Introductie
Datawetenschap is een snelgroeiend veld dat de manier verandert waarop organisaties hun data begrijpen en beslissingen nemen op basis van hun data. Als gevolg hiervan zoeken bedrijven steeds vaker naar datawetenschappers om hen te helpen hun data te begrijpen en bedrijfsresultaten te stimuleren. Dit heeft geleid tot een grote vraag naar datawetenschappers en de concurrentie voor deze functies kan hevig zijn. Om u te helpen bij de voorbereiding op een data science-interview, hebben we een lijst samengesteld met de 100 belangrijkste data science-interviewvragen die u waarschijnlijk zult tegenkomen.
De vragen die we hebben opgenomen bestrijken een breed scala aan onderwerpen, waaronder:
- Python-interviewvragen
- Verkennende data-analyse interviewvragen
- Sollicitatievragen over waarschijnlijkheid en statistiek
- Interviewvragen voor machine learning
Elke interviewvraag bevat een korte uitleg van de belangrijkste concepten en vaardigheden die worden getest, evenals tips voor het benaderen en beantwoorden van de vraag. Door uzelf vertrouwd te maken met deze vragen en uw antwoorden te oefenen, bent u goed voorbereid op uw volgende interview met deze data science-interviewvragen.
Interviewvragen over Python
Interviewvragen voor beginners
Q1. Wat is sneller, pythonlijst of Numpy-arrays, en waarom?
Ans. NumPy-arrays zijn sneller dan Python-lijsten voor numerieke bewerkingen. NumPy is een bibliotheek voor het werken met arrays in Python en biedt een aantal functies voor het efficiënt uitvoeren van bewerkingen op arrays.
Een reden waarom NumPy-arrays sneller zijn dan Python-lijsten, is dat NumPy-arrays in C zijn geïmplementeerd, terwijl Python-lijsten in Python zijn geïmplementeerd. Dit betekent dat bewerkingen op NumPy-arrays worden geïmplementeerd in een gecompileerde taal, waardoor ze sneller zijn dan bewerkingen op Python-lijsten, die worden geïmplementeerd in een geïnterpreteerde taal.
Q2. Wat is het verschil tussen een pythonlijst en een tuple?
Ans. In Python is een lijst een geordende verzameling objecten die van verschillende typen kunnen zijn. Lijsten zijn veranderlijk, wat betekent dat u de waarde van een lijstelement kunt wijzigen of elementen aan een lijst kunt toevoegen of verwijderen. Lijsten worden gemaakt met behulp van vierkante haken en een door komma's gescheiden lijst met waarden.
Een tuple is ook een geordende verzameling objecten, maar is onveranderlijk, wat betekent dat je de waarde van een tuple-element niet kunt wijzigen of elementen aan een tuple kunt toevoegen of verwijderen.
Lijsten worden gedefinieerd met vierkante haken ([ '' ]), terwijl tuples worden gedefinieerd met haakjes (('', )).
Lijsten hebben verschillende ingebouwde methoden voor het toevoegen, verwijderen en manipuleren van elementen, terwijl tuples deze methoden niet hebben.
Over het algemeen zijn tuples sneller dan lijsten in Python
Q3. Wat zijn pythonsets? Leg enkele eigenschappen van verzamelingen uit.
Ans. In Python is een set een ongeordende verzameling unieke objecten. Sets worden vaak gebruikt om een verzameling afzonderlijke objecten op te slaan en om lidmaatschapstests uit te voeren (dwz om te controleren of een object zich in de set bevindt). Sets worden gedefinieerd met behulp van accolades ({ en }) en een door komma's gescheiden lijst met waarden.
Hier zijn enkele belangrijke eigenschappen van sets in Python:
- Sets zijn ongeordend: sets hebben geen specifieke volgorde, dus u kunt ze niet indexeren of segmenteren zoals u kunt met lijsten of tuples.
- Sets zijn uniek: sets staan alleen unieke objecten toe, dus als u een gedupliceerd object aan een set probeert toe te voegen, wordt het niet toegevoegd.
- Sets zijn veranderlijk: u kunt elementen toevoegen aan of verwijderen uit een set met behulp van de methoden voor toevoegen en verwijderen.
- Sets worden niet geïndexeerd: sets ondersteunen geen indexering of segmentering, dus u kunt geen toegang krijgen tot individuele elementen van een set met behulp van een index.
- Sets kunnen niet worden gehasht: sets kunnen worden gewijzigd, dus ze kunnen niet worden gebruikt als sleutels in woordenboeken of als elementen in andere sets. Als u een veranderlijk object als sleutel of element in een set moet gebruiken, kunt u een tuple of een bevroren set (een onveranderlijke versie van een set) gebruiken.
Q4. Wat is het verschil tussen splitsen en joinen?
Ans. Splitsen en samenvoegen zijn beide functies van python-strings, maar ze zijn totaal verschillend als het gaat om functioneren.
De functie split wordt gebruikt om een lijst te maken van strings op basis van een scheidingsteken, bijvoorbeeld. ruimte.
Bijv. a = 'Dit is een tekenreeks'
Li = a.split(' ')
afdrukken(li)
Uitvoer - ['Dit', 'is', 'een', 'string']
De methode join() is een ingebouwde functie van de klasse str van Python die een lijst met tekenreeksen samenvoegt tot een enkele tekenreeks. Het wordt aangeroepen op een scheidingstekenreeks en aangeroepen met een lijst met tekenreeksen die moeten worden samengevoegd. De scheidingstekenreeks wordt ingevoegd tussen elke reeks in de lijst wanneer de reeksen worden samengevoegd.
Hier is een voorbeeld van het gebruik van de join() methode:
Bijv. “ “.join(li)
Uitvoer – Dit is een tekenreeks
Hier wordt de lijst samengevoegd met een spatie ertussen.
Q5. Leg de logische bewerkingen in python uit.
Ans. In Python kunnen de logische bewerkingen and, or, en not worden gebruikt om booleaanse bewerkingen uit te voeren op waarheidswaarden (True en False).
De operator and retourneert True als beide operanden True zijn en anders False.
De operator or retourneert True als een van de operanden True is, en False als beide operanden False zijn.
De operator not inverteert de booleaanse waarde van zijn operand. Als de operand True is, retourneer dan niet False, en als de operand False is, retourneer dan niet True.
Q6. Leg de top 5 functies uit die worden gebruikt voor python-strings.
Ans. Hier zijn de top 5 Python-tekenreeksfuncties:
- len(): Deze functie retourneert de lengte van een string.
s = 'Hallo wereld!'
lens)
13
- strip(): Deze functie verwijdert witruimte aan het begin en einde van een tekenreeks.
s = 'Hallo Wereld! '
s.strip()
'Hallo Wereld!'
- split(): Deze functie splitst een tekenreeks op in een lijst met subtekenreeksen op basis van een scheidingsteken.
s = 'Hallo wereld!'
s.split(',')
['Hallo Wereld!']
- replace(): Deze functie vervangt alle exemplaren van een opgegeven tekenreeks door een andere tekenreeks.
s = 'Hallo wereld!'
s.replace('Wereld', 'Universum')
'Hallo Universum!'
- upper() en lower(): Deze functies zetten een tekenreeks respectievelijk om in hoofdletters of kleine letters.
s = 'Hallo wereld!'
avondeten()
'HALLO WERELD!'
s.lager()
'Hallo Wereld!'
Q7. Wat is het gebruik van het pass-trefwoord in python?
Ans. pass is een null statement dat niets doet. Het wordt vaak gebruikt als tijdelijke aanduiding wanneer een verklaring syntactisch vereist is, maar er geen actie hoeft te worden ondernomen. Als u bijvoorbeeld een functie of een klasse wilt definiëren, maar nog niet hebt besloten wat deze moet doen, kunt u pass als tijdelijke aanduiding gebruiken.
Q8. Wat is het gebruik van het trefwoord continue in python?
Ans. doorgaan wordt gebruikt in een lus om de huidige iteratie over te slaan en door te gaan naar de volgende. Wanneer continue wordt aangetroffen, wordt de huidige iteratie van de lus beëindigd en begint de volgende.
Tussentijdse interviewvragen
Q9. Wat zijn onveranderlijke en veranderlijke gegevenstypen?
Ans. In Python is een onveranderlijk object een object waarvan de status niet kan worden gewijzigd nadat het is gemaakt. Dit betekent dat u de waarde van een onveranderlijk object niet meer kunt wijzigen nadat het is gemaakt. Voorbeelden van onveranderlijke objecten in Python zijn getallen (zoals gehele getallen, drijvers en complexe getallen), strings en tupels.
Aan de andere kant is een veranderlijk object een object waarvan de status kan worden gewijzigd nadat het is gemaakt. Dit betekent dat u de waarde van een veranderlijk object kunt wijzigen nadat het is gemaakt. Voorbeelden van veranderlijke objecten in Python zijn lijsten en woordenboeken.
Het is belangrijk om het verschil tussen onveranderlijke en veranderlijke objecten in Python te begrijpen, omdat dit van invloed kan zijn op hoe u gegevens in uw code gebruikt en manipuleert. Als u bijvoorbeeld een lijst met getallen heeft en u wilt de lijst in oplopende volgorde sorteren, kunt u hiervoor de ingebouwde methode sort() gebruiken. Als u echter een tuple van getallen heeft, kunt u de methode sort() niet gebruiken, omdat tuples onveranderlijk zijn. In plaats daarvan zou je een nieuwe gesorteerde tuple moeten maken van de originele tuple.
Q10. Wat is het nut van probeer en accepteer blok in python
Ans. Het try-and-except-blok in Python wordt gebruikt om uitzonderingen af te handelen. Een uitzondering is een fout die optreedt tijdens de uitvoering van een programma.
Het try-blok bevat code die ervoor kan zorgen dat er een uitzondering wordt gegenereerd. Het exception-blok bevat code die wordt uitgevoerd als er een uitzondering wordt gegenereerd tijdens de uitvoering van het try-blok.
Het gebruik van een try-except-blok zal de code redden van een optredende fout en kan worden uitgevoerd met een bericht of uitvoer die we in het exception-blok willen hebben.
Q11. Wat zijn 2 veranderlijke en 2 onveranderlijke gegevenstypen in python?
Ans. 2 veranderlijke gegevenstypen zijn -
- Woordenboek
- Lijst
U kunt de waarden in een python-woordenboek en een lijst wijzigen/bewerken. Het is niet nodig om een nieuwe lijst te maken, wat betekent dat deze voldoet aan de eigenschap van veranderlijkheid.
2 onveranderlijke gegevenstypen zijn:
- tuples
- Draad
U kunt een tekenreeks of waarde in een tuple niet meer bewerken nadat deze is gemaakt. U moet de waarden toewijzen aan de tuple of een nieuwe tuple maken.
Q12. Wat zijn python-functies en hoe helpen ze bij code-optimalisatie?
Ans. In Python is een functie een codeblok dat door andere delen van uw programma kan worden aangeroepen. Functies zijn handig omdat ze u in staat stellen code opnieuw te gebruiken en uw code op te delen in logische blokken die afzonderlijk kunnen worden getest en onderhouden.
Om een functie in Python aan te roepen, gebruikt u eenvoudig de functienaam gevolgd door een paar haakjes en eventuele noodzakelijke argumenten. De functie kan al dan niet een waarde retourneren die afhangt van het gebruik van de instructie turn.
Functies kunnen ook helpen bij code-optimalisatie:
- Hergebruik van code: met functies kunt u code hergebruiken door deze op één plek in te kapselen en meerdere keren aan te roepen vanuit verschillende delen van uw programma. Dit kan helpen redundantie te verminderen en uw code beknopter en gemakkelijker te onderhouden te maken.
- Verbeterde leesbaarheid: door uw code in logische blokken te verdelen, kunnen functies uw code leesbaarder en begrijpelijker maken. Dit kan het gemakkelijker maken om bugs te identificeren en wijzigingen in uw code aan te brengen.
- Eenvoudiger testen: met functies kunt u afzonderlijke codeblokken afzonderlijk testen, waardoor het gemakkelijker wordt om bugs te vinden en op te lossen.
- Verbeterde prestaties: Functies kunnen ook helpen om de prestaties van uw code te verbeteren door u in staat te stellen geoptimaliseerde codebibliotheken te gebruiken of door de Python-interpreter toe te staan de code effectiever te optimaliseren.
Q13. Waarom is NumPy enorm populair op het gebied van datawetenschap?
Ans. NumPy (afkorting van Numerical Python) is een populaire bibliotheek voor wetenschappelijk computergebruik in Python. Het is enorm populair geworden in de data science-gemeenschap omdat het snelle en efficiënte tools biedt voor het werken met grote arrays en matrices van numerieke gegevens.
NumPy biedt snelle en efficiënte bewerkingen op arrays en matrices van numerieke gegevens. Het gebruikt achter de schermen geoptimaliseerde C- en Fortran-code om deze bewerkingen uit te voeren, waardoor ze veel sneller zijn dan vergelijkbare bewerkingen met de ingebouwde datastructuren van Python. Het biedt snelle en efficiënte hulpmiddelen voor het werken met grote arrays en matrices van numerieke gegevens.
NumPy biedt een groot aantal functies voor het uitvoeren van wiskundige en statistische bewerkingen op arrays en matrices.
Hiermee kunt u efficiënt met grote hoeveelheden gegevens werken. Het biedt tools voor het verwerken van grote datasets die niet in het geheugen passen, zoals functies voor het lezen en schrijven van data naar schijf en voor het laden van slechts een deel van een dataset tegelijk in het geheugen.
NumPy kan goed worden geïntegreerd met andere wetenschappelijke computerbibliotheken in Python, zoals SciPy (Scientific Python) en panda's. Dit maakt het gemakkelijk om NumPy met andere bibliotheken te gebruiken om complexere datawetenschapstaken uit te voeren.
Q14. Uitleg over lijstbegrip en dictaatbegrip.
Ans. Lijstbegrip en dictaatbegrip zijn beide beknopte manieren om nieuwe lijsten of woordenboeken te maken van bestaande iterables.
Lijstbegrip is een beknopte manier om een lijst te maken. Het bestaat uit vierkante haken die een uitdrukking bevatten, gevolgd door een for-clausule en vervolgens nul of meer for- of if-clausules. Het resultaat is een nieuwe lijst die de expressie evalueert in de context van de for- en if-clausules.
Dict comprehension is een beknopte manier om een woordenboek te maken. Het bestaat uit accolades die een sleutel-waardepaar bevatten, gevolgd door een for-clausule en vervolgens nul of meer for- of if-clausules. Een resultaat is een nieuw woordenboek dat het sleutel-waardepaar evalueert in de context van de for- en if-clausules.
Q15. Wat zijn globale en lokale variabelen in python?
Ans. In Python is een variabele die buiten een functie of klasse is gedefinieerd een globale variabele, terwijl een variabele die binnen een functie of klasse is gedefinieerd een lokale variabele is.
Een globale variabele is overal in het programma toegankelijk, inclusief interne functies en klassen. Een lokale variabele is echter alleen toegankelijk binnen de functie of klasse waarin deze is gedefinieerd.
Het is belangrijk op te merken dat u dezelfde naam kunt gebruiken voor een globale variabele en een lokale variabele, maar dat de lokale variabele voorrang heeft op de globale variabele binnen de functie of klasse waarin deze is gedefinieerd.
# Dit is een globale variabele
x = 10
def functie():
# Dit is een lokale variabele
x = 5
print(x)mijn_functie
functie()
afdrukken(x)
Uitvoer – Hiermee wordt 5 en vervolgens 10 afgedrukt
In het bovenstaande voorbeeld is de x-variabele binnen de functie func() een lokale variabele, dus heeft deze voorrang op de globale variabele x. Daarom, wanneer x binnen de functie wordt afgedrukt, wordt 5 afgedrukt; wanneer het buiten de functie wordt afgedrukt, wordt 10 afgedrukt.
Q16. Wat is een geordend woordenboek?
Ans. Een geordend woordenboek, ook wel OrderedDict genoemd, is een subklasse van de ingebouwde Python-woordenboekklasse die de volgorde van de elementen behoudt waarin ze zijn toegevoegd. In een regulier woordenboek wordt de volgorde van elementen bepaald door de hash-waarden van hun sleutels, die in de loop van de tijd kunnen veranderen naarmate het woordenboek groeit en evolueert. Een geordend woordenboek daarentegen gebruikt een dubbel gekoppelde lijst om de volgorde van elementen te onthouden, zodat de volgorde van elementen behouden blijft, ongeacht hoe het woordenboek verandert.
Q17. Wat is het verschil tussen zoekwoorden voor rendement en rendement?
Ans. Return wordt gebruikt om een functie af te sluiten en een waarde terug te sturen naar de beller. Wanneer een return-instructie wordt aangetroffen, wordt de functie onmiddellijk beëindigd en wordt de waarde van de expressie die volgt op de return-instructie teruggestuurd naar de aanroeper.
opbrengst daarentegen wordt gebruikt om een generatorfunctie te definiëren. Een generatorfunctie is een speciaal soort functie die een reeks waarden één voor één produceert, in plaats van één enkele waarde terug te geven. Wanneer een rendementsverklaring wordt aangetroffen, produceert de generatorfunctie een waarde en onderbreekt de uitvoering ervan, waarbij de status wordt bewaard voor later
Geavanceerde interviewvragen
Q18. Wat zijn lambda-functies in python en waarom zijn ze belangrijk?
Ans. In Python is een lambda-functie een kleine anonieme functie. U kunt lambda-functies gebruiken als u geen functie wilt definiëren met het sleutelwoord def.
Lambda-functies zijn handig wanneer u voor een korte periode een kleine functie nodig hebt. Ze worden vaak gebruikt in combinatie met functies van hogere orde, zoals map(), filter() en reduce().
Hier is een voorbeeld van een lambda-functie in Python:
x = lambda a : a + 10
x (5)
15
In dit voorbeeld neemt de lambda-functie één argument (a) en voegt er 10 aan toe. De lambda-functie retourneert het resultaat van deze bewerking wanneer deze wordt aangeroepen.
Lambda-functies zijn belangrijk omdat u hiermee op een beknopte manier kleine anonieme functies kunt maken. Ze worden vaak gebruikt bij functioneel programmeren, een programmeerparadigma dat de nadruk legt op het gebruik van functies om problemen op te lossen.
Q19. Wat is het nut van het trefwoord 'assert' in python?
Ans. In Python wordt de assert-instructie gebruikt om een voorwaarde te testen. Als de voorwaarde waar is, wordt het programma verder uitgevoerd. Als de voorwaarde False is, genereert het programma een AssertionError-uitzondering.
De assert statement wordt vaak gebruikt om de interne consistentie van een programma te controleren. U kunt bijvoorbeeld een assert-instructie gebruiken om te controleren of een lijst is gesorteerd voordat u een binaire zoekopdracht op de lijst uitvoert.
Het is belangrijk op te merken dat de assert-instructie wordt gebruikt voor foutopsporingsdoeleinden en niet bedoeld is om te worden gebruikt als een manier om runtime-fouten op te lossen. In productiecode moet u try-and-except-blokken gebruiken om uitzonderingen af te handelen die tijdens runtime kunnen optreden.
Q20. Wat zijn decorateurs in python?
Ans. In Python zijn decorateurs een manier om de functionaliteit van een functie, methode of klasse te wijzigen of uit te breiden zonder hun broncode te wijzigen. Decorators worden doorgaans geïmplementeerd als functies die een andere functie als argument aannemen en een nieuwe functie retourneren die het gewenste gedrag heeft.
Een decorateur is een speciale functie die begint met het @-symbool en direct voor de functie, methode of klasse wordt geplaatst die wordt gedecoreerd. Het @-symbool wordt gebruikt om aan te geven dat de volgende functie een decorateur is.
Interviewvragen met betrekking tot EDA en statistieken
Interviewvragen voor beginners
Q21. Hoe univariate analyse uitvoeren voor numerieke en categorische variabelen?
Ans. Univariate analyse is een statistische techniek die wordt gebruikt om de kenmerken van een enkele variabele te analyseren en te beschrijven. Het is een handig hulpmiddel om de distributie, centrale tendens en spreiding van een variabele te begrijpen, en om patronen en relaties binnen de gegevens te identificeren. Dit zijn de stappen voor het uitvoeren van univariate analyse voor numerieke en categorische variabelen:
Voor numerieke variabelen:
Bereken beschrijvende statistieken zoals het gemiddelde, de mediaan, de modus en de standaarddeviatie om de verdeling van de gegevens samen te vatten.
Visualiseer de verdeling van de gegevens met behulp van plots zoals histogrammen, boxplots of dichtheidsplots.
Controleer op uitschieters en afwijkingen in de gegevens.
Controleer op normaliteit in de gegevens met behulp van statistische tests of visualisaties zoals een QQ-plot.
Voor categorische variabelen.
Bereken de frequentie of het aantal van elke categorie in de gegevens.
Bereken het percentage of aandeel van elke categorie in de gegevens.
Visualiseer de verdeling van de gegevens met behulp van plots zoals staafdiagrammen of cirkeldiagrammen.
Controleer op onevenwichtigheden of afwijkingen in de distributie van de gegevens.
Merk op dat de specifieke stappen voor het uitvoeren van univariate analyse kunnen variëren, afhankelijk van de specifieke behoeften en doelen van de analyse. Het is belangrijk om de analyse zorgvuldig te plannen en uit te voeren om de gegevens nauwkeurig en effectief te beschrijven en te begrijpen.
Q22. Wat zijn de verschillende manieren waarop we uitschieters in de gegevens kunnen vinden?
Ans. Outliers zijn gegevenspunten die aanzienlijk verschillen van de meeste gegevens. Ze kunnen worden veroorzaakt door fouten, anomalieën of ongebruikelijke omstandigheden en ze kunnen een aanzienlijke impact hebben op statistische analyses en machine learning-modellen. Daarom is het belangrijk om uitschieters op de juiste manier te identificeren en aan te pakken om nauwkeurige en betrouwbare resultaten te verkrijgen.
Hier volgen enkele veelgebruikte manieren om uitschieters in de gegevens te vinden:
Visuele inspectie: Uitbijters kunnen vaak worden geïdentificeerd door de gegevens visueel te inspecteren met behulp van plots zoals histogrammen, scatterplots of boxplots.
Samenvattende statistieken: Uitbijters kunnen soms worden geïdentificeerd door samenvattende statistieken zoals het gemiddelde, de mediaan of het interkwartielbereik te berekenen en deze te vergelijken met de gegevens. Als het gemiddelde bijvoorbeeld significant afwijkt van de mediaan, kan dit wijzen op de aanwezigheid van uitschieters.
Z-score: De z-score van een gegevenspunt is een maat voor hoeveel standaarddeviaties het van het gemiddelde verwijderd is. Gegevenspunten met een z-score die groter is dan een bepaalde drempelwaarde (bijv. 3 of 4) kunnen als uitbijters worden beschouwd.
Er zijn veel andere methoden om uitbijters in de gegevens te detecteren, en de juiste methode hangt af van de specifieke kenmerken en behoeften van de gegevens. Het is belangrijk om de meest geschikte methode voor het identificeren van uitschieters zorgvuldig te evalueren en te kiezen om nauwkeurige en betrouwbare resultaten te verkrijgen.
Q23. Wat zijn de verschillende manieren waarop u de ontbrekende waarden in de dataset kunt imputeren?
Ans. Er zijn verschillende manieren waarop u null-waarden (dwz ontbrekende waarden) in een gegevensset kunt toeschrijven:
Rijen laten vallen: Een optie is om eenvoudig rijen met null-waarden uit de dataset te verwijderen. Dit is een eenvoudige en snelle methode, maar het kan problematisch zijn als een groot aantal rijen wordt weggelaten, omdat hierdoor de steekproefomvang aanzienlijk kan worden verkleind en de statistische kracht van de analyse kan worden beïnvloed.
Kolommen verwijderen: Een andere optie is om kolommen met null-waarden uit de dataset te verwijderen. Dit kan een goede optie zijn als het aantal null-waarden groot is in vergelijking met het aantal niet-null-waarden, of als de kolom niet relevant is voor de analyse.
Imputatie met gemiddelde of mediaan: Een gebruikelijke imputatiemethode is het vervangen van nulwaarden door het gemiddelde of de mediaan van de niet-nullwaarden in de kolom. Dit kan een goede optie zijn als de gegevens willekeurig ontbreken en het gemiddelde of de mediaan een redelijke weergave is van de gegevens.
Imputatie met modus: Een andere optie is om null-waarden te vervangen door de modus (dwz de meest voorkomende waarde) van de niet-null-waarden in de kolom. Dit kan een goede optie zijn voor categorische gegevens waarbij de modus een zinvolle weergave van de gegevens is.
Imputatie met een voorspellend model: Een andere manier van imputeren is het gebruik van een voorspellend model om de ontbrekende waarden te schatten op basis van de andere beschikbare gegevens. Dit kan een complexere en tijdrovendere methode zijn, maar het kan nauwkeuriger zijn als de gegevens niet willekeurig ontbreken en er een sterke relatie is tussen de ontbrekende waarden en de andere gegevens.
Q24. Wat zijn scheefheid in statistieken en zijn typen?
Ans. Scheefheid is een maat voor de symmetrie van een verdeling. Een verdeling is symmetrisch als deze de vorm heeft van een klokkromme, waarbij de meeste gegevenspunten geconcentreerd zijn rond het gemiddelde. Een verdeling is scheef als deze niet symmetrisch is, met meer gegevenspunten geconcentreerd aan de ene kant van het gemiddelde dan aan de andere kant.
Er zijn twee soorten scheefheid: positieve scheefheid en negatieve scheefheid.
Positieve scheefheid: Positieve scheefheid treedt op wanneer de verdeling een lange staart aan de rechterkant heeft, waarbij de meerderheid van de gegevenspunten geconcentreerd is aan de linkerkant van het gemiddelde. Positieve scheefheid geeft aan dat er een paar extreme waarden aan de rechterkant van de verdeling zijn die het gemiddelde naar rechts trekken.
Negatieve scheefheid: Negatieve scheefheid treedt op wanneer de verdeling een lange staart heeft aan de linkerkant, waarbij de meerderheid van de gegevenspunten geconcentreerd is aan de rechterkant van het gemiddelde. Negatieve scheefheid geeft aan dat er aan de linkerkant van de verdeling enkele extreme waarden zijn die het gemiddelde naar links trekken.
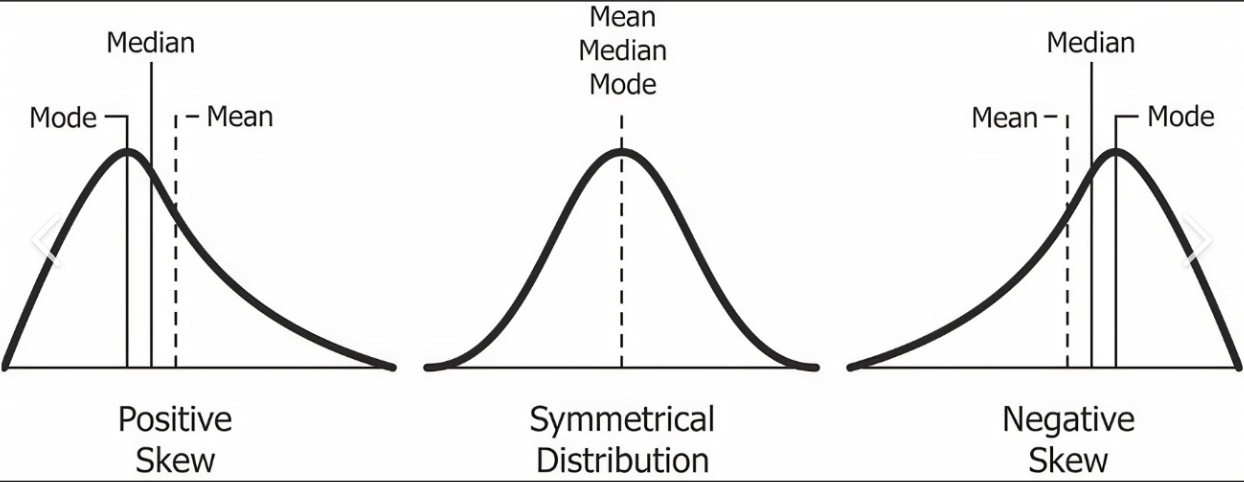
Q25. Wat zijn de maten van centrale tendens?
Ans. In de statistiek zijn maten van centrale tendens waarden die het centrum van een dataset vertegenwoordigen. Er zijn drie hoofdmaten van centrale tendens: gemiddelde, mediaan en modus.
Het gemiddelde is het rekenkundig gemiddelde van een dataset en wordt berekend door alle waarden in de dataset op te tellen en te delen door het aantal waarden. Het gemiddelde is gevoelig voor uitschieters, of waarden die significant hoger of lager zijn dan de meerderheid van de andere waarden in de dataset.
De mediaan is de middelste waarde van een dataset wanneer de waarden zijn gerangschikt van klein naar groot. Om de mediaan te vinden, moet u eerst de waarden op volgorde zetten en vervolgens de middelste waarde zoeken. Als er een oneven aantal waarden is, is de mediaan de middelste waarde. Als er een even aantal waarden is, is de mediaan het gemiddelde van de twee middelste waarden. De mediaan is niet gevoelig voor uitschieters.
De modus is de waarde die het meest voorkomt in een dataset. Een dataset kan meerdere modi hebben of helemaal geen modi. De modus is niet gevoelig voor uitschieters.
Vraag 26. Kunt u het verschil uitleggen tussen beschrijvende en verklarende statistiek?
Ans. Beschrijvende statistiek wordt gebruikt om een dataset samen te vatten en te beschrijven door metingen van centrale tendens (gemiddelde, mediaan, modus) en spreidingsmetingen (standaarddeviatie, variantie, bereik) te gebruiken. Inferentiële statistiek wordt gebruikt om conclusies te trekken over een populatie op basis van een steekproef van gegevens en met behulp van statistische modellen, hypothesetesten en schattingen.
V27.Wat zijn de belangrijkste elementen van een EDA-rapport en hoe dragen ze bij aan het begrijpen van een dataset?
Ans. De belangrijkste elementen van een EDA-rapport zijn univariate analyse, bivariate analyse, ontbrekende gegevensanalyse en basisgegevensvisualisatie. Univariate analyse helpt bij het begrijpen van de verdeling van individuele variabelen, bivariate analyse helpt bij het begrijpen van de relatie tussen variabelen, analyse van ontbrekende gegevens helpt bij het begrijpen van de kwaliteit van gegevens en gegevensvisualisatie biedt een visuele interpretatie van de gegevens.
Tussentijdse interviewvragen
Q28 Wat is de centrale limietstelling?
Ans. De centrale limietstelling is een fundamenteel concept in de statistiek dat stelt dat naarmate de steekproefomvang toeneemt, de verdeling van het steekproefgemiddelde een normale verdeling zal benaderen. Dit geldt ongeacht de onderliggende verdeling van de populatie waaruit de steekproef is getrokken. Dit betekent dat zelfs als de individuele gegevenspunten in een steekproef niet normaal verdeeld zijn, we door het gemiddelde te nemen van een voldoende groot aantal, op normale verdeling gebaseerde methoden kunnen gebruiken om conclusies te trekken over de populatie.
Q29. Noem de twee soorten doelvariabelen voor voorspellende modellering.
Ans. De twee soorten doelvariabelen zijn:
Numerieke/continue variabelen – Variabelen waarvan de waarden binnen een bereik liggen, kunnen elke waarde in dat bereik en het tijdstip van voorspelling zijn; waarden hoeven ook niet binnen hetzelfde bereik te liggen.
Bijvoorbeeld: lengte van studenten - 5; 5.1; 6; 6.7; 7; 4.5; 5.11
Hier is het bereik van de waarden (4,7)
En de lengte van sommige nieuwe studenten kan wel/niet een waarde uit dit bereik hebben.
Categorische variabele - Variabelen die een van een beperkt en meestal vast aantal mogelijke waarden kunnen aannemen, waarbij elk individu of elke andere waarnemingseenheid wordt toegewezen aan een bepaalde groep op basis van een of andere kwalitatieve eigenschap.
Een categorische variabele die precies twee waarden kan aannemen, wordt een binaire variabele of een dichotome variabele genoemd. Categorische variabelen met meer dan twee mogelijke waarden worden polytome variabelen genoemd
Bijvoorbeeld Examenresultaat: Geslaagd, Gezakt (Binaire categorische variabele)
De bloedgroep van een persoon: A, B, O, AB (polytome categorische variabele)
Q30. In welk geval zullen het gemiddelde, de mediaan en de modus hetzelfde zijn voor de dataset?
Ans. Het gemiddelde, de mediaan en de modus van een dataset zijn allemaal hetzelfde als en slechts als de dataset uit één enkele waarde bestaat die met 100% frequentie voorkomt.
Beschouw bijvoorbeeld de volgende dataset: 3, 3, 3, 3, 3, 3. Het gemiddelde van deze dataset is 3, de mediaan is 3 en de modus is 3. Dit komt omdat de dataset uit een enkele waarde bestaat ( 3) dat gebeurt met 100% frequentie.
Aan de andere kant, als de dataset meerdere waarden bevat, zullen het gemiddelde, de mediaan en de modus over het algemeen anders zijn. Neem bijvoorbeeld de volgende dataset: 1, 2, 3, 4, 5. Het gemiddelde van deze dataset is 3, de mediaan is 3 en de modus is 1. Dit komt doordat de dataset meerdere waarden bevat en er geen waarde voorkomt met 100% frequentie.
Het is belangrijk op te merken dat het gemiddelde, de mediaan en de modus kunnen worden beïnvloed door uitschieters of extreme waarden in de dataset. Als de dataset extreme waarden bevat, kunnen het gemiddelde en de mediaan aanzienlijk verschillen van de modus, zelfs als de dataset uit één enkele waarde bestaat die met een hoge frequentie voorkomt.
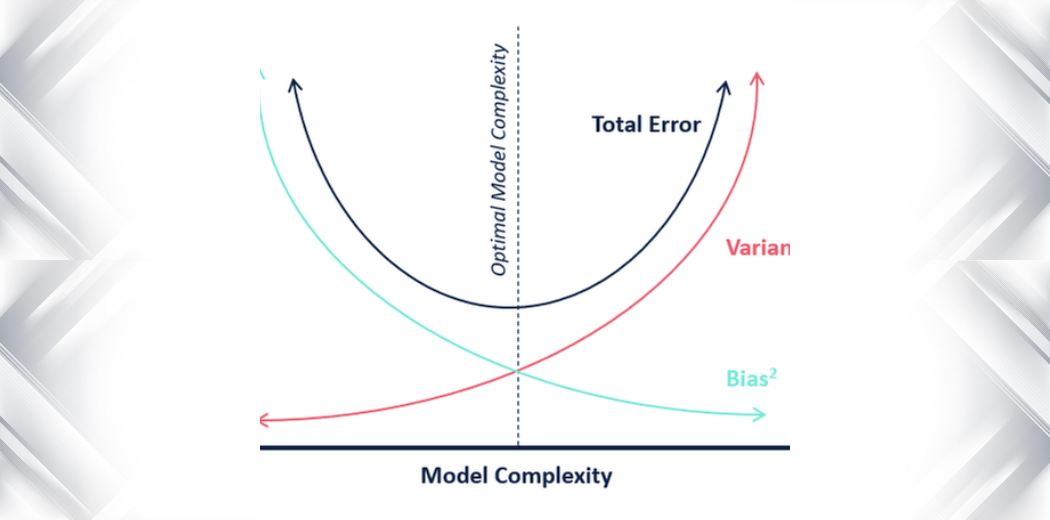
Q31. Wat is het verschil tussen variantie en bias in statistieken?
Ans. In de statistiek zijn variantie en vertekening twee maatstaven voor de kwaliteit of nauwkeurigheid van een model of schatter.
Variantie: Variantie meet de hoeveelheid spreiding of spreiding in een dataset. Het wordt berekend als de gemiddelde kwadratische afwijking van het gemiddelde. Een hoge variantie geeft aan dat de gegevens verspreid zijn en mogelijk meer foutgevoelig zijn, terwijl een lage variantie aangeeft dat de gegevens geconcentreerd zijn rond het gemiddelde en mogelijk nauwkeuriger zijn.
Bias: Bias verwijst naar het verschil tussen de verwachte waarde van een schatter en de werkelijke waarde van de parameter die wordt geschat. Een hoge bias geeft aan dat de schatter consequent de werkelijke waarde onder- of overschat, terwijl een lage bias aangeeft dat de schatter nauwkeuriger is.
Het is belangrijk om zowel variantie als bias in overweging te nemen bij het evalueren van de kwaliteit van een model of schatter. Een model met een lage bias en hoge variantie kan gevoelig zijn voor overfitting, terwijl een model met een hoge bias en lage variantie vatbaar kan zijn voor underfitting. Het vinden van de juiste balans tussen bias en variantie is een belangrijk aspect van modelselectie en -optimalisatie.
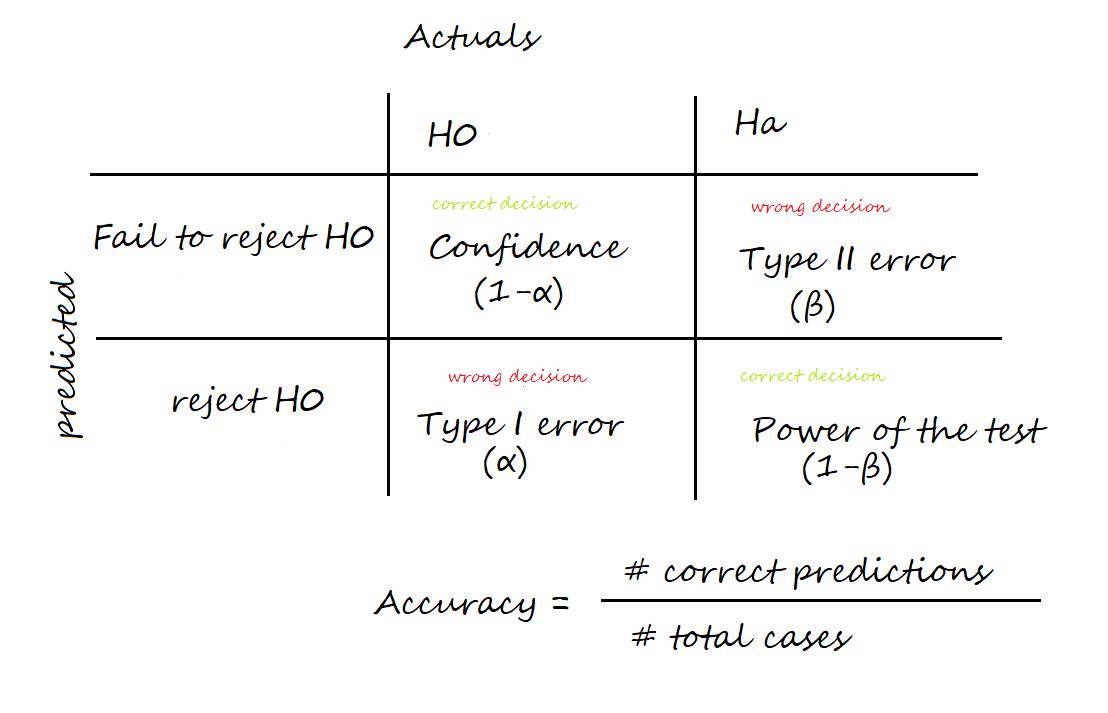
Q32. Wat is het verschil tussen type I- en type II-fouten?
Ans. Twee soorten fouten kunnen komen voor bij het testen van hypothesen: Type I-fouten en Type II-fouten.
Een type I-fout, ook wel een 'vals-positief' genoemd, treedt op wanneer de nulhypothese waar is maar wordt verworpen. Dit type fout wordt aangeduid met de Griekse letter alfa (α) en is meestal ingesteld op een niveau van 0.05. Dit betekent dat er 5% kans is op het maken van een Type I-fout of een fout-positief.
Een type II-fout, ook wel 'vals-negatief' genoemd, treedt op wanneer de nulhypothese onjuist is maar niet wordt verworpen. Dit type fout wordt aangeduid met de Griekse letter beta (β) en wordt vaak weergegeven als 1 – β, waarbij β de kracht van de test is. De kracht van de test is de waarschijnlijkheid dat de nulhypothese correct wordt verworpen als deze onjuist is.
Het is belangrijk om te proberen de kans op beide soorten fouten bij het testen van hypothesen te minimaliseren.
Q33. Wat is het betrouwbaarheidsinterval in statistieken?
Ans. Het betrouwbaarheidsinterval is het bereik waarbinnen we verwachten dat de resultaten zullen liggen als we het experiment herhalen. Het is het gemiddelde van het resultaat plus en minus de verwachte variatie.
Dit laatste wordt bepaald door de standaardfout van de schatting, terwijl het midden van het interval samenvalt met het gemiddelde van de schatting. Het meest voorkomende betrouwbaarheidsinterval is 95%.
V34.Kunt u het concept van correlatie en covariantie uitleggen?
Ans. Correlatie is een statistische maatstaf die de sterkte en richting beschrijft van een lineaire relatie tussen twee variabelen. Een positieve correlatie geeft aan dat de twee variabelen samen toenemen of afnemen, terwijl een negatieve correlatie aangeeft dat de twee variabelen in tegengestelde richtingen bewegen. Covariantie is een maat voor de gezamenlijke variabiliteit van twee willekeurige variabelen. Het wordt gebruikt om te meten hoe twee variabelen gerelateerd zijn.
Geavanceerde interviewvragen
Q35. Waarom is het testen van hypothesen nuttig voor een datawetenschapper?
Ans. Het testen van hypothesen is een statistische techniek die in de datawetenschap wordt gebruikt om de geldigheid van een bewering of hypothese over een populatie te evalueren. Het wordt gebruikt om te bepalen of er voldoende bewijs is om een bewering of hypothese te ondersteunen en om de statistische significantie van de resultaten te beoordelen.
Er zijn veel situaties in de datawetenschap waarin het testen van hypothesen nuttig is. Het kan bijvoorbeeld worden gebruikt om de effectiviteit van een nieuwe marketingcampagne te testen, om te bepalen of er een significant verschil is tussen de gemiddelden van twee groepen, om de relatie tussen twee variabelen te evalueren of om de nauwkeurigheid van een voorspellend model te beoordelen.
Het testen van hypothesen is een belangrijk hulpmiddel in de datawetenschap, omdat het datawetenschappers in staat stelt weloverwogen beslissingen te nemen op basis van gegevens, in plaats van te vertrouwen op aannames of subjectieve meningen. Het helpt datawetenschappers om conclusies te trekken over de gegevens die worden ondersteund door statistisch bewijs, en om hun bevindingen op een duidelijke en betrouwbare manier te communiceren. Het testen van hypothesen is daarom een belangrijk onderdeel van de wetenschappelijke methode en een fundamenteel aspect van data science-praktijken.
Q36. Waarvoor wordt een chikwadraattoets van onafhankelijkheid gebruikt in de statistiek?
Ans. Een chikwadraattoets van onafhankelijkheid is een statistische toets die wordt gebruikt om te bepalen of er een significant verband bestaat tussen twee categorische variabelen. Het wordt gebruikt om de nulhypothese te testen dat de twee variabelen onafhankelijk zijn, wat betekent dat de waarde van de ene variabele niet afhankelijk is van de waarde van de andere variabele.
De chikwadraattest van onafhankelijkheid omvat het berekenen van een chikwadraatstatistiek en deze vergelijken met een kritische waarde om de waarschijnlijkheid te bepalen dat de waargenomen relatie door toeval ontstaat. Als de waarschijnlijkheid onder een bepaalde drempel ligt (bijv. 0.05), wordt de nulhypothese verworpen en wordt geconcludeerd dat er een significant verband bestaat tussen de twee variabelen.
De chikwadraattoets van onafhankelijkheid wordt veel gebruikt in de datawetenschap om de relatie tussen twee categorische variabelen te evalueren, zoals de relatie tussen geslacht en koopgedrag, of de relatie tussen opleidingsniveau en stemvoorkeur. Het is een belangrijk hulpmiddel om de relatie tussen verschillende variabelen te begrijpen en om weloverwogen beslissingen te nemen op basis van de gegevens.
Q37. Wat is de betekenis van de p-waarde?
Ans. De p-waarde wordt gebruikt om de statistische significantie van een resultaat te bepalen. Bij het testen van hypothesen wordt de p-waarde gebruikt om de waarschijnlijkheid te beoordelen van het verkrijgen van een resultaat dat minstens zo extreem is als het waargenomen resultaat, aangezien de nulhypothese waar is. Als de p-waarde lager is dan het vooraf bepaalde significantieniveau (meestal aangeduid als alfa, α), wordt het resultaat als statistisch significant beschouwd en wordt de nulhypothese verworpen.
Het belang van de p-waarde is dat het onderzoekers in staat stelt beslissingen te nemen over de gegevens op basis van een vooraf bepaald betrouwbaarheidsniveau. Door een significantieniveau in te stellen voordat de statistische test wordt uitgevoerd, kunnen onderzoekers bepalen of de resultaten waarschijnlijk door toeval zijn ontstaan of dat er een reëel effect in de gegevens aanwezig is.
V38.Wat zijn de verschillende soorten steekproeftechnieken die door data-analisten worden gebruikt?
Ans. Er zijn veel verschillende soorten steekproeftechnieken die data-analisten kunnen gebruiken, maar enkele van de meest voorkomende zijn:
Eenvoudige aselecte steekproeftrekking: Dit is een basisvorm van steekproeftrekking waarbij elk lid van de populatie een gelijke kans heeft om geselecteerd te worden voor de steekproef.
Gestratificeerde aselecte steekproeftrekking: Bij deze techniek wordt de bevolking op basis van bepaalde kenmerken in subgroepen (of strata) verdeeld en vervolgens uit elke laag een willekeurige steekproef getrokken.
Clusterbemonstering: Bij deze techniek wordt de bevolking in kleinere groepen (of clusters) verdeeld en vervolgens een willekeurige steekproef van clusters geselecteerd.
Systematische steekproeven: Bij deze techniek wordt elk k-de lid van de populatie geselecteerd om in de steekproef te worden opgenomen.
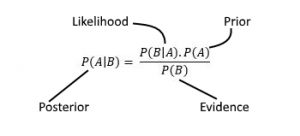
V39.Wat is de stelling van Bayes en hoe wordt deze gebruikt in de gegevenswetenschap?
Ans. De stelling van Bayes is een wiskundige formule die de waarschijnlijkheid beschrijft dat een gebeurtenis plaatsvindt, gebaseerd op voorkennis van omstandigheden die verband kunnen houden met de gebeurtenis. In de datawetenschap wordt de stelling van Bayes vaak gebruikt in Bayesiaanse statistiek en machine learning, voor taken als classificatie, voorspelling en schatting.
V40.Wat is het verschil tussen een parametrische en een niet-parametrische test?
Ans. Een parametrische test is een statistische test die ervan uitgaat dat de gegevens een specifieke kansverdeling volgen, zoals een normale verdeling. Een niet-parametrische test doet geen aannames over de onderliggende kansverdeling van de gegevens.
Sollicitatievragen met betrekking tot machine learning
Beginner interview vragen
Q41. Wat is het verschil tussen functieselectie en -extractie?
Ans. Feature selectie is de techniek waarbij we de features filteren die aan het model moeten worden ingevoerd. Dit is de taak waarin we de meest relevante kenmerken selecteren. De kenmerken die duidelijk geen belang hebben bij het bepalen van de voorspelling van het model worden verworpen.
Functieselectie daarentegen is het proces waarbij de functies uit de onbewerkte gegevens worden gehaald. Het omvat het transformeren van onbewerkte gegevens in een reeks functies die kunnen worden gebruikt om een ML-model te trainen.
Beide zijn erg belangrijk omdat ze helpen bij het filteren van de functies voor ons ML-model, wat helpt bij het bepalen van de nauwkeurigheid van het model.
Q42. Wat zijn de 5 aannames voor lineaire regressie?
Ans. Hier zijn de 5 aannames van lineaire regressie:
- Lineariteit: Er is een lineair verband tussen de onafhankelijke variabelen en de afhankelijke variabele.
- Onafhankelijkheid van fouten: De fouten (restanten) zijn onafhankelijk van elkaar.
- Homoscedasticiteit: de variantie van de fouten is constant voor alle voorspelde waarden.
- Normaliteit: de fouten volgen een normale verdeling.
- Onafhankelijkheid van voorspellers: De onafhankelijke variabelen zijn niet met elkaar gecorreleerd.
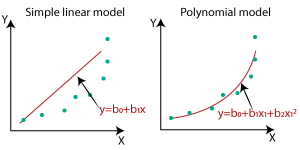
Q43. Wat is het verschil tussen lineaire en niet-lineaire regressie?
Ans. Lineaire regressie is de methode die wordt gebruikt om de relatie tussen een afhankelijke en een of meer onafhankelijke variabelen te vinden. Het model vindt de best passende lijn, wat een lineaire functie is (y = mx +c) die helpt om het model zo aan te passen dat de fout minimaal is, rekening houdend met alle gegevenspunten. De beslissingsgrens van een lineaire regressiefunctie is dus lineair.
Een niet-lineaire regressie wordt gebruikt om de relatie tussen een afhankelijke en een of meer onafhankelijke variabelen te modelleren door middel van een niet-lineaire vergelijking. De niet-lineaire regressiemodellen zijn flexibeler en kunnen de complexere relaties tussen variabelen vinden.
Q44. Hoe herken je underfitting in een model?
Ans. Underfitting treedt op wanneer een statistisch model of machine learning-algoritme niet in staat is om de onderliggende trend van de gegevens vast te leggen. Dit kan verschillende redenen hebben, maar een veelvoorkomende oorzaak is dat het model te simpel is en de complexiteit van de gegevens niet kan vastleggen.
Hier leest u hoe u underfitting in een model kunt identificeren:
De trainingsfout van een underfitting-fout zal hoog zijn, dwz het model zal niet kunnen leren van de trainingsgegevens en zal slecht presteren op de trainingsgegevens.
De validatiefout van een ondermaats model zal ook hoog zijn, omdat het ook slecht zal presteren op de nieuwe gegevens.
Q45. Hoe herken je overfitting in een model?
Ans. Overfitting in een model doet zich voor wanneer het model de volledige trainingsgegevens leert in plaats van signalen/hints uit de gegevens te halen en het model buitengewoon goed presteert op trainingsgegevens en slecht presteert op de testgegevens.
De testfout van het model is hoog in vergelijking met de trainingsfout. De bias van een overfittingmodel is laag, terwijl de variantie hoog is.
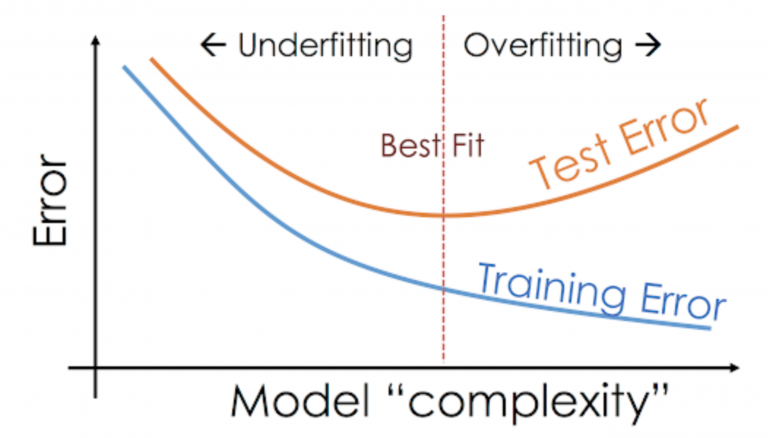
Q46. Wat zijn enkele technieken om overfitting te voorkomen?
Ans. Enkele technieken die kunnen worden gebruikt om overfitting te voorkomen;
- Splitsing trein-validatie-test: Een manier om overfitting te voorkomen, is door uw gegevens op te splitsen in trainings-, validatie- en testsets. Het model wordt getraind op de trainingsset en vervolgens geëvalueerd op de validatieset. De hyperparameters worden vervolgens afgestemd op basis van de prestaties op de validatieset. Zodra het model definitief is, wordt het geëvalueerd op de testset.
- Vroeg stoppen: Een andere manier om overfitting te voorkomen, is door vroegtijdig te stoppen. Dit omvat het trainen van het model totdat de validatiefout een minimum bereikt en vervolgens het trainingsproces stoppen.
- regularisatie: Regularisatie is een techniek die kan worden gebruikt om overfitting te voorkomen door een strafterm aan de doelfunctie toe te voegen. Deze term moedigt het model aan om kleine gewichten te hebben, wat kan helpen de complexiteit van het model te verminderen en overfitting te voorkomen.
- Ensemble-methoden: Ensemble-methoden omvatten het trainen van meerdere modellen en vervolgens het combineren van hun voorspellingen om een definitieve voorspelling te doen. Dit kan overfitting helpen verminderen door de voorspellingen van de individuele modellen te middelen, wat kan helpen de variantie van de uiteindelijke voorspelling te verminderen.
Q47. Wat zijn enkele technieken om underfitting te voorkomen?
Ans. Enkele technieken om underfitting in een model te voorkomen:
Functieselectie: Het is belangrijk om de juiste functie te kiezen die nodig is voor het trainen van een model, aangezien de selectie van de verkeerde functie kan leiden tot ondergeschiktheid.
Het verhogen van het aantal functies helpt om onderfitting te voorkomen
Een complexer model voor machine learning gebruiken
Hyperparameter-afstemming gebruiken om de parameters in het model te verfijnen
Ruis: Als er meer ruis in de data zit, kan het model de complexiteit van de dataset niet detecteren.
Q48. Wat is multicollineariteit?
Ans. Multicollineariteit treedt op wanneer twee of meer voorspellende variabelen in een meervoudig regressiemodel sterk gecorreleerd zijn. Dit kan leiden tot onstabiele en inconsistente coëfficiënten en maakt het moeilijk om de resultaten van het model te interpreteren.
Met andere woorden, multicollineariteit treedt op wanneer er een hoge mate van correlatie is tussen twee of meer voorspellende variabelen. Dit kan het moeilijk maken om de unieke bijdrage van elke voorspellende variabele aan de responsvariabele te bepalen, aangezien de schattingen van hun coëfficiënten kunnen worden beïnvloed door de andere gecorreleerde variabelen.
Q49. Leg regressie- en classificatieproblemen uit.
Ans. Regressie is een methode om de relatie tussen een of meer onafhankelijke variabelen en een afhankelijke variabele te modelleren. Het doel van regressie is om te begrijpen hoe de onafhankelijke variabelen gerelateerd zijn aan de afhankelijke variabele en om voorspellingen te kunnen doen over de waarde van de afhankelijke variabele op basis van nieuwe waarden van de onafhankelijke variabelen.
Een classificatieprobleem is een type machine learning-probleem waarbij het doel is om een afzonderlijk label voor een bepaalde invoer te voorspellen. Met andere woorden, het is een probleem om te identificeren tot welke set categorieën een nieuwe waarneming behoort, op basis van een trainingsset van gegevens die waarnemingen bevatten.
Q50. Wat is het verschil tussen K-middelen en KNN?
Ans. K-betekent en KNN (K-Nearest Neighbours) zijn twee verschillende machine learning-algoritmen.
K-means is een clusteralgoritme dat wordt gebruikt om een groep gegevenspunten te verdelen in K-clusters, waarbij elk gegevenspunt behoort tot het cluster met het dichtstbijzijnde gemiddelde. Het is een iteratief algoritme dat datapunten toewijst aan een cluster en vervolgens het clusterzwaartepunt (gemiddelde) bijwerkt op basis van de datapunten die eraan zijn toegewezen.
Aan de andere kant is KNN een classificatie-algoritme dat wordt gebruikt om gegevenspunten te classificeren op basis van hun gelijkenis met andere gegevenspunten. Het werkt door de K-gegevenspunten in de trainingsset te vinden die het meest lijken op het gegevenspunt dat wordt geclassificeerd, en vervolgens wijst het het gegevenspunt toe aan de klasse die het meest voorkomt onder die K-gegevenspunten.
Kortom, K-means wordt gebruikt voor clustering en KNN wordt gebruikt voor classificatie.
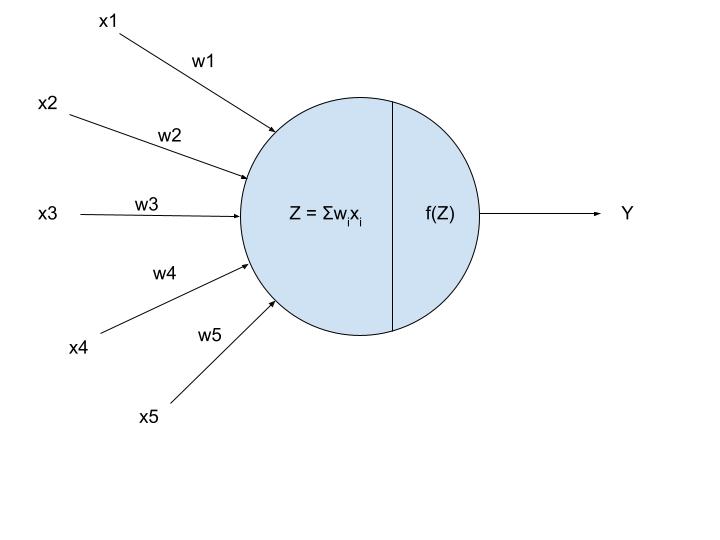
Q51. Wat is het verschil tussen Sigmoid en Softmax?
Ans. Als uw uitvoer in de Sigmoid-functie binair is (0,1), gebruik dan de sigmoid-functie voor de uitvoerlaag. De sigmoid-functie verschijnt in de uitvoerlaag van de deep learning-modellen en wordt gebruikt voor het voorspellen van op waarschijnlijkheid gebaseerde uitvoer.
De softmax-functie is een ander type activeringsfunctie die wordt gebruikt in neurale netwerken om kansverdeling te berekenen op basis van een vector van reële getallen.
Deze functie wordt voornamelijk gebruikt in modellen met meerdere klassen, waar de kansen van elke klasse worden geretourneerd, waarbij de doelklasse de hoogste waarschijnlijkheid heeft.
Het belangrijkste verschil tussen de sigmoid- en softmax-activeringsfunctie is dat terwijl de eerste wordt gebruikt in binaire classificatie, de laatste wordt gebruikt voor multivariate classificatie
Q52. Kunnen we logistische regressie gebruiken voor classificatie met meerdere klassen?
Ans. Ja, logistische regressie kan worden gebruikt voor classificatie met meerdere klassen.
Logistische regressie is een classificatie-algoritme dat wordt gebruikt om de waarschijnlijkheid te voorspellen dat een datapunt tot een bepaalde klasse behoort. Het is een binair classificatie-algoritme, wat betekent dat het slechts twee klassen aankan. Er zijn echter manieren om logistische regressie uit te breiden naar classificatie met meerdere klassen.
Een manier om dit te doen is door een één-vs-all (OvA) of één-vs-rest (OvR) strategie te gebruiken, waarbij u K logistische regressieclassificaties traint, één voor elke klasse, en een gegevenspunt toewijst aan de klasse die heeft de hoogst voorspelde waarschijnlijkheid. Dit wordt OvA genoemd als je voor elke klasse één classifier traint en de andere klasse de "rest" van de klassen is. Dit wordt OvR genoemd als je één classifier voor elke klasse traint en de andere klasse de "alle" klassen is.
Een andere manier om dit te doen is door gebruik te maken van multinominale logistische regressie, wat een veralgemening is van logistische regressie naar het geval dat u meer dan twee klassen hebt. Bij multinomiale logistische regressie traint u een logistische regressieclassificatie voor elk paar klassen en gebruikt u de voorspelde waarschijnlijkheden om een gegevenspunt toe te wijzen aan de klasse met de hoogste waarschijnlijkheid.
Kortom, logistische regressie kan worden gebruikt voor classificatie met meerdere klassen met behulp van OvA/OvR of multinomiale logistische regressie.
Q53. Kun je de wisselwerking tussen bias en variantie verklaren in de context van gesuperviseerd machinaal leren?
Ans. Bij gesuperviseerd machinaal leren is het doel om een model te bouwen dat nauwkeurige voorspellingen kan doen op basis van ongeziene gegevens. Er is echter een wisselwerking tussen het vermogen van het model om goed te passen bij de trainingsgegevens (lage bias) en het vermogen om te generaliseren naar nieuwe gegevens (lage variantie).
Een model met een hoge bias heeft de neiging om de gegevens te onderpassen, wat betekent dat het niet flexibel genoeg is om de patronen in de gegevens vast te leggen. Aan de andere kant heeft een model met een hoge variantie de neiging om de gegevens te overfitten, wat betekent dat het te gevoelig is voor ruis en willekeurige fluctuaties in de trainingsgegevens.
De wisselwerking tussen bias en variantie verwijst naar de wisselwerking tussen deze twee soorten fouten. Een model met een lage vertekening en een hoge variantie past waarschijnlijk te veel bij de gegevens, terwijl een model met een hoge vertekening en een lage variantie de gegevens waarschijnlijk onderschrijdt.
Om de afweging tussen vertekening en variantie in evenwicht te brengen, moeten we een model vinden met het juiste complexiteitsniveau voor het probleem in kwestie. Als het model te simpel is, zal het een hoge bias en lage variantie hebben, maar zal het niet in staat zijn om de onderliggende patronen in de data vast te leggen. Als het model te complex is, zal het weinig vertekening en hoge variantie hebben, maar zal het gevoelig zijn voor de ruis in de data en zal het niet goed generaliseren naar nieuwe data.
Q54. Hoe bepaal je of een model lijdt aan hoge bias of hoge variantie?
Ans. Er zijn verschillende manieren om te bepalen of een model lijdt aan hoge bias of hoge variantie. Enkele veelgebruikte methodes zijn:
Splits de gegevens op in een trainingsset en een testset en controleer de prestaties van het model op beide sets. Als het model goed presteert op de trainingsset maar slecht op de testset, is er waarschijnlijk sprake van een hoge variantie (overfitting). Als het model op beide sets slecht presteert, lijdt het waarschijnlijk aan hoge bias (underfitting).
Gebruik kruisvalidatie om de prestaties van het model te schatten. Als het model een hoge variantie heeft, zullen de prestaties aanzienlijk variëren, afhankelijk van de gegevens die worden gebruikt voor training en testen. Als het model een hoge bias heeft, zullen de prestaties consistent laag zijn over verschillende splitsingen van de gegevens.
Zet de leercurve uit, die de prestaties van het model op de trainingsset en de testset laat zien als functie van het aantal trainingsvoorbeelden. Een model met een hoge bias zal een hoge trainingsfout en een hoge testfout hebben, terwijl een model met een hoge variantie een lage trainingsfout en een hoge testfout zal hebben.
Q55. Wat zijn enkele technieken om bias en variantie in een model in evenwicht te brengen?
Ans. Er zijn verschillende technieken die kunnen worden gebruikt om de vertekening en variantie in een model in evenwicht te brengen, waaronder:
De modelcomplexiteit vergroten door meer parameters of functies toe te voegen: dit kan het model helpen complexere patronen in de gegevens vast te leggen en vertekening te verminderen, maar het kan ook de variantie vergroten als het model te complex wordt.
De complexiteit van het model verminderen door parameters of kenmerken te verwijderen: dit kan het model helpen om overfitting te voorkomen en de variantie te verminderen, maar het kan ook de vertekening vergroten als het model te simpel wordt.
Gebruik van regularisatietechnieken: deze technieken beperken de modelcomplexiteit door grote gewichten te bestraffen, wat het model kan helpen overfitting te voorkomen en variantie te verminderen. Enkele voorbeelden van regularisatietechnieken zijn L1-regularisatie, L2-regularisatie en elastische net-regularisatie.
De gegevens opsplitsen in een trainingsset en een testset: dit stelt ons in staat om het generalisatievermogen van het model te evalueren en de modelcomplexiteit af te stemmen om een goede balans tussen vertekening en variantie te bereiken.
Kruisvalidatie gebruiken: dit is een techniek om de prestaties van het model op verschillende delen van de gegevens te evalueren en de resultaten te middelen om een nauwkeurigere schatting te krijgen
van het generalisatievermogen van het model.
Q56. Hoe kies je de juiste evaluatiemetriek voor een classificatieprobleem en hoe interpreteer je de resultaten van de evaluatie?
Ans. Er zijn veel evaluatiestatistieken die u kunt gebruiken voor een classificatieprobleem, en de juiste statistiek hangt af van de specifieke kenmerken van het probleem en de doelen van de evaluatie. Enkele veelgebruikte evaluatiestatistieken voor classificatie zijn:
Nauwkeurigheid: Dit is de meest gebruikelijke evaluatiemaatstaf voor classificatie. Het meet het percentage correcte voorspellingen van het model.
precisie: Deze statistiek meet het aandeel echt positieve voorspellingen van alle positieve voorspellingen van het model.
Terugroepen: Deze statistiek meet het aandeel van echt positieve voorspellingen onder alle daadwerkelijke positieve gevallen in de testset.
F1-score: Dit is het harmonische gemiddelde van precisie en herinnering. Het is een goede maatstaf om te gebruiken wanneer u precisie en herinnering in evenwicht wilt brengen.
AUC-ROC: Deze statistiek meet het vermogen van het model om onderscheid te maken tussen positieve en negatieve klassen. Het wordt vaak gebruikt voor onevenwichtige classificatieproblemen.
Om de resultaten van de evaluatie te interpreteren, moet u rekening houden met de specifieke kenmerken van het probleem en de doelen van de evaluatie. Als u bijvoorbeeld frauduleuze transacties probeert te identificeren, bent u misschien meer geïnteresseerd in maximale precisie, omdat u het aantal valse alarmen wilt minimaliseren. Aan de andere kant, als u probeert een ziekte te diagnosticeren, bent u misschien meer geïnteresseerd in het maximaliseren van de herinnering, omdat u het aantal gemiste diagnoses wilt minimaliseren.
Q57. Wat is het verschil tussen K-means en hiërarchische clustering en wanneer wat gebruiken?
Ans. K-betekent en hiërarchische clustering zijn twee verschillende methoden voor het clusteren van gegevens. Beide methoden kunnen in verschillende situaties nuttig zijn.
K-means is een zwaartepuntgebaseerd algoritme, of een op afstand gebaseerd algoritme, waarbij we de afstanden berekenen om een punt aan een cluster toe te wijzen. K-means is erg snel en efficiënt in termen van rekentijd, maar kan het globale optimum niet vinden omdat het willekeurige initialisaties gebruikt voor de zwaartepuntzaden.
Hiërarchische clustering daarentegen is een op dichtheid gebaseerd algoritme waarvoor we niet van tevoren het aantal clusters hoeven op te geven. Het bouwt een hiërarchie van clusters op door een boomachtig diagram te maken, een dendrogram genaamd. Er zijn twee hoofdtypen hiërarchische clustering: agglomeratief en verdeeldheid zaaiend. Agglomeratieve clustering begint met individuele punten als afzonderlijke clusters en voegt ze samen tot grotere clusters, terwijl divisieve clustering begint met alle punten in één cluster en ze verdeelt in kleinere clusters. Hiërarchische clustering is een langzaam algoritme en vereist veel rekenkracht, maar het is nauwkeuriger dan K-means.
Dus, wanneer gebruik je K-middelen en wanneer gebruik je hiërarchische clustering? Het hangt echt af van de grootte en structuur van uw gegevens, evenals de bronnen die u tot uw beschikking heeft. Heb je een grote dataset en wil je deze snel clusteren, dan is K-means wellicht een goede keuze. Als je een kleine dataset hebt of als je nauwkeurigere clusters wilt, dan is hiërarchische clustering wellicht een betere keuze.
Q58. Hoe ga je om met onevenwichtige klassen in een logistisch regressiemodel?
Ans. Er zijn verschillende manieren om met onevenwichtige klassen om te gaan in een logistisch regressiemodel. Enkele benaderingen zijn:
Onderbemonstering van de meerderheidsklasse: Dit omvat het willekeurig selecteren van een subset van de meerderheidsklasse-steekproeven om te gebruiken bij het trainen van het model. Dit kan helpen om de klassenverdeling in evenwicht te brengen, maar het kan ook waardevolle informatie weggooien.
Oversampling van de minderheidsklasse: Dit omvat het genereren van synthetische voorbeelden van de minderheidsklasse om toe te voegen aan de trainingsset. Een populaire methode voor het genereren van synthetische samples wordt SMOTE (Synthetic Minority Oversampling Technique) genoemd.
De gewichten van de klassen aanpassen: met veel algoritmen voor machine learning kunt u de weging van elke klas aanpassen. Bij logistische regressie kunt u dit doen door de parameter class_weight in te stellen op "balanced". Hierdoor worden de klassen automatisch omgekeerd evenredig met hun frequentie gewogen, zodat het model meer aandacht besteedt aan de minderheidsklasse.
Een andere evaluatiestatistiek gebruiken: bij onevenwichtige classificatietaken is het vaak informatiever om evaluatiestatistieken te gebruiken die gevoelig zijn voor klasseonevenwichtigheid, zoals precisie, herinnering en de F1-score.
Een ander algoritme gebruiken: Sommige algoritmen, zoals beslissingsbomen en willekeurige forests, zijn robuuster voor onevenwichtige klassen en presteren mogelijk beter op onevenwichtige datasets.
Q59. Wanneer PCA niet gebruiken voor dimensionaliteitsreductie?
Ans. Er zijn verschillende situaties waarin u Principal Component Analysis (PCA) niet wilt gebruiken voor dimensionaliteitsreductie:
Wanneer de gegevens niet lineair scheidbaar zijn: PCA is een lineaire techniek, dus het is mogelijk niet effectief bij het verminderen van de dimensionaliteit van gegevens die niet lineair scheidbaar zijn.
Wanneer de gegevens categorische kenmerken hebben: PCA is ontworpen om te werken met continue numerieke gegevens en is mogelijk niet effectief in het verminderen van de dimensionaliteit van gegevens met categorische kenmerken.
Wanneer de gegevens een groot aantal ontbrekende waarden hebben: PCA is gevoelig voor ontbrekende waarden en werkt mogelijk niet goed met datasets met een groot aantal ontbrekende waarden.
Wanneer de gegevens zeer onevenwichtig zijn: PCA is gevoelig voor klassenonevenwichtigheden en levert mogelijk geen goede resultaten op zeer onevenwichtige datasets.
Wanneer het doel is om de relaties tussen de oorspronkelijke kenmerken te behouden: PCA is een techniek die zoekt naar patronen in de gegevens en nieuwe kenmerken creëert die combinaties zijn van de originele kenmerken. Als gevolg hiervan is het misschien niet de beste keuze als het doel is om de relaties tussen de originele kenmerken te behouden.
Q60. Wat is gradiëntafdaling?
Ans. Verloop afdaling is een optimalisatie-algoritme dat wordt gebruikt bij machine learning om de waarden van parameters (coëfficiënten en bias) van een model te vinden die de kostenfunctie minimaliseren. Het is een iteratief optimalisatiealgoritme van de eerste orde dat de negatieve gradiënt van de kostenfunctie volgt om te convergeren naar het globale minimum.
Bij gradiëntafdaling worden de parameters van het model geïnitialiseerd met willekeurige waarden, en het algoritme werkt de parameters iteratief bij in de tegenovergestelde richting van de gradiënt van de kostenfunctie met betrekking tot de parameters. De grootte van de update wordt bepaald door de leersnelheid, een hyperparameter die bepaalt hoe snel het algoritme convergeert naar het globale minimum.
Naarmate het algoritme de parameters bijwerkt, neemt de kostenfunctie af en verbeteren de prestaties van het model
Q61. Wat is het verschil tussen MinMaxScaler en StandardScaler?
Ans. Zowel de MinMaxScaler als de StandardScaler zijn tools die worden gebruikt om de kenmerken van een dataset te transformeren, zodat ze beter kunnen worden gemodelleerd door algoritmen voor machine learning. Ze werken echter op verschillende manieren.
MinMaxScaler schaalt de kenmerken van een dataset door ze te transformeren naar een specifiek bereik, meestal tussen 0 en 1. Het doet dit door de minimumwaarde van elk kenmerk af te trekken van alle waarden in dat kenmerk en het resultaat vervolgens te delen door het bereik (dwz , het verschil tussen de minimum- en maximumwaarden). Deze transformatie wordt gegeven door de volgende vergelijking:
x_geschaald = (x – x_min) / (x_max – x_min)
StandardScaler standaardiseert de kenmerken van een dataset door ze te transformeren zodat ze geen gemiddelde en eenheidsvariantie hebben. Het doet dit door het gemiddelde van elk kenmerk af te trekken van alle waarden in dat kenmerk en het resultaat vervolgens te delen door de standaarddeviatie. Deze transformatie wordt gegeven door de volgende vergelijking:
x_scaled = (x – gemiddelde(x)) / standaard(x)
Over het algemeen is StandardScaler geschikter voor datasets waarbij de verdeling van de kenmerken ongeveer normaal of Gaussiaans is. MinMaxScaler is meer geschikt voor datasets waar de verdeling scheef is of waar er uitschieters zijn. Het is echter altijd een goed idee om de gegevens te visualiseren en de verdeling van de functies te begrijpen voordat u een schaalmethode kiest.
Q62. Wat is het verschil tussen begeleid en niet-gesuperviseerd leren?
Ans.Bij begeleid leren bevat de trainingsset die u aan het algoritme geeft, het gewenste
oplossingen, genaamd labels
Bijv. = Spamfilter (classificatieprobleem)
k-Naaste buren
- Lineaire regressie
- Logistische regressie
- Ondersteuning van vectormachines (SVM's)
- Beslisbomen en willekeurige bossen
- Neurale netwerken
Bij onbewaakt leren zijn de trainingsgegevens niet gelabeld.
Laten we zeggen: het systeem probeert te leren zonder leraar.
Clustering
—K-middelen
—DBSCAN
—Hiërarchische clusteranalyse (HCA)
- Anomaliedetectie en nieuwheidsdetectie
—Eén klasse SVM
— Isolatiebos
- Visualisatie en dimensionaliteitsreductie
—Principal Component Analyse (PCA)
—Kernel-PCA
—Lokaal lineaire inbedding (LLE)
—t-gedistribueerde stochastische buurinbedding (t-SNE)
Q63. Wat zijn enkele veelgebruikte methoden voor het afstemmen van hyperparameters?
Ans. Er zijn verschillende algemene methoden voor het afstemmen van hyperparameters:
Raster zoeken: Hierbij wordt voor elke hyperparameter een set waarden gespecificeerd en wordt het model getraind en geëvalueerd met behulp van een combinatie van alle mogelijke hyperparameterwaarden. Dit kan rekenkundig duur zijn, aangezien het aantal combinaties exponentieel groeit met het aantal hyperparameters.
Willekeurig zoeken: hierbij worden willekeurige combinaties van hyperparameters bemonsterd en wordt het model voor elke combinatie getraind en geëvalueerd. Dit is minder rekenintensief dan zoeken in rasters, maar is mogelijk minder effectief bij het vinden van de optimale set hyperparameters.
Q64. Hoe bepaal je de grootte van je validatie- en testsets?
Ans. De grootte van de dataset: In het algemeen geldt: hoe groter de dataset, hoe groter de validatie- en testsets kunnen zijn. Dit komt omdat er meer gegevens zijn om mee te werken, zodat de validatie- en testsets representatiever kunnen zijn voor de algehele dataset.
De complexiteit van het model: als het model heel eenvoudig is, zijn er mogelijk niet zoveel gegevens nodig om te valideren en te testen. Aan de andere kant, als het model erg complex is, kan het meer gegevens nodig hebben om ervoor te zorgen dat het robuust is en goed generaliseert naar ongeziene gegevens.
De mate van onzekerheid: als verwacht wordt dat het model zeer goed presteert op de taak, kunnen de validatie- en testsets kleiner zijn. Als de prestaties van het model echter onzeker zijn of de taak erg uitdagend is, kan het nuttig zijn om grotere validatie- en testsets te hebben om een nauwkeurigere beoordeling van de prestaties van het model te krijgen.
De beschikbare bronnen: De omvang van de validatie- en testsets kan ook worden beperkt door de beschikbare rekenbronnen. Het kan onpraktisch zijn om zeer grote validatie- en testsets te gebruiken als het veel tijd kost om het model te trainen en te evalueren.
Q65. Hoe evalueer je de prestaties van een model voor een classificatieprobleem met meerdere klassen?
Ans. Een benadering voor het evalueren van een classificatiemodel met meerdere klassen is het berekenen van een afzonderlijke evaluatiemetriek voor elke klasse en vervolgens het berekenen van een macro- of microgemiddelde. Het macrogemiddelde geeft evenveel gewicht aan alle klassen, terwijl het microgemiddelde meer gewicht geeft aan de klassen met meer waarnemingen. Daarnaast kunnen ook enkele veelgebruikte statistieken worden gebruikt voor classificatieproblemen met meerdere klassen, zoals verwarringsmatrix, precisie, terugroepen, F1-score, nauwkeurigheid en ROC-AUC.
Q66. Wat is het verschil tussen statistisch leren en machine learning met hun voorbeelden?
Ans. Statistisch leren en machine learning zijn beide methoden die worden gebruikt om voorspellingen te doen of beslissingen te nemen op basis van gegevens. Er zijn echter enkele belangrijke verschillen tussen de twee benaderingen:
Statistisch leren richt zich op het doen van voorspellingen of beslissingen op basis van een statistisch model van de gegevens. Het doel is om de relaties tussen de variabelen in de gegevens te begrijpen en voorspellingen te doen op basis van die relaties. Machine learning daarentegen richt zich op het doen van voorspellingen of beslissingen op basis van patronen in de gegevens, zonder noodzakelijkerwijs de relaties tussen de variabelen te proberen te begrijpen.
Statistische leermethoden zijn vaak gebaseerd op sterke aannames over de gegevensdistributie, zoals normaliteit of onafhankelijkheid van fouten. Methoden voor machinaal leren zijn daarentegen vaak beter bestand tegen schendingen van deze aannames.
Statistische leermethoden zijn over het algemeen beter interpreteerbaar omdat het statistische model kan worden gebruikt om de relaties tussen de variabelen in de gegevens te begrijpen. Methoden voor machinaal leren zijn daarentegen vaak minder interpreteerbaar, omdat ze gebaseerd zijn op patronen in de data in plaats van op expliciete relaties tussen variabelen.
Lineaire regressie is bijvoorbeeld een statistische leermethode die uitgaat van een lineaire relatie tussen de voorspellende en doelvariabelen en de coëfficiënten van het lineaire model schat met behulp van een optimalisatie-algoritme. Random forests is een machine learning-methode die een ensemble van beslissingsbomen bouwt en voorspellingen doet op basis van het gemiddelde van de voorspellingen van de individuele bomen.
Q67. Hoe is genormaliseerde data gunstig voor het maken van modellen in data science?
Ans. Verbeterde modelprestaties: het normaliseren van de gegevens kan de prestaties van sommige machine learning-modellen verbeteren, met name die welke gevoelig zijn voor de schaal van de invoergegevens. Het normaliseren van de gegevens kan bijvoorbeeld de prestaties van algoritmen zoals K-naaste buren en neurale netwerken verbeteren.
Gemakkelijkere functievergelijking: Het normaliseren van de gegevens kan het gemakkelijker maken om het belang van verschillende functies te vergelijken. Zonder normalisatie kunnen kenmerken met grote schaal het model domineren, waardoor het moeilijk wordt om het relatieve belang van andere kenmerken te bepalen.
Verminderde impact van uitschieters: Het normaliseren van de gegevens kan de impact van uitschieters op het model verminderen, omdat ze samen met de rest van de gegevens worden verkleind. Dit kan de robuustheid van het model verbeteren en voorkomen dat het beïnvloed wordt door extreme waarden.
Verbeterde interpreteerbaarheid: Het normaliseren van de gegevens kan het gemakkelijker maken om de resultaten van het model te interpreteren, aangezien de coëfficiënten en het belang van kenmerken allemaal op dezelfde schaal liggen.
Het is belangrijk op te merken dat normalisatie niet altijd noodzakelijk of gunstig is voor alle modellen. Het is noodzakelijk om de specifieke kenmerken en behoeften van de gegevens en het model zorgvuldig te evalueren om te bepalen of normalisatie passend is.
Tussentijdse interviewvragen
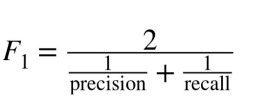
Q68. Waarom wordt het harmonisch gemiddelde berekend in de f1-score en niet het gemiddelde?
Ans.De F1-score is een maatstaf die precisie en herinnering combineert. Precisie is het aantal echt positieve resultaten gedeeld door het totale aantal positieve resultaten dat door de classificator wordt voorspeld, en recall is het aantal echt positieve resultaten gedeeld door het totale aantal positieve resultaten in de grondwaarheid. Het harmonische gemiddelde van precisie en herinnering wordt gebruikt om de F1-score te berekenen, omdat het meer vergevingsgezind is voor onevenwichtige klassenverhoudingen dan het rekenkundig gemiddelde.
Als de harmonische gemiddelden niet zouden worden gebruikt, zou de F1-score hoger zijn omdat deze gebaseerd zou zijn op het rekenkundige gemiddelde van precisie en herinnering, wat meer gewicht zou geven aan de hoge precisie en minder gewicht aan de lage herinnering. Het gebruik van het harmonische gemiddelde in de F1-score helpt om de precisie en herinnering in evenwicht te brengen en geeft een meer accurate algemene beoordeling van de prestaties van de classificator.
Q69. Wat zijn enkele manieren om functies te selecteren?
Ans. Hier zijn enkele manieren om de functies te selecteren:
- Filtermethoden: deze methoden gebruiken statistische scores om de meest relevante kenmerken te selecteren.
bv.
- Correlatiecoëfficiënt: Selecteert kenmerken die sterk gecorreleerd zijn met de doelvariabele.
- Chi-kwadraattoets: Selecteert functies die onafhankelijk zijn van de doelvariabele.
- Wrapper methoden: Deze methoden gebruiken een leeralgoritme om de beste functies te selecteren.
bv.
- Voorwaartse selectie: Begint met een lege set functies en voegt één functie tegelijk toe totdat de prestaties van het model optimaal zijn.
- Achterwaartse selectie: Begint met de volledige set functies en verwijdert één functie tegelijk totdat de prestaties van het model optimaal zijn.
- Ingebedde methoden: Deze methoden leren welke functies het belangrijkst zijn terwijl het model wordt getraind.
bv.
- Lasso-regressie: Regelt het model door een strafterm toe te voegen aan de verliesfunctie die de coëfficiënten van de minder belangrijke kenmerken tot nul reduceert.
- Ridge regressie: Regelt het model door een strafterm toe te voegen aan de verliesfunctie die de coëfficiënten van alle kenmerken naar nul verkleint, maar ze niet op nul zet.
Kenmerk Belang: We kunnen ook de kenmerkbelangparameter gebruiken die ons de belangrijkste kenmerken geeft die door het model worden overwogen
Q70. Wat is het verschil tussen het boosten van zakken?
Ans. Zowel bagging als boosting zijn technieken voor het leren van ensembles die helpen bij het verbeteren van de prestaties van het model.
Bagging is de techniek waarbij verschillende modellen worden getraind op de dataset die we hebben en vervolgens wordt rekening gehouden met het gemiddelde van de voorspellingen van deze modellen. De intuïtie achter het nemen van de voorspellingen van alle modellen en het vervolgens middelen van de resultaten maakt meer diverse en gegeneraliseerde voorspellingen die nauwkeuriger kunnen zijn.
Boosting is de techniek waarin verschillende modellen worden getraind, maar ze worden op een sequentiële manier getraind. Elk volgend model corrigeert de fout van het vorige model. Dit maakt het model sterk wat resulteert in de minste fouten.
Q71. Wat is het verschil tussen stochastische gradiëntversterking en XGboost?
Ans. XGBoost is een implementatie van gradiëntversterking die speciaal is ontworpen om efficiënt, flexibel en draagbaar te zijn. Stochastische XGBoost is een variant van XGBoost die een meer gerandomiseerde benadering gebruikt voor het bouwen van beslissingsbomen, waardoor het resulterende model robuuster kan worden voor overfitting.
Zowel XGBoost als stochastische XGBoost zijn populaire keuzes voor het bouwen van modellen voor machine learning en kunnen worden gebruikt voor een breed scala aan taken, waaronder classificatie, regressie en classificatie. Het belangrijkste verschil tussen de twee is dat XGBoost een deterministisch algoritme voor boomconstructie gebruikt, terwijl stochastisch XGBoost een gerandomiseerd algoritme voor boomconstructie gebruikt.
Q72. Wat is het verschil tussen catboost en XGboost?
Ans. Verschil tussen Catboost en XGboost:
Catboost verwerkt categorische functies beter dan XGboost. In catboost hoeven de categorische functies niet one-hot gecodeerd te zijn, wat veel tijd en geheugen bespaart. XGboost daarentegen kan ook categorische functies aan, maar deze moesten eerst one-hot worden gecodeerd.
XGboost vereist handmatige verwerking van de gegevens, terwijl Catboost dat niet doet. Ze hebben enkele verschillen in de manier waarop ze beslisbomen bouwen en voorspellingen doen.
Catboost is sneller dan XGboost en bouwt symmetrische (gebalanceerde) bomen, in tegenstelling tot XGboost.
Q73. Wat is het verschil tussen lineaire en niet-lineaire classificaties
Ans. Het verschil tussen de lineaire en niet-lineaire classificaties is de aard van de beslissingsgrens.
In een lineaire classificator is de beslissingsgrens een lineaire functie van de invoer. Met andere woorden, de grens is een rechte lijn, een vlak of een hypervlak.
bijv.: lineaire regressie, logistische regressie, LDA
Een niet-lineaire classificatie is er een waarin de beslissingsgrens geen lineaire functie is van de invoer. Dit betekent dat de classificator niet kan worden gerepresenteerd door een lineaire functie van de invoerkenmerken. Niet-lineaire classificaties kunnen complexere relaties tussen de invoerkenmerken en het label vastleggen, maar ze kunnen ook vatbaarder zijn voor overfitting, vooral als ze veel parameters hebben.
bijv.: KNN, beslissingsboom, willekeurig bos
Q74. Wat zijn parametrische en niet-parametrische modellen?
Ans. Een parametrisch model is een model dat wordt beschreven door een vast aantal parameters. Deze parameters worden geschat op basis van de gegevens met behulp van een schattingsprocedure met maximale waarschijnlijkheid of een andere methode, en ze worden gebruikt om voorspellingen te doen over de responsvariabele.
Aan de andere kant zijn niet-parametrische modellen modellen die geen aannames doen over de vorm van de relatie tussen de afhankelijke en onafhankelijke variabelen. Ze zijn over het algemeen flexibeler dan parametrische modellen en passen in een breder scala aan gegevensvormen, maar ze hebben ook minder interpreteerbare parameters en kunnen moeilijker te interpreteren zijn.
Q75. Hoe kunnen we kruisvalidatie gebruiken om overfitting tegen te gaan?
Ans. De kruisvalidatietechniek kan worden gebruikt om vast te stellen of het model onder- of overfitting is, maar kan niet worden gebruikt om een van de problemen op te lossen. We kunnen de prestaties van het model alleen vergelijken op twee verschillende gegevenssets en bepalen of de gegevens overfitting of underfitting zijn, of gegeneraliseerd.
Q76. Hoe zet je een numerieke variabele om in een categorische variabele en wanneer is het handig?
Ans. Er zijn verschillende manieren om een numerieke variabele om te zetten in een categorische variabele. Een gebruikelijke methode is het gebruik van binning, waarbij de numerieke variabele wordt verdeeld in een reeks bins of intervallen en elke bin als een afzonderlijke categorie wordt behandeld.
Een andere manier om een numerieke variabele om te zetten in een categorische variabele is door een techniek te gebruiken die "discretisatie" wordt genoemd, waarbij het bereik van de numerieke variabele wordt verdeeld in een reeks intervallen en elk interval als een afzonderlijke categorie wordt behandeld. Dit kan handig zijn als u een meer gedetailleerde weergave van de gegevens wilt maken.
Het converteren van een numerieke variabele naar een categorische variabele kan handig zijn wanneer de numerieke variabele een beperkt aantal waarden aanneemt en u deze waarden in categorieën wilt groeperen. Het kan ook handig zijn als u de onderliggende patronen of trends in de gegevens wilt benadrukken, in plaats van alleen de ruwe cijfers.
Q77. Wat zijn gegeneraliseerde lineaire modellen?
Ans. Gegeneraliseerde lineaire modellen (GLM's) zijn een familie van modellen waarmee we de relatie tussen een responsvariabele en een of meer voorspellende variabelen kunnen specificeren, terwijl er meer flexibiliteit is in de vorm van deze relatie in vergelijking met traditionele lineaire modellen. In een traditioneel lineair model wordt aangenomen dat de responsvariabele normaal verdeeld is en dat de relatie tussen de responsvariabele en de voorspellende variabelen lineair is. GLM's versoepelen deze aannames, waardoor de responsvariabele kan worden verdeeld volgens een verscheidenheid aan verschillende distributies, en waardoor niet-lineaire relaties tussen de respons- en voorspellende variabelen mogelijk zijn. Enkele veelvoorkomende voorbeelden van GLM's zijn logistische regressie (voor binaire classificatietaken), Poisson-regressie (voor telgegevens) en exponentiële regressie (voor het modelleren van time-to-event-gegevens).
Q78. Wat is het verschil tussen nok- en lasso-regressie? Hoe verschillen ze in hun benadering van modelselectie en regularisatie?
Ans. Ridge-regressie en lasso-regressie zijn beide technieken die worden gebruikt om overfitting in lineaire modellen te voorkomen door een regularisatieterm aan de doelfunctie toe te voegen. Ze verschillen in hoe ze de regularisatietermijn definiëren.
Bij nokregressie wordt de regularisatieterm gedefinieerd als de som van de gekwadrateerde coëfficiënten (ook wel de L2-penalty genoemd). Dit resulteert in een glad optimalisatieoppervlak, waardoor het model beter kan generaliseren naar ongeziene gegevens. Ridge-regressie heeft tot gevolg dat de coëfficiënten naar nul worden gedreven, maar stelt geen enkele coëfficiënt precies op nul. Dit betekent dat alle kenmerken behouden blijven in het model, maar dat hun impact op de uitvoer wordt verminderd.
Aan de andere kant definieert lasso-regressie de regularisatieterm als de som van de absolute waarden van de coëfficiënten (ook wel de L1-penalty genoemd). Dit heeft tot gevolg dat sommige coëfficiënten exact naar nul worden gestuurd, waardoor in feite een subset van de functies wordt geselecteerd die in het model moeten worden gebruikt. Dit kan handig zijn bij het selecteren van kenmerken, omdat het model hierdoor automatisch de belangrijkste kenmerken kan selecteren. Het optimalisatieoppervlak voor lasso-regressie is echter niet glad, wat het moeilijker kan maken om het model te trainen.
Samengevat, nokregressie verkleint de coëfficiënten van alle kenmerken tot nul, terwijl lassoregressie sommige coëfficiënten precies op nul zet. Beide technieken kunnen nuttig zijn om overfitting te voorkomen, maar ze verschillen in de manier waarop ze omgaan met modelselectie en regularisatie.
V79.Hoe beïnvloedt de stapgrootte (of leersnelheid) van een optimalisatie-algoritme de convergentie van het optimalisatieproces in logistische regressie?
Ans. De stapgrootte, of leersnelheid, bepaalt de grootte van de stappen die door het optimalisatie-algoritme worden genomen bij het naderen van het minimum van de doelfunctie. Bij logistische regressie is de objectieve functie de negatieve log-waarschijnlijkheid van het model, die we willen minimaliseren om de optimale coëfficiënten te vinden.
Als de stapgrootte te groot is, kan het optimalisatie-algoritme het minimum overschrijden en eromheen oscilleren, mogelijk zelfs divergerend in plaats van convergerend. Aan de andere kant, als de stapgrootte te klein is, zal het optimalisatie-algoritme zeer langzaam vooruitgang boeken en kan het lang duren om te convergeren.
Daarom is het belangrijk om een geschikte stapgrootte te kiezen om de convergentie van het optimalisatieproces te waarborgen. Over het algemeen kan een grotere stapgrootte leiden tot snellere convergentie, maar het verhoogt ook het risico dat het minimum wordt overschreden. Een kleinere stapgrootte is veiliger, maar ook langzamer.
Er zijn verschillende benaderingen voor het kiezen van een geschikte stapgrootte. Een gebruikelijke benadering is om voor alle iteraties een vaste stapgrootte te gebruiken. Een andere benadering is om een afnemende stapgrootte te gebruiken, die groot begint en in de loop van de tijd afneemt. Dit kan het optimalisatie-algoritme helpen om in het begin sneller vooruitgang te boeken en vervolgens de coëfficiënten te verfijnen naarmate het minimum nadert.
Q80. Wat is overfitting in beslisbomen en hoe kan dit worden beperkt?
Ans. Overfitting in beslissingsbomen doet zich voor wanneer het model te complex is en te veel vertakkingen heeft, wat leidt tot slechte generalisatie naar nieuwe, ongeziene gegevens. Dit komt omdat het model de patronen in de trainingsgegevens te goed heeft "geleerd" en niet in staat is om deze patronen te generaliseren naar nieuwe, ongeziene gegevens.
Er zijn verschillende manieren om overfitting in beslisbomen tegen te gaan:
snoeien: Hierbij worden takken uit de boom verwijderd die geen significante waarde toevoegen aan de voorspellingen van het model. Snoeien kan helpen de complexiteit van het model te verminderen en het generalisatievermogen te verbeteren.
Beperkende boomdiepte: Door de diepte van de boom te beperken, kunt u voorkomen dat de boom te complex wordt en de trainingsgegevens overbelast.
Ensembles gebruiken: Ensemblemethoden zoals willekeurige forests en gradiëntversterking kunnen overfitting helpen verminderen door de voorspellingen van meerdere beslissingsbomen samen te voegen.
Kruisvalidatie gebruiken: Door de prestaties van het model op meerdere trein-testsplitsingen te evalueren, kunt u een betere schatting krijgen van de generalisatieprestaties van het model en het risico op overfitting verkleinen.
Q81. Waarom wordt SVM een classifier met grote marge genoemd?
Ans. SVM, of Support Vector Machine, wordt een classificatie met grote marges genoemd omdat het een hypervlak probeert te vinden met de grootst mogelijke marge of afstand tussen de positieve en negatieve klassen in de kenmerkruimte. De marge is de afstand tussen het hypervlak en de dichtstbijzijnde gegevenspunten en wordt gebruikt om de beslissingsgrens van het model te definiëren.
Door de marge te maximaliseren, kan de SVM-classificator beter generaliseren naar nieuwe, ongeziene gegevens en is hij minder vatbaar voor overfitting. Hoe groter de marge, hoe lager de onzekerheid rond de beslissingsgrens en hoe meer vertrouwen het model heeft in zijn voorspellingen.
Daarom is het doel van het SVM-algoritme het vinden van een hypervlak met de grootst mogelijke marge, daarom wordt het een classifier met grote marge genoemd.
Q82. Wat is scharnierverlies?
Ans. Scharnierverlies is een verliesfunctie die wordt gebruikt in Support Vector Machines (SVM's) en andere lineaire classificatiemodellen. Het wordt gedefinieerd als het verlies dat wordt geleden wanneer een voorspelling onjuist is.
Het scharnierverlies voor een enkel voorbeeld wordt gedefinieerd als:
verlies = max(0, 1 – y * f(x))
waarbij y het ware label is (ofwel -1 of 1) en f(x) de voorspelde uitvoer van het model is. De voorspelde uitvoer is het inproduct tussen de invoerkenmerken en de modelgewichten, plus een biasterm.
Het scharnierverlies wordt gebruikt in SVM's omdat het een convexe functie is die voorspellingen bestraft die niet zelfverzekerd en correct zijn. Het scharnierverlies is gelijk aan nul wanneer het voorspelde label correct is, en neemt toe naarmate het vertrouwen in het onjuiste label toeneemt. Dit moedigt het model aan om vertrouwen te hebben in zijn voorspellingen, maar ook om voorzichtig te zijn en geen voorspellingen te doen die te ver van het ware label verwijderd zijn.
Geavanceerde interviewvragen
Q83. Wat gebeurt er als we het aantal buren in KNN vergroten?
Ans. Als u het aantal buren verhoogt tot een zeer grote waarde in KNN, wordt de classificator steeds conservatiever en wordt de beslissingsgrens vloeiender en vloeiender. Dit kan helpen om overfitting te verminderen, maar het kan er ook voor zorgen dat de classificator minder gevoelig is voor subtiele patronen in de trainingsgegevens. Een grotere waarde van k zal leiden tot een minder complex model, dat minder vatbaar is voor overfitting, maar eerder voor onderfitting.
Om overfitting of underfitting te voorkomen, is het daarom belangrijk om een geschikte waarde van k te kiezen die een balans vindt tussen complexiteit en eenvoud. Het is meestal beter om een reeks waarden voor het aantal buren te proberen en te zien welke het beste werkt voor een bepaalde dataset.
Q84. Wat gebeurt er in de beslisboom als de maximale diepte wordt vergroot?
Ans. Het vergroten van de maximale diepte van een beslissingsboom zal de complexiteit van het model vergroten en het vatbaarder maken voor overfitting. Als u de maximale diepte van een beslissingsboom vergroot, kan de boom complexere en genuanceerdere beslissingen nemen, waardoor het model beter kan aansluiten bij de trainingsgegevens. Als de boom echter te diep is, kan deze te gevoelig worden voor de specifieke patronen in de trainingsgegevens en niet goed generaliseren naar ongeziene gegevens.
Q85. Wat is het verschil tussen extra bomen en willekeurige bossen?
Ans. Het belangrijkste verschil tussen de twee algoritmen is hoe de beslisbomen zijn opgebouwd.
In een Willekeurig bos, worden de beslissingsbomen geconstrueerd met behulp van bootstrap-voorbeelden van de trainingsgegevens en een willekeurige subset van de functies. Dit resulteert erin dat elke boom wordt getraind op een iets andere set gegevens en kenmerken, wat leidt tot een grotere diversiteit aan bomen en een lagere variantie.
In een Extra Trees-classificatie worden de beslissingsbomen op een vergelijkbare manier geconstrueerd, maar in plaats van een willekeurige subset van de kenmerken bij elke splitsing te selecteren, selecteert het algoritme de beste splitsing uit een willekeurige subset van de kenmerken. Dit resulteert in een groter aantal willekeurige splitsingen en een hogere mate van willekeur, wat leidt tot een lagere vertekening en een hogere variantie.
Q86. Wanneer one-hot codering en labelcodering gebruiken?
Ans. One-hot codering en labelcodering zijn twee verschillende technieken die kunnen worden gebruikt om categorische variabelen als numerieke waarden te coderen. Ze worden vaak gebruikt in machine learning-modellen als een voorbewerkingsstap voordat het model aan de gegevens wordt aangepast.
One-hot codering wordt meestal gebruikt wanneer u categorische variabelen hebt die geen ordinale relatie hebben, dwz de categorieën hebben geen natuurlijke volgorde of rangorde. One-hot codering creëert nieuwe binaire kolommen voor elke categorie, met een waarde van 1 die de aanwezigheid van de categorie aangeeft en een waarde van 0 die de afwezigheid van de categorie aangeeft. Dit kan handig zijn als u de uniciteit van elke categorie wilt behouden en wilt voorkomen dat het model ordinale relaties tussen de categorieën aanneemt.
Aan de andere kant wordt labelcodering meestal gebruikt wanneer u categorische variabelen hebt die wel een ordinale relatie hebben, dwz de categorieën hebben een natuurlijke volgorde of rangorde. Labelcodering wijst een unieke integerwaarde toe aan elke categorie, en de integerwaarden worden meestal bepaald door de natuurlijke volgorde van de categorieën. Dit kan handig zijn als u de ordinale relaties tussen de categorieën wilt behouden en het model deze informatie wilt laten gebruiken.
Over het algemeen is het het beste om one-hot codering te gebruiken voor nominale gegevens (dwz gegevens die geen inherente volgorde hebben) en labelcodering voor ordinale gegevens (dwz gegevens die een inherente volgorde hebben). De keuze tussen one-hot encoding en label encoding kan echter ook afhangen van de specifieke vereisten van uw model en de kenmerken van uw dataset.
Q87. Wat is het probleem met het gebruik van labelcodering voor nominale gegevens?
Ans. Labelcodering is een methode voor het coderen van categorische variabelen als numerieke waarden, wat in bepaalde situaties nuttig kan zijn. Er zijn echter enkele potentiële problemen waar u rekening mee moet houden bij het gebruik van labelcodering voor nominale gegevens.
Een probleem met labelcodering is dat het een ordinale relatie kan creëren tussen categorieën waar die niet bestaat
Als u een categorische variabele hebt met drie categorieën: "rood", "groen" en "blauw", en u labelcodering toepast om deze categorieën toe te wijzen aan de numerieke waarden 0, 1 en 2, kan het model ervan uitgaan dat de categorie " groen" zit op de een of andere manier "tussen" de categorieën "rood" en "blauw". Dit kan een probleem zijn als uw model ervan uitgaat dat de categorieën onafhankelijk van elkaar zijn.
Een ander probleem met labelcodering is dat het tot onverwachte resultaten kan leiden als u een onevenwichtige dataset heeft. Als de ene categorie bijvoorbeeld veel vaker voorkomt dan de andere, krijgt deze een veel lagere numerieke waarde toegewezen, waardoor het model er mogelijk minder belang aan hecht dan het verdient.
Q88. Wanneer kan one-hot encoding een probleem zijn?
Ans. One-hot codering kan in bepaalde situaties een probleem zijn omdat het een groot aantal nieuwe kolommen in de gegevensset kan creëren, waardoor het moeilijker kan worden om met de gegevens te werken en mogelijk kan leiden tot overfitting.
One-hot-codering maakt een nieuwe binaire kolom voor elke categorie in een categorische variabele. Als u een categorische variabele met veel categorieën heeft, kan dit resulteren in een zeer groot aantal nieuwe kolommen.
Een ander probleem met one-hot encoding is dat het kan leiden tot overfitting, vooral als je een kleine dataset en een groot aantal categorieën hebt. Wanneer u voor elke categorie veel nieuwe kolommen maakt, vergroot u in feite het aantal functies in de dataset. Dit kan leiden tot overfitting, omdat het model de trainingsgegevens wel kan onthouden, maar niet goed generaliseert naar nieuwe gegevens.
Ten slotte kan one-hot-codering ook een probleem zijn als u in de toekomst nieuwe categorieën aan de dataset moet toevoegen. Als u de bestaande categorieën al eenmalig hebt gecodeerd, moet u voorzichtig zijn om ervoor te zorgen dat de nieuwe categorieën worden toegevoegd op een manier die geen verwarring veroorzaakt of tot onverwachte resultaten leidt.
Q89. Wat kan een geschikte coderingstechniek zijn als er honderden categorische waarden in een kolom staan?
Ans. Een paar technieken kunnen worden gebruikt wanneer we honderden kolommen in een categorische variabele hebben.
Frequentiecodering: hierbij wordt elke categorie vervangen door de frequentie van die categorie in de dataset. Dit kan goed werken als de categorieën een natuurlijke ordinale relatie hebben op basis van hun frequentie.
Doelcodering: hierbij wordt elke categorie vervangen door het gemiddelde van de doelvariabele voor die categorie. Dit kan effectief zijn als de categorieën een duidelijke relatie hebben met de doelvariabele.
Q90. Wat zijn de bronnen van willekeur in willekeurig bos?
Ans. Willekeurige forests zijn een ensemble-leermethode waarbij meerdere beslissingsbomen worden getraind op verschillende subsets van de gegevens en het gemiddelde wordt genomen van de voorspellingen van de individuele bomen om een definitieve voorspelling te doen. Er zijn verschillende bronnen van willekeur bij het trainen van een willekeurig bos:
Bootstrap-voorbeelden: bij het trainen van elke beslissingsboom maakt het algoritme een bootstrap-voorbeeld van de gegevens door steekproeven te nemen met vervanging van de oorspronkelijke trainingsset. Dit betekent dat sommige gegevenspunten meerdere keren in de steekproef worden opgenomen, terwijl andere helemaal niet worden opgenomen. Hierdoor ontstaat er variatie tussen de trainingssets van verschillende bomen.
Willekeurige functieselectie: bij het trainen van elke beslissingsboom selecteert het algoritme een willekeurige subset van de functies die bij elke splitsing in overweging moeten worden genomen. Dit betekent dat verschillende bomen rekening houden met verschillende sets kenmerken, wat leidt tot variatie in de geleerde bomen.
Willekeurige drempelselectie: bij het trainen van elke beslissingsboom selecteert het algoritme een willekeurige drempel voor elke functie om de optimale splitsing te bepalen. Dit betekent dat verschillende bomen zich splitsen op verschillende drempels, wat leidt tot variatie in de aangeleerde bomen.
Door deze bronnen van willekeur te introduceren, kunnen willekeurige forests overfitting verminderen en de generalisatieprestaties verbeteren in vergelijking met een enkele beslissingsboom.
Q91. Hoe beslis je op welk kenmerk je wilt splitsen bij elk knooppunt van de boom?
Ans. Bij het trainen van een beslissingsboom moet het algoritme de functie kiezen om op te splitsen bij elk knooppunt van de boom. Er zijn verschillende strategieën die kunnen worden gebruikt om te beslissen op welke functie moet worden gesplitst, waaronder:
Hebzuchtig zoeken: het algoritme selecteert bij elke stap de functie die een splitsingscriterium maximaliseert (zoals informatiewinst of Gini-onzuiverheid).
Willekeurig zoeken: het algoritme selecteert bij elke stap willekeurig de functie om op te splitsen.
Uitputtend zoeken: het algoritme houdt rekening met alle mogelijke splitsingen en selecteert degene die het splitsingscriterium maximaliseert.
Voorwaarts zoeken: het algoritme begint met een lege boom en voegt splitsingen een voor een toe, waarbij bij elke stap de splitsing wordt geselecteerd die het splitsingscriterium maximaliseert.
Achterwaarts zoeken: het algoritme begint met een volgroeide boom en snoeit één voor één, waarbij de te verwijderen splitsing wordt geselecteerd die resulteert in de kleinste afname van het splitsingscriterium.
Q92. Wat is de betekenis van C in SVM?
Ans. In het Support Vector Machine (SVM)-algoritme is de parameter C een hyperparameter die de afweging regelt tussen het maximaliseren van de marge en het minimaliseren van de misclassificatiefout.
Intuïtief bepaalt C de straf voor het verkeerd classificeren van een trainingsvoorbeeld. Een kleinere waarde van C betekent een grotere straf voor misclassificatie, en daarom zal het model proberen alle trainingsvoorbeelden correct te classificeren (zelfs als dit een kleinere marge betekent). Aan de andere kant betekent een grotere waarde van C een kleinere straf voor verkeerde classificatie, en daarom zal het model proberen de marge te maximaliseren, zelfs als dit resulteert in een verkeerde classificatie van sommige trainingsvoorbeelden.
In de praktijk kun je C zien als het regelen van de flexibiliteit van het model. Een kleinere waarde van C zal resulteren in een meer rigide model dat vatbaarder kan zijn voor onderfitting, terwijl een grotere waarde van C zal resulteren in een flexibeler model dat vatbaarder kan zijn voor overfitting.
Daarom moet de waarde van C zorgvuldig worden gekozen met behulp van kruisvalidatie, om de wisselwerking tussen bias en variantie in evenwicht te brengen en goede generalisatieprestaties op ongeziene gegevens te bereiken.
Q93. Hoe beïnvloeden c en gamma overfitting bij SVM?
Ans. In Support Vector Machines (SVM's) worden de regularisatieparameter C en de kernelparameter gamma gebruikt om overfitting te beheersen.
C is de straf voor misclassificatie. Een kleinere waarde van C betekent een grotere straf voor misclassificatie, wat betekent dat het model conservatiever zal zijn en zal proberen misclassificatie te voorkomen. Dit kan leiden tot een model dat minder vatbaar is voor overfitting, maar kan ook resulteren in een model dat te conservatief is en slechte generalisatieprestaties levert.
Gamma is een parameter die de complexiteit van het model bepaalt. Een kleinere waarde van gamma betekent een complexer model, wat kan leiden tot overfitting. Een grotere waarde van gamma betekent een eenvoudiger model, wat overfitting kan helpen voorkomen, maar ook kan resulteren in een model dat te eenvoudig is om de onderliggende relaties in de gegevens nauwkeurig vast te leggen.
Over het algemeen is het vinden van de optimale waarden voor C en gamma een wisselwerking tussen vertekening en variantie, en het is vaak nodig om verschillende waarden uit te proberen en de prestaties van het model op een validatieset te evalueren om de beste waarden voor deze parameters te bepalen.
Q94. Hoe kies je het aantal modellen dat je wilt gebruiken in een Boosting- of Bagging-ensemble?
Ans. Het aantal modellen dat in een ensemble moet worden gebruikt, wordt meestal bepaald door de afweging tussen prestatie en rekenkosten. Als algemene vuistregel geldt dat het verhogen van het aantal modellen de prestaties van het ensemble zal verbeteren, maar dit gaat ten koste van hogere rekenkosten.
In de praktijk wordt het aantal modellen bepaald door kruisvalidatie die wordt gebruikt om het optimale aantal modellen te bepalen op basis van de gekozen evaluatiemaatstaf.
Q95. In welke scenario's hebben boosting en bagging de voorkeur boven afzonderlijke modellen?
Ans. Zowel boosting als bagging hebben over het algemeen de voorkeur in scenario's waarin de individuele modellen een hoge variantie of hoge bias hebben en het doel is om de algehele prestaties van het model te verbeteren. Bagging wordt over het algemeen gebruikt om de variantie van een model te verminderen, terwijl boosting wordt gebruikt om vertekening te verminderen en de generalisatiefout van het model te verbeteren. Beide methoden zijn ook handig bij het werken met modellen die gevoelig zijn voor de trainingsgegevens en een grote kans op overfitting hebben.
Q96. Kunt u de ROC-curve en AUC-score uitleggen en hoe deze worden gebruikt om de prestaties van een model te evalueren?
Ans. Een ROC-curve (Receiver Operating Characteristic) is een grafische weergave van de prestaties van een binair classificatiemodel. Het plot de True Positive Rate (TPR) tegen de False Positive Rate (FPR) bij verschillende drempels. AUC (Area Under the Curve) is het gebied onder de ROC-curve. Het geeft een enkel getal dat de algehele prestaties van het model vertegenwoordigt. AUC is nuttig omdat het rekening houdt met alle mogelijke drempels, niet alleen met een enkel punt op de ROC-curve.
Q97. Hoe benader je het instellen van de drempel in een binair classificatieprobleem als je de precisie en herinnering zelf wilt aanpassen?
Ans. Bij het instellen van de drempel in een binair classificatieprobleem is het belangrijk om rekening te houden met de wisselwerking tussen precisie en herinnering. Precisie is het aandeel van echt positieve voorspellingen van alle positieve voorspellingen, terwijl herinnering het aandeel van echt positieve voorspellingen is van alle daadwerkelijk positieve gevallen.
Een benadering voor het aanpassen van precisie en herinnering is om eerst een model te trainen en vervolgens de prestaties ervan op een validatieset te evalueren. De validatieset moet een vergelijkbare verdeling van positieve en negatieve gevallen hebben als de testset op het model dat wordt ingezet.
Vervolgens kunt u een verwarringsmatrix gebruiken om de prestaties van het model te visualiseren en de huidige drempel te identificeren die wordt gebruikt om voorspellingen te doen. Een verwarringsmatrix toont het aantal terecht-positieve, fout-positieve, terecht-negatieve en fout-negatieve voorspellingen die het model doet.
Van daaruit kunt u de drempel aanpassen om de balans tussen precisie en terugroepen te wijzigen. Het verhogen van de drempel verhoogt bijvoorbeeld de precisie, maar vermindert de herinnering. Aan de andere kant zal het verlagen van de drempel de herinnering vergroten en de precisie verminderen.
Het is ook belangrijk om rekening te houden met de specifieke use case en de kosten van valse negatieven en valse positieven. In bepaalde toepassingen, zoals medische diagnose, kan het belangrijker zijn om een hoge herinnering te hebben (dwz geen echte positieve gevallen te missen), zelfs als dat betekent dat een lagere precisie moet worden geaccepteerd. In andere gevallen, zoals bij het opsporen van fraude, kan het belangrijker zijn om hoge precisie te hebben (dwz geen legitieme transacties als frauduleus te markeren), zelfs als dat betekent dat een lagere terugroeping moet worden geaccepteerd.
Q98. Wat is het verschil tussen LDA (Linear Discriminant Analysis) en PCA (Principal Component Analysis)?
Ans. LDA (Linear Discriminant Analysis) en PCA (Principal Component Analysis) zijn beide lineaire transformatietechnieken die worden gebruikt om de dimensionaliteit van een dataset te verminderen. Ze worden echter voor verschillende doeleinden gebruikt en werken op verschillende manieren.
PCA is een techniek zonder toezicht, wat betekent dat het wordt gebruikt om patronen in gegevens te vinden zonder verwijzing naar bekende labels. Het doel van PCA is om de richtingen (hoofdcomponenten) in de gegevens te vinden die verantwoordelijk zijn voor de grootste hoeveelheid variantie. Deze richtingen zijn zo gekozen dat ze onderling orthogonaal (loodrecht) op elkaar staan, en de eerste richting is verantwoordelijk voor de grootste variantie, de tweede richting voor de op een na grootste variantie, enzovoort. Zodra de hoofdcomponenten zijn gevonden, kunnen de gegevens worden geprojecteerd op een lager-dimensionale subruimte die wordt gedefinieerd door deze componenten, wat resulteert in een nieuwe, lager-dimensionale representatie van de gegevens.
LDA daarentegen is een gecontroleerde techniek en wordt gebruikt om een lager-dimensionale subruimte te vinden die de scheiding tussen verschillende gegevensklassen maximaliseert. LDA wordt vaak gebruikt als een dimensionaliteitsreductietechniek voor classificatieproblemen, bijvoorbeeld bij gezichtsherkenning, irisherkenning en vingerafdrukherkenning. Het doel van LDA is om een projectie van de data te vinden die de klassen zo goed mogelijk van elkaar scheidt.
Q99. Hoe verhoudt het Naive Bayes-algoritme zich tot andere begeleide leeralgoritmen?
Ans. Naïeve Bayes is een eenvoudig en snel algoritme dat goed werkt met hoog-dimensionale data en kleine trainingssets. Het presteert ook goed op datasets met categorische variabelen en ontbrekende gegevens, die vaak voorkomen bij veel problemen in de echte wereld. Het is goed voor tekstclassificatie, spamfiltering en sentimentanalyse. Vanwege de aanname van onafhankelijkheid tussen kenmerken, presteert het echter niet goed voor problemen met een hoge correlatie tussen kenmerken. Het slaagt er ook vaak niet in om de interacties tussen functies vast te leggen, wat kan resulteren in slechte prestaties op sommige datasets. Daarom wordt het vaak gebruikt als basislijn of startpunt, waarna andere algoritmen zoals SVM en Random Forest kunnen worden gebruikt om de prestaties te verbeteren.
Q100. Kun je het concept van de "kerneltruc" en de toepassing ervan in Support Vector Machines (SVM's) uitleggen?
Ans. De kerneltruc is een techniek die wordt gebruikt om de invoergegevens in SVM's te transformeren naar een hoger-dimensionale kenmerkruimte, waar ze lineair scheidbaar worden. De kerneltruc werkt door het standaard inproduct in de invoerruimte te vervangen door een kernelfunctie, die het inproduct in een hoger-dimensionale ruimte berekent zonder de coördinaten van de gegevens in die ruimte te hoeven berekenen. Hierdoor kunnen SVM's niet-lineair scheidbare gegevens verwerken door deze toe te wijzen aan een hoger-dimensionale ruimte waar ze lineair scheidbaar worden. Algemene kernelfuncties die in SVM's worden gebruikt, zijn onder meer de polynoomkernel, de radiale basisfunctie (RBF) -kernel en de sigmoïde kernel.
Conclusie
In dit artikel hebben we verschillende data science-interviewvragen behandeld over onderwerpen als KNN, lineaire regressie, naïeve baaien, willekeurig bos, enz.
Het werk van datawetenschappers is niet gemakkelijk, maar het geeft voldoening en er zijn veel vacatures. Deze data science-interviewvragen kunnen je een stap dichter bij het vinden van je ideale baan brengen. Zet je dus schrap voor de ontberingen van sollicitatievragen en blijf op de hoogte van de basisprincipes van datawetenschap.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/01/top-100-data-science-interview-questions/

