오늘 우리는 Meta가 개발한 Code Llama 기반 모델을 고객이 다음을 통해 사용할 수 있음을 발표하게 되어 기쁘게 생각합니다. Amazon SageMaker 점프스타트 추론 실행을 위해 한 번의 클릭으로 배포합니다. Code Llama는 코드와 자연어 프롬프트 모두에서 코드와 코드에 대한 자연어를 생성할 수 있는 최첨단 LLM(대형 언어 모델)입니다. ML을 빠르게 시작할 수 있도록 알고리즘, 모델 및 ML 솔루션에 대한 액세스를 제공하는 기계 학습(ML) 허브인 SageMaker JumpStart로 이 모델을 시험해 볼 수 있습니다. 이 게시물에서는 SageMaker JumpStart를 통해 Code Llama 모델을 검색하고 배포하는 방법을 안내합니다.
코드 라마
코드 라마(Code Llama)는 에서 출시된 모델입니다. 메타 이는 Llama 2를 기반으로 구축되었습니다. 이 최첨단 모델은 개발자가 잘 문서화된 고품질 코드를 생성할 수 있도록 지원함으로써 개발자의 프로그래밍 작업 생산성을 향상시키도록 설계되었습니다. 이 모델은 Python, C++, Java, PHP, C#, TypeScript 및 Bash에서 탁월하며 개발자의 시간을 절약하고 소프트웨어 워크플로를 보다 효율적으로 만들 수 있는 잠재력을 가지고 있습니다.
이는 기본 모델(Code Llama), Python 특수 모델(Code Llama Python), 자연어 지침을 이해하기 위한 지침 따르기 모델(Code Llama Instruct) 등 다양한 애플리케이션을 포괄하도록 설계된 세 가지 변형으로 제공됩니다. 모든 Code Llama 변형은 7B, 13B, 34B 및 70B 매개변수의 네 가지 크기로 제공됩니다. 7B 및 13B 기본 및 명령 변형은 주변 콘텐츠를 기반으로 채우기를 지원하므로 코드 지원 애플리케이션에 이상적입니다. 모델은 Llama 2를 기본으로 사용하여 설계되었으며 500억 개의 코드 데이터 토큰에 대해 훈련되었으며, Python 특수 버전은 증분 100억 개의 토큰에 대해 훈련되었습니다. Code Llama 모델은 최대 100,000개의 컨텍스트 토큰으로 안정적인 세대를 제공합니다. 모든 모델은 16,000개의 토큰 시퀀스에 대해 훈련되었으며 최대 100,000개의 토큰을 사용한 입력에 대한 개선 사항을 보여줍니다.
해당 모델은 동일한 모델로 제공됩니다. Llama 2로서의 커뮤니티 라이센스.
SageMaker의 기초 모델
SageMaker JumpStart는 SageMaker의 ML 개발 워크플로 내에서 사용할 수 있는 Hugging Face, PyTorch Hub, TensorFlow Hub 등 인기 모델 허브의 다양한 모델에 대한 액세스를 제공합니다. 최근 ML의 발전으로 인해 다음과 같은 새로운 종류의 모델이 등장했습니다. 기초 모델는 일반적으로 수십억 개의 매개변수에 대해 교육을 받고 텍스트 요약, 디지털 아트 생성, 언어 번역과 같은 광범위한 사용 사례에 적용할 수 있습니다. 이러한 모델은 훈련하는 데 비용이 많이 들기 때문에 고객은 이러한 모델을 직접 훈련하기보다는 기존의 사전 훈련된 기초 모델을 사용하고 필요에 따라 미세 조정하기를 원합니다. SageMaker는 SageMaker 콘솔에서 선택할 수 있는 선별된 모델 목록을 제공합니다.
SageMaker JumpStart 내에서 다양한 모델 공급자의 기초 모델을 찾을 수 있으므로 기초 모델을 빠르게 시작할 수 있습니다. 다양한 작업이나 모델 제공자를 기반으로 기반 모델을 찾고, 모델 특성 및 사용 조건을 쉽게 검토할 수 있습니다. 테스트 UI 위젯을 사용하여 이러한 모델을 시험해 볼 수도 있습니다. 대규모 기반 모델을 사용하려는 경우 SageMaker를 종료하지 않고도 모델 공급자가 사전 구축한 노트북을 사용하여 이를 수행할 수 있습니다. 모델은 AWS에서 호스팅 및 배포되므로 모델을 대규모로 평가하거나 사용하는 데 사용되는 데이터가 제3자와 절대 공유되지 않는다는 점을 확신할 수 있습니다.
SageMaker JumpStart에서 Code Llama 모델을 살펴보세요
Code Llama 70B 모델을 배포하려면 다음 단계를 완료하세요. 아마존 세이지 메이커 스튜디오:
- SageMaker Studio 홈 페이지에서 다음을 선택합니다. 점프 시작 탐색 창에서
- Code Llama 모델을 검색하고 표시된 모델 목록에서 Code Llama 70B 모델을 선택하십시오.
Code Llama 70B 모델 카드에서 모델에 대한 자세한 정보를 확인할 수 있습니다.
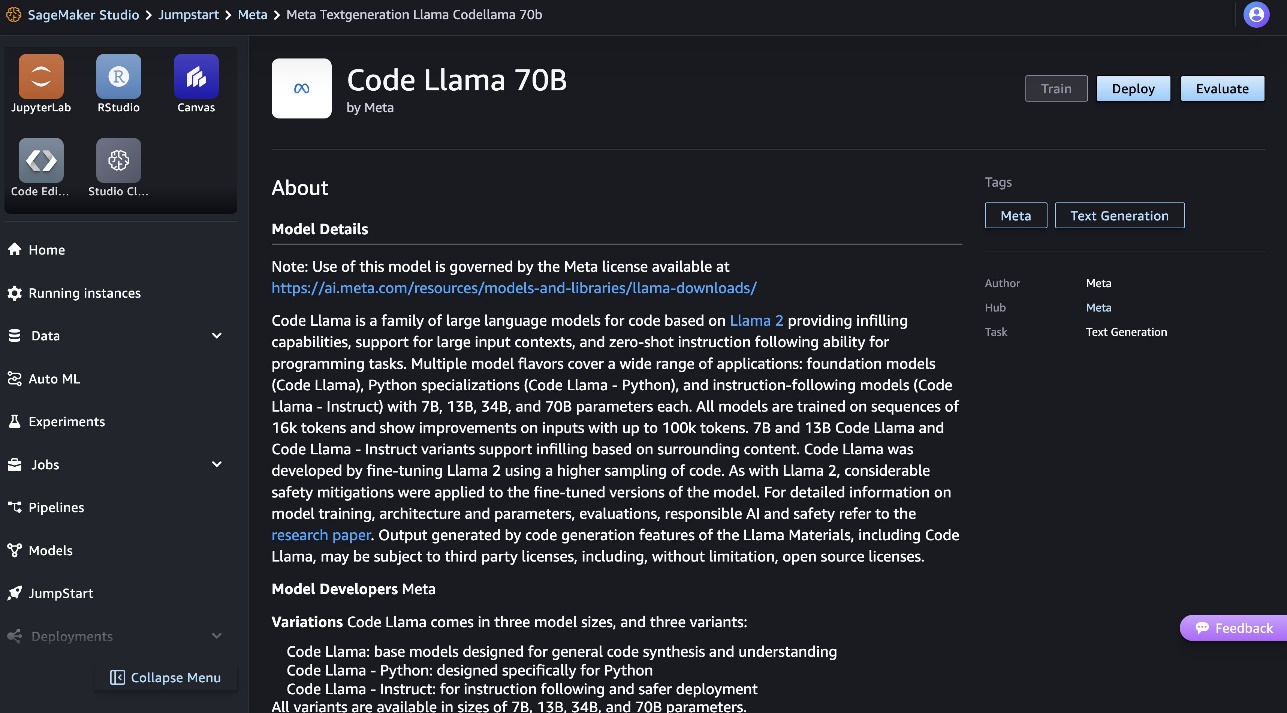
다음 스크린샷은 엔드포인트 설정을 보여줍니다. 옵션을 변경하거나 기본 옵션을 사용할 수 있습니다.
- 최종 사용자 사용권 계약(EULA)에 동의하고 다음을 선택하세요. 배포.
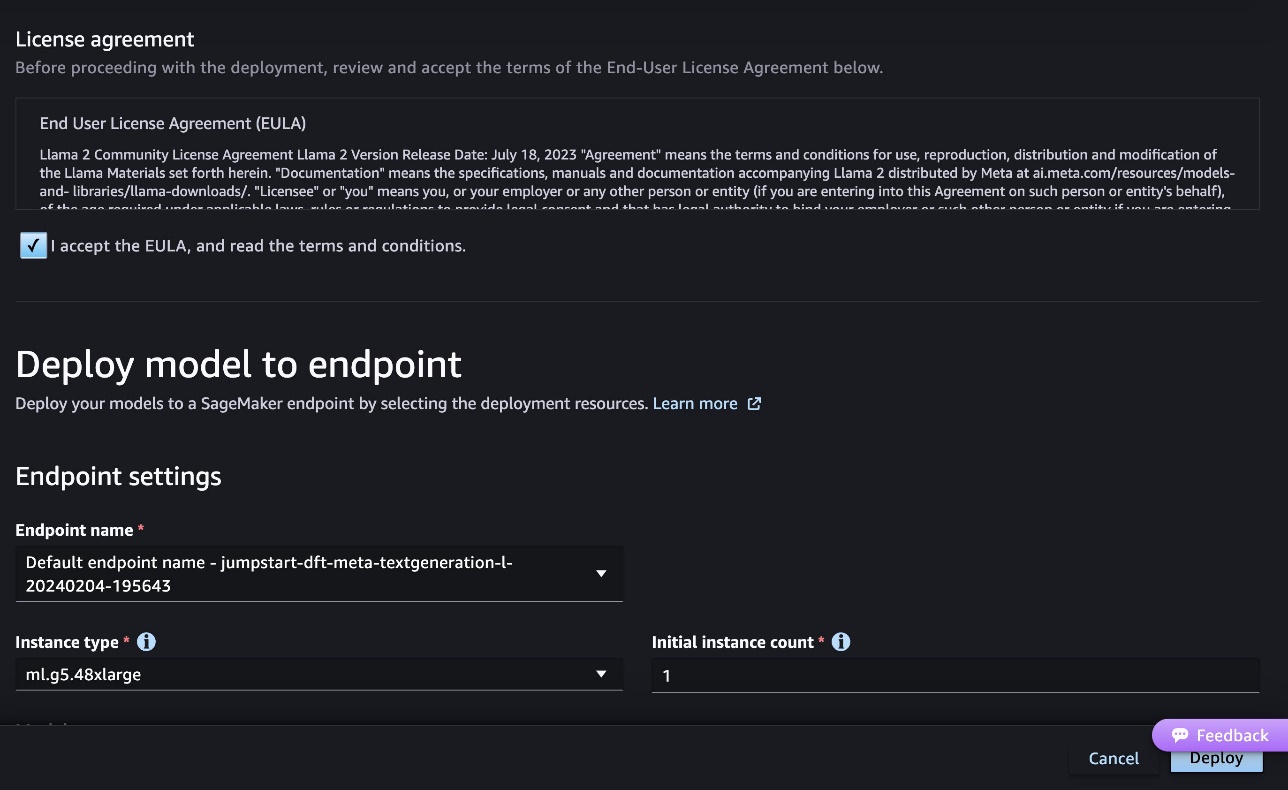
그러면 다음 스크린샷과 같이 엔드포인트 배포 프로세스가 시작됩니다.
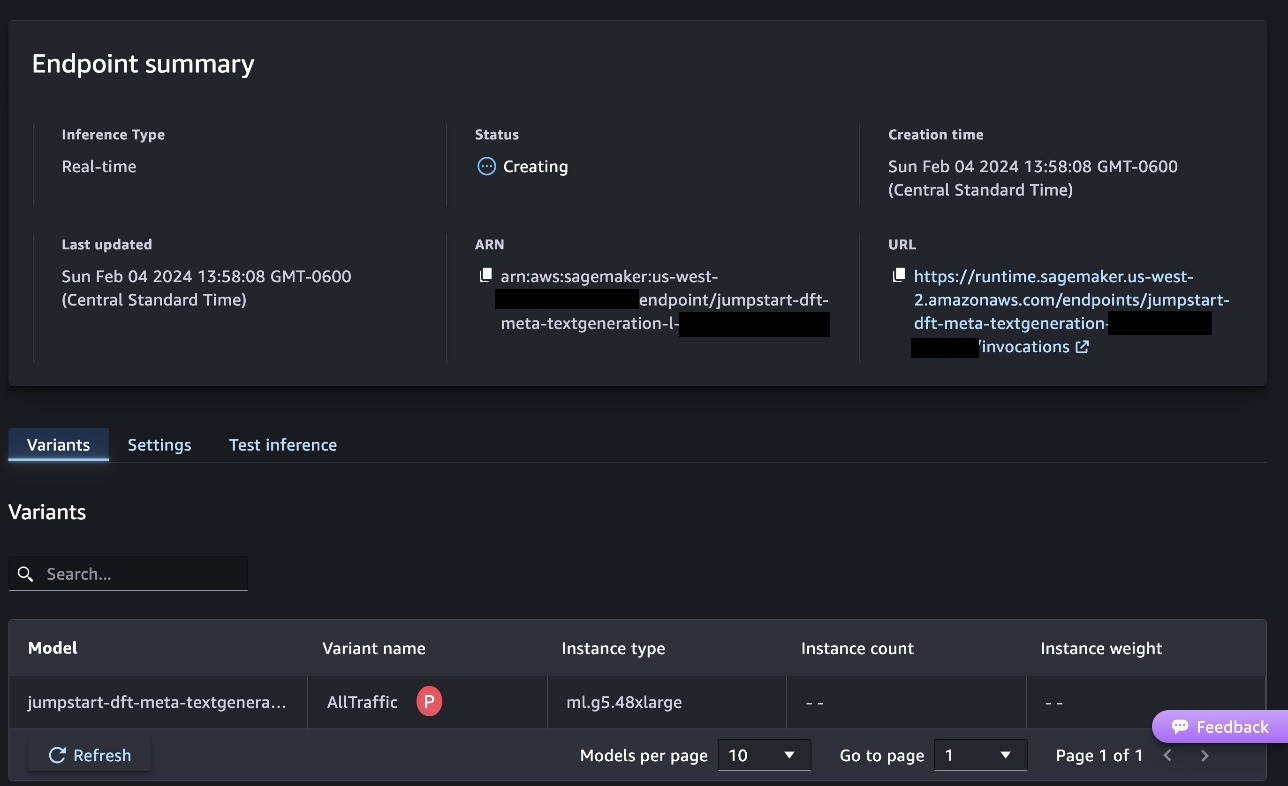
SageMaker Python SDK를 사용하여 모델 배포
또는 다음을 선택하여 예제 노트북을 통해 배포할 수 있습니다. 노트북 열기 Classic Studio의 모델 세부정보 페이지 내. 예제 노트북은 추론을 위해 모델을 배포하고 리소스를 정리하는 방법에 대한 엔드투엔드 지침을 제공합니다.
노트북을 사용하여 배포하려면 먼저 다음에서 지정한 적절한 모델을 선택합니다. model_id. 다음 코드를 사용하여 SageMaker에서 선택한 모델을 배포할 수 있습니다.
이렇게 하면 기본 인스턴스 유형 및 기본 VPC 구성을 포함한 기본 구성으로 SageMaker에 모델이 배포됩니다. 다음에서 기본값이 아닌 값을 지정하여 이러한 구성을 변경할 수 있습니다. JumpStart모델. 기본적으로 accept_eula 가 False. 설정해야합니다 accept_eula=True 엔드포인트를 성공적으로 배포합니다. 그렇게 하면 앞서 언급한 사용자 라이센스 계약과 허용 가능한 사용 정책에 동의하게 됩니다. 당신은 또한 수 다운로드 라이센스 계약.
SageMaker 엔드포인트 호출
엔드포인트가 배포된 후 Boto3 또는 SageMaker Python SDK를 사용하여 추론을 수행할 수 있습니다. 다음 코드에서는 SageMaker Python SDK를 사용하여 추론을 위한 모델을 호출하고 응답을 인쇄합니다.
기능 print_response 페이로드와 모델 응답으로 구성된 페이로드를 가져와 출력을 인쇄합니다. Code Llama는 추론을 수행하는 동안 다양한 매개변수를 지원합니다.
- 최대 길이 – 모델은 출력 길이(입력 컨텍스트 길이 포함)에 도달할 때까지 텍스트를 생성합니다.
max_length. 지정된 경우 양의 정수여야 합니다. - max_new_tokens – 모델은 출력 길이(입력 컨텍스트 길이 제외)에 도달할 때까지 텍스트를 생성합니다.
max_new_tokens. 지정된 경우 양의 정수여야 합니다. - num_beams – 그리디 검색에 사용되는 빔의 개수를 지정합니다. 지정된 경우 다음보다 크거나 같은 정수여야 합니다.
num_return_sequences. - no_repeat_ngram_size – 모델은 다음 단어의 시퀀스를 보장합니다.
no_repeat_ngram_size출력 시퀀스에서 반복되지 않습니다. 지정된 경우 1보다 큰 양의 정수여야 합니다. - 온도 – 출력의 무작위성을 제어합니다. 더 높은
temperature확률이 낮은 단어가 포함된 출력 시퀀스가 생성됩니다.temperature확률이 높은 단어가 포함된 출력 시퀀스가 생성됩니다. 만약에temperature0이면 탐욕스러운 디코딩이 발생합니다. 지정된 경우 양수 부동 소수점이어야 합니다. - 조기 중지 - 만약
True, 모든 빔 가설이 문장 토큰의 끝에 도달하면 텍스트 생성이 완료됩니다. 지정된 경우 부울이어야 합니다. - do_sample - 만약
True, 모델은 가능성에 따라 다음 단어를 샘플링합니다. 지정된 경우 부울이어야 합니다. - top_k – 텍스트 생성의 각 단계에서 모델은
top_k가장 가능성이 높은 단어. 지정된 경우 양의 정수여야 합니다. - top_p – 텍스트 생성의 각 단계에서 모델은 누적 확률을 사용하여 가능한 가장 작은 단어 집합에서 샘플링합니다.
top_p. 지정된 경우 0과 1 사이의 부동 소수점이어야 합니다. - return_full_text - 만약
True, 입력 텍스트는 출력 생성 텍스트의 일부가 됩니다. 지정된 경우 부울이어야 합니다. 기본값은 다음과 같습니다.False. - 중지 – 지정된 경우 문자열 목록이어야 합니다. 지정된 문자열 중 하나라도 생성되면 텍스트 생성이 중지됩니다.
엔드포인트를 호출하는 동안 이러한 매개변수의 하위 집합을 지정할 수 있습니다. 다음으로 이러한 인수를 사용하여 엔드포인트를 호출하는 방법의 예를 보여줍니다.
코드 완성
다음 예에서는 예상되는 끝점 응답이 프롬프트의 자연스러운 연속인 경우 코드 완성을 수행하는 방법을 보여줍니다.
먼저 다음 코드를 실행합니다.
다음 출력을 얻습니다.
다음 예에서는 다음 코드를 실행합니다.
다음 출력을 얻습니다.
코드 생성
다음 예에서는 Code Llama를 사용한 Python 코드 생성을 보여줍니다.
먼저 다음 코드를 실행합니다.
다음 출력을 얻습니다.
다음 예에서는 다음 코드를 실행합니다.
다음 출력을 얻습니다.
Code Llama 70B를 사용한 코드 관련 작업의 예는 다음과 같습니다. 모델을 사용하여 훨씬 더 복잡한 코드를 생성할 수 있습니다. 자신만의 코드 관련 사용 사례와 예제를 사용하여 시도해 보시기 바랍니다!
정리
엔드포인트를 테스트한 후에는 요금이 부과되지 않도록 SageMaker 추론 엔드포인트와 모델을 삭제해야 합니다. 다음 코드를 사용하세요.
결론
이 게시물에서는 SageMaker JumpStart에 Code Llama 70B를 소개했습니다. Code Llama 70B는 코드뿐 아니라 자연어 프롬프트에서도 코드를 생성하기 위한 최첨단 모델입니다. SageMaker JumpStart에서 몇 가지 간단한 단계를 통해 모델을 배포한 다음 이를 사용하여 코드 생성 및 코드 채우기와 같은 코드 관련 작업을 수행할 수 있습니다. 다음 단계로, 자신만의 코드 관련 사용 사례 및 데이터와 함께 모델을 사용해 보세요.
저자 소개
 카일 울리히 박사 Amazon SageMaker JumpStart 팀의 응용 과학자입니다. 그의 연구 관심사는 확장 가능한 기계 학습 알고리즘, 컴퓨터 비전, 시계열, 베이지안 비모수 및 가우시안 프로세스를 포함합니다. Duke University에서 박사 학위를 받았으며 NeurIPS, Cell 및 Neuron에 논문을 발표했습니다.
카일 울리히 박사 Amazon SageMaker JumpStart 팀의 응용 과학자입니다. 그의 연구 관심사는 확장 가능한 기계 학습 알고리즘, 컴퓨터 비전, 시계열, 베이지안 비모수 및 가우시안 프로세스를 포함합니다. Duke University에서 박사 학위를 받았으며 NeurIPS, Cell 및 Neuron에 논문을 발표했습니다.
 파루크 사비르 박사 AWS의 수석 인공 지능 및 기계 학습 전문가 솔루션 설계자입니다. 그는 오스틴에 있는 텍사스 대학교에서 전기 공학 박사 및 석사 학위를, 조지아 공과 대학에서 컴퓨터 공학 석사 학위를 받았습니다. 그는 15년 이상의 경력을 가지고 있으며 대학생들을 가르치고 멘토링하는 것을 좋아합니다. AWS에서 그는 고객이 데이터 과학, 기계 학습, 컴퓨터 비전, 인공 지능, 수치 최적화 및 관련 도메인에서 비즈니스 문제를 공식화하고 해결하도록 돕습니다. 텍사스주 댈러스에 거주하는 그와 그의 가족은 여행과 장거리 자동차 여행을 좋아합니다.
파루크 사비르 박사 AWS의 수석 인공 지능 및 기계 학습 전문가 솔루션 설계자입니다. 그는 오스틴에 있는 텍사스 대학교에서 전기 공학 박사 및 석사 학위를, 조지아 공과 대학에서 컴퓨터 공학 석사 학위를 받았습니다. 그는 15년 이상의 경력을 가지고 있으며 대학생들을 가르치고 멘토링하는 것을 좋아합니다. AWS에서 그는 고객이 데이터 과학, 기계 학습, 컴퓨터 비전, 인공 지능, 수치 최적화 및 관련 도메인에서 비즈니스 문제를 공식화하고 해결하도록 돕습니다. 텍사스주 댈러스에 거주하는 그와 그의 가족은 여행과 장거리 자동차 여행을 좋아합니다.
 준원 SageMaker JumpStart의 제품 관리자입니다. 그는 고객이 제너레이티브 AI 애플리케이션을 구축하는 데 도움이 되도록 기반 모델을 쉽게 검색하고 사용할 수 있도록 만드는 데 중점을 둡니다. Amazon에서의 그의 경험에는 모바일 쇼핑 애플리케이션 및 라스트 마일 배송도 포함됩니다.
준원 SageMaker JumpStart의 제품 관리자입니다. 그는 고객이 제너레이티브 AI 애플리케이션을 구축하는 데 도움이 되도록 기반 모델을 쉽게 검색하고 사용할 수 있도록 만드는 데 중점을 둡니다. Amazon에서의 그의 경험에는 모바일 쇼핑 애플리케이션 및 라스트 마일 배송도 포함됩니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/code-llama-70b-is-now-available-in-amazon-sagemaker-jumpstart/

