개요
오늘날 빠르게 변화하는 현지 음식 배달 세계에서 고객 만족을 보장하는 것은 기업의 핵심입니다. Zomato 및 Swiggy와 같은 주요 업체가 이 산업을 지배하고 있습니다. 고객은 신선한 음식을 기대합니다. 손상된 품목을 받으면 환불이나 할인 바우처를 고맙게 생각합니다. 그러나 식품의 신선도를 수동으로 확인하는 것은 고객과 회사 직원에게 번거로운 작업입니다. 한 가지 해결책은 딥러닝 모델을 사용하여 이 프로세스를 자동화하는 것입니다. 이러한 모델은 식품의 신선도를 예측할 수 있어 최종 검증을 위해 직원이 플래그가 지정된 불만 사항만 검토할 수 있습니다. 모델이 음식의 신선도를 확인하면 자동으로 불만 사항을 기각할 수 있습니다. 이 기사에서는 딥러닝을 사용하여 식품 품질 감지기를 구축할 것입니다.
인공 지능의 하위 집합인 딥 러닝은 이러한 맥락에서 상당한 유용성을 제공합니다. 특히 CNN(Convolutional Neural Networks)을 사용하여 음식 이미지를 사용하여 모델을 훈련하여 신선도를 식별할 수 있습니다. 우리 모델의 정확성은 전적으로 데이터 세트의 품질에 달려 있습니다. 이상적으로는 사용자의 챗봇 불만사항에서 실제 음식 이미지를 지역 음식 배달 앱에 통합하면 정확성이 크게 향상됩니다. 그러나 이러한 데이터에 대한 액세스가 부족하기 때문에 우리는 Kaggle에서 액세스할 수 있는 "신선하고 부패한 분류 데이터세트"라고 알려진 널리 사용되는 데이터세트에 의존합니다. 전체 딥러닝 코드를 탐색하려면 제공된 "복사 및 편집" 버튼을 클릭하기만 하면 됩니다. 여기에서 지금 확인해 보세요..
학습 목표
- 고객 만족과 비즈니스 성장에 있어 식품 품질의 중요성을 알아보세요.
- 식품 품질 감지기를 구성하는 데 딥 러닝이 어떻게 도움이 되는지 알아보세요.
- 이 모델의 단계별 구현을 통해 실무 경험을 쌓으세요.
- 구현과 관련된 과제와 솔루션을 이해합니다.
이 기사는 데이터 과학 블로그.
차례
식품 품질 감지기에서의 딥러닝 활용 이해
깊은 학습, 의 하위 집합 인공 지능, 주로 공간 데이터 세트를 사용하여 모델을 구성합니다. 딥 러닝 내의 신경망은 인간 두뇌의 기능을 모방하여 이러한 모델을 훈련하는 데 활용됩니다.
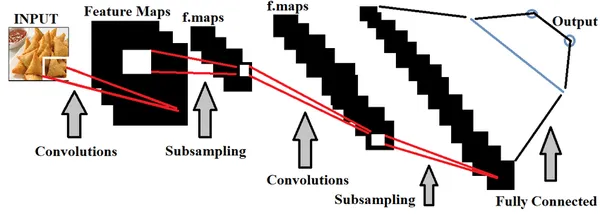
식품 품질 감지의 맥락에서, 광범위한 식품 이미지 세트를 사용하여 딥 러닝 모델을 훈련하는 것은 품질이 좋은 식품과 나쁜 식품을 정확하게 구별하는 데 필수적입니다. 우리는 할 수 있다 하이퍼 파라미터 튜닝 모델을 더욱 정확하게 만들기 위해 제공되는 데이터를 기반으로 합니다.
초지역 배송에서 식품 품질의 중요성
이 기능을 하이퍼로컬 음식 배달에 통합하면 여러 가지 이점을 얻을 수 있습니다. 이 모델은 특정 고객에 대한 편견을 피하고 정확하게 예측하여 불만 해결 시간을 단축합니다. 또한 주문 포장 과정에서 이 기능을 사용하여 배송 전에 식품 품질을 검사하여 고객이 지속적으로 신선한 식품을 받을 수 있도록 할 수 있습니다.

식품 품질 감지기 개발
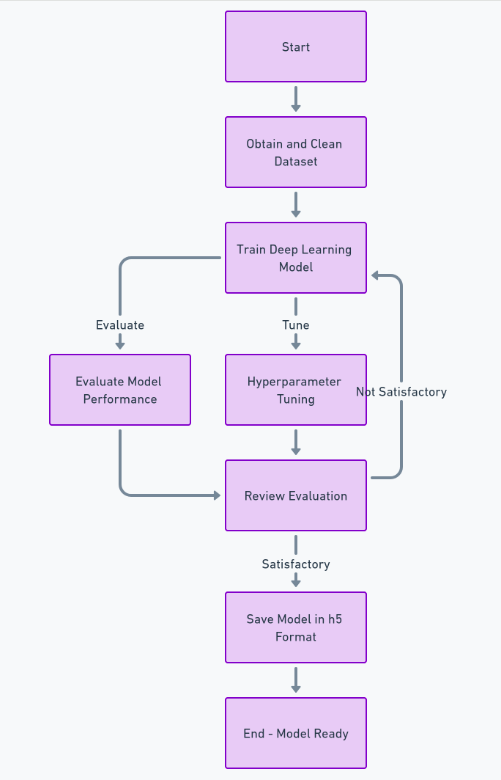
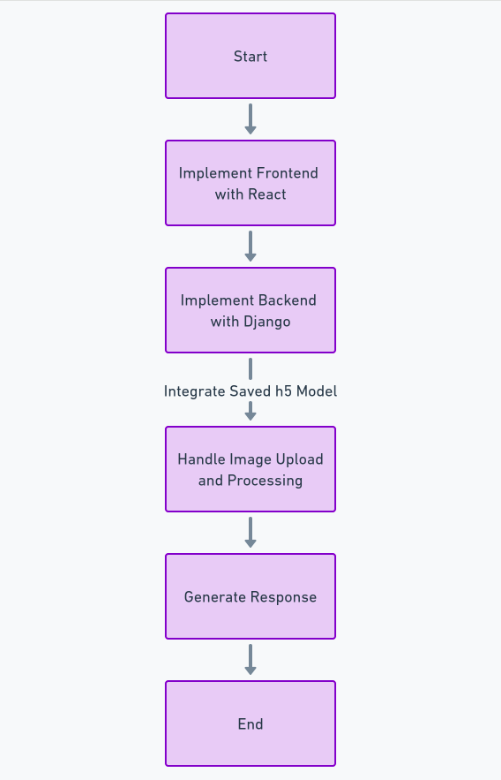
이 기능을 완전히 구축하려면 데이터 세트 획득 및 정리, 딥 러닝 모델 훈련, 성능 평가 및 하이퍼파라미터 조정 수행, 최종적으로 모델 저장과 같은 많은 단계를 수행해야 합니다. h5 체재. 그런 다음 다음을 사용하여 프런트엔드를 구현할 수 있습니다. 반응, 그리고 Python의 프레임워크를 사용하는 백엔드 장고. Django를 사용하여 이미지 업로드를 처리하고 처리하겠습니다.
데이터세트 정보
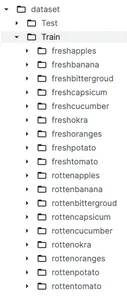
데이터 전처리 및 모델 구축에 대해 자세히 알아보기 전에 데이터세트를 이해하는 것이 중요합니다. 앞에서 설명한 것처럼 Kaggle의 데이터 세트를 사용합니다. 신선식품과 썩은 식품 분류. 이 데이터 세트는 다음과 같은 두 가지 주요 범주로 나뉩니다. Train 과 Test 어느 각각 훈련 및 테스트 목적으로 사용됩니다. 기차 폴더 아래에는 신선한 과일과 신선한 야채로 구성된 하위 폴더 9개와 썩은 과일과 야채로 구성된 하위 폴더 9개가 있습니다.
데이터세트의 주요 특징
- 이미지 다양성: 이 데이터세트에는 각도, 배경, 조명 조건 등이 다양한 음식 이미지가 많이 포함되어 있습니다. 이는 모델이 편향되지 않고 더 정확해지는 데 도움이 됩니다.
- 고품질 이미지: 이 데이터 세트에는 다양한 전문 카메라로 촬영한 매우 좋은 품질의 이미지가 포함되어 있습니다.
데이터 로딩 및 준비
이 섹션에서는 먼저 '를 사용하여 이미지를 로드합니다.tensorflow.keras.preprocessing.image.load_img' matplotlib 라이브러리를 사용하여 이미지를 함수화하고 시각화합니다. 모델 학습을 위해 이러한 이미지를 전처리하는 것은 정말 중요합니다. 여기에는 모델에 적합하도록 이미지를 정리하고 구성하는 작업이 포함됩니다.
import os
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import load_img
def visualize_sample_images(dataset_dir, categories):
n = len(categories)
fig, axs = plt.subplots(1, n, figsize=(20, 5))
for i, category in enumerate(categories):
folder = os.path.join(dataset_dir, category)
image_file = os.listdir(folder)[0]
img_path = os.path.join(folder, image_file)
img = load_img(img_path)
axs[i].imshow(img)
axs[i].set_title(category)
plt.tight_layout()
plt.show()
dataset_base_dir = '/kaggle/input/fresh-and-stale-classification/dataset'
train_dir = os.path.join(dataset_base_dir, 'Train')
categories = ['freshapples', 'rottenapples', 'freshbanana', 'rottenbanana']
visualize_sample_images(train_dir, categories)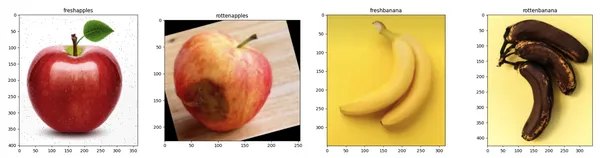
이제 훈련 및 테스트 이미지를 변수에 로드해 보겠습니다. 모든 이미지의 크기를 동일한 높이와 너비 180으로 조정하겠습니다.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
img_height = 180
img_width = 180
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
validation_split=0.2)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='training')
validation_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='validation')
모델 빌딩
이제 'tensorflow.keras'의 Sequential 알고리즘을 사용하여 딥러닝 모델을 구축해 보겠습니다. 3개의 컨볼루션 레이어와 Adam 옵티마이저를 추가하겠습니다. 실제적인 부분을 다루기 전에 먼저 ''라는 용어가 무엇인지 이해해 봅시다.순차 모델','아담 옵티마이저'및'컨볼루션 계층' 평균.
순차 모델
순차 모델은 레이어 스택으로 구성되어 Keras의 기본 구조를 제공합니다. 이는 신경망이 단일 입력 텐서와 단일 출력 텐서를 특징으로 하는 시나리오에 이상적입니다. 순차적인 실행 순서로 레이어를 추가하므로 레이어가 쌓인 간단한 모델을 구성하는 데 적합합니다. 이러한 단순성은 순차 모델을 매우 유용하고 구현하기 쉽게 만듭니다.
아담 옵티마이저
Adam의 약어는 'Adaptive Moment Estimation'입니다. 확률적 경사하강법 대신 최적화 알고리즘으로 사용되어 네트워크 가중치를 반복적으로 업데이트합니다. Adam Optimizer는 각 네트워크 가중치에 대해 학습률(LR)을 유지하므로 데이터의 노이즈를 처리하는 데 유리합니다.
컨벌루션 레이어(Conv2D)
이는 CNN(Convolutional Neural Networks)의 주요 구성 요소입니다. 주로 이미지와 같은 공간 데이터셋을 처리하는 데 사용됩니다. 이 레이어는 컨볼루션 함수나 연산을 입력에 적용한 후 결과를 다음 레이어에 전달합니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size)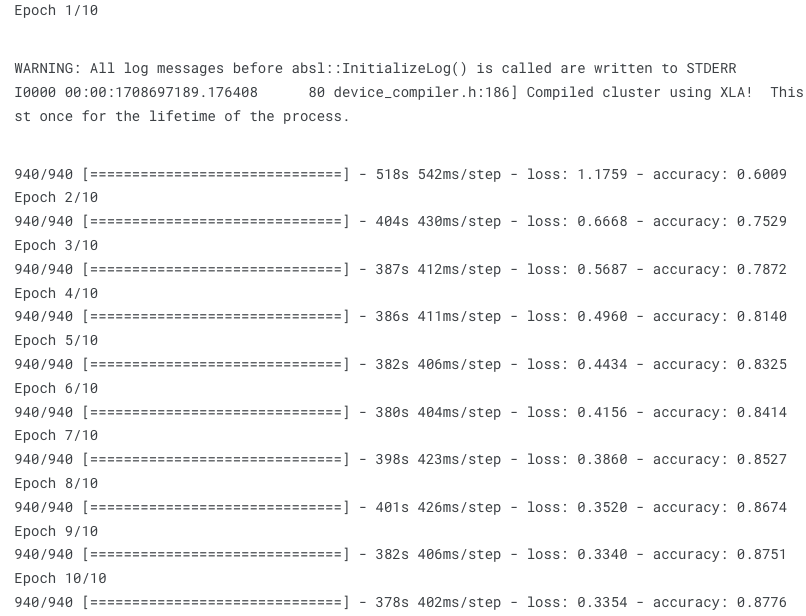
식품 품질 감지기 테스트
이제 새로운 음식 이미지를 제공하여 모델을 테스트하고 신선한 음식과 썩은 음식을 얼마나 정확하게 분류할 수 있는지 살펴보겠습니다.
from tensorflow.keras.preprocessing import image
import numpy as np
def classify_image(image_path, model):
img = image.load_img(image_path, target_size=(img_height, img_width))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
predictions = model.predict(img_array)
if predictions[0] > 0.5:
print("Rotten")
else:
print("Fresh")
image_path = '/kaggle/input/fresh-and-stale-classification/dataset/Train/
rottenoranges/Screen Shot 2018-06-12 at 11.18.28 PM.png'
classify_image(image_path, model)
보시다시피 모델은 올바르게 예측했습니다. 우리가 준대로 로테노렌지 입력으로서의 이미지는 모델이 이를 정확하게 예측한 것입니다. 썩은.
프론트엔드(React) 및 백엔드(Django) 코드의 경우 GitHub에서 전체 코드를 볼 수 있습니다. (링크)
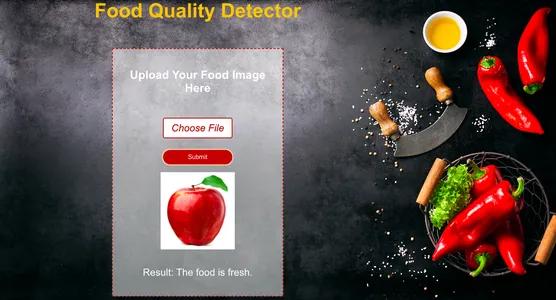
결론
결론적으로, Hyperlocal Delivery 앱에서 식품 품질 불만 사항을 자동화하기 위해 웹 앱과 통합된 딥러닝 모델 구축을 제안합니다. 그러나 제한된 훈련 데이터로 인해 모델이 모든 음식 이미지를 정확하게 감지하지 못할 수도 있습니다. 이 구현은 더 큰 솔루션을 향한 기본 단계 역할을 합니다. 이러한 앱 내에서 사용자가 실시간으로 업로드한 이미지에 액세스하면 모델의 정확성이 크게 향상됩니다.
주요 요점
- 식품 품질은 하이퍼로컬 식품 배달 시장에서 고객 만족을 달성하는 데 중요한 역할을 합니다.
- 딥러닝 기술을 활용하여 정확한 식품 품질 예측자를 훈련할 수 있습니다.
- 이 단계별 가이드를 통해 웹 앱을 구축하는 실습 경험을 얻었습니다.
- 정확한 모델을 구축하기 위해서는 데이터 세트 품질의 중요성을 이해했습니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2024/03/food-quality-detector/

