2022 년 말까지 AWS는 실시간 스트리밍 수집의 일반 가용성을 발표했습니다. 에 아마존 레드 시프트 for Amazon Kinesis 데이터 스트림 과 Apache Kafka 용 Amazon Managed Streaming (Amazon MSK), 스트리밍 데이터를 스테이지할 필요가 없습니다. Amazon Simple Storage Service(Amazon S3) Amazon Redshift에 수집하기 전에.
스트리밍 수집 Amazon MSK에서 Amazon Redshift까지, 실시간 데이터 처리 및 분석에 대한 최첨단 접근 방식을 나타냅니다. Amazon MSK는 확장성이 뛰어나고 Apache Kafka를 위한 완전 관리형 서비스 역할을 하여 방대한 데이터 스트림을 원활하게 수집하고 처리할 수 있습니다. 스트리밍 데이터를 Amazon Redshift에 통합하면 조직이 실시간 분석 및 데이터 중심 의사 결정의 잠재력을 활용할 수 있도록 지원하여 엄청난 가치를 얻을 수 있습니다.
이 통합을 통해 초당 수백 메가바이트의 스트리밍 데이터를 Amazon Redshift로 수집하면서 초 단위로 측정되는 낮은 지연 시간을 달성할 수 있습니다. 동시에 이러한 통합은 최신 정보를 즉시 분석에 사용할 수 있도록 하는 데 도움이 됩니다. 통합에는 Amazon S3의 스테이징 데이터가 필요하지 않기 때문에 Amazon Redshift는 중간 스토리지 비용 없이 더 낮은 지연 시간으로 스트리밍 데이터를 수집할 수 있습니다.
SQL 문을 사용하여 Redshift 클러스터에서 Amazon Redshift 스트리밍 수집을 구성하여 MSK 주제를 인증하고 연결할 수 있습니다. 이 솔루션은 데이터 파이프라인을 단순화하고 운영 비용을 절감하려는 데이터 엔지니어에게 탁월한 옵션입니다.
이 게시물에서는 구성 방법에 대한 전체 개요를 제공합니다. Amazon Redshift 스트리밍 수집 아마존 MSK에서.
솔루션 개요
다음 아키텍처 다이어그램은 귀하가 사용할 AWS 서비스와 기능을 설명합니다.

워크 플로우에는 다음 단계가 포함됩니다.
- 구성부터 시작합니다. 아마존 MSK 커넥트 소스 커넥터를 사용하여 MSK 주제를 생성하고, 모의 데이터를 생성하고, 이를 MSK 주제에 씁니다. 이 게시물에서는 모의 고객 데이터를 사용하여 작업합니다.
- 다음 단계는 다음을 사용하여 Redshift 클러스터에 연결하는 것입니다. 쿼리 편집기 v2.
- 마지막으로 외부 스키마를 구성하고 Amazon Redshift에서 구체화된 보기를 생성하여 MSK 주제의 데이터를 사용합니다. 이 솔루션은 Amazon MSK에서 Amazon Redshift로 데이터를 내보내는 데 MSK Connect 싱크 커넥터를 사용하지 않습니다.
다음 솔루션 아키텍처 다이어그램에서는 사용할 AWS 서비스의 구성 및 통합을 더 자세히 설명합니다.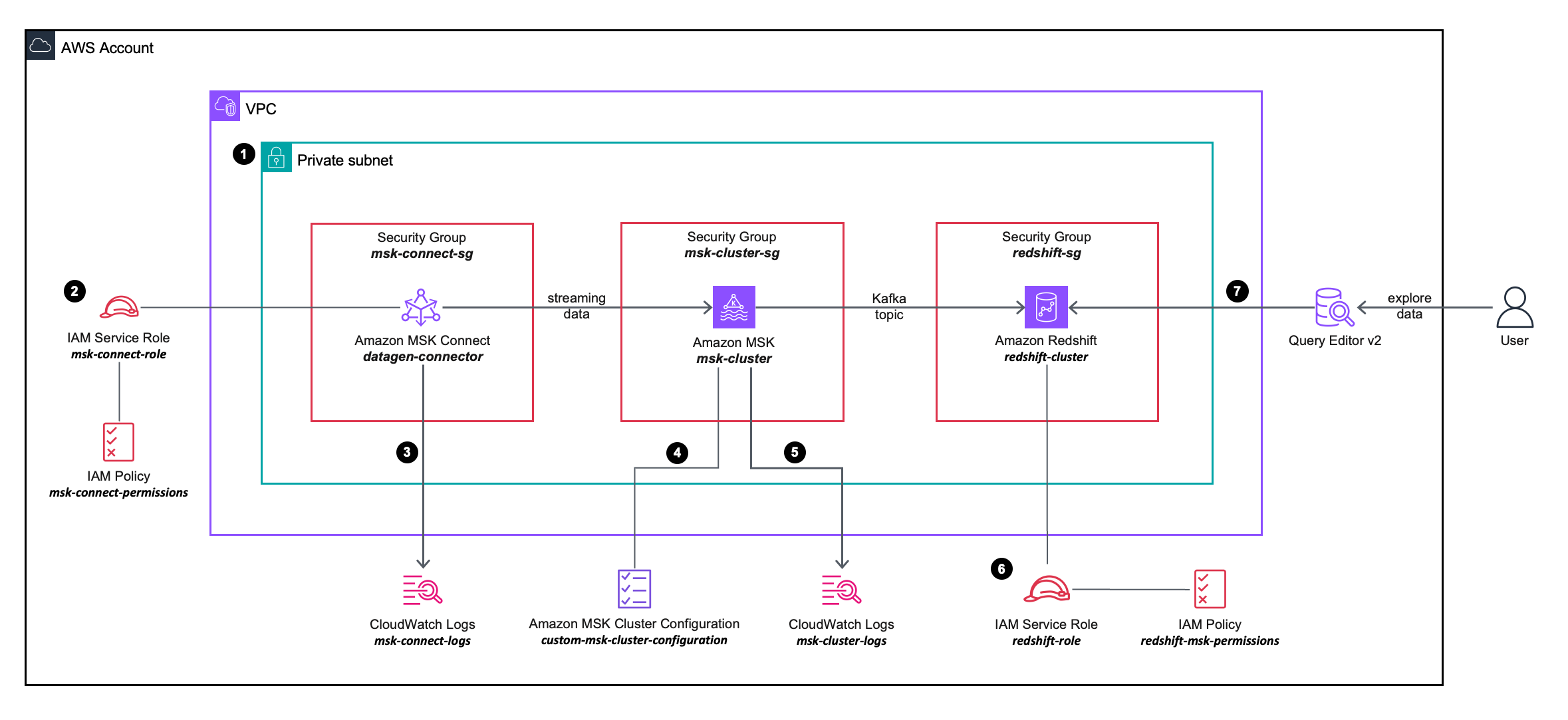
워크 플로우에는 다음 단계가 포함됩니다.
- MSK Connect 소스 커넥터, MSK 클러스터 및 Redshift 클러스터를 VPC의 프라이빗 서브넷 내에 배포합니다.
- MSK Connect 소스 커넥터는 AWS 자격 증명 및 액세스 관리 (IAM) 인라인 정책 에 첨부 IAM 역할이를 통해 소스 커넥터가 MSK 클러스터에서 작업을 수행할 수 있습니다.
- MSK Connect 소스 커넥터 로그가 캡처되어 다음으로 전송됩니다. 아마존 클라우드 워치 로그 그룹.
- MSK 클러스터는 사용자 정의 MSK 클러스터 구성, MSK Connect 커넥터가 MSK 클러스터에 주제를 생성할 수 있도록 허용합니다.
- MSK 클러스터 로그가 캡처되어 Amazon CloudWatch 로그 그룹으로 전송됩니다.
- Redshift 클러스터는 IAM 역할에 연결된 IAM 인라인 정책에 정의된 세분화된 권한을 사용합니다. 이를 통해 Redshift 클러스터는 MSK 클러스터에서 작업을 수행할 수 있습니다.
- 쿼리 편집기 v2를 사용하여 Redshift 클러스터에 연결할 수 있습니다.
사전 조건
필수 구성 요소 리소스의 프로비저닝 및 구성을 단순화하려면 다음을 사용할 수 있습니다. AWS 클라우드 포메이션 주형:
![]()
스택을 시작할 때 다음 단계를 완료하십시오.
- 럭셔리 스택 이름, 스택에 대해 의미 있는 이름을 입력하십시오. 예를 들어,
prerequisites. - 왼쪽 메뉴에서 다음.
- 왼쪽 메뉴에서 다음.
- 선택 AWS CloudFormation이 사용자 지정 이름으로 IAM 리소스를 생성 할 수 있음을 인정합니다.
- 왼쪽 메뉴에서 제출하십시오.
CloudFormation 스택은 다음 리소스를 생성합니다.
- VPC
custom-vpc, 3개의 가용 영역에 걸쳐 생성되었으며, 퍼블릭 서브넷 세 프라이빗 서브넷:- 퍼블릭 서브넷은 퍼블릭 라우팅 테이블과 연결되어 있으며 아웃바운드 트래픽은 인터넷 게이트웨이로 전달됩니다.
- 프라이빗 서브넷은 프라이빗 라우팅 테이블과 연결되고 아웃바운드 트래픽은 NAT 게이트웨이로 전송됩니다.
- An 인터넷 게이트웨이 Amazon VPC에 연결됩니다.
- A NAT 게이트웨이 이는 다음과 연관되어 있습니다. 탄력적 IP 퍼블릭 서브넷 중 하나에 배포됩니다.
- 세 보안 그룹:
msk-connect-sg, 이는 나중에 MSK Connect 커넥터와 연결됩니다.redshift-sg, 이는 나중에 Redshift 클러스터와 연결됩니다.msk-cluster-sg, 이는 나중에 MSK 클러스터와 연결됩니다. 인바운드 트래픽을 허용합니다.msk-connect-sg및redshift-sg.
- 2개의 CloudWatch 로그 그룹:
msk-connect-logs, MSK Connect 로그에 사용됩니다.msk-cluster-logs, MSK 클러스터 로그에 사용됩니다.
- 두 가지 IAM 역할:
msk-connect-role, 여기에는 MSK Connect에 대한 세분화된 IAM 권한이 포함됩니다.redshift-role, 여기에는 Amazon Redshift에 대한 세분화된 IAM 권한이 포함됩니다.
- A 사용자 정의 MSK 클러스터 구성, MSK Connect 커넥터가 MSK 클러스터에 주제를 생성할 수 있도록 허용합니다.
- 3개의 프라이빗 서브넷에 걸쳐 3개의 브로커가 배포된 MSK 클러스터
custom-vpc. XNUMXD덴탈의msk-cluster-sg보안 그룹과custom-msk-cluster-configuration구성은 MSK 클러스터에 적용됩니다. 브로커 로그는msk-cluster-logsCloudWatch 로그 그룹. - A Redshift 클러스터 서브넷 그룹, 이는 3개의 프라이빗 서브넷을 사용하고 있습니다.
custom-vpc. - Redshift 클러스터 서브넷 그룹 내의 프라이빗 서브넷에 배포된 단일 노드가 있는 Redshift 클러스터. 그만큼
redshift-sg보안 그룹 및redshift-roleIAM 역할은 Redshift 클러스터에 적용됩니다.
MSK Connect 사용자 정의 플러그인 생성
이 게시물에는 Amazon MSK 데이터 생성기 MSK Connect에 배포하여 모의 고객 데이터를 생성하고 이를 MSK 주제에 씁니다.
다음 단계를 완료하십시오.
- 를 다운로드 Amazon MSK 데이터 생성기 GitHub의 종속성이 포함된 JAR 파일입니다.

- AWS 계정의 S3 버킷에 JAR 파일을 업로드합니다.
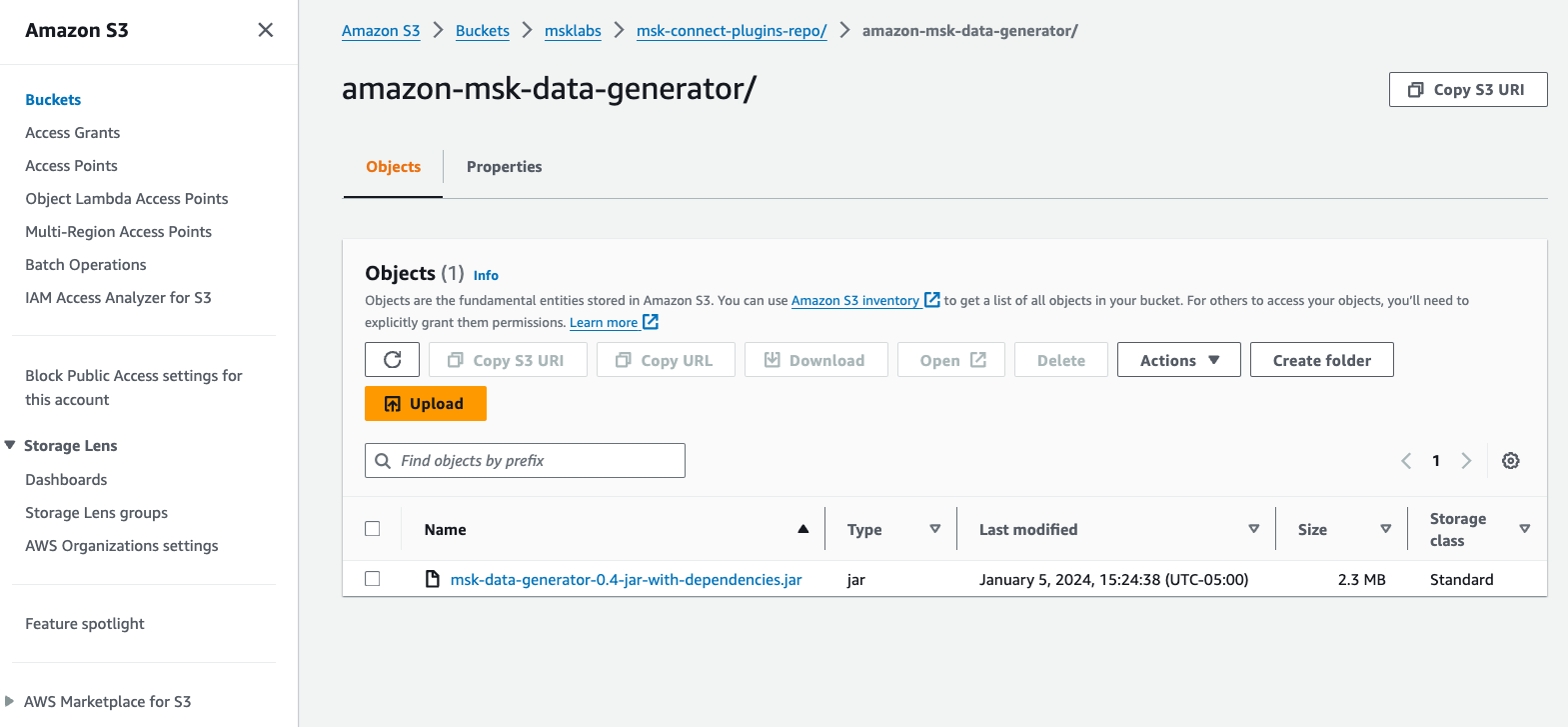
- Amazon MSK 콘솔에서 다음을 선택합니다. 커스텀 플러그인 아래에 MSK 연결 탐색 창에서
- 왼쪽 메뉴에서 사용자 정의 플러그인을 만듭니다.
- 왼쪽 메뉴에서 S3 찾아보기, Amazon S3에 업로드한 Amazon MSK 데이터 생성기 JAR 파일을 검색한 다음 선택 왼쪽 메뉴에서.
- 럭셔리 맞춤 플러그인 이름, 입력
msk-datagen-plugin. - 왼쪽 메뉴에서 사용자 정의 플러그인을 만듭니다.
사용자 정의 플러그인이 생성되면 해당 상태가 다음과 같이 표시됩니다. 최근활동, 다음 단계로 넘어갈 수 있습니다.
MSK Connect 커넥터 만들기
커넥터를 생성하려면 다음 단계를 완료하세요.
- Amazon MSK 콘솔에서 다음을 선택합니다. 커넥터 아래에 MSK 연결 탐색 창에서
- 왼쪽 메뉴에서 커넥터를 만듭니다.
- 럭셔리 맞춤 플러그인 유형선택한다. 기존 플러그인을 사용하세요.
- 선택
msk-datagen-plugin다음을 선택 다음. - 럭셔리 커넥터 이름, 입력
msk-datagen-connector. - 럭셔리 클러스터 유형선택한다. 자체 관리형 Apache Kafka 클러스터.
- 럭셔리 VPC선택한다.
custom-vpc. - 럭셔리 서브넷 1에서 첫 번째 가용 영역 내의 프라이빗 서브넷을 선택합니다.
다음 custom-vpc CloudFormation 템플릿으로 생성되었으므로 퍼블릭 서브넷에는 홀수 CIDR 범위를 사용하고 프라이빗 서브넷에는 CIDR 범위도 사용합니다.
-
- 퍼블릭 서브넷의 CIDR은 10.10.1.0/24, 10.10.3.0/24 및 10.10.5.0/24입니다.
- 프라이빗 서브넷의 CIDR은 10.10.2.0/24, 10.10.4.0/24 및 10.10.6.0/24입니다.
- 럭셔리 서브넷 2에서 두 번째 가용 영역 내의 프라이빗 서브넷을 선택합니다.
- 럭셔리 서브넷 3에서 세 번째 가용 영역 내의 프라이빗 서브넷을 선택합니다.
- 럭셔리 부트스트랩 서버에서 MSK 클러스터의 TLS 인증을 위한 부트스트랩 서버 목록을 입력하세요.
에 MSK 클러스터의 부트스트랩 서버 검색, Amazon MSK 콘솔로 이동하여 클러스터선택한다.
msk-cluster다음을 선택 고객 정보 보기. 부트스트랩 서버의 TLS 값을 복사합니다.
- 럭셔리 보안 그룹선택한다.
이 클러스터에 대한 액세스 권한이 있는 특정 보안 그룹을 사용하십시오., 선택
msk-connect-sg. - 럭셔리 커넥터 구성, 기본 설정을 다음으로 바꿉니다.
- 커넥터 용량으로 다음을 선택합니다. 프로비저닝됨.
- 럭셔리 작업자당 MCU 수선택한다. 1.
- 럭셔리 근로자 수선택한다. 1.
- 럭셔리 작업자 구성선택한다. MSK 기본 구성 사용.
- 럭셔리 액세스 권한선택한다.
msk-connect-role. - 왼쪽 메뉴에서 다음.
- 암호화의 경우 다음을 선택합니다. TLS 암호화 트래픽.
- 왼쪽 메뉴에서 다음.
- 럭셔리 로그 전달선택한다. Amazon CloudWatch Logs에 전달.
- 왼쪽 메뉴에서 검색, 고르다
msk-connect-logs, 선택 왼쪽 메뉴에서. - 왼쪽 메뉴에서 다음.
- 검토 및 선택 커넥터를 만듭니다.
사용자 지정 커넥터가 생성되면 해당 상태가 다음과 같이 표시됩니다. 달리는, 다음 단계로 넘어갈 수 있습니다.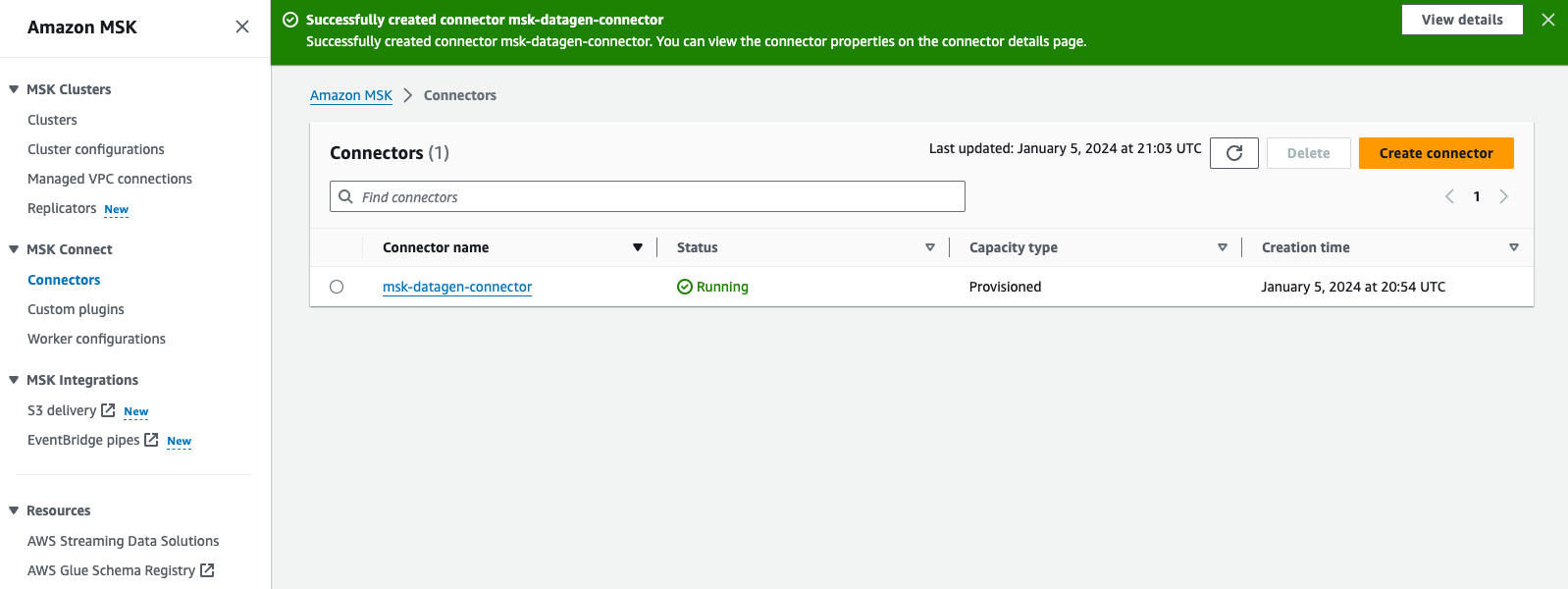
Amazon MSK에 대한 Amazon Redshift 스트리밍 수집 구성
스트리밍 수집을 설정하려면 다음 단계를 완료하세요.
- Query Editor v2를 사용하여 Redshift 클러스터에 연결하고 데이터베이스 사용자 이름으로 인증합니다.
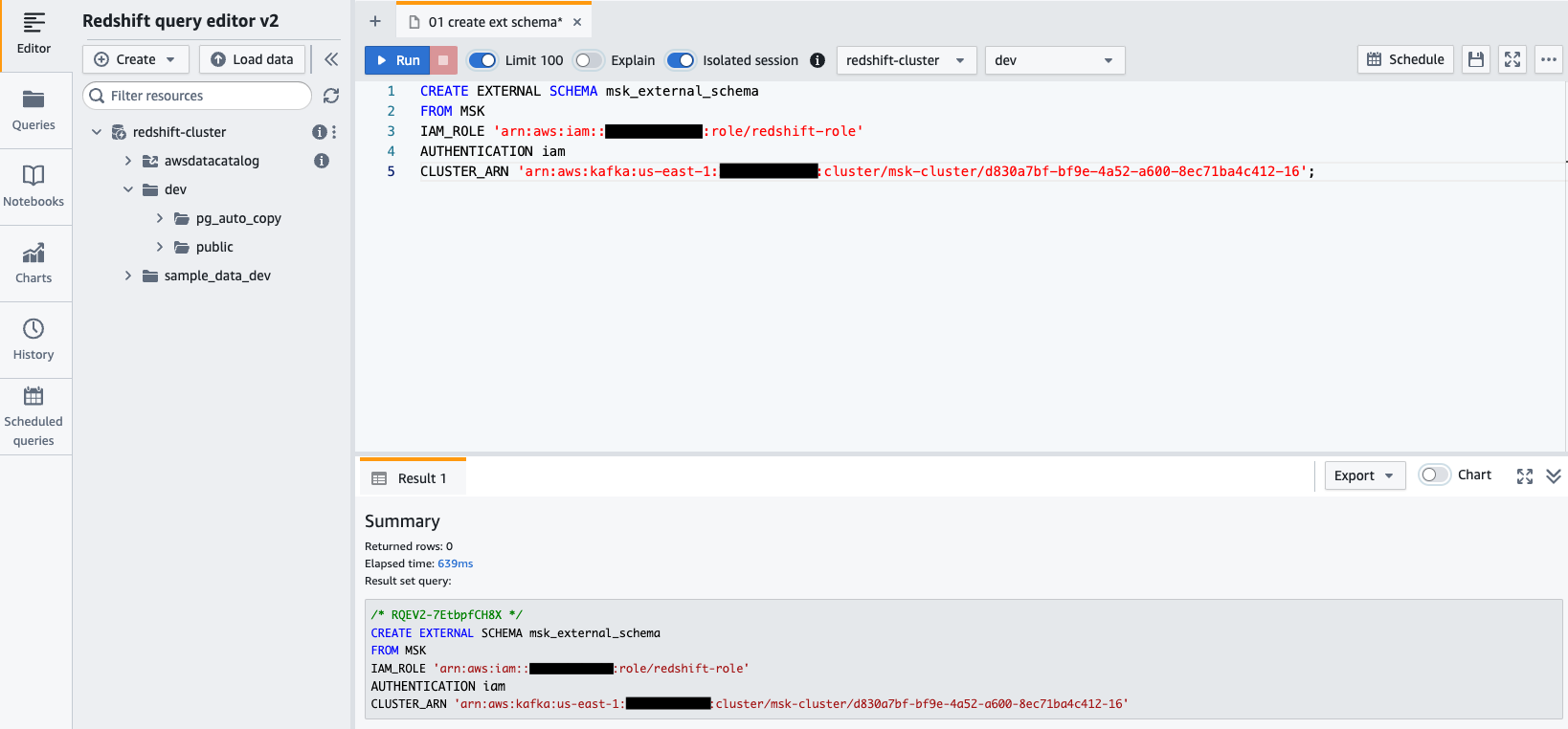
awsuser및 비밀번호Awsuser123. - 다음 SQL 문을 사용하여 Amazon MSK에서 외부 스키마를 생성합니다.
다음 코드에서 redshift-role IAM 역할 및 msk-cluster 클러스터 ARN.
- 왼쪽 메뉴에서 달리기 SQL 문을 실행합니다.
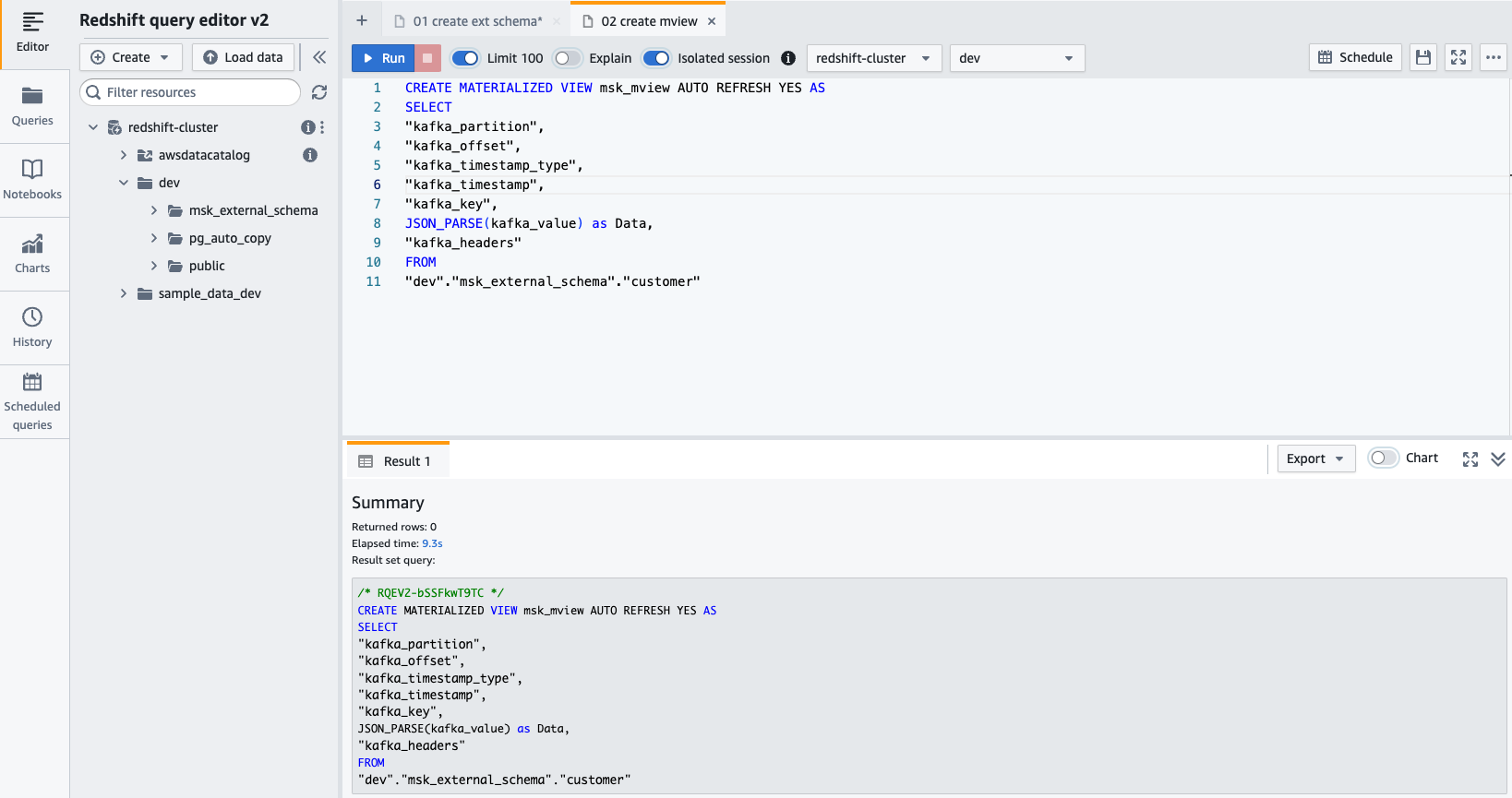
- 만들기 구체화 된 뷰 다음 SQL 문을 사용합니다.
- 왼쪽 메뉴에서 달리기 SQL 문을 실행합니다.
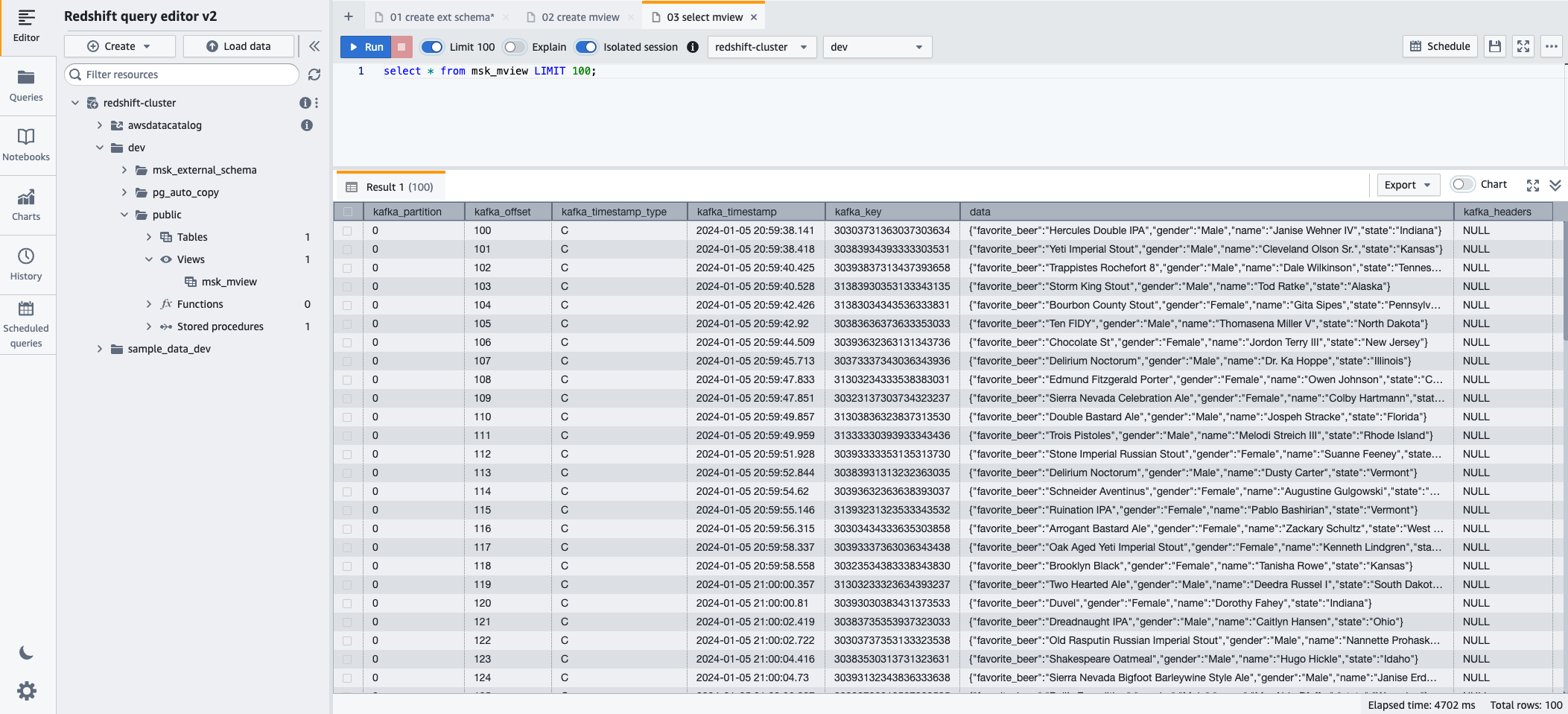
- 이제 다음 SQL 문을 사용하여 구체화된 뷰를 쿼리할 수 있습니다.
- 왼쪽 메뉴에서 달리기 SQL 문을 실행합니다.
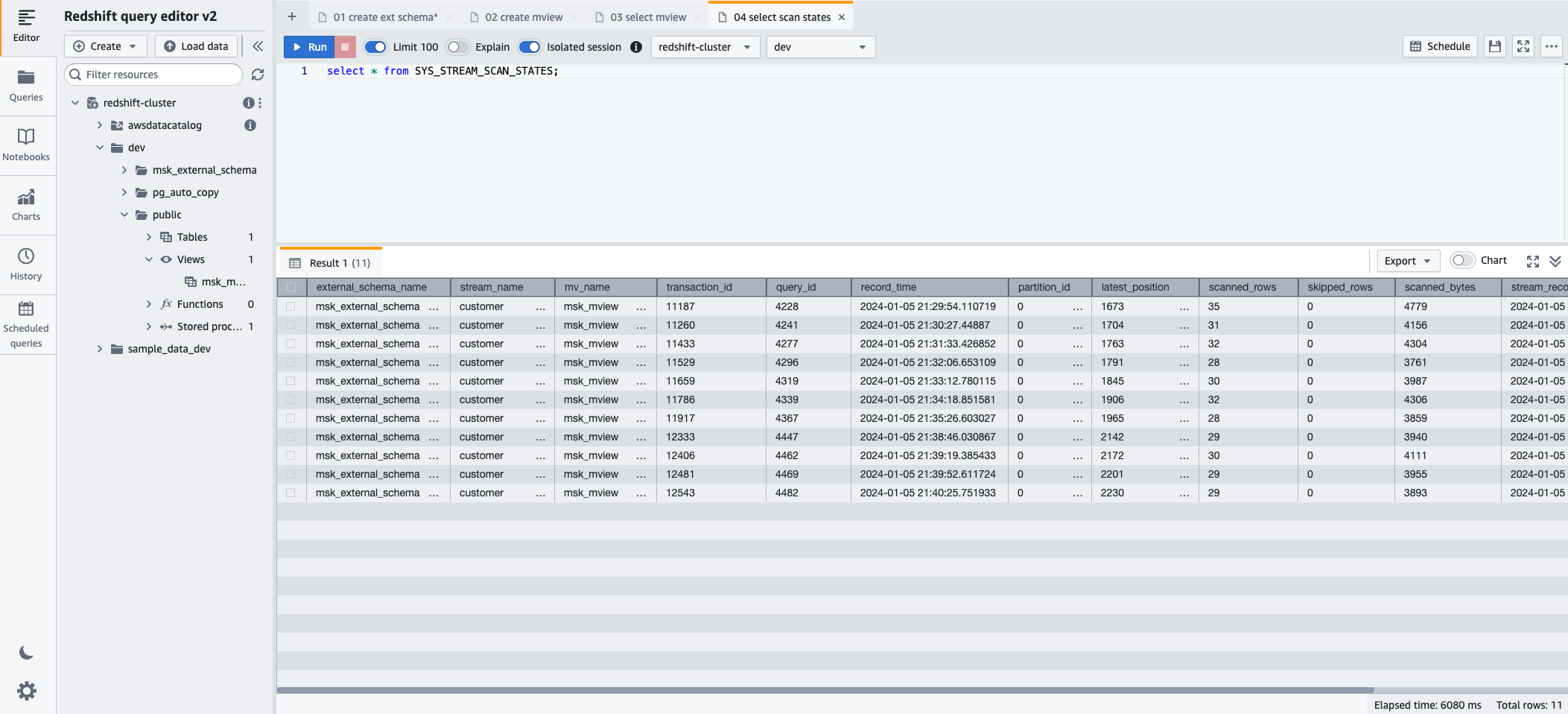
- 스트리밍 수집을 통해 로드된 레코드의 진행 상황을 모니터링하려면 SYS_STREAM_SCAN_STATES 다음 SQL 문을 사용하여 모니터링 보기:
- 왼쪽 메뉴에서 달리기 SQL 문을 실행합니다.
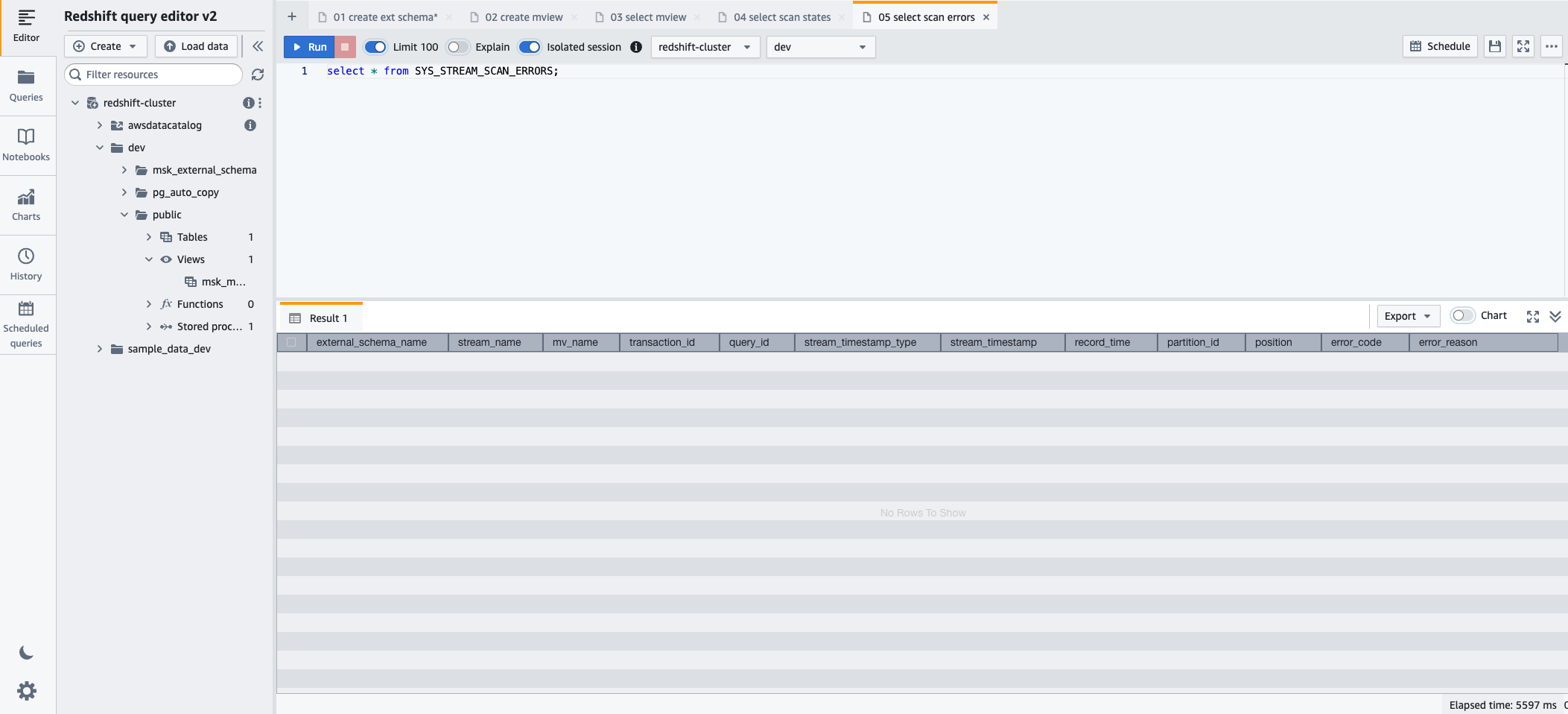
- 스트리밍 수집을 통해 로드된 레코드에서 발생한 오류를 모니터링하려면 SYS_STREAM_SCAN_ERRORS 다음 SQL 문을 사용하여 모니터링 보기:
- 왼쪽 메뉴에서 달리기 SQL 문을 실행합니다.
정리
따라한 후, 생성한 리소스가 더 이상 필요하지 않은 경우 추가 요금이 발생하지 않도록 다음 순서로 삭제하세요.
- MSK Connect 커넥터 삭제
msk-datagen-connector. - MSK Connect 플러그인 삭제
msk-datagen-plugin. - 다운로드한 Amazon MSK 데이터 생성기 JAR 파일을 삭제하고 생성한 S3 버킷을 삭제합니다.
- MSK Connect 커넥터를 삭제한 후 CloudFormation 템플릿을 삭제할 수 있습니다. CloudFormation 템플릿으로 생성된 모든 리소스는 AWS 계정에서 자동으로 삭제됩니다.
결론
이 게시물에서는 개인 정보 보호 및 보안에 중점을 두고 Amazon MSK에서 Amazon Redshift 스트리밍 수집을 구성하는 방법을 시연했습니다.
높은 처리량의 데이터 스트림을 처리하는 Amazon MSK의 기능과 Amazon Redshift의 강력한 분석 기능이 결합되어 기업은 즉시 실행 가능한 통찰력을 얻을 수 있습니다. 이러한 실시간 데이터 통합은 변화하는 데이터 추세, 고객 행동 및 운영 패턴을 이해하는 데 있어 조직의 민첩성과 대응성을 향상시킵니다. 이를 통해 적시에 정보에 입각한 의사 결정을 내릴 수 있으므로 오늘날의 역동적인 비즈니스 환경에서 경쟁 우위를 확보할 수 있습니다.
이 솔루션은 다음을 원하는 고객에게도 적용 가능합니다. Amazon MSK 서버리스 과 Amazon Redshift 서버리스.
이번 포스팅이 AWS 서비스 통합 및 구성에 대해 자세히 알아볼 수 있는 좋은 기회가 되었기를 바랍니다. 의견 섹션에서 귀하의 의견을 알려주십시오.
저자 소개
 세바스티안 블라드 데이터 및 분석 솔루션과 고객 성공에 대한 열정을 갖고 있는 Amazon Web Services의 수석 파트너 솔루션 설계자입니다. Sebastian은 기업 고객과 협력하여 현대적이고 안전하며 확장 가능한 솔루션을 설계하고 구축하여 비즈니스 성과를 달성하도록 돕습니다.
세바스티안 블라드 데이터 및 분석 솔루션과 고객 성공에 대한 열정을 갖고 있는 Amazon Web Services의 수석 파트너 솔루션 설계자입니다. Sebastian은 기업 고객과 협력하여 현대적이고 안전하며 확장 가능한 솔루션을 설계하고 구축하여 비즈니스 성과를 달성하도록 돕습니다.
 샤라드 파이 AWS의 수석 기술 컨설턴트입니다. 그는 스트리밍 분석을 전문으로 하며 고객이 Amazon MSK 및 Amazon Kinesis를 사용하여 확장 가능한 솔루션을 구축하도록 돕습니다. 그는 16년 이상의 업계 경험을 갖고 있으며 현재 AWS에서 라이브 스트리밍 플랫폼을 호스팅하는 미디어 고객과 협력하여 50천만 개가 넘는 최대 동시성을 관리하고 있습니다. AWS에 합류하기 전 Sharad는 수석 소프트웨어 개발자로서 9년간 JavaScript, Python 및 PHP와 같은 오픈 소스 기술을 사용한 코딩 경력을 쌓았습니다.
샤라드 파이 AWS의 수석 기술 컨설턴트입니다. 그는 스트리밍 분석을 전문으로 하며 고객이 Amazon MSK 및 Amazon Kinesis를 사용하여 확장 가능한 솔루션을 구축하도록 돕습니다. 그는 16년 이상의 업계 경험을 갖고 있으며 현재 AWS에서 라이브 스트리밍 플랫폼을 호스팅하는 미디어 고객과 협력하여 50천만 개가 넘는 최대 동시성을 관리하고 있습니다. AWS에 합류하기 전 Sharad는 수석 소프트웨어 개발자로서 9년간 JavaScript, Python 및 PHP와 같은 오픈 소스 기술을 사용한 코딩 경력을 쌓았습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/simplify-data-streaming-ingestion-for-analytics-using-amazon-msk-and-amazon-redshift/

