기업이 다양한 소스에서 점점 더 많은 양의 데이터를 수집함에 따라, 진화하는 분석 요구 사항을 충족하기 위해 해당 데이터의 구조와 구성은 시간이 지남에 따라 변경되어야 하는 경우가 많습니다. 그러나 기존 데이터 레이크에서 스키마와 테이블 파티션을 변경하는 것은 전체 테이블의 이름을 바꾸거나 다시 생성하고 대규모 데이터세트를 다시 처리해야 하므로 혼란스럽고 시간이 많이 걸리는 작업일 수 있습니다. 이는 민첩성과 통찰력을 얻는 시간을 방해합니다.
스키마 발전을 통해 기존 데이터를 다시 쓸 필요 없이 열을 추가, 삭제, 이름 바꾸기 또는 수정할 수 있습니다. 이는 빠르게 변화하는 기업이 새로운 사용 사례를 지원하기 위해 데이터 구조를 강화하는 데 매우 중요합니다. 예를 들어, 전자상거래 회사는 분석을 강화하기 위해 새로운 고객 인구통계학적 속성이나 주문 상태 플래그를 추가할 수 있습니다. 아파치 빙산 혁신적인 메타데이터 테이블 진화 아키텍처를 통해 이전 버전과 호환되는 방식으로 이러한 스키마 변경 사항을 관리합니다.
마찬가지로 파티션 진화를 통해 파티션을 원활하게 추가, 삭제 또는 분할할 수 있습니다. 예를 들어, 전자상거래 시장에서는 처음에 주문 데이터를 날짜별로 분할할 수 있습니다. 주문이 누적되고 일별 쿼리가 비효율적이 되면 일별 및 고객 ID 파티션으로 분할될 수 있습니다. 테이블 분할은 쿼리 성능을 위해 대규모 데이터 세트를 가장 효율적으로 구성합니다. Iceberg는 기업에 지루한 재구축 절차를 요구하지 않고 파티션을 점진적으로 조정할 수 있는 유연성을 제공합니다. 가동 중지 시간이나 기존 데이터 파일을 다시 쓸 필요 없이 완벽하게 호환되는 방식으로 새 파티션을 추가할 수 있습니다.
이 게시물에서는 Iceberg를 활용하는 방법을 보여줍니다. 아마존 단순 스토리지 서비스 (아마존 S3), AWS 접착제, AWS Lake 형성및 AWS 자격 증명 및 액세스 관리 (IAM)은 원활한 진화를 지원하는 트랜잭션 데이터 레이크를 구현합니다. 데이터 통찰력이 발전함에 따라 손쉽게 스키마 및 파티션 조정을 허용함으로써 비즈니스 성공에 필요한 미래 보장형 유연성의 이점을 누릴 수 있습니다.
솔루션 개요
예시 사용 사례에서는 가상의 대규모 전자상거래 회사가 매일 수천 건의 주문을 처리합니다. 주문이 수신, 업데이트, 취소, 배송, 배달 또는 반품되면 온프레미스 시스템에 변경 사항이 적용되며, 데이터 분석가가 S3 데이터 레이크를 통해 쿼리를 실행할 수 있도록 이러한 변경 사항이 SXNUMX 데이터 레이크에 복제되어야 합니다. 아마존 아테나. 변경 사항에는 스키마 업데이트도 포함될 수 있습니다. 다양한 조직의 보안 요구 사항으로 인해 Lake Formation을 통해 분석가에 대한 세분화된 액세스 제어를 관리해야 합니다.
다음 다이어그램은 솔루션 아키텍처를 보여줍니다.
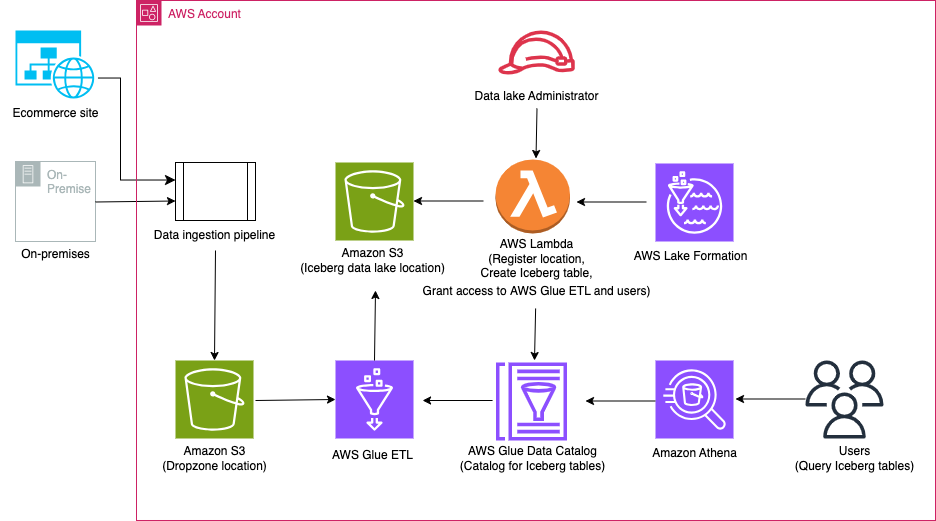
솔루션 워크플로에는 다음과 같은 주요 단계가 포함됩니다.
- 데이터 수집 파이프라인을 사용하여 온프레미스에서 Dropzone 위치로 데이터를 수집합니다.
- AWS Glue를 사용하여 Dropzone 위치의 데이터를 Iceberg에 병합합니다.
- Athena를 사용하여 데이터를 쿼리합니다.
사전 조건
이 연습에서는 다음과 같은 전제 조건이 있어야합니다.
AWS CloudFormation을 사용하여 인프라 설정
다음을 사용하여 인프라를 생성하려면 AWS 클라우드 포메이션 템플릿에서 다음 단계를 완료하세요.
- AWS 계정에 관리자로 로그인합니다.
- AWS CloudFormation 콘솔을 엽니다.
- 왼쪽 메뉴에서 발사 스택:

- 럭셔리 스택 이름, 이름을 입력합니다(이 게시물의 경우 icebergdemo1).
- 왼쪽 메뉴에서 다음 보기.
- 다음 매개변수에 대한 정보를 제공하십시오.
DatalakeUserNameDatalakeUserPasswordDatabaseNameTableNameDatabaseLFTagKeyDatabaseLFTagValueTableLFTagKeyTableLFTagValue
- 왼쪽 메뉴에서 다음 보기.
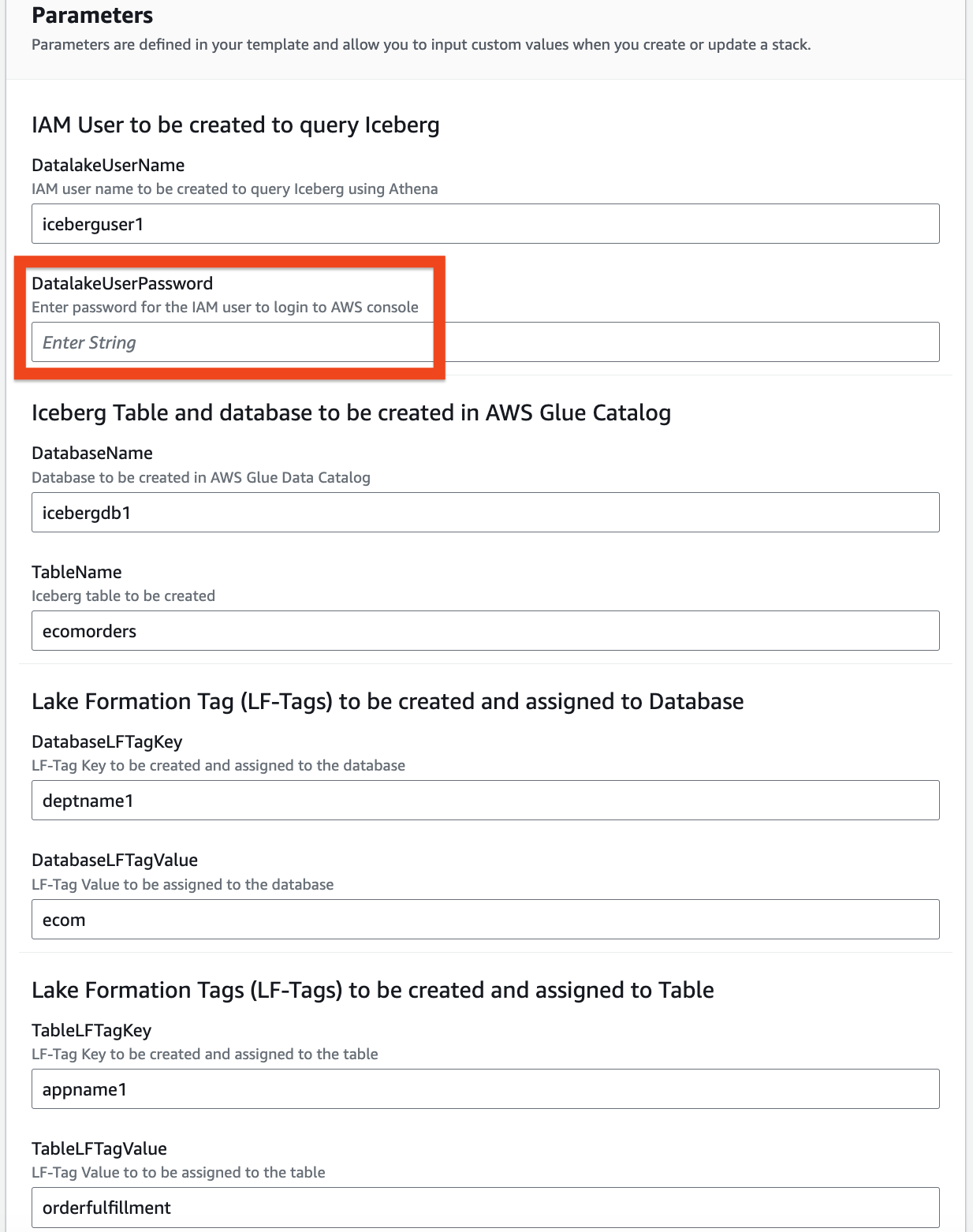
- 왼쪽 메뉴에서 다음 다시.
- . 검토 섹션에서 입력한 값을 검토하세요.
- 선택 AWS CloudFormation이 사용자 지정 이름으로 IAM 리소스를 생성 할 수 있음을 인정합니다 선택하고 문의하기.
몇 분 후에 스택 상태가 다음으로 변경됩니다. CREATE_COMPLETE.
당신은 출력 탭 프로비저닝한 모든 리소스를 보려면 스택을 참조하세요. 리소스 앞에는 귀하가 제공한 스택 이름이 붙습니다(이 게시물의 경우 icebergdemo1).
Lambda를 사용하여 Iceberg 테이블을 생성하고 Lake Formation을 사용하여 액세스 권한을 부여합니다.
Iceberg 테이블을 생성하고 이에 대한 액세스 권한을 부여하려면 다음 단계를 완료하세요.
- 로 이동 자료 CloudFormation 스택 icebergdemo1 탭에서 이름이 지정된 논리적 ID를 검색합니다.
LambdaFunctionIceberg. - 연결된 물리적 ID의 하이퍼링크를 선택하세요.
Lambda 함수로 리디렉션됩니다. icebergdemo1-Lambda-Create-Iceberg-and-Grant-access.
- 에 구성 탭에서 환경 변수 왼쪽 된 창에서.

- 에 암호 탭에서 함수 코드를 확인할 수 있습니다.
이 함수는 Python 용 AWS SDK (Boto3) 리소스를 프로비저닝하기 위한 API입니다. 프로비저닝된 데이터 레이크 관리자 역할을 맡아 다음 작업을 수행합니다.
- 부여 DATA_LOCATION_ACCESS 등록된 데이터 레이크 위치에 대한 데이터 레이크 관리자 역할에 대한 액세스
- 만들기 Lake Formation 태그(LF-태그)
- AWS Glue를 사용하여 AWS Glue 데이터 카탈로그에 데이터베이스 생성 CREATE_DATABASE API
- 데이터베이스에 LF-태그 할당
- LF-태그를 사용하여 데이터 레이크 IAM 사용자 및 AWS Glue ETL IAM 역할에 데이터베이스에 대한 DESCRIBE 액세스 권한을 부여합니다.
- AWS Glue를 사용하여 Iceberg 테이블 생성 create_table API :
- 테이블에 LF-태그 할당
- 데이터 레이크 IAM 사용자에게 Iceberg 테이블 LF-Tags에 DESCRIBE 및 SELECT 권한을 부여합니다.
- Iceberg 테이블 LF-태그에 대한 ALL, DESCRIBE, SELECT, INSERT, DELETE 및 ALTER 액세스 권한을 AWS Glue ETL IAM 역할에 부여합니다.
- 에 Test
탭에서 Test
기능을 실행합니다.

기능이 완료되면 '함수 실행 중: 성공'이라는 메시지가 표시됩니다.
Lake Formation은 분석 및 기계 학습을 위한 데이터를 중앙에서 관리하고 보호하며 전 세계적으로 공유하는 데 도움이 됩니다. Lake Formation을 사용하면 Amazon S3의 데이터 레이크 데이터와 Data Catalog의 해당 메타데이터에 대한 세분화된 액세스 제어를 관리할 수 있습니다.
데이터 레이크에 Amazon S3 위치를 Iceberg 스토리지로 추가하려면, 위치를 등록하다 레이크 포메이션과 함께. 그런 다음 Lake Formation 권한을 사용하여 이 위치를 가리키는 Data Catalog 객체와 해당 위치의 기본 데이터에 대한 세분화된 액세스 제어를 수행할 수 있습니다.
CloudFormation 스택이 데이터 레이크 위치를 등록했습니다.

데이터 위치 권한 Lake Formation에서는 보안 주체가 지정된 등록 Amazon S3 위치를 가리키는 데이터 카탈로그 리소스를 생성하고 변경할 수 있습니다. Lake Formation 외에도 데이터 위치 권한이 작동합니다. 데이터 권한 데이터 레이크의 정보를 보호합니다.
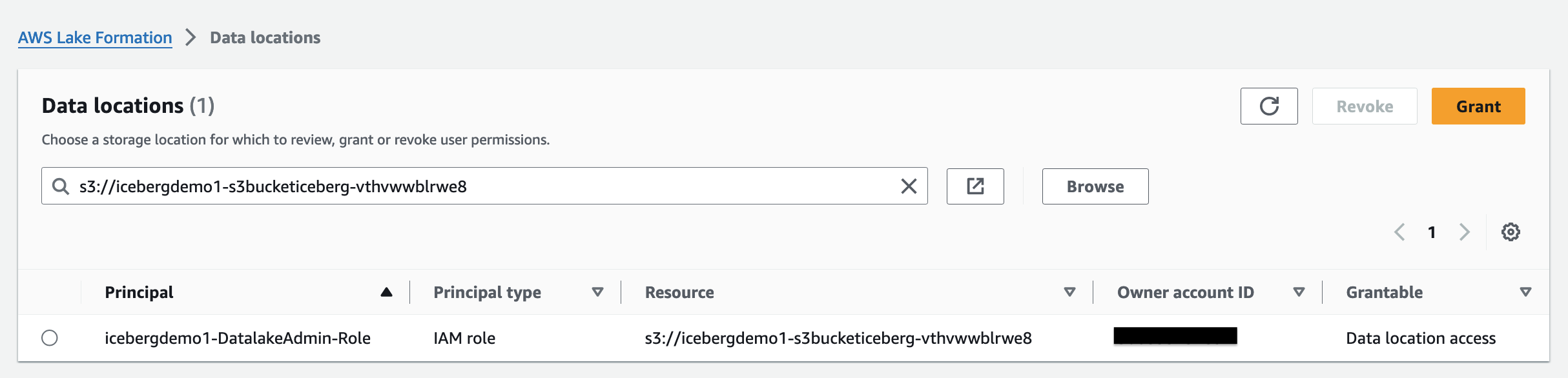
Lake Formation 태그 기반 액세스 제어(LF-TBAC) 속성을 기반으로 권한을 정의하는 권한 부여 전략입니다. Lake Formation에서는 이러한 속성을 LF-태그라고 합니다. Data Catalog 리소스, Lake Formation 주체 및 테이블 열에 LF-태그를 연결할 수 있습니다. 이러한 LF-태그를 사용하여 Lake Formation 리소스에 대한 권한을 할당하고 취소할 수 있습니다. Lake Formation은 주체의 태그가 리소스 태그와 일치할 때 해당 리소스에 대한 작업을 허용합니다.
Lake Formation 콘솔에서 Iceberg 테이블 확인
Iceberg 테이블을 확인하려면 다음 단계를 완료하세요.
- Lake Formation 콘솔에서 데이터베이스 탐색 창에서
- 다음에 대한 세부정보 페이지를 엽니다.
icebergdb1.
연관된 데이터베이스 LF-태그를 볼 수 있습니다.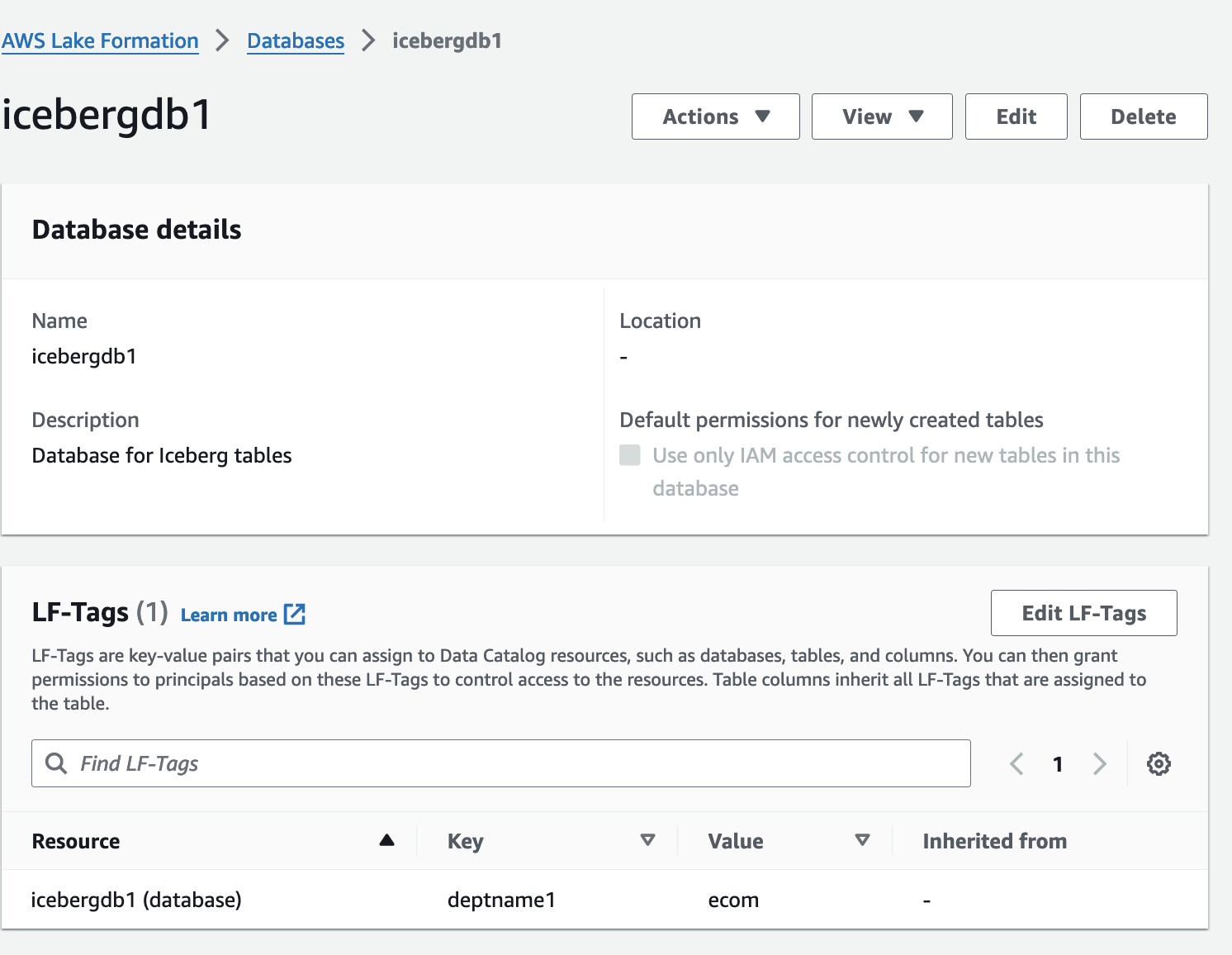
- 왼쪽 메뉴에서 테이블 탐색 창에서
- 다음에 대한 세부정보 페이지를 엽니다.
ecomorders.
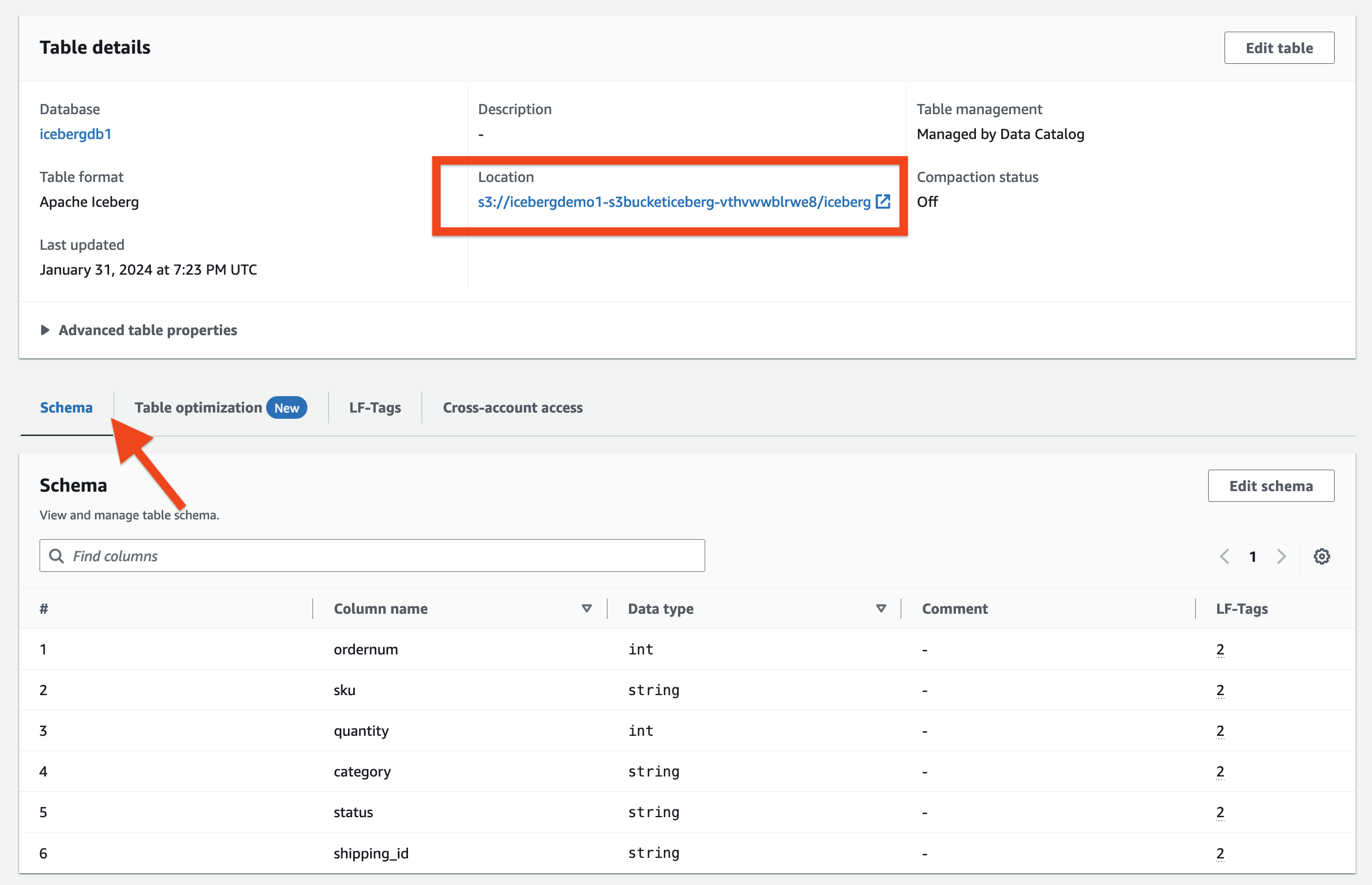
. 테이블 세부정보 섹션에서 다음을 관찰할 수 있습니다.
- 테이블 형식 로 보여줍니다 아파치 빙산
- 테이블 관리 로 보여줍니다 Data Catalog로 관리됨
- 장소 Iceberg 테이블의 데이터 레이크 위치를 나열합니다.
. LF-태그 섹션에서 관련 테이블 LF-Tags를 볼 수 있습니다.
. 테이블 세부정보 섹션, 확장 고급 테이블 속성 다음을 보려면:
metadata_locationIceberg 테이블의 메타데이터 파일 위치를 가리킵니다.table_type로 보여줍니다ICEBERG
에 개요 탭에서는 Iceberg 테이블에 정의된 열을 볼 수 있습니다.
Iceberg를 AWS Glue 데이터 카탈로그 및 Amazon S3와 통합
Iceberg는 디렉터리 대신 테이블의 개별 데이터 파일을 추적합니다. 테이블에 명시적인 커밋이 있으면 Iceberg는 데이터 파일을 생성하여 테이블에 추가합니다. Iceberg는 메타데이터 파일에서 테이블 상태를 유지합니다. 테이블 상태가 변경되면 이전 메타데이터를 원자적으로 대체하는 새 메타데이터 파일이 생성됩니다. 메타데이터 파일은 테이블 스키마, 파티셔닝 구성 및 기타 속성을 추적합니다.
Iceberg에는 Amazon S3와 같은 객체 저장소와 호환되는 작업을 지원하는 파일 시스템이 필요합니다.
Iceberg는 테이블 콘텐츠에 대한 스냅샷을 생성합니다. 각 스냅샷은 특정 시점의 테이블에 있는 완전한 데이터 파일 세트입니다. 스냅샷의 데이터 파일은 테이블의 각 데이터 파일, 해당 파티션 데이터 및 해당 메트릭에 대한 행을 포함하는 하나 이상의 매니페스트 파일에 저장됩니다.
다음 다이어그램은 이 계층 구조를 보여줍니다.
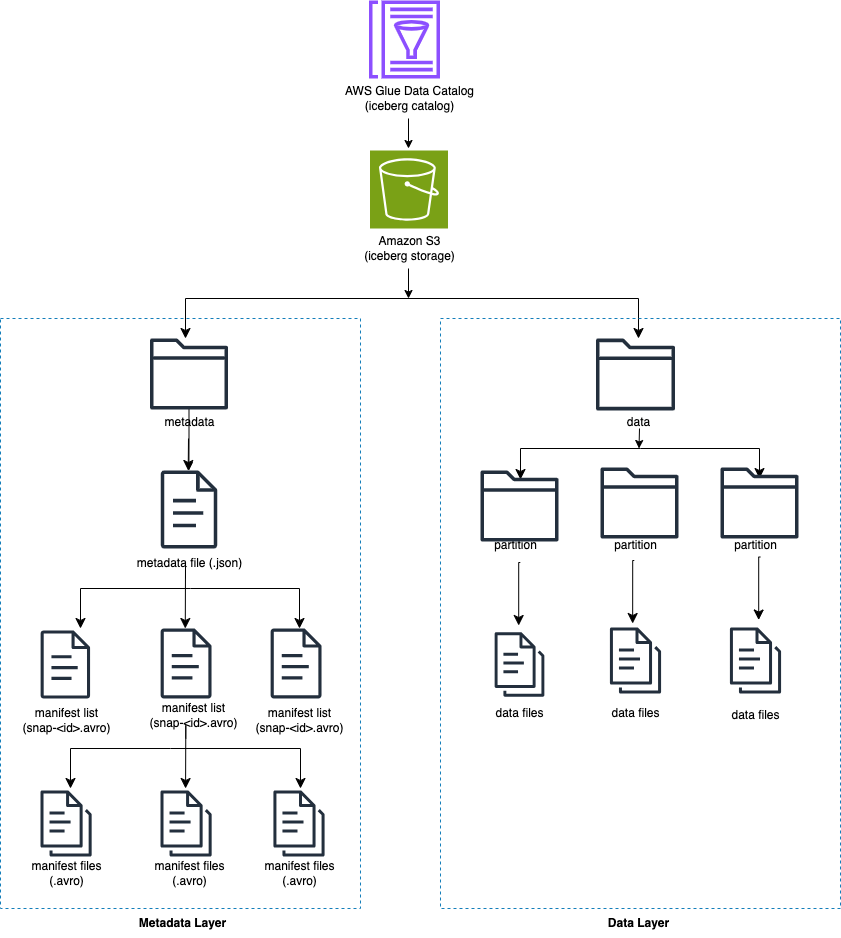
Iceberg 테이블을 생성하면 메타데이터 폴더가 먼저 생성되고 메타데이터 폴더에 메타데이터 파일이 생성됩니다. 데이터 폴더는 Iceberg 테이블에 데이터를 로드할 때 생성됩니다.

Iceberg 메타데이터 파일의 내용
Iceberg 메타데이터 파일에는 다음을 포함하여 많은 정보가 포함되어 있습니다.
- 형식 버전 – 빙산 테이블 버전
- 장소 – 테이블의 Amazon S3 위치
- 스키마 – 테이블의 모든 열의 이름과 데이터 유형
- 파티션 사양 – 분할된 열
- 정렬 순서 – 열의 정렬 순서
- 속성 – 테이블 속성
- 현재 스냅샷 ID – 현재 스냅샷
- 심판 – 테이블 참조
- 스냅 샷 – 각각 다음 정보를 포함하는 스냅샷 목록:
- 시퀀스 번호 – 시간순으로 표시된 스냅샷의 시퀀스 번호(가장 높은 숫자는 현재 스냅샷을 나타내고 첫 번째 스냅샷은 1)
- 스냅샷 ID – 스냅샷 ID
- 타임스탬프-ms – 스냅샷이 커밋된 타임스탬프
- 개요 – 커밋된 변경 사항 요약
- 매니페스트 목록 – 매니페스트 목록 이 파일 이름은 snap-< snapshot-id >로 시작합니다.
- 스키마 ID – 시간순으로 나타낸 스키마의 시퀀스 번호(가장 높은 숫자가 현재 스키마를 나타냄)
- 스냅샷 로그 – 시간순으로 정렬된 스냅샷 목록
- 메타데이터 로그 – 시간순으로 나열된 메타데이터 파일 목록
메타데이터 파일에는 테이블 데이터 및 스키마에 대한 모든 기록 변경 사항이 포함되어 있습니다. 메타파일 파일의 내용을 직접 검토하는 것은 시간이 많이 걸리는 작업일 수 있습니다. 다행히도 다음을 쿼리할 수 있습니다. Athena를 사용하는 Iceberg 메타데이터.
AWS Glue의 Iceberg 프레임워크
AWS Glue 4.0은 Lake Formation에 등록된 Iceberg 테이블을 지원합니다. AWS Glue ETL 작업에서는 다음 코드가 필요합니다. Iceberg 프레임워크 활성화:
기본 데이터에 대한 읽기/쓰기 액세스를 위해 Lake Formation 권한 외에도 AWS Glue ETL 작업을 실행하는 AWS Glue IAM 역할이 부여되었습니다. 레이크포메이션: GetDataAccess IAM 권한. 이 권한을 통해 Lake Formation은 데이터에 액세스하기 위한 임시 자격 증명 요청을 승인합니다.
CloudFormation 스택은 1개의 AWS Glue ETL 작업을 프로비저닝했습니다. 각 작업의 이름은 스택 이름(icebergdemoXNUMX)으로 시작됩니다. 작업을 보려면 다음 단계를 완료하세요.
- AWS 계정에 관리자로 로그인합니다.
- AWS Glue 콘솔에서 ETL 작업 탐색 창에서
- 다음을 사용하여 채용정보를 검색하세요.
icebergdemo1이름으로.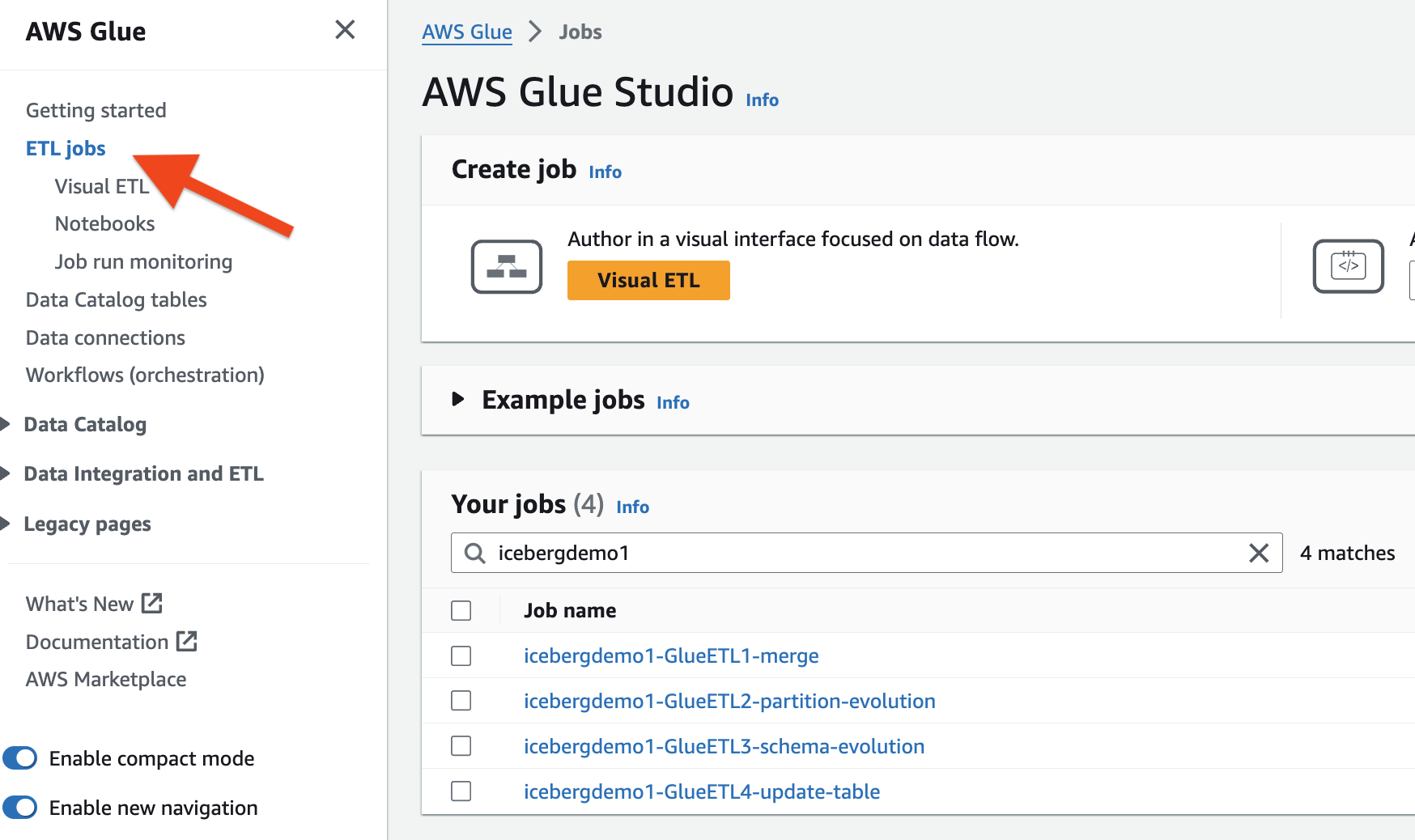
Dropzone의 데이터를 Iceberg 테이블에 병합
사용 사례에서 회사는 매일 온프레미스 위치에서 Amazon S3 Dropzone 위치로 전자상거래 주문 데이터를 수집합니다. CloudFormation 스택은 다음 그림과 같이 3일 동안의 샘플 주문이 포함된 파일 XNUMX개를 로드했습니다. Dropzone 위치에 데이터가 표시됩니다. s3://icebergdemo1-s3bucketdropzone-kunftrcblhsk/data.
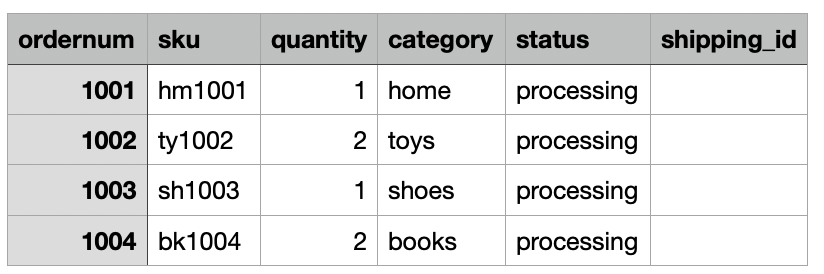


AWS Glue ETL 작업 icebergdemo1-GlueETL1-merge 매일 실행되어 데이터를 Iceberg 테이블에 병합합니다. Iceberg에 데이터를 추가하거나 업데이트하는 논리는 다음과 같습니다.
- 입력 데이터에서 Spark DataFrame을 만듭니다.
- 새로운 주문의 경우 테이블에 추가하세요.
- 테이블에 일치하는 주문이 있으면 상태를 업데이트하고
shipping_id:
AWS Glue 병합 작업을 실행하려면 다음 단계를 완료하십시오.
- AWS Glue 콘솔에서 ETL 작업 탐색 창에서
- ETL 작업 선택
icebergdemo1-GlueETL1-merge. - 에 행위 드롭다운 메뉴에서 선택 매개변수를 사용하여 실행.
- 에 매개변수 실행 페이지로 이동 작업 매개 변수.
- 다음
--dropzone_path매개변수에서 입력 데이터의 S3 위치를 제공합니다(icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge1). - 작업을 실행하여 모든 주문(1001, 1002, 1003, 1004)을 추가합니다.
- 다음
--dropzone_path parameter, S3 위치를 다음으로 변경하십시오.icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge2. - 작업을 다시 실행하여 주문 2001과 2002를 추가하고 주문 1001, 1002, 1003을 업데이트합니다.
- 다음
--dropzone_path매개변수에서 S3 위치를 다음으로 변경합니다.icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge3. - 작업을 다시 실행하여 주문 3001을 추가하고 주문 1001, 1003, 2001 및 2002를 업데이트합니다.
Glue ETL 작업을 사용하여 데이터를 테이블에 병합할 때 Iceberg가 작성한 데이터 파일을 보려면 테이블의 데이터 폴더로 이동하세요. icebergdemo1-GlueETL1-merge.

Athena를 사용하여 Iceberg 쿼리
CloudFormation 스택은 LF-태그를 사용하여 Iceberg 테이블에 대한 읽기 액세스 권한을 가진 IAM 사용자 iceberguser1을 생성했습니다. 이 사용자를 통해 Athena를 사용하여 Iceberg를 쿼리하려면 다음 단계를 완료하세요.
- 다음으로 로그인
iceberguser1~로 AWS 관리 콘솔. - Athena 콘솔에서 작업 그룹 탐색 창에서
- CloudFormation이 프로비저닝한 작업 그룹을 찾습니다(
icebergdemo1-workgroup) - Athena 엔진 버전 3을 확인합니다.
Athena 엔진 버전 3은 다음을 지원합니다. 빙산 파일 형식, Parquet, ORC 및 Avro를 포함합니다.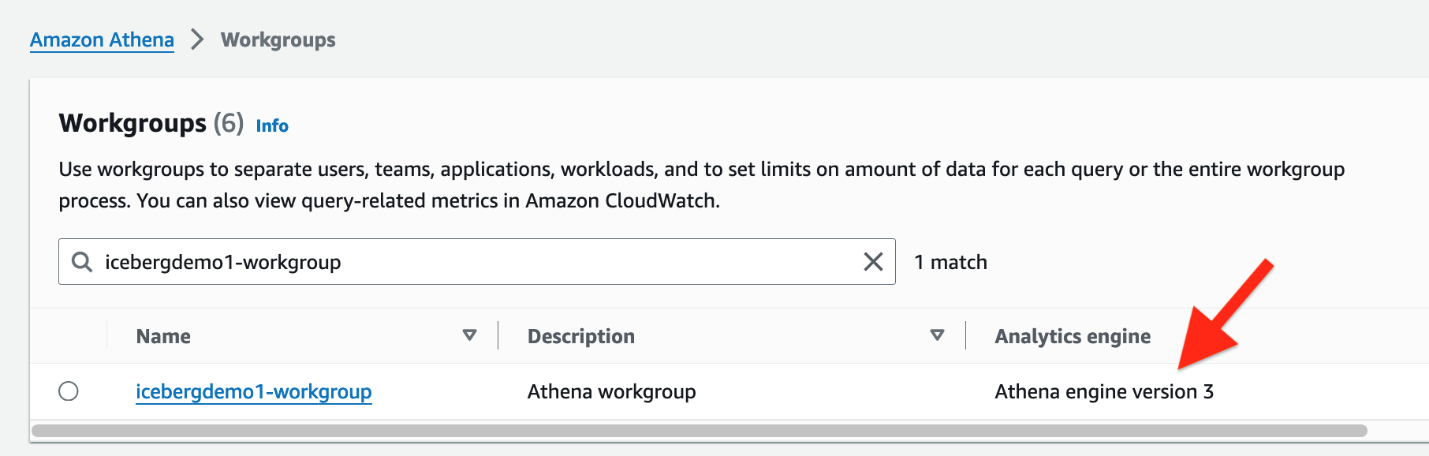
- Athena 쿼리 편집기로 이동합니다.
- 드롭다운 메뉴에서 작업 그룹 icebergdemo1-workgroup을 선택합니다.
- 럭셔리 데이터베이스선택한다.
icebergdb1. 테이블이 보이실거에요ecomorders. - Iceberg 테이블의 데이터를 보려면 다음 쿼리를 실행하세요.
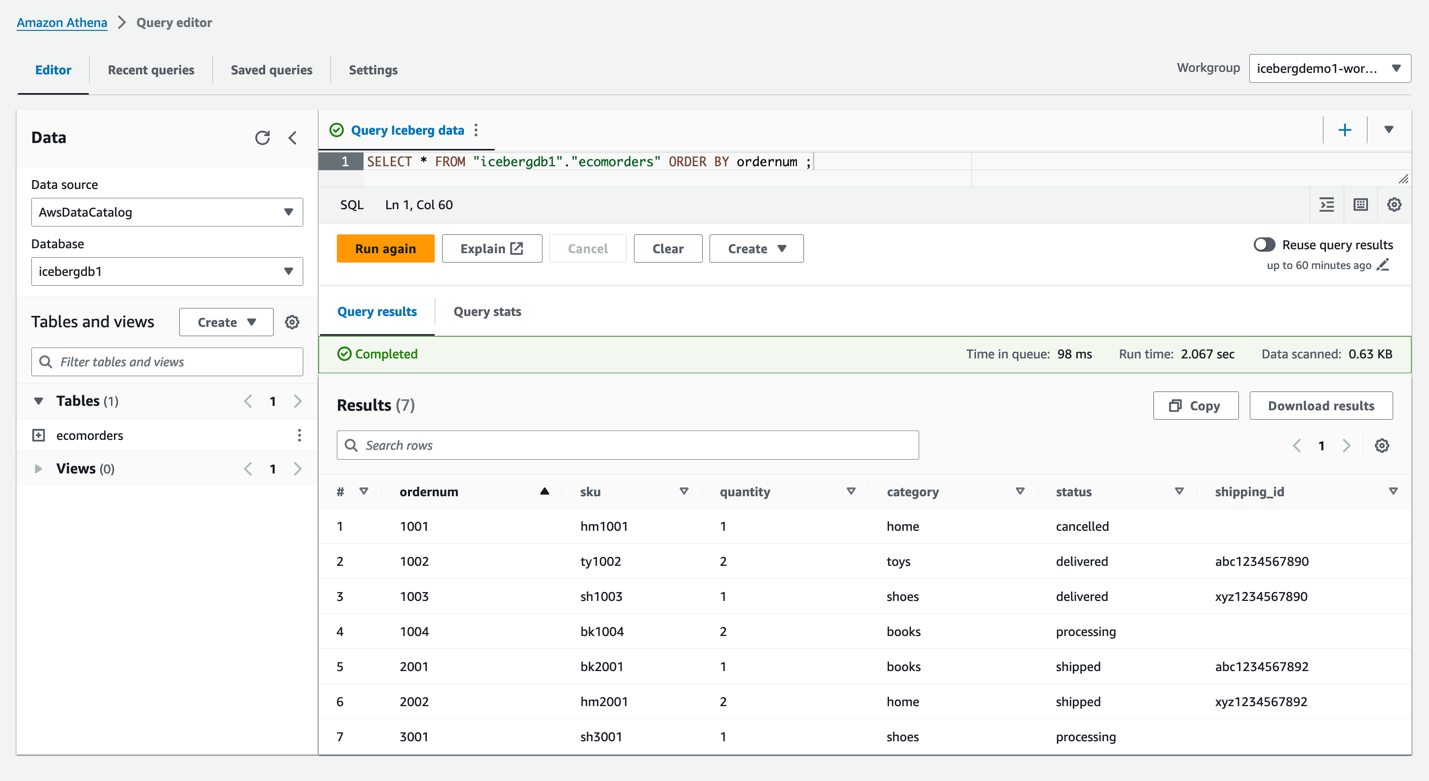
- 테이블의 현재 파티션을 보려면 다음 쿼리를 실행하세요.
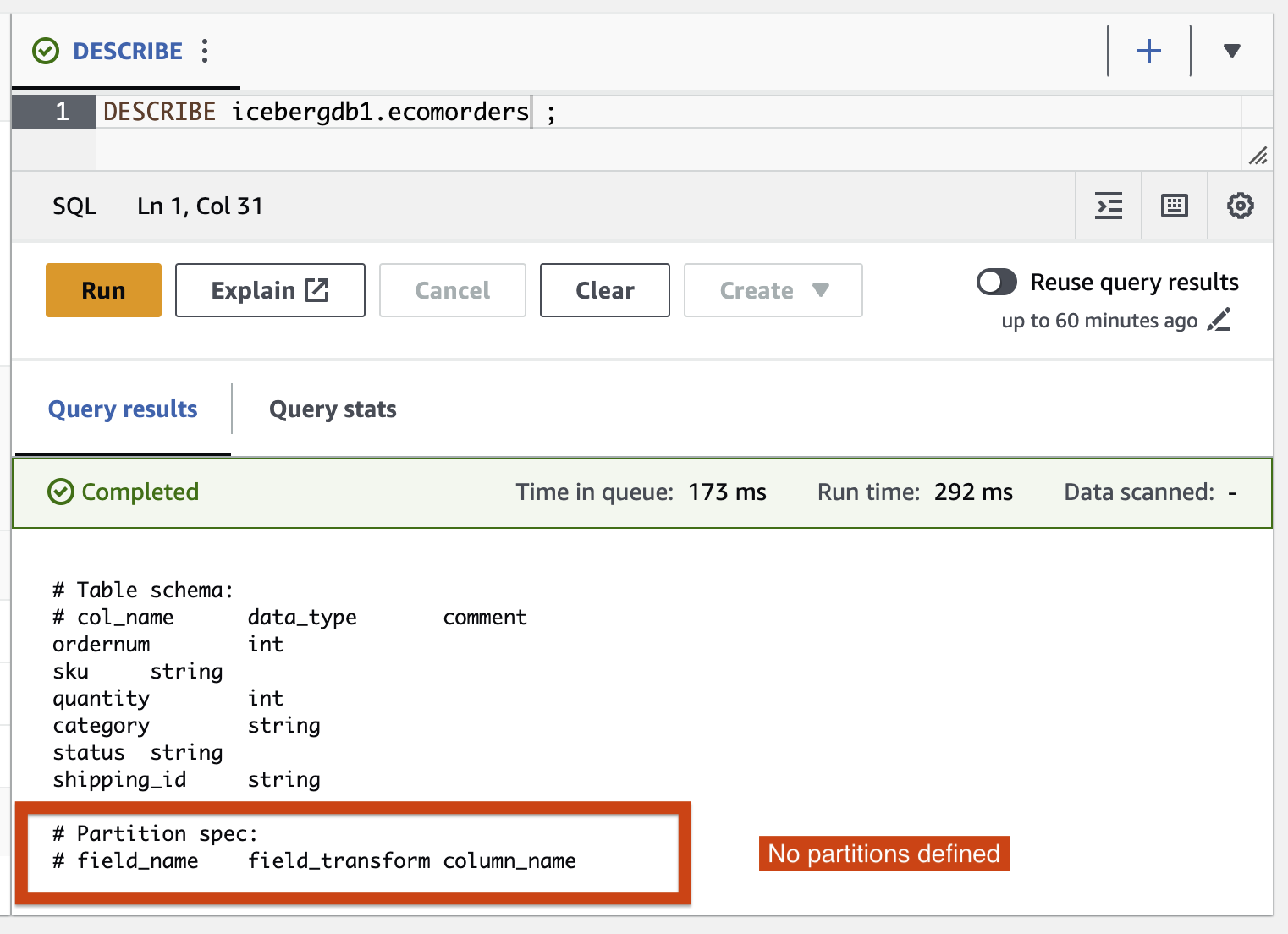
Partition-spec은 테이블이 분할되는 방식을 설명합니다. 이 예에서는 테이블에 파티션을 정의하지 않았기 때문에 파티션된 필드가 없습니다.
빙산 파티션 진화
파티션 구조를 변경해야 할 수도 있습니다. 예를 들어 다운스트림 분석에서 일반적인 쿼리 패턴의 추세 변화로 인해 발생합니다. 기존 테이블의 파티션 구조 변경은 전체 데이터 복사본이 필요한 중요한 작업입니다.
Iceberg는 이를 간단하게 설명합니다. Iceberg에서 파티션 구조를 변경할 때 데이터 파일을 다시 쓸 필요가 없습니다. 이전 파티션으로 작성된 이전 데이터는 변경되지 않습니다. 새로운 레이아웃의 새로운 사양을 사용하여 새로운 데이터가 기록됩니다. 각 파티션 버전의 메타데이터는 별도로 보관됩니다.
AWS Glue ETL 작업을 사용하여 Iceberg 테이블에 파티션 필드 범주를 추가해 보겠습니다. icebergdemo1-GlueETL2-partition-evolution:
AWS Glue 콘솔에서 ETL 작업을 실행합니다. icebergdemo1-GlueETL2-partition-evolution. 작업이 완료되면 Athena를 사용하여 파티션을 쿼리할 수 있습니다.
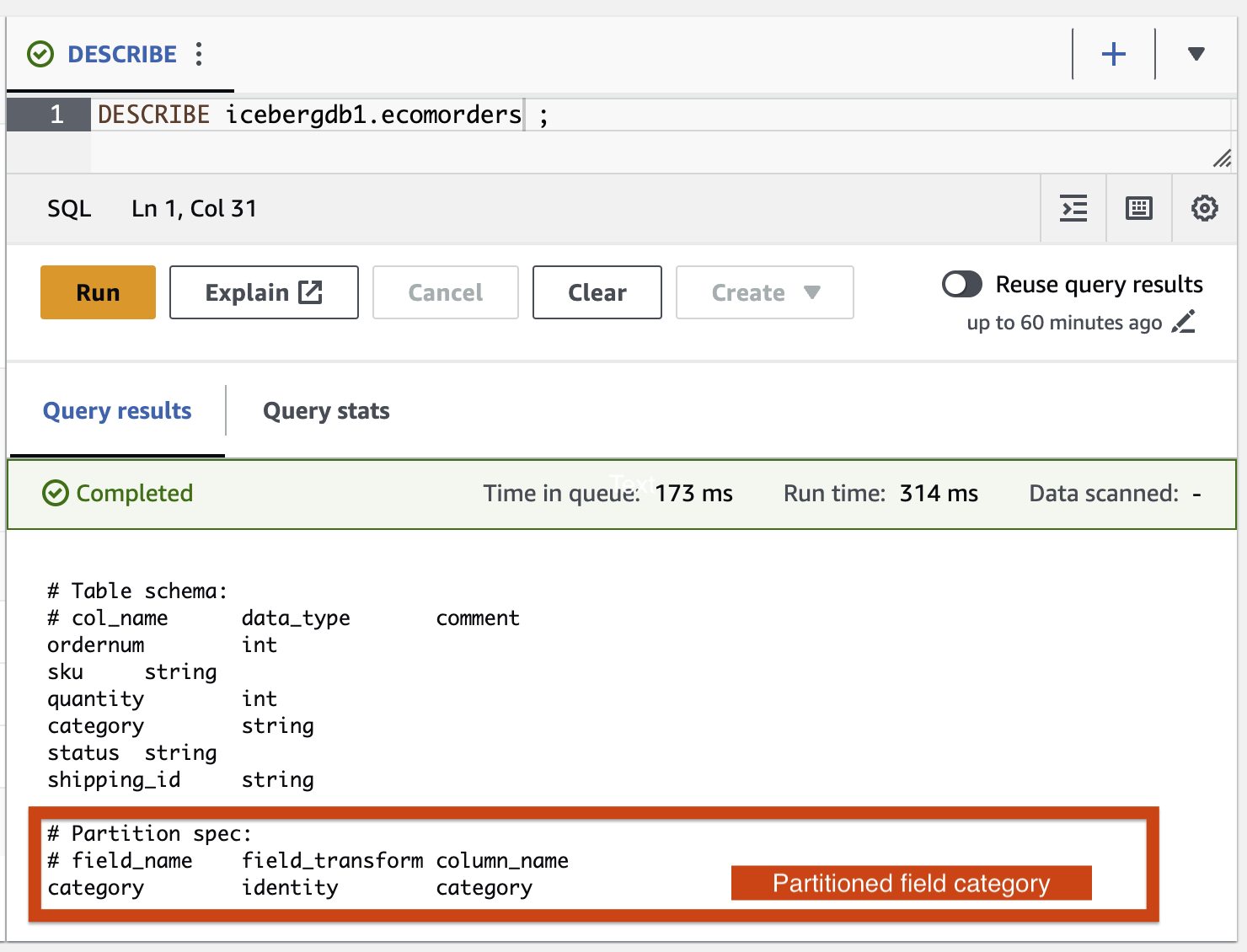
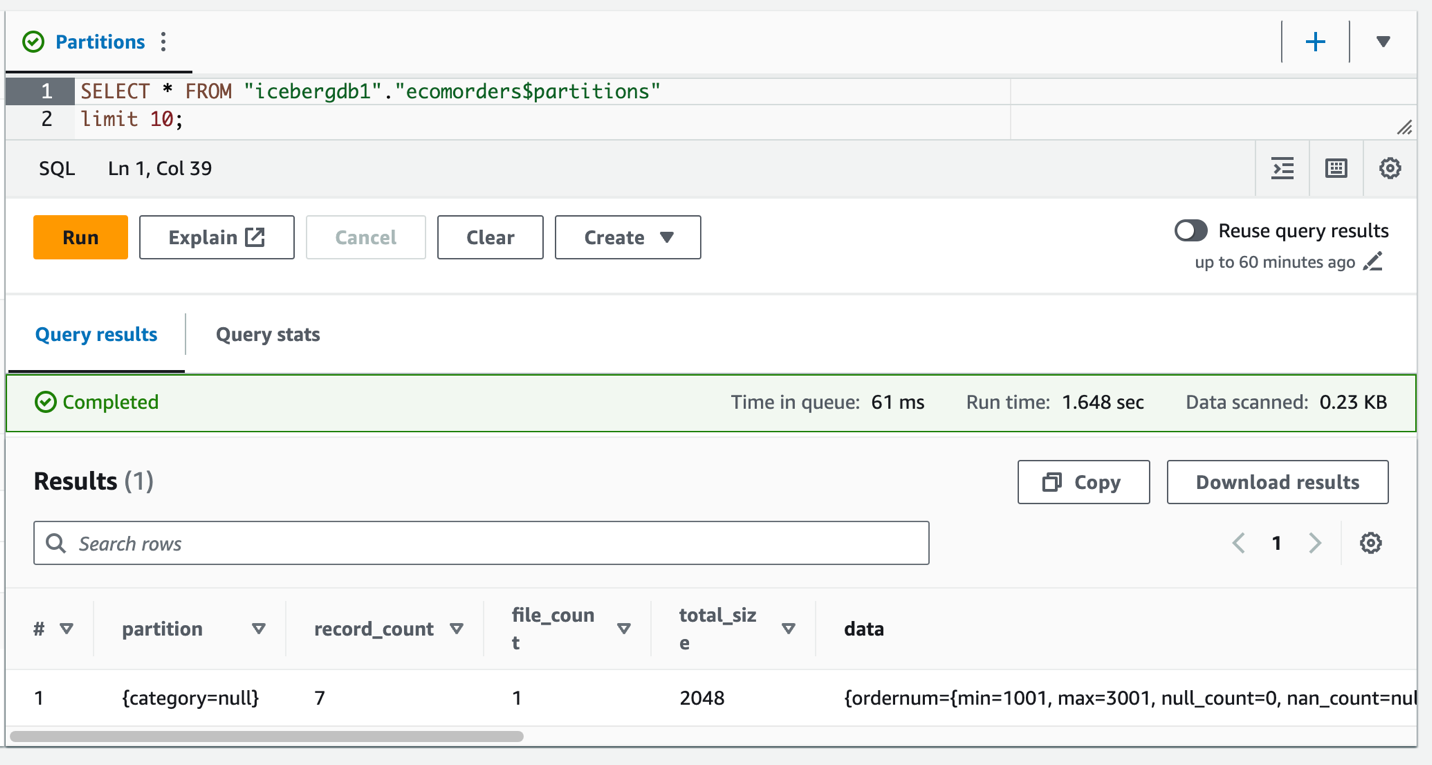
파티션 필드 범주를 볼 수 있지만 파티션 값은 null입니다. 파티션 진화는 메타데이터 작업이고 데이터 파일을 다시 쓰지 않으므로 데이터 폴더에는 새 데이터 파일이 없습니다. 데이터를 추가하거나 업데이트하면 해당 파티션 값이 채워지는 것을 볼 수 있습니다.
빙산 스키마 진화
Iceberg는 내부 테이블 진화를 지원합니다. 당신은 할 수 있습니다 테이블 스키마 발전 마치 SQL처럼요. Iceberg 스키마 업데이트는 메타데이터 변경이므로 스키마 발전을 수행하기 위해 데이터 파일을 다시 작성할 필요가 없습니다.
Iceberg 스키마 진화를 살펴보려면 ETL 작업을 실행하세요. icebergdemo1-GlueETL3-schema-evolution AWS Glue 콘솔을 통해. 작업은 다음 SparkSQL 문을 실행합니다.
Athena 쿼리 편집기에서 다음 쿼리를 실행합니다.

Iceberg 테이블의 스키마 변경 사항을 확인할 수 있습니다.
- 라는 새로운 열이 추가되었습니다.
shipping_carrier - 열
shipping_id로 이름이 변경되었습니다tracking_number - 열의 데이터 유형
ordernumint에서 bigint로 변경되었습니다.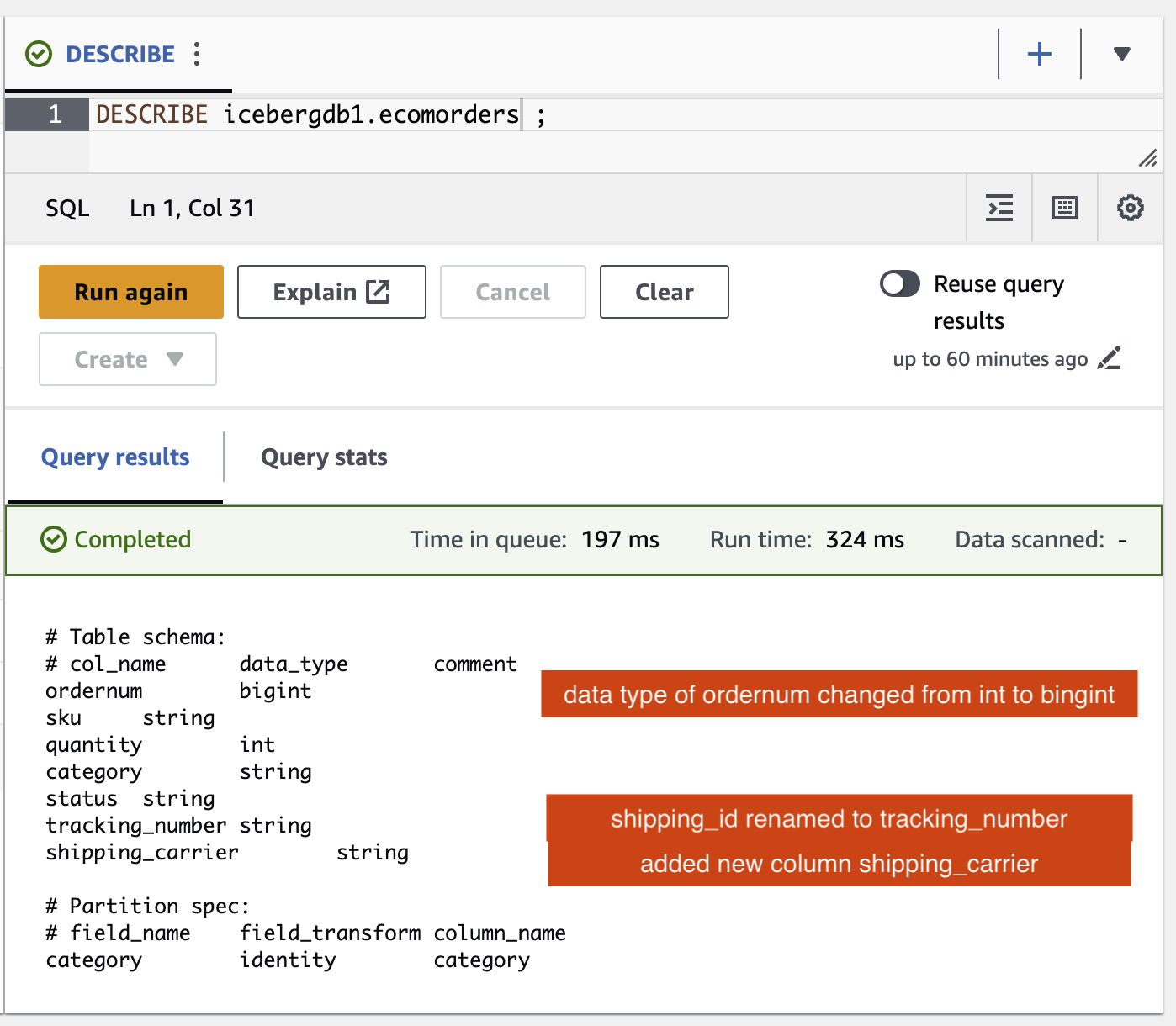
위치 업데이트
의 데이터 tracking_number 추적 번호와 연결된 배송업체가 포함되어 있습니다. 배송업체를 계속 유지하기 위해 이 데이터를 분할한다고 가정해 보겠습니다. shipping_carrier 필드 및 추적 번호 tracking_number 입력란입니다.
AWS Glue 콘솔에서 ETL 작업을 실행합니다. icebergdemo1-GlueETL4-update-table. 작업은 다음 SparkSQL 문을 실행하여 테이블을 업데이트합니다.
Iceberg 테이블을 쿼리하여 업데이트된 데이터를 확인하세요. tracking_number 과 shipping_carrier.
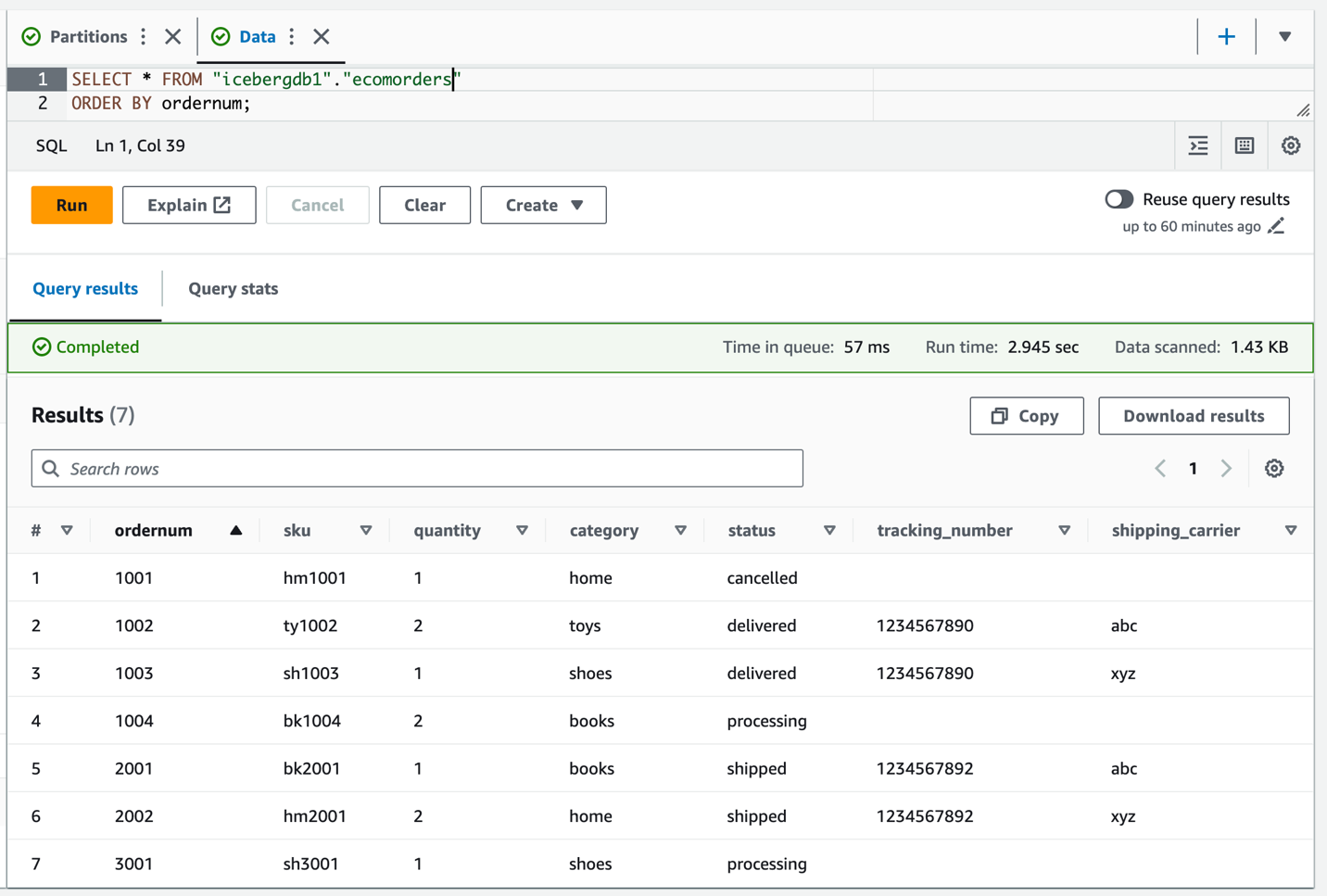
이제 테이블에서 데이터가 업데이트되었으므로 카테고리에 대해 파티션 값이 채워진 것을 볼 수 있습니다.

정리
향후 비용이 발생하지 않도록 생성한 리소스를 정리하세요.
- Lambda 콘솔에서 함수에 대한 세부 정보 페이지를 엽니다.
icebergdemo1-Lambda-Create-Iceberg-and-Grant-access. - . 환경 변수 섹션에서 키를 선택하세요.
Task_To_Perform값을 다음으로 업데이트합니다.CLEANUP. - 데이터베이스, 테이블 및 관련 LF-태그를 삭제하는 함수를 실행합니다.
- AWS CloudFormation 콘솔에서 icebergdemo1 스택을 삭제합니다.
결론
이 게시물에서는 AWS Glue API를 사용하여 Iceberg 테이블을 생성하고 Lake Formation을 사용하여 트랜잭션 데이터 레이크의 Iceberg 테이블에 대한 액세스를 제어했습니다. AWS Glue ETL 작업을 사용하면 데이터를 Iceberg 테이블에 병합하고 Iceberg 테이블을 다시 쓰거나 다시 생성하지 않고도 스키마 진화와 파티션 진화를 수행할 수 있습니다. Athena를 사용하여 Iceberg 데이터와 메타데이터를 쿼리했습니다.
이 게시물의 개념과 데모를 바탕으로 이제 Iceberg, AWS Glue, Lake Formation 및 Amazon S3를 사용하여 기업에서 트랜잭션 데이터 레이크를 구축할 수 있습니다.
저자에 관하여
 사티아 아디물라 보스턴에 본사를 둔 AWS의 수석 데이터 아키텍트입니다. 20년이 넘는 데이터 및 분석 경험을 바탕으로 Satya는 조직이 대규모 데이터에서 비즈니스 통찰력을 얻을 수 있도록 지원합니다.
사티아 아디물라 보스턴에 본사를 둔 AWS의 수석 데이터 아키텍트입니다. 20년이 넘는 데이터 및 분석 경험을 바탕으로 Satya는 조직이 대규모 데이터에서 비즈니스 통찰력을 얻을 수 있도록 지원합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/use-aws-glue-etl-to-perform-merge-partition-evolution-and-schema-evolution-on-apache-iceberg/

