개요
LangChain 및 LangFlow와 같은 도구가 도입되면서 대규모 언어 모델을 사용하여 애플리케이션을 구축할 때 작업이 더 쉬워졌습니다. 응용 프로그램을 구축하고 다양한 대형 언어 모델을 선택하는 것이 더 쉬워졌지만 개발자가 이러한 다양한 소스의 데이터를 변환해야 하기 때문에 LLM 기반 응용 프로그램을 개발하는 동안 데이터가 다양한 소스에서 나오는 데이터 업로드 부분은 여전히 시간이 많이 걸립니다. 일반 텍스트를 벡터 저장소에 삽입하기 전에. 이것이 바로 Embedchain이 등장하는 곳입니다. 이를 통해 모든 데이터 유형의 데이터를 간단하게 업로드하고 즉시 LLM 쿼리를 시작할 수 있습니다. 이번 글에서는 EmbedChain을 시작하는 방법을 살펴보겠습니다.
학습 목표
- LLM(대형 언어 모델)에 대한 데이터 관리 및 쿼리 프로세스를 단순화하는 데 있어 Embedchain의 중요성 이해
- 구조화되지 않은 데이터를 Embedchain에 효과적으로 통합하고 업로드하여 개발자가 다양한 데이터 소스를 원활하게 사용할 수 있도록 하는 방법을 알아보세요.
- embedchain이 지원하는 다양한 대형 언어 모델 및 벡터 저장소에 대해 알아보기
- 웹 페이지, 비디오 등 다양한 데이터 소스를 벡터 저장소에 추가하여 데이터 수집을 이해하는 방법을 알아보세요.
이 기사는 데이터 과학 블로그.
차례
Embedchain이란 무엇입니까?
Embedchain은 개발자가 여러 데이터 소스를 대규모 언어 모델과 원활하게 연결할 수 있는 Python/Javascript 라이브러리입니다. Embedchain을 사용하면 구조화되지 않은 데이터를 업로드, 색인화 및 검색할 수 있습니다. 구조화되지 않은 데이터는 텍스트, 웹사이트/YouTube 비디오 URL, 이미지 등과 같은 모든 유형이 될 수 있습니다.
Emdechain을 사용하면 단일 명령으로 이러한 비정형 데이터를 간단하게 업로드할 수 있으므로 이에 대한 벡터 임베딩을 생성하고 연결된 LLM을 통해 데이터로 즉시 쿼리를 시작할 수 있습니다. 그 뒤에서 embedchain은 소스에서 데이터를 로드하고 청크한 다음 벡터 임베딩을 생성하고 마지막으로 벡터 저장소에 저장하는 작업을 담당합니다.

Embedchain으로 첫 번째 앱 만들기
이 섹션에서는 embedchain 패키지를 설치하고 이를 사용하여 앱을 만듭니다. 첫 번째 단계는 아래와 같이 pip 명령을 사용하여 패키지를 설치하는 것입니다.
!pip install embedchain !pip install embedchain[huggingface-hub]- 첫 번째 명령문은 embedchain Python 패키지를 설치합니다.
- 다음 줄에서는 Huggingface-hub를 설치합니다. Hugging-face에서 제공하는 모델을 사용하려면 이 Python 패키지가 필요합니다.
이제 아래와 같이 Hugging Face Inference API Token을 저장하기 위한 환경 변수를 생성하겠습니다. Hugging Face 웹사이트에 로그인한 후 토큰을 생성하면 추론 API 토큰을 얻을 수 있습니다.
import os os.environ["HUGGINGFACE_ACCESS_TOKEN"] = "Hugging Face Inferenece API Token"Embedchain 라이브러리는 위에 제공된 토큰을 사용하여 포옹하는 얼굴 모델을 추론합니다. 다음으로, Huggingface에서 사용하려는 모델을 정의하는 YAML 파일을 생성해야 합니다. YAML 파일은 LLM 애플리케이션의 구성을 정의하는 간단한 키-값 저장소로 간주될 수 있습니다. 이러한 구성에는 사용할 LLM 모델 또는 사용할 임베딩 모델이 포함될 수 있습니다. YAML 파일에 대해 자세히 알아보려면 다음을 클릭하세요. 여기에서 지금 확인해 보세요.). 다음은 YAML 파일의 예입니다.
config = """
llm: provider: huggingface config: model: 'google/flan-t5-xxl' temperature: 0.7 max_tokens: 1000 top_p: 0.8 embedder: provider: huggingface config: model: 'sentence-transformers/all-mpnet-base-v2' """ with open('huggingface_model.yaml', 'w') as file: file.write(config)- Python 자체에서 YAML 파일을 생성하고 이를 다음과 같은 파일에 저장합니다. Huggingface_model.yaml.
- 이 YAML 파일에서는 모델 매개변수와 사용되는 임베딩 모델까지 정의합니다.
- 위에서는 제공자를huggingface로 지정했으며 플랜-T5 다음을 포함하는 다양한 구성/매개변수를 갖춘 모델 온도 모델의, max_tokens(즉, 출력 길이), 심지어 top_p 값.
- 임베딩 모델로는 Huggingface의 유명한 임베딩 모델을 사용하고 있습니다. 모든-mpnet-베이스-v2, 모델에 대한 임베딩 벡터 생성을 담당합니다.
YAML 구성
다음으로 위의 YAML 구성 파일을 사용하여 앱을 만듭니다.
from embedchain import Pipeline as App app = App.from_config(yaml_path="huggingface_model.yaml")- 여기서는 embedchain에서 파이프라인 개체를 앱으로 가져옵니다. 파이프라인 개체는 위에서 정의한 대로 다양한 구성을 사용하는 LLM 앱을 생성하는 일을 담당합니다.
- 앱은 YAML 파일에 지정된 모델을 사용하여 LLM을 생성합니다. 이에 앱, 다양한 데이터 소스의 데이터를 제공할 수 있고 동일한 앱에 쿼리 메서드를 호출하여 제공된 데이터에 대해 LLM을 쿼리할 수 있습니다.
- 이제 몇 가지 데이터를 추가해 보겠습니다.
app.add("https://en.wikipedia.org/wiki/Alphabet_Inc.")- XNUMXD덴탈의 앱.추가() 메서드는 데이터를 가져와서 벡터 저장소에 추가합니다.
- Embedchain은 웹 페이지에서 데이터를 수집하여 청크로 생성한 다음 데이터에 대한 임베딩을 생성하는 작업을 담당합니다.
- 그런 다음 데이터는 벡터 데이터베이스에 저장됩니다. Embedchain에서 사용되는 기본 데이터베이스는chromdb입니다.
- 이 예에서는 Google의 모회사인 Alphabet의 Wikipedia 페이지를 앱에 추가합니다.
업로드된 데이터를 기반으로 앱을 쿼리해 보겠습니다.

위 이미지에서 질문() 방법에 대해 우리는 우리에게 물었습니다. 앱 즉, flan-t5 모델에 추가된 데이터와 관련된 두 가지 질문입니다. 앱. 모델은 정확하게 대답할 수 있었습니다. 이런 방식으로 여러 데이터 소스를 모델에 전달하여 모델에 추가할 수 있습니다. 더하다() 메서드를 사용하면 내부적으로 처리되고 임베딩이 생성되며 마지막으로 벡터 저장소에 추가됩니다. 그런 다음 다음을 사용하여 데이터를 쿼리할 수 있습니다. 질문() 방법.
다른 모델 및 벡터 저장소로 앱 구성
이전 예에서는 웹사이트를 데이터로 추가하고 포옹 얼굴 모델을 앱의 기본 대형 언어 모델로 추가하는 애플리케이션을 준비하는 방법을 살펴보았습니다. 이 섹션에서는 Embedchain이 얼마나 유연할 수 있는지 알아보기 위해 다른 모델과 다른 벡터 데이터베이스를 어떻게 사용할 수 있는지 살펴보겠습니다. 이 예에서는 Zilliz Cloud를 벡터 데이터베이스로 사용하므로 아래와 같이 해당 Python 클라이언트를 다운로드해야 합니다.
!pip install --upgrade embedchain[milvus] !pip install pytube- 위에서는 Zilliz Cloud와 상호 작용할 수 있는 Pymilvus Python 패키지를 다운로드합니다.
- pytube 라이브러리를 사용하면 YouTube 비디오를 텍스트로 변환하여 Vector Store에 저장할 수 있습니다.
- 다음으로 Zilliz Cloud로 무료 계정을 만들 수 있습니다. 무료 계정을 만든 후 Zilliz Cloud 대시보드로 이동하여 클러스터를 생성하세요.
클러스터를 생성한 후 아래와 같이 연결하기 위한 자격 증명을 얻을 수 있습니다.

OpenAI API 키
퍼블릭 엔드포인트와 토큰을 복사하여 Zilliz Cloud Vector Store에 연결하는 데 필요하므로 다른 곳에 저장하세요. 이제 대규모 언어 모델의 경우 이번에는 OpenAI GPT 모델을 사용하겠습니다. 따라서 앞으로 나아가려면 OpenAI API 키도 필요합니다. 모든 키를 얻은 후 아래와 같이 환경 변수를 만듭니다.
os.environ["OPENAI_API_KEY"]="Your OpenAI API Key" os.environ["ZILLIZ_CLOUD_TOKEN"]= "Your Zilliz Cloud Token" os.environ["ZILLIZ_CLOUD_URI"]= "Your Zilliz Cloud Public Endpoint"위의 내용은 Zilliz Cloud 및 OpenAI에 필요한 모든 자격 증명을 환경 변수로 저장합니다. 이제 다음과 같이 앱을 정의할 차례입니다.
from embedchain.vectordb.zilliz import ZillizVectorDB app = App(db=ZillizVectorDB()) app.add("https://www.youtube.com/watch?v=ZnEgvGPMRXA")- 여기에서는 먼저 다음을 가져옵니다. 질리즈벡터DB embedchain에서 제공하는 클래스입니다.
- 그런 다음 새 앱을 만들 때 다음을 전달합니다. 질리즈벡터DB() ~로 db App() 함수 내부의 변수입니다.
- LLM을 지정하지 않았으므로 기본 LLM은 OpenAI GPT 3.5로 선택됩니다.
- 이제 우리 앱은 OpenAI를 LLM으로, Zilliz를 Vector Store로 정의합니다.
- 다음으로, 다음을 사용하여 앱에 YouTube 비디오를 추가합니다. 더하다() 방법.
- YouTube 동영상을 추가하는 것은 URL을 전달하는 것만큼 간단합니다. 더하다() 기능을 사용하면 모든 비디오에서 텍스트로의 변환이 embedchain에 의해 추상화되어 간단해집니다.
질리즈 클라우드
이제 비디오는 먼저 텍스트로 변환된 다음 OpenAI 임베딩 모델에 의해 청크로 생성되고 벡터 임베딩으로 변환됩니다. 이러한 임베딩은 Zilliz Cloud 내부에 저장됩니다. Zilliz Cloud로 이동하여 클러스터 내부를 확인하면 "라는 이름의 새로운 수집을 찾을 수 있습니다.embedchain_store”, 앱에 추가하는 모든 데이터가 저장되는 위치:
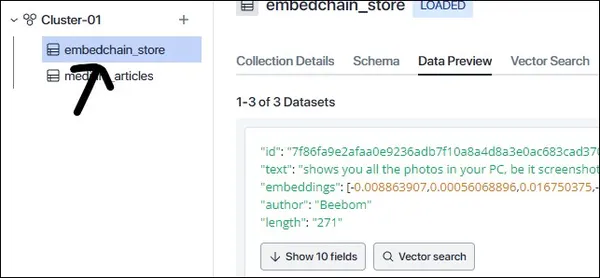
보시다시피 '라는 이름으로 새 컬렉션이 생성되었습니다.embedchain_store” 그리고 이 컬렉션에는 이전 단계에서 추가한 데이터가 포함되어 있습니다. 이제 앱을 쿼리하겠습니다.

앱에 추가된 영상은 새로운 Windows 11 업데이트에 관한 내용입니다. 위 이미지에서는 영상에서 언급된 질문을 앱에 물어봅니다. 그리고 앱은 질문에 정확하게 대답합니다. 이 두 가지 예에서 우리는 EmbedChain을 통해 다양한 대형 언어 모델과 다양한 데이터베이스를 사용하는 방법을 살펴봤고 웹페이지와 YouTube 동영상과 같은 다양한 유형의 데이터도 업로드했습니다.
Embedchain이 지원하는 LLM 및 벡터 스토어
Embedchain은 출시 이후 다양한 대규모 언어 모델 및 벡터 데이터베이스를 지원하여 크게 성장해 왔습니다. 지원되는 대규모 언어 모델은 아래에서 볼 수 있습니다.
- 포옹 얼굴 모델
- OpenAI
- Azure OpenAI
- 인류
- 라마2
- 코어
- 지나챗
- 버텍스 AI
- GPT4올
광범위한 대규모 언어 모델을 지원하는 것 외에도 embedchain은 아래 목록에서 볼 수 있는 많은 벡터 데이터베이스에 대한 지원도 제공합니다.
- 크로마DB
- 탄성
- 오픈 검색
- 질 리츠
- 솔방울
- 위비하다
- 사분면
- 랜스DB
이 외에도 향후 embedchain은 더 많은 대형 언어 모델 및 벡터 데이터베이스에 대한 지원을 추가할 것입니다.
결론
대규모 언어 모델을 사용하여 애플리케이션을 구축하는 동안 가장 큰 과제는 데이터를 처리할 때, 즉 다양한 데이터 소스에서 오는 데이터를 처리하는 것입니다. 모든 데이터 소스는 결국 임베딩으로 변환되기 전에 단일 유형으로 변환되어야 합니다. 그리고 모든 데이터 소스에는 비디오 처리를 위한 별도의 라이브러리, 웹 사이트 처리를 위한 다른 라이브러리 등이 있는 것처럼 이를 처리하는 고유한 방법이 있습니다. 따라서 우리는 모든 어려운 작업을 수행하여 기본 변환에 대한 걱정 없이 모든 데이터 소스의 데이터를 통합할 수 있게 해주는 Embedchain Python 패키지를 통해 이 문제에 대한 솔루션을 살펴보았습니다.
주요 요점
이 기사의 주요 내용은 다음과 같습니다.
- Embedchain은 대규모 언어 모델 세트를 지원하므로 이들 중 어떤 모델과도 작업할 수 있습니다.
- 또한 Embedchain은 많은 인기 있는 벡터 스토어와 통합됩니다.
- 간단한 더하다() 메서드를 사용하면 벡터 저장소에 모든 유형의 데이터를 저장할 수 있습니다.
- Embedchain을 사용하면 LLM과 벡터 DB 간 전환이 더 쉬워지고 데이터를 추가하고 쿼리하는 간단한 방법을 제공합니다.
자주 묻는 질문
A. Embedchain은 사용자가 모든 유형의 데이터를 추가하고 이를 벡터 저장소에 저장하여 모든 대형 언어 모델로 쿼리할 수 있게 해주는 Python 도구입니다.
A. 우리가 선택한 벡터 데이터베이스는 config.yaml 파일을 통해 또는 직접 개발 중인 앱에 제공될 수 있습니다. 앱() 클래스에 데이터베이스를 전달하여 "db” 매개변수 내부 앱() 클래스입니다.
A. 네, Chromdb와 같은 로컬 벡터 데이터베이스를 사용하는 경우 더하다() 방법을 사용하면 데이터가 벡터 임베딩으로 변환된 다음 "폴더 아래에 로컬로 유지되는chromdb와 같은 벡터 데이터베이스에 저장됩니다.db".
A. 아니요, 그렇지 않습니다. 구성을 직접 전달하여 애플리케이션을 구성할 수 있습니다. 앱() 변수를 사용하거나 대신 config.yaml을 사용하여 YAML 파일에서 앱을 생성합니다. Config.yaml 파일은 결과를 복제하는 데 유용합니다/우리 애플리케이션의 구성을 다른 사람과 공유하고 싶지만 반드시 사용해야 하는 것은 아닙니다.
A. Embedchain은 CSV, JSON, Notion, mdx 파일, docx, 웹 페이지, YouTube 비디오, PDF 등을 포함한 다양한 데이터 소스에서 나오는 데이터를 지원합니다. Embedchain은 이러한 모든 데이터 소스를 처리하는 방식을 추상화하므로 데이터를 더 쉽게 추가할 수 있습니다.
참고자료
embedchain과 해당 아키텍처에 대해 자세히 알아보려면 공식 문서 페이지와 Github Repository를 참조하세요.
- https://docs.embedchain.ai
- https://github.com/embedchain/embedchain
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/11/embedchain-a-data-platform-tailored-for-llms/

