유단, 해리 포스터, 톰 피츠패트릭
EDA 4.0 시대에 오신 것을 환영합니다. 여기서 우리는 인공 지능의 힘으로 구동되는 전자 설계 자동화의 혁명적인 변화를 목격하고 있습니다. EDA의 역사는 더 빠른 설계 반복, 생산성 향상 및 복잡한 전자 시스템의 개발을 촉진한 중요한 기술 발전으로 표시되는 뚜렷한 기간으로 구분할 수 있습니다.
특히 EDA 1.0의 출현은 1970년대 초 캘리포니아 버클리 대학에서 SPICE(집적 회로 강조 시뮬레이션 프로그램)를 도입하여 회로 설계에 혁명을 일으켰습니다.
1980년대와 1990년대 초반에 EDA 2.0은 효율적인 배치 및 경로 알고리즘 개발의 결과로 등장했습니다. RTL 시대라고도 하는 이 기간은 RTL 설계가 레지스터 전송 수준에서 회로 설명을 가능하게 하여 시뮬레이션 성능을 향상시키면서 게이트 수준 설계에서 상위 수준 추상화로의 전환을 목격했습니다. 이 기간은 논리 합성의 도입으로 중요한 이정표를 목격했습니다.
1990년대 후반과 2000년대 초반에 시스템 온 칩(SoC) 설계의 부상은 EDA 3.0으로 이어진 중추적인 순간을 기록했습니다. 이 시대는 설계 재사용 방법론과 결합된 IP 개발 경제의 출현을 목격했습니다. EDA 도구 및 표준은 SoC의 설계, 확인 및 유효성 검사를 지원하기 위해 개발되어 엔지니어가 SoC급 설계의 증가하는 복잡성을 관리할 수 있도록 합니다.
여러 측면에서 EDA 4.0은 부분적으로 제조 부문의 디지털화로 인해 회사가 제품을 제조, 개선 및 유통하는 방식을 빠르게 변화시키는 산업 혁명 4.0의 광범위한 추세와 일치합니다. EDA 4.0은 클라우드 컴퓨팅과 인공 지능(AI) 및 기계 학습(ML) 기능의 잠재력을 활용하여 지능적이고 연결된 장치의 설계를 용이하게 하도록 진화했습니다.


EDA 도구는 이제 기계 학습, 가상 프로토타이핑, 디지털 트윈 및 시스템 수준 설계 방법론을 통합하여 EDA 제품에 대한 검증 가속화, 자동화된 검증 워크플로우 및 향상된 검증 정확도를 제공합니다. EDA 4.0 시대는 최적화된 제품 성능, 출시 기간 단축, 간소화된 개발 및 제조 프로세스를 약속합니다.
이 기사에서는 기능 검증을 위해 특별히 맞춤화된 ML 솔루션의 최신 구현에 대해 자세히 살펴봅니다. 우리는 ML로 해결할 수 있는 문제를 탐구하고 이 영역과 관련된 새로운 기술과 알고리즘을 제시합니다.
기능 검증의 ML 주제
표 1은 프로그래밍 코드 검증의 일반적인 관점에서 모든 기능 검증 주제를 포함할 때 기능 검증에 적용할 수 있는 주제 및 하위 주제를 요약한 것입니다. 기울임꼴 텍스트는 다른 일반 설문 조사 간행물에서 탐색되지 않은 하위 주제를 나타냅니다.
표 1: 기능 검증에서 ML 애플리케이션의 주제.

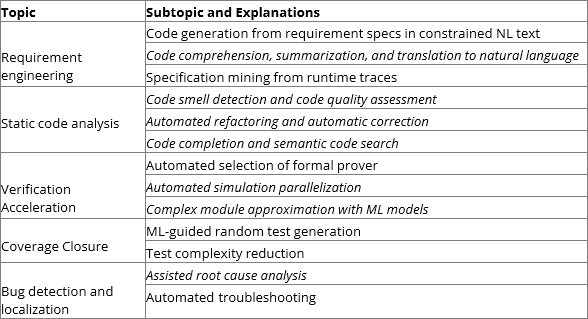
요구 공학
기능 검증에서 요구 사항 엔지니어링은 검증 요구 사항을 정의, 문서화 및 유지 관리하는 프로세스이며 기본 IC 설계의 우수한 품질을 보장하는 데 중요합니다.
요구 사항 정의에는 모호한 자연어(NL) 검증 목표를 형식적이고 정확하게 검증 사양으로 변환하는 작업이 포함됩니다. 번역 품질은 검증의 정확성을 직접적으로 나타냅니다. 전통적으로 이 프로세스는 힘들고 품질을 보장하기 위해 여러 번의 수동 교정 반복으로 상당한 설계 주기를 소비합니다.
번역을 자동화하기 위해 두 그룹의 고전적인 접근 방식이 제안되었습니다. 접근 방식의 한 그룹은 사양 초안 작성을 공식화하기 위해 CNL(제약된 자연어)을 도입한 다음 템플릿 기반 번역 엔진을 도입하는 것입니다. 이 접근 방식은 강력한 CNL 구문 및 포괄적인 컴파일러/템플릿 시스템을 개발하여 기능 검증에서 발생하는 대부분의 요구 사항을 해결할 수 있을 만큼 충분히 강력한지 확인하는 데 상당한 선행 투자가 필요합니다. 또한 개발자에게 추가 언어 학습 부담을 주어 아이디어가 널리 받아들여지는 것을 방해합니다.
다른 그룹은 고전적인 자연어 처리(NLP)를 활용하여 NL 사양을 구문 분석하고 관련 핵심 요소를 추출하여 정식 사양을 공식화합니다.
NL 도메인에서 ML 번역의 발전으로 완전 자동화된 기계 번역이 상업적으로 실현 가능해졌으며 때로는 평균적인 인간 번역가의 성능을 능가합니다. SVA(SystemVerilog Assertions), PSL(Property Specification Language) 또는 기타 언어의 검증 사양으로 NL 사양을 직접 변환하기 위해 최대 수십억 개의 매개변수가 있는 대규모 훈련된 NL 모델을 활용할 수 있다는 희망을 불러일으켰습니다. 종단 간 번역을 성공적으로 수행하려는 여러 시도가 관찰되었지만 프로덕션 준비가 된 것은 없습니다. 이 접근 방식의 주요 장애물은 NL 사양과 공식 번역을 쌍으로 하는 사용 가능한 교육 데이터 세트가 부족하다는 것입니다. 가장 광범위한 데이터 세트는 약 100개의 문장 쌍에 불과합니다.. 일상적으로 수백만 또는 수십억 개의 문장 쌍으로 제공되는 NL 동료와 비교할 때 그 수는 미미합니다.
요구 사항 정의와 달리 요약은 코드를 보고 사람이 이해할 수 있는 NL 요약으로 변환합니다. 개발자가 덜 이상적으로 유지 관리되는 코드를 읽거나 복잡한 논리를 이해하는 데 도움이 됩니다. 이상적으로 구현된 코드 요약은 인라인 문서를 코드 블록에 삽입하거나 별도의 문서를 생성할 수 있습니다. 이를 통해 코드의 유지 관리 및 문서화가 크게 향상될 수 있습니다.
코드 요약에 ML을 적용하는 것은 Python 및 JavaScript와 같은 보다 대중적인 컴퓨터 언어에서 실험되었습니다. 여러 접근 방식 그룹이 다양한 수준의 성공을 실험했습니다. 정보 검색(IR) 기반 접근 방식은 소스 코드에 NLP를 적용하고 기존 요약이 있는 유사한 코드를 찾는 데 중점을 둡니다. 이 접근 방식 그룹은 요약이 포함된 기존 코드의 품질에 크게 의존합니다. 많은 기존 코드 리포지토리를 쉽게 사용할 수 있는 가까운 조직 내에서만 사용할 수 있습니다. 휴리스틱 기반 접근법은 대신 모듈의 정의에서 식별된 휴리스틱을 기반으로 특정 규칙을 정의하려고 시도합니다. 예를 들어 기본 읽기/쓰기 명령줄의 많은 하위 모듈이 있는 모듈은 메모리 모듈로 간주될 수 있습니다. 따라서 메모리 모듈에 대해 미리 정의된 패턴에서 요약을 구성할 수 있습니다.
이 글을 쓰는 시점에서 IC 설계 검증의 코드 요약은 아직 어떤 문헌에도 보고되지 않았습니다. 연구 커뮤니티에서 아직 확인되지 않은 IC 설계 및 검증에서 다른 언어의 성공이 실현될 수 있다고 낙관하는 것이 합리적입니다. 특히, 교차 언어 모델의 최근 발전은 다른 프로그래밍 언어에서 배운 지식을 IC 설계로 이전하는 데 도움이 될 수 있습니다. 그러나 코드 요약에 대한 ML의 일반적인 문제 외에도 IC 설계 및 검증 코드의 본질적인 시간적 병렬성은 다른 프로그래밍 언어에서는 일반적이지 않은 문제를 나타낼 수 있습니다.
사양 마이닝은 오랫동안 소프트웨어 엔지니어링 주제였습니다. 사양을 수동으로 작성하는 대신 DUT(테스트 대상 설계) 실행에서 간접적으로 사양을 추출합니다. ML은 시뮬레이션 추적에서 반복 패턴을 마이닝하는 데 적용할 수 있습니다. 시뮬레이션 기반 커버리지 폐쇄 또는 정식 검증을 자동화하는 데 도움이 될 수 있습니다. 일반적으로 반복되는 패턴이 DUT의 예상 동작일 수 있다고 가정합니다. 또는 추적에서 거의 발생하지 않는 이벤트 패턴은 이상으로 간주될 수 있습니다. 따라서 진단 및 디버깅 목적으로 사용할 수 있습니다.
ML은 복잡한 시스템의 시간 데이터를 사용할 수 있는 많은 도메인에서 패턴 검색 및 이상 감지에 적용되었습니다. Azeem et al. ML을 사용하여 프로토콜 추적을 관찰하고 프로토콜의 가능한 문제 구현을 찾아 공식 사양을 발견하는 일반적인 소프트웨어 엔지니어링 접근 방식을 제안합니다. 성공적인 실험은 ML을 사용한 사양 마이닝에서 흥미로운 후속 연구 프로젝트에 영감을 주었습니다.
정적 코드 분석
IC 개발 단계에 따라 버그 수정 비용이 기하급수적으로 증가함에 따라 정적 코드 분석은 설계 개발 초기 단계에서 코드 품질과 유지 관리성을 개선할 수 있는 매력적인 옵션을 제공합니다.
코드 스멜은 소스 코드의 최적이 아닌 디자인 패턴을 의미하며, 이는 구문 및 의미적으로 정확할 수 있지만 모범 사례를 위반하고 코드 유지 관리 가능성을 저하시킬 수 있습니다. 특정 예는 동일한 기능이 프로젝트 또는 전체 코드 기반에서 여러 번 구현되는 코드 복제입니다. 일부 복사본에는 상대적으로 짧은 기간에 특정 버그가 수정될 수 있지만 다른 복사본에서는 동일한 버그가 눈에 띄지 않습니다.
클래식 코드 냄새 감지는 정의된 휴리스틱 규칙을 사용하여 소스 코드의 패턴을 식별합니다. 정적 코드 분석 도구에서 이러한 규칙과 메트릭을 수동으로 개발하는 대신 코드 냄새를 식별하기 위해 사용 가능한 대량의 소스 코드에서 ML 기반 접근 방식을 학습할 수 있습니다. 연구에 따르면 ML을 사용한 냄새 감지는 범용 코드 냄새 감지 및 패턴 구현 노력을 크게 줄일 수 있습니다. 결과 냄새 점수는 코드 품질 평가에 사용할 수 있으며 개발자가 제품 품질을 지속적으로 개선하는 데 도움이 됩니다. 또한 ML 기반 코드 리팩토링은 코드 냄새 개선 또는 일부 후보 변경에 대한 유용한 힌트를 제공할 수 있습니다.
기능 검증에 ML을 적용하는 것은 아직 눈에 띄지 않으며 대규모 교육 데이터 세트를 사용할 수 없기 때문에 기존 연구가 이 솔루션의 잠재력을 완전히 활용하지 못했습니다.
IC 설계 작업을 하는 개발자는 적절한 도구가 제공될 때 가장 생산적일 수 있습니다. 간단한 코드 완성은 최신 통합 개발 환경(IDE)의 표준 기능입니다. 그러나 딥 러닝과 관련된 보다 진보된 기술이 제안되었고 빠르게 발전하고 있습니다. 이제 많은 대규모 오픈 소스 코드 리포지토리의 수십억 개의 매개 변수로 ANN을 교육하여 개발자의 구현 의도 또는 컨텍스트에서 코드 스니펫에 대한 합리적인 권장 사항을 제공할 수 있습니다.
ML은 또한 NL 쿼리로 관련 코드를 검색할 수 있는 시맨틱 코드 검색을 통해 IC 개발자가 생산성을 유지하는 데 도움이 될 수 있습니다. 코드는 일반적으로 다양한 약어와 전문 용어로 가득 차 있기 때문에 의미론적 검색은 주요 변수, 함수 또는 모듈 이름의 철자를 정확하게 입력하지 않고도 관련 코드 스니펫을 찾는 데 더 효과적일 수 있습니다. 기존의 많은 검색 엔진의 시맨틱 검색과 유사하지만 시맨틱 코드 검색은 모호한 개념을 가진 축약되고 고도로 기술적인 코드를 찾는 데 도움이 될 수 있습니다. 최상의 모델의 평균 상호 순위는 이미 70%의 사용 가능한 점수를 달성할 수 있습니다.
이론적으로 다른 프로그래밍 언어에 적용된 동일한 ML 기술을 IC 설계에 적용할 수 있지만 코딩 지원에 대한 연구는 아직 발표되지 않았습니다.
검증 가속화
최근 설문 조사에 따르면 기능 검증은 여전히 IC 설계에서 가장 시간이 많이 걸리는 단계이며 기능 및 논리 오류는 여전히 respin의 가장 중요한 원인입니다. 기능 검증 속도의 향상은 IC 설계의 품질과 생산성에 상당한 영향을 미칩니다. ML은 가속화를 위해 공식 및 시뮬레이션 기반 검증에 모두 사용되었습니다.
형식 검증은 형식적인 수학적 알고리즘을 사용하여 설계의 정확성을 증명합니다. 최신 형식 검증 오케스트레이션은 형식 알고리즘을 사용하여 크기, 유형 및 복잡성이 다른 디자인을 대상으로 합니다. 경험과 휴리스틱은 개발자가 특정 문제에 대해 라이브러리에서 가장 적합한 알고리즘을 선택하는 데 도움이 될 수 있습니다.
통계적 방법으로서 ML은 공식적인 검증 문제를 직접 해결할 수 없습니다. 그러나 공식적인 오케스트레이션에 매우 도움이 되는 것으로 입증되었습니다. 컴퓨팅 리소스 예측 및 문제 해결 가능성을 통해 공식 솔버가 이러한 리소스를 가장 잘 사용하도록 예약하여 컴퓨팅 리소스 소비가 적은 가장 유망한 솔버를 먼저 예약하여 검증 시간을 단축할 수 있습니다. Ada-boost 의사 결정 트리 기반 분류기는 기준 오케스트레이션에서 해결된 인스턴스의 비율을 95%에서 97%로 개선할 수 있으며 평균 속도는 1.85입니다. 또 다른 실험에서는 평균 32% 오류로 공식 검증의 리소스 요구 사항을 예측할 수 있었습니다. 반복적으로 기능 엔지니어링을 적용하여 DUT, 속성 및 형식 제약 조건에서 기능을 신중하게 선택한 다음 리소스 요구 사항 예측을 위한 다중 선형 회귀 모델을 교육하는 데 사용합니다.
공식 검증과 달리 시뮬레이션 기반 검증은 일반적으로 설계의 완전한 정확성을 보장할 수 없습니다. 대신, 특정 무작위 또는 고정 패턴 입력 자극이 적용된 테스트 벤치 아래에 디자인을 놓고 출력을 참조 출력과 비교하여 디자인의 동작이 예상되는지 확인합니다. 시뮬레이션은 기능 검증의 빵과 버터이지만 시뮬레이션 기반 검증도 검증 시간이 길어질 수 있습니다. 복잡한 설계의 검증을 완료하는 데 몇 주가 걸리는 것은 드문 일이 아닙니다.
논의되고 실험되고 있는 유망한 아이디어는 ML을 사용하여 복잡한 시스템의 동작을 모델링하고 예측하는 것입니다. Universal Approximation Theorem은 적어도 하나의 숨겨진 레이어가 있는 피드포워드 ANN인 MLP(다층 퍼셉트론)가 임의의 정확도로 모든 연속 함수를 근사화할 수 있음을 증명합니다. ANN의 특수한 형태인 정규화된 반복 신경망(RNN)은 메모리가 있는 모든 동적 시스템에 근접하는 것으로 입증되었습니다. 고급 ML 가속기 하드웨어를 통해 ANN은 일부 IC 설계 모듈의 동작을 모델링하여 시뮬레이션을 가속화할 수 있습니다. AI 가속기의 기능과 ML 모델의 복잡성에 따라 상당한 가속화가 달성될 수 있습니다.
테스트 생성 및 커버리지 폐쇄
수동으로 정의된 테스트 패턴 외에도 시뮬레이션 기반 검증에 사용되는 표준 기술에는 무작위 테스트 생성 및 그래프 기반 지능형 테스트벤치 자동화가 포함됩니다. 커버리지 클로저의 "롱테일" 특성으로 인해 약간의 효율성 향상만으로도 시뮬레이션 시간이 크게 단축될 수 있습니다. 기능 검증에 ML을 적용하는 것에 대한 많은 연구가 이 영역에 초점을 맞췄습니다.
광범위한 ML 연구는 무작위 테스트 생성보다 더 잘할 수 있음을 보여주었습니다. 대부분의 연구에서는 DUT가 입력을 제어하고 출력을 모니터링할 수 있는 블랙 박스라고 가정하는 "블랙 박스 모델"을 사용합니다. 선택적으로 일부 테스트 포인트를 관찰할 수 있습니다. 이 연구는 DUT의 동작을 이해하려고 하지 않습니다. 대신 불필요한 테스트를 줄이는 데 중점을 둡니다. 그들은 다양한 ML 기술을 사용하여 과거 입력/출력/관찰 데이터에서 학습하여 무작위 테스트 생성기를 조정하거나 유용하지 않을 것 같은 테스트를 제거합니다. 최근 개발에서는 RL(강화 학습) 기반 모델을 사용하여 DUT의 출력에서 학습하고 캐시 컨트롤러에 대한 가장 가능성 있는 테스트를 예측했습니다. ML 모델에 주어진 보상이 FIFO 깊이인 경우 실험은 과거 결과에서 학습하고 여러 반복에서 전체 목표 FIFO 깊이에 도달할 수 있는 반면, 무작위 테스트 생성 기반 접근 방식은 여전히 1 이상을 달성하기 위해 고군분투하고 있습니다. 훨씬 세분화된 ML 아키텍처에서는 모든 커버 포인트에 대해 ML 모델을 교육해야 합니다. 테스트를 시뮬레이션할지, 폐기할지 또는 모델을 추가로 재훈련하는 데 사용할지 결정하는 데 도움이 되도록 삼항 분류기도 사용됩니다. 지원 벡터 머신(SVM), 랜덤 포레스트 및 심층 신경망은 모두 CPU 설계에서 실험되었습니다. 100배에서 3배 적은 테스트로 5% 커버리지를 닫을 수 있습니다. FSM 및 비-FSM 디자인에 대한 추가 실험에서는 지시된 시퀀스 생성에 비해 69% 및 72% 감소가 입증되었습니다. 그러나 이러한 결과의 대부분은 여전히 ML의 통계적 특성의 한계로 인해 어려움을 겪고 있습니다. ML 기반 CDG(coverage-directed test generation)에 대한 보다 포괄적인 검토에서는 여러 ML 모델 및 해당 실험 결과에 대한 개요를 제공합니다. 베이지안 네트워크 유전 알고리즘 및 유전 프로그래밍 접근 방식, Markov 모델, 데이터 마이닝 및 귀납적 논리 프로그래밍은 모두 다양한 수준의 성공을 거둔 실험입니다.
논의된 모든 접근 방식에서 ML 모델은 수집한 과거 데이터의 학습을 기반으로 예측을 할 수 있지만 미래를 예측할 수 있는 최소한의 기능(즉, 어떤 테스트가 발견되지 않은 테스트 목표를 달성하는 데 더 유망한 옵션일 수 있는지)을 가지고 있습니다. 이러한 종류의 정보는 아직 사용할 수 없기 때문에 그들이 할 수 있는 최선은 과거 테스트와 가장 관련 없는 테스트를 선택하는 것입니다. 또 다른 유망한 실험에서는 DUT를 화이트 박스로 간주하고 코드를 분석하여 제어/데이터 흐름 그래프(CDFG)로 변환하는 다른 접근 방식을 탐색했습니다. 사전 정의된 테스트 대상에 대한 테스트를 생성하기 위해 훈련된 그래프 신경망(GNN)에 대한 그래디언트 기반 검색이 사용됩니다. IBEX v1, v2 및 TPU에 대한 실험은 74% 커버 포인트로 학습했을 때 커버리지 예측에서 73%, 90% 및 50% 정확도를 달성했습니다. 몇 가지 추가 실험은 또한 사용된 그래디언트 검색 방법이 GNN 아키텍처에 둔감하다는 것을 확인합니다.
교육 데이터를 사용할 수 없기 때문에 이러한 ML 접근 방식의 대부분은 다른 유사한 설계의 사전 지식을 활용하지 않고 각 설계에서만 학습합니다.
버그 분석
버그 분석은 잠재적인 버그를 식별하고, 이를 포함하는 코드 블록을 지역화하고, 수정 제안을 제공하는 것을 목표로 합니다. 최근 설문 조사에 따르면 IC 검증은 설계에서와 거의 동일한 시간을 소비하며 기능적 버그가 ASIC 설계에 대한 응답의 약 50%에 기여하는 것으로 나타났습니다. 따라서 초기 기능 검증 단계에서 이러한 버그를 식별하고 수정할 수 있는 것이 매우 중요합니다. ML은 개발자가 설계에서 버그를 감지하고 버그를 더 빨리 찾는 데 도움을 주기 위해 사용되었습니다.
기능 검증에서 버그 헌팅 속도를 높이려면 세 가지 점진적 문제, 즉 근본 원인별 버그 클러스터링, 근본 원인 분류 및 수정 제안을 해결해야 합니다. 대부분의 연구는 처음 두 가지에 초점을 맞추고 있으며 세 번째에 대한 연구 결과는 아직 없습니다.
반구조화된 시뮬레이션 로그 파일을 버그 분석에 사용할 수 있습니다. 미공개 디자인의 로그 파일에서 메타데이터와 메시지 라인에서 616개의 다양한 기능을 추출합니다. 클러스터링에 대한 실험은 K-means와 agglomerative clustering으로 0.543, DBSCAN으로 0.593의 AMI(Adjusted Mutual Information)를 달성했으며, 이는 AMI가 1.0을 달성할 때 이상적인 클러스터링과는 거리가 멀다. 문제 2를 해결하는 정확도를 결정하기 위해 다양한 분류 알고리즘도 테스트되었습니다. 랜덤 포레스트, SVC(Support Vector Classification), 의사 결정 트리, 로지스틱 회귀, K-이웃 및 나이브 베이즈를 포함한 모든 알고리즘은 근본 원인을 예측합니다. 최고의 점수는 90.7%의 예측 정확도와 0.913 F1 점수를 가진 랜덤 포레스트에 의해 달성되었습니다. 또 다른 접근 방식은 코드 커밋에서 레이블이 지정된 데이터 세트를 사용하여 그래디언트 부스팅 모델을 훈련하는 것을 제안합니다. 여기에서 저자, 개정, 코드 및 프로젝트에 대한 100개 이상의 기능이 알고리즘에 대해 36개가 선택될 때까지 테스트되었습니다. 실험은 버그가 있는 코드를 포함할 가능성이 가장 높은 커밋을 예측하고 잠재적으로 수동 버그 사냥 시간을 크게 줄일 수 있음을 보여줍니다.
그러나 채택된 ML 기술의 상대적 단순성으로 인해 코드의 풍부한 의미 체계를 고려하거나 과거 버그 수정에서 학습할 수 있는 ML 모델을 교육할 수 없습니다. 따라서 버그가 발생하는 이유와 방법을 설명할 수 없으며 자동 또는 반자동으로 버그를 제거하기 위한 코드 수정을 제안할 수 없습니다.
기능 검증에 적용할 수 있는 새로운 ML 기술 및 모델
최근 몇 년 동안 ML 기술, 모델 및 알고리즘의 획기적인 발전이 목격되었습니다. 우리의 연구에 따르면 이러한 신기술 중 기능 검증 연구에 채택된 기술은 거의 없으며 기능 검증에서 어려운 문제를 해결하는 데 사용되면 큰 성공이 가능할 것이라고 낙관적으로 믿습니다.
엄청난 양의 텍스트 말뭉치에 대해 훈련된 수십억 개의 매개 변수가 있는 변환기 기반 대규모 NL 모델은 다양한 NL 작업(예: 질문 응답, 기계 번역, 텍스트 분류, 추상 요약 및 기타. 이러한 연구 결과를 코드 분석에 적용하면 이러한 모델의 큰 잠재력과 다재다능함도 입증되었습니다. 이러한 모델은 실제로 많은 양의 교육 데이터를 수집하고 학습한 지식을 구조화하며 쉬운 접근성을 제공할 수 있음이 입증되었습니다. 이 기능은 널리 사용되는 여러 프로그래밍 언어에 대한 정적 코드 분석, 요구 사항 엔지니어링 및 코딩 지원에 도움이 됩니다. 충분한 교육 데이터가 주어지면 이러한 기술이 다양한 기능 검증 작업을 위해 ML 모델을 교육할 수 있다고 믿는 것이 합리적입니다.
최근까지 그래프 데이터는 구조가 복잡해 ML을 적용하기 어려웠다. 그래프 신경망(GNN)의 발전은 기능 검증을 위한 새로운 기회를 약속했습니다. 이러한 접근 방식 중 하나는 디자인을 코드/데이터 흐름 그래프로 변환한 다음 테스트의 커버리지 종료를 예측하는 데 도움이 되도록 GNN을 교육하는 데 추가로 사용됩니다. 이러한 종류의 화이트 박스 접근 방식은 설계의 제어 및 데이터 흐름에 대해 이전에는 사용할 수 없었던 통찰력을 약속하여 잠재적인 커버리지 허점을 채우기 위해 직접 테스트를 생성할 수 있습니다. 그래프는 검증에서 만나는 풍부한 관계, 구조 및 의미 정보를 나타낼 수 있습니다. 그래프에서 ML 모델을 교육함으로써 얻을 수 있는 풍부한 정보는 버그 찾기 및 커버리지 폐쇄와 같은 많은 새로운 기능 검증 작업을 제공할 수 있습니다.
결론
EDA 4.0은 인공 지능의 힘을 통해 전자 설계 자동화를 혁신하고 엔지니어가 Industry 4.0의 혁신적인 변화를 실현하는 데 도움이 되는 몇 가지 핵심 기술을 제공합니다. 이 기사에서는 기능 검증의 다양한 측면을 다루는 기계 학습의 잠재적 기여에 대한 포괄적인 조사를 제공합니다. 이 기사는 기능 검증에서 ML의 일반적인 응용 분야를 강조하고 이 분야의 최신 성과를 요약합니다.
그러나 다양한 ML 기술의 적용에도 불구하고 현재 연구는 주로 기본 ML 방법에 의존하고 있으며 훈련 데이터의 가용성에 의해 제한됩니다. 이러한 상황은 다른 고급 도메인의 ML 애플리케이션 초기 단계를 연상시키며 기능 검증의 ML 애플리케이션이 아직 초기 단계에 있음을 나타냅니다. ML의 기능을 완전히 활용하기 위해 고급 기술과 모델을 활용할 수 있는 상당한 미개발 잠재력이 남아 있습니다. 또한 오늘날의 ML 애플리케이션에서 의미론적, 관계적 및 구조적 정보의 활용은 아직 완전히 실현되지 않았습니다.
이 주제에 대한 자세한 내용은 백서를 참조하십시오. 기능 검증에서 기계 학습 애플리케이션에 대한 설문 조사. 이 백서에서는 주제를 더 깊이 파고들어 산업적 관점에서 통찰력을 제공하고 제한된 데이터 가용성으로 인해 제기된 시급한 문제에 대해 논의합니다. 전체 논문에는 또한 이 기사의 많은 부분을 알려주는 매혹적인 연구 및 저술에 대한 철저한 참조가 포함되어 있습니다.
Harry Foster는 Siemens Digital Industries Software의 수석 과학자 Verification입니다. Verification Academy의 공동 창립자이자 편집장입니다. Foster는 2021 Design Automation Conference General Chair를 역임했으며 현재 Past Chair를 맡고 있습니다. 그는 검증 분야에서 여러 특허를 보유하고 있으며 검증에 관한 2022권의 책을 공동 집필했습니다. Foster는 산업 표준 개발에 기여한 공로로 Accellera Technical Excellence Award를 수상했으며 Accellera OVL(Open Verification Library) 표준의 최초 작성자였습니다. 또한 Foster는 2022 ACM Distinguished Service Award 및 XNUMX IEEE CEDA Outstanding Service Award를 수상했습니다.
Tom Fitzpatrick은 Siemens Digital Industries Software(Siemens EDA)의 Strategic Verification Architect로 고급 검증 방법론, 언어 및 표준을 개발하고 있습니다. 그는 Verilog 25, SystemVerilog 1364 및 UVM 1800를 포함하여 지난 1800.2년 동안 기능 검증 환경을 극적으로 개선한 여러 산업 표준에 크게 기여했습니다. 그는 Accellera Portable Stimulus 워킹 그룹의 창립 멤버이자 현재 부의장이며 현재 IEEE 1800 및 Accellera UVM-AMS 워킹 그룹의 의장을 맡고 있습니다. Fitzpatrick은 DVCon US 운영 위원회의 오랜 회원이며 DVConUS 2024의 일반 의장입니다. 그는 또한 디자인 자동화 컨퍼런스 집행 위원회의 회원이기도 합니다. Fitzpatrick은 MIT에서 전기 공학 및 컴퓨터 과학 석사 및 학사 학위를 받았습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoAiStream. Web3 데이터 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 미래 만들기 w Adryenn Ashley. 여기에서 액세스하십시오.
- PREIPO®로 PRE-IPO 회사의 주식을 사고 팔 수 있습니다. 여기에서 액세스하십시오.
- 출처: https://semiengineering.com/welcome-to-eda-4-0-and-the-ai-driven-revolution/

