과거를 되돌아보고 미래를 바라보는 것은 연말까지의 전통적인 운동입니다. 2024년에 걱정할 만큼 중요한 데이터 문제는 무엇입니까? 2024년에 우리가 좋은 일을 할 가능성이 있는 것은 무엇입니까? 말할 것도 없이 돈(예산, 비용)이 문제이다. 그러나 말할 필요도 없이 실제 비즈니스 과제를 해결하는 것이 아마도 더 중요할 것입니다. 비용이 누적되고 혜택이 짜증스러울 정도로 늦게 나타날 수 있다는 점을 기억하세요. 일부 혜택은 "승리 아니면 죽기" 범주에 속하기도 합니다.
물론 쉽지는 않습니다.
그러면 격려가 됩니다. 우리는 과거로부터 무엇을 배울 수 있습니까?
나는 2024년에 매우 흥미로운 다섯 가지 우려 사항을 제시했습니다.
- 사업 실적
- 주제와 프로세스
- 모델링: 현실인가, 데이터인가?
- 정보학 – 그것이 왜 유럽적인 것입니까?
- 인지 개선으로 데이터 모델링 개선???
비즈니스 결과, 지금 아니면 영원히
비즈니스 문제에 컴퓨팅이 적용된 것은 1960년대 후반으로 거슬러 올라갑니다. 데이터 입력은 처음에는 Flexowriter 종이 테이프(전기 타자기)와 천공 카드를 사용했습니다. XNUMX년대에는 직접 액세스 장치(디스크)로 대체되기 위해 자기 테이프에서 다단계 정렬/병합 알고리즘으로 복잡한 알고리즘이 수행되었습니다.
비즈니스 사용 사례는 매우 간단했으며 저와 같은 사람들은 BOM 및 자재 요구 사항 처리 애플리케이션을 구현하는 데 10~15년 동안 매우 바빴습니다. 해당 사용 사례를 위해 구입한 컴퓨터에서. XNUMX만 달러 이상의 가격으로 제공됩니다.
인보이스 발행이 사용 사례로 빠르게 추가되었지만 다음과 같은 이유로 인해 어려워지기 시작했습니다. 데이터 품질 문제(예, 그 당시에는 이미 그랬습니다. 고객은 어려운 무리입니다).
통합이 문제가 되기 시작했고, 이는 초기 데이터베이스 시스템이 주로 도메인 애플리케이션을 위한 포인트 솔루션으로 사용되었기 때문에 큰 관심사로 판명되었습니다. 그러나 엔터프라이즈 데이터베이스의 비전은 네트워크 및 인덱싱된(ISAM/VSAM 데이터베이스)에 대한 SQL의 승리로 이어졌습니다. 이전 DBMS의 너무 물리적인 데이터 모델에 비해 정규화된 데이터베이스의 유연성이 인식되었기 때문입니다.
70년대에는 소위 "DIKW 피라미드"가 도처에 나타나기 시작했습니다.

엔터프라이즈 모델링 비전은 객체지향 모델(UML, OO) 및 OODBMS로 이어지는 코드 계층에도 진입했지만 메인라인 경로에는 진입하지 못했습니다.
이러한 종류의 정보 시스템 구축 및 구현에 대한 가설은 계획, 거버넌스, 방법, 비즈니스 전문가의 참여 및 일부 기술(관계형 모델링, OO 등)과 같은 분야를 기반으로 했습니다.
그러나 80년대와 90년대에는 이러한 "사일로"가 너무 어렵고 비용이 많이 든다는 인식이 확산되었습니다. 실제 비즈니스 요구 사항을 어느 정도 완화하기 위해 미니 컴퓨터, 개인용 컴퓨터, OLAP 및 데이터 웨어하우징과 같은 새로운 기술이 등장했습니다.
프로세스보다는 주제
새로운 세기에 들어서면서 ERP 시스템(예: Oracle, SAP 등)과 OLAP, SAS 등과 같은 분석이 지원되는 대규모 데이터 웨어하우스가 실제로 대부분의 대기업을 운영하고 있었습니다. 높은 비용으로 그렇습니다. 그리고 바꾸기도 어렵습니다. 그렇습니다. 그러나 높은 비용으로 인한 이점은 방어할 수 있었습니다. 시장 기반 투자 사고(신자유주의)의 성장, 유럽연합이 강력한 새로운 거시정치 상황, 중국의 핵심 역할 등 외부효과는 금세기 초에 발생했습니다.
기업 활동의 세계화는 빠르게 이루어졌으며 오늘날에도 계속되고 있습니다. 이로 인해 인수합병, 제품 라인의 충돌, 비즈니스 규칙의 모순 등으로 인해 기업이 훨씬 더 복잡해졌습니다. 투자자들은 훨씬 더 짧은 ROI 주기를 요구하는 압력이 높았습니다. 정치, 이데올로기, 격동의 역학은 모두 전통적으로 (관리/컴퓨터) 과학으로 생각되었던 것에 영향을 미쳤습니다.
야후, 구글 등 대형 테크 기업이 '빅데이터'를 다루는 데 성공하면서 '기술을 구출한다'는 야심찬 기대감이 생겼다.
결과적으로 사람들은 NoSQL, 함수형 프로그래밍, "최신 데이터 스택" 등의 솔루션을 찾는 곳이 기술이었습니다. 이제 스토리지는 쉽고 저렴해졌지만, "컴퓨팅"은 이전과 마찬가지로 번거롭습니다. AI는 더욱 강력해졌습니다(그러나 여전히 컴퓨팅 비용과 환경적 영향 측면에서 매우 비쌉니다).
2024년에는 데이터가 사용될 환경으로의 데이터 흐름에 엄청난 초점이 맞춰질 것입니다. (AI 포함 여부 등) "현대 데이터 스택"이라는 우산 아래 "데이터 엔지니어링", "데이터 패브릭", "데이터 메시" 등의 기술 뉴스를 사용하여 데이터가 이동되고 있으며 알고리즘 및 통계 처리(일명 AI)에 적합한 대부분 물리적 구조로 변환됩니다.
에너지는 강렬하며, 도구는 숫자로 획득되고 적용되며, 이는 주방에 필요한 것에 대한 신혼 부부의 쇼핑 목록과 일치하기 시작합니다. (죄송합니다. 어쩔 수 없었습니다.) 다음을 살펴보세요(Our West Nest라는 매우 유익한 사이트에서 제공).

그리고 위의 내용은 귀하가 보유하도록 권장되는 가젯 및 도구 카테고리에 불과합니다. 필요한 나머지 부분에 대해서는 해당 사이트를 참조하세요. 이제 "식품 엔지니어"가 되기 위해 필요한 것이 무엇인지 알게 되었습니다. 데이터 엔지니어링 툴링에 관해서는 이것이 압도적인지 확인하십시오. 대지!
불행하게도 훌륭한 요리사라면 누구나 기쁘게 말할 수 있듯이, 재료(음식)를 아는 것과 좋은 제품의 맛을 결합하고 일치시키는 방법, 즉 어디서 찾고 어떻게 취급하는지 아는 것이 사업의 비결입니다. 우리의 영역으로 번역하면 수많은 엔지니어링 도구를 적용할 수 있지만 비즈니스 도메인의 주제를 알고, 비즈니스 문제를 알고, 연합의 비즈니스맨과 함께 문제를 해결하는 경우에만 작업이 완료될 것입니다. 시나리오.
그렇지 않으면 아마도 비용 효율적인 솔루션 제공자가 될 수 없을 것입니다. 이것은 로켓 과학이나 컴퓨터 과학이 아닌 비즈니스 문제입니다.
그리고 그 사업이 무엇인지 아는 것이 우리의 다음 주제입니다.
현실 모델링: 데이터가 아닌 지식
현실은 잔인할 수 있습니다. 제가 가장 좋아하는 (진짜) 공포 이야기 중 하나는 새로운 판매 보고 체계를 구현하려는 다국적 B2C 회사에 관한 것입니다. 우리는 여러 국가에서 실행되는 여러 ERP 시스템에서 데이터를 수집하여 이를 구축했지만 통합 데이터베이스에서 판매 보고서 라인의 50% 이상에서 제품 카테고리 계층 구조 정보가 누락되었다는 사실을 발견했습니다. 이로 인해 프로젝트가 몇 달 지연되었고, 젊고 강인한 컨트롤러들이 교대로 여러 자회사를 방문했습니다. 그들이 미리 알았더라면 프로젝트는 아마도 달라 보였을 것입니다.
GenAI(Generative AI)가 오늘날 모든 첫 페이지에 등장하는 것 같습니다. 그리고 2페이지에서 많은 사람들은 GenAI의 환각 경향을 멈추려면 다음과 같은 도움을 주어야 한다고 주장합니다. 지식 그래프. 그래프는 비즈니스 의미론에 가깝기 때문에 이는 매우 좋은 아이디어입니다.
마이크 딜린저는 매우 직접적인 AI가 좀 더 효과적으로 작동하도록 하려면 지식 그래프가 필요합니다.
“컴퓨터 및 데이터 과학자의 경우 지식 그래프 사용을 장려하는 한 가지 방법은 관계형 데이터베이스에서 데이터와 지식을 표현하고 선형 기계 학습 모델로 조작하는 데 따른 많은 단점을 극복하는 방법으로 지식 그래프를 배치하는 것입니다.
데이터베이스의 크고 나쁘고 극적으로 단순화된 가정 중 하나는 열이 독립적이거나 직교하는 것으로 처리된다는 것입니다. 분류기와 같은 기계 학습 기술은 동일한 가정을 합니다. 즉, 각 특성/변수에 대한 가중치가 있지만 둘 이상의 특성 간의 공분산 또는 상호 의존성을 나타내는 용어가 없습니다. 분류자의 대상 클래스도 서로 분리되거나 상관되지 않은 것으로 가정됩니다. 이는 분류자가 계층적으로 관련된 클래스 사이를 결정하는 데 제대로 수행되지 않는 이유입니다. 즉, 서로 분리되지 않고 하나가 다른 클래스를 포함합니다. 변수가 실제로 관련되어 있으면서 관련이 없다고 믿는 것은 오류 분산을 허용할 수 없는 수준으로 부풀릴 뿐입니다.”
또한 Dillinger의 슬라이드 중 하나는 다음과 같습니다. “지식 그래프를 사용하는 이유는 무엇입니까? 수학은 말 그대로, 의도적으로 전혀 의미가 없기 때문입니다. 그리고 논리도 그렇습니다.”
비즈니스에 영향을 미치는 것은 그것이 시작되는 곳이자 끝나는 곳입니다.
AI는 신뢰할 수 있는 제안을 생성해야 합니다. 왜 안 돼 인증을 요청하다?
더 많은 정보학, 더 적은 기술
다음은 큰 문제는 아니지만, 정확하지 않은 용어가 우리 '길드'를 감염시킨 것 같습니다.
저는 1969년에 코펜하겐 대학교에서 공부를 시작했습니다. 제 교수는 Peter Naur였습니다. 그는 다음과 같은 분야로 가장 잘 알려져 있습니다.
- Edsger Dijkstra et al.과 공동 저자. Algol-60 프로그래밍 언어
- BNF의“N”, 많은 언어 정의에 사용되는 Backus-Naur-Form
- 그는 "컴퓨터 과학자"라고 부르기를 원하지 않았고 "컴퓨터 과학"대신 "데이터 로지"를 선호했습니다. 그 이유는 두 영역 (컴퓨터와 인간의 지식)이 매우 다르고 그의 관심이 데이터에 있었기 때문입니다. 우리가 인간으로 만들고 묘사했습니다.
- 컴퓨터 과학에 대한 그의 공헌 모음집 인 그의 저서“Computing : A Human Activity”(1992)에서 그는 프로그래밍을 수학의 한 분야로 보는 프로그래밍 학교를 거부했습니다.
- IEEE 컴퓨터 협회의 컴퓨터 개척자 상 (1986)
- 2005 년 튜링 상 수상자, 그의 수상 강연 제목은 "컴퓨팅 대 인간 사고"
(더 많은 배경보기 여기에서 지금 확인해 보세요..)
실제로는 세 가지 경쟁 용어가 있습니다.
- 컴퓨터 과학
- 정보학
- 정보 과학
"정보 과학"은 전통적으로 사서와 기록 보관인이 수행하는 종류의 정보 처리를 의미합니다. 요즘은 다 디지털인데...
유럽 및 기타 국가의 대부분에서는 컴퓨터 과학 대신 "정보학"이 사용됩니다. 미국 등에서는 의료 분야의 정보를 다루기 위해 인포매틱스(informatics)를 자주 사용한다.
그리고 "컴퓨터 과학"이 있습니다. 오늘날 학문적으로는 논리와 기능을 기반으로 하는 매우 수학적이며 추상적입니다. 그러나 이는 데이터를 처리하는 데 사용되는 일련의 기술로 자주 설명됩니다. 그러나 "컴퓨터를 구성하는 방법"이라는 직접적인 의미는 더 이상 범위에 포함되지 않습니다. 나는 엔지니어와 물리학자가 이 문제를 처리할 것이라고 기대합니다.
고속도로를 건설하면 고속도로와 관련된 특별한 기술을 사용할 수 있습니다. 하지만 그게 나를 "고속도로 과학자"로 만드는 걸까요? 별로.
Communications of the ACM(Association for Computing Machinery, 로그인 필요)에서 ACM의 전 회장인 Peter Denning은 "컴퓨터 과학은 과학인가?"라는 제목의 기사에서 컴퓨터 "과학"에 대해 찬반 주장을 펼치고 있습니다. 컴퓨터 과학은 과학이 되기 위한 모든 기준을 충족하지만 자초적인 신뢰성 문제를 안고 있습니다.”라고 2005년에 그는 다음과 같이 결론을 내렸습니다.
“컴퓨터 공학 주장을 검증하세요
거기에 우리가 있습니다. 우리는 광고 부서의 과대 광고가 우리 실험실에 침투하도록 허용했습니다. Walter Tichy는 400년 이전에 출판된 1995개의 컴퓨터 과학 논문 샘플에서 제안된 모델이나 가설 중 약 50%가 이를 테스트하지 않았다는 사실을 발견했습니다[12]. 다른 과학 분야에서는 검증되지 않은 가설이 포함된 논문의 비율이 약 10%였습니다. Tichy는 우리가 더 많은 테스트를 하지 않으면 많은 불건전한 아이디어가 실제로 시도될 수 있고 과학으로서 우리 분야의 신뢰성이 낮아진다고 결론지었습니다. …
우리 분야에 대한 인식은 세대적인 문제인 것 같습니다. 나이가 많은 회원들은 해당 분야의 세 가지 뿌리인 과학, 공학, 수학 중 하나에 자신을 동일시하는 경향이 있습니다. 과학 패러다임은 다른 두 그룹에서는 거의 보이지 않습니다.
새로운 컴퓨팅 기술에 대한 이전 세대보다 훨씬 덜 경외심을 느끼는 젊은 세대는 비판적 사고에 더 개방적입니다. 컴퓨터 과학은 항상 그들의 세계의 일부였습니다. 그들은 그 타당성에 의문을 제기하지 않습니다. 그들의 연구에서 그들은 점점 더 과학 패러다임을 따르고 있습니다.”
Tichy에 대한 참조는 Tichy, W입니다. 컴퓨터 과학자들이 더 많은 실험을 해야 할까요? IEEE 컴퓨터 1998.
궁금합니다. 우리는 여전히 "광고 부서의 과대 광고가 우리 실험실에 침투"하도록 허용하고 있습니까?
저는 "정보학"이 우리가 하는 일을 가리키는 가장 일반적이고 정확한 용어라고 생각합니다. 컴퓨팅은 인간 활동이고 정보학은 인간을 위해, 인간에 의해 정보를 처리하는 인간 활동을 설명합니다.
네, 이제 기분이 좋아졌어요. 감사합니다!
미래를 내다보며: 인지 개선
미래의 데이터 모델링?
독자 중 일부는 기억하겠지만 저는 수년 간의 모델링 경력을 지닌 (그래프) 데이터 모델러입니다. 저는 또한 비즈니스 문제에 정보학을 적용하여 비즈니스 문제 해결을 우리가 하는 핵심 업무로 삼는 것을 강력하게 옹호합니다. 우리는 지난 15~25년 동안 비용/이익에 대한 논의로 어려움을 겪었습니다.
사람들은 또한 데이터 모델링이 이제 종말에 이르렀다고 믿는 경향이 있습니다. 생산성을 높이고 품질을 높이려면 어떻게 해야 할까요? 1970년대에 개발됐어요. 70년대에는 얼마나 남았나요? (글쎄요, 그냥 농담입니다: 관계형 모델링은 살아남았습니다…)
어떤 이론이든 가정에 도전해야 합니다. 현재 우리가 알고 있는 데이터 모델링은 복잡한 다이어그램을 사용하는 매우 엔지니어링 지향적이며 소비자의 최선의 희망에 너무 가깝지 않습니다. 여러 면에서 이는 여전히 데이터베이스 정규화 등과 같은 공리적 패러다임을 기반으로 하는 "청사진"입니다. 이는 데이터베이스와 같은 물리적 구성의 구축을 의미합니다. 예외는 의미론적 모델(그래프)이 표현력, 정확성 및 상대적인 사용 용이성(읽기: "지식 그래프")으로 인해 상당한 성공을 거두는 정보학 분야입니다.
강력하고 미래 지향적인 연구가 존재합니다
그럼 이제 여행은 끝나는 걸까요? JSON이 데이터 모델의 전체 영역을 차지하게 될까요?
나는 그렇게 생각하지 않는다. 의미론을 갖춘 데이터 모델링은 개방형 연구 분야입니다. 전통적인 컴퓨터 과학 기반 데이터 모델링은 논리와 추상화로 강화된 다소 좁은 공리와 패러다임을 기반으로 했습니다.
그러나 의미론과 인지는 매우 넓은 담론의 세계로 향하는 문을 열어줍니다. 실제로 지난 수년 동안 데이터 모델링이 시도한 것은 인지과학(심리학, 임상, 철학)의 영역으로 들어가려는 것이었습니다.
데이터 모델은 우리의 감각으로 인식되는 세계에 대한 해석으로, 우리가 보고 경험하는 모든 것에 대한 인식을 형성합니다. 이것이 앞으로 나아갈 열린 길입니다!
그렇다면 우리는 무엇을 보고 있는 걸까요? 재미삼아 이를 '인지 위치 확인 시스템'(CPS)이라고 부르겠습니다. 보세요:

여행을 다녀온 숙련된 CPS 사용자는 해당 사진이 프랑스 파리에서 촬영된 것임을 알 수 있습니다. 어떤 사람들은 강이 센강이라는 이름으로 알려져 있다는 사실도 알고 있을 것입니다.
시각적 인지에 의한 생존
나를 포함한 대부분의 동물의 기본 인지 능력은 무엇보다도 다음과 같은 상황을 이해하는 것을 목표로 합니다.

앗, 사자! (남성) 실제로 숨으려고 하는 것은 아닙니다. 잔디 - 니가 맞았 어! 그러나 결정을 내릴 수 있는 풍부한 컨텍스트는 없습니다. 본능을 따르십시오( 차로 돌아가는 것도 좋은 생각입니다).
그리고 여기 또 다른 맥락이 있습니다.

이런 – 또 다른 사자! 이번에는 여자인데 아마 배가 꽉 차 있을 거예요. 작업할 컨텍스트가 좀 더 많습니다. 그 짐승(누우?)은 이미 거의 잡아먹혔습니다. 추론: 지금은 배가 고프지 않습니다. 사진을 찍고 뒤로 물러나 조용하고 조용하게 – 당신과 같은 세계적 수준의 사진작가에게는 충분히 안전한 것 같습니다…
이러한 문제에 대한 풍부한 학술 연구 포트폴리오가 있습니다. 우리는 뇌의 인지 처리 장치에 도달하는 지속적인 감각(지각)의 흐름을 통해 우리에게 제시되는 상황에 대한 현장, 지금, 여기의 이해를 처리하도록 진화했습니다. 그것은 기본 심리학에서 신경심리학, 인지 신경과학, 심지어 지능, 의식, 철학까지 이어집니다.
나는 지난 10년 동안 다양한 연구자와 작가들을 팔로우해 왔으며 여기서는 흥미로운 관찰이 담긴 작은 행렬을 살펴보겠습니다.
지도
분명히 지도는 주의와 이해를 쉽게 하기 위한 탐구의 일부입니다. 다음은 런던 지하철 지도(중심)입니다.
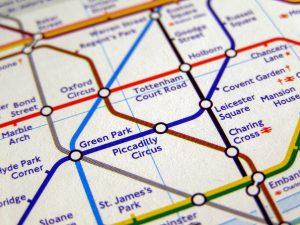
우선, 지도에는 위에서 설명한 것처럼 여러 가지 특성이 있습니다.
- 위치가 매핑되었습니다.
- 원하는 경우 관계나 경로가 매핑됩니다.
- 지도는 그래프이고, 그래프는 지도입니다!
- 지도는 직관적으로 이해됩니다
또한 지도에는 위치/랜드마크가 표시되어 있습니다. 그러나 슬론 스퀘어(Sloane Square) 지하철역 근처에 무엇이 있는지 잊어버린 경우 언제든지 햇빛에 일어나 CPS가 주변 환경(= 상황)을 인식하는지 확인할 수 있습니다. "아, 응, 저기 노란 집에 있는 작은 가게에 있는 게 우리가 신혼여행 때 엘렌을 위해 빨간 두건을 샀던 곳이야."
데이터 모델을 만들 때 지도 우화를 생각하는 것은 간단하고 강력합니다. 이것이 제가 몇 년 전에 ER 다이어그램과 UML 클래스 다이어그램을 포기한 이유입니다.
위치 표시자/위치 표시/장소 이름
길을 찾는 것은 지도와 인지적 직관 그 이상입니다. Michael Bond(과학 저널리스트이자 New Scientist의 전 수석 편집자)는 그의 뛰어난 저서 “Wayfinding”에서 Picador MacMillan 2020에서 몇 가지 놀라운 관찰과 계시를 받았습니다.
그는 인류학자인 아리안 버크(Ariane Burke)의 말을 인용하여 초기 현대 인류가 광범위한 사회적 네트워크를 가지고 있었다는 고고학적 증거가 있다고 말했습니다. 그녀는 전화 통화에서 “이러한 광범위한 네트워크는 우리 문화에 필수적이었습니다.”라고 설명했습니다. “구석기 시대에는 주변에 사람이 비교적 적었다는 것을 기억하십시오. … 공간적으로 광범위한 소셜 네트워크를 유지하는 것은 지속적인 생존을 보장하는 방법이었습니다. 당신은 당신의 연락처에 대한 정보와 그들이 풍경에 대해 당신에게 말하는 내용을 지속적으로 업데이트해야 하는 매우 역동적인 인지 지도가 필요할 것입니다.”
Bond는 또한 지형학적 지명(toponyms)의 사용을 언급합니다. 예를 들어, 스코틀랜드에 있는 그의 부모님 농장에서 북서쪽으로 가면 '빛나고 빛나는 시냇물 합류점'을 만나고, 오래된 가축 산책로인 '새바위'를 따라갑니다. 1마일 정도 더 가면 "큰 검은 언덕"을 만나고 "붉은 시내"를 건너게 됩니다. 바로 앞에는 "전투의 언덕"이 있습니다. 등반 후에는 "클라우드베리 언덕"(아직도 그곳에서 자라고 있음)에 도달하게 됩니다.
역사가들은 지형적 지명이 초기 정착민들에게 위도와 경도의 전조인 지리적 참조 시스템을 제공했다고 믿습니다. 설명적인 이름은 정신적 이미지를 불러일으킵니다. 이 이름을 보면 "마당 위의 풀이 무성한 언덕"(Funtulich, 게일어로)이라는 것을 인식하게 될 것입니다. 일련의 장소 이름은 일련의 방향을 구성합니다. 이러한 장비를 갖추고 있으면 여행을 할 수 있습니다.
더 북쪽에는 캐나다 북부, 알래스카, 그린란드의 이니우트족이 있습니다. 탐험가 조지 프랜시스 리옹(George Francis Lyon)은 1822년 북서 항로를 찾기 위해 캐나다 북극의 이글루릭(Igloolik)이라는 작은 마을을 통과했을 때 “모든 개울, 호수, 만, 지점 또는 섬에는 이름이 있고 심지어 특정 섬에도 이름이 있습니다. 돌무더기야.”
외부인에게 북극은 특징이 없고 단조롭게 보일 수 있습니다. … Baffin Island의 남쪽 기슭에는 Nuluujaak, 즉 "엉덩이처럼 보이는 두 개의 섬"이 있습니다. 놓치기 어렵습니다. 해안 위로 더 올라가면 "목이 없는 언덕"인 Qumanguaq을 보면 자신이 어디에 있는지 정확히 알 수 있습니다.
장소 이름 지정에 대한 이러한 접근 방식은 지역 지형이나 문화보다는 고국의 친구, 후원자 또는 유명인을 기념하는 경향이 있었던 최초의 유럽인 아메리카 탐험가가 취한 접근 방식과 매우 다릅니다.
우리가 탐색하는 방법
Michael Bond를 떠나기 전에 생각해 볼 가치가 있는 몇 가지 발언은 다음과 같습니다.
“인간은 어떤 인공 시스템보다 헤아릴 수 없을 정도로 정교하고 능력이 뛰어난 내부 항해자를 축복받았습니다. 어떻게 사용하나요?
심리학자들은 사람들이 익숙하지 않은 지형에서 길을 찾을 때 두 가지 전략 중 하나를 따른다는 사실을 발견했습니다. 즉, 모든 것을 공간에서 자신의 위치, '자기 중심적' 접근 방식과 연관시키거나 풍경의 특징과 연관 방식에 의존하는 것입니다. 서로에게 자신이 어디에 있는지 알려주는 '공간적' 접근 방식입니다.”
내가 흥미롭게 생각하는 또 다른 관찰은 우리가 실제로 풍경 속에서 이동하고 경로를 따라가는 방식입니다. 경계는 위치만큼 중요한 것 같습니다. 그리고 나는 그것이 경계가 탐색을 상당히 (그리고 직관적으로) 쉽게 할 수 있는 구성된 "풍경"으로 일반화될 수 있다고 생각합니다.
마이클 본드의 'Wayfinding'을 적극 추천합니다.
모션, 공간
제가 언급할 다음 책은 ''입니다.움직이는 마음: 행동이 생각을 형성하는 방법” 2019년 Barbara Tversky(스탠포드 심리학 명예 교수) 저작.
여러 면에서 Michael Bond가 보고한 것과 동일한 결과를 바탕으로 구성되었습니다.
대부분의 생물과 마찬가지로 사람들도 이곳 저곳으로 이동합니다. 그들이 움직일 때 땅 위에, 뇌 안에, 길과 장소에 흔적을 남깁니다. 해마는 움직임을 경로, 일련의 장소 및 경로로 기록합니다. 이것은 사실, 2014년 노벨 생리의학상, 절반은 John O'Keefe에게, 나머지 절반은 "뇌의 위치 확인 시스템을 구성하는 세포를 발견한 공로"로 May-Britt Moser와 Edvard I. Moser에게 공동으로 수여되었습니다. 이 세포는 격자 세포(grid cell)라고 불리며 뇌의 공간 구조를 생성할 때 해마와 함께 작동하는 마커로 사용됩니다.
Barbara Tversky는 더 넓은 관점을 가지고 있습니다. 그녀는 마음 속에 공간적으로 기록된 동작이 사고의 플랫폼임을 증명하고 싶습니다. 그래프뿐만 아니라 단어, 제스처, 그래픽도 마찬가지입니다. 또한 추론과 발견을 촉진하고 커뮤니티의 생성, 수정 및 추론을 허용합니다. 분류는 인지된 전체 그림에 대한 정신적 단순화입니다. 물론이죠. Tversky는 스탠포드와 컬럼비아 대학교의 심리학 연구실에서 이러한 것들의 여러 측면을 연구했습니다.
공간에는 의미가 있고, 근접성은 모든 차원에서 친밀함을 의미합니다. 수직: 위, 모든 것이 양호, 수평: 중립. 공간은 특별하고 초형태적이며 생존에 필수적이며 다른 지식의 기초입니다. 제스처로 지원됩니다.
즉, 마음으로부터의 커뮤니케이션은 쉽게 인식할 수 있어야 하며, 그 커뮤니케이션(커뮤니케이션)이 맥락에서 중요한 작업에 어떻게 도움이 될 수 있는지 소비자에게 명백해야 합니다. 향후 데이터 모델을 향상하는 방법에 대한 좋은 권장 사항인 것 같습니다!
“Mind in Motion: How Action Shapes Thought”는 인지 과학 분야의 중요한 작품입니다. 훌륭한 YouTube 동영상이 있습니다(공간적 사고는 사고의 기초입니다) 2022년부터 그녀와 함께, 여기에서 지금 확인해 보세요..
뇌의 인지(왼쪽 및 오른쪽)
인지 문제에 대해 가장 중요하고 신중하게 연구된 책 중 하나는 정신과 의사, 신경과학 연구자, 철학자, 문학 학자인 Dr. Ian McGilchrist가 쓴 "The Matter with Things: Our Brains, Our Delusions, and the Unmaking of the World"입니다. 2021.
자신의 말로 :
“사실 부품이 없어요. 부품은 세상에 관심을 기울이는 특정 방식의 인공물입니다. 전체 만 있습니다. 그리고 우리가 부분으로 생각하는 것들은 다른 수준에서는 전체이고, 우리가 전체로 생각하는 것들은 더 큰 전체의 부분으로 볼 수 있습니다.
그러나 사물을 여러 부분으로 쪼개는 일은 좌반구의 단편적인 관심이 만들어낸 인공물입니다. 따라서 이 작은 세부 사항에 초점을 맞추려고 하기 때문에 360도 주의 범위 중 세 개 정도의 아주 작은 부분에 집중하게 되고, 이는 우반구와는 다른 시각으로 세상을 바라보게 됩니다.”
현학적인 좌반구와 직관적인 우반구
우리의 두 뇌 반구 사이의 노동 분업은 몇 가지 예로 요약될 수 있습니다.
| 좌회전 | 권리 |
| 알려진 | |
| 확실성 | 가능성 |
| 정착 | 흐름 |
| 부품 | 모든 |
| 명백한 | 절대적인 |
| 멍한 | 문맥 |
| 일반 | 유일한 |
| 부량 | 자격 |
| 무생물 | 생명있는 |
| 낙관적인 | 현실적인 |
| 다시 제시 | 제시 |
이분법의 이유는 진화론적이다. 단순화된 설명은 위의 두 사자 사진과 대략적으로 일치합니다. 하나는 “아, 그게 뭔지 알아요”이고, 다른 하나는 “도와주세요. 도망가는 게 좋겠어요!”입니다. 두 반응 모두 매우 유용합니다.
여기에 매우 흥미로운 내용이 있습니다. 유튜브 강의: Iain McGilchrist 박사는 CERN의 IdeaSquare 혁신 공간에서 인간 두뇌와 철학의 관점에서 현실의 본질에 대해 논의했습니다. 이번 행사는 학생들에게 대규모 시스템 사고 능력과 사회 변화 유도 방법을 갖춘 파일럿 코스와 연계해 진행됐다. 그는 또한 웹사이트를 운영하고 있습니다 여기에서 지금 확인해 보세요..
그의 최근 저서 '사물에 관한 물질'은 1,300권, 총 XNUMX페이지에 이른다. 한동안 바쁘게 지내야합니다!
데이터 모델이 무엇인지 더 잘 이해할 수 있는 여러 가지 기회가 있다는 점을 확신하셨기를 바랍니다. 눈을 떼지 마세요 열 수! 직관으로 소통하라! 2024년은 혁신적인 진화로 모든 데이터가 더 쉬워지는 해가 될 것입니다!
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.dataversity.net/handling-data-concerns-in-2024-and-onwards/

