AutoML Hiermee kunt u snelle, algemene inzichten uit uw gegevens halen, direct aan het begin van de levenscyclus van een Machine Learning (ML)-project. Als u vooraf begrijpt welke voorverwerkingstechnieken en algoritmetypen de beste resultaten opleveren, verkort u de tijd die nodig is om het juiste model te ontwikkelen, trainen en implementeren. Het speelt een cruciale rol in het ontwikkelingsproces van elk model en stelt datawetenschappers in staat zich te concentreren op de meest veelbelovende ML-technieken. Bovendien biedt AutoML basismodelprestaties die als referentiepunt kunnen dienen voor het datawetenschapsteam.
Een AutoML-tool past een combinatie van verschillende algoritmen en verschillende voorbewerkingstechnieken toe op uw gegevens. Het kan bijvoorbeeld de gegevens schalen, univariate kenmerkselectie uitvoeren, PCA uitvoeren op verschillende variantiedrempelniveaus en clustering toepassen. Dergelijke voorbewerkingstechnieken kunnen afzonderlijk worden toegepast of in een pijplijn worden gecombineerd. Vervolgens traint een AutoML-tool verschillende modeltypen, zoals lineaire regressie, Elastic-Net of Random Forest, op verschillende versies van uw voorverwerkte dataset en voert hyperparameteroptimalisatie (HPO) uit. Amazon SageMaker-stuurautomaat elimineert het zware werk van het bouwen van ML-modellen. Na het aanleveren van de dataset onderzoekt SageMaker Autopilot automatisch verschillende oplossingen om het beste model te vinden. Maar wat als u uw op maat gemaakte versie van een AutoML-workflow wilt implementeren?
Dit bericht laat zien hoe u een op maat gemaakte AutoML-workflow kunt maken Amazon Sage Maker gebruik Amazon SageMaker automatische modelafstemming met voorbeeldcode beschikbaar in a GitHub-opslagplaats.
Overzicht oplossingen
Laten we voor dit gebruiksscenario aannemen dat u deel uitmaakt van een data science-team dat modellen ontwikkelt in een gespecialiseerd domein. U heeft een reeks aangepaste voorverwerkingstechnieken ontwikkeld en een aantal algoritmen geselecteerd waarvan u doorgaans verwacht dat ze goed zullen werken met uw ML-probleem. Wanneer u aan nieuwe ML-gebruiksscenario's werkt, wilt u eerst een AutoML-run uitvoeren met behulp van uw voorverwerkingstechnieken en algoritmen om de reikwijdte van mogelijke oplossingen te beperken.
Voor dit voorbeeld gebruikt u geen gespecialiseerde dataset; in plaats daarvan werkt u met de California Housing-gegevensset waaruit u importeert Amazon eenvoudige opslagservice (Amazone S3). De focus ligt op het demonstreren van de technische implementatie van de oplossing met behulp van SageMaker HPO, die later op elke dataset en domein kan worden toegepast.
Het volgende diagram toont de algemene oplossingsworkflow.

Voorwaarden
Het volgende zijn vereisten voor het voltooien van de walkthrough in dit bericht:
Implementeer de oplossing
De volledige code is beschikbaar in de GitHub repo.
De stappen om de oplossing te implementeren (zoals vermeld in het workflowdiagram) zijn als volgt:
- Maak een notebookinstantie en specificeer het volgende:
- Voor Type exemplaar van notebook, kiezen ml.t3.medium.
- Voor Elastische gevolgtrekking, kiezen geen.
- Voor Platform-ID, kiezen Amazon Linux 2, Jupyter Lab 3.
- Voor IAM-rol, kies de standaard
AmazonSageMaker-ExecutionRole. Als het niet bestaat, maak dan een nieuw AWS Identiteits- en toegangsbeheer (IAM) rol en voeg de AmazonSageMakerFullAccess IAM-beleid.
Houd er rekening mee dat u in de productie een uitvoeringsrol en -beleid met een minimaal bereik moet maken.
- Open de JupyterLab-interface voor uw notebookinstantie en kloon de GitHub-opslagplaats.
U kunt dat doen door een nieuwe terminalsessie te starten en de git clone <REPO> opdracht of door de UI-functionaliteit te gebruiken, zoals weergegeven in de volgende schermafbeelding.

- Open de
automl.ipynbnotebook-bestand, selecteert u hetconda_python3kernel en volg de instructies om een reeks HPO-banen.
Als u de code zonder wijzigingen wilt uitvoeren, moet u het servicequotum verhogen voor ml.m5.large voor gebruik van trainingstaken en Aantal instanties voor alle trainingstaken. AWS staat standaard slechts 20 parallelle SageMaker-trainingstaken toe voor beide quota. Voor beide moet u een quotumverhoging naar 30 aanvragen. Beide quotawijzigingen moeten doorgaans binnen enkele minuten worden goedgekeurd. Verwijzen naar Verzoek om een verhoging van het quotum voor meer informatie.

Als u het quotum niet wilt wijzigen, kunt u eenvoudigweg de waarde van de MAX_PARALLEL_JOBS variabele in het script (bijvoorbeeld naar 5).
- Elke HPO-taak voltooit een reeks opleiding baan proeven en geef het model aan met optimale hyperparameters.
- Analyseer de resultaten en het best presterende model inzetten.
Deze oplossing brengt kosten met zich mee in uw AWS-account. De kosten van deze oplossing zijn afhankelijk van het aantal en de duur van de HPO-opleidingsbanen. Naarmate deze stijgen, zullen ook de kosten stijgen. U kunt de kosten verlagen door de trainingstijd en configuratie te beperken TuningJobCompletionCriteriaConfig volgens de instructies die later in dit bericht worden besproken. Voor prijsinformatie, zie Amazon SageMaker-prijzen.
In de volgende secties bespreken we de notebook in meer detail met codevoorbeelden en de stappen om de resultaten te analyseren en het beste model te selecteren.
Initiële setup
Laten we beginnen met het uitvoeren van de Importeren en instellen sectie in de custom-automl.ipynb notitieboekje. Het installeert en importeert alle vereiste afhankelijkheden, instantiëert een SageMaker-sessie en -client en stelt de standaardregio en S3-bucket in voor het opslaan van gegevens.
Data voorbereiding
Download de California Housing-gegevensset en bereid deze voor door de Download Data gedeelte van het notitieboekje. De dataset wordt opgesplitst in trainings- en testdataframes en geüpload naar de standaard S3-bucket van de SageMaker-sessie.
De volledige dataset bevat in totaal 20,640 records en 9 kolommen, inclusief het doel. Het doel is om de mediaanwaarde van een huis te voorspellen (medianHouseValue kolom). De volgende schermafbeelding toont de bovenste rijen van de gegevensset.

Sjabloon voor trainingsscript
De AutoML-workflow in dit bericht is gebaseerd op scikit-leren pijpleidingen en algoritmen voorbewerken. Het doel is om een grote combinatie van verschillende voorverwerkingspijplijnen en algoritmen te genereren om de best presterende opstelling te vinden. Laten we beginnen met het maken van een algemeen trainingsscript, dat lokaal op de notebookinstantie wordt bewaard. In dit script zijn er twee lege commentaarblokken: één voor het injecteren van hyperparameters en de andere voor het pijplijnobject voor het preprocessing-model. Ze zullen dynamisch worden geïnjecteerd voor elk kandidaat-voorverwerkingsmodel. Het doel van één generiek script is om de implementatie DROOG te houden (herhaal jezelf niet).
Maak voorbewerkings- en modelcombinaties
De preprocessors woordenboek bevat een specificatie van voorverwerkingstechnieken die worden toegepast op alle invoerkenmerken van het model. Elk recept wordt gedefinieerd met behulp van een Pipeline of FeatureUnion object van scikit-learn, dat individuele gegevenstransformaties aan elkaar koppelt en op elkaar stapelt. Bijvoorbeeld, mean-imp-scale is een eenvoudig recept dat ervoor zorgt dat ontbrekende waarden worden geïmputeerd met behulp van gemiddelde waarden van de respectievelijke kolommen en dat alle objecten worden geschaald met behulp van de Standaardscaler. De mean-imp-scale-pca Receptketens brengen nog een paar bewerkingen samen:
- Vul ontbrekende waarden in kolommen toe met het gemiddelde ervan.
- Pas functieschaling toe met behulp van gemiddelde en standaarddeviatie.
- Bereken PCA bovenop de invoergegevens bij een gespecificeerde variantiedrempelwaarde en voeg deze samen met de toegerekende en geschaalde invoerkenmerken.
In dit bericht zijn alle invoerfuncties numeriek. Als uw invoergegevensset meer gegevenstypen bevat, moet u een ingewikkeldere pijplijn opgeven waarin verschillende voorverwerkingstakken worden toegepast op verschillende sets met functietypen.
De models woordenboek bevat specificaties van verschillende algoritmen waaraan u de dataset kunt aanpassen. Elk modeltype wordt geleverd met de volgende specificatie in het woordenboek:
- script_uitvoer – Verwijst naar de locatie van het trainingsscript dat door de schatter wordt gebruikt. Dit veld wordt dynamisch gevuld wanneer de
modelswoordenboek wordt gecombineerd met depreprocessorswoordenboek. - inserties – Definieert code die in het bestand wordt ingevoegd
script_draft.pyen vervolgens opgeslagen onderscript_output. De sleutel“preprocessor”is opzettelijk leeg gelaten omdat deze locatie is gevuld met een van de preprocessors om meerdere model-preprocessorcombinaties te creëren. - hyperparameters – Een set hyperparameters die zijn geoptimaliseerd door de HPO-taak.
- include_cls_metadata – Meer configuratiedetails vereist door de SageMaker
Tunerklasse.
Een volledig voorbeeld van de models woordenboek is beschikbaar in de GitHub-repository.
Laten we vervolgens de preprocessors en models woordenboeken en maak alle mogelijke combinaties. Als uw preprocessors woordenboek bevat 10 recepten en je hebt 5 modeldefinities in de models woordenboek bevat het nieuw gemaakte pijplijnwoordenboek 50 preprocessormodelpijplijnen die worden geëvalueerd tijdens HPO. Houd er rekening mee dat er op dit moment nog geen afzonderlijke pijplijnscripts zijn gemaakt. Het volgende codeblok (cel 9) van het Jupyter-notebook doorloopt alle preprocessor-modelobjecten in de pipelines woordenboek, voegt alle relevante codestukken in en bewaart een pijplijnspecifieke versie van het script lokaal in het notitieblok. Deze scripts worden gebruikt in de volgende stappen bij het maken van individuele schatters die u in de HPO-taak aansluit.
Definieer schatters
U kunt nu werken aan het definiëren van SageMaker Estimators die de HPO-taak gebruikt nadat de scripts gereed zijn. Laten we beginnen met het maken van een wrapper-klasse die enkele gemeenschappelijke eigenschappen voor alle schatters definieert. Het erft van de SKLearn class en specificeert de rol, het aantal exemplaren en het type, evenals welke kolommen door het script worden gebruikt als functies en het doel.
Laten we de . bouwen estimators woordenboek door alle scripts te doorlopen die eerder zijn gegenereerd en zich in de scripts map. U instantiëert een nieuwe schatter met behulp van de SKLearnBase klasse, met een unieke schatternaam, en een van de scripts. Merk op dat de estimators woordenboek heeft twee niveaus: het hoogste niveau definieert a pipeline_family. Dit is een logische groepering op basis van het type modellen dat moet worden geëvalueerd en is gelijk aan de lengte van de models woordenboek. Het tweede niveau bevat individuele preprocessortypen gecombineerd met de gegeven pipeline_family. Deze logische groepering is vereist bij het aanmaken van de HPO-functie.
Definieer HPO-tunerargumenten
Om het doorgeven van argumenten aan de HPO te optimaliseren Tuner klasse, de HyperparameterTunerArgs dataklasse wordt geïnitialiseerd met argumenten vereist door de HPO-klasse. Het wordt geleverd met een reeks functies die ervoor zorgen dat HPO-argumenten worden geretourneerd in een formaat dat wordt verwacht bij het tegelijk implementeren van meerdere modeldefinities.
Het volgende codeblok maakt gebruik van het eerder geïntroduceerde HyperparameterTunerArgs gegevensklasse. Je maakt een ander woordenboek genaamd hp_args en genereer een set invoerparameters die specifiek zijn voor elk estimator_family van het estimators woordenboek. Deze argumenten worden in de volgende stap gebruikt bij het initialiseren van HPO-taken voor elke modelfamilie.
Maak HPO-tunerobjecten
In deze stap maakt u voor elk afzonderlijk stemapparaat aan estimator_family. Waarom creëer je drie afzonderlijke HPO-banen in plaats van er maar één in alle schatters te lanceren? De HyperparameterTuner klasse is beperkt tot 10 daaraan gekoppelde modeldefinities. Daarom is elke HPO verantwoordelijk voor het vinden van de best presterende preprocessor voor een bepaalde modelfamilie en het afstemmen van de hyperparameters van die modelfamilie.
Hieronder volgen nog enkele punten met betrekking tot de opstelling:
- De optimalisatiestrategie is Bayesiaans, wat betekent dat de HPO actief de prestaties van alle onderzoeken monitort en de optimalisatie navigeert naar meer veelbelovende hyperparametercombinaties. Vroegtijdig stoppen moet worden ingesteld af or automobiel bij het werken met een Bayesiaanse strategie, die die logica zelf afhandelt.
- Elke HPO-taak heeft een capaciteit van maximaal 100 banen en voert 10 banen parallel uit. Als u met grotere gegevenssets te maken heeft, wilt u wellicht het totale aantal taken verhogen.
- Daarnaast wilt u mogelijk instellingen gebruiken die bepalen hoe lang een taak wordt uitgevoerd en hoeveel taken uw HPO activeert. Eén manier om dat te doen is door de maximale looptijd in seconden in te stellen (voor dit bericht stellen we deze in op 1 uur). Een andere is om de onlangs uitgebrachte te gebruiken
TuningJobCompletionCriteriaConfig. Het biedt een reeks instellingen die de voortgang van uw opdrachten monitoren en beslissen of het waarschijnlijk is dat meer opdrachten het resultaat zullen verbeteren. In dit bericht hebben we het maximale aantal trainingstaken die niet verbeteren ingesteld op 20. Op die manier hoef je, als de score niet verbetert (bijvoorbeeld vanaf de veertigste proef), pas voor de resterende proeven te betalenmax_jobsis bereikt.
Laten we nu de tuners en hp_args woordenboeken en activeer alle HPO-taken in SageMaker. Let op het gebruik van het wait-argument ingesteld op False, wat betekent dat de kernel niet wacht tot de resultaten compleet zijn en dat je alle taken in één keer kunt activeren.
Het is waarschijnlijk dat niet alle trainingstaken zullen worden voltooid en dat sommige ervan door de HPO-taak kunnen worden stopgezet. De reden hiervoor is de TuningJobCompletionCriteriaConfig—de optimalisatie eindigt als aan een van de gespecificeerde criteria wordt voldaan. In dit geval, wanneer de optimalisatiecriteria gedurende 20 opeenvolgende banen niet verbeteren.
Analyseer resultaten
Cel 15 van het notebook controleert of alle HPO-taken zijn voltooid en combineert alle resultaten in de vorm van een panda-dataframe voor verdere analyse. Laten we, voordat we de resultaten in detail analyseren, eens op hoog niveau naar de SageMaker-console kijken.
Bovenaan de Taken voor het afstemmen van hyperparameters pagina kunt u uw drie gelanceerde HPO-banen zien. Ze waren allemaal vroeg klaar en voerden niet alle 100 trainingsopdrachten uit. In de volgende schermafbeelding kunt u zien dat de Elastic-Net-modelfamilie het grootste aantal tests heeft voltooid, terwijl andere niet zoveel trainingstaken nodig hadden om het beste resultaat te vinden.
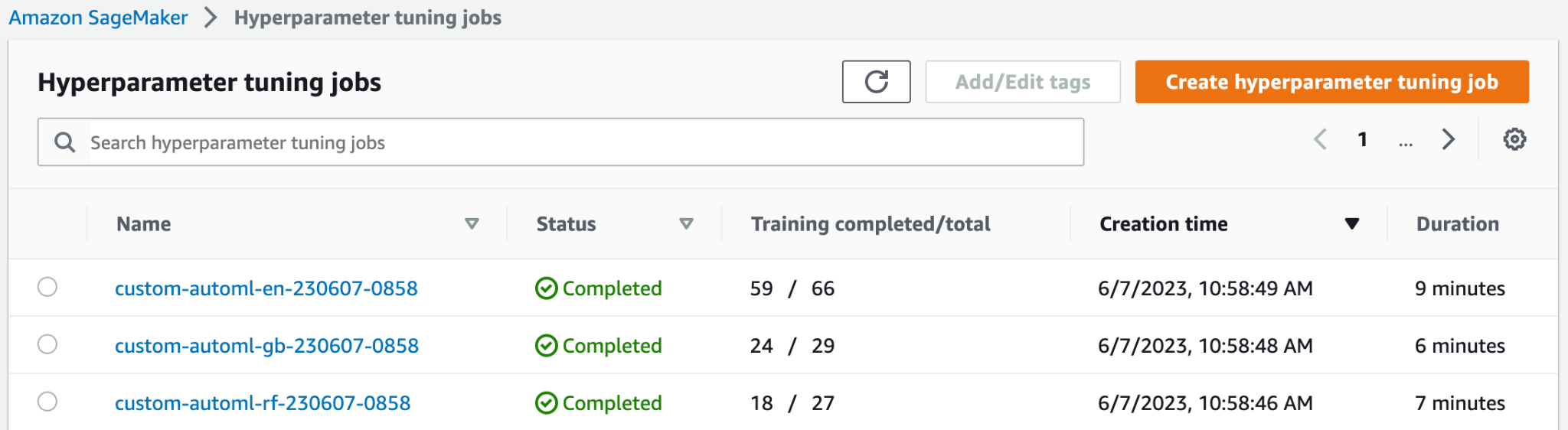
U kunt de HPO-taak openen voor toegang tot meer details, zoals individuele trainingstaken, taakconfiguratie en de informatie en prestaties van de beste trainingsfunctie.

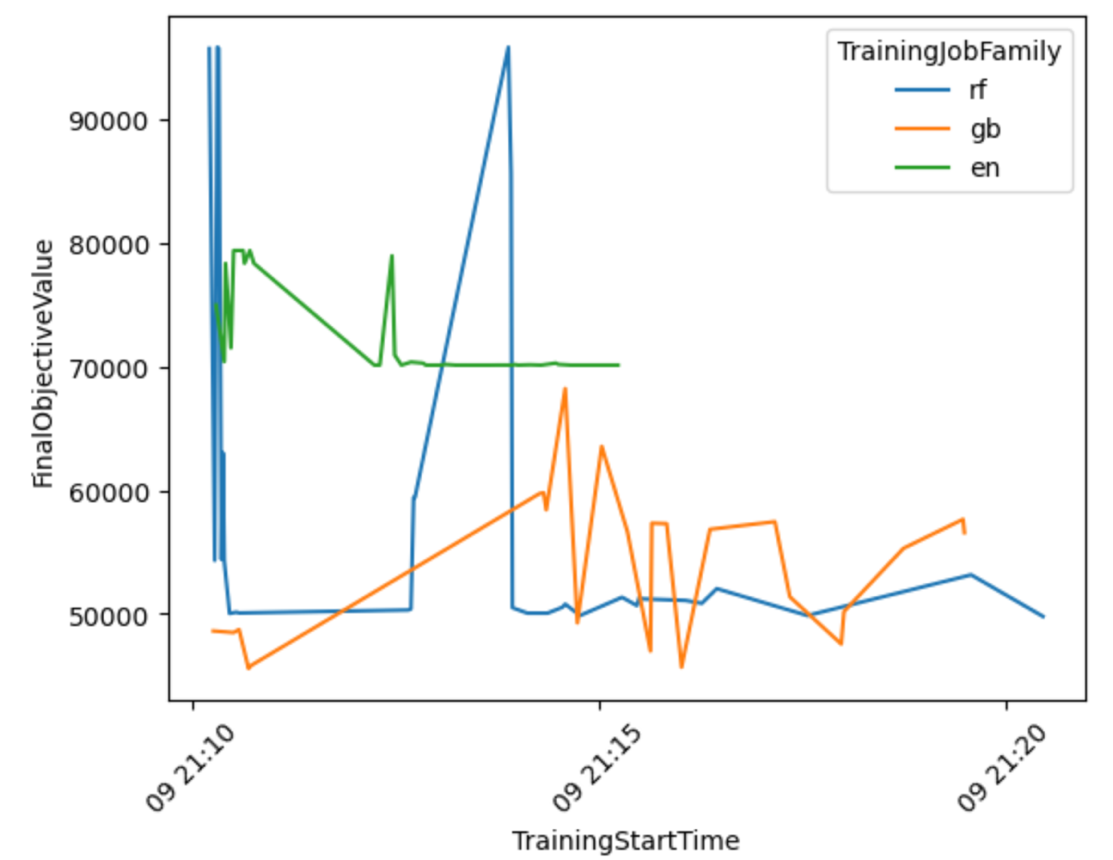
Laten we een visualisatie maken op basis van de resultaten om meer inzicht te krijgen in de prestaties van de AutoML-workflow voor alle modelfamilies.
Uit de volgende grafiek kun je concluderen dat de Elastic-Net De prestaties van het model schommelden tussen de 70,000 en 80,000 RMSE en liepen uiteindelijk vast, omdat het algoritme de prestaties niet kon verbeteren ondanks het uitproberen van verschillende voorverwerkingstechnieken en hyperparameterwaarden. Daar lijkt het ook op RandomForest De prestaties varieerden sterk, afhankelijk van de hyperparameterset die door HPO werd onderzocht, maar ondanks vele pogingen konden ze niet onder de 50,000 RMSE-fout komen. GradientBoosting behaalde al vanaf het begin de beste prestaties en ging onder de 50,000 RMSE. HPO probeerde dat resultaat verder te verbeteren, maar slaagde er niet in om betere prestaties te behalen bij andere hyperparametercombinaties. Een algemene conclusie voor alle HPO-taken is dat er niet zo veel taken nodig waren om de best presterende set hyperparameters voor elk algoritme te vinden. Om het resultaat verder te verbeteren, zou u moeten experimenteren met het creëren van meer functies en het uitvoeren van aanvullende functie-engineering.
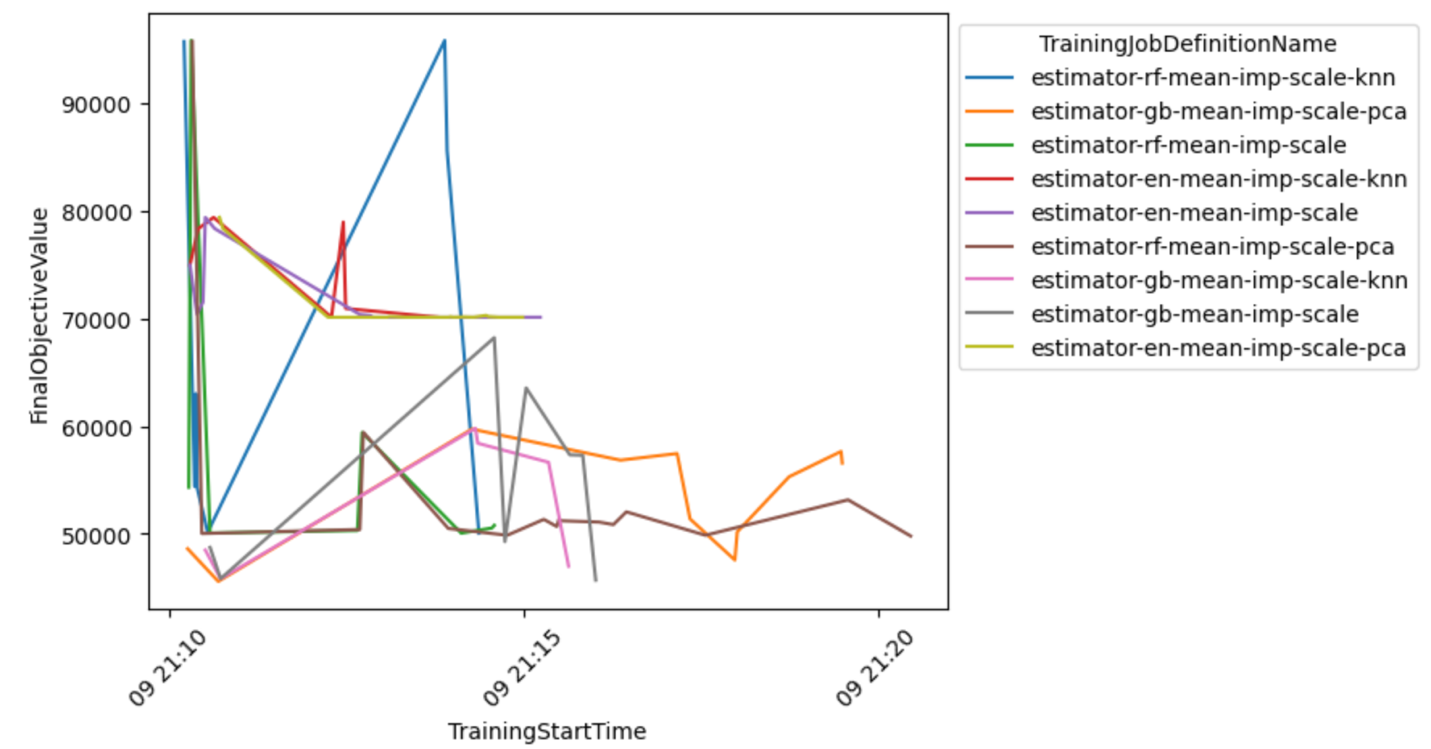
U kunt ook een gedetailleerder beeld van de model-preprocessorcombinatie bekijken om conclusies te trekken over de meest veelbelovende combinaties.
Selecteer het beste model en implementeer het
Het volgende codefragment selecteert het beste model op basis van de laagst behaalde objectieve waarde. U kunt het model vervolgens implementeren als een SageMaker-eindpunt.
Opruimen
Om ongewenste afschrijvingen op uw AWS-account te voorkomen, raden we u aan de AWS-bronnen te verwijderen die u in dit bericht hebt gebruikt:
- Leeg op de Amazon S3-console de gegevens uit de S3-bucket waarin de trainingsgegevens zijn opgeslagen.

- Stop op de SageMaker-console de notebookinstantie.

- Verwijder het modeleindpunt als u dit hebt geïmplementeerd. Eindpunten moeten worden verwijderd wanneer ze niet meer worden gebruikt, omdat ze worden gefactureerd op basis van de implementatietijd.
Conclusie
In dit bericht hebben we laten zien hoe u een aangepaste HPO-taak kunt maken in SageMaker met behulp van een aangepaste selectie van algoritmen en voorverwerkingstechnieken. Dit voorbeeld demonstreert met name hoe u het proces van het genereren van veel trainingsscripts kunt automatiseren en hoe u Python-programmeerstructuren kunt gebruiken voor een efficiënte implementatie van meerdere parallelle optimalisatietaken. We hopen dat deze oplossing de basis zal vormen voor alle aangepaste modelafstemmingstaken die u met SageMaker gaat implementeren om hogere prestaties te bereiken en uw ML-workflows te versnellen.
Bekijk de volgende bronnen om uw kennis over het gebruik van SageMaker HPO verder te verdiepen:
Over de auteurs
 Konrad Semsch is een Senior ML Solutions Architect bij het Amazon Web Services Data Lab Team. Hij helpt klanten machine learning te gebruiken om hun zakelijke uitdagingen met AWS op te lossen. Hij houdt ervan om te bedenken en te vereenvoudigen om klanten eenvoudige en pragmatische oplossingen te bieden voor hun AI/ML-projecten. Hij is het meest gepassioneerd door MlOps en traditionele datawetenschap. Buiten zijn werk is hij een groot fan van windsurfen en kitesurfen.
Konrad Semsch is een Senior ML Solutions Architect bij het Amazon Web Services Data Lab Team. Hij helpt klanten machine learning te gebruiken om hun zakelijke uitdagingen met AWS op te lossen. Hij houdt ervan om te bedenken en te vereenvoudigen om klanten eenvoudige en pragmatische oplossingen te bieden voor hun AI/ML-projecten. Hij is het meest gepassioneerd door MlOps en traditionele datawetenschap. Buiten zijn werk is hij een groot fan van windsurfen en kitesurfen.
 Tonijn Ersoy is een Senior Solutions Architect bij AWS. Haar primaire focus is het helpen van klanten uit de publieke sector bij het adopteren van cloudtechnologieën voor hun workloads. Ze heeft een achtergrond in applicatieontwikkeling, enterprise-architectuur en contactcentertechnologieën. Haar interesses omvatten serverloze architecturen en AI/ML.
Tonijn Ersoy is een Senior Solutions Architect bij AWS. Haar primaire focus is het helpen van klanten uit de publieke sector bij het adopteren van cloudtechnologieën voor hun workloads. Ze heeft een achtergrond in applicatieontwikkeling, enterprise-architectuur en contactcentertechnologieën. Haar interesses omvatten serverloze architecturen en AI/ML.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/implement-a-custom-automl-job-using-pre-selected-algorithms-in-amazon-sagemaker-automatic-model-tuning/

