại dữ liệu nhị phân làm ví dụ tích cực hoặc tiêu cực. Cô lập luận rằng sự đơn giản hóa quá mức này đã bỏ qua tính chủ quan phức tạp vốn có trong các kịch bản và nội dung trong thế giới thực. Thông qua nhiều trường hợp sử dụng khác nhau, Aroyo đã chứng minh sự mơ hồ về nội dung và sự khác biệt tự nhiên trong quan điểm của con người thường dẫn đến những bất đồng không thể tránh khỏi. Cô nhấn mạnh tầm quan trọng của việc coi những bất đồng này như những tín hiệu có ý nghĩa chứ không phải chỉ là tiếng ồn.

Dưới đây là những điểm chính rút ra từ buổi nói chuyện:
- Sự bất đồng giữa những người lao động của con người có thể mang lại hiệu quả. Thay vì coi tất cả các câu trả lời là đúng hoặc sai, Lora Aroyo đã giới thiệu “sự thật bằng sự không đồng tình”, một cách tiếp cận sự thật phân bổ để đánh giá độ tin cậy của dữ liệu bằng cách khai thác sự bất đồng của người đánh giá.
- Chất lượng dữ liệu khó khăn ngay cả với các chuyên gia vì các chuyên gia không đồng ý nhiều như những người làm việc trong đám đông. Những bất đồng này có thể mang lại nhiều thông tin hơn so với phản hồi từ một chuyên gia.
- Trong nhiệm vụ đánh giá an toàn, các chuyên gia không đồng ý với 40% ví dụ. Thay vì cố gắng giải quyết những bất đồng này, chúng ta cần thu thập thêm những ví dụ như vậy và sử dụng chúng để cải thiện mô hình và thước đo đánh giá.
- Lora Aroyo cũng trình bày An toàn với sự đa dạng phương pháp xem xét kỹ lưỡng dữ liệu về nội dung trong đó và ai đã chú thích nó.
- Phương pháp này tạo ra một tập dữ liệu chuẩn với sự thay đổi trong các đánh giá an toàn LLM giữa các nhóm người xếp hạng nhân khẩu học khác nhau (tổng cộng 2.5 triệu xếp hạng).
- Đối với 20% cuộc trò chuyện, rất khó để quyết định liệu phản hồi của chatbot là An toàn hay Không an toàn, vì có số lượng người trả lời gần như bằng nhau gắn nhãn chúng là an toàn hoặc không an toàn.
- Sự đa dạng của người xếp hạng và dữ liệu đóng một vai trò quan trọng trong việc đánh giá các mô hình. Việc không thừa nhận nhiều quan điểm khác nhau của con người và sự mơ hồ trong nội dung có thể cản trở sự liên kết giữa hiệu suất học máy với những kỳ vọng trong thế giới thực.
- 80% nỗ lực đảm bảo an toàn cho AI vốn đã khá tốt, nhưng 20% còn lại đòi hỏi nỗ lực gấp đôi để giải quyết các trường hợp nguy hiểm và tất cả các biến thể trong không gian đa dạng vô tận.
Số liệu thống kê mạch lạc, trải nghiệm tự tạo và lý do tại sao con người trẻ tuổi thông minh hơn nhiều so với AI hiện tại
In cuộc nói chuyện của cô ấy, Linda Smith, Giáo sư xuất sắc tại Đại học Indiana Bloomington, đã khám phá chủ đề về sự thưa thớt dữ liệu trong quá trình học tập của trẻ sơ sinh và trẻ nhỏ. Cô đặc biệt tập trung vào nhận dạng đối tượng và học tên, đi sâu vào cách số liệu thống kê về trải nghiệm tự tạo của trẻ sơ sinh đưa ra các giải pháp tiềm năng cho thách thức về sự thưa thớt dữ liệu.
Những điểm chính:
- Đến ba tuổi, trẻ đã phát triển khả năng học một lần trong nhiều lĩnh vực khác nhau. Trong vòng chưa đầy 16,000 giờ thức dậy trước sinh nhật lần thứ tư, các em đã học được hơn 1,000 loại đồ vật, nắm vững cú pháp của ngôn ngữ mẹ đẻ và tiếp thu các sắc thái văn hóa và xã hội của môi trường.
- Tiến sĩ Linda Smith và nhóm của bà đã phát hiện ra ba nguyên tắc học tập của con người cho phép trẻ em tiếp thu được rất nhiều điều từ những dữ liệu thưa thớt như vậy:
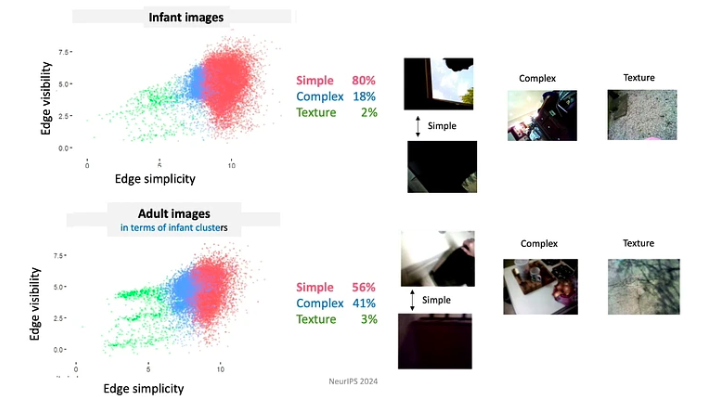
- Người học kiểm soát đầu vào, trong từng thời điểm họ đang định hình và cấu trúc đầu vào. Ví dụ, trong những tháng đầu đời, trẻ có xu hướng nhìn nhiều hơn vào những đồ vật có cạnh đơn giản.
- Vì trẻ sơ sinh liên tục phát triển về kiến thức và khả năng nên chúng phải tuân theo một chương trình giảng dạy rất hạn chế. Dữ liệu họ tiếp xúc được tổ chức theo những cách có ý nghĩa sâu sắc. Ví dụ, trẻ dưới 4 tháng dành nhiều thời gian nhất để nhìn vào khuôn mặt, khoảng 15 phút mỗi giờ, trong khi những trẻ lớn hơn 12 tháng tập trung chủ yếu vào tay, quan sát chúng trong khoảng 20 phút mỗi giờ.
- Các giai đoạn học tập bao gồm một loạt các trải nghiệm được kết nối với nhau. Các mối tương quan về không gian và thời gian tạo ra sự gắn kết, từ đó tạo điều kiện thuận lợi cho việc hình thành những ký ức lâu dài về các sự kiện xảy ra một lần. Ví dụ, khi được đưa ra một loại đồ chơi ngẫu nhiên, trẻ thường tập trung vào một số đồ chơi “yêu thích”. Trẻ tương tác với những đồ chơi này bằng cách sử dụng các mô hình lặp đi lặp lại, giúp trẻ học các đồ vật nhanh hơn.
- Ký ức thoáng qua (đang hoạt động) tồn tại lâu hơn thông tin đầu vào từ giác quan. Các thuộc tính giúp nâng cao quá trình học tập bao gồm tính đa phương thức, mối liên kết, mối quan hệ dự đoán và kích hoạt ký ức trong quá khứ.
- Để học nhanh, bạn cần có sự liên minh giữa các cơ chế tạo ra dữ liệu và các cơ chế học hỏi.
Phác thảo: các công cụ cốt lõi, tăng cường học tập và khả năng thích ứng mạnh mẽ
Jelani Nelson, Giáo sư Kỹ thuật Điện và Khoa học Máy tính tại UC Berkeley, giới thiệu khái niệm về 'bản phác thảo' dữ liệu – biểu diễn tập dữ liệu được nén trong bộ nhớ vẫn cho phép trả lời các truy vấn hữu ích. Mặc dù bài nói chuyện khá mang tính kỹ thuật nhưng nó đã cung cấp một cái nhìn tổng quan tuyệt vời về một số công cụ phác thảo cơ bản, bao gồm cả những tiến bộ gần đây.
Những điểm chính:
- CountSketch, công cụ phác thảo cốt lõi, được giới thiệu lần đầu tiên vào năm 2002 để giải quyết vấn đề về 'những người đánh giá cao', báo cáo một danh sách nhỏ các mục thường xuyên nhất từ dòng mục nhất định. CountSketch là thuật toán tuyến tính con đầu tiên được biết đến được sử dụng cho mục đích này.
- Hai ứng dụng không phát trực tuyến của những người chơi hạng nặng bao gồm:
- Phương pháp dựa trên điểm bên trong (IPM) đưa ra thuật toán tiệm cận nhanh nhất được biết đến cho lập trình tuyến tính.
- Phương pháp HyperAttention giải quyết thách thức tính toán đặt ra do độ phức tạp ngày càng tăng của các ngữ cảnh dài được sử dụng trong LLM.
- Nhiều công việc gần đây đã tập trung vào việc thiết kế các bản phác thảo có khả năng tương tác thích ứng mạnh mẽ. Ý tưởng chính là sử dụng những hiểu biết sâu sắc từ phân tích dữ liệu thích ứng.
Ngoài bảng điều chỉnh tỷ lệ
T bảng điều khiển tuyệt vời về các mô hình ngôn ngữ lớn được kiểm duyệt bởi Alexander Rush, Phó giáo sư tại Cornell Tech và là nhà nghiên cứu tại Ôm mặt. Những người tham gia khác bao gồm:
- Aakanksha Chowdhery – Nhà khoa học nghiên cứu tại Google DeepMind với mối quan tâm nghiên cứu về hệ thống, đào tạo trước LLM và đa phương thức. Cô ấy là thành viên của nhóm phát triển PaLM, Gemini và Pathways.
- Angela Fan – Nhà khoa học nghiên cứu tại Meta Generative AI với mối quan tâm nghiên cứu về sự liên kết, trung tâm dữ liệu và đa ngôn ngữ. Cô đã tham gia phát triển Llama-2 và Meta AI Assistant.
- Percy Liang – Giáo sư tại Stanford nghiên cứu về người sáng tạo, nguồn mở và tác nhân tạo. Ông là Giám đốc Trung tâm Nghiên cứu Mô hình Nền tảng (CRFM) tại Stanford và là người sáng lập Together AI.
Cuộc thảo luận tập trung vào bốn chủ đề chính: (1) kiến trúc và kỹ thuật, (2) dữ liệu và sự liên kết, (3) đánh giá và tính minh bạch, và (4) người sáng tạo và cộng tác viên.
Dưới đây là một số điều rút ra được từ bảng này:
- Việc đào tạo các mô hình ngôn ngữ hiện nay vốn không khó. Thách thức chính trong việc đào tạo một mô hình như Llama-2-7b nằm ở yêu cầu cơ sở hạ tầng và nhu cầu phối hợp giữa nhiều GPU, trung tâm dữ liệu, v.v. Tuy nhiên, nếu số lượng tham số đủ nhỏ để cho phép đào tạo trên một GPU, ngay cả một sinh viên đại học cũng có thể quản lý nó.
- Mặc dù các mô hình tự hồi quy thường được sử dụng để tạo văn bản và mô hình khuếch tán để tạo hình ảnh và video, nhưng đã có những thử nghiệm đảo ngược các phương pháp này. Cụ thể, trong dự án Gemini, mô hình tự hồi quy được sử dụng để tạo hình ảnh. Cũng đã có những khám phá về việc sử dụng các mô hình khuếch tán để tạo văn bản, nhưng những mô hình này vẫn chưa được chứng minh là đủ hiệu quả.
- Do dữ liệu tiếng Anh cho các mô hình đào tạo còn hạn chế nên các nhà nghiên cứu đang khám phá các phương pháp thay thế. Một khả năng là đào tạo các mô hình đa phương thức về sự kết hợp giữa văn bản, video, hình ảnh và âm thanh với mong muốn rằng các kỹ năng học được từ các phương thức thay thế này có thể chuyển sang văn bản. Một lựa chọn khác là sử dụng dữ liệu tổng hợp. Điều quan trọng cần lưu ý là dữ liệu tổng hợp thường trộn lẫn với dữ liệu thực, nhưng việc tích hợp này không phải là ngẫu nhiên. Văn bản được xuất bản trực tuyến thường trải qua quá trình tuyển chọn và chỉnh sửa của con người, điều này có thể tăng thêm giá trị cho việc đào tạo mô hình.
- Các mô hình nền tảng mở thường được coi là có lợi cho sự đổi mới nhưng có khả năng gây hại cho sự an toàn của AI vì chúng có thể bị các tác nhân độc hại khai thác. Tuy nhiên, Tiến sĩ Percy Liang cho rằng các mô hình mở cũng đóng góp tích cực cho sự an toàn. Ông lập luận rằng bằng cách có thể truy cập được, chúng mang lại cho nhiều nhà nghiên cứu cơ hội tiến hành nghiên cứu về an toàn AI và xem xét các mô hình để tìm các lỗ hổng tiềm ẩn.
- Ngày nay, dữ liệu chú thích đòi hỏi nhiều chuyên môn hơn trong lĩnh vực chú thích so với XNUMX năm trước. Tuy nhiên, nếu trợ lý AI hoạt động như mong đợi trong tương lai, chúng ta sẽ nhận được nhiều dữ liệu phản hồi có giá trị hơn từ người dùng, giảm sự phụ thuộc vào dữ liệu mở rộng từ người chú thích.
Hệ thống cho các mô hình nền tảng và Mô hình nền tảng cho các hệ thống
In cuộc nói chuyện này, Christopher Ré, Phó Giáo sư tại Khoa Khoa học Máy tính tại Đại học Stanford, cho thấy các mô hình nền tảng đã thay đổi hệ thống chúng ta xây dựng như thế nào. Anh cũng khám phá cách xây dựng các mô hình nền tảng một cách hiệu quả, mượn những hiểu biết sâu sắc từ nghiên cứu hệ thống cơ sở dữ liệu và thảo luận về các kiến trúc có khả năng hiệu quả hơn cho các mô hình nền tảng so với Transformer.
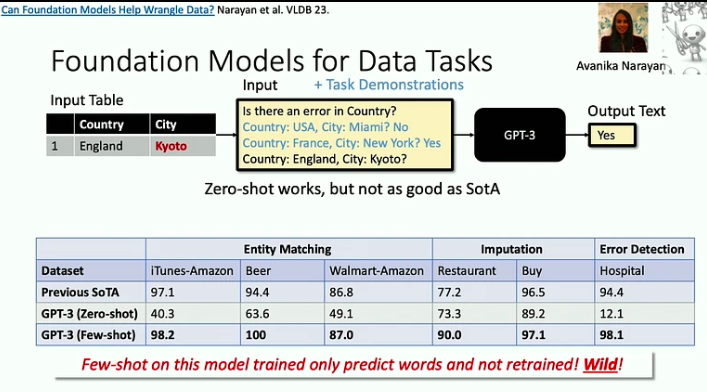
Dưới đây là những điểm chính rút ra từ buổi nói chuyện này:
- Các mô hình nền tảng có hiệu quả trong việc giải quyết các vấn đề 'tử vong do 1000 lần cắt giảm', trong đó mỗi nhiệm vụ riêng lẻ có thể tương đối đơn giản, nhưng độ rộng và sự đa dạng của các nhiệm vụ lại là một thách thức đáng kể. Một ví dụ điển hình cho điều này là vấn đề làm sạch dữ liệu mà LLM hiện có thể giúp giải quyết hiệu quả hơn nhiều.
- Khi máy gia tốc trở nên nhanh hơn, bộ nhớ thường xuất hiện như một nút thắt cổ chai. Đây là vấn đề mà các nhà nghiên cứu cơ sở dữ liệu đã giải quyết trong nhiều thập kỷ và chúng ta có thể áp dụng một số chiến lược của họ. Ví dụ: phương pháp Chú ý nhanh giảm thiểu luồng đầu vào-đầu ra thông qua việc chặn và tổng hợp tích cực: bất cứ khi nào chúng tôi truy cập vào một phần thông tin, chúng tôi sẽ thực hiện nhiều thao tác trên đó nhất có thể.
- Có một lớp kiến trúc mới, bắt nguồn từ việc xử lý tín hiệu, có thể hiệu quả hơn mô hình Transformer, đặc biệt là trong việc xử lý các chuỗi dài. Việc xử lý tín hiệu mang lại sự ổn định và hiệu quả, đặt nền tảng cho các mẫu máy cải tiến như S4.
Học tăng cường trực tuyến trong các can thiệp sức khỏe kỹ thuật số
In cuộc nói chuyện của cô ấySusan Murphy, Giáo sư Thống kê và Khoa học Máy tính tại Đại học Harvard, đã chia sẻ những giải pháp đầu tiên cho một số thách thức mà họ gặp phải trong việc phát triển thuật toán RL trực tuyến để sử dụng trong các biện pháp can thiệp sức khỏe kỹ thuật số.
Dưới đây là một số điều rút ra từ bài thuyết trình:
- Tiến sĩ Susan Murphy đã thảo luận về hai dự án mà cô đang thực hiện:
- HeartStep, nơi các hoạt động được đề xuất dựa trên dữ liệu từ điện thoại thông minh và thiết bị theo dõi có thể đeo được, và
- Thuốc uống để huấn luyện sức khỏe răng miệng, trong đó các biện pháp can thiệp dựa trên dữ liệu tương tác nhận được từ bàn chải đánh răng điện tử.
- Khi phát triển chính sách hành vi cho tác nhân AI, các nhà nghiên cứu phải đảm bảo rằng chính sách đó có tính tự chủ và có thể được triển khai khả thi trong hệ thống chăm sóc sức khỏe rộng hơn. Điều này đòi hỏi phải đảm bảo rằng thời gian cần thiết cho sự tham gia của một cá nhân là hợp lý và các hành động được đề xuất vừa hợp lý về mặt đạo đức vừa hợp lý về mặt khoa học.
- Những thách thức chính trong việc phát triển tác nhân RL cho các biện pháp can thiệp sức khỏe kỹ thuật số bao gồm xử lý mức độ tiếng ồn cao, vì mọi người sống cuộc sống của họ và không phải lúc nào cũng có thể trả lời tin nhắn, ngay cả khi họ muốn, cũng như quản lý các tác động tiêu cực mạnh và chậm trễ. .
Như bạn có thể thấy, NeurIPS 2023 đã mang đến cái nhìn sáng tỏ về tương lai của AI. Các cuộc tọa đàm được mời đã nêu bật xu hướng hướng tới các mô hình hiệu quả hơn, tiết kiệm tài nguyên hơn và khám phá các kiến trúc mới ngoài các mô hình truyền thống.
Thưởng thức bài viết này? Đăng ký để cập nhật thêm nghiên cứu AI.
Chúng tôi sẽ cho bạn biết khi chúng tôi phát hành thêm các bài viết tóm tắt như thế này.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.topbots.com/neurips-2023-invited-talks/

