개요
다음 단어를 식별하는 것은 언어 모델링이라고도 하는 다음 단어 예측 작업입니다. 중 하나 NLP의 벤치마크 작업은 언어 모델링입니다. 가장 기본적인 형태에서는 발생 가능성이 가장 높은 일련의 단어를 기반으로 단어를 선택하는 것입니다. 많은 다른 분야에서 언어 모델링은 매우 다양한 응용 프로그램을 가지고 있습니다.
학습 목표
- 통계 분석, 기계 학습 및 데이터 과학에 사용되는 수많은 모델의 기본 아이디어와 원칙을 인식합니다.
- 데이터를 기반으로 정확한 예측 및 유형을 생성하기 위해 회귀, 분류, 클러스터링 등을 포함한 예측 모델을 만드는 방법을 배웁니다.
- 과대적합 및 과소적합의 원리를 이해하고 정확성, 정밀도, 재현율 등과 같은 척도를 사용하여 모델 성능을 평가하는 방법을 배웁니다.
- 데이터를 전처리하고 모델링에 적합한 특성을 식별하는 방법을 알아봅니다.
- 하이퍼파라미터를 조정하고 그리드 검색 및 교차 검증을 사용하여 모델을 최적화하는 방법을 알아보세요.
이 기사는 데이터 과학 블로그.
차례
언어 모델링의 응용
다음은 언어 모델링의 몇 가지 주목할만한 응용 프로그램입니다.
모바일 키보드 텍스트 추천
모바일 키보드 텍스트 추천 또는 예측 텍스트 또는 자동 제안이라고 하는 스마트폰 키보드의 기능은 글을 쓸 때 단어나 구를 제안합니다. 타이핑 속도를 높이고 오류 발생률을 낮추고 보다 정확하고 상황에 맞는 권장 사항을 제공합니다.
또한 읽기 : 콘텐츠 기반 추천 시스템 구축
Google 검색 자동 완성
무엇이든 찾기 위해 Google과 같은 검색 엔진을 사용할 때마다 우리는 많은 아이디어를 얻습니다. 구문을 계속 추가함에 따라 권장 사항이 현재 검색과 더욱 관련성이 높아지고 향상됩니다. 그러면 어떻게 될까요?

자연어 처리(NLP) 기술이 이를 가능하게 합니다. 여기서는 자연어 처리(NLP)를 사용하여 양방향 LSTM(Long short-term memory) 모델을 활용하여 문장의 나머지 단어를 예측하는 예측 모델을 만듭니다.
자세히 알아보기 : LSTM이란 무엇입니까? 장단기 기억 소개
필요한 라이브러리 및 패키지 가져오기
양방향 LSTM을 사용하여 다음 단어 예측 모델을 구성하기 위해 필요한 라이브러리 및 패키지를 가져오는 것이 가장 좋습니다. 일반적으로 필요한 라이브러리 샘플은 다음과 같습니다.
import pandas as pd
import os
import numpy as np import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam데이터세트 정보
다루고 있는 데이터 세트의 기능과 속성을 이해하려면 지식이 필요합니다. 무작위로 선택되어 2019년에 게시된 다음 XNUMX개 출판물의 매체 기사가 이 데이터 세트에 포함됩니다.
- 데이터 과학을 향해
- UX 콜렉티브
- 스타트 업
- 글쓰기 협동조합
- 데이터 기반 투자자
- 더 나은 인간
- 더 나은 마케팅
데이터세트 링크: https://www.kaggle.com/code/ysthehurricane/next-word-prediction-bi-lstm-tutorial-easy-way/input
medium_data = pd.read_csv('../input/medium-articles-dataset/medium_data.csv')
medium_data.head()
여기에는 6508개의 다른 필드와 XNUMX개의 레코드가 있지만 제목 필드는 다음 단어를 예측하는 데만 사용합니다.
print("Number of records: ", medium_data.shape[0])
print("Number of fields: ", medium_data.shape[1])
데이터 세트 정보를 살펴보고 이해함으로써 다음 단어 예측 과제에 대한 전처리 절차, 모델 및 평가 지표를 선택할 수 있습니다.
다양한 기사 제목 표시 및 전처리
기사 제목 준비를 설명하기 위해 몇 가지 샘플 제목을 살펴보겠습니다.
medium_data['title']
제목에서 원하지 않는 문자 및 단어 제거
예측 작업을 위한 텍스트 데이터 전처리에는 때때로 제목에서 바람직하지 않은 문자와 구를 제거하는 작업이 포함됩니다. 불필요한 문자와 단어는 노이즈로 데이터를 오염시키고 불필요한 복잡성을 추가하여 모델의 성능과 정확도를 낮출 수 있습니다.
- 원하지 않는 문자:
- 구두: 느낌표, 물음표, 쉼표 및 기타 구두점을 제거해야 합니다. 일반적으로 예측 할당에 도움이 되지 않기 때문에 안전하게 버릴 수 있습니다.
- 특수 문자: 예측 작업에 불필요한 달러 기호, @ 기호, 해시태그 및 기타 특수 문자와 같은 영숫자가 아닌 기호를 제거합니다.
- HTML 태그: 제목에 HTML 마크업이나 태그가 있는 경우 적절한 도구나 라이브러리를 사용하여 제거하여 텍스트를 추출합니다.
- 원하지 않는 단어:
- 불용어: "a", "an", "the", "is", "in"과 같은 일반적인 불용어 및 중요한 의미나 예측력이 없는 기타 자주 발생하는 단어를 제거합니다.
- 관련 없는 단어: 예측 작업 또는 도메인과 관련이 없는 특정 단어를 식별하고 제거합니다. 예를 들어 영화 장르를 예측하는 경우 "영화" 또는 "영화"와 같은 단어는 유용한 정보를 제공하지 않을 수 있습니다.
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace(u'xa0',u' '))
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace('u200a',' '))
토큰 화
토큰 화 텍스트를 토큰, 단어, 하위 단어 또는 문자로 나눈 다음 각 토큰에 고유 ID 또는 인덱스를 할당하여 단어 인덱스 또는 어휘를 생성합니다.
토큰화 프로세스에는 다음 단계가 포함됩니다.
텍스트 전처리: 구두점을 제거하고 소문자로 변경하고 특정 작업 또는 도메인별 요구 사항을 처리하여 텍스트를 전처리합니다.
토큰 화 : 전처리된 텍스트를 사전 결정된 규칙 또는 방법에 따라 별도의 토큰으로 나눕니다. 정규식, 공백으로 구분 및 특수 토크나이저 사용은 모두 일반적인 토큰화 기술입니다.
어휘 증가 각 토큰에 고유한 ID 또는 색인을 할당하여 단어 색인이라고도 하는 사전을 만들 수 있습니다. 이 과정에서 각 티켓은 관련 인덱스 값에 매핑됩니다.
tokenizer = Tokenizer(oov_token='<oov>') # For those words which are not found in word_index
tokenizer.fit_on_texts(medium_data['title'])
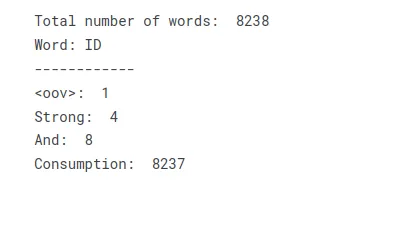
total_words = len(tokenizer.word_index) + 1 print("Total number of words: ", total_words)
print("Word: ID")
print("------------")
print("<oov>: ", tokenizer.word_index['<oov>'])
print("Strong: ", tokenizer.word_index['strong'])
print("And: ", tokenizer.word_index['and'])
print("Consumption: ", tokenizer.word_index['consumption'])텍스트를 어휘 또는 단어 인덱스로 변환하여 텍스트를 숫자 인덱스 모음으로 나타내는 조회 테이블을 만들 수 있습니다. 텍스트의 고유한 각 단어는 해당 인덱스 값을 받아 숫자 입력이 필요한 추가 처리 또는 모델링 작업을 허용합니다.
텍스트를 시퀀스로 제목 지정하고 N_gram 모델을 만듭니다.
이러한 단계는 제목 시퀀스를 기반으로 정확한 예측을 위한 n-gram 모델을 구축하는 데 사용할 수 있습니다.
- 제목을 시퀀스로 변환: 토크나이저를 사용하여 각 제목을 일련의 토큰으로 바꾸거나 각 슬립을 구성 단어로 수동으로 분리하십시오. 어휘집의 각 단어에 고유 번호 인덱스를 할당합니다.
- n-그램 생성: 시퀀스에서 n-그램을 만듭니다. n-title 토큰의 연속 실행을 n-gram이라고 합니다.
- 빈도를 세십시오: 각 n-gram이 데이터 세트에 나타나는 빈도를 결정합니다.
- n-gram 모델 구축: n-gram 빈도를 사용하여 n-gram 모델을 만듭니다. 모델은 이전 n-1 토큰이 주어진 각 토큰 확률을 추적합니다. 조회 테이블 또는 사전으로 표시할 수 있습니다.
- 다음 단어 예측: n-1-토큰 시퀀스에서 예상되는 다음 토큰은 n-그램 모델을 사용하여 식별할 수 있습니다. 이를 위해서는 알고리즘에서 확률을 찾아 가장 가능성이 높은 토큰을 선택해야 합니다.
자세히 알아보기 : N-gram이란 무엇이며 Python에서 N-gram을 구현하는 방법은 무엇입니까?
이러한 단계를 사용하여 제목의 시퀀스를 활용하여 다음 단어 또는 토큰을 예측하는 n-gram 모델을 구축할 수 있습니다. 학습 데이터를 기반으로 이 방법은 제목의 언어 사용에 대한 통계적 관계 및 추세를 캡처하므로 정확한 예측을 생성할 수 있습니다.

input_sequences = []
for line in medium_data['title']: token_list = tokenizer.texts_to_sequences([line])[0] #print(token_list) for i in range(1, len(token_list)): n_gram_sequence = token_list[:i+1] input_sequences.append(n_gram_sequence) # print(input_sequences)
print("Total input sequences: ", len(input_sequences))
패딩을 사용하여 모든 제목을 같은 길이로 만들기
다음 단계에 따라 패딩을 사용하여 각 제목이 동일한 크기인지 확인할 수 있습니다.
- 다른 모든 제목을 비교하여 데이터 세트에서 가장 긴 제목을 찾습니다.
- 각 타이틀에 대해 이 프로세스를 반복하여 각 타이틀의 길이를 전체 제한과 비교합니다.
- 제목이 너무 짧으면 특정 패딩 토큰이나 문자를 사용하여 확장해야 합니다.
- 데이터 세트의 각 제목에 대해 패딩 절차를 다시 수행하십시오.
패딩은 모든 제목의 길이가 동일하도록 하고 후처리 또는 모델 교육에 일관성을 제공합니다.
# pad sequences max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
input_sequences[1]
기능 및 레이블 준비
주어진 시나리오에서 각 입력 시퀀스의 마지막 요소를 레이블로 간주하면 제목에 원-핫 인코딩을 수행하여 총 고유 단어 수에 해당하는 벡터로 나타낼 수 있습니다.
# create features and label
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words) print(xs[5])
print(labels[5])
print(ys[5][14])
양방향 LSTM 신경망의 아키텍처
순환 신경망(RNN) LSTM(Long Short-Term Memory)을 사용하면 광범위한 시퀀스에서 정보를 수집하고 유지할 수 있습니다. LSTM 네트워크는 기울기 소실 문제로 자주 어려움을 겪고 장기 종속성을 유지하는 데 어려움을 겪는 일반 RNN의 제약 조건을 극복하기 위해 특수 메모리 셀과 게이팅 기술을 사용합니다.
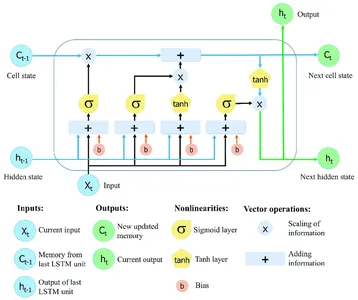
LSTM 네트워크의 중요한 기능은 시간이 지남에 따라 정보를 저장할 수 있는 메모리 단위 역할을 하는 셀 상태입니다. 셀 상태는 망각 게이트, 입력 게이트 및 출력 게이트의 세 가지 주요 게이트에 의해 보호되고 제어됩니다. 이 게이트는 LSTM 셀 안팎의 정보 흐름을 조절하여 네트워크가 다른 시간 단계에서 선택적으로 정보를 기억하거나 잊을 수 있도록 합니다.
자세히 알아보기 : 장단기 기억 | LSTM의 아키텍처
양방향 LSTM
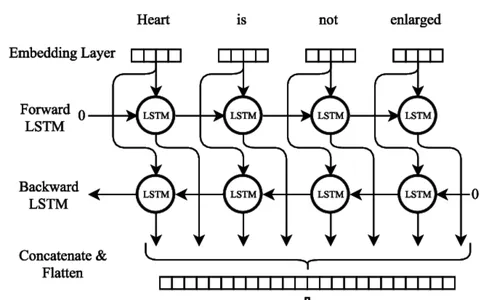
Bi-LSTM 신경망 모델 교육
양방향 LSTM(Bi-LSTM) 신경망 모델을 교육하는 동안 수많은 중요한 절차를 따라야 합니다. 첫 번째 단계는 다음 단어를 나타내는 해당 입력 및 출력 시퀀스로 교육 데이터 세트를 컴파일하는 것입니다. 텍스트 데이터는 별도의 줄로 구분하고 구두점을 제거하고 대소문자를 소문자로 변경하여 전처리해야 합니다.
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150)))
model.add(Dense(total_words, activation='softmax'))
adam = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
history = model.fit(xs, ys, epochs=50, verbose=1)
#print model.summary()
print(model)
fit() 메서드를 호출하면 모델이 학습됩니다. 학습 데이터는 입력 시퀀스(xs)와 일치하는 출력 시퀀스(ys)로 구성됩니다. 모델은 전체 학습 세트를 통해 50회 반복을 진행합니다. 학습 프로세스 중에 학습 진행률이 표시됩니다(verbose=1).
플로팅 모델 정확도 및 손실
교육 전반에 걸쳐 모델의 정확도와 손실을 플로팅하면 모델의 성능과 교육 진행 방식에 대한 통찰력 있는 정보를 얻을 수 있습니다. 예상 값과 실제 값 사이의 실수 또는 차이를 손실이라고 합니다. 반면 모델에서 생성된 정확한 예측의 백분율을 정확도라고 합니다.
import matplotlib.pyplot as plt def plot_graphs(history, string): plt.plot(history.history[string]) plt.xlabel("Epochs") plt.ylabel(string) plt.show() plot_graphs(history, 'accuracy')
plot_graphs(history, 'loss')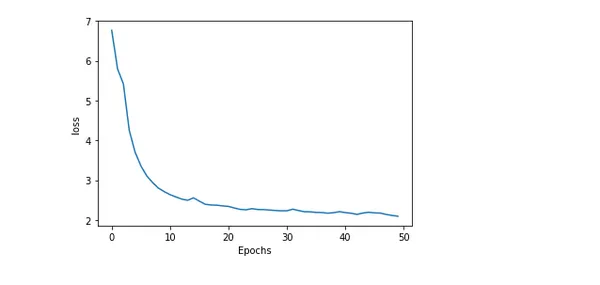
제목의 다음 단어 예측
자연어 처리에서 매력적인 도전은 제목에서 다음 단어를 추측하는 것입니다. 모델은 텍스트 데이터에서 패턴과 상관 관계를 찾아 가장 그럴듯한 대화를 제안할 수 있습니다. 이 예측 능력은 텍스트 제안 시스템 및 자동 완성과 같은 애플리케이션을 가능하게 합니다. RNN 및 변환기 기반 아키텍처와 같은 정교한 접근 방식은 정확도를 높이고 상황에 맞는 관계를 캡처합니다.
seed_text = "implementation of"
next_words = 2 for _ in range(next_words): token_list = tokenizer.texts_to_sequences([seed_text])[0] token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre') predicted = model.predict_classes(token_list, verbose=0) output_word = "" for word, index in tokenizer.word_index.items(): if index == predicted: output_word = word break seed_text += " " + output_word
print(seed_text)
결론
결론적으로 일련의 단어에서 후속 단어를 예측하도록 모델을 훈련시키는 것은 Bidirectional LSTM을 사용한 다음 단어 예측으로 알려진 흥미진진한 자연어 처리 과제입니다. 글머리 기호로 요약한 결론은 다음과 같습니다.
- 순차적 데이터 처리를 위한 강력한 딥 러닝 아키텍처 BI-LSTM은 장거리 관계 및 구문 컨텍스트를 캡처할 수 있습니다.
- BI-LSTM 학습을 위한 원시 텍스트 데이터를 준비하려면 데이터 준비가 필수적입니다. 여기에는 토큰화, 어휘 생성 및 텍스트 벡터화가 포함됩니다.
- 손실 함수 생성, 옵티마이저를 사용하여 모델 구축, 사전 처리된 데이터에 피팅, 유효성 검사 세트에 대한 성능 평가는 BI-LSTM 모델 교육 단계입니다.
- BI-LSTM 다음 단어 예측은 이론적 지식과 실습 실험을 결합하여 마스터합니다.
- 자동 완성, 언어 생성 및 텍스트 제안 알고리즘은 다음 단어 예측 모델 응용 프로그램의 예입니다.
다음 단어 예측을 위한 애플리케이션에는 챗봇, 기계 번역 및 텍스트 완성이 포함됩니다. 더 많은 연구와 개선을 통해 보다 정확하고 상황을 인식하는 다음 단어 예측 모델을 만들 수 있습니다.
자주 묻는 질문
A. 다음 단어 예측은 모델이 주어진 단어나 문맥의 순서를 따를 가능성이 가장 높은 단어를 예측하는 NLP 작업입니다. 학습 데이터에서 학습한 패턴과 관계를 기반으로 다음 단어에 대한 일관되고 상황에 맞는 제안을 생성하는 것을 목표로 합니다.
A. 다음 단어 예측은 일반적으로 RNN(Recurrent Neural Networks)과 LSTM(Long Short-Term Memory) 및 GRU(Gated Recurrent Unit)와 같은 변형을 사용합니다. 또한 GPT(Generative Pre-trained Transformer) 모델과 같은 Transformer 기반 아키텍처와 같은 모델도 이 작업에서 상당한 발전을 보여주었습니다.
A. 일반적으로 다음 단어 예측을 위한 학습 데이터를 준비할 때 텍스트를 일련의 단어로 분할하고 입력-출력 쌍을 만듭니다. 해당 출력은 각 입력 시퀀스에 대한 텍스트의 다음 단어를 나타냅니다. 텍스트 전처리에는 구두점 제거, 단어를 소문자로 변환, 텍스트를 개별 단어로 토큰화하는 작업이 포함됩니다.
A. Perplexity, Accuracy, Top-k Accuracy 등의 평가 지표를 사용하여 다음 단어 예측 모델의 성능을 평가할 수 있습니다. Perplexity는 주어진 컨텍스트에서 모델이 다음 단어를 얼마나 잘 예측하는지 측정합니다. 정확도 메트릭은 예측된 단어를 실측 정보와 비교하는 반면, top-k 정확도는 top-k 가장 가능성 있는 댓글 내에서 모델의 예측을 고려합니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/07/next-word-prediction-with-bidirectional-lstm/

