Apache Hive is a SQL-based data warehouse system for processing highly distributed datasets on the Apache Hadoop platform. There are two key components to Apache Hive: the Hive SQL query engine and the Hive metastore (HMS). The Hive metastore is a repository of metadata about the SQL tables, such as database names, table names, schema, serialization and deserialization information, data location, and partition details of each table. Apache Hive, Apache Spark, Presto, and Trino can all use a Hive Metastore to retrieve metadata to run queries. The Hive metastore can be hosted on an Apache Hadoop cluster or can be backed by a relational database that is external to a Hadoop cluster. Although the Hive metastore stores the metadata of tables, the actual data of the table could be residing on Amazon Simple Storage Service (Amazon S3), the Hadoop Distributed File System (HDFS) of the Hadoop cluster, or any other Hive-supported data stores.
Because Apache Hive was built on top of Apache Hadoop, many organizations have been using the software from the time they have been using Hadoop for big data processing. Also, Hive metastore provides flexible integration with many other open-source big data software like Apache HBase, Apache Spark, Presto, and Apache Impala. Therefore, organizations have come to host huge volumes of metadata of their structured datasets in the Hive metastore. A metastore is a critical part of a data lake, and having this information available, wherever it resides, is important. However, many AWS analytics services don’t integrate natively with the Hive metastore, and therefore, organizations have had to migrate their data to the AWS Glue Data Catalog to use these services.
AWS Lake Formation has launched support for managing user access to Apache Hive metastores through a federated AWS Glue connection. Previously, you could use Lake Formation to manage user permissions on AWS Glue Data Catalog resources only. With the Hive metastore connection from AWS Glue, you can connect to a database in a Hive metastore external to the Data Catalog, map it to a federated database in the Data Catalog, apply Lake Formation permissions on the Hive database and tables, share them with other AWS accounts, and query them using services such as Amazon Athena, Amazon Redshift Spectrum, Amazon EMR, and AWS Glue ETL (extract, transform, and load). For additional details on how the Hive metastore integration with Lake Formation works, refer to Managing permissions on datasets that use external metastores.
Use cases for Hive metastore integration with the Data Catalog include the following:
- An external Apache Hive metastore used for legacy big data workloads like on-premises Hadoop clusters with data in Amazon S3
- Transient Amazon EMR workloads with underlying data in Amazon S3 and the Hive metastore on Amazon Relational Database Service (Amazon RDS) clusters.
In this post, we demonstrate how to apply Lake Formation permissions on a Hive metastore database and tables and query them using Athena. We illustrate a cross-account sharing use case, where a Lake Formation steward in producer account A shares a federated Hive database and tables using LF-Tags to consumer account B.
Solution overview
Producer account A hosts an Apache Hive metastore in an EMR cluster, with underlying data in Amazon S3. We launch the AWS Glue Hive metastore connector from AWS Serverless Application Repository in account A and create the Hive metastore connection in account A’s Data Catalog. After we create the HMS connection, we create a database in account A’s Data Catalog (called the federated database) and map it to a database in the Hive metastore using the connection. The tables from the Hive database are then accessible to the Lake Formation admin in account A, just like any other tables in the Data Catalog. The admin continues to set up Lake Formation tag-based access control (LF-TBAC) on the federated Hive database and share it to account B.
The data lake users in account B will access the Hive database and tables of account A, just like querying any other shared Data Catalog resource using Lake Formation permissions.
The following diagram illustrates this architecture.

The solution consists of steps in both accounts. In account A, perform the following steps:
- Create an S3 bucket to host the sample data.
- Launch an EMR 6.10 cluster with Hive. Download the sample data to the S3 bucket. Create a database and external tables, pointing to the downloaded sample data, in its Hive metastore.
- Deploy the application GlueDataCatalogFederation-HiveMetastore from AWS Serverless Application Repository and configure it to use the Amazon EMR Hive metastore. This will create an AWS Glue connection to the Hive metastore that shows up on the Lake Formation console.
- Using the Hive metastore connection, create a federated database in the AWS Glue Data Catalog.
- Create LF-Tags and associate them to the federated database.
- Grant permissions on the LF-Tags to account B. Grant database and table permissions to account B using LF-Tag expressions.
In account B, perform the following steps:
- As a data lake admin, review and accept the AWS Resource Access Manager (AWS RAM) invites for the shares from account A.
- The data lake admin then sees the shared database and tables. The admin creates a resource link to the database and grants fine-grained permissions to a data analyst in this account.
- Both the data lake admin and the data analyst query the Hive tables that are available to them using Athena.
Account A has the following personas:
- hmsblog-producersteward – Manages the data lake in the producer account A
Account B has the following personas:
- hmsblog-consumersteward – Manages the data lake in the consumer account B
- hmsblog-analyst – A data analyst who needs access to selected Hive tables
Prerequisites
To follow the tutorial in this post, you need the following:
Lake Formation and AWS CloudFormation setup in account A
To keep the setup simple, we have an IAM admin registered as the data lake admin. Complete the following steps:
- Sign into the AWS Management Console and choose the
us-west-2Region. - On the Lake Formation console, under Permissions in the navigation pane, choose Administrative roles and tasks.
- Choose Manage Administrators in the Data lake administrators section.
- Under IAM users and roles, choose the IAM admin user that you are logged in as and choose Save.
- Choose Launch Stack to deploy the CloudFormation template:

- Choose Next.
- Provide a name for the stack and choose Next.
- On the next page, choose Next.
- Review the details on the final page and select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create.
Stack creation takes about 10 minutes. The stack establishes the producer account A setup as follows:
- Creates an S3 data lake bucket
- Registers the data lake bucket to Lake Formation with the Enable catalog federation flag
- Launches an EMR 6.10 cluster with Hive and runs two steps in Amazon EMR:
- Downloads the sample data from public S3 bucket to the newly created bucket
- Creates a Hive database and four external tables for the data in Amazon S3, using a HQL script
- Creates an IAM user (
hmsblog-producersteward) and sets this user as Lake Formation administrator - Creates LF-Tags (
LFHiveBlogCampaignRole=Admin,Analyst)
Review CloudFormation stack output in account A
To review the output of your CloudFormation stack, complete the following steps:
- Log in to the console as the IAM admin user you used earlier to run the CloudFormation template.
- Open the CloudFormation console in another browser tab.
- Review and note down the stack Outputs tab details.

- Choose the link under Value for
ProducerStewardCredentials.
This will open the AWS Secrets Manager console.
- Choose Retrieve value and note down the credentials of
hmsblog-producersteward.

Set up a federated AWS Glue connection in account A
To set up a federated AWS Glue connection, complete the following steps:
- Open the AWS Serverless Application Repository console in another browser tab.
- In the navigation pane, choose Available applications.
- Select Show apps that create custom IAM roles or resource policies.
- In the search bar, enter Glue.
This will list various applications.
- Choose the application named
GlueDataCatalogFederation-HiveMetastore.
This will open the AWS Lambda console configuration page for a Lambda function that runs the connector application code.

To configure the Lambda function, you need details of the EMR cluster launched by the CloudFormation stack.
- On another tab of your browser, open the Amazon EMR console.
- Navigate to the cluster launched for this post and note down the following details from the cluster details page:
- Primary node public DNS
- Subnet ID
- Security group ID of the primary node


- Back on the Lambda configuration page, under Review, configure, and deploy, in the Application settings section, provide the following details. Leave the rest as the default values.
- For GlueConnectionName, enter
hive-metastore-connection. - For HiveMetastoreURIs enter
thrift://<Primary-node-public-DNS-of your-EMR>:9083. For example, thrift://ec2-54-70-203-146.us-west-2.compute.amazonaws.com:9083, where9083is the Hive metastore port in EMR cluster. - For VPCSecurityGroupIds, enter the security group ID of the EMR primary node.
- For VPCSubnetIds, enter the subnet ID of the EMR cluster.
- For GlueConnectionName, enter
- Choose Deploy.

Wait for the Create Completed status of the Lambda application. You can review the details of the Lambda application on the Lambda console.

- Open Lake Formation console and in the navigation pane, choose Data sharing.
You should see hive-metastore-connection under Connections.

- Choose it and review the details.

- In the navigation pane, under Administrative roles and tasks, choose LF-Tags.
You should see the created LF-tag LFHiveBlogCampaignRole with two values: Analyst and Admin.

- Choose LF-Tag permissions and choose Grant.
- Choose IAM users and roles and enter
hmsblog-producersteward. - Under LF-Tags, choose Add LF-Tag.
- Enter
LFHiveBlogCampaignRolefor Key and enterAnalystandAdminfor Values. - Under Permissions, select Describe and Associate for LF-Tag permissions and Grantable permissions.
- Choose Grant.
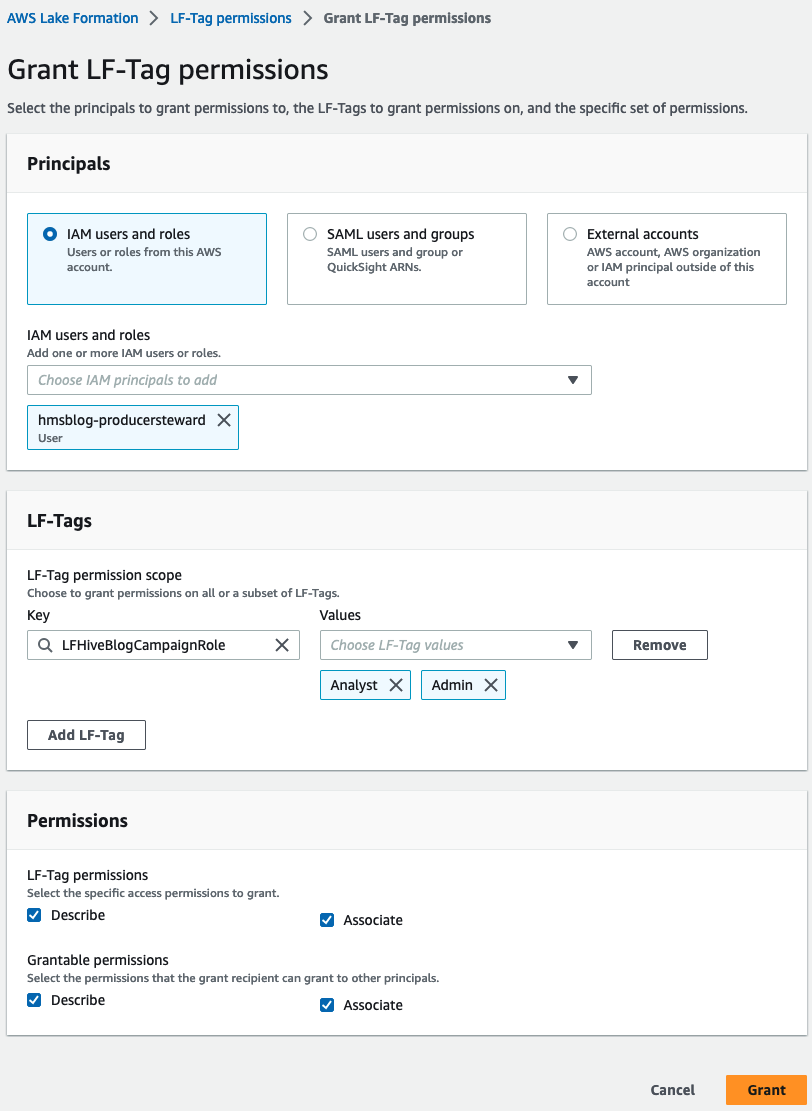
This gives LF-Tags permissions for the producer steward.
- Log out as the IAM administrator user.
Grant Lake Formation permissions as producer steward
Complete the following steps:
- Sign in to the console as
hmsblog-producersteward, using the credentials from the CloudFormation stack Output tab that you noted down earlier. - On the Lake Formation console, in the navigation pane, choose Administrative roles and tasks.
- Under Database creators, choose Grant.

- Add
hmsblog-producerstewardas a database creator.
- In the navigation pane, choose Data sharing.
- Under Connections, choose the
hive-metastore-connectionhyperlink.
- On the Connection details page, choose Create database.
- For Database name, enter
federated_emrhivedb.
This is the federated database in the local AWS Glue Data Catalog that will point to a Hive metastore database. This is a one-to-one mapping of a database in the Data Catalog to a database in the external Hive metastore.
- For Database identifier, enter the name of the database in the EMR Hive metastore that was created by the Hive SQL script. For this post, we use
emrhms_salesdb.
- Once created, select
federated_emrhivedband choose View tables.
This will fetch the database and table metadata from the Hive metastore on the EMR cluster and display the tables created by the Hive script.

Now you associate the LF-Tags created by the CloudFormation script on this federated database and share it to the consumer account B using LF-Tag expressions.
- In the navigation pane, choose Databases.
- Select
federated_emrhivedband on the Actions menu, choose Edit LF-Tags. - Choose Assign new LF-Tag.
- Enter
LFHiveBlogCampaignRolefor Assigned keys andAdminfor Values, then choose Save.
- In the navigation pane, choose Data lake permissions.
- Choose Grant.
- Select External accounts and enter the consumer account B number.
- Under LF-Tags or catalog resources, choose Resource matched by LF-Tags.
- Choose Add LF-Tag.
- Enter
LFHiveBlogCampaignRolefor Key andAdminfor Values.
- In the Database permissions section, select Describe for Database permissions and Grantable permissions.
- In the Table permissions section, select Select and Describe for Table permissions and Grantable permissions.
- Choose Grant.

- In the navigation pane, under Administrative roles and tasks, choose LF-Tag permissions.
- Choose Grant.
- Select External accounts and enter the account ID of consumer account B.
- Under LF-Tags, enter
LFHiveBlogCampaignRolefor Key and enterAnalystandAdminfor Values. - Under Permissions, select Describe and Associate under LF-Tag permissions and Grantable permissions.
- Choose Grant and verify that the granted LF-Tag permissions display correctly.

- In the navigation pane, choose Data lake permissions.
You can review and verify the permissions granted to account B.
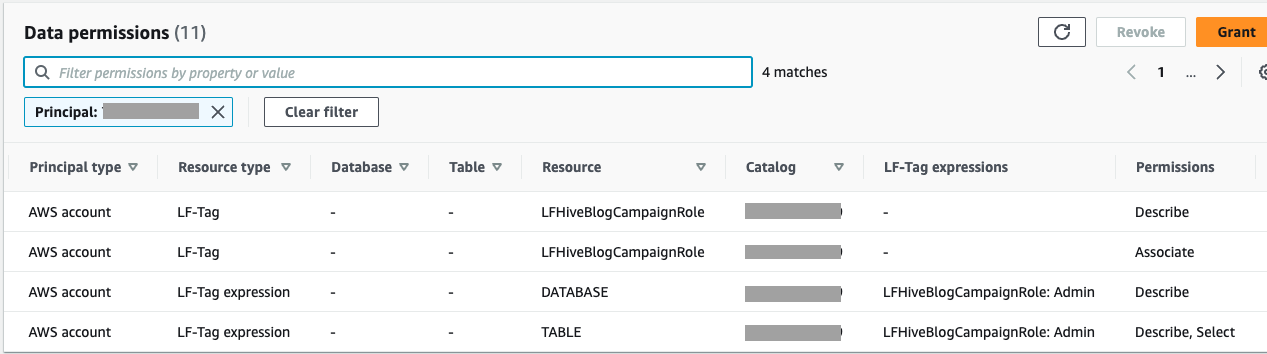
- In the navigation pane, under Administrative roles and tasks, choose LF-Tag permissions.
You can review and verify the permissions granted to account B.

- Log out of account A.
Lake Formation and AWS CloudFormation setup in account B
To keep the setup simple, we use an IAM admin registered as the data lake admin.
- Sign into the AWS Management Console of account B and select the
us-west-2Region. - On the Lake Formation console, under Permissions in the navigation pane, choose Administrative roles and tasks.
- Choose Manage Administrators in the Data lake administrators section.
- Under IAM users and roles, choose the IAM admin user that you are logged in as and choose Save.
- Choose Launch Stack to deploy the CloudFormation template:
- Choose Next.
- Provide a name for the stack and choose Next.
- On the next page, choose Next.
- Review the details on the final page and select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create.
Stack creation should take about 5 minutes. The stack establishes the producer account B setup as follows:
- Creates an IAM user
hmsblog-consumerstewardand sets this user as Lake Formation administrator - Creates another IAM user
hmsblog-analyst - Creates an S3 data lake bucket to store Athena query results, with
ListBucketand write object permissions to bothhmsblog-consumerstewardandhmsblog-analyst
Note down the stack output details.

Accept resource shares in account B
Sign in to the console as hmsblog-consumersteward and complete the following steps:
- On the AWS CloudFormation console, navigate to the stack Outputs tab.
- Choose the link for
ConsumerStewardCredentialsto be redirected to the Secrets Manager console. - On the Secrets Manager console, choose Retrieve secret value and copy the password for the consumer steward user.
- Use the
ConsoleIAMLoginURLvalue from the CloudFormation template Output to log in to account B with the consumer steward user namehmsblog-consumerstewardand the password you copied from Secrets Manager. - Open the AWS RAM console in another browser tab.
- In the navigation pane, under Shared with me, choose Resource shares to view the pending invitations.
You should see two resource share invitations from producer account A: one for a database-level share and one for a table-level share.

- Choose each resource share link, review the details, and choose Accept.

After you accept the invitations, the status of the resource shares changes from Pending to Active.
- Open the Lake Formation console in another browser tab.
- In the navigation pane, choose Databases.
You should see the shared database federated_emrhivedb from producer account A.
- Choose the database and choose View tables to review the list of tables shared under that database.

You should see the four tables of the Hive database that is hosted on the EMR cluster in the producer account.

Grant permissions in account B
To grant permissions in account B, complete the following steps as hmsblog-consumersteward:
- On the Lake Formation console, in the navigation pane, choose Administrative roles and tasks.
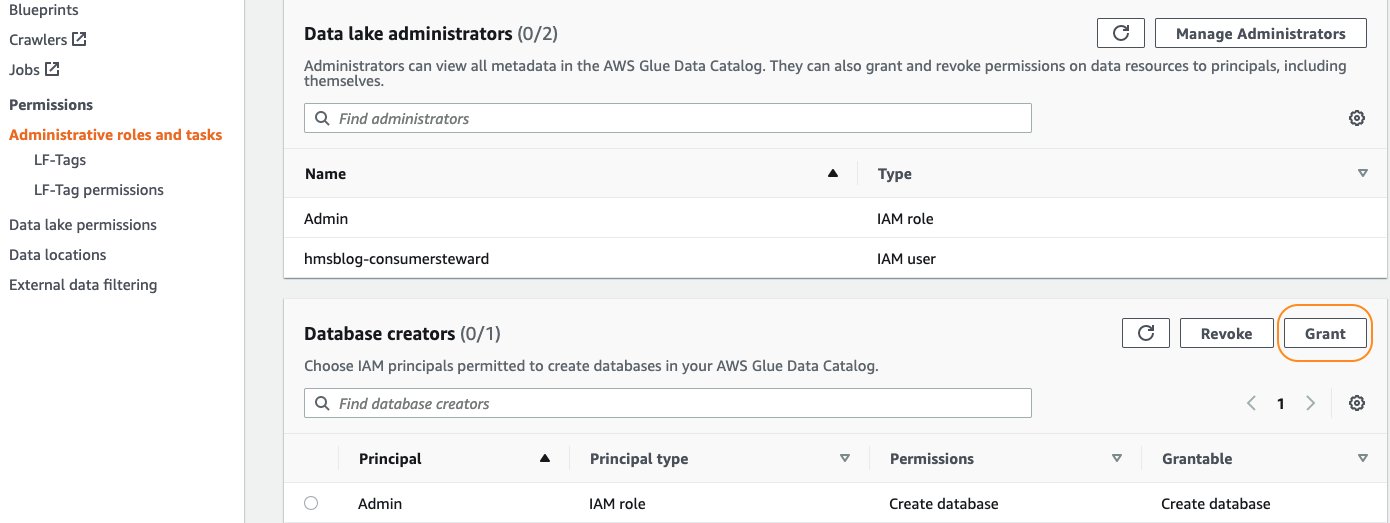
- Under Database creators, choose Grant.
- For IAM users and roles, enter
hmsblog-consumersteward. - For Catalog permissions, select Create database.
- Choose Grant.

This allows hmsblog-consumersteward to create a database resource link.
- In the navigation pane, choose Databases.
- Select
federated_emrhivedband on the Actions menu, choose Create resource link.
- Enter
rl_federatedhivedbfor Resource link name and choose Create.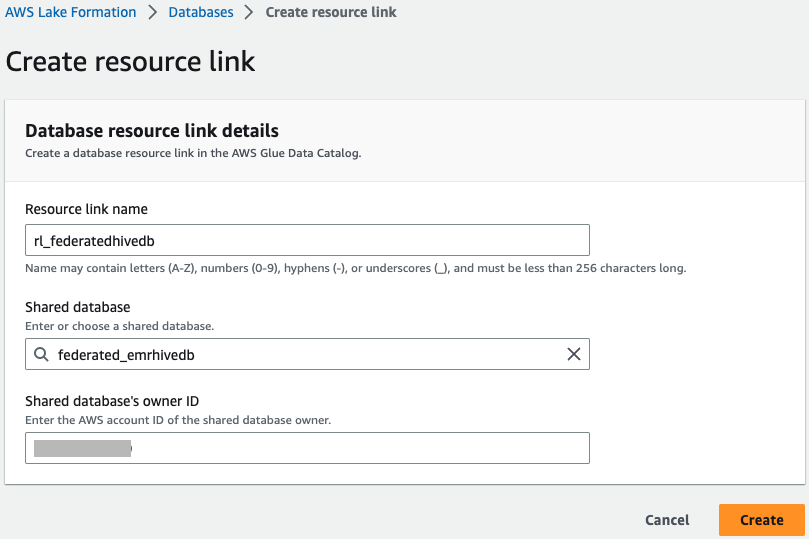
- Choose Databases in the navigation pane.
- Select the resource link
rl_federatedhivedband on the Actions menu, choose Grant. - Choose
hmsblog-analystfor IAM users and roles.
- Under Resource link permissions, select Describe, then choose Grant.
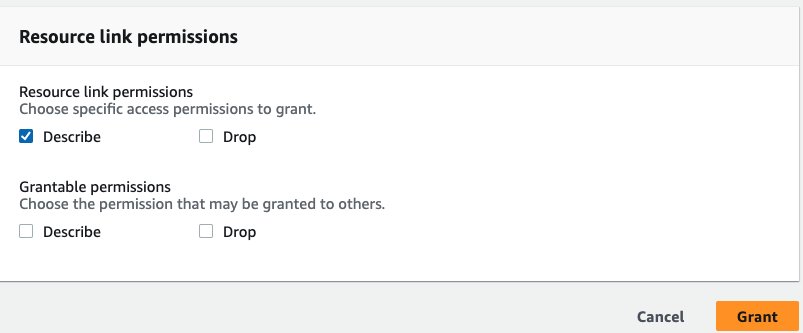
- Select Databases in the navigation pane.
- Select the resource link
rl_federatedhivedband on the Actions menu, choose Grant on target. - Choose
hmsblog-analystfor IAM users and roles. - Choose
hms_productcategoryandhms_supplierfor Tables.
- For Table permissions, select Select and Describe, then choose Grant.

- In the navigation pane, choose Data lake permissions and review the permissions granted to
hms-analyst.
Query the Apache Hive database of the producer from the consumer Athena
Complete the following steps:
- On the Athena console, navigate to the query editor.
- Choose Edit settings to configure the Athena query results bucked.

- Browse and choose the S3 bucket
hmsblog-athenaresults-<your-account-B>-us-west-2that the CloudFormation template created. - Choose Save.

hmsblog-consumersteward has access to all four tables under federated_emrhivedb from the producer account.
- In the Athena query editor, choose the database
rl_federatedhivedband run a query on any of the tables.
You were able to query an external Apache Hive metastore database of the producer account through the AWS Glue Data Catalog and Lake Formation permissions using Athena from the recipient consumer account.
- Sign out of the console as
hmsblog-consumerstewardand sign back in ashmsblog-analyst. - Use the same method as explained earlier to get the login credentials from the CloudFormation stack Outputs tab.
hmsblog-analyst has Describe permissions on the resource link and access to two of the four Hive tables. You can verify that you see them on the Databases and Tables pages on the Lake Formation console.


On the Athena console, you now configure the Athena query results bucket, similar to how you configured it as hmsblog-consumersteward.
- In the query editor, choose Edit settings.
- Browse and choose the S3 bucket
hmsblog-athenaresults-<your-account-B>-us-west-2that the CloudFormation template created. - Choose Save.
- In the Athena query editor, choose the database
rl_federatedhivedband run a query on the two tables.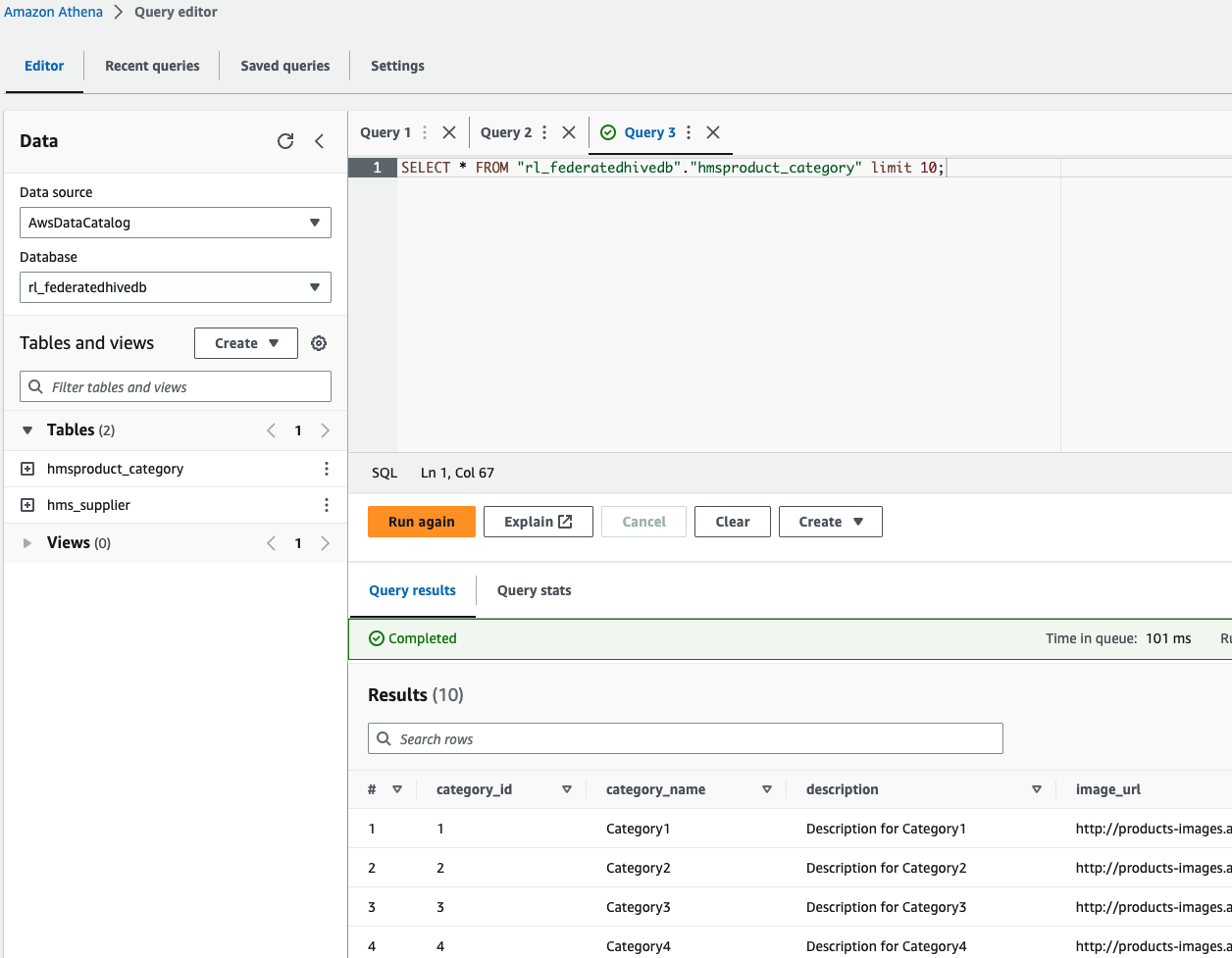
- Sign out of the console as
hmsblog-analyst.
You were able to restrict sharing the external Apache Hive metastore tables using Lake Formation permissions from one account to another and query them using Athena. You can also query the Hive tables using Redshift Spectrum, Amazon EMR, and AWS Glue ETL from the consumer account.
Clean up
To avoid incurring charges on the AWS resources created in this post, you can perform the following steps.
Clean up resources in account A
There are two CloudFormation stacks associated with producer account A. You need to delete the dependencies and the two stacks in the correct order.
- Log in as the admin user to producer account B.
- On the Lake Formation console, choose Data lake permissions in the navigation pane.
- Choose Grant.
- Grant Drop permissions to your role or user on
federated_emrhivedb.
- In the navigation pane, choose Databases.
- Select
federated_emrhivedband on the Actions menu, choose Delete to delete the federated database that is associated with the Hive metastore connection.
This makes the AWS Glue connection’s CloudFormation stack ready to be deleted.

- In the navigation pane, choose Administrative roles and tasks.
- Under Database creators, select Revoke and remove
hmsblog-producerstewardpermissions. - On the CloudFormation console, delete the stack named
serverlessrepo-GlueDataCatalogFederation-HiveMetastorefirst.
This is the one created by your AWS SAM application for the Hive metastore connection. Wait for it to complete deletion.
- Delete the CloudFormation stack that you created for the producer account set up.
This deletes the S3 buckets, EMR cluster, custom IAM roles and policies, and the LF-Tags, database, tables, and permissions.
Clean up resources in account B
Complete the following steps in account B:
- Revoke permission to
hmsblog-consumerstewardas database creator, similar to the steps in the previous section. - Delete the CloudFormation stack that you created for the consumer account setup.
This deletes the IAM users, S3 bucket, and all the permissions from Lake Formation.
If there are any resource links and permissions left, delete them manually in Lake Formation from both accounts.
Conclusion
In this post, we showed you how to launch the AWS Glue Hive metastore federation application from AWS Serverless Application Repository, configure it with a Hive metastore running on an EMR cluster, create a federated database in the AWS Glue Data Catalog, and map it to a Hive metastore database on the EMR cluster. We illustrated how to share and access the Hive database tables for a cross-account scenario and the benefits of using Lake Formation to restrict permissions.
All Lake Formation features such as sharing to IAM principals within same account, sharing to external accounts, sharing to external account IAM principals, restricting column access, and setting data filters work on federated Hive database and tables. You can use any of the AWS analytics services that are integrated with Lake Formation, such as Athena, Redshift Spectrum, AWS Glue ETL, and Amazon EMR to query the federated Hive database and tables.
We encourage you to check out the features of the AWS Glue Hive metastore federation connector and explore Lake Formation permissions on your Hive database and tables. Please comment on this post or talk to your AWS Account Team to share feedback on this feature.
For more details, see Managing permissions on datasets that use external metastores.
About the authors
 Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She likes building data lake solutions for AWS customers and partners. When not on the keyboard, she explores the latest science and technology trends and spends time with her family.
Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She likes building data lake solutions for AWS customers and partners. When not on the keyboard, she explores the latest science and technology trends and spends time with her family.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/query-your-apache-hive-metastore-with-aws-lake-formation-permissions/

