여러 IoT(사물 인터넷) 센서에서 데이터를 수집하고 통합하여 통찰력을 얻을 수 있습니다. 그러나 공통 데이터 요소를 기반으로 모든 센서에서 장비 상태 정보와 같은 분석을 도출하려면 여러 IoT 센서 장치의 데이터를 통합해야 할 수도 있습니다. 이러한 각 센서 장치는 고유한 스키마와 다양한 속성을 사용하여 데이터를 전송할 수 있습니다.
모든 IoT 센서의 데이터를 중앙 위치로 수집할 수 있습니다. 아마존 단순 스토리지 서비스 (아마존 S3). 스키마 진화 수집되는 파일 속성의 변경 사항을 수용하기 위해 데이터베이스 테이블의 스키마를 발전시킬 수 있는 기능입니다. 다음에서 사용할 수 있는 스키마 진화 기능을 사용하여 AWS 접착제, 아마존 레드시프트 스펙트럼 새 속성이 추가되거나 기존 속성이 삭제되면 자동으로 스키마 변경을 처리할 수 있습니다. 이는 S3 파일 구조를 기반으로 스키마 변경 사항을 읽어 AWS Glue 크롤러를 통해 달성됩니다. 크롤러는 이전 데이터세트와 새 데이터세트 모두에서 작동하는 하이브리드 스키마를 생성합니다. 단일 명령을 통해 다양한 스키마를 사용하여 지정된 Amazon S3 위치에서 수집된 모든 데이터 파일을 읽을 수 있습니다. 아마존 레드시프트 스펙트럼 AWS Glue 메타데이터 카탈로그를 참조하여 표를 확인하세요.
이 게시물에서는 AWS Glue 스키마 진화 기능을 사용하여 단일 Amazon S3 위치에 저장된 다양한 스키마가 포함된 여러 JSON 형식 파일을 읽는 방법을 보여줍니다. 또한 스키마를 재정의하거나 데이터를 Redshift 테이블에 로드하지 않고 Redshift Spectrum을 사용하여 Amazon S3에서 이 데이터를 쿼리하는 방법도 보여줍니다.
솔루션 개요
솔루션은 다음 단계로 구성됩니다.
- 를 생성 아마존 데이터 파이어호스 Amazon S3를 대상으로 하는 전송 스트림.
- 다음에서 샘플 스트림 데이터를 생성합니다. Amazon Kinesis 데이터 생성기 (KDG)를 대상으로 Firehose 전송 스트림을 사용합니다.
- 초기 데이터 파일을 Amazon S3 위치에 업로드합니다.
- AWS Glue 크롤러를 생성하고 실행하여 Amazon S3에서 데이터 파일을 읽어 외부 테이블 정의로 데이터 카탈로그를 채웁니다.
- 라는 외부 스키마를 생성합니다.
iotdb_extAmazon Redshift에서 Data Catalog 테이블을 쿼리합니다. - Redshift Spectrum에서 외부 테이블을 쿼리하여 초기 스키마에서 데이터를 읽습니다.
- KDG 템플릿에 추가 데이터 요소를 추가하고 데이터를 Firehose 전송 스트림으로 보냅니다.
- 추가 데이터 파일이 추가 데이터 요소와 함께 Amazon S3에 로드되는지 확인합니다.
- AWS Glue 크롤러를 실행하여 외부 테이블 정의를 업데이트합니다.
- Redshift Spectrum에서 외부 테이블을 다시 쿼리하여 두 개의 서로 다른 스키마에서 결합된 데이터 세트를 읽습니다.
- 템플릿에서 데이터 요소를 삭제하고 해당 데이터를 Firehose 전송 스트림으로 보냅니다.
- 추가 데이터 파일이 하나 적은 데이터 요소로 Amazon S3에 로드되는지 확인합니다.
- AWS Glue 크롤러를 실행하여 외부 테이블 정의를 업데이트합니다.
- Redshift Spectrum에서 외부 테이블을 쿼리하여 세 가지 다른 스키마에서 결합된 데이터 세트를 읽습니다.
이 솔루션은 다음 아키텍처 다이어그램에 설명되어 있습니다.

사전 조건
이 솔루션에는 다음 전제 조건이 필요합니다.
솔루션 구현
솔루션을 빌드하려면 다음 단계를 완료하세요.
- Kinesis 콘솔에서 다음 매개변수를 사용하여 Firehose 전송 스트림을 생성합니다.
- 럭셔리 출처선택한다. 직접 넣기.
- 럭셔리 목적지선택한다. 아마존 S3.
- 럭셔리 S3 버킷, S3 버킷을 입력하세요.
- 럭셔리 동적 파티셔닝, 고르다 사용.

-
- 다음 동적 파티셔닝 키를 추가합니다.
- 표현이 포함된 주요 연도
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%Y") - 표현이 있는 주요 월
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%m") - 표정이 있는 중요한 날
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%d") - 표정이 있는 주요 시간
.connectionTime | strptime("%d/%m/%Y:%H:%M:%S") | strftime("%H")
- 표현이 포함된 주요 연도
- 다음 동적 파티셔닝 키를 추가합니다.
-
- 럭셔리 S3 버킷 접두사, 입력
year=!{partitionKeyFromQuery:year}/month=!{partitionKeyFromQuery:month}/day=!{partitionKeyFromQuery:day}/hour=!{partitionKeyFromQuery:hour}/
- 럭셔리 S3 버킷 접두사, 입력

Kinesis Data Firehose 콘솔에서 전송 스트림 세부 정보를 검토할 수 있습니다.
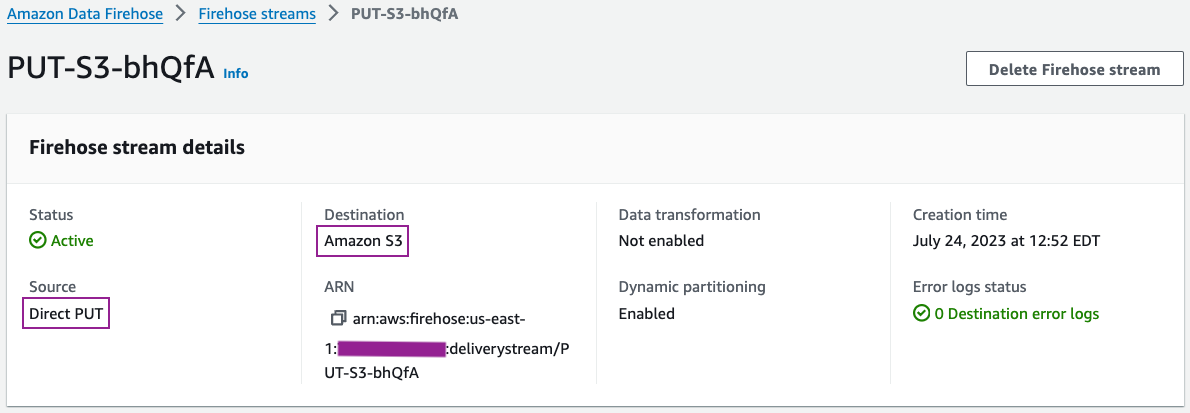
전송 스트림 구성 세부 정보는 다음 스크린샷과 유사해야 합니다.

- 다음 템플릿을 사용하여 Firehose 전송 스트림을 대상으로 사용하여 KDG에서 샘플 스트림 데이터를 생성합니다.

- Amazon S3 콘솔에서 초기 파일 세트가 S3 버킷에 로드되었는지 확인합니다.
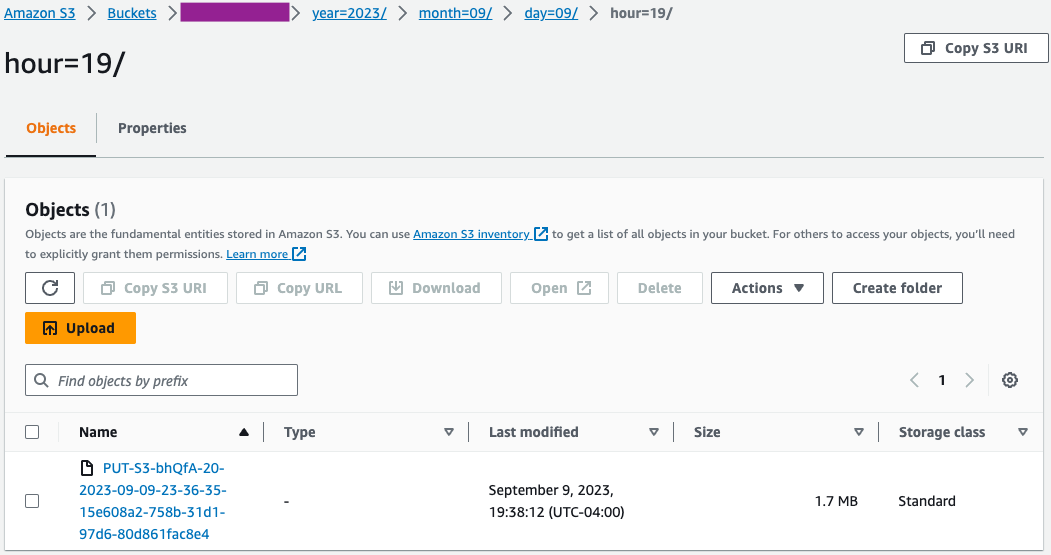
- AWS Glue 콘솔에서 AWS Glue 크롤러 생성 및 실행 데이터 원본을 이전 단계에서 사용한 S3 버킷으로 사용합니다.
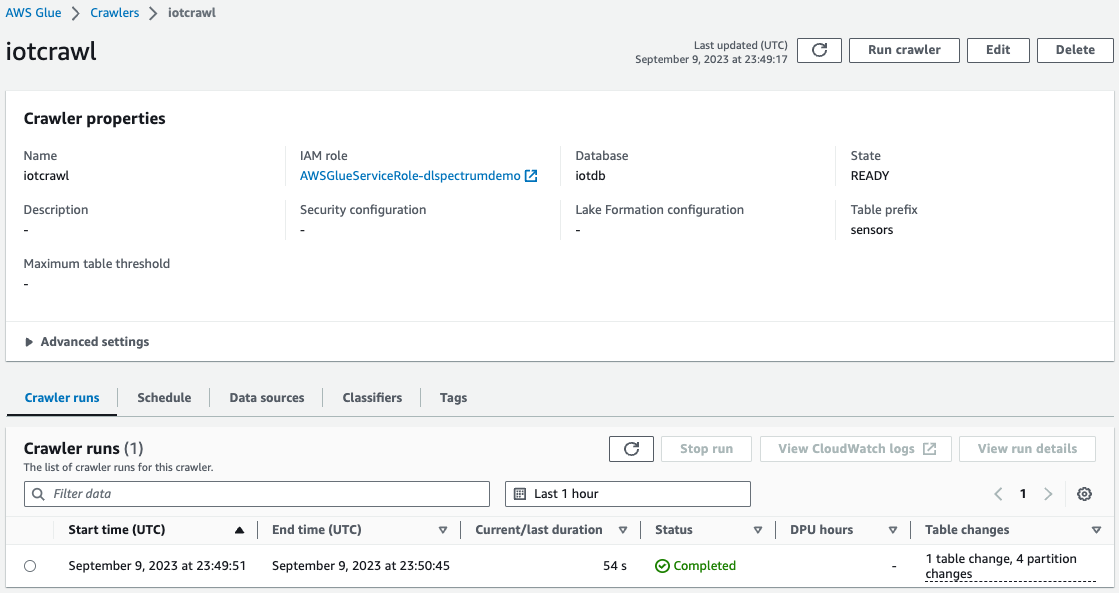
크롤러가 완료되면 AWS Glue 콘솔에서 테이블이 생성되었는지 확인할 수 있습니다.

문제해결
데이터를 KDG 템플릿에서 Firehose 전송 스트림으로 보낸 후 Amazon S3에 로드되지 않으면 새로 고치고 KDG에 로그인했는지 확인하세요.
정리
AWS 계정에 불필요한 비용이 발생하지 않도록 더 이상 사용할 계획이 없다면 S3 데이터 및 Redshift 클러스터를 삭제하는 것이 좋습니다.
결론
빅데이터 기반 예측 및 처방 분석에 대한 요구 사항이 등장하면서 최소한의 노력으로 여러 이기종 데이터 모델의 데이터를 통합하는 데이터 솔루션에 대한 수요가 증가하고 있습니다. 이 게시물에서는 고유한 스키마를 사용하여 다양한 데이터 소스의 공통 원자 데이터 요소에서 메트릭을 파생하는 방법을 보여주었습니다. 모든 데이터 소스의 데이터를 공통 S3 위치(동일한 폴더 또는 각 데이터 소스별 여러 하위 폴더)에 저장할 수 있습니다. 데이터 소비에 대한 데이터 새로 고침 요구 사항과 동일한 빈도로 실행되도록 AWS Glue 크롤러를 정의하고 예약할 수 있습니다. 이 솔루션을 사용하면 AWS Glue 데이터 카탈로그 및 스키마 진화 기능을 사용하여 다양한 파일 구조가 있는 S3 위치에서 읽을 수 있는 Redshift Spectrum 테이블을 생성할 수 있습니다.
질문이나 제안 사항이 있는 경우 댓글 섹션에 피드백을 남겨주세요. 다양한 IoT 센서의 데이터로 분석 솔루션을 구축하는 데 추가 지원이 필요한 경우 AWS 계정 팀에 문의하십시오.
저자에 관하여
 스왑나 반들라 AWS Analytics Specialist SA 팀의 수석 솔루션 아키텍트입니다. Swapna는 고객의 데이터 및 분석 요구 사항을 이해하고 고객이 클라우드 기반의 Well-Architected 솔루션을 개발할 수 있도록 지원하는 데 열정을 갖고 있습니다. 업무 외에 그녀는 가족과 함께 시간을 보내는 것을 즐깁니다.
스왑나 반들라 AWS Analytics Specialist SA 팀의 수석 솔루션 아키텍트입니다. Swapna는 고객의 데이터 및 분석 요구 사항을 이해하고 고객이 클라우드 기반의 Well-Architected 솔루션을 개발할 수 있도록 지원하는 데 열정을 갖고 있습니다. 업무 외에 그녀는 가족과 함께 시간을 보내는 것을 즐깁니다.
 인디라 발라크리슈난 AWS Analytics Specialist SA 팀의 수석 솔루션 아키텍트입니다. 그녀는 고객이 데이터 기반 의사 결정을 사용하여 비즈니스 문제를 해결하기 위해 클라우드 기반 분석 솔루션을 구축하도록 돕는 데 열정적입니다. 직장 밖에서 그녀는 아이들의 활동에 자원 봉사하고 가족과 시간을 보냅니다.
인디라 발라크리슈난 AWS Analytics Specialist SA 팀의 수석 솔루션 아키텍트입니다. 그녀는 고객이 데이터 기반 의사 결정을 사용하여 비즈니스 문제를 해결하기 위해 클라우드 기반 분석 솔루션을 구축하도록 돕는 데 열정적입니다. 직장 밖에서 그녀는 아이들의 활동에 자원 봉사하고 가족과 시간을 보냅니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/build-an-analytics-pipeline-that-is-resilient-to-schema-changes-using-amazon-redshift-spectrum/

