Quy trình công việc được quản lý của Amazon cho Luồng khí Apache (Amazon MWAA) là dịch vụ điều phối được quản lý dành cho Luồng khí Apache mà bạn có thể sử dụng để thiết lập và vận hành đường dẫn dữ liệu trên đám mây ở quy mô lớn. Apache Airflow là một công cụ nguồn mở được sử dụng để lập trình, lên lịch và giám sát các chuỗi quy trình và nhiệm vụ, được gọi là Luồng công việc. Với Amazon MWAA, bạn có thể sử dụng Apache Airflow và Python để tạo quy trình công việc mà không cần phải quản lý cơ sở hạ tầng cơ bản về khả năng mở rộng, tính khả dụng và bảo mật.
Bằng cách sử dụng nhiều tài khoản AWS, các tổ chức có thể mở rộng quy mô khối lượng công việc của mình một cách hiệu quả và quản lý độ phức tạp khi chúng phát triển. Cách tiếp cận này cung cấp một cơ chế mạnh mẽ để giảm thiểu tác động tiềm tàng của sự gián đoạn hoặc lỗi, đảm bảo rằng khối lượng công việc quan trọng vẫn hoạt động. Ngoài ra, nó còn cho phép tối ưu hóa chi phí bằng cách sắp xếp các nguồn lực cho phù hợp với các trường hợp sử dụng cụ thể, đảm bảo rằng chi phí được kiểm soát tốt. Bằng cách tách biệt khối lượng công việc với các yêu cầu bảo mật hoặc nhu cầu tuân thủ cụ thể, các tổ chức có thể duy trì mức độ bảo mật và quyền riêng tư dữ liệu ở mức cao nhất. Hơn nữa, khả năng tổ chức nhiều tài khoản AWS theo cách có cấu trúc cho phép bạn điều chỉnh các quy trình và tài nguyên kinh doanh theo các yêu cầu về hoạt động, quy định và ngân sách riêng của bạn. Cách tiếp cận này thúc đẩy tính hiệu quả, tính linh hoạt và khả năng mở rộng, cho phép các doanh nghiệp lớn đáp ứng nhu cầu ngày càng tăng và đạt được mục tiêu của họ.
Bài đăng này trình bày cách sắp xếp một đường ống trích xuất, chuyển đổi và tải (ETL) từ đầu đến cuối bằng cách sử dụng Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), Keo AWSvà Amazon Redshift không có máy chủ với Amazon MWAA.
Tổng quan về giải pháp
Đối với bài đăng này, chúng tôi xem xét trường hợp sử dụng trong đó nhóm kỹ thuật dữ liệu muốn xây dựng quy trình ETL và mang lại trải nghiệm tốt nhất cho người dùng cuối khi họ muốn truy vấn dữ liệu mới nhất sau khi các tệp thô mới được thêm vào Amazon S3 ở trung tâm tài khoản (Tài khoản A trong sơ đồ kiến trúc sau). Nhóm kỹ thuật dữ liệu muốn tách dữ liệu thô vào tài khoản AWS của riêng mình (Tài khoản B trong sơ đồ) để tăng cường bảo mật và kiểm soát. Họ cũng muốn thực hiện công việc xử lý và chuyển đổi dữ liệu trong tài khoản của chính họ (Tài khoản B) để phân chia nhiệm vụ và ngăn chặn mọi thay đổi ngoài ý muốn đối với dữ liệu thô nguồn có trong tài khoản trung tâm (Tài khoản A). Cách tiếp cận này cho phép nhóm xử lý dữ liệu thô được trích xuất từ Tài khoản A sang Tài khoản B, dành riêng cho các tác vụ xử lý dữ liệu. Điều này đảm bảo dữ liệu thô và đã xử lý có thể được duy trì tách biệt an toàn trên nhiều tài khoản, nếu cần, để tăng cường quản trị và bảo mật dữ liệu.
Giải pháp của chúng tôi sử dụng quy trình ETL đầu cuối được điều phối bởi Amazon MWAA để tìm kiếm các tệp gia tăng mới ở vị trí Amazon S3 trong Tài khoản A, nơi có dữ liệu thô. Việc này được thực hiện bằng cách gọi các tác vụ AWS Glue ETL và ghi vào đối tượng dữ liệu trong cụm Redshift Serverless trong Tài khoản B. Sau đó, quy trình bắt đầu chạy thủ tục lưu trữ và các lệnh SQL trên Redshift Serverless. Khi các truy vấn chạy xong, một BỎ TẢI hoạt động được gọi từ kho dữ liệu Redshift tới bộ chứa S3 trong Tài khoản A.
Vì bảo mật rất quan trọng nên bài đăng này cũng đề cập đến cách định cấu hình kết nối Airflow bằng cách sử dụng Quản lý bí mật AWS để tránh lưu trữ thông tin xác thực cơ sở dữ liệu trong các biến và kết nối Airflow.
Sơ đồ sau đây minh họa tổng quan về kiến trúc của các thành phần liên quan đến việc điều phối quy trình công việc.
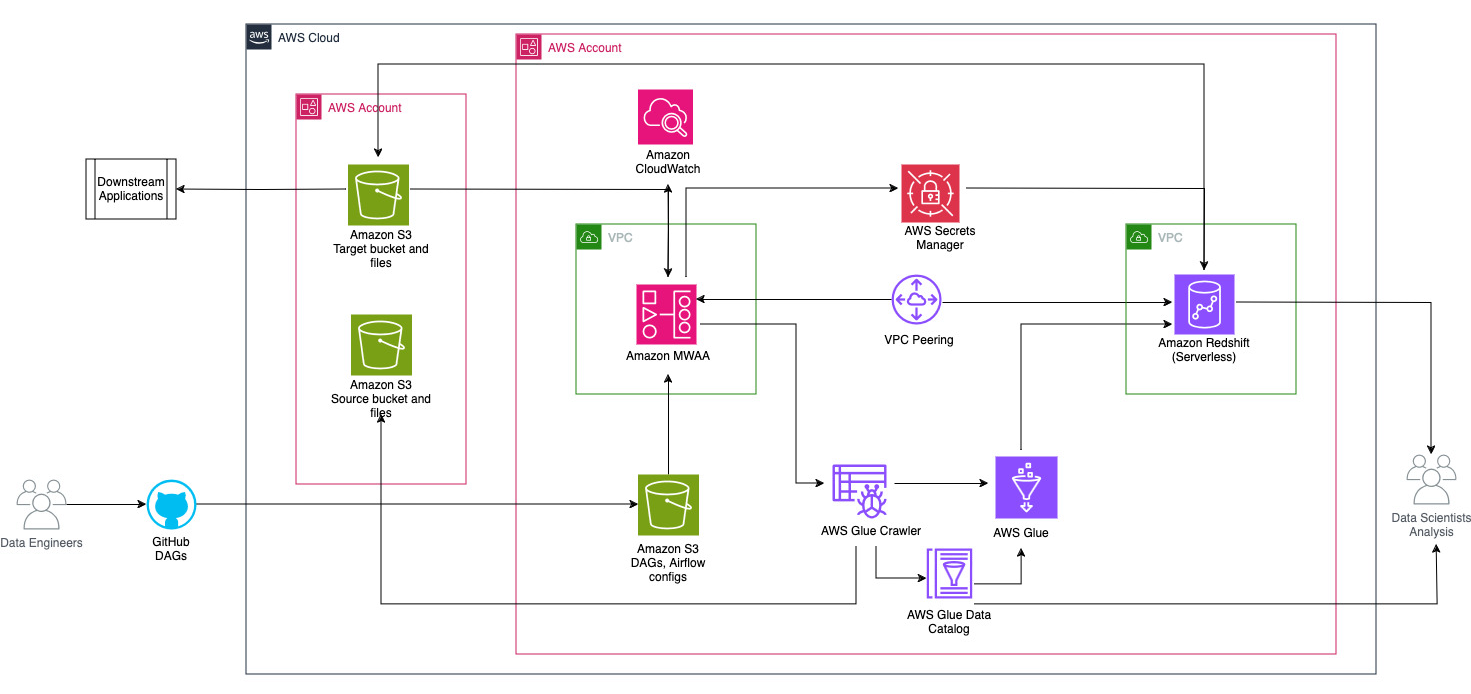
Quy trình làm việc bao gồm các thành phần sau:
- Nhóm S3 nguồn và đích nằm trong tài khoản trung tâm (Tài khoản A), trong khi Amazon MWAA, AWS Glue và Amazon Redshift nằm trong một tài khoản khác (Tài khoản B). Quyền truy cập nhiều tài khoản đã được thiết lập giữa các nhóm S3 trong Tài khoản A với các tài nguyên trong Tài khoản B để có thể tải và dỡ dữ liệu.
- Trong tài khoản thứ hai, Amazon MWAA được lưu trữ trên một VPC và Redshift Serverless trên một VPC khác, được kết nối thông qua VPC ngang hàng. Nhóm làm việc Redshift Serverless được bảo mật bên trong các mạng con riêng tư trên ba Vùng sẵn sàng.
- Các bí mật như tên người dùng, mật khẩu, cổng DB và Khu vực AWS dành cho Redshift Serverless được lưu trữ trong Secrets Manager.
- Điểm cuối VPC được tạo để Amazon S3 và Secrets Manager tương tác với các tài nguyên khác.
- Thông thường, các kỹ sư dữ liệu tạo Đồ thị tuần hoàn theo hướng luồng không khí (DAG) và gửi các thay đổi của họ cho GitHub. Với các hành động GitHub, chúng được triển khai vào vùng lưu trữ S3 trong Tài khoản B (đối với bài đăng này, chúng tôi tải tệp trực tiếp lên vùng lưu trữ S3). Nhóm S3 lưu trữ các tệp liên quan đến luồng không khí như tệp DAG,
requirements.txttập tin và plugin. Các tập lệnh và nội dung AWS Glue ETL được lưu trữ trong một bộ chứa S3 khác. Sự tách biệt này giúp duy trì tổ chức và tránh nhầm lẫn. - Airflow DAG sử dụng nhiều toán tử, cảm biến, kết nối, tác vụ và quy tắc khác nhau để chạy đường ống dữ liệu khi cần.
- Nhật ký luồng khí được đăng nhập amazoncloudwatchvà cảnh báo có thể được cấu hình cho các tác vụ giám sát. Để biết thêm thông tin, xem Giám sát bảng thông tin và cảnh báo trên Amazon MWAA.
Điều kiện tiên quyết
Vì giải pháp này xoay quanh việc sử dụng Amazon MWAA để điều phối quy trình ETL nên bạn cần thiết lập trước một số tài nguyên cơ bản nhất định trên các tài khoản. Cụ thể, bạn cần tạo các nhóm và thư mục S3, tài nguyên AWS Glue và tài nguyên Redshift Serverless trong các tài khoản tương ứng trước khi triển khai tích hợp quy trình công việc đầy đủ bằng Amazon MWAA.
Triển khai tài nguyên trong Tài khoản A bằng AWS CloudFormation
Trong Tài khoản A, khởi chạy được cung cấp Hình thành đám mây AWS ngăn xếp để tạo các tài nguyên sau:
- Các nhóm và thư mục S3 nguồn và đích. Theo cách thực hành tốt nhất, cấu trúc nhóm đầu vào và đầu ra được định dạng bằng phân vùng kiểu tổ ong như
s3://<bucket>/products/YYYY/MM/DD/. - Một tập dữ liệu mẫu có tên
products.csv, mà chúng tôi sử dụng trong bài viết này.
![]()
Tải tác vụ AWS Glue lên Amazon S3 trong Tài khoản B
Trong Tài khoản B, tạo một vị trí Amazon S3 có tên aws-glue-assets-<account-id>-<region>/scripts (nếu không có mặt). Thay thế các thông số cho ID tài khoản và Khu vực trong sample_glue_job.py tập lệnh và tải tệp công việc AWS Glue lên vị trí Amazon S3.
Triển khai tài nguyên trong Tài khoản B bằng AWS CloudFormation
Trong Tài khoản B, khởi chạy mẫu ngăn xếp CloudFormation được cung cấp để tạo các tài nguyên sau:
- Nhóm S3
airflow-<username>-bucketđể lưu trữ các tệp liên quan đến Luồng khí với cấu trúc sau:- ngu xuẩn – Thư mục chứa file DAG.
- bổ sung – Tệp dành cho mọi plugin Airflow tùy chỉnh hoặc cộng đồng.
- yêu cầu -
requirements.txttệp cho bất kỳ gói Python nào. - kịch bản – Bất kỳ tập lệnh SQL nào được sử dụng trong DAG.
- dữ liệu – Bất kỳ bộ dữ liệu nào được sử dụng trong DAG.
- Một môi trường Redshift Serverless. Tên của nhóm làm việc và không gian tên có tiền tố là
sample. - Môi trường AWS Glue chứa những nội dung sau:
- Keo AWS thu thập thông tin, thu thập dữ liệu từ nhóm nguồn S3
sample-inp-bucket-etl-<username>trong tài khoản A - Một cơ sở dữ liệu được gọi là
products_dbtrong Danh mục dữ liệu AWS Glue. - Một ELT việc làm gọi là
sample_glue_job. Công việc này có thể đọc các tập tin từproductsbảng trong Danh mục dữ liệu và tải dữ liệu vào bảng Redshiftproducts.
- Keo AWS thu thập thông tin, thu thập dữ liệu từ nhóm nguồn S3
- Điểm cuối cổng VPC tới Amazon S3.
- Một môi trường Amazon MWAA. Để biết các bước chi tiết nhằm tạo môi trường Amazon MWAA bằng bảng điều khiển Amazon MWAA, hãy tham khảo Giới thiệu Quy trình làm việc được quản lý của Amazon cho Apache Airflow (MWAA).
![]()
Tạo tài nguyên Amazon Redshift
Tạo hai bảng và một thủ tục được lưu trữ trên nhóm làm việc Redshift Serverless bằng cách sử dụng sản phẩm.sql tập tin.
Trong ví dụ này, chúng ta tạo hai bảng có tên products và products_f. Tên của thủ tục được lưu trữ là sp_products.
Định cấu hình quyền của Airflow
Sau khi môi trường Amazon MWAA được tạo thành công, trạng thái sẽ hiển thị là Có Sẵn. Chọn Mở giao diện người dùng luồng khí để xem giao diện người dùng Airflow. DAG được tự động đồng bộ hóa từ nhóm S3 và hiển thị trong giao diện người dùng. Tuy nhiên, ở giai đoạn này, không có DAG nào trong thư mục S3.
Thêm chính sách do khách hàng quản lý AmazonMWAAFullConsoleAccess, cấp cho người dùng Airflow quyền truy cập Quản lý truy cập và nhận dạng AWS (IAM) và đính kèm chính sách này với vai trò Amazon MWAA. Để biết thêm thông tin, xem Truy cập môi trường Amazon MWAA.
Các chính sách gắn liền với vai trò Amazon MWAA có toàn quyền truy cập và chỉ được sử dụng cho mục đích thử nghiệm trong môi trường thử nghiệm an toàn. Để triển khai sản xuất, hãy tuân theo nguyên tắc đặc quyền tối thiểu.
Thiết lập môi trường
Phần này phác thảo các bước để cấu hình môi trường. Quá trình này bao gồm các bước cấp cao sau:
- Cập nhật bất kỳ nhà cung cấp cần thiết.
- Thiết lập quyền truy cập nhiều tài khoản.
- Thiết lập kết nối ngang hàng VPC giữa Amazon MWAA VPC và Amazon Redshift VPC.
- Định cấu hình Trình quản lý bí mật để tích hợp với Amazon MWAA.
- Xác định kết nối luồng không khí.
Cập nhật các nhà cung cấp
Hãy làm theo các bước trong phần này nếu phiên bản Amazon MWAA của bạn nhỏ hơn 2.8.1 (phiên bản mới nhất tính đến thời điểm viết bài này).
Nhà cung cấp là các gói được cộng đồng duy trì và bao gồm tất cả các toán tử cốt lõi, móc nối và cảm biến cho một dịch vụ nhất định. Nhà cung cấp Amazon được sử dụng để tương tác với các dịch vụ AWS như Amazon S3, Amazon Redshift Serverless, AWS Glue, v.v. Có hơn 200 mô-đun trong nhà cung cấp Amazon.
Mặc dù phiên bản Airflow được hỗ trợ trong Amazon MWAA là 2.6.3, đi kèm với gói phiên bản 8.2.0 do Amazon cung cấp, nhưng hỗ trợ cho Amazon Redshift Serverless không được thêm vào cho đến khi Amazon cung cấp phiên bản gói 8.4.0. Vì phiên bản nhà cung cấp đi kèm mặc định cũ hơn so với thời điểm hỗ trợ Redshift Serverless được giới thiệu nên phiên bản nhà cung cấp phải được nâng cấp để sử dụng chức năng đó.
Bước đầu tiên là cập nhật tệp ràng buộc và requirements.txt tập tin với các phiên bản chính xác. tham khảo Chỉ định các gói nhà cung cấp mới hơn để biết các bước cập nhật gói nhà cung cấp Amazon.
- Nêu rõ các yêu cầu như sau:
- Cập nhật phiên bản trong tệp ràng buộc lên 8.4.0 trở lên.
- Thêm ràng buộc-3.11-update.txt nộp vào
/dagsthư mục.
Tham khảo Các phiên bản Apache Airflow trên Amazon Managed Workflow dành cho Apache Airflow để biết phiên bản chính xác của tệp ràng buộc tùy thuộc vào phiên bản Airflow.
- Điều hướng đến môi trường Amazon MWAA và chọn Chỉnh sửa.
- Theo Mã DAG trong Amazon S3, Cho Hồ sơ yêu cầu, chọn phiên bản mới nhất.
- Chọn Lưu.
Điều này sẽ cập nhật môi trường và các nhà cung cấp mới sẽ có hiệu lực.
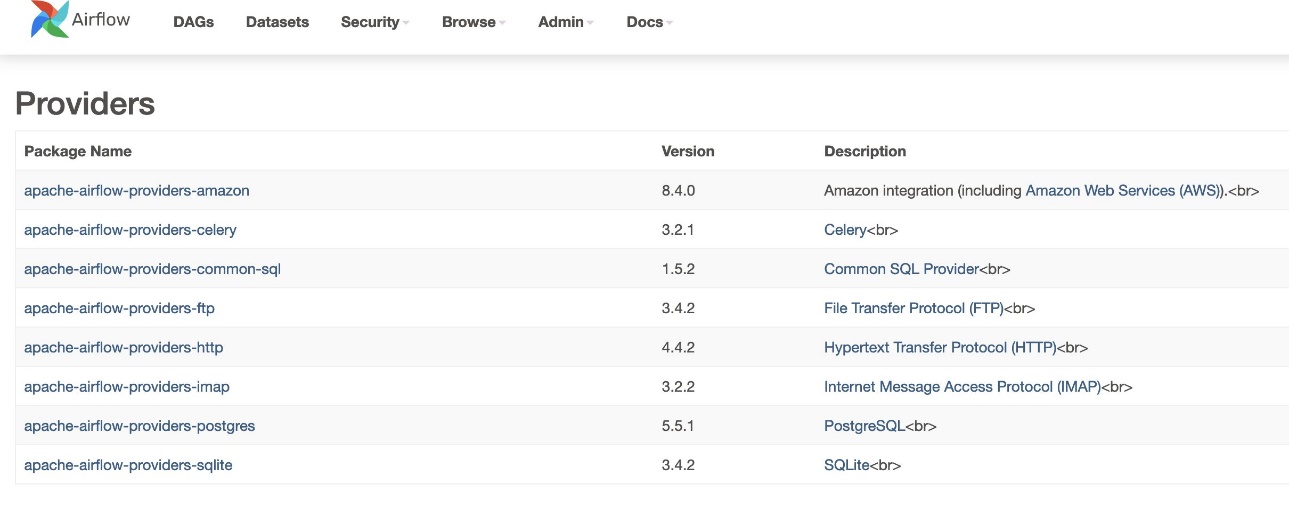
- Để xác minh phiên bản của nhà cung cấp, hãy truy cập Nhà cung cấp theo quản trị viên bảng.
Phiên bản dành cho gói nhà cung cấp Amazon phải là 8.4.0, như minh họa trong ảnh chụp màn hình sau. Nếu không thì đã xảy ra lỗi khi tải requirements.txt. Để gỡ lỗi bất kỳ lỗi nào, hãy đi tới bảng điều khiển CloudWatch và mở requirements_install_ip đăng nhập Luồng nhật ký, nơi các lỗi được liệt kê. tham khảo Kích hoạt nhật ký trên bảng điều khiển Amazon MWAA để biết thêm chi tiết.
Thiết lập quyền truy cập nhiều tài khoản
Bạn cần thiết lập các chính sách và vai trò trên nhiều tài khoản giữa Tài khoản A và Tài khoản B để truy cập vào nhóm S3 để tải và dỡ dữ liệu. Hoàn thành các bước sau:
- Trong Tài khoản A, định cấu hình chính sách nhóm cho nhóm
sample-inp-bucket-etl-<username>để cấp quyền cho các vai trò AWS Glue và Amazon MWAA trong Tài khoản B cho các đối tượng trong nhómsample-inp-bucket-etl-<username>: - Tương tự, định cấu hình chính sách nhóm cho nhóm
sample-opt-bucket-etl-<username>để cấp quyền cho các vai trò Amazon MWAA trong Tài khoản B để đặt các đối tượng vào bộ chứa này: - Trong Tài khoản A, tạo chính sách IAM có tên
policy_for_roleA, cho phép các hành động cần thiết của Amazon S3 trên nhóm đầu ra: - Tạo một vai trò IAM mới có tên là
RoleAvới Tài khoản B là vai trò thực thể đáng tin cậy và thêm chính sách này vào vai trò. Điều này cho phép Tài khoản B đảm nhận Vai tròA để thực hiện các hành động Amazon S3 cần thiết trên nhóm đầu ra. - Trong Tài khoản B, tạo chính sách IAM có tên
s3-cross-account-accesscó quyền truy cập các đối tượng trong nhómsample-inp-bucket-etl-<username>, nằm trong Tài khoản A. - Thêm chính sách này vào vai trò AWS Glue và vai trò Amazon MWAA:
- Trong Tài khoản B, tạo chính sách IAM
policy_for_roleBchỉ định Tài khoản A là một thực thể đáng tin cậy. Sau đây là chính sách tin cậy để giả địnhRoleAtrong Tài khoản A: - Tạo một vai trò IAM mới có tên là
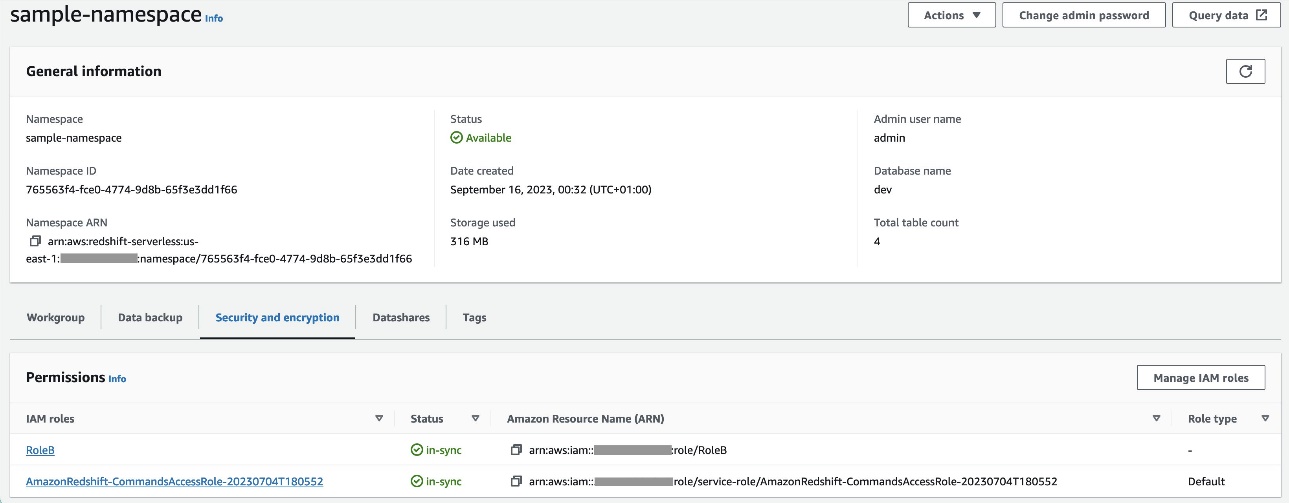
RoleBvới Amazon Redshift làm loại thực thể đáng tin cậy và thêm chính sách này vào vai trò. Điều này cho phépRoleBgiả địnhRoleAtrong Tài khoản A và cũng có thể được Amazon Redshift tiếp nhận. - Đính kèm
RoleBvào không gian tên Redshift Serverless, để Amazon Redshift có thể ghi đối tượng vào nhóm đầu ra S3 trong Tài khoản A. - Đính kèm chính sách
policy_for_roleBvới vai trò Amazon MWAA, cho phép Amazon MWAA truy cập vào nhóm đầu ra trong Tài khoản A.
Tham khảo Làm cách nào để cung cấp quyền truy cập nhiều tài khoản vào các đối tượng trong bộ chứa Amazon S3? để biết thêm chi tiết về cách thiết lập quyền truy cập nhiều tài khoản vào các đối tượng trong Amazon S3 từ AWS Glue và Amazon MWAA. tham khảo Làm cách nào để SAO CHÉP hoặc UNLOAD dữ liệu từ Amazon Redshift sang bộ chứa Amazon S3 trong tài khoản khác? để biết thêm thông tin chi tiết về cách thiết lập vai trò dỡ dữ liệu từ Amazon Redshift sang Amazon S3 từ Amazon MWAA.
Thiết lập kết nối VPC ngang hàng giữa Amazon MWAA và VPC Amazon Redshift
Vì Amazon MWAA và Amazon Redshift nằm trong hai VPC riêng biệt nên bạn cần thiết lập kết nối VPC ngang hàng giữa chúng. Bạn phải thêm tuyến vào bảng tuyến được liên kết với mạng con cho cả hai dịch vụ. tham khảo Làm việc với các kết nối ngang hàng VPC để biết thông tin chi tiết về VPC tiên phong.

Đảm bảo rằng phạm vi CIDR của Amazon MWAA VPC được cho phép trong nhóm bảo mật Redshift và phạm vi CIDR của Amazon Redshift VPC được cho phép trong nhóm bảo mật Amazon MWAA, như minh họa trong ảnh chụp màn hình sau.

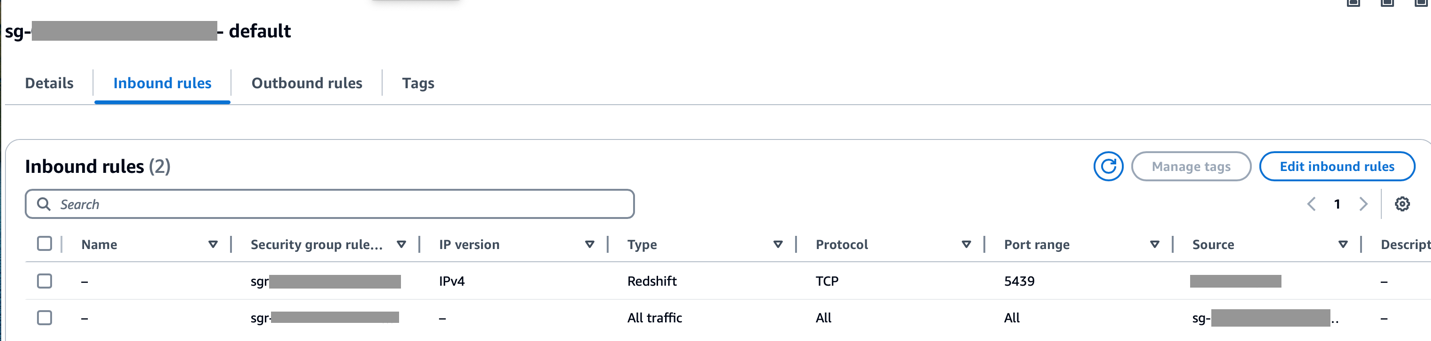
Nếu bất kỳ bước nào trước đó được định cấu hình không chính xác, bạn có thể gặp phải lỗi “Hết thời gian kết nối” trong quá trình chạy DAG.
Định cấu hình kết nối Amazon MWAA bằng Trình quản lý bí mật
Khi quy trình Amazon MWAA được đặt cấu hình để sử dụng Trình quản lý bí mật, trước tiên, quy trình này sẽ tìm kiếm các kết nối và biến trong một chương trình phụ trợ thay thế (như Trình quản lý bí mật). Nếu phần phụ trợ thay thế chứa giá trị cần thiết thì nó sẽ được trả về. Nếu không, nó sẽ kiểm tra cơ sở dữ liệu siêu dữ liệu để tìm giá trị và thay vào đó trả về giá trị đó. Để biết thêm chi tiết, hãy tham khảo Định cấu hình kết nối Apache Airflow bằng bí mật AWS Secrets Manager.
Hoàn thành các bước sau:
- Định cấu hình một Điểm cuối VPC để liên kết Amazon MWAA và Secrets Manager (
com.amazonaws.us-east-1.secretsmanager).
Điều này cho phép Amazon MWAA truy cập thông tin xác thực được lưu trữ trong Trình quản lý bí mật.

- Để cấp cho Amazon MWAA quyền truy cập vào khóa bí mật của Trình quản lý bí mật, hãy thêm chính sách có tên
SecretsManagerReadWriteđến vai trò IAM của môi trường. - Để tạo phần phụ trợ của Trình quản lý bí mật dưới dạng tùy chọn cấu hình Apache Airflow, hãy chuyển đến tùy chọn cấu hình Airflow, thêm các cặp khóa-giá trị sau và lưu cài đặt của bạn.
Điều này định cấu hình Airflow để tìm kiếm các chuỗi và biến kết nối tại airflow/connections/* và airflow/variables/* đường dẫn:

- Để tạo chuỗi URI kết nối Airflow, hãy truy cập Đám mây AWS và nhập vào trình bao Python.
- Chạy đoạn mã sau để tạo chuỗi URI kết nối:
Chuỗi kết nối phải được tạo như sau:
- Thêm kết nối trong Trình quản lý bí mật bằng lệnh sau trong Giao diện dòng lệnh AWS (AWS CLI).
Điều này cũng có thể được thực hiện từ bảng điều khiển Secrets Manager. Điều này sẽ được thêm vào Trình quản lý bí mật dưới dạng bản rõ.
Sử dụng kết nối airflow/connections/secrets_redshift_connection trong DAG. Khi DAG được chạy, nó sẽ tìm kiếm kết nối này và truy xuất các bí mật từ Trình quản lý bí mật. Trong trường hợp RedshiftDataOperator, vượt qua secret_arn làm tham số thay vì tên kết nối.
Bạn cũng có thể thêm bí mật bằng bảng điều khiển Trình quản lý bí mật dưới dạng cặp khóa-giá trị.
- Thêm một bí mật khác vào Trình quản lý bí mật và lưu nó dưới dạng
airflow/connections/redshift_conn_test.
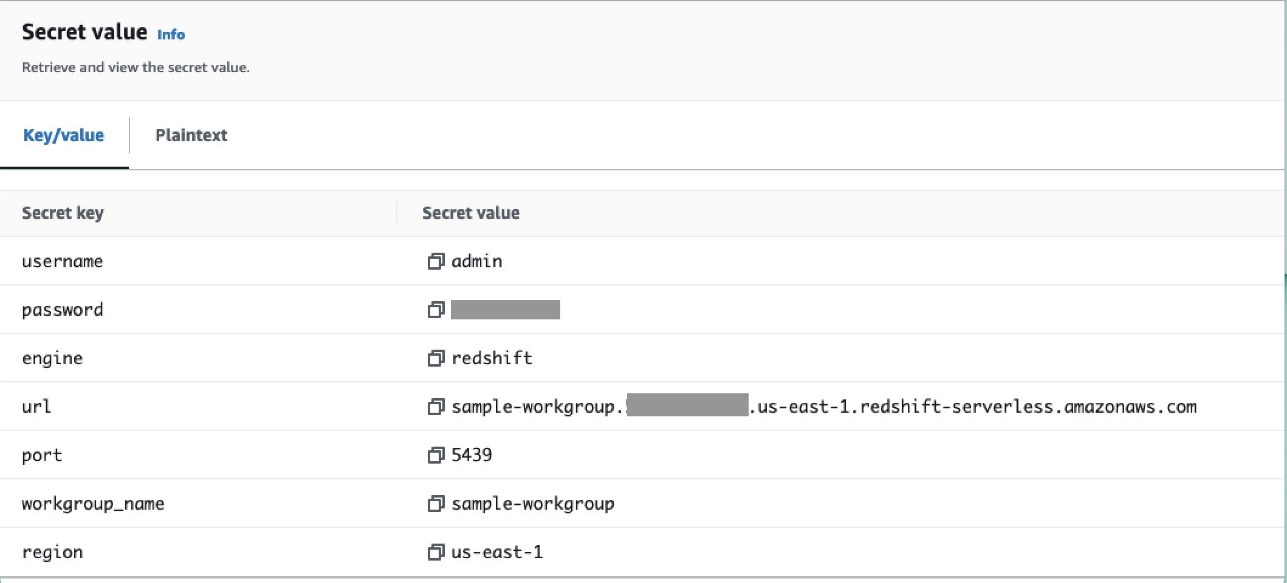
Tạo kết nối Airflow thông qua cơ sở dữ liệu siêu dữ liệu
Bạn cũng có thể tạo kết nối trong giao diện người dùng. Trong trường hợp này, chi tiết kết nối sẽ được lưu trữ trong cơ sở dữ liệu siêu dữ liệu Airflow. Nếu môi trường Amazon MWAA không được định cấu hình để sử dụng phụ trợ Trình quản lý bí mật, môi trường này sẽ kiểm tra cơ sở dữ liệu siêu dữ liệu để tìm giá trị và trả về giá trị đó. Bạn có thể tạo kết nối Airflow bằng UI, AWS CLI hoặc API. Trong phần này, chúng tôi trình bày cách tạo kết nối bằng Giao diện người dùng Airflow.
- Trong Mã kết nối, nhập tên cho kết nối.
- Trong Kiểu kết nối, chọn Amazon RedShift.
- Trong Máy chủ, nhập điểm cuối Redshift (không có cổng và cơ sở dữ liệu) cho Redshift Serverless.
- Trong Cơ sở dữ liệu, đi vào
dev. - Trong người sử dang, nhập tên người dùng quản trị viên của bạn.
- Trong Mật khẩu, nhập mật khẩu của bạn.
- Trong Hải cảng, sử dụng cổng 5439.
- Trong thêm, đặt
regionvàtimeoutthông số. - Kiểm tra kết nối, sau đó lưu cài đặt của bạn.

Tạo và chạy DAG
Trong phần này, chúng tôi mô tả cách tạo DAG bằng nhiều thành phần khác nhau. Sau khi tạo và chạy DAG, bạn có thể xác minh kết quả bằng cách truy vấn các bảng Redshift và kiểm tra nhóm S3 mục tiêu.
Tạo DAG
Trong Airflow, đường ống dữ liệu được xác định bằng mã Python dưới dạng DAG. Chúng tôi tạo một DAG bao gồm nhiều toán tử, cảm biến, kết nối, tác vụ và quy tắc khác nhau:
- DAG bắt đầu bằng việc tìm kiếm các tệp nguồn trong nhóm S3
sample-inp-bucket-etl-<username>trong Tài khoản A cho ngày hiện tại bằng cách sử dụngS3KeySensor. S3KeySensor được sử dụng để chờ một hoặc nhiều khóa xuất hiện trong nhóm S3.- Ví dụ: nhóm S3 của chúng tôi được phân vùng thành
s3://bucket/products/YYYY/MM/DD/, vì vậy cảm biến của chúng tôi sẽ kiểm tra các thư mục có ngày hiện tại. Chúng tôi lấy ngày hiện tại trong DAG và chuyển ngày này choS3KeySensor, tìm kiếm bất kỳ tệp mới nào trong thư mục ngày hiện tại. - Chúng tôi cũng thiết lập
wildcard_matchasTrue, cho phép tìm kiếm trênbucket_keyđược hiểu là mẫu ký tự đại diện Unix. Đặtmodeđếnrescheduleđể tác vụ cảm biến giải phóng vị trí công việc khi các tiêu chí không được đáp ứng và nó được lên lịch lại sau đó. Cách tốt nhất là sử dụng chế độ này khipoke_intervaldài hơn 1 phút để tránh tải quá nhiều cho bộ lập lịch.
- Ví dụ: nhóm S3 của chúng tôi được phân vùng thành
- Sau khi có sẵn tệp trong bộ chứa S3, trình thu thập thông tin AWS Glue sẽ chạy bằng cách sử dụng
GlueCrawlerOperatorđể thu thập dữ liệu nhóm nguồn S3sample-inp-bucket-etl-<username>trong Tài khoản A và cập nhật siêu dữ liệu của bảng trong tài khoảnproducts_dbcơ sở dữ liệu trong Danh mục dữ liệu. Trình thu thập thông tin sử dụng vai trò AWS Glue và cơ sở dữ liệu Danh mục dữ liệu đã được tạo ở các bước trước. - DAG sử dụng
GlueCrawlerSensorđể chờ trình thu thập thông tin hoàn tất. - Khi công việc của trình thu thập thông tin hoàn tất,
GlueJobOperatorđược sử dụng để chạy tác vụ AWS Glue. Tên tập lệnh AWS Glue (cùng với vị trí) và được chuyển cho người vận hành cùng với vai trò AWS Glue IAM. Các thông số khác nhưGlueVersion,NumberofWorkersvàWorkerTypeđược thông qua bằng cách sử dụngcreate_job_kwargstham số. - DAG sử dụng
GlueJobSensorđể chờ công việc AWS Glue hoàn thành. Khi hoàn tất, bảng phân tầng Redshiftproductssẽ được tải dữ liệu từ tệp S3. - Bạn có thể kết nối với Amazon Redshift từ Airflow bằng ba cách khác nhau khai thác:
PythonOperator.SQLExecuteQueryOperator, sử dụng kết nối PostgreSQL vàredshift_defaultlàm kết nối mặc định.RedshiftDataOperator, sử dụng API dữ liệu Redshift vàaws_defaultlàm kết nối mặc định.
Trong DAG của chúng tôi, chúng tôi sử dụng SQLExecuteQueryOperator và RedshiftDataOperator để chỉ ra cách sử dụng các toán tử này. Các thủ tục lưu trữ Redshift được chạy RedshiftDataOperator. DAG cũng chạy các lệnh SQL trong Amazon Redshift để xóa dữ liệu khỏi bảng phân tầng bằng cách sử dụng SQLExecuteQueryOperator.
Vì chúng tôi đã đặt cấu hình môi trường Amazon MWAA để tìm kiếm các kết nối trong Trình quản lý bí mật nên khi DAG chạy, nó sẽ truy xuất các chi tiết kết nối Redshift như tên người dùng, mật khẩu, máy chủ, cổng và Khu vực từ Trình quản lý bí mật. Nếu không tìm thấy kết nối trong Trình quản lý bí mật thì các giá trị sẽ được truy xuất từ các kết nối mặc định.
In SQLExecuteQueryOperator, chúng tôi chuyển tên kết nối mà chúng tôi đã tạo trong Trình quản lý bí mật. Nó tìm airflow/connections/secrets_redshift_connection và lấy các bí mật từ Secrets Manager. Nếu Trình quản lý bí mật không được thiết lập thì kết nối được tạo theo cách thủ công (ví dụ: redshift-conn-id) có thể được thông qua.
In RedshiftDataOperator, chúng tôi truyền lại bí mật của airflow/connections/redshift_conn_test kết nối được tạo trong Trình quản lý bí mật dưới dạng tham số.
- Là nhiệm vụ cuối cùng,
RedshiftToS3Operatorđược sử dụng để tải dữ liệu từ bảng Redshift sang nhóm S3sample-opt-bucket-etltrong Tài khoản B.airflow/connections/redshift_conn_testtừ Secrets Manager được sử dụng để dỡ bỏ dữ liệu. TriggerRuleđược thiết lập đểALL_DONE, cho phép bước tiếp theo chạy sau khi tất cả các tác vụ ngược dòng hoàn tất.- Sự phụ thuộc của các nhiệm vụ được xác định bằng cách sử dụng
chain()chức năng, cho phép chạy song song các tác vụ nếu cần. Trong trường hợp của chúng tôi, chúng tôi muốn tất cả các tác vụ chạy theo trình tự.
Sau đây là mã DAG hoàn chỉnh. Các dag_id phải khớp với tên tập lệnh DAG, nếu không nó sẽ không được đồng bộ hóa vào giao diện người dùng Airflow.
Xác minh việc chạy DAG
Sau khi bạn tạo tệp DAG (thay thế các biến trong tập lệnh DAG) và tải nó lên s3://sample-airflow-instance/dags thư mục, nó sẽ được tự động đồng bộ hóa với giao diện người dùng Airflow. Tất cả DAG xuất hiện trên DAG chuyển hướng. Chuyển đổi ON tùy chọn để làm cho DAG có thể chạy được. Bởi vì DAG của chúng tôi được đặt thành schedule="@once", bạn cần thực hiện công việc theo cách thủ công bằng cách chọn biểu tượng chạy bên dưới Hoạt động. Khi DAG hoàn tất, trạng thái được cập nhật bằng màu xanh lục, như minh họa trong ảnh chụp màn hình sau.
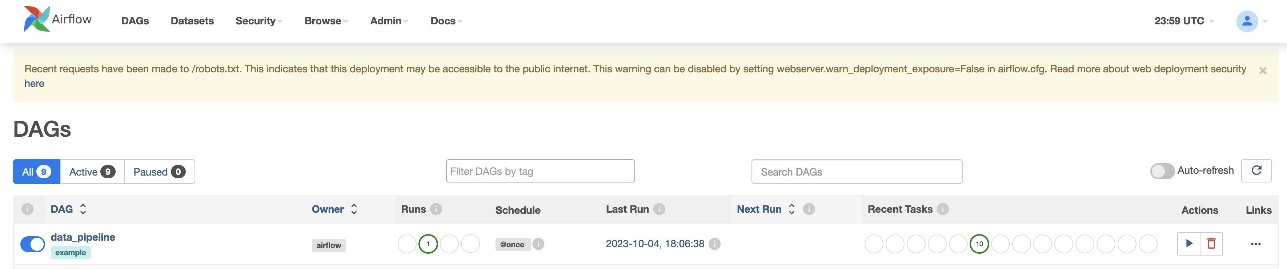
Trong tạp chí Liên kết phần này, có các tùy chọn để xem mã, biểu đồ, lưới, nhật ký, v.v. Chọn Đồ thị để trực quan hóa DAG ở định dạng biểu đồ. Như được hiển thị trong ảnh chụp màn hình sau, mỗi màu của nút biểu thị một toán tử cụ thể và màu của đường viền nút biểu thị một trạng thái cụ thể.

Xác minh kết quả
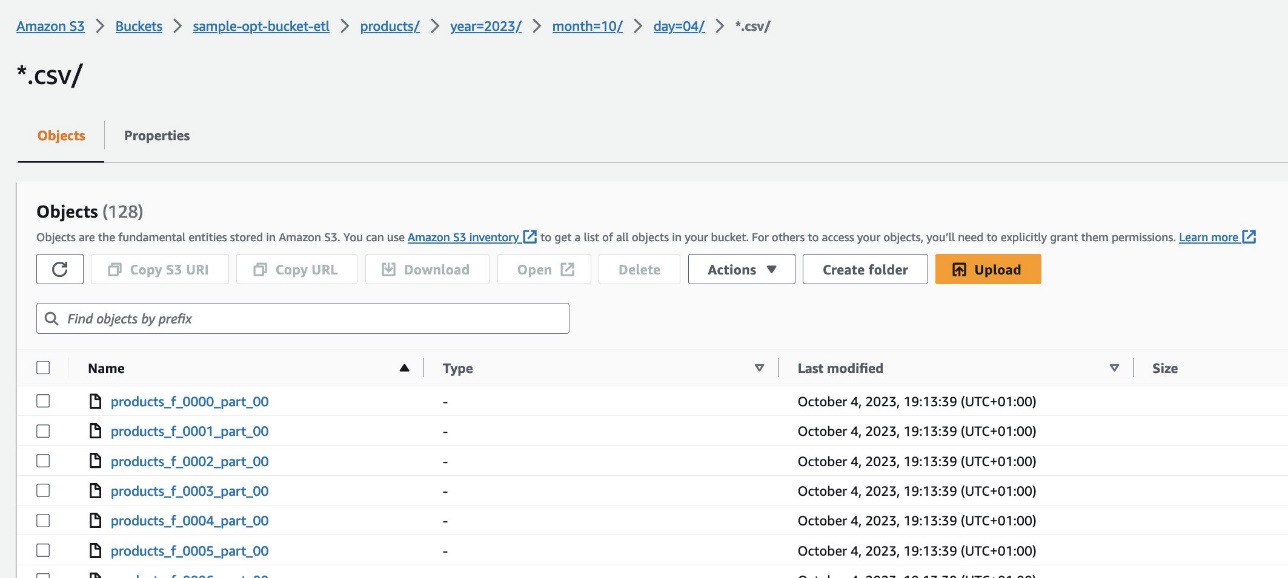
Trên bảng điều khiển Amazon Redshift, điều hướng đến Trình chỉnh sửa truy vấn v2 và chọn dữ liệu trong products_f bàn. Bảng phải được tải và có cùng số lượng bản ghi như tệp S3.

Trên bảng điều khiển Amazon S3, điều hướng đến nhóm S3 s3://sample-opt-bucket-etl trong Tài khoản B. product_f các tập tin nên được tạo theo cấu trúc thư mục s3://sample-opt-bucket-etl/products/YYYY/MM/DD/.
Làm sạch
Dọn dẹp các tài nguyên được tạo trong bài đăng này để tránh phát sinh các khoản phí liên tục:
- Xóa ngăn xếp CloudFormation và nhóm S3 mà bạn đã tạo làm điều kiện tiên quyết.
- Xóa các kết nối ngang hàng VPC và VPC, các chính sách và vai trò trên nhiều tài khoản cũng như các bí mật trong Trình quản lý bí mật.
Kết luận
Với Amazon MWAA, bạn có thể xây dựng các quy trình công việc phức tạp bằng Airflow và Python mà không cần quản lý cụm, nút hay bất kỳ chi phí vận hành nào khác thường liên quan đến việc triển khai và mở rộng quy mô Airflow trong sản xuất. Trong bài đăng này, chúng tôi đã trình bày cách Amazon MWAA cung cấp một cách tự động để nhập, chuyển đổi, phân tích và phân phối dữ liệu giữa các tài khoản và dịch vụ khác nhau trong AWS. Để biết thêm ví dụ về các nhà khai thác AWS khác, hãy tham khảo phần sau Kho GitHub; chúng tôi khuyến khích bạn tìm hiểu thêm bằng cách thử một số ví dụ này.
Về các tác giả

Radhika Jakkula là Kiến trúc sư giải pháp tạo mẫu dữ liệu lớn tại AWS. Cô giúp khách hàng xây dựng nguyên mẫu bằng cách sử dụng dịch vụ phân tích AWS và cơ sở dữ liệu chuyên dụng. Cô là chuyên gia trong việc đánh giá nhiều yêu cầu khác nhau và áp dụng các dịch vụ AWS, công cụ và khung dữ liệu lớn có liên quan để tạo ra một kiến trúc mạnh mẽ.
 Sidhanth Muralidhar là Giám đốc tài khoản kỹ thuật chính tại AWS. Anh ấy làm việc với các khách hàng doanh nghiệp lớn vận hành khối lượng công việc của họ trên AWS. Anh ấy đam mê làm việc với khách hàng và giúp họ thiết kế khối lượng công việc về chi phí, độ tin cậy, hiệu suất và hoạt động xuất sắc trên quy mô lớn trong hành trình đám mây của họ. Anh ấy cũng rất quan tâm đến phân tích dữ liệu.
Sidhanth Muralidhar là Giám đốc tài khoản kỹ thuật chính tại AWS. Anh ấy làm việc với các khách hàng doanh nghiệp lớn vận hành khối lượng công việc của họ trên AWS. Anh ấy đam mê làm việc với khách hàng và giúp họ thiết kế khối lượng công việc về chi phí, độ tin cậy, hiệu suất và hoạt động xuất sắc trên quy mô lớn trong hành trình đám mây của họ. Anh ấy cũng rất quan tâm đến phân tích dữ liệu.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/orchestrate-an-end-to-end-etl-pipeline-using-amazon-s3-aws-glue-and-amazon-redshift-serverless-with-amazon-mwaa/

