Hình ảnh của Tác giả
Phân tích dữ liệu thăm dò (hoặc EDA) là giai đoạn cốt lõi trong Quy trình phân tích dữ liệu, nhấn mạnh việc điều tra kỹ lưỡng về các chi tiết và đặc điểm bên trong của tập dữ liệu.
Mục đích chính của nó là khám phá các mẫu cơ bản, nắm bắt cấu trúc của tập dữ liệu và xác định mọi điểm bất thường hoặc mối quan hệ tiềm ẩn giữa các biến.
Bằng cách thực hiện EDA, các chuyên gia dữ liệu sẽ kiểm tra chất lượng của dữ liệu. Do đó, nó đảm bảo rằng các phân tích sâu hơn dựa trên thông tin chính xác và sâu sắc, từ đó giảm khả năng xảy ra sai sót trong các giai đoạn tiếp theo.
Vì vậy, chúng ta hãy cùng nhau cố gắng hiểu các bước cơ bản để thực hiện một EDA tốt cho dự án Khoa học dữ liệu tiếp theo của chúng ta là gì.
Tôi khá chắc chắn rằng bạn đã từng nghe cụm từ:
Rác vào, rác ra
Chất lượng dữ liệu đầu vào luôn là yếu tố quan trọng nhất cho bất kỳ dự án dữ liệu thành công nào.
Thật không may, hầu hết dữ liệu ban đầu đều là dữ liệu bẩn. Thông qua quá trình Phân tích dữ liệu khám phá, một tập dữ liệu gần như có thể sử dụng được có thể được chuyển đổi thành một tập dữ liệu hoàn toàn có thể sử dụng được.
Điều quan trọng cần làm rõ là đây không phải là giải pháp kỳ diệu để lọc bất kỳ tập dữ liệu nào. Tuy nhiên, nhiều chiến lược EDA có hiệu quả trong việc giải quyết một số vấn đề điển hình gặp phải trong bộ dữ liệu.
Vậy… hãy cùng tìm hiểu những bước cơ bản nhất theo Ayodele Oluleye trong cuốn sách Phân tích dữ liệu khám phá với Python Cookbook của anh ấy.
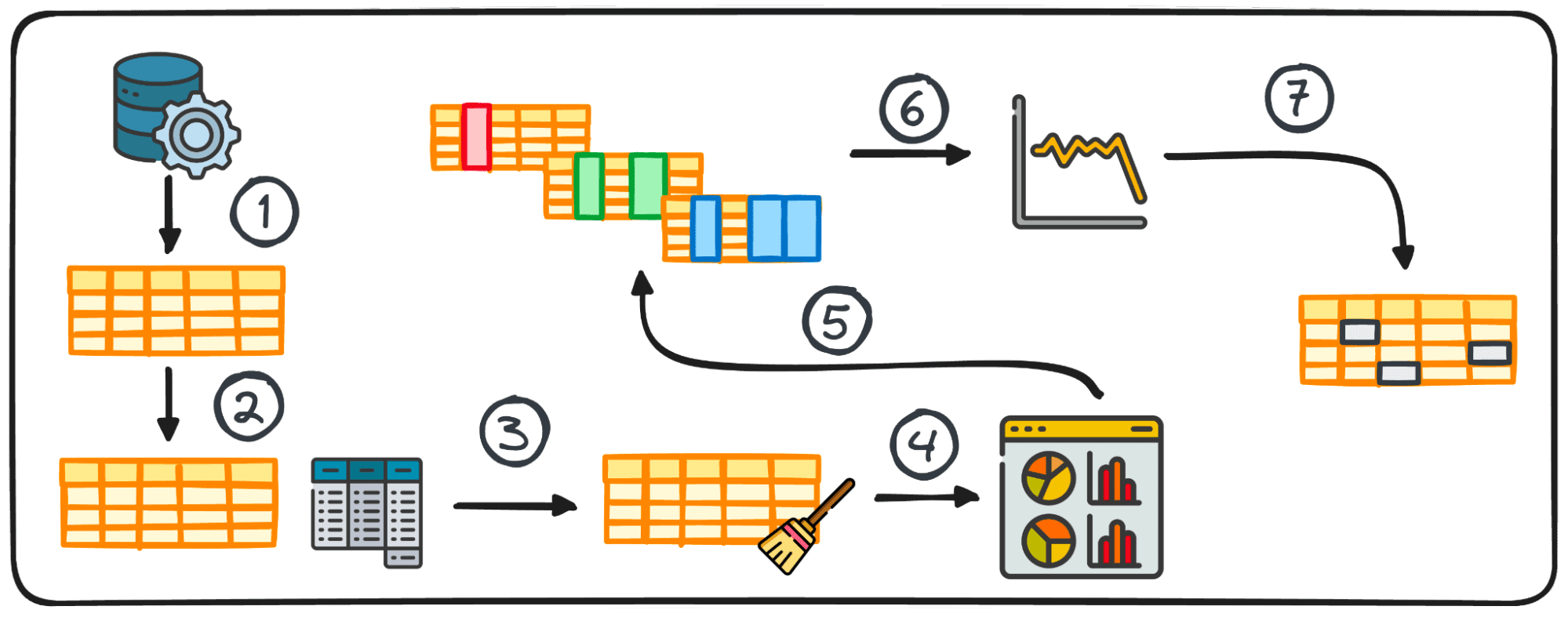
Bước 1: Thu thập dữ liệu
Bước đầu tiên trong bất kỳ dự án dữ liệu nào là có chính dữ liệu đó. Bước đầu tiên này là nơi dữ liệu được thu thập từ nhiều nguồn khác nhau để phân tích tiếp theo.
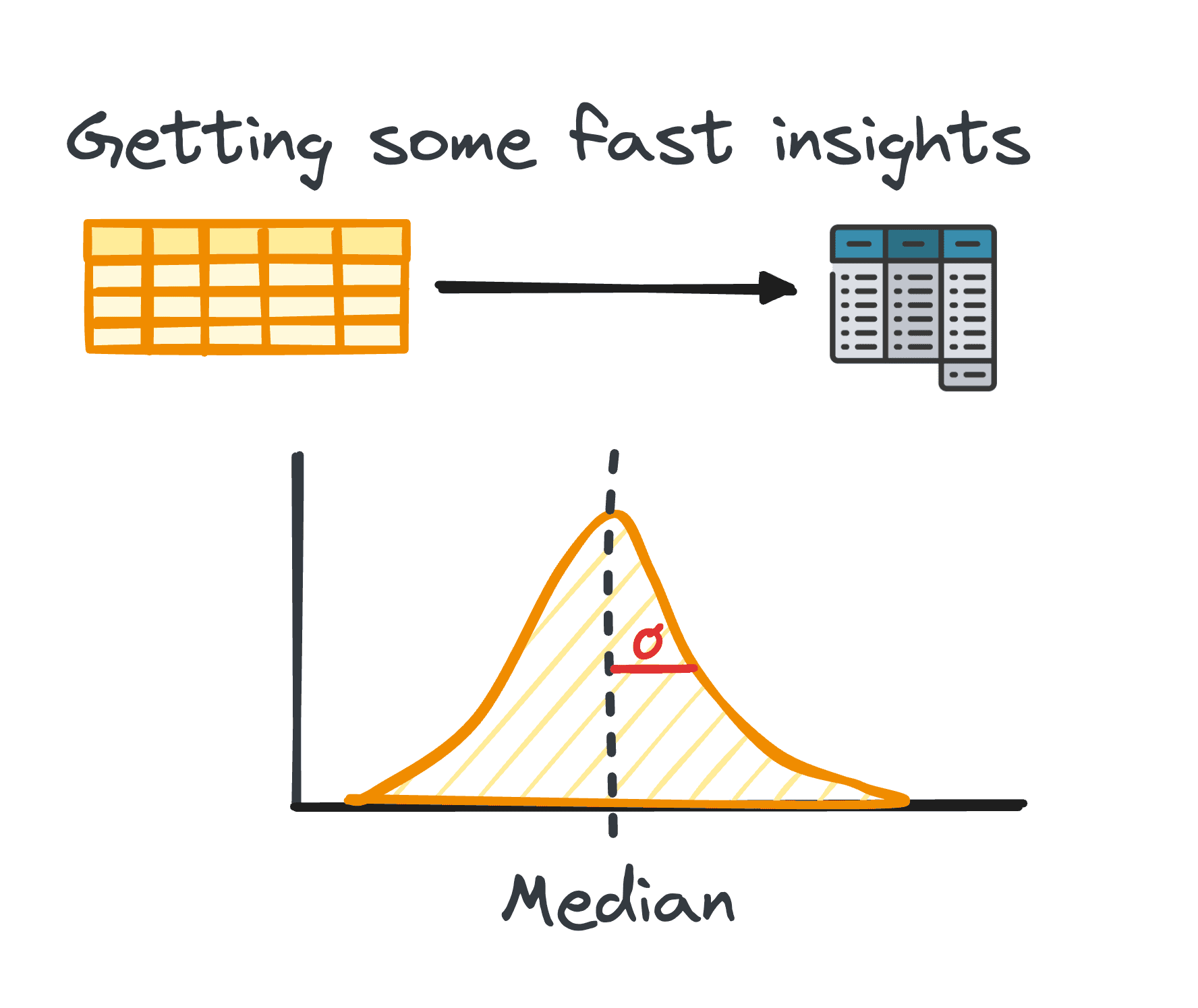
2. Thống kê tóm tắt
Trong phân tích dữ liệu, việc xử lý dữ liệu dạng bảng khá phổ biến. Trong quá trình phân tích dữ liệu đó, thường cần phải có được những hiểu biết nhanh chóng về mô hình và sự phân bổ của dữ liệu.
Những hiểu biết ban đầu này đóng vai trò là cơ sở để khám phá sâu hơn và phân tích chuyên sâu và được gọi là số liệu thống kê tóm tắt.
Chúng cung cấp một cái nhìn tổng quan ngắn gọn về cách phân phối và các mẫu của tập dữ liệu, được gói gọn thông qua các số liệu như giá trị trung bình, trung vị, chế độ, phương sai, độ lệch chuẩn, phạm vi, phần trăm và phần tư.
Hình ảnh của Tác giả
3. Chuẩn bị dữ liệu cho EDA
Trước khi bắt đầu khám phá, dữ liệu thường cần được chuẩn bị để phân tích thêm. Chuẩn bị dữ liệu bao gồm việc chuyển đổi, tổng hợp hoặc làm sạch dữ liệu bằng thư viện pandas của Python để phù hợp với nhu cầu phân tích của bạn.
Bước này được điều chỉnh theo cấu trúc của dữ liệu và có thể bao gồm việc nhóm, nối thêm, hợp nhất, sắp xếp, phân loại và xử lý các bản sao.
Trong Python, việc hoàn thành nhiệm vụ này được thư viện pandas hỗ trợ thông qua các mô-đun khác nhau.
Quá trình chuẩn bị dữ liệu dạng bảng không tuân theo một phương pháp chung; thay vào đó, nó được định hình bởi các đặc điểm cụ thể của dữ liệu của chúng tôi, bao gồm các hàng, cột, loại dữ liệu và các giá trị chứa trong đó.
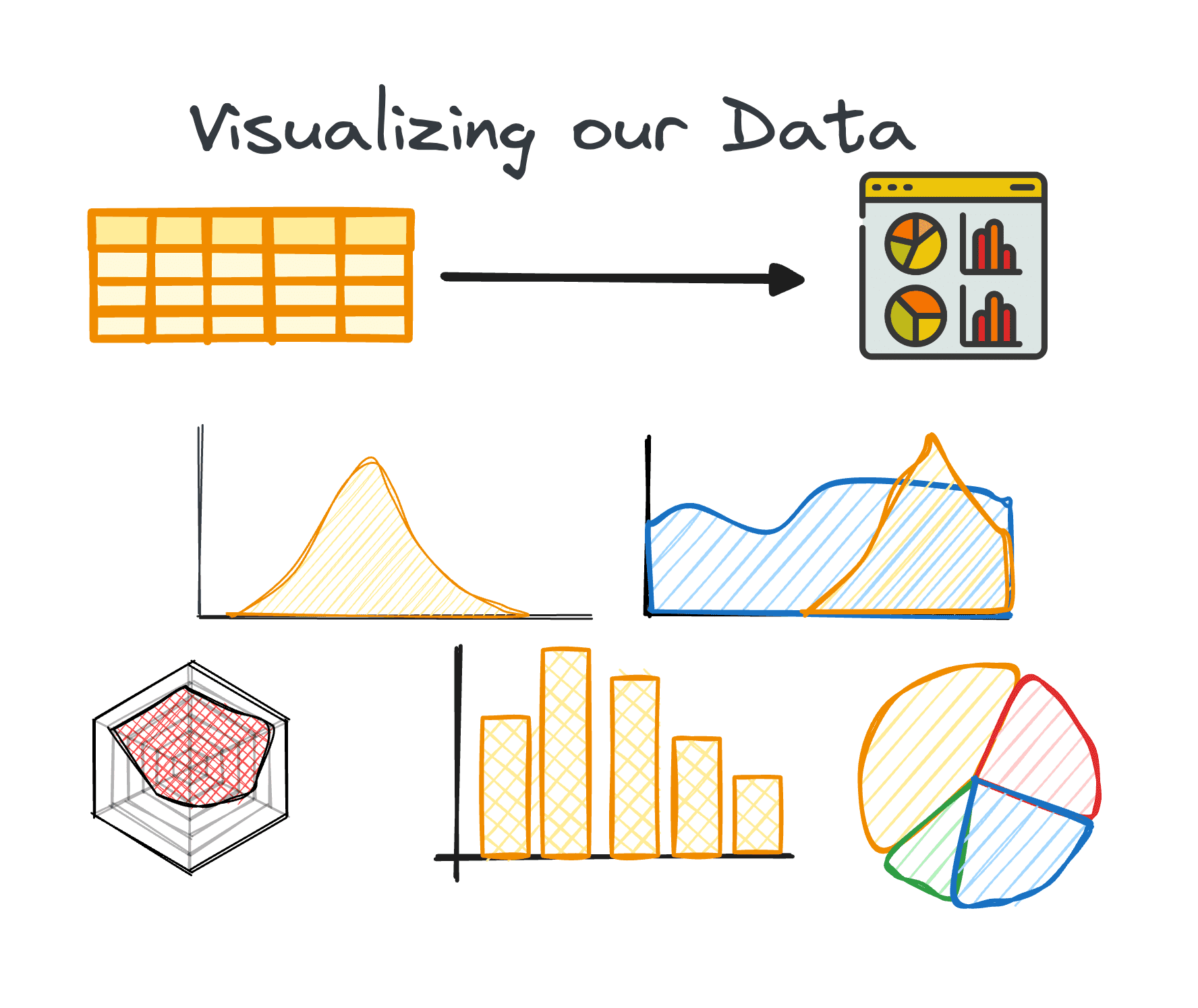
4. Trực quan hóa dữ liệu
Trực quan hóa là thành phần cốt lõi của EDA, giúp dễ dàng hiểu được các mối quan hệ và xu hướng phức tạp trong tập dữ liệu.
Việc sử dụng biểu đồ phù hợp có thể giúp chúng tôi xác định xu hướng trong một tập dữ liệu lớn và tìm ra các mẫu hoặc ngoại lệ ẩn. Python cung cấp các thư viện khác nhau để trực quan hóa dữ liệu, bao gồm Matplotlib hoặc Seaborn cùng nhiều thư viện khác.
Hình ảnh của Tác giả
5. Thực hiện phân tích biến:
Phân tích biến có thể là đơn biến, hai biến hoặc đa biến. Mỗi trong số chúng cung cấp cái nhìn sâu sắc về sự phân bố và mối tương quan giữa các biến của tập dữ liệu. Các kỹ thuật khác nhau tùy thuộc vào số lượng biến được phân tích:
Đơn biến
Trọng tâm chính trong phân tích đơn biến là kiểm tra từng biến trong tập dữ liệu của chúng tôi. Trong quá trình phân tích này, chúng tôi có thể khám phá những thông tin chuyên sâu như giá trị trung bình, chế độ, mức tối đa, phạm vi và giá trị ngoại lệ.
Kiểu phân tích này có thể áp dụng cho cả biến phân loại và biến số.
Sinh đôi
Phân tích hai biến nhằm mục đích tiết lộ những hiểu biết sâu sắc giữa hai biến được chọn và tập trung vào việc tìm hiểu sự phân phối và mối quan hệ giữa hai biến này.
Khi chúng tôi phân tích hai biến cùng lúc, loại phân tích này có thể phức tạp hơn. Nó có thể bao gồm ba cặp biến khác nhau: số-số, số-phân loại và phân loại-phân loại.
Đa biến
Một thách thức thường gặp với các tập dữ liệu lớn là việc phân tích đồng thời nhiều biến. Mặc dù các phương pháp phân tích đơn biến và hai biến cung cấp những hiểu biết có giá trị nhưng điều này thường không đủ để phân tích các tập dữ liệu chứa nhiều biến (thường là nhiều hơn năm biến).
Vấn đề quản lý dữ liệu nhiều chiều này, thường được gọi là lời nguyền của chiều, đã được ghi chép rõ ràng. Việc có số lượng lớn các biến có thể có lợi vì nó cho phép khai thác được nhiều thông tin chi tiết hơn. Đồng thời, lợi thế này có thể gây bất lợi cho chúng tôi do số lượng kỹ thuật sẵn có để phân tích hoặc hiển thị đồng thời nhiều biến số còn hạn chế.
6. Phân tích dữ liệu chuỗi thời gian
Bước này tập trung vào việc kiểm tra các điểm dữ liệu được thu thập trong khoảng thời gian đều đặn. Dữ liệu chuỗi thời gian áp dụng cho dữ liệu thay đổi theo thời gian. Về cơ bản, điều này có nghĩa là tập dữ liệu của chúng tôi bao gồm một nhóm điểm dữ liệu được ghi lại theo các khoảng thời gian đều đặn.
Khi chúng tôi phân tích dữ liệu chuỗi thời gian, chúng tôi thường có thể phát hiện ra các mô hình hoặc xu hướng lặp lại theo thời gian và thể hiện tính thời vụ theo thời gian. Các thành phần chính của dữ liệu chuỗi thời gian bao gồm xu hướng, biến đổi theo mùa, biến đổi theo chu kỳ và biến thể hoặc nhiễu không đều.
7. Xử lý các giá trị ngoại lệ và giá trị bị thiếu
Các giá trị ngoại lệ và giá trị bị thiếu có thể làm sai lệch kết quả phân tích nếu không được xử lý đúng cách. Đây là lý do tại sao chúng ta nên luôn xem xét từng giai đoạn để giải quyết chúng.
Việc xác định, loại bỏ hoặc thay thế các điểm dữ liệu này là rất quan trọng để duy trì tính toàn vẹn của phân tích dữ liệu. Do đó, điều cực kỳ quan trọng là phải giải quyết chúng trước khi bắt đầu phân tích dữ liệu của chúng tôi.
- Các ngoại lệ là các điểm dữ liệu có độ lệch đáng kể so với phần còn lại. Chúng thường có giá trị cao hoặc thấp bất thường.
- Giá trị bị thiếu là sự vắng mặt của các điểm dữ liệu tương ứng với một biến hoặc quan sát cụ thể.
Bước đầu tiên quan trọng trong việc xử lý các giá trị bị thiếu và các giá trị ngoại lệ là hiểu lý do tại sao chúng có mặt trong tập dữ liệu. Sự hiểu biết này thường hướng dẫn việc lựa chọn phương pháp phù hợp nhất để giải quyết chúng. Các yếu tố bổ sung cần xem xét là đặc điểm của dữ liệu và phân tích cụ thể sẽ được tiến hành.
EDA không chỉ nâng cao tính rõ ràng của tập dữ liệu mà còn cho phép các chuyên gia dữ liệu điều hướng lời nguyền về chiều bằng cách cung cấp các chiến lược quản lý tập dữ liệu với nhiều biến số.
Thông qua các bước tỉ mỉ này, EDA với Python trang bị cho các nhà phân tích những công cụ cần thiết để rút ra những hiểu biết sâu sắc có ý nghĩa từ dữ liệu, tạo nền tảng vững chắc cho tất cả các nỗ lực phân tích dữ liệu tiếp theo.
Josep Ferrer là một kỹ sư phân tích từ Barcelona. Anh tốt nghiệp kỹ sư vật lý và hiện đang làm việc trong lĩnh vực Khoa học dữ liệu ứng dụng cho khả năng di chuyển của con người. Anh ấy là người sáng tạo nội dung bán thời gian tập trung vào khoa học dữ liệu và công nghệ. Bạn có thể liên hệ với anh ấy trên LinkedIn, Twitter or Trung bình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/7-steps-to-mastering-exploratory-data-analysis?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-mastering-exploratory-data-analysis

