Machine learning (ML) wordt steeds complexer naarmate klanten steeds meer uitdagende problemen proberen op te lossen. Deze complexiteit leidt vaak tot de behoefte aan gedistribueerde ML, waarbij meerdere machines worden gebruikt om één model te trainen. Hoewel dit parallellisatie van taken over meerdere knooppunten mogelijk maakt, wat leidt tot versnelde trainingtijden, verbeterde schaalbaarheid en verbeterde prestaties, zijn er aanzienlijke uitdagingen bij het effectief gebruiken van gedistribueerde hardware. Datawetenschappers moeten uitdagingen aanpakken zoals datapartitionering, taakverdeling, fouttolerantie en schaalbaarheid. ML-ingenieurs moeten parallellisatie, planning, fouten en nieuwe pogingen handmatig afhandelen, waarvoor complexe infrastructuurcode nodig is.
In dit bericht bespreken we de voordelen van het gebruik straal en Amazon Sage Maker voor gedistribueerde ML, en een stapsgewijze handleiding bieden over hoe u deze raamwerken kunt gebruiken om een schaalbare ML-workflow te bouwen en te implementeren.
Ray, een open-source gedistribueerd computerframework, biedt een flexibel raamwerk voor gedistribueerde training en het aanbieden van ML-modellen. Het abstraheert gedistribueerde systeemdetails op laag niveau via eenvoudige, schaalbare bibliotheken voor algemene ML-taken zoals gegevensvoorverwerking, gedistribueerde training, afstemming van hyperparameters, versterkend leren en modelserving.
SageMaker is een volledig beheerde service voor het bouwen, trainen en implementeren van ML-modellen. Ray kan naadloos worden geïntegreerd met de functies van SageMaker om complexe ML-workloads te bouwen en te implementeren die zowel efficiënt als betrouwbaar zijn. De combinatie van Ray en SageMaker biedt end-to-end mogelijkheden voor schaalbare ML-workflows en heeft de volgende opvallende kenmerken:
- Gedistribueerde actoren en parallellismeconstructies in Ray vereenvoudigen het ontwikkelen van gedistribueerde applicaties.
- Ray AI Runtime (AIR) vermindert de wrijving bij de overgang van ontwikkeling naar productie. Met Ray en AIR kan dezelfde Python-code naadloos worden geschaald van een laptop naar een groot cluster.
- De beheerde infrastructuur van SageMaker en functies zoals verwerkingstaken, trainingstaken en hyperparameterafstemmingstaken kunnen onderliggende Ray-bibliotheken gebruiken voor gedistribueerd computergebruik.
- Amazon SageMaker-experimenten maakt het mogelijk om snel te itereren en proeven bij te houden.
- Amazon SageMaker Feature Store biedt een schaalbare opslagplaats voor het opslaan, ophalen en delen van ML-functies voor modeltraining.
- Getrainde modellen kunnen worden opgeslagen, bijgewerkt en bijgehouden Amazon SageMaker-modelregister voor bestuur en management.
- Amazon SageMaker-pijpleidingen maakt het mogelijk de end-to-end ML-levenscyclus te orkestreren, van gegevensvoorbereiding en training tot modelimplementatie als geautomatiseerde workflows.
Overzicht oplossingen
Dit bericht richt zich op de voordelen van het samen gebruiken van Ray en SageMaker. We hebben een end-to-end Ray-gebaseerde ML-workflow opgezet, georkestreerd met behulp van SageMaker Pipelines. De workflow omvat parallelle opname van gegevens in de functieopslag met behulp van Ray-acteurs, voorverwerking van gegevens met Ray Data, trainingsmodellen en afstemming van hyperparameters op schaal met behulp van Ray Train en afstemmingstaken voor hyperparameteroptimalisatie (HPO), en ten slotte modelevaluatie en registratie van het model in een modelregistratie.
Voor onze gegevens gebruiken wij een synthetische woningdataset dat uit acht functies bestaat (YEAR_BUILT, SQUARE_FEET, NUM_BEDROOM, NUM_BATHROOMS, LOT_ACRES, GARAGE_SPACES, FRONT_PORCH en DECK) en ons model zal voorspellen PRICE van het huis.
Elke fase in de ML-workflow is opgedeeld in afzonderlijke stappen, met een eigen script dat invoer- en uitvoerparameters opneemt. In de volgende sectie belichten we sleutelcodefragmenten uit elke stap. De volledige code vind je op de website aws-samples-for-ray GitHub-repository.
Voorwaarden
Om de SageMaker Python SDK te gebruiken en de code uit te voeren die bij dit bericht hoort, heb je de volgende vereisten nodig:
Neem gegevens op in de SageMaker Feature Store
De eerste stap in de ML-workflow is het lezen van het brongegevensbestand Amazon eenvoudige opslagservice (Amazon S3) in CSV-formaat en neem het op in de SageMaker Feature Store. SageMaker Feature Store is een speciaal gebouwde opslagplaats waarmee teams eenvoudig ML-functies kunnen creëren, delen en beheren. Het vereenvoudigt het ontdekken, hergebruiken en delen van functies, wat leidt tot snellere ontwikkeling, betere samenwerking binnen klantteams en lagere kosten.
Het opnemen van functies in het functiearchief omvat de volgende stappen:
- Definieer een functiegroep en maak de functiegroep in het functiearchief.
- Bereid de brongegevens voor het functiearchief voor door een gebeurtenistijd en record-ID toe te voegen voor elke rij met gegevens.
- Neem de voorbereide gegevens op in de functiegroep met behulp van de Boto3 SDK.
In deze sectie belichten we alleen stap 3, omdat dit het deel is dat de parallelle verwerking van de opnametaak met Ray omvat. U kunt de volledige code voor dit proces bekijken in de GitHub repo.
De ingest_features methode wordt gedefinieerd binnen een klasse genaamd Featurestore. Merk op dat de Featurestore klas is versierd met @ray.remote. Dit geeft aan dat een instantie van deze klasse een Ray-acteur is, een stateful en gelijktijdige rekeneenheid binnen Ray. Het is een programmeermodel waarmee u gedistribueerde objecten kunt maken die een interne status behouden en die gelijktijdig toegankelijk zijn voor meerdere taken die op verschillende knooppunten in een Ray-cluster worden uitgevoerd. Actoren bieden een manier om de veranderlijke toestand te beheren en in te kapselen, waardoor ze waardevol worden voor het bouwen van complexe, stateful applicaties in een gedistribueerde omgeving. U kunt ook resourcevereisten specificeren in actoren. In dit geval wordt elke instantie van de FeatureStore klasse vereist 0.5 CPU's. Zie de volgende code:
@ray.remote(num_cpus=0.5)
class Featurestore: def ingest_features(self,feature_group_name, df, region): """ Ingest features to Feature Store Group Args: feature_group_name (str): Feature Group Name data_path (str): Path to the train/validation/test data in CSV format. """ ...U kunt communiceren met de acteur door te bellen naar de remote exploitant. In de volgende code wordt het gewenste aantal actoren als invoerargument aan het script doorgegeven. De gegevens worden vervolgens gepartitioneerd op basis van het aantal actoren en doorgegeven aan de externe parallelle processen om te worden opgenomen in het functiearchief. Je kan bellen get op het object ref om de uitvoering van de huidige taak te blokkeren totdat de berekening op afstand is voltooid en het resultaat beschikbaar is. Wanneer het resultaat beschikbaar is, ray.get zal het resultaat retourneren en de uitvoering van de huidige taak zal doorgaan.
import modin.pandas as pd
import ray df = pd.read_csv(s3_path)
data = prepare_df_for_feature_store(df)
# Split into partitions
partitions = [ray.put(part) for part in np.array_split(data, num_actors)]
# Start actors and assign partitions in a loop
actors = [Featurestore.remote() for _ in range(args.num_actors)]
results = [] for actor, partition in zip(actors, input_partitions): results.append(actor.ingest_features.remote( args.feature_group_name, partition, args.region ) ) ray.get(results)Gegevens voorbereiden voor training, validatie en testen
In deze stap gebruiken we Ray Dataset om onze dataset efficiënt te splitsen, transformeren en schalen ter voorbereiding op machinaal leren. Ray Dataset biedt een standaardmanier om gedistribueerde gegevens in Ray te laden en ondersteunt verschillende opslagsystemen en bestandsformaten. Het beschikt over API's voor algemene voorverwerkingsbewerkingen van ML-gegevens, zoals parallelle transformaties, shuffling, groepering en aggregaties. Ray Dataset verzorgt ook bewerkingen waarvoor stateful setup en GPU-versnelling nodig zijn. Het kan probleemloos worden geïntegreerd met andere gegevensverwerkingsbibliotheken zoals Spark, Pandas, NumPy en meer, evenals met ML-frameworks zoals TensorFlow en PyTorch. Dit maakt het mogelijk om end-to-end datapijplijnen en ML-workflows bovenop Ray te bouwen. Het doel is om gedistribueerde gegevensverwerking en ML eenvoudiger te maken voor praktijkmensen en onderzoekers.
Laten we eens kijken naar gedeelten van de scripts die deze gegevensvoorverwerking uitvoeren. We beginnen met het laden van de gegevens uit de feature store:
def load_dataset(feature_group_name, region): """ Loads the data as a ray dataset from the offline featurestore S3 location Args: feature_group_name (str): name of the feature group Returns: ds (ray.data.dataset): Ray dataset the contains the requested dat from the feature store """ session = sagemaker.Session(boto3.Session(region_name=region)) fs_group = FeatureGroup( name=feature_group_name, sagemaker_session=session ) fs_data_loc = fs_group.describe().get("OfflineStoreConfig").get("S3StorageConfig").get("ResolvedOutputS3Uri") # Drop columns added by the feature store # Since these are not related to the ML problem at hand cols_to_drop = ["record_id", "event_time","write_time", "api_invocation_time", "is_deleted", "year", "month", "day", "hour"] ds = ray.data.read_parquet(fs_data_loc) ds = ds.drop_columns(cols_to_drop) print(f"{fs_data_loc} count is {ds.count()}") return ds
Vervolgens splitsen en schalen we de gegevens met behulp van de abstracties op een hoger niveau die beschikbaar zijn via de ray.data bibliotheek:
def split_dataset(dataset, train_size, val_size, test_size, random_state=None): """ Split dataset into train, validation and test samples Args: dataset (ray.data.Dataset): input data train_size (float): ratio of data to use as training dataset val_size (float): ratio of data to use as validation dataset test_size (float): ratio of data to use as test dataset random_state (int): Pass an int for reproducible output across multiple function calls. Returns: train_set (ray.data.Dataset): train dataset val_set (ray.data.Dataset): validation dataset test_set (ray.data.Dataset): test dataset """ # Shuffle this dataset with a fixed random seed. shuffled_ds = dataset.random_shuffle(seed=random_state) # Split the data into train, validation and test datasets train_set, val_set, test_set = shuffled_ds.split_proportionately([train_size, val_size]) return train_set, val_set, test_set def scale_dataset(train_set, val_set, test_set, target_col): """ Fit StandardScaler to train_set and apply it to val_set and test_set Args: train_set (ray.data.Dataset): train dataset val_set (ray.data.Dataset): validation dataset test_set (ray.data.Dataset): test dataset target_col (str): target col Returns: train_transformed (ray.data.Dataset): train data scaled val_transformed (ray.data.Dataset): val data scaled test_transformed (ray.data.Dataset): test data scaled """ tranform_cols = dataset.columns() # Remove the target columns from being scaled tranform_cols.remove(target_col) # set up a standard scaler standard_scaler = StandardScaler(tranform_cols) # fit scaler to training dataset print("Fitting scaling to training data and transforming dataset...") train_set_transformed = standard_scaler.fit_transform(train_set) # apply scaler to validation and test datasets print("Transforming validation and test datasets...") val_set_transformed = standard_scaler.transform(val_set) test_set_transformed = standard_scaler.transform(test_set) return train_set_transformed, val_set_transformed, test_set_transformed
De verwerkte trein-, validatie- en testdatasets worden opgeslagen in Amazon S3 en worden doorgegeven als invoerparameters voor volgende stappen.
Voer modeltraining en hyperparameteroptimalisatie uit
Nu onze gegevens zijn voorverwerkt en gereed zijn voor modellering, is het tijd om enkele ML-modellen te trainen en hun hyperparameters te verfijnen om de voorspellende prestaties te maximaliseren. We gebruiken XGBoost-Ray, een gedistribueerde backend voor XGBoost gebouwd op Ray waarmee XGBoost-modellen kunnen worden getraind op grote datasets door gebruik te maken van meerdere knooppunten en GPU's. Het biedt eenvoudige drop-in vervangingen voor de trein- en voorspellings-API's van XGBoost, terwijl de complexiteit van gedistribueerd gegevensbeheer en training onder de motorkap wordt afgehandeld.
Om distributie van de training over meerdere knooppunten mogelijk te maken, gebruiken we een helperklasse met de naam RayHelper. Zoals weergegeven in de volgende code, gebruiken we de resourceconfiguratie van de trainingstaak en kiezen we de eerste host als hoofdknooppunt:
class RayHelper(): def __init__(self, ray_port:str="9339", redis_pass:str="redis_password"): .... self.resource_config = self.get_resource_config() self.head_host = self.resource_config["hosts"][0] self.n_hosts = len(self.resource_config["hosts"])We kunnen de hostinformatie gebruiken om te beslissen hoe Ray moet worden geïnitialiseerd voor elk van de trainingstaakinstanties:
def start_ray(self): head_ip = self._get_ip_from_host() # If the current host is the host choosen as the head node # run `ray start` with specifying the --head flag making this is the head node if self.resource_config["current_host"] == self.head_host: output = subprocess.run(['ray', 'start', '--head', '-vvv', '--port', self.ray_port, '--redis-password', self.redis_pass, '--include-dashboard', 'false'], stdout=subprocess.PIPE) print(output.stdout.decode("utf-8")) ray.init(address="auto", include_dashboard=False) self._wait_for_workers() print("All workers present and accounted for") print(ray.cluster_resources()) else: # If the current host is not the head node, # run `ray start` with specifying ip address as the head_host as the head node time.sleep(10) output = subprocess.run(['ray', 'start', f"--address={head_ip}:{self.ray_port}", '--redis-password', self.redis_pass, "--block"], stdout=subprocess.PIPE) print(output.stdout.decode("utf-8")) sys.exit(0)
Wanneer een trainingstaak wordt gestart, kan een Ray-cluster worden geïnitialiseerd door de start_ray() methode op een exemplaar van RayHelper:
if __name__ == '__main__': ray_helper = RayHelper() ray_helper.start_ray() args = read_parameters() sess = sagemaker.Session(boto3.Session(region_name=args.region))
Voor de training gebruiken wij dan de XGBoost trainer van XGBoost-Ray:
def train_xgboost(ds_train, ds_val, params, num_workers, target_col = "price") -> Result: """ Creates a XGBoost trainer, train it, and return the result. Args: ds_train (ray.data.dataset): Training dataset ds_val (ray.data.dataset): Validation dataset params (dict): Hyperparameters num_workers (int): number of workers to distribute the training across target_col (str): target column Returns: result (ray.air.result.Result): Result of the training job """ train_set = RayDMatrix(ds_train, 'PRICE') val_set = RayDMatrix(ds_val, 'PRICE') evals_result = {} trainer = train( params=params, dtrain=train_set, evals_result=evals_result, evals=[(val_set, "validation")], verbose_eval=False, num_boost_round=100, ray_params=RayParams(num_actors=num_workers, cpus_per_actor=1), ) output_path=os.path.join(args.model_dir, 'model.xgb') trainer.save_model(output_path) valMAE = evals_result["validation"]["mae"][-1] valRMSE = evals_result["validation"]["rmse"][-1] print('[3] #011validation-mae:{}'.format(valMAE)) print('[4] #011validation-rmse:{}'.format(valRMSE)) local_testing = False try: load_run(sagemaker_session=sess) except: local_testing = True if not local_testing: # Track experiment if using SageMaker Training with load_run(sagemaker_session=sess) as run: run.log_metric('validation-mae', valMAE) run.log_metric('validation-rmse', valRMSE)
Houd er rekening mee dat tijdens het instantiëren van de trainer, we zijn door RayParams, waarbij het aantal acteurs en het aantal CPU's per acteur wordt vermeld. XGBoost-Ray gebruikt deze informatie om de training te verdelen over alle knooppunten die aan het Ray-cluster zijn gekoppeld.
We maken nu een XGBoost-schatterobject op basis van de SageMaker Python SDK en gebruiken dat voor de HPO-taak.
Orchestreer de voorgaande stappen met behulp van SageMaker Pipelines
Om een end-to-end schaalbare en herbruikbare ML-workflow te bouwen, moeten we een CI/CD-tool gebruiken om de voorgaande stappen in een pijplijn te orkestreren. SageMaker Pipelines heeft directe integratie met SageMaker, de SageMaker Python SDK en SageMaker Studio. Met deze integratie kunt u ML-workflows maken met een gebruiksvriendelijke Python SDK, en vervolgens uw workflow visualiseren en beheren met SageMaker Studio. U kunt ook de geschiedenis van uw gegevens volgen binnen de pijplijnuitvoering en stappen voor caching aanwijzen.
SageMaker Pipelines creëert een Directed Acyclic Graph (DAG) die de stappen bevat die nodig zijn om een ML-workflow te bouwen. Elke pijplijn is een reeks onderling verbonden stappen, georkestreerd door gegevensafhankelijkheden tussen stappen, en kan worden geparametriseerd, zodat u invoervariabelen als parameters kunt opgeven voor elke uitvoering van de pijplijn. SageMaker Pipelines heeft vier soorten pijplijnparameters: ParameterString, ParameterInteger, ParameterFloat en ParameterBoolean. In deze sectie parametriseren we enkele invoervariabelen en stellen we de stapcaching-configuratie in:
processing_instance_count = ParameterInteger( name='ProcessingInstanceCount', default_value=1
)
feature_group_name = ParameterString( name='FeatureGroupName', default_value='fs-ray-synthetic-housing-data'
)
bucket_prefix = ParameterString( name='Bucket_Prefix', default_value='aws-ray-mlops-workshop/feature-store'
)
rmse_threshold = ParameterFloat(name="RMSEThreshold", default_value=15000.0) train_size = ParameterString( name='TrainSize', default_value="0.6"
)
val_size = ParameterString( name='ValidationSize', default_value="0.2"
)
test_size = ParameterString( name='TestSize', default_value="0.2"
) cache_config = CacheConfig(enable_caching=True, expire_after="PT12H")
We definiëren twee verwerkingsstappen: één voor opname in de SageMaker Feature Store, de andere voor gegevensvoorbereiding. Dit zou erg op de voorgaande stappen moeten lijken die eerder zijn beschreven. De enige nieuwe coderegel is de ProcessingStep na de definitie van de stappen, waardoor we de configuratie van de verwerkingstaak kunnen nemen en deze als pijplijnstap kunnen opnemen. We specificeren verder de afhankelijkheid van de gegevensvoorbereidingsstap van de opnamestap van de SageMaker Feature Store. Zie de volgende code:
feature_store_ingestion_step = ProcessingStep( name='FeatureStoreIngestion', step_args=fs_processor_args, cache_config=cache_config
) preprocess_dataset_step = ProcessingStep( name='PreprocessData', step_args=processor_args, cache_config=cache_config
)
preprocess_dataset_step.add_depends_on([feature_store_ingestion_step])
Op dezelfde manier moeten we, om een modeltraining en afstemmingsstap te bouwen, een definitie toevoegen van TuningStep na de code van de modeltrainingsstap om ons in staat te stellen SageMaker-hyperparameterafstemming uit te voeren als een stap in de pijplijn:
tuning_step = TuningStep( name="HPTuning", tuner=tuner, inputs={ "train": TrainingInput( s3_data=preprocess_dataset_step.properties.ProcessingOutputConfig.Outputs[ "train" ].S3Output.S3Uri, content_type="text/csv" ), "validation": TrainingInput( s3_data=preprocess_dataset_step.properties.ProcessingOutputConfig.Outputs[ "validation" ].S3Output.S3Uri, content_type="text/csv" ) }, cache_config=cache_config,
)
tuning_step.add_depends_on([preprocess_dataset_step])
Na de afstemmingsstap kiezen we ervoor om het beste model te registreren in het SageMaker Model Registry. Om de modelkwaliteit te controleren, implementeren we een minimale kwaliteitspoort die de objectieve metriek (RMSE) van het beste model vergelijkt met een drempelwaarde die is gedefinieerd als de invoerparameter van de pijplijn rmse_threshold. Om deze evaluatie uit te voeren, creëren we nog een verwerkingsstap om een evaluatiescript. Het modelevaluatieresultaat wordt opgeslagen als een eigenschappenbestand. Eigenschappenbestanden zijn vooral handig bij het analyseren van de resultaten van een verwerkingsstap om te beslissen hoe andere stappen moeten worden uitgevoerd. Zie de volgende code:
# Specify where we'll store the model evaluation results so that other steps can access those results
evaluation_report = PropertyFile( name='EvaluationReport', output_name='evaluation', path='evaluation.json',
) # A ProcessingStep is used to evaluate the performance of a selected model from the HPO step. # In this case, the top performing model is evaluated. evaluation_step = ProcessingStep( name='EvaluateModel', processor=evaluation_processor, inputs=[ ProcessingInput( source=tuning_step.get_top_model_s3_uri( top_k=0, s3_bucket=bucket, prefix=s3_prefix ), destination='/opt/ml/processing/model', ), ProcessingInput( source=preprocess_dataset_step.properties.ProcessingOutputConfig.Outputs['test'].S3Output.S3Uri, destination='/opt/ml/processing/test', ), ], outputs=[ ProcessingOutput( output_name='evaluation', source='/opt/ml/processing/evaluation' ), ], code='./pipeline_scripts/evaluate/script.py', property_files=[evaluation_report],
)
We definiëren een ModelStep om het beste model in onze pijplijn te registreren in het SageMaker Model Registry. Indien het beste model onze vooraf bepaalde kwaliteitscontrole niet doorstaat, specificeren we bovendien een FailStep om een foutmelding uit te voeren:
register_step = ModelStep( name='RegisterTrainedModel', step_args=model_registry_args
) metrics_fail_step = FailStep( name="RMSEFail", error_message=Join(on=" ", values=["Execution failed due to RMSE >", rmse_threshold]),
)
Vervolgens gebruiken we een ConditionStep om te evalueren of de modelregistratiestap of de faalstap als volgende in de pijplijn moet worden genomen. In ons geval wordt het beste model geregistreerd als de RMSE-score lager is dan de drempelwaarde.
# Condition step for evaluating model quality and branching execution
cond_lte = ConditionLessThanOrEqualTo( left=JsonGet( step_name=evaluation_step.name, property_file=evaluation_report, json_path='regression_metrics.rmse.value', ), right=rmse_threshold,
)
condition_step = ConditionStep( name='CheckEvaluation', conditions=[cond_lte], if_steps=[register_step], else_steps=[metrics_fail_step],
)Ten slotte orkestreren we alle gedefinieerde stappen in een pijplijn:
pipeline_name = 'synthetic-housing-training-sm-pipeline-ray'
step_list = [ feature_store_ingestion_step, preprocess_dataset_step, tuning_step, evaluation_step, condition_step ] training_pipeline = Pipeline( name=pipeline_name, parameters=[ processing_instance_count, feature_group_name, train_size, val_size, test_size, bucket_prefix, rmse_threshold ], steps=step_list
) # Note: If an existing pipeline has the same name it will be overwritten.
training_pipeline.upsert(role_arn=role_arn)
De voorgaande pijplijn kan rechtstreeks in SageMaker Studio worden gevisualiseerd en uitgevoerd, of worden uitgevoerd door aan te roepen execution = training_pipeline.start(). De volgende afbeelding illustreert de pijpleidingstroom.
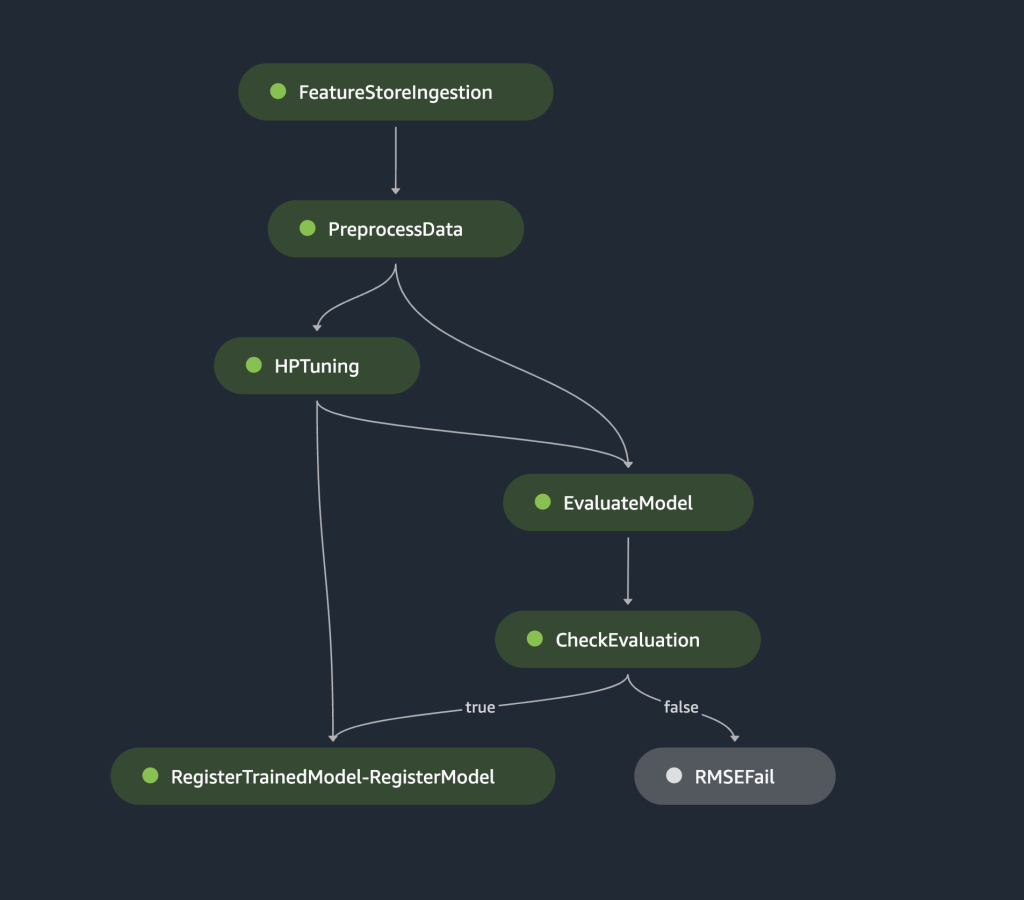
Bovendien kunnen we de reeks artefacten bekijken die zijn gegenereerd door de uitvoering van de pijplijn.
from sagemaker.lineage.visualizer import LineageTableVisualizer viz = LineageTableVisualizer(sagemaker.session.Session())
for execution_step in reversed(execution.list_steps()): print(execution_step) display(viz.show(pipeline_execution_step=execution_step)) time.sleep(5)
Implementeer het model
Nadat het beste model via een pijplijnrun in SageMaker Model Registry is geregistreerd, implementeren we het model op een realtime eindpunt met behulp van de volledig beheerde modelimplementatiemogelijkheden van SageMaker. SageMaker heeft andere modelimplementatieopties om aan de behoeften van verschillende gebruiksscenario's te voldoen. Voor details, zie Implementeer modellen voor gevolgtrekking bij het kiezen van de juiste optie voor uw gebruikssituatie. Laten we eerst het model registreren in het SageMaker Model Registry:
xgb_regressor_model = ModelPackage( role_arn, model_package_arn=model_package_arn, name=model_name
)De huidige status van het model is PendingApproval. We moeten de status instellen op Approved voorafgaand aan de inzet:
sagemaker_client.update_model_package( ModelPackageArn=xgb_regressor_model.model_package_arn, ModelApprovalStatus='Approved'
) xgb_regressor_model.deploy( initial_instance_count=1, instance_type='ml.m5.xlarge', endpoint_name=endpoint_name
)
Opruimen
Vergeet niet om, nadat u klaar bent met experimenteren, de bronnen op te ruimen om onnodige kosten te voorkomen. Om op te schonen, verwijdert u het realtime eindpunt, de modelgroep, de pijplijn en de functiegroep door de API's aan te roepen Eindpunt verwijderen, VerwijderModelPackageGroup, Pipeline verwijderen en VerwijderFeatureGrouprespectievelijk, en sluit alle SageMaker Studio-notebookinstanties af.
Conclusie
Dit bericht demonstreerde een stapsgewijze uitleg over hoe u SageMaker Pipelines kunt gebruiken om op Ray gebaseerde ML-workflows te orkestreren. We hebben ook de mogelijkheid gedemonstreerd van SageMaker Pipelines om te integreren met ML-tools van derden. Er zijn verschillende AWS-services die Ray-workloads op een schaalbare en veilige manier ondersteunen om uitmuntende prestaties en operationele efficiëntie te garanderen. Nu is het jouw beurt om deze krachtige mogelijkheden te verkennen en te beginnen met het optimaliseren van je machine learning-workflows met Amazon SageMaker Pipelines en Ray. Onderneem vandaag nog actie en ontgrendel het volledige potentieel van uw ML-projecten!
Over de auteur
 Raju Rangan is Senior Solutions Architect bij Amazon Web Services (AWS). Hij werkt samen met door de overheid gesponsorde entiteiten en helpt hen bij het bouwen van AI/ML-oplossingen met behulp van AWS. Als hij niet aan cloudoplossingen sleutelt, zie je hem rondhangen met familie of vogeltjes verpletteren in een levendig potje badminton met vrienden.
Raju Rangan is Senior Solutions Architect bij Amazon Web Services (AWS). Hij werkt samen met door de overheid gesponsorde entiteiten en helpt hen bij het bouwen van AI/ML-oplossingen met behulp van AWS. Als hij niet aan cloudoplossingen sleutelt, zie je hem rondhangen met familie of vogeltjes verpletteren in een levendig potje badminton met vrienden.
 sherry ding is een senior AI/ML-specialistische oplossingsarchitect bij Amazon Web Services (AWS). Ze heeft uitgebreide ervaring met machinaal leren en heeft een doctoraat in computerwetenschappen. Ze werkt voornamelijk met klanten uit de publieke sector aan verschillende AI/ML-gerelateerde zakelijke uitdagingen, en helpt hen hun machine learning-traject op de AWS Cloud te versnellen. Als ze geen klanten helpt, houdt ze van buitenactiviteiten.
sherry ding is een senior AI/ML-specialistische oplossingsarchitect bij Amazon Web Services (AWS). Ze heeft uitgebreide ervaring met machinaal leren en heeft een doctoraat in computerwetenschappen. Ze werkt voornamelijk met klanten uit de publieke sector aan verschillende AI/ML-gerelateerde zakelijke uitdagingen, en helpt hen hun machine learning-traject op de AWS Cloud te versnellen. Als ze geen klanten helpt, houdt ze van buitenactiviteiten.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/orchestrate-ray-based-machine-learning-workflows-using-amazon-sagemaker/

