大規模言語モデル (LLM) は、テキストを生成するようにトレーニングされたディープ ラーニング モデルです。 この印象的な能力により、LLM は現代の自然言語処理 (NLP) のバックボーンとなっています。 従来、彼らは学術機関や、OpenAI、Microsoft、NVIDIA などの大手テクノロジー企業によって事前トレーニングを受けています。 それらのほとんどは、その後、一般に利用できるようになります。 このプラグアンドプレイのアプローチは、大規模な AI の採用に向けた重要なステップです。企業は、一般的な言語知識を備えたモデルのトレーニングに膨大なリソースを費やす代わりに、特定のユース ケースに合わせて既存の LLM を微調整することに集中できるようになりました。
ただし、アプリケーションに適したモデルを選択するのは難しい場合があります。 ユーザーとその他の利害関係者は、言語モデルと関連する革新の活気に満ちた風景を通り抜けなければなりません。 これらの改善は、トレーニング データ、トレーニング前の目的、アーキテクチャ、微調整アプローチなど、言語モデルのさまざまなコンポーネントに対応しています。これらの各側面については、XNUMX 本の本を書くことができます。 これらすべての調査に加えて、巨大な言語モデルにまつわるマーケティングのうわさと人工知能 (AI) の興味深いオーラが、物事をさらに難読化しています。
この詳細な教育コンテンツがあなたに役立つ場合は、 AIメーリングリストに登録する 新しい素材がリリースされたときに警告が表示されます。
この記事では、LLM の背後にある主な概念と原則について説明します。 目標は、非技術関係者に直感的な理解と、開発者や AI 専門家との効率的なやり取りのための言語を提供することです。 より広い範囲をカバーするために、この記事には多数の NLP 関連の出版物に根ざした分析が含まれています。 言語モデルの数学的な詳細については掘り下げませんが、これらは参照から簡単に取得できます。
この記事は次のように構成されています。まず、進化する NLP の状況のコンテキストに言語モデルを配置します。 XNUMX 番目のセクションでは、LLM の構築方法と事前トレーニング方法について説明します。 最後に、微調整プロセスについて説明し、モデルの選択に関するガイダンスを提供します。
言語モデルの世界
人間と機械のギャップを埋める
言語は、人間の心の魅力的なスキルです。言語は、世界に関する豊富な知識だけでなく、意図、意見、感情などのより主観的な側面を伝達するための普遍的なプロトコルです。 AI の歴史の中で、人間の言語を数学的手段で近似 (「モデル化」) するための研究の波が何度もありました。 ディープ ラーニングの時代以前は、表現は単語のワンホット表現、逐次確率モデル、再帰構造などの単純な代数的および確率論的概念に基づいていました。 過去数年間の深層学習の進化により、言語表現の精度、複雑さ、および表現力が向上しました。
2018 年、新しい Transformer アーキテクチャに基づく最初の LLM として BERT が導入されました。 それ以来、Transformer ベースの LLM は勢いを増しています。 言語モデリングは、その普遍的な有用性により、特に魅力的です。 感情分析、情報検索、情報抽出などの現実世界の NLP タスクの多くは言語を生成する必要はありませんが、言語を生成するモデルには、より専門的なさまざまな言語的課題を解決するスキルもあると想定されています。
サイズは重要
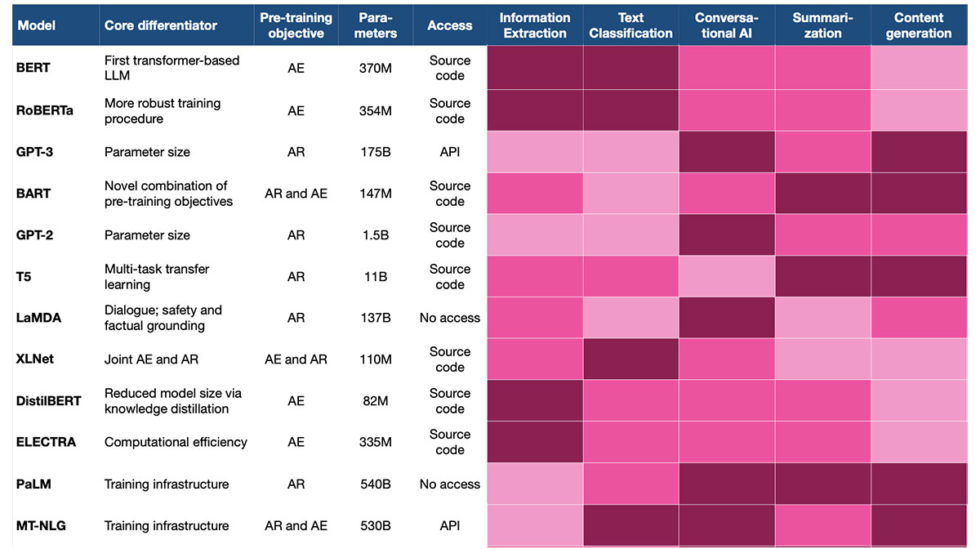
学習はパラメーターに基づいて行われます。パラメーターは、最高の予測品質を達成するためにトレーニング プロセス中に最適化される変数です。 パラメータの数が増えるにつれて、モデルはより詳細な知識を取得し、予測を改善することができます。 2017 ~ 2018 年に最初の LLM が導入されて以来、パラメーター サイズが指数関数的に爆発的に増加しました。画期的な BERT は 340 億 2022 万のパラメーターでトレーニングされましたが、530 年にリリースされたモデルである Megatron-Turing NLG は XNUMX 億のパラメーターでトレーニングされました。千倍の増加。
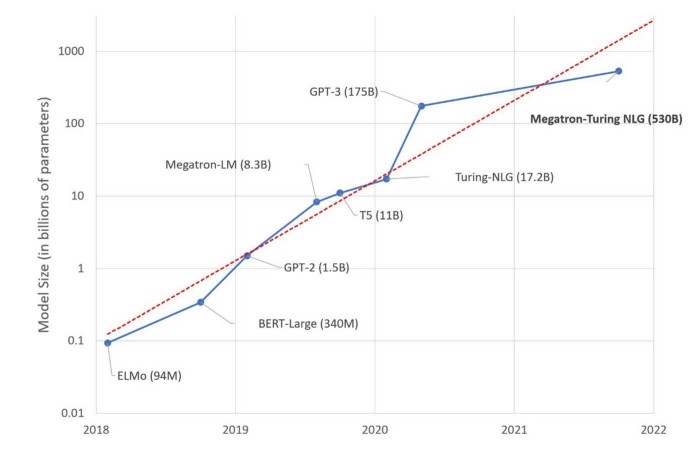
このように、メインストリームは、これまで以上に大量のパラメータで大衆を驚かせ続けています。 ただし、モデルのパフォーマンスがモデルのサイズと同じ速度で向上していないことを指摘する批判的な声がありました。 一方で、モデルの事前トレーニングはかなりの二酸化炭素排出量を残す可能性があります。 ダウンサイジングの取り組みは、言語モデリングの進歩をより持続可能なものにするための力ずくのアプローチに対抗してきました。
言語モデルの寿命
LLM の環境は競争が激しく、革新は短命です。 次のグラフは、15 年から 2018 年までの期間で最も人気のある上位 2022 の LLM と、時間の経過に伴うシェア オブ ボイスを示しています。
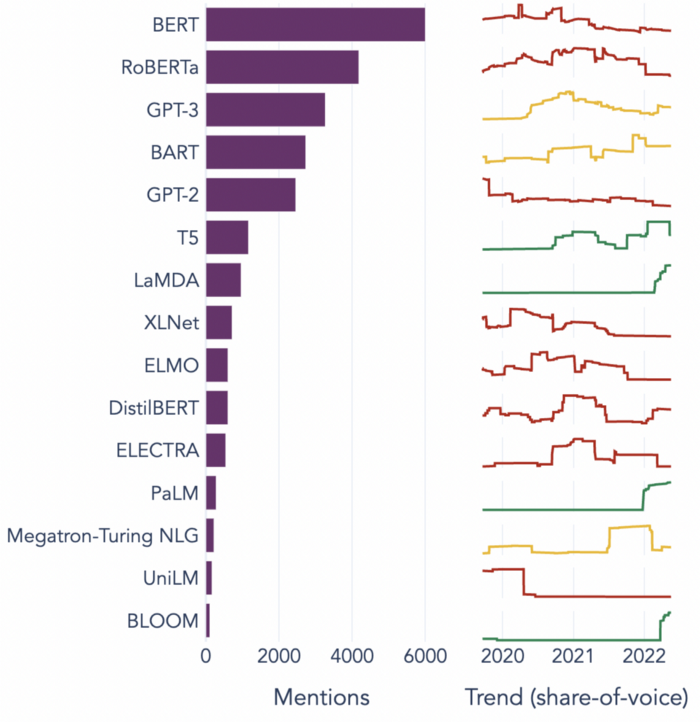
ほとんどのモデルの人気は、比較的短期間で衰退することがわかります。 最先端を維持するために、ユーザーは現在の技術革新を監視し、アップグレードする価値があるかどうかを評価する必要があります。
ほとんどの LLM は同様のライフサイクルに従います。まず、「上流」でモデルが事前トレーニングされます。 データ サイズとコンピューティングに対する要件が厳しいため、これは主に大規模なテクノロジー企業や大学の特権です。 最近では、いくつかの共同作業も行われています (例: ビッグサイエンス ワークショップ)LLM分野の共同発展のために。 Cohere や AI21 Labs など、資金の潤沢な少数の新興企業も事前トレーニング済みの LLM を提供しています。
リリース後、モデルはアプリケーションに焦点を当てた開発者や企業によって「下流」で採用され、展開されます。 この段階では、ほとんどのモデルで、特定のドメインとタスクに対する追加の微調整ステップが必要です。 GPT-3 のような他のものは、予測 (ゼロまたは少数ショット予測) 中にさまざまな言語タスクを直接学習できるという点でより便利です。
最後に、時間の扉がノックされ、さらに多くのパラメーター、より効率的なハードウェアの使用、または人間の言語のモデリングに対するより根本的な改善のいずれかを備えた、より優れたモデルが間近に迫っています。 実質的な革新をもたらしたモデルは、モデルファミリー全体を生み出すことができます。 たとえば、BERT は BERT-QA、DistilBERT、および RoBERTa で生き続けていますが、これらはすべて元のアーキテクチャに基づいています。
次のセクションでは、このライフサイクルの最初の XNUMX つのフェーズ (事前トレーニングと展開のための微調整) について説明します。
事前トレーニング: LLM がどのように生まれるか
ほとんどのチームと NLP 実践者は、LLM の事前トレーニングには関与せず、微調整と展開に関与します。 ただし、モデルを適切に選択して使用するには、「内部」で何が行われているかを理解することが重要です。 このセクションでは、LLM の基本的な構成要素を見ていきます。
- トレーニングデータ
- 入力表現
- 事前トレーニングの目的
- モデル アーキテクチャ (エンコーダー - デコーダー)
これらのそれぞれは、選択だけでなく、LLM の微調整と展開にも影響します。
トレーニングデータ
LLM トレーニングに使用されるデータのほとんどは、文学、ユーザー生成コンテンツ、ニュース データなど、さまざまなスタイルをカバーするテキスト データです。 さまざまな種類のテキストを見た後、結果として得られるモデルは言語の詳細を認識するようになります。 テキスト データ以外に、コードが定期的に入力として使用され、モデルに有効なプログラムとコード スニペットを生成するように教えます。
当然のことながら、トレーニング データの品質はモデルのパフォーマンスに直接影響し、モデルの必要なサイズにも影響します。 トレーニング データを賢く準備すれば、サイズを縮小しながらモデルの品質を向上させることができます。 その一例が T0 モデルです。これは GPT-16 の 3 分の 3 ですが、さまざまなベンチマーク タスクで優れています。 トリックは次のとおりです。テキストをトレーニングデータとして使用するだけでなく、タスクの定式化と直接連携して、学習信号をより集中的にします。 図 XNUMX は、いくつかのトレーニング例を示しています。

トレーニング データに関する最後の注意: 言語モデルは教師なしでトレーニングされるとよく耳にします。 これは魅力的ですが、技術的には間違っています。 代わりに、整形式のテキストは必要な学習シグナルをすでに提供しているため、手動でデータに注釈を付けるという面倒なプロセスを省くことができます。 予測されるラベルは、文中の過去および/または未来の単語に対応します。 したがって、注釈は自動的かつ大規模に行われ、現場での比較的迅速な進歩を可能にします。
入力表現
トレーニング データが組み立てられたら、モデルが消化できる形式にパックする必要があります。 ニューラル ネットワークには代数構造 (ベクトルと行列) が与えられており、言語の最適な代数表現は進行中の探求であり、単純な単語のセットから高度に差別化されたコンテキスト情報を含む表現に到達しています。 新たな一歩を踏み出すたびに、研究者は自然言語の際限のない複雑さに直面し、現在の表現の限界が明らかになります。
言語の基本単位は単語です。 NLP の初期には、これがナイーブを生み出しました。 バッグオブワード 順序に関係なく、テキストからすべての単語を一緒にスローする表現。 次の XNUMX つの例を考えてみましょう。

bag-of-words の世界では、これらの文は同じ単語で構成されているため、まったく同じ表現になります。 明らかに、それはそれらの意味のほんの一部しか含んでいません。
逐次表現は、語順に関する情報に対応します。 ディープラーニングでは、シーケンスの処理はもともと順序認識で実装されていました リカレントニューラルネットワーク (RNN).[2] しかし、さらに一歩進んで、言語の根底にある構造は純粋に連続的ではなく、階層的です。 つまり、リストについてではなく、ツリーについて話しているのです。 離れている単語は、実際には隣接する単語よりも構文上および意味上の結びつきが強い場合があります。 次の例を検討してください。

ここでは、 彼女の を指します 女の子. RNN が文の終わりに到達し、最終的に見るとき 彼女の、文頭の記憶はすでに薄れている可能性があり、この関係を回復することはできません.
これらの遠距離の依存関係を解決するために、より複雑な神経構造が提案され、コンテキストのより差別化された記憶が構築されました。 アイデアは、将来の予測に関連する単語をメモリに保持し、他の単語を忘れるというものです。 これは、Long-Short Term Memory (LSTM)[3] セルと Gated Recurrent Units (GRU)[4] の貢献によるものです。 ただし、これらのモデルは、予測される特定のポジションに対して最適化するのではなく、一般的な将来のコンテキストに対して最適化します。 さらに、構造が複雑なため、従来の RNN よりもトレーニングに時間がかかります。
最後に、人々は再発をなくし、 注意メカニズムに組み込まれている トランスフォーマー [5] 注意により、モデルは予測中に異なる単語間を行き来することができます。 各単語は、予測される特定の位置との関連性に従って重み付けされます。 上記の文の場合、モデルが次の位置に到達すると、 彼女の, 女の子 よりも高い重量になります。 at、線形順序ではるかに離れているという事実にもかかわらず。
これまでのところ、注意メカニズムは、情報処理中の人間の脳の生物学的働きに最も近いものです。 研究によると、注意は階層的な構文構造を学習します。 一連の複雑な構文現象 (cf. BERTology の入門書 およびそこで参照されている論文)。 また、並列計算が可能になるため、より高速で効率的なトレーニングが可能になります。
事前トレーニングの目的
適切なトレーニング データの表現が整ったら、モデルの学習を開始できます。 言語モデルの事前トレーニングに使用される XNUMX つの一般的な目的があります: シーケンスからシーケンスへの変換、自己回帰、および自動エンコードです。 それらはすべて、モデルが幅広い言語知識を習得することを必要とします。
エンコーダー/デコーダー アーキテクチャと Transformer モデルによって対処される元のタスクは次のとおりです。 シーケンスからシーケンスへの変換: シーケンスは、異なる表現フレームワークのシーケンスに変換されます。 古典的なシーケンスからシーケンスへのタスクは機械翻訳ですが、要約などの他のタスクはこの方法で定式化されることがよくあります。 ターゲット シーケンスは必ずしもテキストではないことに注意してください。画像などの他の非構造化データや、プログラミング言語などの構造化データでもかまいません。 sequence-to-sequence LLM の例は、BART ファミリーです。
XNUMXつ目のタスクは 自己回帰、元の言語モデリングの目的でもあります。 自己回帰では、モデルは前のトークンに基づいて次の出力 (トークン) を予測することを学習します。 学習信号は、企業の一方向性によって制限されます。モデルは、予測されたトークンの右または左からの情報のみを使用できます。 単語は過去と将来の位置の両方に依存する可能性があるため、これは大きな制限です。 例として、動詞の使い方を考えてみましょう。 書かれた 両方向で次の文に影響を与えます。

ここで、の位置は 紙 書き込み可能なものに制限されていますが、の位置は 学生 人間、またはとにかく、書くことができる別の知的な実体に制限されています。
今日の見出しを作っている LLM の多くは自己回帰的です。 GPT ファミリー、PaLM および BLOOM。
6 番目のタスクである自動エンコードは、一方向性の問題を解決します。 自動エンコーディングは、従来の単語埋め込みの学習に非常に似ています。[10] まず、入力内のトークンの特定の部分 (通常は 20 ~ XNUMX%) を非表示にして、トレーニング データを破損します。 次に、モデルは、前後のトークンの両方を考慮して、周囲のコンテキストに基づいて正しい入力を再構築することを学習します。 自動エンコーダーの典型的な例は、BERT ファミリーです。 双方向の トランスフォーマーからのエンコーダー表現。
モデル アーキテクチャ (エンコーダー - デコーダー)
言語モデルの基本的な構成要素は、エンコーダーとデコーダーです。 エンコーダーは、元の入力を高次元の代数表現 (「非表示」ベクトルとも呼ばれます) に変換します。 ちょっと待って — 非表示? 実は、現時点では大きな秘密はありません。 もちろん、この表現を見ることはできますが、数字の長いベクトルは、人間にとって意味のあるものを何も伝えません。 それに対処するには、モデルの数学的知性が必要です。 デコーダーは、別の言語、プログラミング コード、画像などのわかりやすい形式で、隠された表現を再現します。

エンコーダー/デコーダー アーキテクチャは、もともとリカレント ニューラル ネットワーク用に導入されました。 注意ベースの Transformer モデルが導入されて以来、従来の反復は人気を失いましたが、エンコーダー/デコーダーのアイデアは存続しています。 ほとんどの自然言語理解 (NLU) タスクはエンコーダーに依存していますが、自然言語生成 (NLG) タスクにはデコーダーが必要であり、シーケンスからシーケンスへの変換には両方のコンポーネントが必要です。
ここでは、Transformer アーキテクチャとアテンション メカニズムの詳細については説明しません。 詳細をマスターしたい人は、頭を包み込むのに十分な時間を費やす準備をしてください. 元の論文を超えて、[7] と [8] は優れた説明を提供します。 簡単な紹介として、Andrew Ng の対応するセクションをお勧めします シーケンスモデルコース.
現実世界での言語モデルの使用
微調整
言語モデリングは強力なアップストリーム タスクです。言語を正常に生成するモデルがある場合、おめでとうございます。それはインテリジェントなモデルです。 ただし、ランダムなテキストでバブリングするモデルを持つことのビジネス上の価値は限られています。 代わりに、NLP はよりターゲットを絞った目的で主に使用されます。 ダウンストリームタスク 感情分析、質問応答、情報抽出など。 応募の時期はこちら 転移学習 より具体的な課題のために既存の言語知識を再利用します。 微調整中、モデルの一部は「凍結」され、残りはドメインまたはタスク固有のデータでさらにトレーニングされます。
明示的な微調整は、LLM 展開への道のりを複雑にします。 また、モデルの急増につながる可能性もあり、各ビジネス タスクには微調整された独自のモデルが必要となり、保守不可能なさまざまなモデルにエスカレートします。 そのため、人々は少数またはゼロショット学習を使用して微調整ステップを取り除く努力をしてきました (GPT-3 [9] など)。 この学習は、予測中にオンザフライで行われます。モデルには、将来の例の予測を導くための「プロンプト」 (タスクの説明と、場合によってはいくつかのトレーニング例) が与えられます。
実装ははるかに迅速ですが、ゼロまたは少数ショット学習の利便性要因は、予測品質の低下によって相殺されます。 さらに、これらのモデルの多くは、クラウド API 経由でアクセスする必要があります。 これは、開発の初期段階では歓迎すべき機会かもしれませんが、より高度な段階では、別の望ましくない外部依存関係に変わる可能性があります。
ダウンストリーム タスクに適したモデルの選択
AI 市場で新しい言語モデルが継続的に供給されていることを考えると、特定のダウンストリーム タスクに適したモデルを選択し、最先端のモデルと同期し続けることは難しい場合があります。
研究論文は通常、特定のダウンストリーム タスクおよびデータセットに対して各モデルをベンチマークします。 などの標準化されたタスク スイート 強力接着剤 および ビッグベンチ 多数の NLP タスクに対する統一されたベンチマークを可能にし、比較の基礎を提供します。 それでも、これらのテストは高度に管理された環境で準備されていることに留意する必要があります。 現在、言語モデルの一般化能力はかなり限られているため、実際のデータセットへの移行はモデルのパフォーマンスに大きな影響を与える可能性があります。 適切なモデルの評価と選択には、本番データにできるだけ近いデータでの実験が必要です。
経験則として、トレーニング前の目標は重要なヒントを提供します。自己回帰モデルは、会話型 AI、質問応答、テキスト要約などのテキスト生成タスクでうまく機能しますが、自動エンコーダーは言語の「理解」と構造化に優れています。たとえば、感情分析およびさまざまな情報抽出タスク用。 ゼロショット学習を目的としたモデルは、適切なプロンプトを受け取る限り、理論的にはあらゆる種類のタスクを実行できますが、精度は一般に微調整されたモデルよりも低くなります。
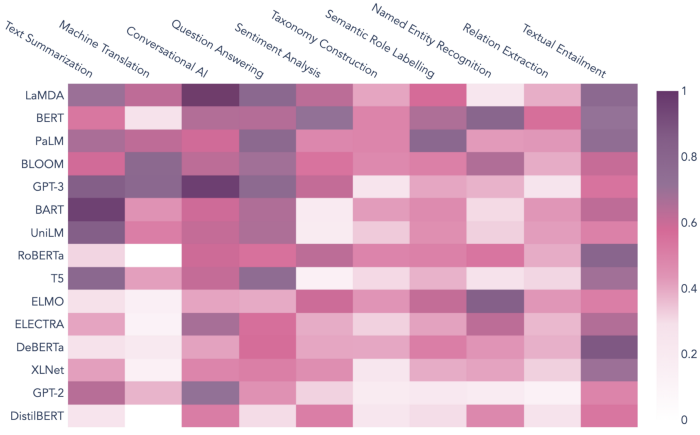
より具体的に説明すると、次の図は、人気のある NLP タスクが NLP 文献の著名な言語モデルとどのように関連付けられているかを示しています。 関連付けは、複数の類似性および集計メトリックに基づいて計算されます。 類似性と距離加重共起の埋め込み。 BART / Text Summarization や LaMDA / Conversational AI など、スコアが高いモデルとタスクのペアは、履歴データに基づいて適切であることを示しています。
主要な取り組み
この記事では、LLM の基本的な概念と、イノベーションが起こっている主な次元について説明しました。 次の表は、最も一般的な LLM の主な機能の概要を示しています。
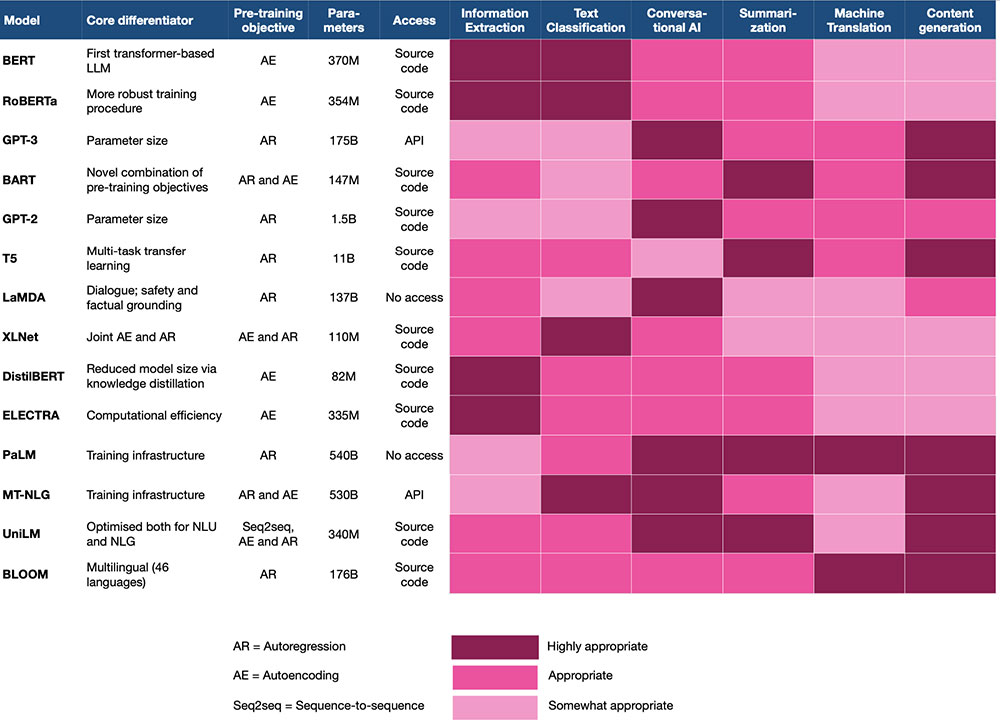
LLM の選択と展開に関する一般的なガイドラインをまとめてみましょう。
1. 潜在的なモデルを評価するときは、AI ジャーニーのどこにいるのかを明確にしてください。
- 最初は、クラウド API を介してデプロイされた LLM を試してみることをお勧めします。
- Product-Market Fit を見つけたら、モデルのホスティングとメンテナンスを自分で行うことを検討して、アプリケーションに対するモデルのパフォーマンスをより詳細に制御し、さらに研ぎ澄まします。
2. 下流のタスクに合わせて、AI チームは次の基準に基づいてモデルの候補リストを作成する必要があります。
- ダウンストリーム タスクに焦点を当てた、学術文献でのベンチマーク結果
- トレーニング前の目的とダウンストリーム タスクの調整: NLU の自動エンコードと NLG の自動回帰を検討する
- このモデルとタスクの組み合わせについて報告された以前の経験 (図 5 を参照)
4. 次に、最終候補のモデルを実際のタスクとデータセットに対してテストして、パフォーマンスの最初の感覚を得る必要があります。
5. ほとんどの場合、専用の微調整を行うことでより良い品質を実現できます。 ただし、内部の技術スキルや微調整のための予算がない場合、または多数のタスクをカバーする必要がある場合は、少数/ゼロ ショット ラーニングを検討してください。
6. LLM のイノベーションとトレンドは短命です。 言語モデルを使用するときは、そのライフサイクルと LLM ランドスケープの全体的なアクティビティに注意を払い、ゲームを強化する機会に注意してください。
最後に、LLM の制限に注意してください。 彼らは言語を生成する驚くべき人間のような能力を持っていますが、全体的な認知力は私たち人間から離れた銀河です. これらのモデルの世界知識と推論能力は、言語の表面で見つけた情報に厳密に制限されています。 また、彼らは事実を適時に配置することができず、まばたきもせずに古い情報を提供する可能性があります。 最新または独自の知識の生成に依存するアプリケーションを構築している場合は、LLM を追加のマルチモーダル、構造化または動的な知識ソースと組み合わせることを検討してください。
参考文献
[1] ビクター・サン他。 2021年。 マルチタスクプロンプトトレーニングにより、ゼロショットタスクの一般化が可能になります. CoRR、abs/2110.08207。
[2] ヨシュア・ベンギオ他。 1994年。 勾配降下法による長期的な依存関係の学習は難しい. ニューラル ネットワーク上の IEEE トランザクション、5(2):157–166。
[3] ゼップ・ホホライターとユルゲン・シュミットフーバー。 1997年。 長期短期記憶. 神経計算、9(8):1735–1780。
[4] チョ・キョンヒョンほか2014年。 ニューラル機械翻訳の性質について: エンコーダ-デコーダのアプローチ。 に SSST-8 の議事録、統計翻訳における構文、意味論、および構造に関する第 XNUMX 回ワークショップ、103~111ページ、ドーハ、カタール。
[5] Ashish Vaswani 他。 2017年。 必要なのは注意だけです。 In 神経情報処理システムの進歩、第 30 巻。Curran Associates, Inc.
[6] トーマス・ミコロフ他。 2013年。 語句の分散表現とその構成性. CoRR、abs/1310.4546。
[7] ジェイ・ジャラマー。 2018年。 図示された変圧器.
[8] アレクサンダー・ラッシュ他。 2018年。 注釈付きトランスフォーマー.
[9] トム・B・ブラウン他。 2020年。 言語モデルは少数の学習者です。 に 神経情報処理システムに関する第34回国際会議の議事録、NIPS'20、レッドフック、ニューヨーク、米国。 カラン・アソシエイツ株式会社
[10] ジェイコブ・デブリンら。 2019年。 BERT: 言語理解のためのディープ双方向トランスフォーマーの事前トレーニング。 に 計算言語学協会の北米支部の2019年会議の議事録:人間言語技術、Volume 1 (Long and Short Papers)、4171 ~ 4186 ページ、ミネソタ州ミネアポリス。
[11] ジュリアン・サイモン 2021. 大規模な言語モデル: 新しいムーアの法則?
[12] 基礎となるデータセット: AI と NLP に関する 320 件を超える記事が、2018 年から 2022 年にかけて専門の AI リソース、テクノロジー ブログ、主要な AI シンクタンクによる出版物で公開されました。
特に断りのない限り、すべての画像は著者によるものです。
この記事は、最初に公開された Janna Lipenkova の Web サイト 著者の許可を得てTOPBOTSに再公開しました。
この記事をお楽しみください? AIリサーチの最新情報にサインアップしてください。
このような要約記事がさらにリリースされたらお知らせします。
関連記事
- コインスマート。 ヨーロッパで最高のビットコインと暗号通貨取引所。ここをクリック
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.topbots.com/choosing-the-right-language-model/

