This post is co-written with Praveen Nischal, Mulugeta Mammo, and Akash Shankaran from Intel.
Amazon OpenSearch Service is a managed service that makes it straightforward to secure, deploy, and operate OpenSearch clusters at scale in the AWS Cloud. In an OpenSearch Service domain, the data is managed in the form of indexes. Based on the usage pattern, an OpenSearch cluster may have one or more indexes, and their shards are spread across the data nodes in the cluster. Each data node has a fixed disk size and the disk usage is dependent on the number of index shards stored on the node. Each index shard may occupy different sizes based on its number of documents. In addition to the number of documents, one of the important factors that determine the size of the index shard is the compression strategy used for an index.
As part of an indexing operation, the ingested documents are stored as immutable segments. Each segment is a collection of various data structures, such as inverted index, block K dimensional tree (BKD), term dictionary, or stored fields, and these data structures are responsible for retrieving the document faster during the search operation. Out of these data structures, stored fields, which are largest fields in the segment, are compressed when stored on the disk and based on the compression strategy used, the compression speed and the index storage size will vary.
In this post, we discuss the performance of the Zstandard algorithm, which was introduced in OpenSearch v2.9, amongst other available compression algorithms in OpenSearch.
Importance of compression in OpenSearch
Compression plays a crucial role in OpenSearch, because it significantly impacts the performance, storage efficiency and overall usability of the platform. The following are some key reasons highlighting the importance of compression in OpenSearch:
- Storage efficiency and cost savings OpenSearch often deals with vast volumes of data, including log files, documents, and analytics datasets. Compression techniques reduce the size of data on disk, leading to substantial cost savings, especially in cloud-based and/or distributed environments.
- Reduced I/O operations Compression reduces the number of I/O operations required to read or write data. Fewer I/O operations translate into reduced disk I/O, which is vital for improving overall system performance and resource utilization.
- Environmental impact By minimizing the storage requirements and reduced I/O operations, compression contributes to a reduction in energy consumption and a smaller carbon footprint, which aligns with sustainability and environmental goals.
When configuring OpenSearch, it’s essential to consider compression settings carefully to strike the right balance between storage efficiency and query performance, depending on your specific use case and resource constraints.
Core concepts
Before diving into various compression algorithms that OpenSearch offers, let’s look into three standard metrics that are often used while comparing compression algorithms:
- Compression ratio The original size of the input compared with the compressed data, expressed as a ratio of 1.0 or greater
- Compression speed The speed at which data is made smaller (compressed), expressed in MBps of input data consumed
- Decompression speed The speed at which the original data is reconstructed from the compressed data, expressed in MBps
Index codecs
OpenSearch provides support for codecs that can be used for compressing the stored fields. Until OpenSearch 2.7, OpenSearch provided two codecs or compression strategies: LZ4 and Zlib. LZ4 is analogous to best_speed because it provides faster compression but a lesser compression ratio (consumes more disk space) when compared to Zlib. LZ4 is used as the default compression algorithm if no explicit codec is specified during index creation and is preferred by most because it provides faster indexing and search speeds though it consumes relatively more space than Zlib. Zlib is analogous to best_compression because it provides a better compression ratio (consumes less disk space) when compared to LZ4, but it takes more time to compress and decompress, and therefore has higher latencies for indexing and search operations. Both LZ4 and Zlib codecs are part of the Lucene core codecs.
Zstandard codec
The Zstandard codec was introduced in OpenSearch as an experimental feature in version 2.7, and it provides Zstandard-based compression and decompression APIs. The Zstandard codec is based on JNI binding to the Zstd native library.
Zstandard is a fast, lossless compression algorithm aimed at providing a compression ratio comparable to Zlib but with faster compression and decompression speed comparable to LZ4. The Zstandard compression algorithm is available in two different modes in OpenSearch: zstd and zstd_no_dict. For more details, see Index codecs.
Both codec modes aim to balance compression ratio, index, and search throughput. The zstd_no_dict option excludes a dictionary for compression at the expense of slightly larger index sizes.
With the recent OpenSearch 2.9 release, the Zstandard codec has been promoted from experimental to mainline, making it suitable for production use cases.
Create an index with the Zstd codec
You can use the index.codec during index creation to create an index with the Zstd codec. The following is an example using the curl command (this command requires the user to have necessary privileges to create an index):
Zstandard compression levels
With Zstandard codecs, you can optionally specify a compression level using the index.codec.compression_level setting, as shown in the following code. This setting takes integers in the [1, 6] range. A higher compression level results in a higher compression ratio (smaller storage size) with a trade-off in speed (slower compression and decompression speeds lead to higher indexing and search latencies). For more details, see Choosing a codec.
Update an index codec setting
You can update the index.codec and index.codec.compression_level settings any time after the index is created. For the new configuration to take effect, the index needs to be closed and reopened.
You can update the setting of an index using a PUT request. The following is an example using curl commands.
Close the index:
Update the index settings:
Reopen the index:
Changing the index codec settings doesn’t immediately affect the size of existing segments. Only new segments created after the update will reflect the new codec setting. To have consistent segment sizes and compression ratios, it may be necessary to perform a reindexing or other indexing processes like merges.
Benchmarking compression performance of compression in OpenSearch
To understand the performance benefits of Zstandard codecs, we carried out a benchmark exercise.
Setup
The server setup was as follows:
- Benchmarking was performed on an OpenSearch cluster with a single data node which acts as both data and coordinator node and with a dedicated
cluster_managernode. - The instance type for the data node was r5.2xlarge and the
cluster_managernode was r5.xlarge, both backed by an Amazon Elastic Block Store (Amazon EBS) volume of type GP3 and size 100GB.
Benchmarking was set up as follows:
- The benchmark was run on a single node of type c5.4xlarge (sufficiently large to avoid hitting client-side resource constraints) backed by an EBS volume of type GP3 and size 500GB.
- The number of clients was 16 and bulk size was 1024
- The workload was nyc_taxis
The index setup was as follows:
- Number of shards: 1
- Number of replicas: 0
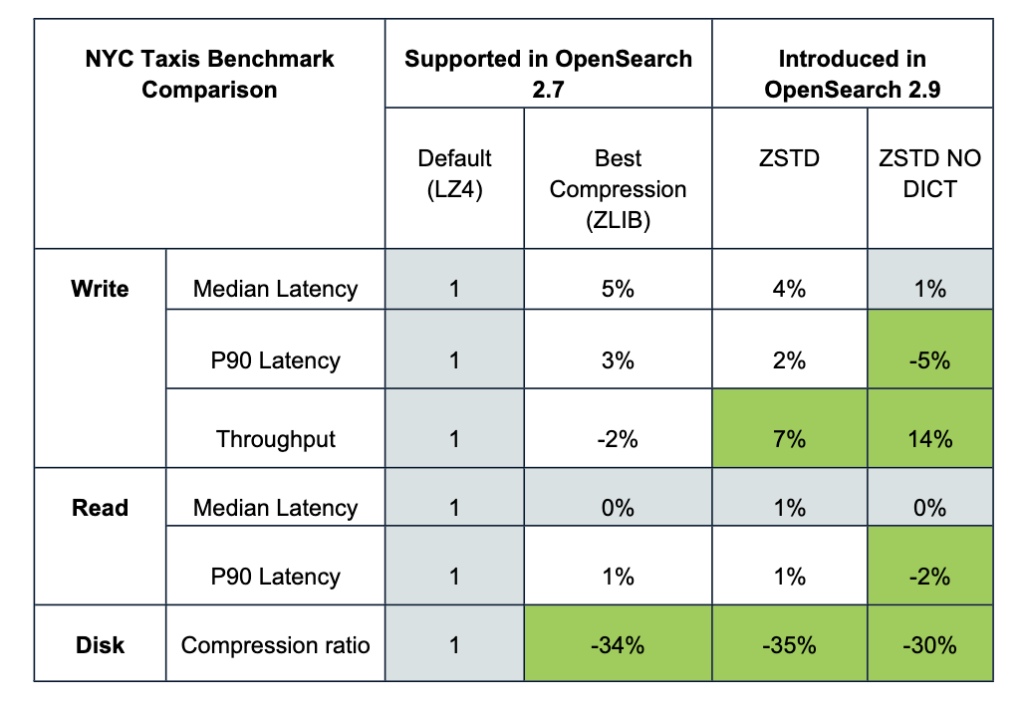
Results
From the experiments, zstd provides a better compression ratio compared to Zlib (best_compression) with a slight gain in write throughput and with similar read latency as LZ4 (best_speed). zstd_no_dict provides 14% better write throughput than LZ4 (best_speed) and a slightly lower compression ratio than Zlib (best_compression).
The following table summarizes the benchmark results.
Limitations
Although Zstd provides the best of both worlds (compression ratio and compression speed), it has the following limitations:
- Certain queries that fetch the entire stored fields for all the matching documents may observe an increase in latency. For more information, see Changing an index codec.
- You can’t use the
zstdandzstd_no_dictcompression codecs for k-NN or Security Analytics indexes.
Conclusion
Zstandard compression provides a good balance between storage size and compression speed, and is able to tune the level of compression based on the use case. Intel and the OpenSearch Service team collaborated on adding Zstandard as one of the compression algorithms in OpenSearch. Intel contributed by designing and implementing the initial version of compression plugin in open-source which was released in OpenSearch v2.7 as experimental feature. OpenSearch Service team worked on further improvements, validated the performance results and integrated it into the OpenSearch server codebase where it was released in OpenSearch v2.9 as a generally available feature.
If you would want to contribute to OpenSearch, create a GitHub issue and share your ideas with us. We would also be interested in learning about your experience with Zstandard in OpenSearch Service. Please feel free to ask more questions in the comments section.
About the Authors
 Praveen Nischal is a Cloud Software Engineer, and leads the cloud workload performance framework at Intel.
Praveen Nischal is a Cloud Software Engineer, and leads the cloud workload performance framework at Intel.
 Mulugeta Mammo is a Senior Software Engineer, and currently leads the OpenSearch Optimization team at Intel.
Mulugeta Mammo is a Senior Software Engineer, and currently leads the OpenSearch Optimization team at Intel.
 Akash Shankaran is a Software Architect and Tech Lead in the Xeon software team at Intel. He works on pathfinding opportunities, and enabling optimizations for data services such as OpenSearch.
Akash Shankaran is a Software Architect and Tech Lead in the Xeon software team at Intel. He works on pathfinding opportunities, and enabling optimizations for data services such as OpenSearch.
 Sarthak Aggarwal is a Software Engineer at Amazon OpenSearch Service. He has been contributing towards open-source development with indexing and storage performance as a primary area of interest.
Sarthak Aggarwal is a Software Engineer at Amazon OpenSearch Service. He has been contributing towards open-source development with indexing and storage performance as a primary area of interest.
 Prabhakar Sithanandam is a Principal Engineer with Amazon OpenSearch Service. He primarily works on the scalability and performance aspects of OpenSearch.
Prabhakar Sithanandam is a Principal Engineer with Amazon OpenSearch Service. He primarily works on the scalability and performance aspects of OpenSearch.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/optimize-storage-costs-in-amazon-opensearch-service-using-zstandard-compression/

