아마존 아테나 오픈 소스 프레임워크를 기반으로 구축된 서버리스 대화형 분석 서비스로, 오픈 테이블 파일 형식을 지원합니다. Athena는 데이터가 있는 곳에서 페타바이트 규모의 데이터를 분석하는 간단하고 유연한 방법을 제공합니다. 데이터를 분석하거나 애플리케이션을 구축할 수 있습니다. 아마존 단순 스토리지 서비스 (Amazon S3) 데이터 레이크 및 30개의 데이터 소스(온프레미스 데이터 소스 또는 SQL 또는 Python을 사용하는 기타 클라우드 시스템 포함) Athena는 프로비저닝이나 구성 노력 없이 오픈 소스 Trino 및 Presto 엔진과 Apache Spark 프레임워크를 기반으로 구축되었습니다.
오늘부터 Athena SQL 엔진은 AWS 접착제 테이블 메타데이터의 일부인 Data Catalog. CBO는 이러한 통계를 사용하여 쿼리 실행 계획을 개선하고 Athena에서 실행되는 쿼리 성능을 향상시킵니다. CBO가 사용할 수 있는 특정 최적화에는 조인 재정렬 및 각 테이블과 열에 사용 가능한 통계를 기반으로 집계 푸시가 포함됩니다.
TPC-DS 벤치마크 이러한 벤치마크는 비용 기반 최적화 프로그램의 강력한 성능을 보여줍니다. CBO 없이 동일한 TPC-DS 쿼리를 실행하는 것과 비교하여 CBO를 활성화하면 쿼리가 최대 2배 더 빠르게 실행됩니다.
TPC-DS 벤치마크의 성능 및 비용 비교
우리는 다양한 고객 사용 사례를 나타내기 위해 업계 표준 TPC-DS 3TB를 사용했습니다. 이는 명시된 벤치마크 크기의 10배에 달하는 워크로드를 나타냅니다. 즉, 3TB 벤치마크 데이터 세트는 30~50TB 데이터 세트에 대한 고객 워크로드를 정확하게 나타냅니다.
테스트에서 데이터 세트는 압축되지 않은 Parquet 형식으로 Amazon S3에 저장되었으며 AWS Glue 데이터 카탈로그는 데이터베이스 및 테이블에 대한 메타데이터를 저장하는 데 사용되었습니다. 팩트 테이블은 조인 작업에 사용되는 날짜 열을 기준으로 분할되었으며 각 팩트 테이블은 2,000개의 파티션으로 구성되었습니다. CBO의 성능을 설명하기 위해 다양한 쿼리의 동작을 비교하고 CBO를 활성화한 상태와 비활성화한 상태로 실행하는 경우의 성능 차이를 강조합니다.
다음 그래프는 CBO가 있거나 없는 엔진의 쿼리 런타임을 보여줍니다.

다음 그래프는 TPC-DS 벤치마크에서 성능이 가장 크게 향상된 상위 10개 쿼리를 보여줍니다.
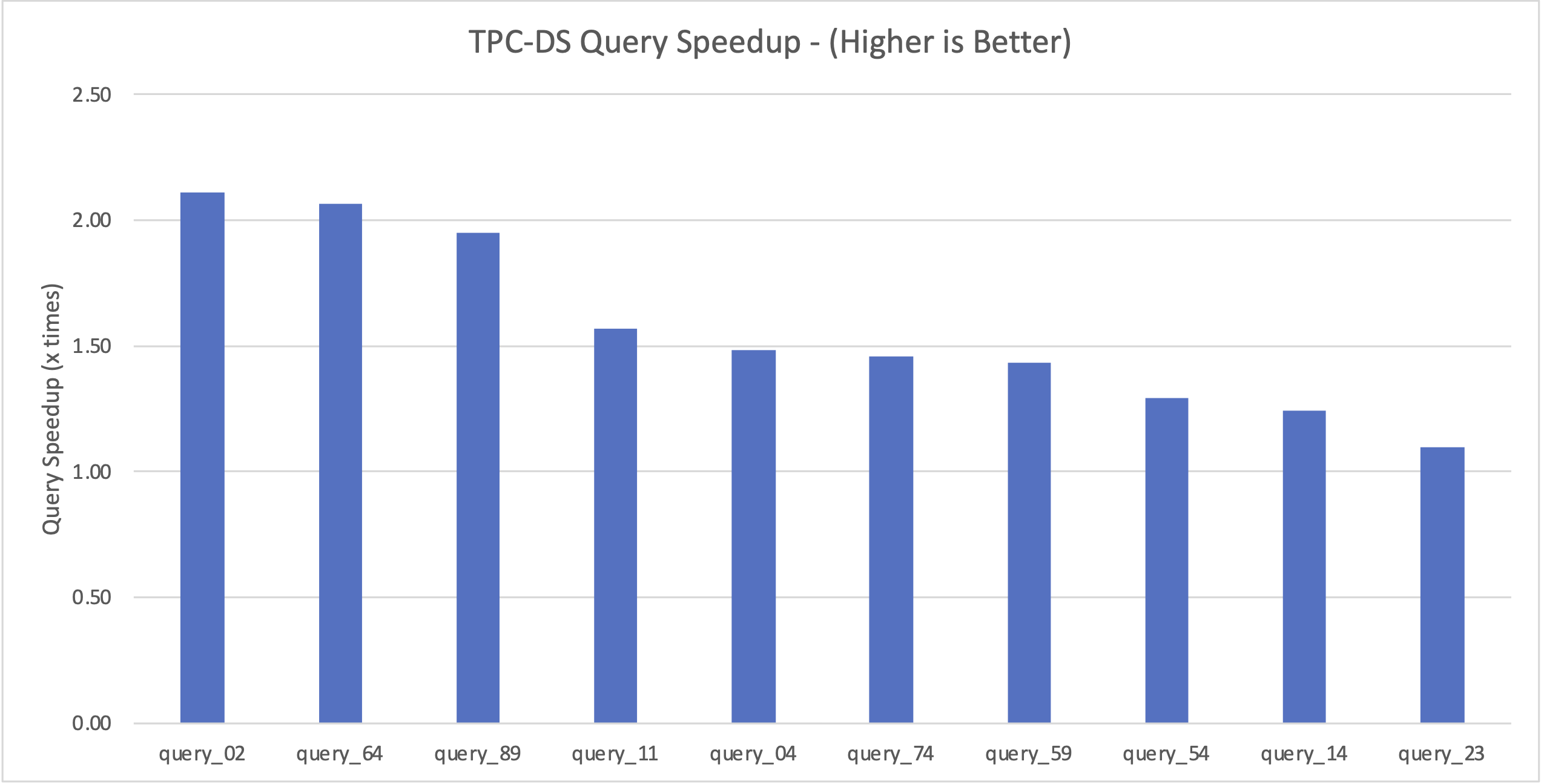
쿼리 성능 향상에 기여한 몇 가지 비용 기반 최적화 기술에 대해 논의해 보겠습니다.
비용 기반 조인 재정렬
비용 기반 SQL 최적화 프로그램에서 사용하는 최적화 기술인 조인 재정렬은 다양한 조인 시퀀스를 분석하여 각 단계에서 처리되는 중간 데이터를 줄이고 메모리 및 CPU 요구 사항을 낮춤으로써 쿼리 런타임을 최소화하는 순서를 선택합니다.
TPC-DS 82TB 데이터 세트의 쿼리 3에 대해 이야기해 보겠습니다. 쿼리는 XNUMX개의 테이블에 대해 내부 조인을 수행합니다. item, inventory, date_dim및 store_sales. 그만큼 store_sales 테이블에는 8.6억 개의 행이 있으며 날짜별로 분할되어 있습니다. 그만큼 inventory 테이블에는 1억 개의 행이 있으며 날짜별로 분할되어 있습니다. 그만큼 item 테이블에는 360,000개의 행이 포함되어 있으며 date_dim 테이블에는 73,000개의 행이 있습니다.
쿼리 82
CBO 없이
CBO를 사용하지 않으면 엔진은 내부 경험적 방법을 사용하여 입력 쿼리에 정의된 테이블 순서를 기반으로 조인 순서를 결정합니다. 입력 쿼리의 FROM 절은 다음과 같습니다. "from item, inventory, date_dim, store_sales" (모든 내부 조인). 내부 휴리스틱을 거친 후 Athena는 조인 순서를 ((item ⋈ (inventory ⋈ date_dim)) ⋈ store_sales). 에도 불구하고 store_sales 가장 큰 팩트 테이블이므로 FROM 절에서 마지막으로 정의되므로 마지막에 조인됩니다. 이 계획은 가능한 한 빨리 중간 조인 크기를 줄이는 데 실패하여 쿼리 런타임이 증가합니다. 다음 다이어그램은 CBO가 없는 조인 순서와 여러 단계를 통과하는 행 수를 보여줍니다.

CBO와 함께
CBO를 사용할 때 옵티마이저는 통계는 물론 조인 크기 추정, 조인 빌드 측, 조인 유형 등 다양한 데이터를 사용하여 최상의 조인 순서를 결정합니다. 이 경우 Athena가 선택한 조인 순서는 ((store_sales ⋈ item) ⋈ (inventory ⋈ date_dim)). 가장 큰 팩트 테이블, store_sales는 섞이지 않고 먼저 item 차원 테이블. 다른 파티션 테이블, inventory, 또한 먼저 내부에서 결합됩니다. date_dim 차원 테이블. 차원 테이블과의 조인은 팩트 테이블에 대한 필터 역할을 하여 뒤따르는 조인의 입력 데이터 크기를 크게 줄입니다. Athena에서는 조인을 위해 테이블이 어느 쪽에 있는지가 중요합니다. 왜냐하면 조인 작업을 위해 메모리에 구축될 오른쪽 테이블이기 때문입니다. 따라서 우리는 항상 큰 테이블을 왼쪽에 두고 작은 테이블을 오른쪽에 두려고 합니다. CBO는 예전에는 좌파가 8.6억이었는데 지금은 13.6만이라는 계획을 택했다.

CBO를 사용하면 최적의 조인 순서를 선택하여 쿼리 런타임이 25%(15초에서 11초로) 향상되었습니다.
다음으로 또 다른 CBO 기술에 대해 논의해 보겠습니다.
비용 기반 집계 푸시다운
집계 푸시다운은 쿼리 최적화 프로그램이 성능을 향상시키기 위해 사용하는 최적화 기술입니다. 여기에는 동일한 쿼리 의미 체계를 유지하면서 SUM, COUNT 및 AVG와 같은 집계 작업을 쿼리 계획의 초기 단계로 푸시하는 작업이 포함됩니다. 이렇게 하면 단계 간에 전송되는 데이터의 양이 줄어듭니다. 집계 푸시다운은 데이터 처리를 최소화하여 메모리 사용량, I/O 비용 및 네트워크 트래픽을 줄입니다.
그러나 집계를 내리는 것이 항상 유익한 것은 아닙니다. 데이터 분포에 따라 다릅니다. 예를 들어 행은 많지만 고유한 값(예: 성별)이 적은 열을 조인하기 전에 그룹화하는 것이 더 효과적입니다. 먼저 그룹화한다는 것은 많은 수의 레코드를 더 적은 수의 레코드(예: 남성, 여성만)로 집계하는 것을 의미합니다. 조인 후 그룹화한다는 것은 집계되기 전에 많은 수의 레코드가 조인에 참여해야 함을 의미합니다. 반면, 카디널리티가 높은 열에 대한 그룹화는 조인 후에 수행하는 것이 더 좋습니다. 각 값이 어쨌든 고유할 가능성이 높으며 해당 단계로 인해 중간 단계 간에 전송되는 데이터 양이 조기에 줄어들지 않기 때문에 이전에 수행하면 불필요한 집계 오버헤드가 발생할 위험이 있습니다.
따라서 집계를 푸시다운할지 여부는 비용을 기준으로 결정해야 합니다. 2TB TPC-DS 데이터 세트에서 실행되는 쿼리 3의 예를 들어 집계 푸시다운 값이 데이터 배포에 따라 어떻게 달라지는지 보여줍니다. 그만큼 web_sales 테이블에는 2.1억 개의 행이 있고 catalog_sales 테이블에는 4.23억 XNUMX천만 개의 행이 있습니다. 두 테이블 모두 날짜 열을 기준으로 분할되어 있습니다.
쿼리 2
CBO 없이
Athena는 먼저 연합 전체 작전의 결과에 합류합니다. web_sales 테이블과 catalog_sales 다른 테이블이 있는 테이블. 그런 다음에만 결합된 결과에 대해 집계를 수행합니다. 이 예에서는 조인해야 하는 데이터의 양이 커서 쿼리 런타임이 길어졌습니다.

CBO와 함께
Athena는 통계 값 중 하나인 고유 값 개수를 활용하여 집계를 푸시다운할 때와 그렇지 않을 때의 비용 영향을 평가합니다. 열에 행은 많지만 고유한 값이 거의 없는 경우 CBO는 집계를 아래로 푸시할 가능성이 높습니다. 이로 인해 정규화된 행이 축소되었습니다. web_sales 과 catalog_sales 테이블을 각각 2,590행과 3,590행으로 늘립니다. 그런 다음 이러한 집계된 레코드를 통합하여 테이블과 조인하는 데 사용했습니다. CBO가 없는 계획에 비해 두 개의 대형 테이블에서 조인에 참여하는 레코드는 6.33억 2.1천만 행(4.23억 + 6,180억 2,590천만)에서 3,590행(XNUMX + XNUMX)으로 줄었습니다. 이로 인해 쿼리 런타임이 크게 감소했습니다.

CBO를 사용하면 쿼리 런타임이 50% 향상되었습니다(37초에서 18초로 감소). 요약하면 CBO는 Athena가 최적의 집계 푸시다운 계획을 선택하도록 도왔으며 비용 기반 최적화를 사용하지 않는 경우에 비해 쿼리 시간을 절반으로 줄였습니다.
결론
이 게시물에서는 Athena가 엔진 v3에서 비용 기반 최적화 프로그램(CBO)을 사용하여 보다 효율적인 쿼리 실행 계획을 생성하기 위해 테이블 통계를 사용하는 방법에 대해 논의했습니다. TPC-DS 벤치마크 테스트에서는 CBO를 사용하지 않을 때와 비교하여 CBO를 사용할 때 전체 쿼리 성능이 11% 향상된 것으로 나타났습니다.
CBO가 채택한 두 가지 주요 최적화는 조인 재정렬과 집계 푸시다운입니다. 조인 재정렬은 통계를 기반으로 테이블 조인 순서를 지능적으로 선택하여 중간 데이터를 줄입니다. 집계 푸시다운은 유익한 경우 계획 초기에 집계를 푸시하여 중간 데이터를 줄입니다.
요약하면 Athena의 새로운 비용 기반 최적화 프로그램은 우수한 실행 계획을 선택하여 쿼리 속도를 크게 향상시킵니다. CBO는 AWS Glue 데이터 카탈로그에 저장된 테이블 통계를 기반으로 최적화합니다. 이 자동 최적화는 응답성이 뛰어난 쿼리 성능을 통해 Athena 사용자의 생산성을 향상시킵니다. CBO의 최적화 기술을 활용하려면 다음을 참조하세요. 열 통계 작업 AWS Glue 데이터 카탈로그의 테이블과 열에 대한 통계를 생성합니다.
저자에 관하여
 다르시트 타카르 AWS의 기술 제품 관리자이며 매사추세츠주 보스턴에 위치한 Amazon Athena 팀과 협력하고 있습니다.
다르시트 타카르 AWS의 기술 제품 관리자이며 매사추세츠주 보스턴에 위치한 Amazon Athena 팀과 협력하고 있습니다.
 웨이 젱 Amazon Athena의 수석 소프트웨어 개발 엔지니어입니다. 그는 2021년에 AWS에 합류했으며 Athena의 여러 성능 개선 작업을 진행해 왔습니다.
웨이 젱 Amazon Athena의 수석 소프트웨어 개발 엔지니어입니다. 그는 2021년에 AWS에 합류했으며 Athena의 여러 성능 개선 작업을 진행해 왔습니다.
 장추호 Amazon Athena의 소프트웨어 개발 엔지니어입니다. 그는 XNUMX년 넘게 쿼리 최적화 프로그램 관련 작업을 해왔습니다.
장추호 Amazon Athena의 소프트웨어 개발 엔지니어입니다. 그는 XNUMX년 넘게 쿼리 최적화 프로그램 관련 작업을 해왔습니다.
 파틱 샤 Amazon Athena의 수석 분석 설계자입니다. 그는 2015년에 AWS에 합류했으며 그 이후로 빅 데이터 분석 분야에 집중하여 고객이 AWS 분석 서비스를 사용하여 확장 가능하고 강력한 솔루션을 구축하도록 돕고 있습니다.
파틱 샤 Amazon Athena의 수석 분석 설계자입니다. 그는 2015년에 AWS에 합류했으며 그 이후로 빅 데이터 분석 분야에 집중하여 고객이 AWS 분석 서비스를 사용하여 확장 가능하고 강력한 솔루션을 구축하도록 돕고 있습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/speed-up-queries-with-cost-based-optimizer-in-amazon-athena/

