Met de komst van generatieve AI kunnen de huidige basismodellen (FM's), zoals de grote taalmodellen (LLM's) Claude 2 en Llama 2, een reeks generatieve taken uitvoeren, zoals het beantwoorden van vragen, samenvattingen en het maken van inhoud op tekstgegevens. Gegevens uit de echte wereld bestaan echter in meerdere modaliteiten, zoals tekst, afbeeldingen, video en audio. Neem bijvoorbeeld een PowerPoint-diapresentatie. Het kan informatie bevatten in de vorm van tekst, of ingebed in grafieken, tabellen en afbeeldingen.
In dit bericht presenteren we een oplossing die gebruik maakt van multimodale FM's zoals de Multimodale inbedding van Amazon Titan model en LLaVA 1.5 en AWS-services inclusief Amazonebodem en Amazon Sage Maker om soortgelijke generatieve taken uit te voeren op multimodale data.
Overzicht oplossingen
De oplossing biedt een implementatie voor het beantwoorden van vragen met behulp van informatie in de tekst en visuele elementen van een diapresentatie. Het ontwerp is gebaseerd op het concept van Retrieval Augmented Generation (RAG). Traditioneel wordt RAG geassocieerd met tekstuele gegevens die door LLM's kunnen worden verwerkt. In dit bericht breiden we RAG uit met afbeeldingen. Dit biedt een krachtige zoekmogelijkheid om contextueel relevante inhoud te extraheren uit visuele elementen zoals tabellen en grafieken, samen met tekst.
Er zijn verschillende manieren om een RAG-oplossing te ontwerpen die afbeeldingen bevat. We hebben hier één benadering gepresenteerd en zullen een alternatieve benadering volgen in het tweede bericht van deze driedelige serie.
Deze oplossing bevat de volgende componenten:
- Amazon Titan Multimodal Embeddings-model – Deze FM wordt gebruikt om insluitingen te genereren voor de inhoud in het diadeck dat in dit bericht wordt gebruikt. Als multimodaal model kan dit Titan-model tekst, afbeeldingen of een combinatie ervan als invoer verwerken en inbedding genereren. Het Titan Multimodal Embeddings-model genereert vectoren (inbedding) van 1,024 dimensies en is toegankelijk via Amazon Bedrock.
- Grote Taal- en Visieassistent (LLaVA) – LLaVA is een open source multimodaal model voor visueel en taalbegrip en wordt gebruikt om de gegevens in de dia's te interpreteren, inclusief visuele elementen zoals grafieken en tabellen. We gebruiken de versie met 7 miljard parameters LLaVA 1.5-7b bij deze oplossing.
- Amazon Sage Maker – Het LLaVA-model wordt geïmplementeerd op een SageMaker-eindpunt met behulp van SageMaker-hostingservices, en we gebruiken het resulterende eindpunt om gevolgtrekkingen uit te voeren tegen het LLaVA-model. We gebruiken ook SageMaker-notebooks om deze oplossing van begin tot eind te orkestreren en demonstreren.
- Amazon OpenSearch Serverloos – OpenSearch Serverless is een on-demand serverloze configuratie voor Amazon OpenSearch-service. We gebruiken OpenSearch Serverless als een vectordatabase voor het opslaan van insluitingen die zijn gegenereerd door het Titan Multimodal Embeddings-model. Een index gemaakt in de OpenSearch Serverless-collectie dient als vectoropslag voor onze RAG-oplossing.
- Amazon OpenSearch-opname (OSI) – OSI is een volledig beheerde, serverloze gegevensverzamelaar die gegevens levert aan OpenSearch Service-domeinen en OpenSearch Serverloze collecties. In dit bericht gebruiken we een OSI-pijplijn om gegevens te leveren aan de OpenSearch Serverless vectorstore.
Oplossingsarchitectuur
Het oplossingsontwerp bestaat uit twee delen: opname en gebruikersinteractie. Tijdens de opname verwerken we de ingevoerde diaserie door elke dia om te zetten in een afbeelding, insluitingen voor deze afbeeldingen te genereren en vervolgens de vectorgegevensopslag te vullen. Deze stappen worden voltooid voorafgaand aan de stappen voor gebruikersinteractie.
In de gebruikersinteractiefase wordt een vraag van de gebruiker omgezet in inbedding en wordt er gezocht naar gelijkenissen in de vectordatabase om een dia te vinden die mogelijk antwoorden op gebruikersvragen kan bevatten. Vervolgens leveren we deze dia (in de vorm van een afbeeldingsbestand) aan het LLaVA-model en de gebruikersvraag als prompt om een antwoord op de vraag te genereren. Alle code voor dit bericht is beschikbaar in de GitHub rest.
Het volgende diagram illustreert de opnamearchitectuur.
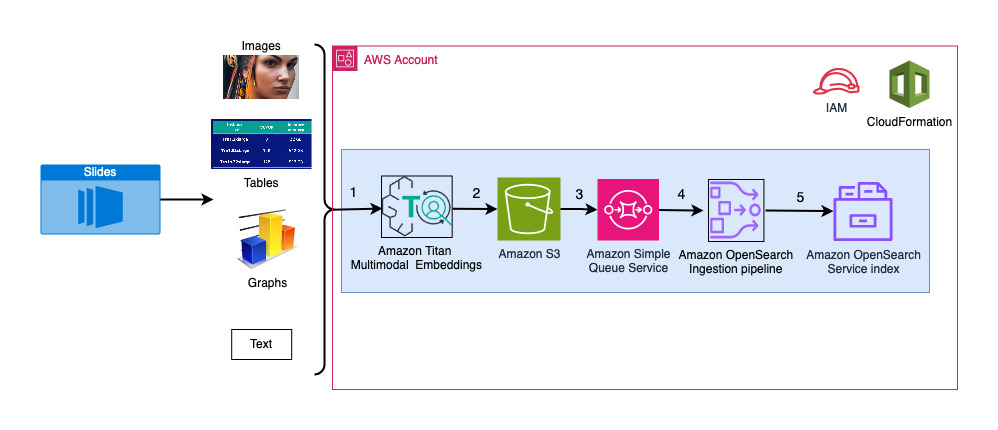
De workflowstappen zijn als volgt:
- Dia's worden geconverteerd naar afbeeldingsbestanden (één per dia) in JPG-formaat en doorgegeven aan het Titan Multimodal Embeddings-model om insluitingen te genereren. In dit bericht gebruiken we het diadeck met de titel Train en implementeer stabiele diffusie met AWS Trainium en AWS Inferentia van de AWS Summit in Toronto, juni 2023, om de oplossing te demonstreren. Het voorbeelddeck heeft 31 dia's, dus we genereren 31 sets vectorinsluitingen, elk met 1,024 dimensies. We voegen extra metadatavelden toe aan deze gegenereerde vectorinsluitingen en maken een JSON-bestand. Deze extra metagegevensvelden kunnen worden gebruikt om uitgebreide zoekopdrachten uit te voeren met behulp van de krachtige zoekmogelijkheden van OpenSearch.
- De gegenereerde insluitingen worden samengevoegd in één JSON-bestand waarnaar wordt geüpload Amazon eenvoudige opslagservice (Amazone S3).
- Via Meldingen van Amazon S3-evenementen, wordt een gebeurtenis in een Amazon Simple Queue-service (Amazon SQS) wachtrij.
- Deze gebeurtenis in de SQS-wachtrij fungeert als trigger voor het uitvoeren van de OSI-pijplijn, die op zijn beurt de gegevens (JSON-bestand) als documenten in de OpenSearch Serverless-index opneemt. Houd er rekening mee dat de OpenSearch Serverless-index is geconfigureerd als de sink voor deze pijplijn en is gemaakt als onderdeel van de OpenSearch Serverless-collectie.
Het volgende diagram illustreert de architectuur voor gebruikersinteractie.
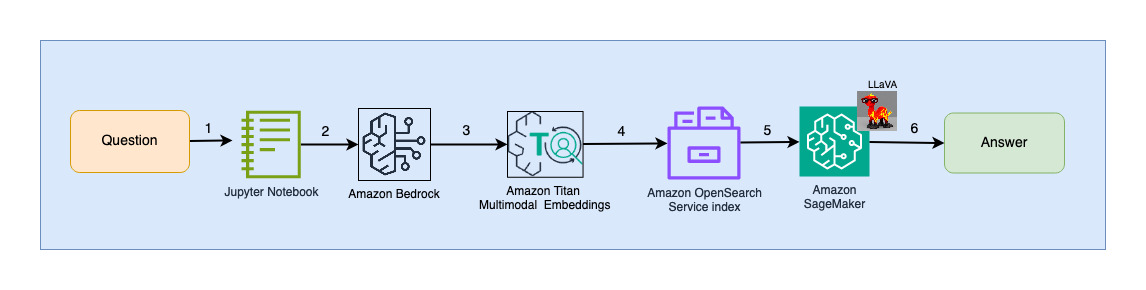
De workflowstappen zijn als volgt:
- Een gebruiker dient een vraag in met betrekking tot de diapresentatie die is opgenomen.
- De gebruikersinvoer wordt omgezet in insluitingen met behulp van het Titan Multimodal Embeddings-model dat toegankelijk is via Amazon Bedrock. Met behulp van deze insluitingen wordt een OpenSearch-vectorzoekopdracht uitgevoerd. We voeren een zoekopdracht met k-dichtstbijzijnde buur (k=1) uit om de meest relevante insluiting op te halen die overeenkomt met de zoekopdracht van de gebruiker. Door k=1 in te stellen, wordt de meest relevante dia voor de gebruikersvraag opgehaald.
- De metadata van het antwoord van OpenSearch Serverless bevat een pad naar de afbeelding die overeenkomt met de meest relevante dia.
- Er wordt een prompt gemaakt door de gebruikersvraag en het afbeeldingspad te combineren en aan LLaVA aangeboden, gehost op SageMaker. Het LLaVA-model kan de gebruikersvraag begrijpen en beantwoorden door de gegevens in de afbeelding te onderzoeken.
- Het resultaat van deze gevolgtrekking wordt teruggestuurd naar de gebruiker.
Deze stappen worden in de volgende paragrafen gedetailleerd besproken. Zie de Resultaten sectie voor schermafbeeldingen en details over de uitvoer.
Voorwaarden
Om de oplossing in dit bericht te implementeren, moet u een AWS-account en bekendheid met FM's, Amazon Bedrock, SageMaker en OpenSearch Service.
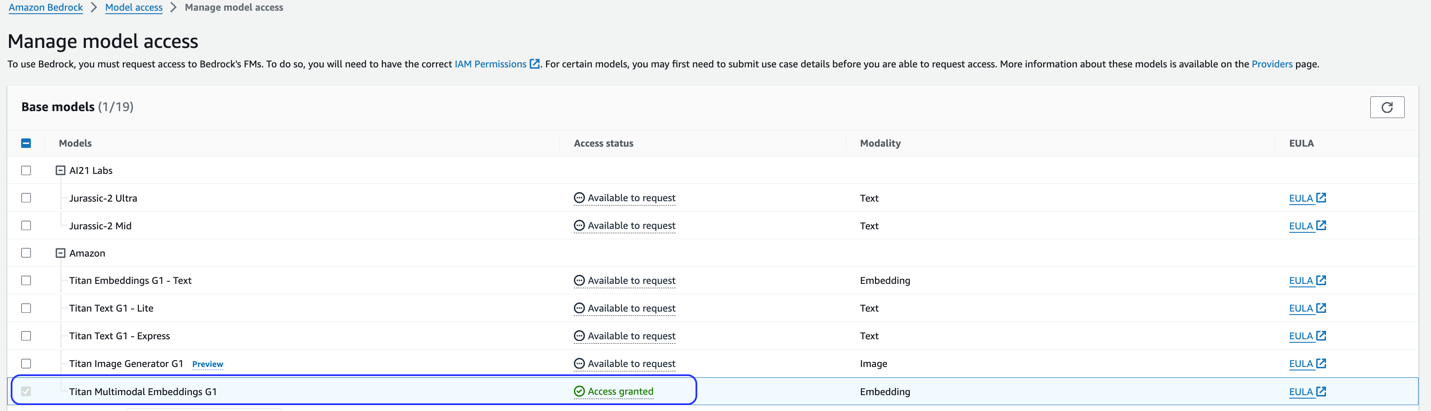
Deze oplossing maakt gebruik van het Titan Multimodal Embeddings-model. Zorg ervoor dat dit model is ingeschakeld voor gebruik in Amazon Bedrock. Kies op de Amazon Bedrock-console Toegang tot modellen in het navigatievenster. Als Titan Multimodal Embeddings is ingeschakeld, wordt de toegangsstatus weergegeven Toegang verleend.
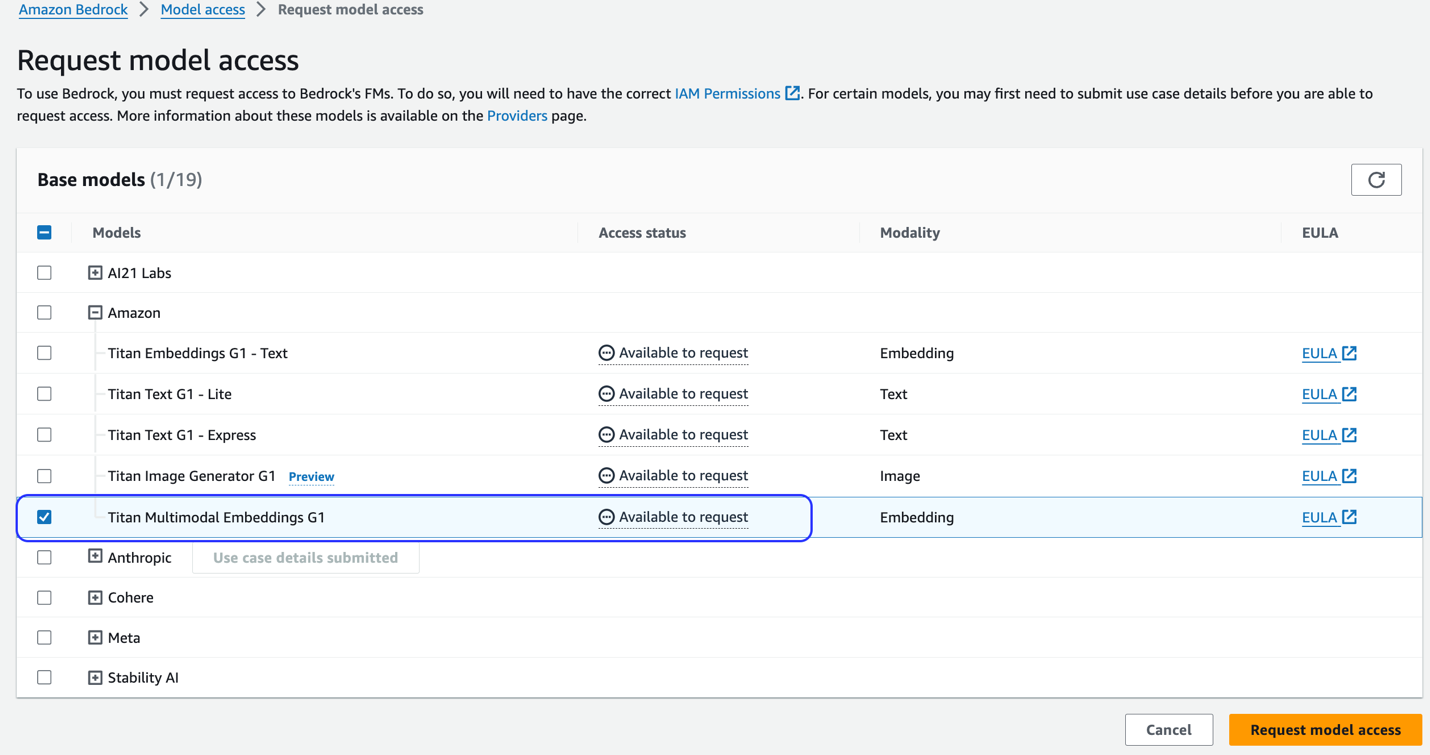
Als het model niet beschikbaar is, schakelt u de toegang tot het model in door te kiezen Beheer modeltoegang, selecteren Titan multimodale inbedding G1en kiezen Modeltoegang aanvragen. Het model is onmiddellijk klaar voor gebruik.
Gebruik een AWS CloudFormation-sjabloon om de oplossingenstack te maken
Gebruik een van de volgende AWS CloudFormatie sjablonen (afhankelijk van uw regio) om de oplossingsbronnen te starten.
| AWS-regio | Link |
|---|---|
us-east-1 |
|
us-west-2 |
Nadat de stapel met succes is gemaakt, navigeert u naar de stapel Uitgangen tabblad op de AWS CloudFormation-console en noteer de waarde voor MultimodalCollectionEndpoint, die we in de volgende stappen gebruiken.
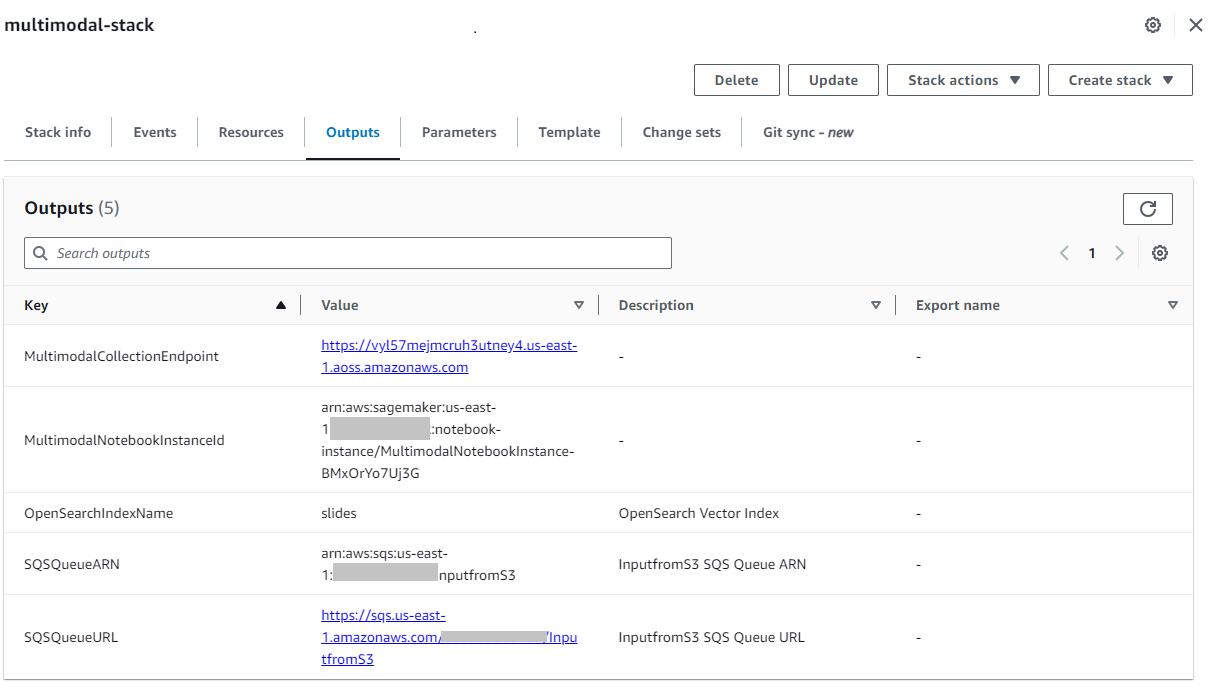
De CloudFormation-sjabloon maakt de volgende bronnen:
- IAM-rollen - Het volgende AWS Identiteits- en toegangsbeheer (IAM)-rollen worden aangemaakt. Update deze rollen zodat ze van toepassing zijn machtigingen met de minste rechten.
SMExecutionRolemet volledige toegang tot Amazon S3, SageMaker, OpenSearch Service en Bedrock.OSPipelineExecutionRolemet toegang tot specifieke Amazon SQS- en OSI-acties.
- SageMaker notitieboek – Alle code voor dit bericht wordt via dit notitieboekje uitgevoerd.
- OpenSearch serverloze verzameling – Dit is de vectordatabase voor het opslaan en ophalen van inbedding.
- OSI-pijplijn – Dit is de pijplijn voor het opnemen van gegevens in OpenSearch Serverless.
- S3 emmer – Alle gegevens voor dit bericht worden in deze bucket opgeslagen.
- SQS-wachtrij – De gebeurtenissen voor het activeren van de OSI-pijplijnrun worden in deze wachtrij geplaatst.
De CloudFormation-sjabloon configureert de OSI-pijplijn met Amazon S3- en Amazon SQS-verwerking als bron en een OpenSearch Serverless-index als sink. Alle objecten die zijn gemaakt in de opgegeven S3-bucket en het voorvoegsel (multimodal/osi-embeddings-json) activeert SQS-meldingen, die door de OSI-pijplijn worden gebruikt om gegevens in OpenSearch Serverless op te nemen.
De CloudFormation-sjabloon maakt ook netwerk, encryptie en toegang tot data beleid vereist voor de OpenSearch Serverless-collectie. Update dit beleid om machtigingen met de minste bevoegdheden toe te passen.
Houd er rekening mee dat er naar de CloudFormation-sjabloonnaam wordt verwezen in SageMaker-notebooks. Als de standaardsjabloonnaam wordt gewijzigd, zorg er dan voor dat u deze bijwerkt in globals.py
Test de oplossing
Nadat de vereiste stappen zijn voltooid en de CloudFormation-stack met succes is gemaakt, bent u nu klaar om de oplossing te testen:
- Kies op de SageMaker-console Notitieboekjes in het navigatievenster.
- Selecteer het
MultimodalNotebookInstancenotebook-instantie en kies JupyterLab openen.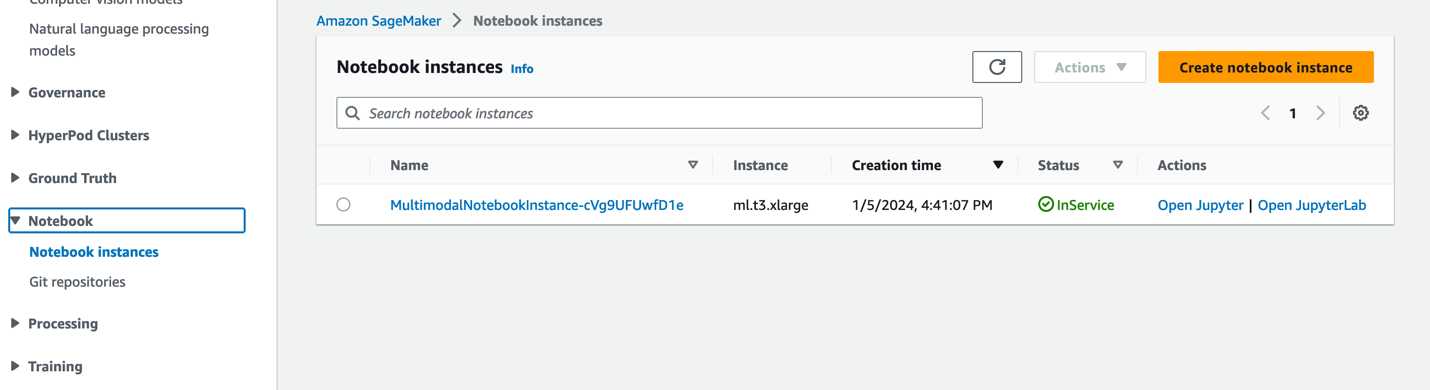
- In Bestandsbrowser, ga naar de map notebooks om de notebooks en ondersteunende bestanden te bekijken.
De notebooks zijn genummerd in de volgorde waarin ze worden gebruikt. Instructies en opmerkingen in elk notitieboekje beschrijven de acties die door dat notitieboekje worden uitgevoerd. We voeren deze notebooks één voor één uit.
- Kies 0_deploy_llava.ipynb om het in JupyterLab te openen.
- Op de lopen menu, kies Voer alle cellen uit om de code in dit notitieblok uit te voeren.
Deze notebook implementeert het LLaVA-v1.5-7B-model op een SageMaker-eindpunt. In deze notebook downloaden we het LLaVA-v1.5-7B-model van HuggingFace Hub en vervangen we het inference.py-script door llava_inference.pyen maak een model.tar.gz-bestand voor dit model. Het model.tar.gz-bestand wordt geüpload naar Amazon S3 en gebruikt voor het implementeren van het model op het SageMaker-eindpunt. De llava_inference.py script heeft extra code om het lezen van een afbeeldingsbestand van Amazon S3 mogelijk te maken en er gevolgtrekkingen op uit te voeren.
- Kies 1_data_prep.ipynb om het in JupyterLab te openen.
- Op de lopen menu, kies Voer alle cellen uit om de code in dit notitieblok uit te voeren.
Dit notitieboekje downloadt de schuif het deck, converteert elke dia naar JPG-bestandsindeling en uploadt deze naar de S3-bucket die voor dit bericht wordt gebruikt.
- Kies 2_data_ingestion.ipynb om het in JupyterLab te openen.
- Op de lopen menu, kies Voer alle cellen uit om de code in dit notitieblok uit te voeren.
In dit notitieboekje doen we het volgende:
- We maken een index in de OpenSearch Serverless-collectie. In deze index worden de insluitingsgegevens voor het diadeck opgeslagen. Zie de volgende code:
- We gebruiken het Titan Multimodal Embeddings-model om de JPG-afbeeldingen die in het vorige notitieboekje zijn gemaakt, om te zetten in vectorinsluitingen. Deze insluitingen en aanvullende metagegevens (zoals het S3-pad van het afbeeldingsbestand) worden opgeslagen in een JSON-bestand en geüpload naar Amazon S3. Houd er rekening mee dat er één JSON-bestand wordt gemaakt, dat documenten bevat voor alle dia's (afbeeldingen) die zijn omgezet in insluitingen. Het volgende codefragment laat zien hoe een afbeelding (in de vorm van een met Base64 gecodeerde tekenreeks) wordt omgezet in insluitingen:
- Deze actie activeert de OpenSearch Ingestion-pijplijn, die het bestand verwerkt en opneemt in de OpenSearch Serverless-index. Het volgende is een voorbeeld van het gemaakte JSON-bestand. (In de voorbeeldcode wordt een vector met vier dimensies weergegeven. Het Titan Multimodal Embeddings-model genereert 1,024 dimensies.)
- Kies 3_rag_inference.ipynb om het in JupyterLab te openen.
- Op de lopen menu, kies Voer alle cellen uit om de code in dit notitieblok uit te voeren.
Dit notebook implementeert de RAG-oplossing: we zetten de gebruikersvraag om in inbedding, zoeken een vergelijkbare afbeelding (dia) uit de vectordatabase en leveren de opgehaalde afbeelding aan LLaVA om een antwoord op de gebruikersvraag te genereren. We gebruiken de volgende promptsjabloon:
Het volgende codefragment biedt de RAG-workflow:
Resultaten
Het volgende is een compilatie van enkele gebruikersvragen en -antwoorden die door onze implementatie zijn gegenereerd. De Vraag kolom legt de gebruikersvraag vast, en de Antwoord kolom is het tekstuele antwoord gegenereerd door LLaVA. Beeld is de k-dichtstbijzijnde (k=1) diamatch die wordt geretourneerd door de OpenSearch Serverless vectorzoekopdracht. Deze dia wordt door LLaVA geïnterpreteerd om het antwoord te bieden.
Multimodale RAG-resultaten
| Vraag | Antwoord | Beeld |
|---|---|---|
| Hoe verhoudt Inf2 zich qua prestaties tot vergelijkbare EC2-instanties? Ik heb cijfers nodig. | Volgens het slidedeck bieden Inf2-instanties van AWS Inferentia2 tot 4x hogere doorvoer en 10x lagere latentie vergeleken met vergelijkbare EC2-instanties. |  |
| Wat bieden de AI/ML-services van AWS, volgens het AI/ML-vliegwiel? | De AWS AI/ML-services bieden betere $/perfer-mogelijkheden, nieuwe mogelijkheden en investeringen in innovatie. | 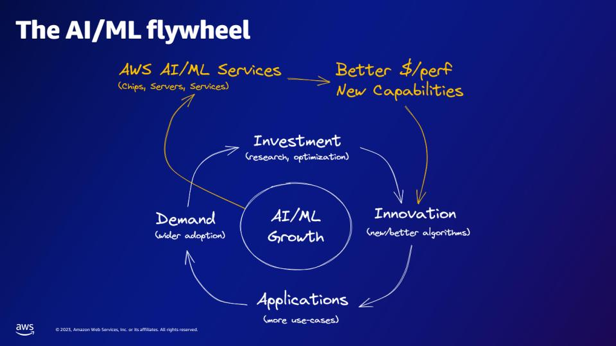 |
| Hoeveel meer parameters heeft GPT-2 vergeleken met GPT-3? Wat is het numerieke verschil tussen de parametergrootte van GPT-2 en GPT-3? | Volgens de dia heeft GPT-3 175 miljard parameters, terwijl GPT-2 1.5 miljard parameters heeft. Het numerieke verschil tussen de parametergrootte van GPT-2 en GPT-3 is 173.5 miljard. | 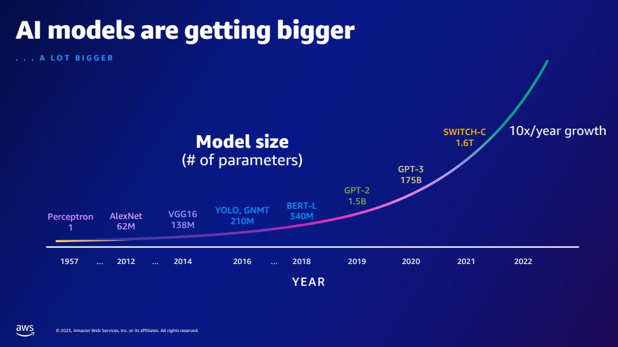 |
| Wat zijn quarks in de deeltjesfysica? | Ik heb het antwoord op deze vraag niet gevonden in het diadeck. |  |
Voel je vrij om deze oplossing uit te breiden naar je slide decks. Werk eenvoudigweg de SLIDE_DECK-variabele in globals.py bij met een URL naar uw diapresentatie en voer de opnamestappen uit die in de vorige sectie zijn beschreven.
Tip
U kunt OpenSearch Dashboards gebruiken voor interactie met de OpenSearch API om snelle tests uit te voeren op uw index en opgenomen gegevens. De volgende schermafbeelding toont een GET-voorbeeld van een OpenSearch-dashboard.
Opruimen
Om te voorkomen dat er in de toekomst kosten in rekening worden gebracht, verwijdert u de bronnen die u heeft gemaakt. Dit doe je door de stack te verwijderen via de CloudFormation console.

Verwijder bovendien het SageMaker-inferentie-eindpunt dat is gemaakt voor LLaVA-inferentie. U kunt dit doen door de opruimstap uit te schakelen 3_rag_inference.ipynb en de cel uitvoeren, of door het eindpunt te verwijderen via de SageMaker-console: kies Gevolgtrekking en Eindpunten in het navigatiedeelvenster, selecteer vervolgens het eindpunt en verwijder het.
Conclusie
Bedrijven genereren voortdurend nieuwe inhoud, en diapresentaties zijn een veelgebruikt mechanisme dat wordt gebruikt om informatie intern met de organisatie en extern met klanten of op conferenties te delen en te verspreiden. Na verloop van tijd kan rijke informatie verborgen en verborgen blijven in niet-tekstuele modaliteiten zoals grafieken en tabellen in deze diapresentaties. U kunt deze oplossing en de kracht van multimodale FM's zoals het Titan Multimodal Embeddings-model en LLaVA gebruiken om nieuwe informatie te ontdekken of nieuwe perspectieven op inhoud in diapresentaties te ontdekken.
We moedigen u aan om meer te leren door te verkennen Amazon SageMaker JumpStart, Amazon Titan-modellen, Amazon Bedrock en OpenSearch Service, en het bouwen van een oplossing met behulp van de voorbeeldimplementatie in dit bericht.
Houd rekening met twee extra berichten als onderdeel van deze serie. Deel 2 behandelt een andere aanpak die u kunt volgen om met uw slidedeck te praten. Deze aanpak genereert en bewaart LLaVA-gevolgtrekkingen en gebruikt deze opgeslagen gevolgtrekkingen om te reageren op vragen van gebruikers. Deel 3 vergelijkt de twee benaderingen.
Over de auteurs
 Amit Arora is een AI- en ML-specialistarchitect bij Amazon Web Services, die zakelijke klanten helpt bij het gebruik van cloudgebaseerde machine learning-services om hun innovaties snel op te schalen. Hij is ook adjunct-docent in het MS data science and analytics-programma aan de Georgetown University in Washington DC
Amit Arora is een AI- en ML-specialistarchitect bij Amazon Web Services, die zakelijke klanten helpt bij het gebruik van cloudgebaseerde machine learning-services om hun innovaties snel op te schalen. Hij is ook adjunct-docent in het MS data science and analytics-programma aan de Georgetown University in Washington DC
 Manju Prasad is een Senior Solutions Architect binnen Strategic Accounts bij Amazon Web Services. Ze richt zich op het bieden van technische begeleiding in verschillende domeinen, waaronder AI/ML aan een grote M&E-klant. Voordat ze bij AWS kwam, ontwierp en bouwde ze oplossingen voor bedrijven in de financiële dienstverleningssector en ook voor een startup.
Manju Prasad is een Senior Solutions Architect binnen Strategic Accounts bij Amazon Web Services. Ze richt zich op het bieden van technische begeleiding in verschillende domeinen, waaronder AI/ML aan een grote M&E-klant. Voordat ze bij AWS kwam, ontwierp en bouwde ze oplossingen voor bedrijven in de financiële dienstverleningssector en ook voor een startup.
 Archana Inapudi is een Senior Solutions Architect bij AWS die strategische klanten ondersteunt. Ze heeft meer dan tien jaar ervaring met het helpen van klanten bij het ontwerpen en bouwen van data-analyse- en databaseoplossingen. Ze heeft een passie voor het gebruik van technologie om waarde te bieden aan klanten en bedrijfsresultaten te bereiken.
Archana Inapudi is een Senior Solutions Architect bij AWS die strategische klanten ondersteunt. Ze heeft meer dan tien jaar ervaring met het helpen van klanten bij het ontwerpen en bouwen van data-analyse- en databaseoplossingen. Ze heeft een passie voor het gebruik van technologie om waarde te bieden aan klanten en bedrijfsresultaten te bereiken.
 Antara Raisa is een AI- en ML Solutions Architect bij Amazon Web Services en ondersteunt strategische klanten in Dallas, Texas. Ze heeft ook eerdere ervaring met het werken met grote zakelijke partners bij AWS, waar ze werkte als Partner Success Solutions Architect voor digital native klanten.
Antara Raisa is een AI- en ML Solutions Architect bij Amazon Web Services en ondersteunt strategische klanten in Dallas, Texas. Ze heeft ook eerdere ervaring met het werken met grote zakelijke partners bij AWS, waar ze werkte als Partner Success Solutions Architect voor digital native klanten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/talk-to-your-slide-deck-using-multimodal-foundation-models-hosted-on-amazon-bedrock-and-amazon-sagemaker-part-1/

